Woher wissen Sie sicher, was sich in dem Brötchen befindet?
Vielleicht schluckst du es und darin ist ein Fluss? © Tanya Zadorozhnaya
Was Data Science heute ist, wissen anscheinend nicht nur Kinder, sondern auch Haustiere. Fragen Sie eine Katze, und sie wird sagen: Statistik, Python, R, BigData, maschinelles Lernen, Visualisierung und viele andere Wörter, je nach Qualifikation. Aber nicht alle Katzen sowie diejenigen, die Spezialist für Data Science werden möchten, wissen genau, wie das Data Science-Projekt aufgebaut ist, aus welchen Phasen es besteht und wie sich jede von ihnen auf das Endergebnis auswirkt und wie ressourcenintensiv jede Phase des Projekts ist. Die Methodik wird normalerweise verwendet, um diese Fragen zu beantworten. Die meisten Schulungen zu Data Science sagen jedoch nichts über die Methodik aus, sondern enthüllen einfach mehr oder weniger konsequent die Essenz der oben genannten Technologien, und jeder Anfänger von Data Scientist lernt die Struktur des Projekts aus eigener Erfahrung (und Rechen) kennen. Aber ich persönlich gehe gerne mit einer Karte und einem Kompass in den Wald und stelle mir gerne im Voraus den Plan der Route vor, die Sie bewegen. Nach einigen Recherchen gelang es mir, eine gute Methodik von IBM zu finden, einem bekannten Hersteller von Handbüchern und Methoden zum Verwalten von Dingen.
Im Data Science-Projekt gibt es also 3 Blöcke mit jeweils 3 Stufen, insgesamt 9 Stufen. Kurz gesagt, das Projekt besteht aus der Arbeit mit Geschäftsanforderungen, Daten und dem Modell selbst.
Arbeiten Sie mit geschäftlichen Anforderungen
Zu diesem Zeitpunkt wissen wir nichts darüber, über welche Daten wir verfügen. Wir müssen uns mit der Problemstellung befassen, verstehen, welche Ergebnisse für das Projekt erforderlich sind, und alles über die Teilnehmer und Stakeholder erfahren. Ferner müssen wir gemäß einer bestimmten Aufgabe entscheiden, mit welcher Methode das Problem gelöst wird. Das Ergebnis dieses Schritts sind Datenanforderungen: OK, die Aufgabe ist klar, die Methode wurde ausgewählt. Jetzt überlegen wir, was wir für eine erfolgreiche Lösung benötigen.
Mit Daten arbeiten
Im zweiten Schritt beginnen wir mit der Suche nach Daten, um das Problem zu lösen: Wir finden heraus, welche Quellen uns zur Verfügung stehen, und bilden ein Beispiel, mit dem wir weiterarbeiten werden. Nach der Datenerfassung müssen eine Reihe von Studien durchgeführt werden, um die Organisation der Stichprobe besser zu verstehen: Untersuchung der zentralen Position und Variabilität, Identifizierung von Korrelationen zwischen Merkmalen und Erstellung von Verteilungsdiagrammen. Nach dieser Phase können Sie mit der Vorbereitung der Daten beginnen. In der Regel ist diese Phase am zeitaufwändigsten und kann bis zu 90% der gesamten Projektzeit in Anspruch nehmen. Der Erfolg des gesamten Projekts hängt jedoch davon ab, wie gut es abgeschlossen ist.
Entwicklung und Umsetzung
Zum Schluss der dritte Schritt. Sobald die Daten fertig sind, können Sie mit der eigentlichen Entwicklung und Implementierung fortfahren. Wir programmieren das Modell, setzen es auf das Trainingsmuster, überprüfen es auf dem Testmuster, wenn das Ergebnis zufriedenstellend ist, demonstrieren es dem Kunden, implementieren es, stellen das Feedback zusammen und ... Sie können von vorne beginnen.
