Vor ungefähr einem Jahr wurden meine Kollegen und ich beauftragt, das beliebte Netzwerkinfrastruktur-Überwachungssystem - Zabbix - zu sortieren. Nachdem wir die Dokumentation studiert hatten, gingen wir sofort zum Lasttest über: Wir wollten bewerten, wie viele Parameter Zabbix ohne merkliche Leistungseinbußen arbeiten kann. Als DBMS wurde nur PostgreSQL verwendet.
Während der Tests wurden einige Architekturmerkmale des Datenbanklayouts und das Verhalten des Überwachungssystems selbst identifiziert, die es dem Überwachungssystem standardmäßig nicht ermöglichen, seine maximale Leistung zu erreichen. Infolgedessen wurden einige Optimierungsmaßnahmen entwickelt, durchgeführt und getestet, hauptsächlich im Hinblick auf die Optimierung der Datenbank.
Ich möchte die Ergebnisse der in diesem Artikel geleisteten Arbeit teilen. Dieser Artikel ist sowohl für Zabbix- als auch für PostgreSQL-DBA-Administratoren sowie für alle nützlich, die das beliebte PosgreSQL-DBMS besser verstehen und verstehen möchten.
Ein kleiner Spoiler: Auf einem schwachen Computer mit einer Last von 200.000 Parametern pro Minute ist es uns gelungen, die CPU iowait von 20% auf 2% zu reduzieren, die Aufzeichnungszeit in Teilen auf Primärdatentabellen um das 250-fache und auf aggregierte Datentabellen um das 32-fache zu reduzieren und die Größe der Indizes zu reduzieren 5-10 mal und beschleunigen den Empfang historischer Proben in einigen Fällen bis zu 18 mal.
Lasttest
Lasttests wurden gemäß dem Schema durchgeführt: ein Zabbix-Server, ein aktiver Zabbix-Proxy, zwei Agenten. Jeder Agent wurde so konfiguriert, dass er 50 Tonnen Ganzzahl- und 50 Tonnen Zeichenfolgenparameter pro Minute ergibt (für insgesamt 200 Agenten 200 Tonnen Parameter pro Minute oder 3333 Parameter pro Sekunde). Um Agentenparameter zu generieren, haben wir ein
Plug-In für Zabbix verwendet. Um zu überprüfen, wie viele maximale Parameter ein Agent generieren kann, müssen Sie ein
spezielles Skript desselben Plug-In-Autors zabbix_module_stress verwenden . Der Zabbix-Webadministrator hat Schwierigkeiten, große Vorlagen zu registrieren. Daher haben wir die Parameter in 20 Vorlagen mit 5 Tonnen Parametern (2500 numerische und 2500 Zeichenfolgen) unterteilt.
Skriptgeneratorvorlage für Lasttests in Pythonimport argparse """ . 20 5000 ( 2500 : echo, ; ping, ) """ TEMP_HEAD = """ <?xml version="1.0" encoding="UTF-8"?> <zabbix_export> <version>2.0</version> <date>2015-08-17T23:15:01Z</date> <groups> <group> <name>Templates</name> </group> </groups> <templates> <template> <template>Template Zabbix Srv Stress {count} passive {char}</template> <name>Template Zabbix Srv Stress {count} passive {char}</name> <description/> <groups> <group> <name>Templates</name> </group> </groups> <applications/> <items> """ TEMP_END = """</items> <discovery_rules/> <macros/> <templates/> <screens/> </template> </templates> </zabbix_export> """ TEMP_ITEM = """<item> <name>{k}</name> <type>0</type> <snmp_community/> <multiplier>0</multiplier> <snmp_oid/> <key>{k}</key> <delay>1m</delay> <history>3</history> <trends>365</trends> <status>0</status> <value_type>{t}</value_type> <allowed_hosts/> <units/> <delta>0</delta> <snmpv3_contextname/> <snmpv3_securityname/> <snmpv3_securitylevel>0</snmpv3_securitylevel> <snmpv3_authprotocol>0</snmpv3_authprotocol> <snmpv3_authpassphrase/> <snmpv3_privprotocol>0</snmpv3_privprotocol> <snmpv3_privpassphrase/> <formula>1</formula> <delay_flex/> <params/> <ipmi_sensor/> <data_type>0</data_type> <authtype>0</authtype> <username/> <password/> <publickey/> <privatekey/> <port/> <description/> <inventory_link>0</inventory_link> <applications/> <valuemap/> <logtimefmt/> </item> """ TMP_FNAME_DEFAULT = "Template_App_Zabbix_Server_Stress_{count}_passive_{char}.xml" chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if __name__ == "__main__": parser = argparse.ArgumentParser( description=' zabbix') parser.add_argument('--items', dest='items', type=int, default=1000, help='- (default: 1000)') parser.add_argument('--templates', dest='templates', type=int, default=1, help=f'- [1-{len(chars)}] (default: 1)') args = parser.parse_args() items_count = args.items tmps_count = args.templates if not (tmps_count >= 1 and tmps_count <= len(chars)): sys.exit(f"Templates must be in range 1 - {len(chars)}") for i in range(tmps_count): fname = TMP_FNAME_DEFAULT.format(count=items_count, char=chars[i]) with open(fname, "w") as output: output.write(TEMP_HEAD.format(count=items_count, char=chars[i])) for k,t in [('stress.ping[{}-I-{:06d}]',3), ('stress.echo[{}-S-{:06d}]',4)]: for j in range(int(items_count/2)): output.write(TEMP_ITEM.format(k=k.format(chars[i],j),t=t)) output.write(TEMP_END)
Die CPU-Iostat-Metrik ist ein guter Indikator für die Zabbix-Leistung. Sie gibt den Bruchteil der Zeiteinheit wieder, in der der Prozessor auf den Festplattenzugriff wartet. Je höher es ist, desto mehr ist die Festplatte mit Lese- und Schreibvorgängen beschäftigt, was sich indirekt auf die Leistungsverschlechterung des gesamten Überwachungssystems auswirkt. Das heißt, Dies ist ein sicheres Zeichen dafür, dass etwas mit der Überwachung nicht stimmt. Übrigens lautet die häufig gestellte Frage auf den Freiflächen des Netzwerks „Wie wird der Iostat-Trigger in Zabbix entfernt?“. Dies ist also ein wunder Punkt, da es viele Gründe gibt, den Wert der iowait-Metrik zu erhöhen.
