Hallo. Wir haben mehr als 15.260 Objekte und 38.000 Netzwerkgeräte, die konfiguriert, aktualisiert und überprüft werden müssen, um betriebsbereit zu sein. Die Wartung einer solchen Geräteflotte ist recht schwierig und erfordert viel Zeit, Mühe und Personal. Daher mussten wir die Arbeit mit Netzwerkgeräten automatisieren und beschlossen, das Konzept des Netzwerks als Code für die Verwaltung des Netzwerks in unserem Unternehmen anzupassen. Lesen Sie unter dem Schnitt unsere Automatisierungshistorie, gemachte Fehler und einen weiteren Plan für Gebäudesysteme.
Kurz gesagt, wir wollen das Netzwerk automatisieren
Hallo! Mein Name ist Alexander Prokhorov und zusammen mit dem Team von Netzwerkingenieuren in unserer Abteilung arbeiten wir an einem Netzwerk in
#IT X5 . Unsere Abteilung entwickelt Netzwerkinfrastruktur, Überwachung, Netzwerkautomatisierung und die Trendrichtung von Network as a Code.
Anfangs habe ich im Prinzip nicht wirklich an eine Automatisierung in unserem Netzwerk geglaubt. Es gab viele Legacy- und Konfigurationsfehler - nicht überall gab es eine zentrale Autorisierung, nicht alle Hardware unterstützte SSH, nicht überall, wo
SNMP konfiguriert wurde. All dies hat den Glauben an die Automatisierung stark untergraben. Daher haben wir zunächst aufgeräumt, was zum Starten der Automatisierung erforderlich ist, nämlich: Standardisierung der SSH-Verbindung, Einzelautorisierung (
AAA ) und SNMP-Profile. Mit all diesen Grundlagen können Sie ein Tool für die Massenlieferung von Konfigurationen an ein Gerät schreiben. Es stellt sich jedoch die Frage: Kann ich mehr bekommen? Daher mussten wir einen Plan für die Entwicklung der Automatisierung und insbesondere für das Konzept des Netzwerks als Code erstellen.
Das Konzept des Netzwerks als Code bedeutet laut Cisco die folgenden Prinzipien:
- Speichern Sie Zielkonfigurationen im Repository Quellcodeverwaltung
- Konfigurationsänderungen werden über das Repository "Single Source of Truth" durchgeführt
- Einbetten von Konfigurationen über die API

Mit den ersten beiden Punkten können Sie den DevOps- oder NetDevOps-Ansatz auf die Verwaltung Ihrer Netzwerkinfrastruktur anwenden. Beim dritten Absatz gibt es beispielsweise Schwierigkeiten, was zu tun ist, wenn keine API vorhanden ist. Natürlich, SSH und CLI, wir sind Netzwerker!
Und ist das alles was wir brauchen?Die Anwendung dieser Prinzipien allein löst nicht alle Probleme der Netzwerkinfrastruktur, ebenso wie ihre Anwendung eine bestimmte Grundlage für Netzwerkdaten erfordert.
Fragen, die sich stellten, als wir darüber nachdachten:
- OK, ich speichere die Konfiguration als Code. Wie soll ich sie auf ein bestimmtes Objekt anwenden?
- Ok, ich habe eine Konfigurationsvorlage im Repository, aber wie kann ich automatisch eine Konfiguration für ein darauf basierendes Objekt konfigurieren?
- Wie kann man herausfinden, welches Modell und welcher Anbieter auf diesem Objekt sein sollte? Kann es automatisch sein?
- Wie kann ich überprüfen, ob die aktuellen Einstellungen des Objekts mit den Parametern im Repository übereinstimmen?
- Wie arbeite ich mit Änderungen im Repository und repliziere sie in einem produktiven Netzwerk?
- Welche Datensätze und Systeme muss ich über Zero Touch Provisioning nachdenken?
- Was ist mit den Unterschieden zwischen Anbietern und sogar Modellen desselben Anbieters?
- Wie speichere ich Subnetze für die automatische Konfiguration?
Anhand aller oben genannten Fragen wurde klar, dass wir eine Reihe von Systemen benötigen, die verschiedene Probleme lösen, zusammenarbeiten und uns vollständige Informationen über die Netzwerkinfrastruktur geben.

Neben dem Versuch, neue Ansätze für das Netzwerkmanagement anzuwenden, wollten wir einige akutere Probleme in der Netzwerkinfrastruktur lösen, z. B. Datenintegrität, Aktualisierung und natürlich Automatisierung. Unter Automatisierung verstehen wir nicht nur die Massenlieferung von Konfigurationen an Geräte, sondern auch die automatische Konfiguration, die automatische Erfassung von Inventardaten von Netzwerkgeräten und die Integration in Überwachungssysteme. Aber das Wichtigste zuerst.
