Heutzutage bedeuten die Wörter "künstliche Intelligenz" viele verschiedene Systeme - von einem neuronalen Netzwerk zur Bilderkennung bis zu einem Bot zum Spielen von Quake. Wikipedia gibt eine wunderbare Definition von KI - dies ist "die Eigenschaft intelligenter Systeme, kreative Funktionen auszuführen, die traditionell als Vorrecht des Menschen angesehen werden". Das heißt, aus der Definition geht klar hervor, dass eine bestimmte Funktion, wenn sie erfolgreich automatisiert wurde, nicht mehr als künstliche Intelligenz betrachtet wird.
Als jedoch die Aufgabe „künstliche Intelligenz schaffen“ zum ersten Mal gestellt wurde, bedeutete KI etwas anderes. Dieses Ziel wird jetzt als Starke KI oder Allzweck-KI bezeichnet.
Erklärung des Problems
Nun gibt es zwei bekannte Formulierungen des Problems. Der erste ist Starke KI. Die zweite ist eine Allzweck-KI (auch bekannt als Artifical General Intelligence, abgekürzt AGI).
Upd. In den Kommentaren sagen sie mir, dass dieser Unterschied auf der Ebene der Sprache wahrscheinlicher ist. Im Russischen bedeutet das Wort "Intelligenz" nicht genau das, was das Wort "Intelligenz" im Englischen bedeutet
Eine starke KI ist eine hypothetische KI, die alles kann, was eine Person tun kann. Es wird normalerweise erwähnt, dass er den Turing-Test in der Anfangseinstellung bestehen muss (hmm, bestehen die Leute ihn?), Sich seiner selbst als separate Person bewusst sein und in der Lage sein muss, seine Ziele zu erreichen.
Das heißt, es ist so etwas wie eine künstliche Person. Meiner Meinung nach ist der Nutzen einer solchen KI hauptsächlich Forschung, da die Definitionen einer starken KI nirgendwo sagen, was ihre Ziele sein werden.
AGI oder Allzweck-KI ist eine „Maschine der Ergebnisse“. Sie erhält eine bestimmte Zielsetzung am Eingang - und gibt einige Steueraktionen für Motoren / Laser / Netzwerkkarten / Monitore aus. Und das Ziel ist erreicht. Gleichzeitig hat AGI zunächst kein Wissen über die Umgebung - nur Sensoren, Aktoren und den Kanal, über den es Ziele setzt. Das Managementsystem wird als AGI betrachtet, wenn es in einer beliebigen Umgebung Ziele erreichen kann. Wir haben sie dazu gebracht, ein Auto zu fahren und Unfälle zu vermeiden - sie wird damit umgehen. Wir haben sie unter die Kontrolle eines Kernreaktors gebracht, damit mehr Energie vorhanden ist, aber nicht explodiert - sie kann damit umgehen. Wir werden einen Briefkasten geben und anweisen, Staubsauger zu verkaufen - werden auch damit fertig. AGI ist ein Löser für "inverse Probleme". Es ist ganz einfach zu überprüfen, wie viele Staubsauger verkauft werden. Aber herauszufinden, wie man eine Person davon überzeugt, diesen Staubsauger zu kaufen, ist bereits eine Aufgabe für den Intellekt.
In diesem Artikel werde ich über AGI sprechen. Keine Turing-Tests, kein Selbstbewusstsein, keine künstlichen Persönlichkeiten - außergewöhnlich pragmatische KI und nicht weniger pragmatische Operatoren.
Aktueller Stand der Dinge
Jetzt gibt es eine Klasse von Systemen wie Verstärkungslernen oder verstärktes Lernen. Dies ist so etwas wie AGI, nur ohne Vielseitigkeit. Sie können lernen und dadurch Ziele in einer Vielzahl von Umgebungen erreichen. Dennoch sind sie in jedem Umfeld weit davon entfernt, Ziele zu erreichen.
Wie sind Reinforcement Learning-Systeme im Allgemeinen angeordnet und was sind ihre Probleme?