Hier ist das Bild für die CPU iowait-Metrik, die wir zunächst drei Tage später erhalten haben:
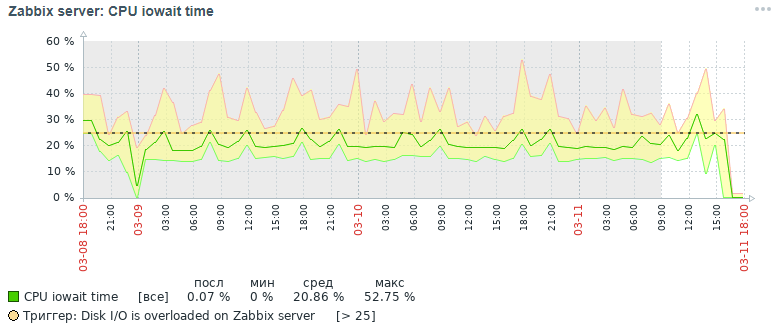
Aber welches Bild für dieselbe Metrik haben wir am Ende auch innerhalb von drei Tagen nach all den durchgeführten Optimierungsmaßnahmen erhalten, auf die weiter unten eingegangen wird:
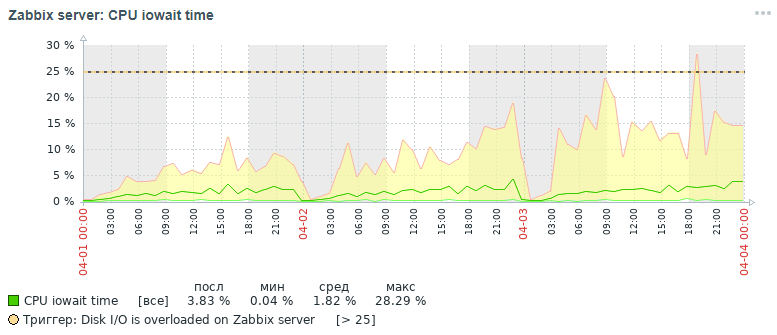
Wie aus den Diagrammen ersichtlich ist, fiel der CPU-Iowaowit-Indikator von fast 20% auf 2%, was indirekt die Ausführungszeit aller Anforderungen zum Hinzufügen und Lesen von Daten beschleunigte. Lassen Sie uns nun sehen, warum mit den Standarddatenbankeinstellungen die Gesamtleistung des Überwachungssystems sinkt und wie dies behoben werden kann.
Gründe für den Leistungsabfall von Zabbix
Bei der Anhäufung von mehr als 10 Millionen Parameterwerten in jeder Tabelle mit Primärdaten wurde festgestellt, dass die Leistung des Überwachungssystems aus folgenden Gründen stark abnimmt:
- Die iowait-Metrik für die Server-CPU wird um mehr als 20% erhöht, was auf eine Verlängerung der Zeit hinweist, in der die CPU den Zugriff auf Lese- und Schreibvorgänge auf der Festplatte erwartet
- Indizes von Tabellen, in denen Überwachungsdaten stark aufgeblasen sind
- Die Auslastungsmetrik wird für eine Festplatte mit Überwachungsdaten auf 100% erhöht, was die volle Auslastung der Festplatte mit Lese- und Schreibvorgängen angibt
- Veraltete Werte haben keine Zeit, um bei der Reinigung gemäß dem Zeitplan der Haushälterin aus den Verlaufstabellen gelöscht zu werden
Die Situation verschärft sich zu Beginn jeder Stunde, wenn zusätzlich aggregierte Stundenstatistiken berechnet werden - gleichzeitig wird das aktive Lesen und Schreiben von Indexseiten von der Festplatte, das Löschen veralteter Daten aus dem Verlauf durchgeführt, was zu demselben Ergebnis führt - ein Rückgang der Datenbankleistung und eine Erhöhung der Ausführungszeit Anfragen (im Limit wurde eine Anfrage von bis zu 5 Minuten notiert!).
Eine kleine Hilfe bei der Organisation eines Überwachungs-Data-Warehouse in Zabbix. Darüber hinaus werden Primärdaten und aggregierte Daten in verschiedenen Tabellen gespeichert, wobei die Parametertypen getrennt werden. Jede Tabelle speichert ein Element-ID-Feld (eine implizite Referenz auf ein registriertes Datenelement im System), einen Zeitstempel zum Registrieren des Taktwerts im Unix-Zeitstempelformat (Millisekunden in einer separaten Spalte) und einen Wert in einer separaten Spalte (die Ausnahme ist die Protokolltabelle, sie enthält mehr Felder - es ist wie ein Ereignisprotokoll ):
Optimierungsaktivitäten
Um die Leistung der PostgreSQL-Datenbank zu verbessern, wurden verschiedene Optimierungsmaßnahmen durchgeführt, von denen die wichtigsten das Partitionieren und Ändern von Indizes sind. Es lohnt sich jedoch, einige Worte über einige wichtige und nützliche Maßnahmen zu erwähnen, die die Arbeit einer Datenbank unter dem PostgreSQL-Datenbankverwaltungssystem beschleunigen können.
Wichtiger Hinweis. Zum Zeitpunkt des Sammelns des Materials des Artikels haben wir Zabbix Version 4.0 verwendet, obwohl Version 4.2 bereits veröffentlicht wurde und Version 4.4 für die Veröffentlichung vorbereitet wird. Warum ist es wichtig, dies zu erwähnen? Da Zabbix ab Version 4.2 eine spezielle leistungsstarke Erweiterung für die Arbeit mit TimescaleDB-Zeitreihen unterstützt, jedoch bisher im experimentellen Modus: Bei allen Vorteilen der Verwendung dieser Erweiterung wird angenommen, dass einige Anforderungen langsamer funktionieren und es immer noch ungelöste Leistungsprobleme gibt (es wird welche geben) behoben in Version 4.4) -
lesen Sie diesen Artikel .
