Neuronale Netze erobern die Welt. Sie zählen Besucher, überwachen die Qualität, führen Statistiken und bewerten die Sicherheit. Eine Reihe von Startups, industrielle Nutzung.
Tolle Rahmenbedingungen. Was ist PyTorch, was ist der zweite TensorFlow? Alles wird bequemer und bequemer, einfacher und einfacher ...
Aber es gibt eine dunkle Seite. Sie versuchen über sie zu schweigen. Dort gibt es nichts Freudiges, nur Dunkelheit und Verzweiflung. Jedes Mal, wenn Sie einen positiven Artikel sehen, seufzen Sie traurig, weil Sie verstehen, dass nur eine Person etwas nicht verstanden hat. Oder versteckte es.
Lassen Sie uns über die Produktion auf eingebetteten Geräten sprechen.

Was ist das Problem.
Es scheint. Sehen Sie sich die Leistung des Geräts an, stellen Sie sicher, dass es ausreicht, führen Sie es aus und erzielen Sie einen Gewinn.
Aber wie immer gibt es ein paar Nuancen. Stellen wir sie in die Regale:
- Produktion. Wenn Ihr Gerät nicht in Einzelkopien erstellt wurde, müssen Sie sicherstellen, dass das System nicht hängt, dass die Geräte nicht überhitzen und dass bei einem Stromausfall automatisch alles startet. Und das ist auf einer großen Party. Dies bietet nur zwei Möglichkeiten: Entweder sollte das Gerät unter Berücksichtigung aller möglichen Probleme vollständig ausgelegt sein. Oder Sie müssen die Probleme des Quellgeräts überwinden. Nun, das sind zum Beispiel ( 1 , 2 ). Was natürlich Zinn ist. Um die Probleme des Geräts eines anderen in großen Mengen zu lösen, muss eine unrealistische Menge an Energie aufgewendet werden.
- Echte Benchmarks. Viele Betrügereien und Tricks. NVIDIA überschätzt in den meisten Beispielen die Leistung um 30-40%. Aber nicht nur sie hat Spaß. Im Folgenden gebe ich viele Beispiele, bei denen die Produktivität vier- bis fünfmal geringer sein kann als gewünscht. Sie können sich nicht hinlegen "am Computer hat alles gut funktioniert, hier wird es proportional schlechter."
- Sehr begrenzte Unterstützung für die neuronale Netzwerkarchitektur. Es gibt viele eingebettete Hardwareplattformen, die die Netzwerke, die auf ihnen ausgeführt werden können, stark einschränken (Coral, Gyrfalcone, Snapdragon). Das Portieren auf solche Plattformen ist schmerzhaft.
- Unterstützung. Etwas funktioniert bei Ihnen nicht, aber das Problem liegt auf der Geräteseite? .. Dies ist Schicksal, es wird nicht funktionieren. Nur für RPi schließt die Community die meisten Fehler. Und zum Teil für Jetson.
- Preis Vielen scheint Embedded billig zu sein. In der Realität wird der Preis jedoch mit dem Wachstum der Geräteleistung fast exponentiell steigen. RPi-4 ist 5-mal billiger als Jetson Nano / Google Coral und 2-3-mal schwächer. Jetson Nano ist 5-mal billiger als Jetson TX2 / Intel NUC und 2-3-mal schwächer als sie.
- Lorgus. Erinnern Sie sich an diesen Entwurf von Zhelyazny?
Es scheint, dass ich es als Titelbild festgelegt habe ... " Das Logrus ist ein sich veränderndes dreidimensionales Labyrinth, das die Kräfte des Chaos im Multiversum darstellt. " All dies ist eine Fülle von Insekten und Löchern, all diese verschiedenen Eisenstücke, all die sich ändernden Rahmenbedingungen ... Es ist normal, wenn sich das Marktbild in 2-3 Monaten vollständig ändert. In diesem Jahr hat es sich 3-4 mal geändert. Sie können denselben Fluss nicht zweimal betreten. Alle aktuellen Gedanken gelten also für den Sommer 2019.
Was gibt es
Nehmen wir es in Ordnung, es schmeckt nicht süß ... Was ist jetzt da und ist für Neuronen geeignet? Trotz ihrer Variabilität gibt es nicht so viele Optionen. Einige allgemeine Wörter, um die Suche einzuschränken:
- Ich werde keine Neuronen / Schlussfolgerungen auf Telefonen analysieren. Dies an sich ist ein großes Thema. Da es sich bei Telefonen jedoch um eingebettete Plattformen mit Interferenzanpassung handelt, denke ich nicht, dass dies schlecht ist.
- Ich werde Jetson TX1 | TX2 berühren. Unter den gegenwärtigen Bedingungen sind diese Plattformen für den Preis nicht die optimalsten, aber es gibt Situationen, in denen sie immer noch bequem zu bedienen sind.
- Ich kann nicht garantieren, dass die Liste alle Plattformen enthält, die heute existieren. Vielleicht habe ich etwas vergessen, vielleicht weiß ich nichts. Wenn Sie weitere interessante Plattformen kennen - schreiben Sie!
Also. Die wichtigsten Dinge, die klar eingebettet sind. In dem Artikel werden wir sie genau vergleichen:

- Jetson- Plattform. Es gibt mehrere Geräte dafür:
- Jetson Nano - ein billiges und ziemlich modernes Spielzeug (Frühjahr 2019)
- Jetson Tx1 | Tx2 - ziemlich teuer, aber gut für Leistungs- und Vielseitigkeitsplattformen
- Himbeer-Pi . In Wirklichkeit hat nur RPi4 die Leistung für neuronale Netze. In der dritten Generation können jedoch einige separate Aufgaben ausgeführt werden. Ich habe am Anfang sogar sehr einfache Gitter gestartet.
- Google Coral Platform. Tatsächlich gibt es zum Einbetten von Geräten nur einen Chip und zwei Geräte - Dev Board und USB Accelerator
- Intel Movidius- Plattform. Wenn Sie kein großes Unternehmen sind, stehen Ihnen nur Movidius 1 | Movidius 2-Sticks zur Verfügung.
- Gyrfalcone- Plattform. Das Wunder der chinesischen Technologie. Es gibt bereits zwei Generationen - 2801, 2803
Sonstiges Wir werden nach den Hauptvergleichen darüber sprechen:
- Intel-Prozessoren. Zuallererst NUC-Baugruppen. Fast eingebettet
- Nvidia Mobile GPUs. Fertige Lösungen können als nicht einbettend betrachtet werden. Und wenn Sie Einbettungen sammeln, wird es sich anständig auf die Finanzen auswirken.
- Handys. Android zeichnet sich dadurch aus, dass für eine maximale Leistung genau die Hardware eines bestimmten Herstellers verwendet werden muss. Oder verwenden Sie etwas Universelles wie Tensorflow-Licht. Für Apple das Gleiche.
- Jetson AGX Xavier ist eine teure Version von Jetson mit mehr Leistung.
- GAP8 - Low-Power-Prozessoren für supergünstige Geräte.
- Mysterious Grove AI HAT
Jetson
Wir arbeiten seit sehr langer Zeit mit Jetson zusammen. Bereits 2014 erfand
Vasyutka die Mathematik für den damaligen
Swift genau auf Jetson. Bei einem Treffen mit Artec 3D im Jahr 2015 haben wir darüber gesprochen, was für eine coole Plattform es ist. Danach haben sie vorgeschlagen, einen darauf basierenden Prototyp zu bauen. Nach ein paar Monaten war der Prototyp fertig. Nur ein paar Jahre Arbeit des gesamten Unternehmens, ein paar Jahre Flüche auf der Plattform und im Himmel ... Und
Artec Leo wurde geboren - der coolste Scanner seiner Klasse. Sogar Nvidia
zeigte ihn bei der Präsentation von TX2 als eines der interessantesten Projekte, die auf der Plattform erstellt wurden.
Seitdem haben wir TX1 / TX2 / Nano irgendwo in 5-6 Projekten verwendet.
Und wahrscheinlich kennen wir alle Probleme, die mit der Plattform aufgetreten sind. Nehmen wir es in Ordnung.
Jetson tk1
Ich werde nicht besonders über ihn sprechen. Die Plattform war an ihrem Tag sehr effizient in Bezug auf Rechenleistung. Aber sie war kein Lebensmittelgeschäft. NVIDIA verkaufte die
TegraTK1- Chips, auf denen Jetson
basiert . Für kleine und mittlere Hersteller war es jedoch unmöglich, diese Chips zu verwenden. In Wirklichkeit konnte außer Nvidia nur Google / HTC / Xiaomi / Acer / Google etwas dagegen tun. Alle anderen in das Produkt integrierten Debug-Boards oder Plünderungen anderer Geräte.
Jetson TX1 | TX2
Nvidia kam zu den richtigen Schlussfolgerungen, und die nächste Generation war großartig. TX1 | TX2, das sind keine Chips mehr, sondern ein Chip auf der Platine.