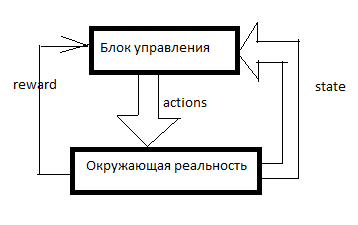
Jedes RL ist so angeordnet. Es gibt ein Steuerungssystem, einige Signale über die umgebende Realität treten durch die Sensoren (Zustand) und durch die Leitungsgremien (Aktionen) in das System ein, das auf die umgebende Realität einwirkt. Belohnung ist ein Signal der Verstärkung. In RL-Systemen wird die Verstärkung von außerhalb der Steuereinheit gebildet und zeigt an, wie gut die KI mit dem Erreichen des Ziels zurechtkommt. Wie viele Staubsauger wurden zum Beispiel in letzter Minute verkauft?
Dann wird eine Tabelle aus so etwas gebildet (ich werde es die SAR-Tabelle nennen):

Die Zeitachse ist nach unten gerichtet. Die Tabelle zeigt alles, was die KI getan hat, alles, was sie gesehen hat und alle Verstärkungssignale. Damit RL etwas Sinnvolles tun kann, muss er normalerweise zunächst eine Weile zufällige Bewegungen ausführen oder sich die Bewegungen einer anderen Person ansehen. Im Allgemeinen startet RL, wenn die SAR-Tabelle bereits mindestens einige Zeilen enthält.
Was passiert als nächstes?
Sarsa
Die einfachste Form des verstärkenden Lernens.
Wir nehmen eine Art maschinelles Lernmodell und sagen unter Verwendung einer Kombination von S und A (Zustand und Aktion) das Gesamt-R für die nächsten Taktzyklen voraus. Zum Beispiel werden wir sehen, dass (basierend auf der obigen Tabelle), wenn Sie einer Frau sagen: „Sei ein Mann, kaufe einen Staubsauger!“, Dann ist die Belohnung niedrig, und wenn du einem Mann dasselbe sagst, dann hoch.
Welche spezifischen Modelle verwendet werden können - ich werde später beschreiben, im Moment werde ich nur sagen, dass dies nicht nur neuronale Netze sind. Sie können Entscheidungsbäume verwenden oder sogar eine Funktion in einer Tabellenform definieren.
Und dann passiert folgendes. AI empfängt eine andere Nachricht oder einen Link zu einem anderen Client. Alle Kundendaten werden von außen in die KI eingegeben - wir betrachten den Kundenstamm und den Nachrichtenzähler als Teil des Sensorsystems. Das heißt, es bleibt etwas A (Aktion) zuzuweisen und auf Verstärkung zu warten. AI ergreift alle möglichen Maßnahmen und sagt dies wiederum voraus (unter Verwendung des gleichen Modells für maschinelles Lernen) - was passiert, wenn ich das tue? Was ist, wenn es ist? Und wie viel Verstärkung wird dafür sein? Und dann führt RL die Aktion aus, für die die maximale Belohnung erwartet wird.
Ich habe ein so einfaches und ungeschicktes System in eines meiner Spiele eingeführt. SARSA stellt Einheiten im Spiel ein und passt sich im Falle einer Änderung der Spielregeln an.
Darüber hinaus gibt es bei allen Arten von verstärktem Training einen Rabatt auf Belohnungen und ein Explorations- / Exploit-Dilemma.
Das Diskontieren von Belohnungen ist ein solcher Ansatz, wenn RL versucht, nicht den Belohnungsbetrag für die nächsten N Züge zu maximieren, sondern den gewichteten Betrag nach dem Prinzip "100 Rubel sind jetzt besser als 110 in einem Jahr". Wenn der Abzinsungsfaktor beispielsweise 0,9 beträgt und der Planungshorizont 3 beträgt, trainieren wir das Modell nicht für die nächsten 3 Taktzyklen, sondern für R1 * 0,9 + R2 * 0,81 + R3 * 0,729. Warum ist das notwendig? Dann brauchen wir diese KI, die irgendwo im Unendlichen einen Gewinn erzielt, nicht. Wir brauchen eine KI, die hier und jetzt einen Gewinn generiert.