Im nächsten Artikel möchte ich über die Ergebnisse von Lasttests schreiben, die bereits mit der TimescaleDB-Erweiterung im Vergleich zu diesem Lösungsfall durchgeführt wurden. PostgreSQL-Version wurde 10 verwendet, aber alle angegebenen Informationen sind für 11 und 12 Versionen relevant (wir warten!).
Deshalb das Wichtigste zuerst:
- Einrichten einer Konfigurationsdatei mit dem Dienstprogramm pgtune
- Speichern der Datenbank auf einer separaten physischen Festplatte
- Partitionieren von Verlaufstabellen mit pg_pathman
- Ändern der Indextypen von Verlaufstabellen in brin (clock) und btree-gin (itemid)
- Erfassung und Analyse von Abfrageausführungsstatistiken pg_stat_statements
- Festlegen der Überwachungsparameter für physische Datenträger
- Verbesserung der Hardwareleistung
- Erstellung eines verteilten Clusters (Material, das über den Rahmen dieses Artikels hinausgeht)
Konfigurieren einer Konfigurationsdatei mit dem Dienstprogramm pgtune
Tatsächlich ist PostgreSQL ein ziemlich leichtes DBMS. Die Standardkonfigurationsdatei ist so konfiguriert, dass, wie mein Kollege sagt, „sogar an der Kaffeemaschine gearbeitet wird“, d. H. auf einem sehr bescheidenen Eisen. Daher muss PostgreSQL für die Serverkonfiguration unter Berücksichtigung der Speichermenge, der Anzahl der Prozessoren, der Art der beabsichtigten Verwendung der Datenbank, der Art der Festplatte (HDD oder SSD) und der Anzahl der Verbindungen konfiguriert werden.
Leider gibt es keine einzige Formel zum Optimieren aller DBMS, aber es gibt bestimmte Regeln und Muster, die für die meisten Konfigurationen geeignet sind (eine feinere Optimierung ist bereits die Arbeit eines Experten). Um die Lebensdauer von DBA zu vereinfachen, wurde das Dienstprogramm
pgtune geschrieben, das durch die
Webversion von
le0pard , dem Autor eines interessanten und nützlichen Buches zur PostgreSQL-Administration, ergänzt wurde.
Ein Beispiel für die Ausführung des Dienstprogramms in der Konsole mit 100 Verbindungen (Zabbix hat einen anspruchsvollen Webadministrator) für den Anwendungstyp "Data Warehouses":
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
Die Konfigurationsparameter, die das Dienstprogramm pgtune mit einer Beschreibung des Zwecks ändert (Werte sind als Beispiel angegeben). # DB Version: 11
# Betriebssystemtyp: Linux
# DB Typ: Web
# Gesamtspeicher (RAM): 8 GB
# CPUs num: 1
# Verbindungsnummer: 100
# Datenspeicherung: Festplatte
max_connections = 100 # maximale Anzahl gleichzeitiger Datenbankverbindungen
shared_buffers = 2 GB # Speichergröße für verschiedene Puffer (hauptsächlich Cache von Tabellenblöcken und Indexblöcken) im gemeinsam genutzten Speicher
effektive_cache_size = 6 GB # maximale Größe des erforderlichen Speichers für die Ausführung von Abfragen mithilfe von Indizes
wartung_arbeit_mem = 512MB # beeinflusst die Betriebsgeschwindigkeit VACUUM, ANALYZE, CREATE INDEX
checkpoint_completion_target = 0,7 # Zielzeit, um die Checkpoint-Prozedur abzuschließen
wal_buffers = 16 MB # Speicherplatz, der vom gemeinsam genutzten Speicher zum Verwalten von Transaktionsprotokollen verwendet wird
default_statistics_target = 100 # Anzahl der vom Befehl ANALYZE gesammelten Statistiken. Beim Erhöhen erstellt das Optimierungsprogramm Abfragen langsamer, aber besser
random_page_cost = 4 # bedingte Kosten für den Indexzugriff auf Datenseiten - wirkt sich auf die Entscheidung zur Verwendung des Index aus
effektive_io_concurrency = 2 # Anzahl asynchroner E / A-Vorgänge, die das DBMS in einer separaten Sitzung ausführen möchte
work_mem = 10485kB # Die Menge an Speicher, die zum Sortieren und Hashing von Tabellen verwendet wird, bevor temporäre Dateien auf der Festplatte verwendet werden
min_wal_size = 1 GB # liegt unter der Anzahl der WAL-Dateien, die für die zukünftige Verwendung recycelt werden
max_wal_size = 2 GB # begrenzt zusätzlich die Anzahl der WAL-Dateien, die für die zukünftige Verwendung recycelt werden
Einige nützliche Postgresql-Konfigurationsoptionen # gleichzeitige Anforderungshandler verwalten
max_worker_processes = 8 # die maximale Anzahl von Hintergrundprozessen - mindestens einer pro Datenbank
max_parallel_workers_per_gather = 4 # maximale Anzahl paralleler Prozesse innerhalb einer einzelnen Anforderung
max_parallel_workers = 8 # Die maximale Anzahl von Arbeitsprozessen, die das System für parallele Operationen unterstützen kann
# Protokollierungseinstellungen (eine einfache Möglichkeit, die Ausführungszeit von Abfragen zu ermitteln, ohne die Erweiterung pg_stat_statements zu verwenden)
log_min_duration_statement = 3000 # Schreibe die Dauer der Ausführung aller Befehle in die Protokolle, deren Betriebszeit> = des angegebenen Wertes in ms ist
log_duration = off # zeichnet die Dauer jedes abgeschlossenen Befehls auf
log_statement = 'none' # welche SQL-Befehle in das Protokoll geschrieben werden sollen, Werte: none (deaktiviert), ddl, mod und all (alle Befehle)
debug_print_plan = off # Ausgabe des Abfrageplanbaums zur weiteren Analyse
# Drücken Sie das Maximum aus der Datenbank heraus und seien Sie bereit, es für jeden Fehler zu erhalten (für die am meisten unterdrückten, die die Existenz von ssd und eines verteilten Clusters ignorieren)
#fsync = off # physisches Schreiben auf die Änderungsdiskette. Das Deaktivieren von fsync führt zu einem Geschwindigkeitsgewinn, kann jedoch zu dauerhaften Fehlern führen
Mit #synchronous_commit = off # können Sie dem Client antworten, noch bevor sich die Transaktionsinformationen in der WAL befinden - eine nahezu sichere Alternative zum Deaktivieren von fsync
#full_page_writes = off # Das Herunterfahren beschleunigt den normalen Betrieb, kann jedoch zu Datenbeschädigung oder Datenbeschädigung führen, wenn das System abstürzt
Auflisten einer Datenbank auf einer separaten physischen Festplatte
Dieses Element ist optional und stellt eher eine Übergangslösung für einen vollwertigen verteilten Cluster dar. Es ist jedoch hilfreich, diese Möglichkeit zu kennen. Um die Datenbank zu beschleunigen, können Sie sie auf einer separaten Festplatte ablegen. Wir haben die gesamte Festplatte im Basisverzeichnis gemountet, in dem alle PostgreSQL-Datenbanken gespeichert sind. Im Allgemeinen kann dies jedoch anders erfolgen: Erstellen Sie eine neue Tabellenbasis und übertragen Sie die Datenbank (oder nur einen Teil davon - die Tabellen der primären und aggregierten Überwachungsdaten) auf dieser Tabellenbasis auf einer separaten Festplatte.