Sie sind teurer, haben aber ein komplettes Lebensmittelgeschäft. Ein kleines Unternehmen kann sie in sein Produkt integrieren, dieses Produkt ist vorhersehbar und stabil. Ich persönlich habe gesehen, wie 3-4 Produkte zur Produktion gebracht wurden - und alles war gut.
Ich werde über TX2 sprechen, da es sich bei der aktuellen Leitung um die Hauptplatine handelt.
Aber natürlich danken nicht alle Gott. Was ist los:
- Jetson TX2 ist eine teure Plattform. In den meisten Produkten verwenden Sie das Hauptmodul (nach meinem Verständnis liegt der Preis je nach Chargengröße zwischen 200 und 250 bis 350 und 400 cu pro Stück). Er braucht ein CarrierBoard. Ich kenne den aktuellen Markt nicht, aber früher waren es ungefähr 100-300 cu abhängig von der Konfiguration. Nun, und zusätzlich zu Ihrem Bodykit.
- Jetson TX2 ist nicht die schnellste Plattform. Im Folgenden werden die Vergleichsgeschwindigkeiten erörtert. Dort werde ich zeigen, warum dies nicht die beste Option ist.
- Es ist notwendig, viel Wärme abzuführen. Dies gilt wahrscheinlich für fast alle Plattformen, über die wir sprechen werden. Das Gehäuse muss das Problem der Wärmeableitung lösen. Fans
- Dies ist eine schlechte Plattform für kleine Gruppen. Viele Hunderte von Geräten - ca. Die Bestellung von Motherboards, die Entwicklung von Designs und Verpackungen ist die Norm. Viele tausend Geräte? Gestalte dein Motherboard - und schick. Wenn Sie 5-10 brauchen - schlecht. Sie müssen höchstwahrscheinlich DevBoard nehmen. Sie sind groß, sie sind ein bisschen ekelhaft zu blinken. Dies ist keine RPi-fähige Plattform.
- Nvidias schlechte technische Unterstützung. Ich habe viel schwören hören, dass Antworten beantwortet werden, dass dies entweder geheime Informationen oder monatliche Antworten sind.
- Schlechte Infrastruktur in Russland. Es ist schwer zu bestellen, es dauert lange. Gleichzeitig arbeiten die Händler gut. Ich bin kürzlich auf einen Jetson Nano gestoßen, der am Starttag ausgebrannt ist - ohne Frage geändert. Sam wurde per Kurier abgeholt / brachte einen neuen mit. WAH! Auch er selbst hat gesehen, dass das Moskauer Büro gut berät. Sobald ihr Kenntnisstand die Beantwortung der Frage nicht zulässt und eine Anfrage an das internationale Büro erfordert, müssen sie lange auf Antworten warten.
Was ist großartig:
- Viele Informationen, eine sehr große Community.
- Rund um Nvidia gibt es viele kleine Unternehmen, die Zubehör herstellen. Sie sind offen für Verhandlungen, Sie können ihre Entscheidung abstimmen. Und CarierBoard, Firmware und Kühlsysteme.
- Unterstützung für alle normalen Frameworks (TensorFlow | PyTorch) und vollständige Unterstützung für alle Netzwerke. Die einzige Konvertierung, die Sie möglicherweise durchführen müssen, ist die Übertragung des Codes an TensorRT. Dies spart Speicher und beschleunigt möglicherweise. Im Vergleich zu anderen Plattformen ist dies lächerlich.
- Ich weiß nicht, wie man Bretter züchtet. Aber von denen, die dies für Nvidia getan haben, habe ich gehört, dass TX2 eine gute Option ist. Es gibt Handbücher, die der Realität entsprechen.
- Guter Stromverbrauch. Aber von all dem wird genau "eingebettet" bei uns sein - das Schlimmste :)
- Bremssattel in Russland (oben erklärt warum)
- Im Gegensatz zu movidius | RPi | Koralle | Gyrfalcon ist eine echte GPU. Sie können darauf nicht nur Gitter, sondern auch normale Algorithmen fahren
Infolgedessen ist dies eine gute Plattform für Sie, wenn Sie Stückgeräte haben, aber aus irgendeinem Grund können Sie keinen vollwertigen Computer liefern. Etwas Massives? Biometrie - höchstwahrscheinlich nicht. Die Nummernerkennung ist je nach Fluss am Rande. Tragbare Geräte mit einem Preis von über 5.000 Dollar - möglich. Autos - nein, es ist einfacher, eine leistungsstärkere Plattform etwas teurer zu machen.
Es scheint mir, dass TX2 mit der Veröffentlichung einer neuen Generation billiger Geräte im Laufe der Zeit sterben wird.
Motherboards für Jetson TX1 | TX2 | TX2i und andere sehen ungefähr so aus:

Und
hier oder
hier gibt es mehr Variationen.
Jetson Nano

Jetson Nano ist eine sehr interessante Sache. Für Nvidia ist dies ein neuer Formfaktor, der in Bezug auf die Revolution mit dem TK1 verglichen werden müsste. Aber die Konkurrenten gehen bereits aus. Es gibt andere Geräte, über die wir sprechen werden. Es ist 2 mal schwächer als TX2, aber 4 mal billiger. Genauer gesagt ... Mathe ist kompliziert. Jetson Nano auf dem Demo-Board kostet 100 Dollar (in Europa). Wenn Sie jedoch nur einen Chip kaufen, ist dieser teurer. Und du musst ihn züchten (es gibt noch kein Motherboard für ihn). Und Gott bewahre, dass es auf einer großen Party zweimal billiger ist als TX2.
Tatsächlich ist Jetson Nano auf seiner Basisplatine ein solches Werbeprodukt für Institute / Wiederverkäufer / Amateure, das das Interesse und die Geschäftsanwendung anregen sollte. Durch Vor- und Nachteile (überschneidet sich teilweise mit TX2):
- Das Design ist schwach und nicht debuggt:
- Es überhitzt sich mit einer konstanten Last, die regelmäßig hängt / fliegt. Ein bekanntes Unternehmen versucht seit 3 Monaten, alle Probleme zu lösen - es funktioniert nicht.
- Ich habe einen durchgebrannt, wenn er über USB mit Strom versorgt wird. Ich habe gehört, dass ein Freund einen USB-Ausgang durchgebrannt hat und der Stecker funktioniert. Höchstwahrscheinlich einige Probleme mit der USB-Stromversorgung.
- Wenn Sie die Originalplatine verpacken, ist nicht genügend Kühler von NVIDIA vorhanden. Beispielsweise wird er überhitzt.
- Geschwindigkeit ist irgendwie nicht genug. Fast 2 mal weniger als TX2 (in Wirklichkeit kann es 1,5 sein, aber es hängt von der Aufgabe ab).
- Viele 5-10 Geräte sind im Allgemeinen sehr gut. 50-200 - es ist schwierig, Sie müssen alle Fehler des Herstellers kompensieren, sie an Ihre Hunde hängen. Wenn Sie etwas wie POE hinzufügen müssen, tut es weh. Größere Parteien. Heute habe ich noch nichts von erfolgreichen Projekten gehört. Aber es scheint mir, dass dort Schwierigkeiten auftreten können wie bei TK1. Um ehrlich zu sein, möchte ich hoffen, dass im nächsten Jahr Jetson Nano 2 veröffentlicht wird, wo diese Kinderkrankheiten korrigiert werden.
- Die Unterstützung ist schlecht, genau wie bei TX2
- Schlechte Infrastruktur
Gut:
- Genug Budget im Vergleich zu Mitbewerbern. Besonders für kleine Partys. Günstiger Preis / Leistung
- Im Gegensatz zu movidius | RPi | Koralle | Gyrfalcon ist eine echte GPU. Sie können darauf nicht nur Gitter, sondern auch normale Algorithmen fahren
- Starten Sie einfach ein beliebiges Netzwerk (wie tx2)
- Stromverbrauch (wie tx2)
- Bremssattel in Russland (wie tx2)
Nano selbst kam im zeitigen Frühjahr heraus, irgendwo im April / Mai stocherte ich aktiv darin herum. Wir haben bereits zwei Projekte auf ihnen gemacht. Im Allgemeinen sind die oben genannten Probleme. Als Hobbyprodukt / Produkt für Kleinserien - sehr cool. Ob es jedoch möglich ist, die Produktion in die Länge zu ziehen und wie dies zu tun ist, ist noch nicht klar.
Sprechen Sie über die Geschwindigkeit von Jetson.
Wir werden viel später mit anderen Geräten vergleichen. Sprechen Sie in der Zwischenzeit nur über Jetson und Geschwindigkeit. Warum Nvidia uns anlügt. So optimieren Sie Ihre Projekte.
Im Folgenden wird alles über TensorRT-5.1 geschrieben. TensorRT-6.0.1 wurde am 17. September 2019 veröffentlicht, alle Aussagen müssen dort noch einmal überprüft werden.
Nehmen wir an, wir glauben Nvidia. Öffnen wir ihre
Website und sehen wir den Zeitpunkt der Inferenz von SSD-mobilet-v2 auf 300 * 300:
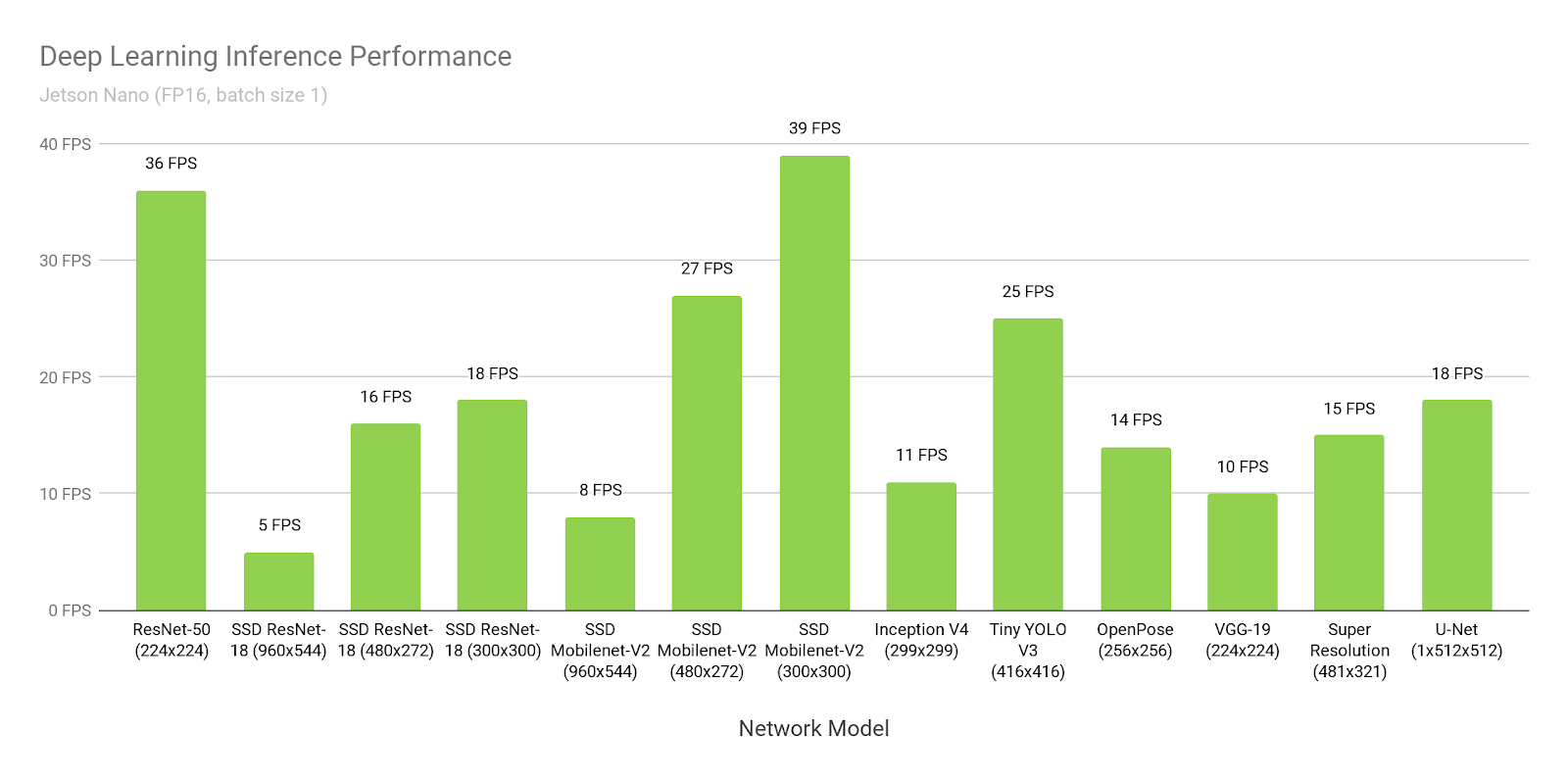
Wow, 39 FPS (25 ms). Ja, und der Quellcode ist
angelegt !
Hmm ... Aber warum steht es
hier ungefähr 46ms?
Warten Sie ... Und hier schreiben
sie , dass 309 ms nativ sind und 72 ms portiert werden ...
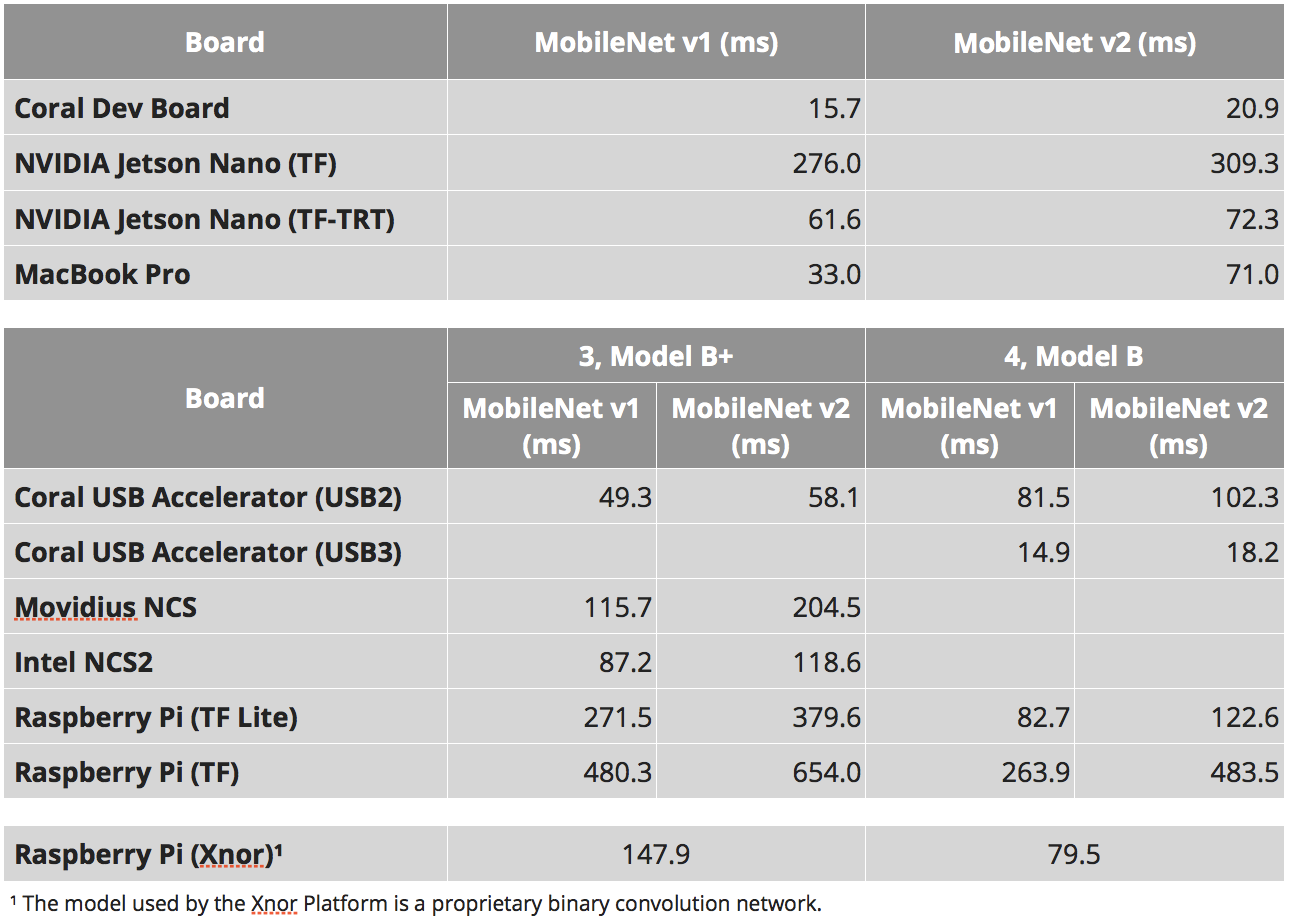
Wo ist die Wahrheit?
Die Wahrheit ist, dass jeder ganz anders denkt:
- SSD besteht aus zwei Teilen. Ein Teil ist das Neuron. Der zweite Teil ist die Nachbearbeitung dessen, was das Neuron produziert hat (nicht maximale Unterdrückung) + die Vorverarbeitung dessen, was auf die Eingabe geladen wird.
- Wie ich bereits sagte, muss unter Jetson alles auf TensorRT umgestellt werden. Dies ist ein solches natives Framework von NVIDIA. Ohne es wird alles schlecht sein. Es gibt nur ein Problem. Dort wird nicht alles portiert, insbesondere von TensorFlow. Weltweit gibt es zwei Ansätze:
- Als Google erkannte, dass dies ein Problem ist, veröffentlichte es für TensorFlow das sogenannte "tf-trt". Tatsächlich ist dies ein Add-On für tf, mit dem Sie jedes Raster in Tensorrt konvertieren können. Teile, die nicht unterstützt werden, werden auf der CPU abgeleitet, der Rest auf der GPU.
- Schreiben Sie alle Ebenen neu / finden Sie ihre Analoga
In den obigen Beispielen:
- In diesem Link ist 300 ms Zeit der übliche Tensorfluss ohne Optimierung.
- Dort ist 72ms die tf-trt-Version. Dort werden alle nms im Wesentlichen für den Prozess ausgeführt.
- Dies ist eine Fan-Version, bei der eine Person alle NMS übertragen und selbst auf GPU geschrieben hat.
- Und das ... Diese NVIDIA hat beschlossen, die gesamte Leistung ohne Nachbearbeitung zu messen, ohne sie irgendwo explizit zu erwähnen.
Sie müssen selbst verstehen, dass wenn es Ihr Neuron wäre, das niemand vor Ihnen konvertiert hätte, Sie es ohne Probleme mit einer Geschwindigkeit von 72 ms starten könnten. Und mit einer Geschwindigkeit von 46 ms über den Handbüchern und Sorsa Tag-Woche sitzen.
Im Vergleich zu vielen anderen Optionen ist dies sehr gut. Aber vergessen Sie nicht, was auch immer Sie tun - glauben Sie niemals den Benchmarks von NVIDIA!
HimbeerPI 4
Produktion? .. Und ich höre, wie Dutzende Ingenieure über die Erwähnung der Wörter "RPI" und "Produktion" in der Nähe lachen. Aber ich muss sagen - RPI ist immer noch stabiler als Jetson Nano und Google Coral. Aber natürlich verliert TX2 und anscheinend Gyrfalcon.