Dilemma erkunden / ausnutzen. Wenn RL das tut, was sein Modell für optimal hält, wird es nie erfahren, ob es bessere Strategien gibt. Exploit ist eine Strategie, bei der RL das tut, was maximale Belohnungen verspricht. Explore ist eine Strategie, bei der RL etwas unternimmt, um die Umgebung auf der Suche nach besseren Strategien zu erkunden. Wie implementiere ich effektive Intelligenz? Beispielsweise können Sie alle paar Takte eine zufällige Aktion ausführen. Oder Sie können nicht ein Vorhersagemodell erstellen, sondern mehrere mit leicht unterschiedlichen Einstellungen. Sie führen zu unterschiedlichen Ergebnissen. Je größer der Unterschied ist, desto größer ist der Unsicherheitsgrad dieser Option. Sie können die Aktion so ausführen, dass sie den Maximalwert hat: M + k * std, wobei M die durchschnittliche Vorhersage aller Modelle ist, std die Standardabweichung der Vorhersagen ist und k der Neugierkoeffizient ist.
Was sind die Nachteile?Nehmen wir an, wir haben Optionen. Gehen Sie mit dem Auto zum Ziel (das 10 km von uns entfernt ist und die Straße dorthin ist gut) oder gehen Sie zu Fuß. Und dann, nach dieser Wahl, haben wir Optionen - gehen Sie vorsichtig vor oder versuchen Sie, gegen jede Säule zu stoßen.
Die Person wird sofort sagen, dass es normalerweise besser ist, ein Auto zu fahren und sich vorsichtig zu verhalten.
Aber SARSA ... Er wird sich ansehen, wozu die Entscheidung, mit dem Auto zu fahren, zuvor geführt hat. Aber es führte dazu. In der Phase der ersten Statistik fuhr die KI rücksichtslos und stürzte in der Hälfte der Fälle irgendwo ab. Ja, er kann gut fahren. Aber wenn er sich für ein Auto entscheidet, weiß er nicht, was er als nächstes wählen wird. Er hat Statistiken - dann wählte er in der Hälfte der Fälle die geeignete Option und in der Hälfte Selbstmord. Daher ist es im Durchschnitt besser zu laufen.
SARSA geht davon aus, dass der Agent dieselbe Strategie einhält, mit der die Tabelle gefüllt wurde. Und handelt auf dieser Basis. Aber was ist, wenn wir etwas anderes annehmen - dass der Agent in den nächsten Schritten die beste Strategie einhält?
Q-Learning
Dieses Modell berechnet für jeden Staat die maximal erreichbare Gesamtbelohnung daraus. Und er schreibt es in eine spezielle Spalte Q. Das heißt, wenn Sie aus dem Zustand S je nach Kurs 2 Punkte oder 1 erhalten können, ist Q (S) gleich 2 (mit einer Vorhersage-Tiefe von 1). Welche Belohnung aus dem Zustand S erhalten werden kann, lernen wir aus dem Vorhersagemodell Y (S, A). (S - Zustand, A - Aktion).
Dann erstellen wir ein Vorhersagemodell Q (S, A) - das heißt, in welchen Zustand Q geht, wenn wir Aktion A von S ausführen. Und erstellen die nächste Spalte in der Tabelle - Q2. Das heißt, das Maximum Q, das aus dem Zustand S erhalten werden kann (wir sortieren alle möglichen A).
Dann erstellen wir ein Regressionsmodell Q3 (S, A) - das heißt, in den Zustand, mit dem wir Q2 gehen, wenn wir Aktion A von S ausführen.
Usw. So können wir eine unbegrenzte Prognosetiefe erreichen.