Die Funktionalität, die wir anstrebten, ist:
- Datenbank für Netzwerkgeräte (+ Erkennung, + automatische Aktualisierung)
- Basisnetzwerkadressen (IPAM + Validierungsprüfungen)
- Integration von Überwachungssystemen mit Bestandsdaten
- Speicherung von Konfigurationsstandards im Versionskontrollsystem
- Automatische Bildung von Zielkonfigurationen für ein Objekt
- Massenlieferung von Konfigurationen an Netzwerkgeräte
- Implementieren Sie einen CI / CD-Prozess, um Änderungen an der Netzwerkkonfiguration zu verwalten
- Testen von Netzwerkkonfigurationen mit CI / CD
- ZTP (Zero Touch Provisioning) - automatische Einrichtung von Geräten für ein Objekt
Lange Geschichte, wir haben versucht, zu automatisierenWir haben vor 2 Jahren begonnen, die Netzwerk-Setup-Arbeit zu automatisieren. Warum ist diese Frage jetzt wieder aufgetaucht und braucht Aufmerksamkeit?
Es ist mühsam und langweilig, mehr als ein Dutzend Geräte mit den Händen zu konfigurieren. Manchmal zuckt die Hand des Ingenieurs und er macht Fehler. Für mehrere Dutzend reicht normalerweise ein von einem Techniker geschriebenes Skript aus, mit dem die aktualisierten Einstellungen auf die Netzwerkgeräte übertragen werden.
Warum nicht dort aufhören? Tatsächlich wissen viele Netzwerktechniker bereits, wie man alle Arten von Pythons macht, und diejenigen, die nicht wissen, wie man das macht, werden es schon sehr bald können (Natalya Samoilenko hat jedoch
eine hervorragende Arbeit über Python veröffentlicht , insbesondere für Netzwerker). Jeder, der mit der Konfiguration von n + 1 Routern beauftragt ist, kann sehr schnell ein Skript schreiben und die Einstellungen bereitstellen. Viel schneller als dann in der Lage, alles zurückzubringen. Nach der Erfahrung der Automatisierung „jeder für sich“ treten Fehler auf, wenn Sie die Kommunikation nur mit Ihren Händen und nur mit großem Leid des gesamten Teams wiederherstellen können.

Beispiel
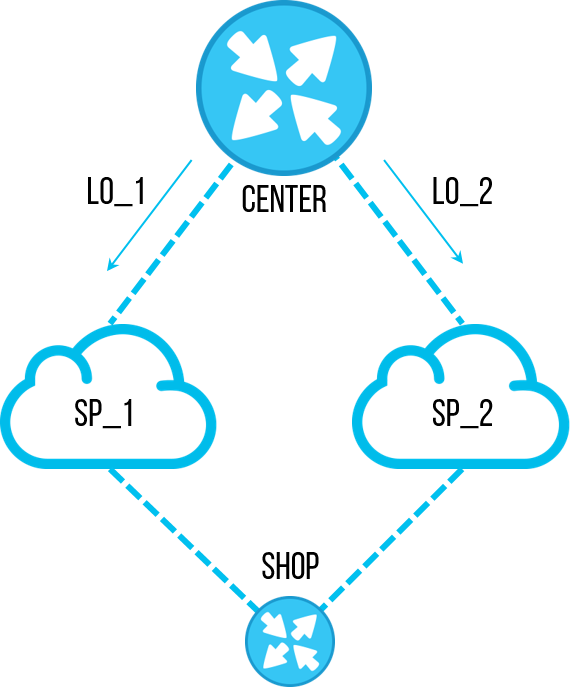
Einmal entschied sich einer der Ingenieure, eine wichtige Aufgabe auszuführen - die Ordnung in den Konfigurationen der Router wiederherzustellen. Als Ergebnis der Prüfung mehrerer Objekte wurde eine veraltete
Präfixliste mit bestimmten Subnetzen gefunden, die wir nicht mehr benötigten. Bisher wurde es verwendet, um die
Loopback- Adressen von zentralen Standorten so zu filtern, dass sie nur über einen Kanal kamen, und wir konnten die Verbindung auf diesem Kanal testen. Der Mechanismus wurde jedoch optimiert, und sie verwendeten kein solches Kanaltestschema mehr. Der Mitarbeiter hat beschlossen, diese
Präfixliste zu entfernen, damit sie nicht in der Konfiguration auftaucht und in Zukunft Verwirrung stiftet. Alle stimmten zu, die nicht verwendete
Präfixliste zu löschen, die Aufgabe ist einfach, sie vergaßen sofort. Das Entfernen derselben
Präfixliste mit den Händen an Dutzenden von Objekten ist jedoch ziemlich langweilig und zeitaufwändig. Und der Ingenieur hat ein Skript geschrieben, das schnell durch die Ausrüstung geht,
"keine Präfixliste pl-cisco-primer" erstellt und die Konfiguration feierlich speichert.
Einige Zeit nach der Diskussion, einige Stunden oder einen Tag, ich erinnere mich nicht, fiel ein Objekt. Nach ein paar Minuten noch eine, ähnlich. Die Anzahl der unzugänglichen Objekte stieg in einer halben Stunde auf 10 weiter an, und alle 2-3 Minuten wurde ein neues hinzugefügt. Alle Ingenieure wurden zur Diagnose angeschlossen. 40-50 Minuten nach Beginn des Unfalls wurden alle zu den Änderungen befragt, und der Mitarbeiter stoppte das Skript. Zu diesem Zeitpunkt gab es bereits etwa 20 Objekte mit unterbrochenen Kanälen. Eine vollständige Restaurierung dauerte 7 Ingenieure für mehrere Stunden.