(Das Bild ist
von hier . Es scheint mir, dass das Anschließen von Fans an das RPi4 eine separate Volksunterhaltung ist.)
Aus der gesamten Liste ist dies das einzige Gerät, das ich nicht in meinen Händen gehalten / nicht getestet habe. Aber er hat Neuronen auf Rpi, Rpi2, Rpi3 gestartet (zum Beispiel hat er es mir
hier erzählt). Im Allgemeinen unterscheidet sich Rpi4, wie ich es verstehe, nur in der Leistung. Es scheint mir, dass die Vor- und Nachteile von RPi alles wissen, aber immer noch. Nachteile:
- So sehr ich nicht möchte, ist dies keine Lebensmittellösung. Überhitzung . Periodisches Einfrieren. Aufgrund der großen Community gibt es jedoch Hunderte von Lösungen für jedes Problem. Dies macht Rpi nicht gut für Tausende von Auflagen. Aber Zehn / Hunderte - Wai-Noten.
- Geschwindigkeit. Dies ist das langsamste Gerät aller Hauptgeräte, über die wir sprechen.
- Es gibt fast keine Unterstützung vom Hersteller. Dieses Produkt richtet sich an Enthusiasten.
Vorteile:
- Preis Nein, natürlich, wenn Sie das Board selbst züchten, können Sie es mit Gyrfalcon in vielen Tausenden billiger machen. Aber höchstwahrscheinlich ist das unrealistisch. Wo RPi-Leistung ausreicht, ist dies die billigste Lösung.
- Popularität. Als Caffe2 herauskam, gab es eine Version für Rpi in der Basisversion. Tensorflow Licht? Natürlich funktioniert es. I.T.D., I.T.P. Was der Hersteller nicht tut, ist Benutzer zu übertragen. Ich lief auf verschiedenen RPi und Caffe und Tensorflow und PyTorch und ein paar selteneren Dingen.
- Bequemlichkeit für kleine Partys / Stücke. Flashen Sie einfach das Flash-Laufwerk und starten Sie es. Im Gegensatz zu JetsonNano gibt es an Bord WLAN. Sie können es einfach über PoE mit Strom versorgen (anscheinend müssen Sie einen Adapter kaufen, der aktiv verkauft wird).
Wir werden am Ende über die RPI-Geschwindigkeit sprechen. Da der Hersteller nicht postuliert, dass sein Produkt für Neuronen, gibt es nur wenige Benchmarks. Jeder versteht, dass Rpi nicht perfekt in der Geschwindigkeit ist. Aber auch er ist für einige Aufgaben geeignet.
Wir hatten einige Halbproduktaufgaben, die wir bei Rpi implementiert haben. Der Eindruck war angenehm.
Movidius 2