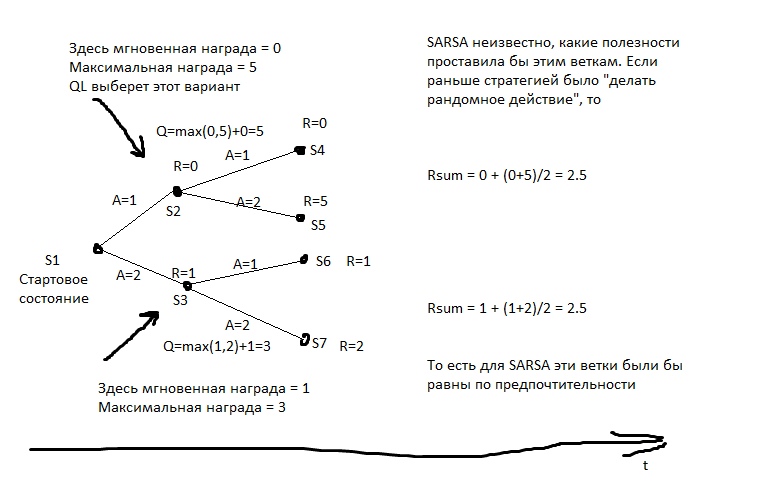
Im Bild ist R die Verstärkung.
Und dann wählen wir bei jeder Bewegung die Aktion aus, die das größte Qn verspricht. Wenn wir diesen Algorithmus auf Schach anwenden würden, würden wir so etwas wie einen idealen Minimax erhalten. Etwas, das fast einer Fehlkalkulation entspricht, bewegt sich in große Tiefen.
Ein häufiges Beispiel für Q-Learning-Verhalten. Der Jäger hat einen Speer und geht von sich aus mit zum Bären. Er weiß, dass die überwiegende Mehrheit seiner zukünftigen Züge eine sehr große negative Belohnung hat (es gibt viel mehr Möglichkeiten zu verlieren als zu gewinnen). Er weiß, dass es Züge mit einer positiven Belohnung gibt. Der Jäger glaubt, dass er in Zukunft die besten Züge machen wird (und es ist nicht bekannt, welche wie in SARSA), und wenn er die besten Züge macht, wird er den Bären besiegen. Das heißt, um zum Bären zu gehen, reicht es aus, dass er jedes Element herstellen kann, das für die Jagd notwendig ist, aber es ist nicht notwendig, Erfahrung mit sofortigem Erfolg zu haben.
Wenn der Jäger im SARSA-Stil handeln würde, würde er davon ausgehen, dass seine Handlungen in Zukunft ungefähr die gleichen sein würden wie zuvor (trotz der Tatsache, dass er jetzt ein anderes Wissensgepäck hat), und er würde nur zum Bären gehen, wenn er bereits zu ging und er gewann zum Beispiel in> 50% der Fälle (na ja, oder wenn andere Jäger in mehr als der Hälfte der Fälle gewonnen haben, wenn er aus ihren Erfahrungen lernt).
Was sind die Nachteile?- Das Modell kommt mit der sich ändernden Realität nicht zurecht. Wenn wir unser ganzes Leben lang für das Drücken des roten Knopfes ausgezeichnet wurden und sie uns jetzt bestrafen und keine sichtbaren Veränderungen aufgetreten sind ... QL wird dieses Muster für eine sehr lange Zeit beherrschen.
- Qn kann eine sehr komplexe Funktion sein. Um dies zu berechnen, müssen Sie beispielsweise einen Zyklus von N Iterationen scrollen - und es wird nicht schneller funktionieren. Ein Vorhersagemodell weist normalerweise eine begrenzte Komplexität auf - selbst ein großes neuronales Netzwerk hat eine Komplexitätsgrenze, und fast kein maschinelles Lernmodell kann Zyklen drehen.
- Die Realität hat normalerweise versteckte Variablen. Wie spät ist es jetzt zum Beispiel? Es ist leicht herauszufinden, ob wir auf die Uhr schauen, aber sobald wir wegschauen, ist dies bereits eine versteckte Variable. Um diese nicht beobachtbaren Werte zu berücksichtigen, muss das Modell nicht nur den aktuellen Status, sondern auch eine Art Verlauf berücksichtigen. In QL können Sie dies tun - zum Beispiel, um nicht nur das aktuelle S, sondern auch mehrere vorherige in das Neuron-oder-was-bei-uns-dort einzuspeisen. Dies geschieht in RL, das Atari-Spiele spielt. Darüber hinaus können Sie ein wiederkehrendes neuronales Netzwerk für die Vorhersage verwenden - lassen Sie es nacheinander über mehrere Frames des Verlaufs laufen und berechnen Sie Qn.