Technische Seite
Die Präfixliste wurde verwendet, um
Loopbacks zu filtern - einer wurde auf einem Kanal gefiltert, der zweite auf dem Backup. Dies wurde verwendet, um die Kommunikation zu testen, ohne den produktiven Verkehr zwischen Kanälen zu wechseln. Daher war die erste Regel einer eingehenden
Routenkarte auf einem
BGP- Nachbarn
DENY mit
"IP-Adresspräfixliste abgleichen" . Die restlichen Regeln in
der Routenkarte waren alle
ERLAUBT .
Es gibt einige Nuancen, die erwähnenswert sein können:
- Die Routenkartenregel, bei der es keine Übereinstimmung gibt, überspringt alles
- Am Ende der Präfixliste steht implizit Verweigerung , aber nur wenn sie nicht leer ist
- Eine leere Präfixliste ist eine implizite Erlaubnis
All dies gilt für
Cisco IOS . Eine leere
Präfixliste wird möglicherweise angezeigt, wenn Sie eine
Routenkarte deklarieren und sie als
"IP-Adresspräfixliste pl-test-cisco übereinstimmen" festlegen . Diese
Präfixliste wird in der Konfiguration nicht explizit deklariert (zusätzlich zu der Zeile mit
Übereinstimmung ), befindet sich jedoch in der
Präfixliste show ip .
2901-NOC-4.2(config)#route-map rm-test-in 2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh run | i prefix match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh ip prefix ip prefix-list pl-test-in: 0 entries 2901-NOC-4.2(config-route-map)#
Zurück zu dem, was passiert ist, als die Präfixliste vom Skript gelöscht wurde, wurde sie leer, da sie sich noch in der ersten
DENY- Regel in der
Routenkarte befand . Eine leere
Präfixliste erlaubt alle Subnetze, sodass alles, was ein
BGP- Peer an uns übergeben hat, in die erste
DENY- Regel fällt.
Warum bemerkte der Ingenieur nicht sofort, dass er die Verbindung unterbrochen hatte? Hier spielte die Rolle der
BGP- Timer in Cisco.
BGP selbst tauscht keine Routen nach einem Zeitplan aus. Wenn Sie die
BGP- Routing-Richtlinie aktualisiert haben, müssen Sie die BGP-Sitzung zurücksetzen, um die Änderungen
"clear ip bgp <peer-ip>" auf Cisco anzuwenden.
Um die Sitzung nicht zurückzusetzen, gibt es zwei Mechanismen:
Die Soft-Rekonfiguration enthält die vom Nachbarn in
UPDATE empfangenen Informationen zu den Routen, bis Richtlinien in der lokalen
adj-RIB-in- Tabelle angewendet werden. Beim Aktualisieren von Richtlinien wird es möglich,
UPDATE von einem Nachbarn zu emulieren.
Routenaktualisierung ist die "Fähigkeit" von Peers,
UPDATE auf Anfrage zu senden. Die Verfügbarkeit dieser Möglichkeit wird bei der Gründung einer Nachbarschaft vereinbart. Vorteile - Es ist nicht erforderlich, eine Kopie von
UPDATE lokal zu speichern. Nachteile - In der Praxis müssen Sie nach einer
UPDATE- Anfrage eines Nachbarn warten, bis er sie sendet. Übrigens können Sie die Funktion unter Cisco mit einem versteckten Befehl deaktivieren:
neighbor <peer-ip> dont-capability-negotiate
Es gibt eine undokumentierte Funktion von Cisco - einen 30-Sekunden-Timer, der durch eine Änderung der
BGP- Richtlinien ausgelöst wird. Nach dem Ändern der Richtlinien wird in 30 Sekunden der Prozess zum Aktualisieren von Routen mit einer der oben genannten Technologien gestartet. Ich konnte keine dokumentierte Beschreibung dieses Timers finden, aber es wird in
BUG CSCvi91270 erwähnt . Sie können sich über die Verfügbarkeit in der Praxis informieren.

Nachdem Sie im Labor Änderungen vorgenommen und im
Debug nach
UPDATE- Anforderungen an den Nachbarn oder dem
Soft-Rekonfigurationsprozess gesucht
haben . (Wenn es zusätzliche Informationen zum Thema gibt - können Sie in den Kommentaren hinterlassen)
Bei der
Soft-Rekonfiguration funktioniert der Timer folgendermaßen:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26 2901-NOC-4.2(config)#do sh clock 16:53:31.117 Tue Sep 24 2019 Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1 Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map. Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26 Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26 2901-NOC-4.2(config)#
Für die
Routenaktualisierung von der Seite des Nachbarn wie folgt:
2801-RTR (config-router)# *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1 *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
Wenn die
Routenaktualisierung von einem der Peers nicht unterstützt wird und die
eingehende Soft-Rekonfiguration nicht aktiviert ist, erfolgt die Aktualisierung der Routen durch die neue Richtlinie nicht automatisch.