Beispiel montierenZuerst müssen Sie die Festplatte mit dem ext4-Dateisystem formatieren und mit dem Server verbinden. Hängen Sie die Festplatte für die Datenbank mit dem Noatime-Label ein:
mount / dev / sdc1 / var / lib / pgsql / 10 / data / base -o noatime
Fügen Sie für die dauerhafte Bereitstellung die Zeile zur Datei / etc / fstab hinzu:
# wobei UUID die Kennung der Festplatte ist, können Sie sie mit dem Dienstprogramm blkid anzeigen
UUID = 121efe29-70bf-410b-bc71-90704568ce3b / var / lib / pgsql / 10 / data / base ext4-Standardeinstellungen, noatime 0 0
Partitionieren von Verlaufstabellen mit pg_pathman
Eines der Probleme, auf die wir beim Stresstest von Zabbix gestoßen sind - PostgreSQL schafft es nicht, veraltete Daten aus der Datenbank zu löschen. Mithilfe der Partitionierung können Sie die Tabelle in ihre Bestandteile aufteilen und so die Größe der Indizes und Bestandteile der Supertabelle verringern, was sich positiv auf die Geschwindigkeit der gesamten Datenbank auswirkt.
Die Partitionierung löst zwei Probleme gleichzeitig:
1. Beschleunigen Sie das Entfernen veralteter Daten, indem Sie ganze Tabellen löschen
2. Aufteilen von Indizes für jede zusammengesetzte Tabelle
Es gibt vier Mechanismen für die Partitionierung in PostgreSQL:
1.Standard Constraint_Exclusion
2. Erweiterung pg_partman (
nicht mit pg_pathman verwechseln )
3. Erweiterung
pg_pathman4. Erstellen und pflegen Sie Partitionen manuell von uns
Die bequemste, zuverlässigste und optimierte Partitionierungslösung ist unserer Meinung nach die Erweiterung
pg_pathman . Mit dieser Partitionierungsmethode bestimmt der Abfrageplaner flexibel, in welchen Partitionen nach Daten gesucht werden soll.
Gerüchten zufolge wird es in der 12. Version von PostgreSQL bereits eine hervorragende Partition geben.Daher haben wir begonnen, Überwachungsdaten für jeden Tag in eine separate geerbte Tabelle von der Supertabelle zu schreiben, und das Entfernen veralteter Parameterwerte begann durch das gleichzeitige Entfernen aller veralteten Tabellen, was für ein DBMS für Arbeitskosten viel einfacher ist. Das Löschen erfolgte durch Aufrufen der Datenbankbenutzerfunktion als Überwachungsparameter des Zabbix-Servers um 2 Uhr morgens mit Angabe des akzeptablen Bereichs der Statistikspeicherung.
Installieren und konfigurieren Sie die Partitionierung für PostgreSQL 10Installieren und konfigurieren Sie die Erweiterung
pg_pathman aus dem Standard-Betriebssystem-Repository (Anweisungen zum
Erstellen der neuesten Version der Erweiterung aus den Quellen finden Sie im selben Repository auf github):
yum installiere pg_pathman10
nano /var/pgsqldb/postgresql.conf
shared_preload_libraries = 'pg_pathman' # wichtig - hier schreibe pg_pathman zuletzt in die Liste
Wir starten das DBMS neu, erstellen die Erweiterung für die Datenbank und konfigurieren die Partitionierung (1 Tag für die primären Überwachungsdaten und 3 Tage für die aggregierten Überwachungsdaten - dies könnte für 1 Tag erfolgen):
systemctl starte postgresql-10.service neu
psql -d zabbix -U postgres
CREATE EXTENSION pg_pathman;
# Konfigurieren Sie einen Tag für die Tabellen der primären Überwachungsdaten
# 1552424400 - Countdown als Unix-Zeitstempel, 86400 - Sekunden in Tagen
Wählen Sie create_range_partitions ('history', 'clock', 1552424400, 86400).
Wählen Sie create_range_partitions ('history_uint', 'clock', 1552424400, 86400).
Wählen Sie create_range_partitions ('history_text', 'clock', 1552424400, 86400).
Wählen Sie create_range_partitions ('history_str', 'clock', 1552424400, 86400).
Wählen Sie create_range_partitions ('history_log', 'clock', 1552424400, 86400).
# Konfigurieren Sie drei Tage lang für aggregierte Überwachungsdatentabellen
# 1552424400 - Countdown als Unix-Zeitstempel, 259200 - Sekunden in drei Tagen
Wählen Sie create_range_partitions aus ('Trends', 'Uhr', 1545771600, 259200).
Wählen Sie create_range_partitions aus ('trend_uint', 'clock', 1545771600, 259200).