Von hier und unten werden nicht mehr vollwertige Prozessoren eingesetzt, sondern Prozessoren, die speziell für neuronale Netze entwickelt wurden. Es ist, als ob ihre Stärken und Schwächen gleichzeitig sind.
Also. Movidius. Das Unternehmen wurde 2016 von Intel gekauft. In dem Segment, das uns interessiert, hat das Unternehmen zwei Produkte veröffentlicht, Movidius und Movidius 2. Das zweite ist schneller, wir werden nur über das zweite sprechen.
Nein, nicht so. Das Gespräch sollte nicht mit Movidius beginnen, sondern mit Intel
OpenVino . Ich würde sagen, dass dies Ideologie ist. Genauer gesagt, das Framework. Tatsächlich handelt es sich hierbei um eine Reihe von vorab trainierten Neuronen und deren Schlussfolgerungen, die für Intel-Produkte (Prozessoren, GPUs, Spezialcomputer) optimiert sind. OpenCV, Raspberry Pi, .
OpenVino , . . , , , , , ..., ... (
1 ,
2 ,
3 ). . , Intel'. / . , .
? . — . — . , .
OpenVino, , . . - — . . GAN . . , , , - , .
, :

, Intel OpenVino . . , . — . 70% OpenVino.
Movidius . . ( , ).
. USB , , !!! USB. . Intel
. - (
1 ,
2 )
. -. - .
?.. :)
, . OpenVino, , , ( Computer Vision ). :
( AI 2.0, OpenVino ).
, . Movidius 2. :
- . Rpi Jetson Nano. — . . Third Party ?
- . . .
- . .
- . USB 3.0
- , . -. . Movidius . .
Vorteile:
- . . .
- ,
- ,
. — .
, “ 20-30 , , ” — Movidius.
Intel
. , .
 UPD
UPD. . embedded . PCI-e . . — 200 .. . …
Google Coral
Ich bin enttäuscht. Nein, es gibt nichts, was ich nicht vorhersagen würde. Ich bin jedoch enttäuscht, dass Google beschlossen hat, dies zu veröffentlichen. Testen ist zu Beginn des Sommers ein Wunder. Vielleicht hat sich seitdem etwas geändert, aber ich werde meine Erfahrung dieser Zeit beschreiben.
Einrichten ... Um Jetson Tk-Tx1-Tx2 zu flashen, musste es an den Host-Computer und an das Netzteil angeschlossen werden. Und das war genug. Um Jetson Nano und RPi zu flashen, müssen Sie das Bild nur auf das USB-Flash-Laufwerk übertragen.
Und um Coral zu blinken, müssen Sie drei Drähte in der
richtigen Reihenfolge stecken:

Und versuchen Sie nicht, einen Fehler zu machen! Übrigens gibt es im Handbuch Fehler / unbeschreibliches Verhalten. Wahrscheinlich werde ich sie nicht beschreiben, da sie von Anfang des Sommers an etwas hätten reparieren können. Ich erinnere mich, dass nach der Installation von Mendel jeglicher Zugriff über ssh verloren ging, einschließlich des von ihnen beschriebenen, ich einige Linux-Konfigurationen manuell bearbeiten musste.
Ich habe 2-3 Stunden gebraucht, um diesen Vorgang abzuschließen.
Ok Gestartet. Denken Sie, dass es einfach ist, Ihr Raster darauf zu betreiben? Fast nichts :)
Hier ist eine Liste von dem, was Sie loslassen können.
Um ehrlich zu sein, bin ich nicht schnell an diesen Punkt gekommen. Verbrachte einen halben Tag. Nein wirklich. Sie können das Modell nicht aus
dem TF-Repository herunterladen und auf dem Gerät ausführen. Oder dort müssen alle Schichten gekreuzt werden. Ich habe keine Anweisungen gefunden.
Also. Das Modell muss von oben aus dem Repository entnommen werden. Es gibt nicht viele von ihnen (3 Modelle wurden seit Beginn des Sommers hinzugefügt). Und wie trainiere ich sie? In TensorFlow in einer Standard-Pipeline öffnen? HAHAHAHAHAHAHAHA. Natürlich nicht!!!
Sie haben einen speziellen
Doker-Container , und das Modell trainiert nur darin. (Wahrscheinlich können Sie sich auch irgendwie über Ihren TF lustig machen ... Aber es gibt Anweisungen, Anweisungen ... die es nicht waren und nicht zu sein scheinen.)
Herunterladen / Installieren / Starten. Was ist das ... Warum ist die GPU auf Null? .. WEIL TRAINING AUF DER CPU IST. Docker ist nur für ihn !!! Willst du noch mehr Spaß? Das Handbuch sagt "basierend auf einer 6-Kern-CPU mit 64G-Speicher-Workstation". Es scheint, dass dies nur ein Rat ist? Kann sein. Erst jetzt hatte ich nicht genug von meinen 8 Gigs auf dem Server, auf dem die meisten Modelle trainieren. Das Training in der 4. Stunde verbrauchte sie alle. Ein starkes Gefühl, dass etwas floss. Ich habe ein paar Tage mit verschiedenen Parametern auf verschiedenen Maschinen versucht, der Effekt war einer.
Ich habe dies vor dem Posten des Artikels nicht noch einmal überprüft. Um ehrlich zu sein, hat es mir einmal gereicht.
Was noch hinzuzufügen? Dass dieser Code kein Modell generiert? Um es zu generieren, müssen Sie:
- Lag count
- Wandle ihn in Flit um
- Kompilieren Sie zu Formal Edge TPU. Gott sei Dank geschieht dies jetzt auf einem Computer. Im Frühjahr konnte es nur online gemacht werden. Und dort musste ein Häkchen gesetzt werden: "Ich werde es nicht für das Böse verwenden / ich verstoße mit diesem Modell nicht gegen Gesetze." Gott sei Dank gibt es nichts davon.