Also wurde die
Präfixliste gelöscht, die Verbindung blieb bestehen, nach 30 Sekunden verschwand sie. Das Skript konnte die Konfiguration ändern, die Verbindung überprüfen und die Konfiguration speichern. Der Sturz aus dem Skript war vor dem Hintergrund einer großen Anzahl von Objekten nicht sofort verbunden.
All dies konnte leicht durch Testen und teilweise Replikation von Einstellungen vermieden werden. Man war sich einig, dass die Automatisierung zentralisiert und gesteuert werden sollte.

Die Systeme, die wir brauchen, und ihre Verbindungen
Eine kurze Schlussfolgerung des Spoilers: Es ist besser, den Prozess der Massenlieferung von Konfigurationen zu systematisieren und zu steuern, um nicht zur Massenlieferung von Fehlern in Konfigurationen zu gelangen.
- DevOps: 50ms 4 - : ", !@#$%"
Das Schema, zu dem wir gekommen sind, besteht aus "Geschäfts" -Stammdatenblöcken, "Netzwerk" -Stammdatenblöcken, Netzwerkinfrastrukturüberwachungssystemen, Konfigurationslieferungssystemen und Versionskontrollsystemen mit einer Testeinheit.
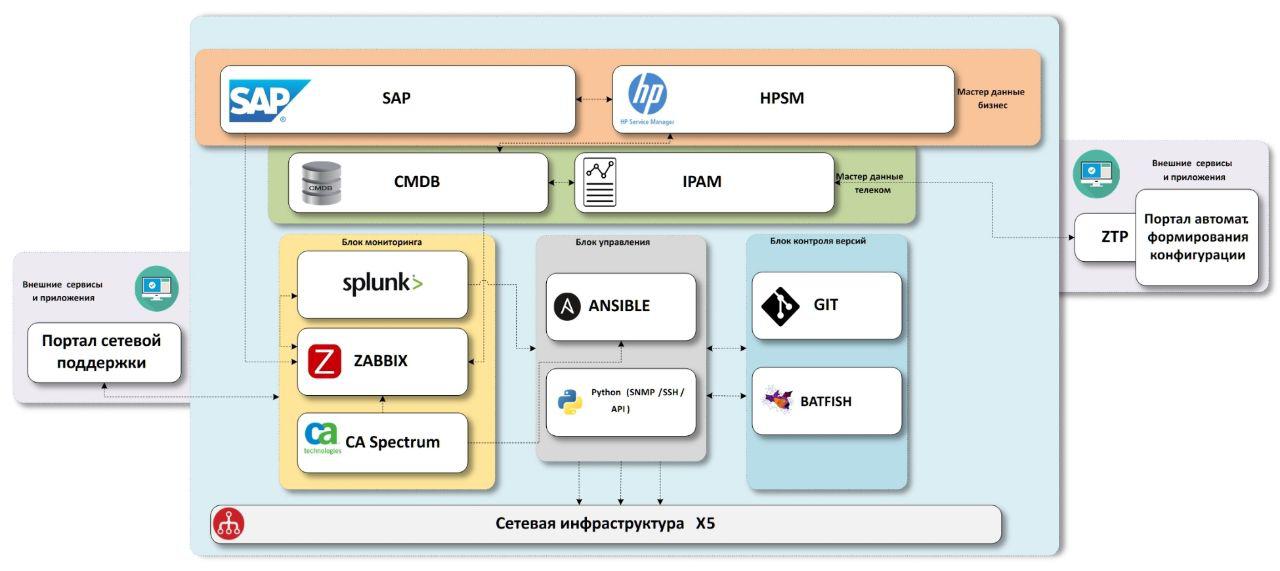
Wir brauchen nur Daten
Zuerst müssen wir wissen, welche Objekte sich im Unternehmen befinden.
SAP -
ERP Unternehmenssystem. Daten zu fast allen Einrichtungen sind vorhanden, genauer gesagt zu allen Filialen und Vertriebszentren. Darüber hinaus gibt es Daten zu Geräten, die ein IT-Lager mit Bestandsnummern durchlaufen haben, was uns auch in Zukunft nützlich sein wird. Es fehlen nur Büros, sie werden nicht im System gestartet. Wir versuchen, dieses Problem in einem separaten Prozess zu lösen. Ab dem Moment des Öffnens benötigen wir eine Verbindung für jedes Objekt und wählen die Einstellungen für die Kommunikation aus. Daher müssen wir irgendwo in diesem Moment Stammdaten erstellen. Datenmangel ist jedoch ein separates Thema. Wenn Interesse daran besteht, ist es besser, diese Beschreibung in einen separaten Artikel aufzunehmen.
HPSM - ein System, das eine gemeinsame
CMDB für IT, Incident Management und Change Management enthält. Da das System allen IT-Abteilungen gemeinsam ist, muss es über alle IT-Geräte einschließlich der Netzwerkgeräte verfügen. Hier fügen wir alle endgültigen Daten über das Netzwerk hinzu. Mit dem Incident- und Change-Management planen wir, in Zukunft von Überwachungssystemen aus zu interagieren.