Wenn noch keine Daten in einer der Tabellen vorhanden sind, muss beim Aufrufen der Funktion create_range_partitions ein weiteres zusätzliches Argument p_count = 0_ übergeben werden.Nützliche Abfragen zum Überwachen und Verwalten von Partitionen:
# allgemeine Liste der partitionierten Tabellen, Hauptkonfigurationsspeicher:
wähle * aus pathman_config;
# Darstellung mit allen vorhandenen Abschnitten sowie deren Eltern und Bereichsgrenzen:
Wählen Sie * aus pathman_partition_list.
# zusätzliche Parameter, die das Standardverhalten von pg_pathman überschreiben:
Wählen Sie * aus pathman_config_params;
# Kopieren Sie den Inhalt zurück in die übergeordnete Tabelle und löschen Sie Partitionen:
select drop_partitions ('table_name' :: regclass, false);
Nützliches Skript zum Anzeigen von Statistiken zur Anzahl und Größe von Partitionen:
SELECT nspname AS schemaname, relname, relkind, cast (reltuples as int), pg_size_pretty(pg_relation_size(C.oid)) AS "size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') and (relname like 'history%' or relname like 'trends%') and relkind = 'r'
Automatische Optimierung des Löschens veralteter Partitionen (ahtung - eine große SQL-Funktion)Um das automatische Löschen von Partitionen zu konfigurieren, müssen Sie eine Funktion in der Datenbank erstellen
(Breittext, also musste ich die Syntaxhervorhebung entfernen):
CREATE OR REPLACE FUNCTION public.delete_old_partitions (Ganzzahl history_days, Ganzzahl trend_days, Ganzzahl str_days)
RETURNS Text
SPRACHE plpgsql
AS $ function $
/ *
Die Funktion löscht alle Partitionen, die älter als die angegebene Anzahl von Tagen sind:
history_days - für Partitionen history_x, history_uint_x
Trends_Tage - für Partitionen Trends_x, Trends_Uint_x
str_days - für Partitionen history_str_x, history_text_x, history_log_x
* /
deklarieren clock_today_start int;
deklariere clock_delete_less_history int = 0;
deklariere clock_delete_less_trends int = 0;
deklariere clock_delete_less_strings int = 0;
clock_delete_less int = 0;
deklariere Iterator int = 0;
deklariere result_str text = '';
deklarieren Sie buf_table_size Text;
deklarieren Sie buf_table_len text;
deklariere partition_name text;
deklariere clock_max text;
deklariere err_detail text;
deklariere t_start timestamp = clock_timestamp ();
deklarieren Sie den Zeitstempel t_end;
beginnen
Wenn $ 1 <= 0, dann wird 'ups zurückgegeben, etwas stimmt nicht: Das Argument history_days muss ein positiver ganzzahliger Wert sein'; ende wenn;
Wenn $ 2 <= 0 ist, wird "ups" zurückgegeben. Es stimmt etwas nicht: Das Argument "Trends_days" muss ein positiver ganzzahliger Wert sein. " ende wenn;
Wenn $ 3 <= 0, dann wird 'ups zurückgegeben, etwas stimmt nicht: Das Argument str_days muss ein positiver ganzzahliger Wert sein.'; ende wenn;
clock_today_start = extract (Epoche von date_trunc ('day', now ())) :: int;
clock_delete_less_history = extrahieren (Epoche von date_trunc ('Tag', jetzt ()) - ($ 1 :: Text || 'Tage') :: Intervall) :: int;
clock_delete_less_trends = extract (Epoche von date_trunc ('Tag', jetzt ()) - ($ 2 :: Text || 'Tage') :: Intervall) :: int;
clock_delete_less_strings = extract (Epoche von date_trunc ('Tag', jetzt ()) - ($ 3 :: text || 'Tage') :: Intervall) :: int;
clock_delete_less = least (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings);
- Erhöhen Sie den Hinweis 'clock_today_start% (%)', to_timestamp (clock_today_start), clock_today_start;
- Erhöhen Sie den Hinweis 'clock_delete_less_history% (%)% days', to_timestamp (clock_delete_less_history), clock_delete_less_history, $ 1;
- Benachrichtigung 'clock_delete_less_trends% (%)% days', to_timestamp (clock_delete_less_trends), clock_delete_less_trends, $ 2;
- Erhöhen Sie den Hinweis 'clock_delete_less_strings% (%)% days', to_timestamp (clock_delete_less_strings), clock_delete_less_strings, $ 3;
für partition_name, clock_max in der ausgewählten Partition, range_max von pathman_partition_list where
range_max :: int <= am größten (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings) und
(Partition :: Text wie 'Verlauf%' oder Partition :: Text wie 'Trends%') Reihenfolge nach Partition aufsteigend
Schleife
if (Partitionsname ~ 'history_uint_ \ d' und clock_max :: int <= clock_delete_less_history)
oder (partition_name ~ 'history_ \ d' und clock_max :: int <= clock_delete_less_history)
oder (Partitionsname ~ 'Trends_ \ d' und clock_max :: int <= clock_delete_less_trends)
oder (Partitionsname ~ 'history_log_ \ d' und clock_max :: int <= clock_delete_less_strings)
oder (Partitionsname ~ 'history_str_ \ d' und clock_max :: int <= clock_delete_less_strings)
oder (partition_name ~ 'history_text_ \ d' und clock_max :: int <= clock_delete_less_strings)
dann
Iterator = Iterator + 1;
Benachrichtigung auslösen '%', Format ('!!!% s% s löschen', Partitionsname, Uhr_max);
Wählen Sie max (reltuples :: int), pg_size_pretty (sum (pg_relation_size (pg_class.oid))) als "size" aus pg_class, wobei relname wie partition_name || '%' in strikte buf_table_len, buf_table_size;
wenn result_str! = '' dann result_str = result_str || ','; ende wenn;
result_str = result_str || Format ('% s (dt <% s, len% s,% s)', Partitionsname, to_char (to_timestamp (clock_max :: int), 'JJJJ-MM-TT'), buf_table_len, buf_table_size);
Format ausführen ('Tabelle löschen, falls vorhanden% s', Partitionsname);
ende wenn;
Endschleife;
wenn iterator = 0, dann result_str = format ('es gibt keine Partitionen zum Löschen älterer, dann% s date', to_char (to_timestamp (clock_delete_less), 'YYYY-MM-DD'));
sonst result_str = format ('% s Partitionen in% s Sekunden gelöscht:', Iterator, Trunc (Extrakt (Sekunden von (clock_timestamp () - t_start)) :: numeric, 3)) || result_str;
ende wenn;
- Hinweis '%', result_str;
return result_str;
Ausnahme wenn andere dann
Get Stacked Diagnostics err_detail = PG_EXCEPTION_CONTEXT;
Rückgabeformat ('ups, etwas stimmt nicht:% s [Fehlercode% s],% s', sqlerrm, sqlstate, err_detail);
Ende;
$ function $;
Um die Funktion zum automatischen Bereinigen von Partitionen automatisch aufzurufen, müssen Sie ein Datenelement für den zabbix Server-Host vom Typ "Datenbankmonitor" mit den folgenden Einstellungen erstellen:
- Typ: Datenbankmonitor
- name: delete_old_history_partitions
- Schlüssel: db.odbc.select [delete_old_history_partitions, zabbix]
- SQL-Ausdruck: Wählen Sie delete_old_partitions (3, 30, 30).