Modellbasierte Systeme
Aber was ist, wenn wir nicht nur R oder Q vorhersagen, sondern im Allgemeinen alle sensorischen Daten? Wir werden ständig eine Taschenkopie der Realität haben und in der Lage sein, unsere Pläne darauf zu überprüfen. In diesem Fall sind wir viel weniger besorgt über die Schwierigkeit, die Q-Funktion zu berechnen. Ja, für die Berechnung sind viele Uhren erforderlich. Auf jeden Fall werden wir für jeden Plan das Prognosemodell wiederholt ausführen. Planen Sie 10 Schritte vorwärts? Wir starten das Modell zehnmal und jedes Mal, wenn wir seine Ausgaben seiner Eingabe zuführen.
Was sind die Nachteile?- Ressourcenintensität. Angenommen, wir müssen bei jeder Maßnahme zwei Alternativen auswählen. Dann haben wir für 10 Taktzyklen 2 ^ 10 = 1024 mögliche Pläne. Jeder Plan umfasst 10 Modellstarts. Wenn wir ein Flugzeug mit Dutzenden von Leitungsgremien kontrollieren? Und simulieren wir die Realität mit einem Zeitraum von 0,1 Sekunden? Möchten Sie einen Planungshorizont für mindestens ein paar Minuten haben? Wir müssen das Modell viele Male ausführen, es gibt viele Prozessortaktzyklen für eine Lösung. Selbst wenn Sie die Aufzählung von Plänen irgendwie optimieren, gibt es dennoch Größenordnungen mehr Berechnungen als in QL.
- Das Problem des Chaos. Einige Systeme sind so konzipiert, dass bereits eine geringe Ungenauigkeit der Eingabesimulation zu einem großen Ausgabefehler führt. Um dem entgegenzuwirken, können Sie mehrere Simulationen der Realität ausführen - etwas anders. Sie werden sehr unterschiedliche Ergebnisse liefern, und daraus wird es möglich sein zu verstehen, dass wir uns in der Zone einer solchen Instabilität befinden.
Strategie-Aufzählungsmethode
Wenn wir Zugriff auf die Testumgebung für KI haben, wenn wir sie nicht in der Realität, sondern in einer Simulation ausführen, können wir die Strategie des Verhaltens unseres Agenten in irgendeiner Form aufschreiben. Und dann wählen Sie - mit Evolution oder etwas anderem - eine Strategie, die zu maximalem Gewinn führt.
„Wähle eine Strategie“ bedeutet, dass wir zuerst lernen müssen, wie man eine Strategie so aufschreibt, dass sie in den Evolutionsalgorithmus übernommen werden kann. Das heißt, wir können die Strategie mit Programmcode schreiben, aber an einigen Stellen lassen wir die Koeffizienten und lassen sie von der Evolution aufgreifen. Oder wir können eine Strategie mit einem neuronalen Netzwerk aufschreiben - und die Evolution die Gewichte ihrer Verbindungen erfassen lassen.
Das heißt, hier gibt es keine Prognose. Keine SAR-Tabelle. Wir wählen einfach eine Strategie aus und sie gibt sofort Aktionen aus.
Dies ist eine leistungsstarke und effektive Methode. Wenn Sie RL ausprobieren möchten und nicht wissen, wo Sie anfangen sollen, empfehle ich sie. Dies ist ein sehr billiger Weg, um „ein Wunder zu sehen“.
Was sind die Nachteile?- Die Fähigkeit, dieselben Experimente viele Male durchzuführen, ist erforderlich. Das heißt, wir sollten in der Lage sein, die Realität bis zum Ausgangspunkt zurückzuspulen - zehntausende Male. Eine neue Strategie ausprobieren.
Das Leben bietet selten solche Möglichkeiten. Wenn wir ein Modell des Prozesses haben, an dem wir interessiert sind, können wir normalerweise keine listige Strategie erstellen - wir können einfach einen Plan erstellen, wie bei einem modellbasierten Ansatz, selbst mit stumpfer roher Gewalt. - Unverträglichkeit gegenüber Erfahrung. Haben wir eine SAR-Tabelle mit jahrelanger Erfahrung? Wir können es vergessen, es passt nicht in das Konzept.