Wir wissen, welche Objekte wir haben, und bereichern sie mit Daten über das Netzwerk. Zu diesem Zweck haben wir zwei Systeme -
IPAM von
SolarWinds und unser eigenes CMDB.noc-System.
IPAM ist ein Repository für IP-Subnetze. Die korrektesten und korrektesten Daten zum Besitz von IP-Adressen im Unternehmen sollten hier vorhanden sein.
CMDB.noc ist eine Datenbank mit einer WEB-Schnittstelle, in der statische Daten auf Netzwerkgeräten gespeichert werden - Router, Switches, Access Points sowie Anbieter und deren Eigenschaften. Unter statischen Mitteln wird ihre Veränderung nur unter Beteiligung des Menschen durchgeführt. Mit anderen Worten, die automatische Erkennung nimmt keine Änderungen an dieser Datenbank vor. Wir benötigen sie, um zu verstehen, was auf dem Objekt installiert werden soll. Die Basis wird als Puffer zwischen den Produktivsystemen, mit denen das gesamte Unternehmen arbeitet, und den internen Netzwerkwerkzeugen benötigt. Beschleunigt die Entwicklung, Hinzufügen der erforderlichen Felder, neue Beziehungen, Anpassen von Parametern usw. Darüber hinaus besteht diese Lösung nicht nur aus der Geschwindigkeit der Entwicklung, sondern auch aus dem Vorhandensein der Beziehungen zwischen den Daten, die wir benötigen, ohne Kompromisse. Als
kleines Beispiel verwenden wir mehrere
Exids in der Datenbank für die Kommunikation zwischen IPAM, SAP und HPSM.
Als Ergebnis erhielten wir vollständige Daten zu allen Objekten mit angeschlossenen Netzwerkgeräten und IP-Adressen. Jetzt benötigen wir Konfigurationsvorlagen oder Netzwerkdienste, die wir an diesen Standorten bereitstellen.

Eine einzige Quelle der Wahrheit
Hier haben wir gerade die Anwendung des ersten NaaC-Prinzips erreicht - das Speichern von Zielkonfigurationen im Repository. In unserem Fall ist dies Gitlab. Die Wahl für uns war einfach:
- Erstens haben wir dieses Tool bereits in unserem Unternehmen, wir mussten es nicht von Grund auf neu bereitstellen
- Zweitens ist es für alle aktuellen und zukünftigen Aufgaben der Netzwerkinfrastruktur gut geeignet
Der wichtigste interessante Teil der Automatisierung wird in Gitlab stattfinden - der Prozess der Änderung des Konfigurationsstandards oder einfacher der Vorlage.
Beispiel für einen Standardänderungsprozess
Eine der Arten von Objekten, die wir haben, ist der Pyaterochka-Laden. Dort besteht eine typische Topologie aus einem Router und einem / zwei Switches. Die Vorlagenkonfigurationsdatei wird in Gitlab gespeichert, in diesem Teil ist alles einfach. Das ist aber nicht ganz NaaC.
Nehmen wir jetzt an, ein neues Projekt kommt zu uns. Die Aufgabe des neuen IT-Projekts besteht darin, ein Pilotprojekt in einem bestimmten Filialvolumen durchzuführen. Nach den Ergebnissen des Piloten - bei Erfolg eine Replikation für alle Objekte dieses Typs durchführen; Andernfalls kollabieren Sie den Piloten, ohne eine Replikation durchzuführen.
Dieser Prozess passt sehr gut in die Git-Logik:
- Für ein neues Projekt erstellen wir einen Zweig, in dem wir Änderungen an den Konfigurationen vornehmen.
- In Branch führen wir auch eine Liste der Objekte, auf denen dieses Projekt pilotiert wird.
- Bei Erfolg stellen wir eine Zusammenführungsanforderung in der Hauptniederlassung, die in das Produktnetzwerk repliziert werden muss
- Im Fehlerfall verlassen Sie Branch entweder für den Verlauf oder löschen Sie ihn einfach

In erster Näherung - auch ohne Automatisierung - ist es ein sehr praktisches Werkzeug für die Zusammenarbeit an einer Netzwerkkonfiguration. Vor allem, wenn Sie sich vorstellen, dass drei oder mehr Projekte gleichzeitig entstanden sind. Wenn die Zeit für die Freigabe von Projekten in prod gekommen ist, müssen Sie alle Konfigurationskonflikte in den Zusammenführungsanforderungen lösen und sicherstellen, dass sich die Änderungen an den Einstellungen nicht gegenseitig ausschließen. Und das ist sehr praktisch in Git.
Darüber hinaus bietet dieser Ansatz die Flexibilität, mit den Gitlab CI / CD-Tools Konfigurationen virtuell zu testen und die Bereitstellung von Konfigurationen an einen Prüfstand oder eine Pilotgruppe von Objekten zu automatisieren. // Und sogar auf Prod, wenn du willst.