Dies ist der größte Ekel, den ich im letzten Jahr in Bezug auf ein IT-Produkt erlebt habe ...
Weltweit sollte Coral die gleiche Ideologie wie OpenVino mit Movidius haben. Erst jetzt ist Intel seit mehreren Jahren auf diesem Weg. Mit hervorragenden Handbüchern, Support und guten Produkten ... und Google. Nun, es ist nur Google ...
Nachteile:
- Dieses Board ist kein Lebensmittelgeschäft auf AD-Ebene. Ich habe noch nichts über den Verkauf von Chips gehört => Die Produktion ist unrealistisch
- Der Entwicklungsstand ist so schrecklich wie möglich. Alles bazhet. Die Entwicklungspipeline passt nicht in traditionelle Systeme.
- Der Lüfter. Auf den „energetisch optimalen Chip“ setzen sie ihn. Okay, ich werde nicht mehr über Produktion sprechen.
- Kosten. Am teuersten als TX2.
- Es können nicht zwei Gitter gleichzeitig gespeichert werden. Es ist notwendig, einen Upload-Download durchzuführen. Dies verlangsamt die Inferenz mehrerer Netzwerke.
Vorteile:
- Von allem, worüber wir sprechen, ist Coral die schnellste
- Wenn der Chip aufgerufen wird, ist er möglicherweise produktiver als Movidius. Und es scheint, dass seine Architektur für Neuronen mehr gerechtfertigt ist.
Gyrfalcon

In den letzten anderthalb Jahren wurde über dieses chinesische Tier gesprochen. Noch vor einem
Jahr habe ich etwas über ihn gesagt. Aber reden ist eine Sache und Informationen geben ist eine andere. Ich sprach mit 3-4 großen Unternehmen, in denen Projektmanager / Direktoren mir sagten, wie cool dieser Girfalkon war. Aber sie hatten keine Dokumentation. Und sie haben ihn nicht lebend gesehen. Die
Seite hat fast keine Informationen.
Download von der Seite kann zumindest etwas nur Partner (Hardware-Entwickler). Darüber hinaus sind die Informationen auf der Website sehr widersprüchlich. An einer Stelle schreiben sie, dass sie nur
VGG unterstützen , an einer anderen, dass nur ihre Neuronen auf GNet basieren (die nach
ihren Zusicherungen sehr klein und wirklich ohne Genauigkeitsverlust sind). Im dritten wird geschrieben, dass alles mit TF | Caffe | PyTorch konvertiert wird, und im vierten wird über das Mobiltelefon und andere Reize geschrieben.
Die Wahrheit zu verstehen ist fast unmöglich. Einmal habe ich ein paar Videos gegraben und gegraben, in denen zumindest einige Zahlen verrutschen:
Wenn dies zutrifft, bedeutet dies, dass SSD (auf Mobilgeräten?) Unter 224 * 224 auf dem GTI2801-Chip ~ 60 ms haben, was mit movidius durchaus vergleichbar ist.
Es scheint, als hätten sie einen viel schnelleren Chip 2803, aber die Informationen darüber sind noch geringer:
Diesen Sommer haben wir ein
Board von Firefly in unseren Händen (
dieses Modul wird dort für Berechnungen installiert).
Es gab eine Hoffnung, dass wir endlich lebend sehen würden. Aber es hat nicht geklappt. Das Board war sichtbar, funktionierte aber nicht. Beim Durchblättern einzelner englischer Phrasen in der chinesischen Dokumentation haben sie fast sogar verstanden, wo das Problem lag (das ursprüngliche Rändelsystem unterstützte das neuronale Modul nicht, es war notwendig, alles selbst neu zu erstellen und neu zu rollen). Aber es hat einfach nicht geklappt und es gab bereits den Verdacht, dass das Board nicht zu unserer Aufgabe passt (2 GB RAM sind für neuronale Netze + Systeme sehr klein. Außerdem gab es keine Unterstützung für zwei Netze gleichzeitig).
Aber ich habe es geschafft, die Originaldokumentation zu sehen. Daraus wird zu wenig verstanden (Chinesisch). Für immer war es notwendig, die Quelle zu testen und zu betrachten.
Der technische Support von RockChip hat uns dumm getroffen.
Trotz dieses Grauens ist mir klar, dass hier trotzdem die Pfosten von RockChip zuallererst hier sind. Und ich habe die Hoffnung, dass in einem normalen Board Gyrfalcon durchaus verwendet werden kann. Aufgrund fehlender Informationen fällt es mir jedoch schwer, dies zu sagen.
Nachteile:
- Kein offener Verkauf, nur Interaktion mit Firmen
- Wenig Informationen, keine Community. Vorhandene Informationen sind oft auf Chinesisch. Plattformfunktionen können nicht im Voraus vorhergesagt werden
- Höchstwahrscheinlich ist die Inferenz nicht mehr als ein Netzwerk gleichzeitig.
- Nur die Eisenhersteller können mit dem Gyroplane selbst interagieren. Der Rest muss nach Vermittlern / Herstellern von Boards suchen.
Vorteile:
- Soweit ich weiß, ist der Preis für einen Girfcon-Chip viel günstiger als für andere. Auch in Form von Flash-Laufwerken.
- Es gibt bereits Geräte von Drittanbietern mit integriertem Chip. Daher ist die Entwicklung etwas einfacher als bei movidius.
- Sie stellen sicher, dass es viele vorab trainierte Gitter gibt. Die Übertragung von Gittern ist viel einfacher als bei Movidius | Coral. Aber ich würde dies nicht als die Wahrheit garantieren. Es ist uns nicht gelungen.
Kurz gesagt, die Schlussfolgerung lautet: sehr wenig Informationen. Sie können nicht nur auf dieser Plattform liegen. Und bevor Sie etwas dagegen tun, müssen Sie eine große Bewertung abgeben.
Geschwindigkeiten
Mir gefällt sehr gut, wie 90% der Vergleiche eingebetteter Geräte auf Geschwindigkeitsvergleiche reduziert werden. Wie Sie oben verstanden haben, ist diese Eigenschaft sehr willkürlich. Für Jetson Nano können Sie Neuronen als reinen Tensorflow ausführen, Sie können Tensorflow-Tensorrt verwenden oder Sie können reinen Tensorrt verwenden. Geräte mit spezieller Tensorarchitektur (movidius | coral | gyrfalcone) - können schnell sein, aber in erster Linie können sie nur mit Standardarchitekturen arbeiten. Selbst für den Raspberry Pi ist nicht alles so einfach. Neuronen von
xnor.ai beschleunigen eineinhalb Mal. Aber ich weiß nicht, wie ehrlich sie sind und was durch den Wechsel zu int8 oder anderen Witzen gewonnen wurde.
Gleichzeitig ist ein weiterer interessanter Moment ein solcher Moment. Je komplexer das Neuron ist, desto komplexer ist das Inferenzgerät - desto unvorhersehbarer ist die endgültige Beschleunigung, die herausgezogen werden kann. Nehmen Sie etwas OpenPose. Es gibt ein nicht triviales Netzwerk, komplexe Nachbearbeitung. Sowohl dies als auch das können optimiert werden durch:
- GPU-Nachbearbeitungsmigration
- Nachbearbeitung optimieren
- Neuronale Netzwerkoptimierung für Plattformfunktionen, zum Beispiel:
- Plattformoptimierte Netzwerke verwenden
- Verwenden von Netzwerkmodulen für die Plattform
- Portierung auf int8 | int16 | binarization
- Verwendung mehrerer Taschenrechner (GPU | CPU | etc.). Ich erinnere mich, dass wir auf Jetson TX1 einmal gut beschleunigt haben, als wir alle Funktionen im Zusammenhang mit Video-Streaming zu diesem Zweck auf die eingebauten Beschleuniger übertragen haben. Trite, aber das Netzwerk beschleunigte sich. Beim Balancieren tauchen viele interessante Kombinationen auf
Manchmal versucht jemand, etwas für alle möglichen Kombinationen zu bewerten. Aber wirklich, wie es mir scheint, ist das zwecklos. Zuerst müssen Sie sich für die Plattform entscheiden und erst dann versuchen, alles, was möglich ist, vollständig herauszuholen.
Warum bin ich das alles? Außerdem ist der "
wie lange MobileNet " -Test ein sehr schlechter Test. Er kann sagen, dass Plattform X optimal ist. Wenn Sie jedoch versuchen, Ihr Neuron und die Nachbearbeitung dort einzusetzen, sind Sie möglicherweise sehr enttäuscht.
Der Vergleich von mobilnet'ov liefert jedoch noch einige Informationen über die Plattform. Für einfache Aufgaben. In Situationen, in denen Sie verstehen, dass die Aufgabe ohnehin einfacher auf Standardansätze zu reduzieren ist. Wenn Sie die Geschwindigkeit des Rechners bewerten möchten.
Die folgende Tabelle stammt von mehreren Stellen:
- Diese Studien sind: 1 , 2 , 3
- Für SSD gibt es einen solchen Parameter "Anzahl der Ausgabeklassen". Und von diesem Parameter kann die Inferenzrate stark variieren. Ich habe versucht, Studien mit der gleichen Anzahl von Klassen zu wählen. Dies ist jedoch möglicherweise nicht überall der Fall.
- Unsere Erfahrung mit TensorRT. Ich wusste, welche Sorten funktionieren, welche nicht.
- Für Gyrfalcon basieren diese Videos auf der Tatsache, dass Mobilnet v2 vorhanden ist + eine Schätzung, wie viel die Gebietsänderung kostet. Dieses Video sagt, dass 2803 3-4 mal schneller sein kann. Für 2803 gibt es jedoch keine SSD-Bewertungen. Im Allgemeinen bezweifle ich die Geschwindigkeiten an dieser Stelle am meisten.
- Ich habe versucht, die Studie auszuwählen, die die tatsächliche Höchstgeschwindigkeit ergibt (ich habe beispielsweise die Version von Nvidia nicht ohne NMS verwendet).
- Für Jetson TX2 habe ich diese Bewertungen verwendet, aber es gibt 5 Klassen mit der gleichen Anzahl von Klassen, dass der Rest langsamer sein wird. Ich habe irgendwie aus der Erfahrung / dem Vergleich mit Nano in den Kernen herausgefunden, was da sein sollte
- Witze mit Bitrate habe ich nicht berücksichtigt. Ich weiß nicht, an welcher Bitterkeit Movidius und Gyrfalcon gearbeitet haben.
Als Ergebnis haben wir:

Plattformvergleich
Ich werde versuchen, alles, was ich oben gesagt habe, an einen einzigen Tisch zu bringen. Ich habe die Stellen gelb hervorgehoben, an denen mein Wissen nicht ausreicht, um eine eindeutige Schlussfolgerung zu ziehen. Und tatsächlich 1-6 - dies ist eine vergleichende Bewertung der Plattformen. Je näher an 1, desto besser.

Ich weiß, dass der Energieverbrauch für viele von entscheidender Bedeutung ist. Aber es scheint mir, dass hier alles etwas mehrdeutig ist, und ich verstehe das zu schlecht - also habe ich es nicht eingegeben. Darüber hinaus scheint die Ideologie selbst überall gleich zu sein.
Seitenschritt
Worüber wir gesprochen haben, ist nur ein kleiner Punkt in der Vielzahl von Variationen Ihres Systems. Wahrscheinlich die gebräuchlichen Wörter, die diesen Bereich charakterisieren können:
- Geringer Stromverbrauch
- Kleine Größe
- Hohe Rechenleistung
Wenn Sie jedoch global die Bedeutung eines der Kriterien verringern, können Sie der Liste viele andere Geräte hinzufügen. Im Folgenden werde ich alle Ansätze durchgehen, die ich getroffen habe.
Intel
Wie bereits bei der Diskussion über Movidius erwähnt, verfügt Intel über eine OpenVino-Plattform. Es ermöglicht eine sehr effiziente Verarbeitung von Neuronen auf Intel-Prozessoren. Darüber hinaus können Sie mit der Plattform sogar alle Arten von Intel-GPU auf einem Chip unterstützen. Ich habe jetzt Angst, genau zu sagen, welche Art von Leistung für welche Aufgaben verfügbar ist. Aber so wie ich es verstehe, ergibt ein guter Stein mit einer GPU an Bord eine Leistung von 1080. Bei einigen Aufgaben kann es sogar schneller sein.

In diesem Fall ist der Formfaktor, beispielsweise Intel NUC, recht kompakt. Gute Kühlung, Verpackung usw. Die Geschwindigkeit ist schneller als beim Jetson TX2. Durch Verfügbarkeit / einfache Anschaffung - viel einfacher. Die Stabilität der Plattform nach dem Auspacken ist höher.
Zwei Nachteile - Stromverbrauch und Preis. Die Entwicklung ist etwas komplizierter.
Jetson agx

Dies ist ein weiterer Jetson. Im Wesentlichen die älteste Version. Die Geschwindigkeit ist ungefähr 2-mal schneller als bei Jetson TX2 und es werden int8-Berechnungen unterstützt, mit denen Sie weitere 4-mal übertakten können. Schauen Sie sich übrigens dieses
Bild von Nvidia an:
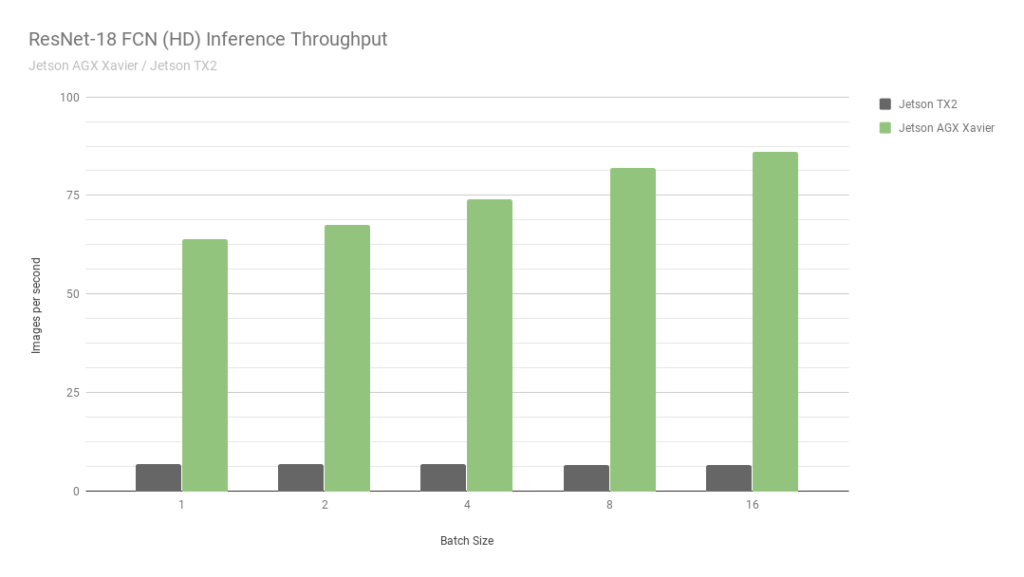
Sie vergleichen zwei ihrer eigenen Jetson. Eine in int8, die zweite in int32. Ich weiß nicht einmal, was ich hier sagen soll ... Kurz gesagt: "GLAUBEN SIE NIEMALS NVIDIA-GRAFIKEN".
Trotz der Tatsache, dass AGX gut ist, erreicht es die normalen GPUs von Nvidia in Bezug auf die Rechenleistung nicht. Trotzdem sind sie in Bezug auf Energieeffizienz sehr cool. Das Haupt abzüglich des Preises.
Wir selbst haben nicht mit ihnen zusammengearbeitet, daher fällt es mir schwer, etwas Detaillierteres zu sagen, um die Aufgabenbereiche zu beschreiben, bei denen sie am optimalsten sind.
Nvidia gpu | Laptop-Version
Wenn Sie die strikte Beschränkung des Stromverbrauchs aufheben, sieht der Jetson TX2 nicht optimal aus. Wie die AGX. Normalerweise haben die Leute Angst, die GPU in der Produktion einzusetzen. Separate Zahlung, das alles.
Es gibt jedoch Millionen von Unternehmen, die Ihnen anbieten, eine kundenspezifische Lösung auf einer Platine zusammenzustellen. Normalerweise sind dies Karten für Laptops / Minicomputer. Oder am Ende
so :