# Hier geben die Parameter des Funktionsaufrufs delete_old_partitions die Speicherzeit in Tagen an
# für numerische Werte, aggregierte numerische Werte und Zeichenfolgenwerte
- Datentyp: Text
- Aktualisierungsintervall: 0
- Benutzerintervall: geplant in h2
- Verlaufslagerzeit: 90 Tage
- Datenelementgruppe: Datenbank
Als Ergebnis erhalten wir Statistiken über die Bereinigung von Partitionen vom ungefähr folgenden Typ:
2019-09-16 02:00:00, 3 Partitionen in 0,024 Sekunden gelöscht: Trends_78 (dt <2019-08-17, Länge 1, 48 kB), Verlauf_193 (dt <2019-09-13, Länge 85343, 9448 kB) ), history_uint_186 (dt <2019-09-13, len 27969, 3480 kB)
Wichtig! Nachdem Sie das automatische Löschen von Partitionen über das Datenelement und die Benutzerfunktion eingerichtet haben, müssen Sie die Verlaufs- und Trendbereinigung im Zabbix Housekeeper-
Taskplaner deaktivieren :
Wählen Sie über den Zabbix-Menüpunkt "Administration" -> "Allgemein" -> "Verlauf löschen" aus der Liste in der Ecke -> Deaktivieren alle Kontrollkästchen in den Abschnitten „Verlauf“ und „Änderungsdynamik“. Ändern der Indextypen von Verlaufstabellen in brin (clock) und btree-gin (itemid)
Besonderer Dank geht an
erogov für die
hervorragende Reihe von Übersichtsartikeln zu PostgreSQL-Indizes .
Und in der Tat das gesamte PostgresPRO-Team.Beeindruckt von diesen Artikeln haben wir mit verschiedenen Arten von Indizes in den Überwachungsdatentabellen herumgespielt und sind zu dem Schluss gekommen, welche Arten von Indizes in welchen Feldern die maximale Leistungssteigerung bewirken.Es wurde festgestellt, dass der zusammengesetzte Index btree (itemid, clock) standardmäßig für alle Tabellen mit Überwachungsdaten erstellt wird. Er ist schnell für die Suche, insbesondere nach monoton geordneten Werten, schwillt jedoch auf der Festplatte an, wenn viele Daten vorhanden sind - mehr als 10 Millionen.Auf den Tabellen Standardmäßig werden stündlich aggregierte Statistiken erstellt. In der Regel wird ein eindeutiger Index erstellt, obwohl diese Tabellen zur Datenspeicherung und Eindeutigkeit hier auf Anwendungsserverebene bereitgestellt werden und ein eindeutiger Index nur das Einfügen von Daten verlangsamt.Beim Testen verschiedener Indizes wurde die erfolgreichste Kombination von Indizes ermittelt: der Brin-Index im Clock-Feld und der Btree-Gin-Index im Itemid-Feld für alle Tabellen mit Überwachungsdaten.Der Brin-Index ist ideal für monoton ansteigende Daten, wie den Zeitstempel der Tatsache eines Ereignisses, d.h. für Zeitreihen. Und der btree-gin-Index ist im Wesentlichen ein Gin-Index über Standarddatentypen, der im Allgemeinen viel schneller ist als der klassische btree-Index, weil Der Gin-Index wird beim Hinzufügen neuer Werte nicht neu erstellt, sondern nur durch diese ergänzt. Der btree-gin-Index wird als Erweiterung von PostgreSQL eingefügt.Ein Vergleich der Abtastgeschwindigkeit für diese Indizierungsstrategie und für Indizes in der Zabbix-Datenbank ist unten angegeben. Während der Auslastungstests haben wir drei Tage lang Daten für drei Partitionen gesammelt:Um die Ergebnisse auszuwerten, wurden drei Arten von Abfragen durchgeführt:- für einen bestimmten Parameter itemid Daten für den letzten Monat, tatsächlich die letzten drei Tage (insgesamt 1660 Datensätze)
EXPLAIN Analysieren Wählen Sie * aus history_uint aus, wobei itemid = 313300
und Uhr> = Auszug (Epoche von '2019-03-09 00:00:00' :: Zeitstempel) :: int
und clock <= extract (Epoche von '2019-04-09 12:00:00' :: timestamp) :: int;
- für einen bestimmten Parameter Daten für 12 Stunden eines Tages (insgesamt 649 Einträge)
EXPLAIN Analysieren Wählen Sie * aus history_text aus, wobei itemid = 310650 ist
und Uhr> = Auszug (Epoche von '2019-04-09 00:00:00' :: Zeitstempel) :: int
und clock <= extract (Epoche von '2019-04-09 12:00:00' :: timestamp) :: int;
- für eine bestimmte Parameterdaten für eine Stunde (insgesamt 61 Datensätze):
EXPLAIN analysieren Analyse Anzahl (*) aus history_text mit itemid = 336540
und Uhr> = Auszug (Epoche von '2019-04-08 11:00:00' :: Zeitstempel) :: int
und clock <= extract (Epoche von '2019-04-08 12:00:00' :: timestamp) :: int;
Die Testergebnisse sind nachstehend tabellarisch aufgeführt:* Die Größe in MB wird insgesamt für drei Partitionen angegeben.** Typ 1-Anforderung - Daten für 3 Tage, Typ 2-Anforderung - Daten für 12 Stunden, Typ 3-Anforderung - Daten für eine Stunde.Aus der Vergleichstabelle ist ersichtlich, dass für große Datentabellen die Anzahl der Datensätze gilt Bei mehr als 100 Millionen ist deutlich zu erkennen, dass die Änderung des Standard-Composite-Index btree in zwei Indizes brin und btree-gin sich günstig auf die Reduzierung der Indexgröße und die Beschleunigung der Ausführungszeit von Abfragen auswirkt.Die Effizienz der Indizierung und Partitionierung wird unten am Beispiel einer Anforderung zum Hinzufügen neuer Datensätze zu den Tabellen history_uint und trend_uint gezeigt (Ergänzungen erfolgen durchschnittlich 2000 Werte pro Abfrage).Zusammenfassend lassen sich die Testergebnisse verschiedener Indexkonfigurationen für Zabbix-Systemüberwachungsdatentabellen zusammenfassen. Eine ähnliche Änderung des Standardindex für Zabbix-Systemüberwachungsdatentabellen wirkt sich positiv auf die Gesamtsystemleistung aus, was am deutlichsten zu spüren ist, wenn Datenmengen von über 10 Millionen akkumuliert werden Sie sollten den indirekten Effekt des „Aufschwellens“ des Standard-BTree-Index standardmäßig vergessen - häufige Neuerstellungen des Multi-Gigabyte-Index führen zu einer hohen Auslastung der Festplatte (utiliz-Metrik) ation), was letztendlich die Zeit der Festplattenoperationen und die Latenz des Zugriffs von der CPU auf die Festplatte erhöht (iowait-Metrik).Aber Damit der btree-gin-Index mit dem Datentyp bigint (in8) arbeiten kann, bei dem es sich um die Spalte itemid handelt, müssen Sie eine Familie von Operatoren des Typs bigint für den btree-gin-Index registrieren.Registrieren einer Bigint-Operatorfamilie für den btree-gin-Index/*