Bereitstellen der Konfiguration in einer beliebigen Umgebung
Ursprünglich war das Hauptziel genau die Massenlieferung von Konfigurationen, ein Tool, mit dem Sie ganz klar Zeit sparen und die Ausführung von Konfigurationsaufgaben beschleunigen können. Zu diesem Zweck haben wir bereits vor Beginn der großartigen Aktivität „Netzwerk als Code“ eine
Python- Lösung für die Verbindung mit Geräten geschrieben, um Gerätekonfigurationen zu erfassen oder zu konfigurieren. Das ist
Netmiko , das ist
Pysnmp , das ist
Jinja2 usw.
Es ist jedoch an der Zeit, die Massenkonfiguration in mehrere Unterarten zu unterteilen:
Lieferung von Konfigurationen an Test- und PilotzonenDieses Element basiert auf Gitlab CI, mit dem Sie die Konfigurationsbereitstellung für die Pilot- und Testzonen in der Pipeline aktivieren können.
Vervielfältigung von Konfigurationen in prod- Ein separates Element, meistens die Replikation auf 38k-Geräte, erfolgt in mehreren Wellen - mit zunehmendem Volumen -, um die Situation im Produkt zu überwachen. Außerdem erfordert eine Arbeit dieser Größenordnung eine Koordinierung der Arbeit. Daher ist es besser, diesen Prozess von Hand zu starten. Hierzu ist es zweckmäßig, Ansible + -AWX zu verwenden und die dynamische Bestandserstellung aus unseren Stammdatensystemen daran zu befestigen.
- Darüber hinaus ist dies eine praktische Lösung, wenn Sie der zweiten Zeile den Start vorkonfigurierter Playbooks geben müssen, die komplexe und wichtige Vorgänge ausführen, z. B. das Umschalten des Datenverkehrs zwischen Standorten.
Datenerfassung- Netzwerkgeräte automatisch erkennen
- Backup-Konfigurationen
- Überprüfen Sie die Konnektivität
Wir haben diese Aufgabe in einem separaten Block zugewiesen, da es Zeiten gibt, in denen jemand plötzlich einen Switch zerlegt oder ein neues Gerät installiert hat, aber wir wussten dies nicht im Voraus. Dementsprechend ist dieses Gerät nicht in unseren Stammdaten enthalten und fällt aus dem Prozess der Konfigurationsbereitstellung, Überwachung und im Allgemeinen der Betriebsarbeit heraus. Es kommt vor, dass das Gerät rechtmäßig installiert wurde, aber die Konfiguration dort falsch "gegossen" wurde und aus irgendeinem Grund
ssh ,
snmp ,
aaa oder nicht standardmäßige Passwörter für den Zugriff dort nicht funktionieren. Zu diesem Zweck haben wir Python, um alle möglichen
Legacy- Verbindungsmethoden, die wir im Unternehmen haben könnten, auszuprobieren, alle alten Passwörter
brutal zu erzwingen und alles, um an das Stück Eisen zu gelangen und es für die Arbeit mit
Ansible und Überwachung vorzubereiten .
Es gibt eine einfache Möglichkeit, mehrere
Inventardateien für Ansible zu erstellen, in denen alle möglichen Daten für Verbindungen (alle Arten von Anbietern mit allen möglichen Benutzernamen / Passwort-Paaren) beschrieben und für jede
Inventarvariante ein
Playbook ausgeführt werden. Wir hofften auf eine bessere Lösung, aber auf der RedHat-Konferenz riet Ansible Architect auf die gleiche Weise. Es wird allgemein angenommen, dass Sie im Voraus wissen, mit was Sie sich verbinden.
Wir wollten eine universelle Lösung - suchen Sie beim Entfernen eines Backups nach neuen Geräten und fügen Sie diese, falls vorhanden, allen erforderlichen Systemen hinzu. Aus diesem Grund wählen wir eine Lösung in Python - wissen, was schöner sein könnte als ein Programm, das selbst eine Netzwerkhardware erkennt, um eine Verbindung herzustellen, unabhängig davon, was darauf konfiguriert ist (natürlich in angemessenen Grenzen), nach Bedarf konfigurieren, die Konfiguration entfernen und gleichzeitig Fügen Sie den erforderlichen Systemen API-Daten hinzu.
Überprüfung wie Überwachung
Eine der Aufgaben der Automatisierung ist es natürlich herauszufinden, was aus dieser Automatisierung herausgefallen ist. Nicht alle 38k sind beim ersten Mal perfekt konfiguriert, es kommt sogar vor, dass jemand die Ausrüstung mit den Händen aufstellt. Und es ist notwendig, diese Änderungen zu verfolgen und
der Zielkonfiguration wieder
gerecht zu werden .
Es gibt drei Ansätze zur Überprüfung der Konformitätskonformität mit dem Standard:
- Führen Sie einmal pro Periode eine Überprüfung durch - entladen Sie den aktuellen Status, überprüfen Sie ihn anhand des Ziels und beheben Sie die festgestellten Mängel.