Der gesamte Prozess wird in Form eines Teufelskreises dargestellt: Auf gute Weise kann ein DS-Projekt niemals als abgeschlossen betrachtet werden (ungefähr wie eine Reparatur, die, wie Sie wissen, nicht abgeschlossen, sondern nur gestoppt werden kann):
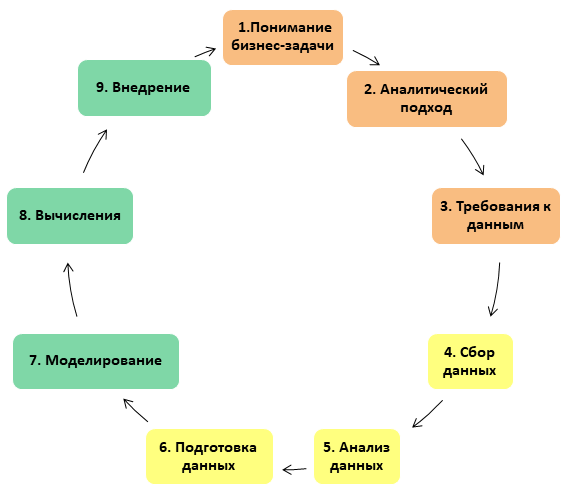
Lassen Sie uns auf jede der Stufen näher eingehen.
1. Die geschäftliche Herausforderung verstehen
Diese Phase ist die Grundlage für alle nachfolgenden Arbeiten: Ohne sie kann man nichts bauen. Es ist notwendig, den Zweck der Studie klar zu definieren: Was ist das Problem? Warum sollte das Problem gelöst werden? Wer ist von dem Problem betroffen? Was sind die Alternativen? Und vor allem: An welchen Metriken wird der Erfolg des Projekts gemessen?
Mit anderen Worten, es ist notwendig, das Ziel des Kunden klar zu identifizieren. Ein Geschäftsinhaber fragt beispielsweise: Können wir die Kosten einer bestimmten Aktivität senken? Müssen Sie klarstellen: Ist das Ziel, die Wirksamkeit dieser Aktivität zu erhöhen? Oder den Geschäftsumsatz steigern?
Sobald das Ziel definiert ist, können Sie mit dem nächsten Schritt fortfahren.
2. Der analytische Ansatz
Jetzt müssen Sie einen analytischen Ansatz wählen, um ein Geschäftsproblem zu lösen. Die Wahl des Ansatzes hängt davon ab, welche Art von Antwort Sie am Ende benötigen: Wenn die Antwort Ja / Nein sein sollte, ist ein naiver Bayes-Klassifikator geeignet. Wenn Sie eine Antwort in Form eines numerischen Vorzeichens benötigen, sind Regressionsmodelle geeignet. Entscheidungsbäume können sowohl numerische als auch kategoriale Daten verarbeiten. Wenn die Frage darin besteht, die Wahrscheinlichkeiten bestimmter Ergebnisse zu bestimmen, muss ein Vorhersagemodell verwendet werden. Wenn Links identifiziert werden müssen, wird ein beschreibender Ansatz verwendet.
3. Datenanforderungen
Wenn der Zweck der Studie klar definiert ist und der Ansatz gewählt ist, dh wir klar verstehen, welche Art von Antwort auf die gesuchte Frage wir suchen, müssen wir bestimmen, welche Daten es uns ermöglichen, die gewünschte Antwort zu geben. Wir müssen Datenanforderungen vorbereiten: Inhalte, Formate und Quellen, die in der nächsten Phase des Projekts verwendet werden.
4. Datenerfassung
In dieser Phase sammeln wir Daten aus verfügbaren Quellen: Wir stellen sicher, dass die Quellen verfügbar und zuverlässig sind und verwendet werden können, um die erforderlichen Daten in der erforderlichen Qualität zu erhalten. Nach Abschluss der ersten Datenerfassung muss bekannt sein, ob wir die gewünschten Daten erhalten haben. In dieser Phase können Sie die Datenanforderungen überarbeiten und Entscheidungen über den Bedarf an zusätzlichen Daten treffen (dh, Sie müssen wahrscheinlich zu Phase 3 zurückkehren). In den Daten können Lücken identifiziert und ein Plan erstellt werden, wie diese geschlossen oder ein Ersatz gefunden werden kann.
5. Datenanalyse
Die Datenanalyse umfasst alle Entwurfsarbeiten für Stichproben. Zu diesem Zeitpunkt ist es notwendig, eine Antwort auf die Frage zu erhalten: Sind die gesammelten Daten repräsentativ für die Aufgabe?
Hier brauchen wir beschreibende Statistiken. Dies gilt für alle Variablen, die im ausgewählten Modell verwendet werden: Die zentrale Position (Mittelwert, Median, Modus) wird untersucht, Ausreißer werden gesucht und die Variabilität wird geschätzt (in der Regel sind dies Größe, Varianz und Standardabweichung). Es werden auch Histogramme der Variablenverteilung erstellt. Histogramme sind ein gutes Werkzeug, um zu verstehen, wie Datenwerte verteilt sind und welche Art von Vorbereitung erforderlich ist, damit die Variable beim Erstellen eines Modells am nützlichsten ist. Andere Visualisierungstools wie Schnurrbartboxen können ebenfalls hilfreich sein.