gin biginteger integer .
- gin int2, int4, int8,
bigint , bigint (<= 2147483647)
intger_ops, :
create index on tablename using gin(columnname int8_family_ops) with (fastupdate = false);
*/
-- btree_gin
CREATE EXTENSION btree_gin;
CREATE OPERATOR FAMILY integer_ops using gin;
CREATE OPERATOR CLASS int4_family_ops
FOR TYPE int4 USING gin FAMILY integer_ops
Wie
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4,int4),
FUNCTION 2 gin_extract_value_int4(int4, internal),
FUNCTION 3 gin_extract_query_int4(int4, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int4(int4,int4,int2, internal),
STORAGE int4;
CREATE OPERATOR CLASS int8_family_ops
FOR TYPE int8 USING gin FAMILY integer_ops
Wie
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8,int8),
FUNCTION 2 gin_extract_value_int8(int8, internal),
FUNCTION 3 gin_extract_query_int8(int8, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int8(int8,int8,int2, internal),
STORAGE int8;
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int4,int8),
OPERATOR 2 <=(int4,int8),
OPERATOR 3 =(int4,int8),
OPERATOR 4 >=(int4,int8),
OPERATOR 5 >(int4,int8);
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int8,int4),
OPERATOR 2 <=(int8,int4),
OPERATOR 3 =(int8,int4),
OPERATOR 4 >=(int8,int4),
OPERATOR 5 >(int8,int4);
Dieses Skript verteilt alle Indizes in der PostgreSQL-Datenbank für Zabbix von der Standardkonfiguration auf die oben beschriebene optimale Konfiguration./*
*/
--
drop index history_1;
drop index history_uint_1;
drop index history_str_1;
drop index history_text_1;
drop index history_log_1;
-- PK
-- ( , )
alter table trends drop constraint trends_pk;
alter table trends_uint drop constraint trends_uint_pk;
-- bree-gin itemid
-- btree-gin bigint
-- https://habr.com/ru/company/postgrespro/blog/340978/#comment_10545932
-- create extension btree_gin;
create index on history using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_uint using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_str using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_text using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_log using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends_uint using gin(itemid int8_family_ops) with (fastupdate = false);
-- bree-gin itemid
-- brin 128 ,
-- ,
-- https://habr.com/ru/company/postgrespro/blog/346460/
create index on history using brin(clock) with (pages_per_range = 128);
create index on history_uint using brin(clock) with (pages_per_range = 128);
create index on history_str using brin(clock) with (pages_per_range = 128);
create index on history_text using brin(clock) with (pages_per_range = 128);
create index on history_log using brin(clock) with (pages_per_range = 128);
create index on trends using brin(clock) with (pages_per_range = 128);
create index on trends_uint using brin(clock) with (pages_per_range = 128);
Für den Brin-Index für unser Datenvolumen mit einer Intensität von 100 Tonnen Parametern pro Minute (100 Tonnen in der Historie und 100 Tonnen in history_uint) wurde festgestellt, dass der Index in Tabellen mit primären Überwachungsdaten mit einer Zonengröße von 512 Seiten doppelt so schnell funktioniert als bei der Standardgröße von 128 Seiten, dies ist jedoch individuell und hängt von der Größe der Tabellen und der Serverkonfiguration ab. In jedem Fall nimmt der Brin-Index nur sehr wenig Platz ein, aber seine Geschwindigkeit kann durch Feinabstimmung der Größe der Zone leicht erhöht werden, vorausgesetzt, die Datenflussrate ändert sich nicht wesentlich.Daher ist anzumerken, dass die Architektur von Zabbix selbst mit einer Einschränkung verbunden ist: Auf der Registerkarte „Zuletzt verwendete Daten“ werden die letzten beiden Werte für jeden Parameter unter Berücksichtigung der Filterung erfasst. Für jeden Parameter werden Werte in der Datenbank separat angefordert. Je mehr solche Parameter ausgewählt werden, desto länger wird die Abfrage ausgeführt. Die neuesten Daten werden durchsucht, wenn der btree-Index (itemid, clock desc) für Verlaufstabellen mit umgekehrter Sortierung nach Zeit festgelegt wird, aber der Index selbst "schwillt" natürlich auf der Festplatte an und verlangsamt im Allgemeinen indirekt die Datenbank, was ein Problem verursacht. oben beschrieben.Daher gibt es drei Auswege:- « » 100 (.. , « » )
- Zabbix , , « »
- Lassen Sie die Indizes so, wie sie standardmäßig sind, und beschränken Sie sich auf die Partitionierung, um gleichzeitig eine große Auswahl auf der Registerkarte "Zuletzt verwendete Daten" für eine Vielzahl von Parametern zu erhalten (es wurde jedoch festgestellt, dass der Zabbix-Webserver immer noch eine Begrenzung für die Anzahl der gleichzeitig angezeigten Parameterwerte hat auf der Registerkarte "Zuletzt verwendete Daten" - Wenn ich also versuche, 5000 Werte anzuzeigen, hat die Datenbank das Ergebnis berechnet, aber der Server konnte die Webseite nicht vorbereiten und eine so große Datenmenge anzeigen.