- Führen Sie die Zielkonfigurationen einmal pro Zeitraum aus, ohne etwas zu überprüfen. Es besteht die Gefahr, dass etwas kaputt geht - möglicherweise war nicht alles in der Zielkonfiguration enthalten.
- Ein praktischer Ansatz ist, wenn Unterschiede zur Zielkonfiguration in Single Source of Truth als Warnungen betrachtet und vom Überwachungssystem überwacht werden. Dies beinhaltet: eine Nichtübereinstimmung mit dem aktuellen Konfigurationsstandard, einen Unterschied zwischen der Hardware und der in den Stammdaten angegebenen, eine Nichtübereinstimmung mit den Daten in IPAM .
Im dritten Fall scheint eine Option diese Arbeit an das Incident Management (OS) zu übertragen, so dass die Inkonsistenzen während der gesamten Zeit in kleinen Teilen als einmal im Notfall beseitigt werden.
Zabbix , über das ich bereits in dem Artikel
„Wie wir 14.000 Objekte überwacht haben“ geschrieben habe, ist unser System zur Überwachung verteilter Objekte, mit dem wir alle möglichen Auslöser und Warnungen auslösen können. Seit dem Schreiben des letzten Artikels haben wir ein Upgrade auf Zabbix 4.0
LTS durchgeführt .
Basierend auf
Web Zabbix haben wir ein Update für unser Netzwerk-Support-Portal vorgenommen, in dem Sie jetzt alle Informationen zu einem Objekt von allen unseren Systemen auf einem Bildschirm finden und Skripts ausführen können, um nach häufig auftretenden Problemen zu suchen.
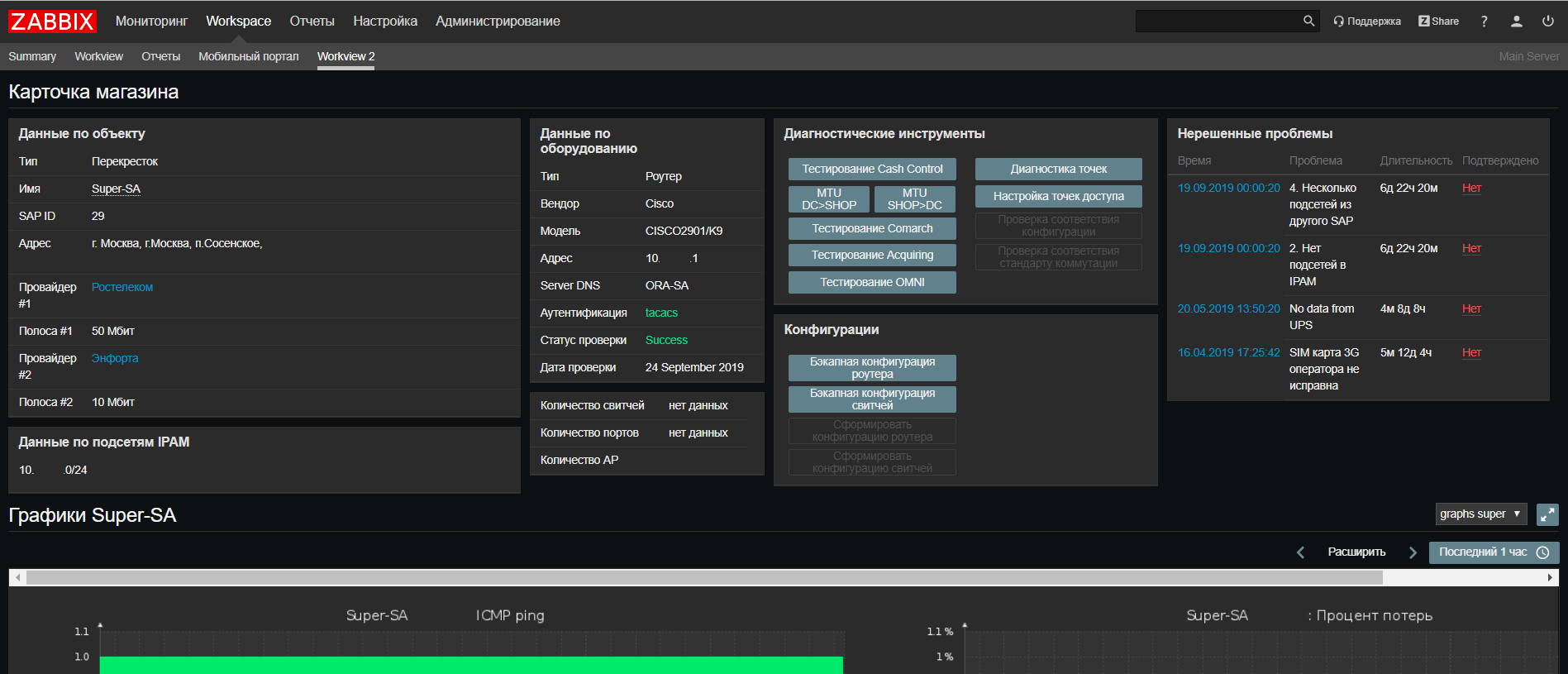
Wir haben auch eine neue Funktion eingeführt - für uns ist Zabbix in gewisser Weise ein
CRON zum Starten geplanter Skripte wie Systemintegrationsskripte und Skripte zur
automatischen Erkennung geworden . Dies ist sehr praktisch, wenn Sie sich aktuelle Skripts ansehen müssen und wann und wo sie ausgeführt werden, ohne alle Server zu überprüfen. Für Skripte, die länger als 30 Sekunden ausgeführt werden, benötigen Sie einen
Launcher , der sie startet, ohne auf das Ende zu warten. Zum Glück ist es einfach:
 Splunk
Splunk ist eine Lösung, mit der Sie Ereignisprotokolle von Netzwerkgeräten erfassen können.