Als nächstes werden paarweise Vergleiche durchgeführt: Korrelationen zwischen den Variablen werden berechnet, um zu bestimmen, welche von ihnen in Beziehung stehen und wie viel. Wenn zwischen den Variablen signifikante Korrelationen bestehen, werden einige von ihnen möglicherweise als redundant verworfen.
6. Datenaufbereitung
Zusammen mit der Erfassung und Analyse von Daten ist die Datenaufbereitung eine der ressourcenintensivsten Aktivitäten des Projekts: Diese Phasen können 70 oder sogar 90% der Projektzeit in Anspruch nehmen. In dieser Phase verarbeiten wir die Daten so, dass es bequem ist, damit zu arbeiten: Duplikate löschen, fehlende oder falsche Daten verarbeiten, Formatierungsfehler prüfen und gegebenenfalls korrigieren.
Auch in dieser Phase konstruieren wir eine Reihe von Faktoren, mit denen maschinelles Lernen in den nächsten Phasen arbeiten wird: Wir extrahieren und wählen Funktionen aus, die möglicherweise zur Lösung eines Geschäftsproblems beitragen. Fehler in dieser Phase können sich als kritisch für das gesamte Projekt herausstellen. Daher sollte besonders darauf geachtet werden: Eine übermäßige Anzahl von Attributen kann dazu führen, dass das Modell umgeschult wird und das Modell nicht ausreichend geschult wird.
7. Modell erstellen
Wie Sie sehen, erfolgt die Auswahl des Modells zu Beginn der Arbeit und hängt von der Geschäftsaufgabe ab. Wenn also der Modelltyp bestimmt wird und ein Trainingsmuster vorhanden ist, entwickelt der Analyst das Modell und prüft, wie es mit den in Schritt 6 erstellten Features funktioniert.
8. Anwendung des Modells
Die Anwendung des Modells ist eng mit der tatsächlichen Konstruktion des Modells verbunden: Berechnungen wechseln sich mit der Konfiguration des Modells ab. In dieser Phase müssen wir die Frage beantworten, ob das konstruierte Modell die Geschäftsaufgabe erfüllt.
Die Berechnung des Modells besteht aus zwei Phasen: Es werden diagnostische Messungen durchgeführt, um zu verstehen, ob das Modell wie beabsichtigt funktioniert. Wenn ein Vorhersagemodell verwendet wird, kann ein Entscheidungsbaum verwendet werden, um zu verstehen, dass die Ausgabe des Modells mit dem ursprünglichen Plan übereinstimmt. In der zweiten Phase wird die statistische Signifikanz der Hypothese überprüft. Es muss sichergestellt werden, dass die Daten im Modell korrekt verwendet und interpretiert werden und das erhaltene Ergebnis über dem statistischen Fehler liegt.
9. Implementierung
Wenn das Modell eine zufriedenstellende Antwort auf die Frage gibt, sollte diese Antwort von Vorteil sein. Wenn das Modell entwickelt ist und der Analyst vom Ergebnis seiner Arbeit überzeugt ist, muss der Kunde mit dem entwickelten Tool vertraut gemacht werden. Es ist sinnvoll, nicht nur den Eigentümer des Produkts, sondern auch andere Interessenten anzulocken: Marketing, Entwickler, Systemadministratoren: Jeder, der die weitere Verwendung der Projektergebnisse irgendwie beeinflussen kann. Als nächstes müssen Sie mit der Implementierung fortfahren. Die Implementierung kann schrittweise erfolgen, z. B. für eine begrenzte Gruppe von Benutzern oder in einer Testumgebung. Es ist auch notwendig, ein Feedback-System einzurichten, um zu verfolgen, wie erfolgreich das entwickelte Modell die Aufgabe bewältigt. Nach einiger Zeit wird dieses Feedback hilfreich sein, um das Modell zu verbessern. Es können auch neue Datenquellen und neue Stakeholder auftreten, ganz zu schweigen von der Tatsache, dass die Geschäftsaufgabe selbst angegeben werden kann. Der Perfektion sind also keine Grenzen gesetzt: Selbst ein eingebettetes Modell kann niemals als ideal angesehen werden.