Eine Methode zur Aufzählung von Strategien, aber "leben"
Die gleiche Aufzählung von Strategien, aber auf lebendige Realität. Wir versuchen 10 Maßnahmen einer Strategie. Dann misst 10 einen anderen. Dann 10 Takte des dritten. Dann wählen wir die aus, bei der es mehr Verstärkung gab.
Die besten Ergebnisse für laufende Humanoide wurden mit dieser Methode erzielt.

Für mich klingt dies etwas unerwartet - es scheint, dass der QL + -Modell-basierte Ansatz mathematisch ideal ist. Aber nichts dergleichen. Die Vorteile des Ansatzes sind ungefähr die gleichen wie die des vorherigen - aber sie sind weniger ausgeprägt, da die Strategien nicht sehr lange getestet werden (wir haben keine Jahrtausende in Bezug auf die Evolution), was bedeutet, dass die Ergebnisse instabil sind. Darüber hinaus kann auch die Anzahl der Tests nicht auf unendlich angehoben werden - was bedeutet, dass die Strategie in einem nicht sehr komplizierten Bereich von Optionen gesucht werden muss. Sie wird nicht nur "Stifte" haben, die "verdreht" werden können. Nun, die Erfahrungsintoleranz wurde nicht abgesagt. Und im Vergleich zu QL oder modellbasiert nutzen diese Modelle die Erfahrung ineffizient. Sie brauchen viel mehr Interaktionen mit der Realität als Ansätze, die maschinelles Lernen verwenden.
Wie Sie sehen können, sollten alle Versuche, theoretisch eine AGI zu erstellen, entweder maschinelles Lernen für die Vorhersage von Auszeichnungen oder eine Form der parametrischen Notation einer Strategie enthalten, damit Sie diese Strategie mit so etwas wie Evolution aufgreifen können.
Dies ist ein starker Angriff auf Personen, die anbieten, KI basierend auf Datenbanken, Logik und konzeptionellen Grafiken zu erstellen. Wenn Sie, die Befürworter des symbolischen Ansatzes, dies lesen - willkommen zu den Kommentaren, ich werde froh sein zu wissen, was AGI ohne die oben beschriebene Mechanik tun kann.
Modelle für maschinelles Lernen für RL
Fast jedes ML-Modell kann für verstärktes Lernen verwendet werden. Neuronale Netze sind natürlich gut. Aber es gibt zum Beispiel KNN. Für jedes Paar S und A suchen wir nach den ähnlichsten, aber in der Vergangenheit. Und wir suchen nach dem, was danach R. Dumm sein wird? Ja, aber es funktioniert. Es gibt entscheidende Bäume - hier ist es besser, einen Spaziergang mit den Schlüsselwörtern "Gradientenverstärkung" und "entscheidender Wald" zu machen. Können Bäume komplexe Abhängigkeiten nicht erfassen? Verwenden Sie Feature-Engineering. Willst du deine KI näher an General? Verwenden Sie die automatische FE! Gehen Sie eine Reihe verschiedener Formeln durch, senden Sie sie als Funktionen für Ihren Boost, verwerfen Sie Formeln, die den Fehler erhöhen, und belassen Sie die Formeln, die die Genauigkeit verbessern. Dann reichen Sie die besten Formeln als Argumente für die neuen Formeln ein und so weiter.
Sie können symbolische Regressionen für die Vorhersage verwenden, dh einfach Formeln aussortieren, um etwas zu erhalten, das sich Q oder R annähert. Es ist möglich, Algorithmen zu sortieren. Dann erhalten Sie eine sogenannte Solomonov-Induktion, die theoretisch optimal, aber fast sehr schwer zu trainieren ist Approximationen von Funktionen.
Neuronale Netze sind jedoch normalerweise ein Kompromiss zwischen Ausdruckskraft und Lernkomplexität. Die algorithmische Regression nimmt idealerweise jede Abhängigkeit auf - für Hunderte von Jahren. Der Entscheidungsbaum wird sehr schnell funktionieren - aber er kann y = a + b nicht extrapolieren. Ein neuronales Netzwerk ist etwas dazwischen.