Diese Lösung kann auch zur Überwachung der Automatisierung verwendet werden. Wenn beispielsweise eine Konfigurationssicherung
erfasst wird , generiert ein
Python- Skript eine
LOG- Nachricht
CFG-5-BACKUP . Ein Router oder Switch sendet eine Nachricht an Splunk, in der die Anzahl der Nachrichten dieses Typs von Netzwerkgeräten gezählt wird. Auf diese Weise können wir die Menge der vom Skript erkannten Geräte verfolgen. Und wir sehen, wie viele Eisenstücke dies
Splunk melden
konnten und überprüfen, ob Nachrichten von allen Eisenstücken eingetroffen sind.
Spectrum ist ein umfassendes System, mit dem wir kritische Objekte überwachen. Dieses leistungsstarke Tool hilft uns sehr bei der Lösung kritischer Netzwerkvorfälle. In der Automatisierung verwenden wir es nur zum Abrufen von Daten, es ist nicht
Open Source , daher sind die Möglichkeiten etwas begrenzt.
Die Kirsche auf dem Kuchen

Bei Verwendung von Systemen mit Stammdaten auf Geräten können wir über das Erstellen von ZTP oder Zero Touch Provisioning nachdenken. Wie eine Taste "Auto-Tuning", aber nur ohne Taste.
Wir haben alle notwendigen Daten aus den vorherigen Blöcken - wir kennen das Objekt, seinen Typ, welche Ausrüstung (Hersteller und Modell), welche Adressen (IPAM) und welcher aktuelle Konfigurationsstandard (Git). Indem wir sie alle zusammenfügen, können wir zumindest eine Konfigurationsvorlage für das Hochladen auf das Gerät vorbereiten. Sie ähnelt eher der One-Touch-Bereitstellung, manchmal ist jedoch nicht mehr erforderlich.
True Zero Touch benötigt eine Möglichkeit, die Konfiguration automatisch an nicht konfigurierte Hardware zu liefern. Darüber hinaus ist es unabhängig vom Anbieter wünschenswert. Es gibt verschiedene Arbeitsoptionen - einen Konsolenserver, wenn alle Geräte das Zentrallager durchlaufen, mobile Konsolenlösungen, wenn die Geräte sofort eintreffen. Wir arbeiten gerade an diesen Lösungen, aber sobald es eine funktionierende Option gibt, können wir sie teilen.
Fazit
Insgesamt gab es in unserem Konzept von
Netzwerk als Code 5 Hauptmeilensteine:
- Stammdaten (Kommunikation von Systemen und Daten untereinander, API von Systemen, ausreichende Daten für Support und Start)
- Überwachung von Daten und Konfigurationen (automatische Erkennung von Netzwerkgeräten, Überprüfung der Relevanz der Konfiguration in der Einrichtung)
- Konfigurationen für Versionskontrolle, Testen und Pilotieren (Gitlab CI / CD für das Netzwerk, Tools zum Testen der Netzwerkkonfiguration)
- Konfigurationsbereitstellung (Ansible, AWX, Python-Skripte zum Verbinden)
- Zero Touch Provisioning (Welche Daten werden benötigt, wie wird ein Prozess so erstellt, dass eine Verbindung zu einer nicht konfigurierten Hardware hergestellt wird?)
Es hat nicht funktioniert, alles in einen Artikel zu packen, jeder Punkt verdient eine separate Diskussion, wir können jetzt über etwas sprechen, über etwas, wenn wir die Lösungen in der Praxis überprüfen. Wenn Sie an einem der Themen interessiert sind, finden Sie am Ende eine Umfrage, in der Sie für den nächsten Artikel abstimmen können. Wenn das Thema nicht in der Liste enthalten ist, es aber interessant ist, darüber zu lesen, hinterlassen Sie so bald wie möglich einen Kommentar und teilen Sie unsere Erfahrungen mit.
Besonderer Dank geht an Alexander Virilin (
xscrew ) und Sibgatulin Marat (
eucariot ) für den Referenzbesuch im Herbst 2018 in der Yandex Cloud und die Geschichte über die Automatisierung in der Cloud-Netzwerkinfrastruktur. Nach ihm erhielten wir Inspiration und viele Ideen zum Einsatz von Automatisierung und NetDevOps in der Infrastruktur der X5 Retail Group.