Eines der Startups, in denen ich seit 2,5 Jahren
arbeite (
CherryHome ), hat
genau diesen Weg eingeschlagen. Und wir sind sehr zufrieden.
Minus, wie üblich, beim Energieverbrauch, was für uns nicht kritisch war. Nun, der Preis beißt ein bisschen.
Handys
Ich möchte nicht tief in dieses Thema einsteigen. Um alles zu sagen, was in modernen Mobiltelefonen für Neuronen / welche Frameworks / welche Hardware usw. enthalten ist, benötigen Sie mehr als einen Artikel mit dieser Größe. Und angesichts der Tatsache, dass wir nur 2-3 Mal in diese Richtung gestochert haben, halte ich mich dafür für inkompetent. Also nur ein paar Beobachtungen:
- Es gibt viele Hardwarebeschleuniger, auf denen Neuronen optimiert werden können.
- Es gibt keine allgemeine Lösung, die überall gut funktioniert. Nun gibt es einen Versuch, Tensorflow lite zu einer solchen Lösung zu machen. Aber so wie ich es verstehe, ist es noch nicht eins geworden.
- Einige Hersteller haben ihre eigenen speziellen landwirtschaftlichen Betriebe. Wir haben vor einem Jahr geholfen, das Framework für Snapdragon zu optimieren. Und es war schrecklich. Die Qualität der Neuronen dort ist viel geringer als bei allem, worüber ich heute gesprochen habe. 90% der Ebenen werden nicht unterstützt, auch nicht grundlegende, wie z. B. "Addition".
- Da es keine Python gibt, ist die Schlussfolgerung von Netzwerken sehr seltsam, unlogisch und unpraktisch.
- In Bezug auf die Leistung kommt es vor, dass alles sehr gut ist (zum Beispiel auf einem iPhone).
Es scheint mir, dass für eingebettete Mobiltelefone nicht die beste Lösung ist (die Ausnahme sind einige Low-Budget-Gesichtserkennungssysteme). Aber ich habe einige Fälle gesehen, in denen sie als frühe Prototypen verwendet wurden.
Lücke8
War vor kurzem auf einer
Usedata- Konferenz. Und dort ging es in einem der Berichte um die Inferenz von Neuronen zu den günstigsten Prozentsätzen (GAP8). Und wie sie sagen, ist das Bedürfnis nach Erfindungen gerissen. In der Geschichte war ein Beispiel sehr weit hergeholt. Aber der Autor erzählte, wie sie in etwa einer Sekunde eine Schlussfolgerung aus dem Gesicht ziehen konnten. Auf einem sehr einfachen Gitter, im Wesentlichen ohne Detektor. Durch verrückte und lange Optimierungen und Einsparungen bei Spielen.
Ich mag solche Aufgaben immer nicht. Keine Forschung, nur Blut.
Es ist jedoch erwähnenswert, dass ich mir Rätsel vorstellen kann, bei denen niedrige Prozentsätze ein cooles Ergebnis liefern. Wahrscheinlich nicht zur Gesichtserkennung. Aber irgendwo, wo Sie das Eingabebild in 5-10 Sekunden erkennen können ...
Grove AI HAT

Bei der Vorbereitung dieses Artikels bin ich auf
diese eingebettete Plattform gestoßen. Es gibt sehr wenig Informationen darüber. Soweit ich weiß, keine Unterstützung. Die Produktivität ist auch bei Null ... Und kein einziger Geschwindigkeitstest ...
Server- / Fernerkennung
Jedes Mal, wenn sie auf einer eingebetteten Plattform zu uns kommen, um Ratschläge zu erhalten, möchte ich „Lauf, du Narren!“ Rufen. Es ist notwendig, die Notwendigkeit einer solchen Lösung sorgfältig zu prüfen. Überprüfen Sie alle anderen Optionen. Ich rate jedem, einen Prototyp mit Serverarchitektur zu erstellen. Und während des Betriebs liegt es an Ihnen, zu entscheiden, ob Sie ein echtes Embedded implementieren möchten. Immerhin ist eingebettet:
- Erhöhte Entwicklungszeit, oft 2-3 mal.
- Anspruchsvoller Support und Debugging in der Produktion. Jede Entwicklung mit ML ist eine ständige Überarbeitung, Aktualisierung von Neuronen, Systemaktualisierungen. Eingebettet ist noch schwieriger. Wie lade ich die Firmware neu? Und wenn Sie bereits Zugriff auf alle Einheiten haben, warum sollten Sie dann damit rechnen, wenn Sie mit einem Gerät rechnen können?
- Systemkomplexität / erhöhtes Risiko. Weitere Fehlerquellen. Während das System nicht als Ganzes funktioniert, kann man nicht verstehen: Ist die Plattform für diese Aufgabe geeignet?
- Preiserhöhung. Es ist eine Sache, ein einfaches Board wie Nano Pi zu platzieren. Und das andere ist, TX2 zu kaufen.
Ja, ich weiß, dass es Aufgaben gibt, bei denen Serverentscheidungen nicht getroffen werden können. Aber seltsamerweise sind sie viel kleiner als allgemein angenommen.
Schlussfolgerungen
In dem Artikel habe ich versucht, auf offensichtliche Schlussfolgerungen zu verzichten. Es ist eher eine Geschichte über das, was jetzt ist. Um Schlussfolgerungen zu ziehen, ist es notwendig, jeweils zu untersuchen. Und nicht nur Plattformen. Aber die Aufgabe selbst. Jede Aufgabe kann unter dem Gerät leicht vereinfacht / leicht modifiziert / leicht geschärft werden.
Das Problem bei diesem Thema ist, dass sich das Thema ändert. Neue Geräte / Frameworks / Ansätze kommen. Wenn NVIDIA beispielsweise morgen die int8-Unterstützung für Jetson Nano aktiviert, ändert sich die Situation dramatisch. Wenn ich diesen Artikel schreibe, kann ich nicht sicher sein, dass sich die Informationen vor zwei Tagen nicht geändert haben. Ich hoffe jedoch, dass meine Kurzgeschichte Ihnen hilft, Ihr nächstes Projekt besser zu steuern.
Es wäre cool, wenn Sie zusätzliche Informationen hätten / Ich habe etwas verpasst / etwas Falsches gesagt - schreiben Sie Details hier.
ps
Selbst als ich den Artikel fast
fertig geschrieben hatte, ließ
snakers4 einen kürzlich veröffentlichten
Beitrag von seinem Telegrammkanal Spark in mir fallen, was fast die gleichen Probleme mit Jetson darstellt. Aber, wie ich oben schrieb, würde ich - unter den Bedingungen eines Stromverbrauchs - so etwas wie Zotacs oder IntelNUC einsetzen. Und da Embedded Jetson nicht die schlechteste Plattform ist.