Erfassung und Analyse von Abfrageausführungsstatistiken pg_stat_statements
Pg_stat_statements ist eine Erweiterung zum Sammeln von Statistiken zur Abfrageleistung auf dem gesamten Server. Der Vorteil dieser Erweiterung besteht darin, dass keine PostgreSQL-Protokolle erfasst und analysiert werden müssen.Verwenden der Erweiterung pg_stat_statementspsql:
CREATE EXTENSION pg_stat_statements;
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # sql , ( );
pg_stat_statements.track = all # all - ( ), top - /, none -
pg_stat_statements.save = true #
:
SELECT pg_stat_statements_reset();
:
select substring(query from '[^(]*') as query_sub, sum(calls) as calls, avg(mean_time) as mean_time from pg_stat_statements where query ~ 'insert into' or query ~ 'update trends' group by substring(query from '[^(]*') order by calls desc
Zur Überwachung von Festplatten in Zabbix werden standardmäßig nur die Parameter vfs.dev.read und vfs.dev.write bereitgestellt. Diese Optionen enthalten keine Informationen zur Festplattenauslastung. Nützliche Kriterien zum Auffinden von Problemen mit der Leistung Ihrer Festplatten sind der Auslastungsfaktor, das Warten auf die Abfragezeit und das Laden der Festplattenwarteschlange.In der Regel korreliert eine hohe Festplattenlast mit einem hohen iowait der CPU selbst und mit einer Verlängerung der Ausführungszeit von SQL-Abfragen, die beim Stresstest eines zabbix-Servers mit einer Standardkonfiguration ohne Partitionierung und ohne Einrichtung alternativer Indizes festgestellt wurde. Sie können diese Parameter für die Überwachung von Festplatten mithilfe der folgenden Schritte hinzufügen, die in einem Artikel eines Freundes beschrieben wurdenlesovsky und verbessert: Jetzt werden die iostat-Parameter für jede Platte im json-Zeitparameter separat erfasst, von wo aus sie gemäß den Nachbearbeitungseinstellungen bereits in die endgültigen Überwachungsparameter zerlegt werden.Während die Pull-Anforderung aussteht, können Sie versuchen, die Überwachung der Festplattenparameter gemäß den detaillierten Anweisungen über meine Gabel zu erweitern .Nach allen beschriebenen Schritten können Sie dem Hauptüberwachungsfeld des Zabbix-Servers ein benutzerdefiniertes Diagramm mit iowait-CPU- und Nutzungsparametern für die Systemfestplatte und die Festplatte aus der Datenbank (sofern diese unterschiedlich sind) hinzufügen. Das Ergebnis könnte folgendermaßen aussehen (sda ist die Hauptfestplatte, sdc ist die Festplatte mit der Datenbank):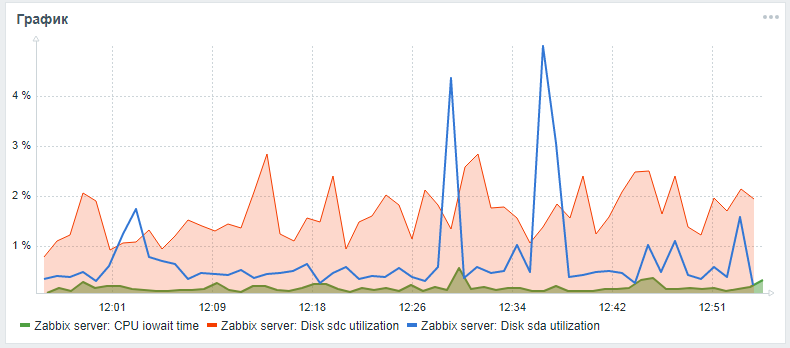
Verbesserung der Hardwareleistung
Nach dem Einrichten des DBMS, der Indizierung und Partitionierung können Sie mit der vertikalen Skalierung fortfahren, um die Hardwareeigenschaften des Servers zu verbessern: RAM hinzufügen, Laufwerke in Solid-State ändern und Prozessorkerne hinzufügen. Dies ist eine garantierte Leistungssteigerung, aber es ist besser, dies erst nach der Softwareoptimierung zu tun.Erstellen eines verteilten Clusters
Nach einer moderaten vertikalen Skalierung müssen Sie horizontal starten - erstellen Sie einen verteilten Cluster: entweder Shard oder Replikation des Master-Slaves. Dies ist jedoch ein separates Thema und Material eines separaten Artikels (wie man eine Ansammlung von Scheiße und Stöcken formt ) sowie ein Vergleich der oben beschriebenen Zabbix-Datenbankoptimierungstechnik unter Verwendung von pg_pathman und Indizierung mit der Methode zum Anwenden der TimescaleDB-Erweiterung.In der Zwischenzeit kann man nur hoffen, dass sich das Material in diesem Artikel als nützlich und informativ erwiesen hat!