Entwicklungsperspektiven
Wie kann AGI jetzt genau durchgeführt werden? Zumindest theoretisch.
Evolution
Wir können viele verschiedene Testumgebungen erstellen und die Entwicklung eines neuronalen Netzwerks starten.
Die Konfigurationen, die bei allen Versuchen insgesamt mehr Punkte erzielen, werden multipliziert.Das neuronale Netzwerk muss über einen Speicher verfügen, und es wäre wünschenswert, mindestens einen Teil des Speichers in Form eines Bandes wie einer Turing-Maschine oder einer Festplatte zu haben.Das Problem ist, dass man mit Hilfe der Evolution natürlich so etwas wie RL wachsen lassen kann. Aber wie sollte die Sprache aussehen, in der RL kompakt aussieht - damit die Evolution sie findet - und gleichzeitig findet die Evolution keine Lösungen wie "Aber werde ich ein Neuron für 150 Schichten erstellen, damit Sie alle verrückt werden, während ich es unterrichte!" . Evolution ist wie eine Menge von Analphabeten - es wird Fehler im Code finden und das gesamte System über Bord werfen.Aixi
Sie können ein modellbasiertes System erstellen, das auf einer Reihe vieler algorithmischer Regressionen basiert. Der Algorithmus ist garantiert vollständig, was bedeutet, dass es keine Muster gibt, die nicht erfasst werden können. Der Algorithmus ist in Code geschrieben - was bedeutet, dass seine Komplexität leicht berechnet werden kann. Dies bedeutet, dass es möglich ist, Ihre Hypothesen über das Gerät der Welt hinsichtlich der Komplexität mathematisch korrekt zu verfeinern. Bei neuronalen Netzen zum Beispiel funktioniert dieser Trick nicht - dort ist die Strafe für Komplexität sehr indirekt und heuristisch.Es bleibt nur zu lernen, wie man algorithmische Regressionen schnell trainiert. Bisher ist das Beste dafür die Evolution, und sie ist unverzeihlich lang.Seed AI
Es wäre cool, eine KI zu erstellen, die sich selbst verbessert. Verbessern Sie Ihre Fähigkeit, Probleme zu lösen. Dies mag seltsam erscheinen, aber dieses Problem wurde bereits für statische Optimierungssysteme wie die Evolution gelöst . Wenn Sie dies realisieren ... Ist alles über den Aussteller bekannt? Wir werden in sehr kurzer Zeit eine sehr mächtige KI bekommen.Wie kann man das machen?
Sie können versuchen, dafür zu sorgen, dass einige der Aktionen in RL die Einstellungen von RL selbst beeinflussen.Oder geben Sie dem RL-System ein Tool, mit dem Sie neue Vor- und Nachdatenprozessoren für sich selbst erstellen können. Lassen Sie RL dumm sein, aber es wird in der Lage sein, Taschenrechner, Notebooks und Computer für sich selbst zu erstellen.Eine andere Möglichkeit besteht darin, mithilfe von Evolution eine Art KI zu erstellen, bei der sich ein Teil der Aktionen auf Codeebene auf das Gerät auswirkt.Aber im Moment habe ich keine praktikablen Optionen für Seed AI gesehen - wenn auch sehr begrenzt. Verstecken sich die Entwickler? Oder sind diese Optionen so schwach, dass sie keine allgemeine Aufmerksamkeit verdient haben und an mir vorbeigegangen sind?Jetzt arbeiten sowohl Google als auch DeepMind hauptsächlich mit neuronalen Netzwerkarchitekturen. Anscheinend wollen sie sich nicht auf die kombinatorische Aufzählung einlassen und versuchen, ihre Ideen für die Methode der Rückübertragung des Fehlers geeignet zu machen.Ich hoffe, dieser Übersichtsartikel hat sich als nützlich erwiesen =) Kommentare sind willkommen, insbesondere Kommentare wie „Ich weiß, wie man AGI besser macht“!