Die Entwicklung hat sich in den letzten Jahren stark verändert. Anstelle monolithischer Anwendungen kamen Mikrodienste und Funktionen. Datenbanken von universellen Industriemonstern sind zu eng zielgerichteten Datenbanken verkommen. Docker änderte seine Meinung über den Einsatz. Aber hat sich unsere Vorstellung von Protokollen geändert?
Eines der großen Probleme bei Yandex.Verticals waren die Protokolle - 18 TB pro Tag und 250.000 Protokolle pro Sekunde, alles wird in Dateien geschrieben. Protokolle sind heterogen, da es viele Sprachen gibt: Scala, Java, Python, Go. Dann werden sie von Fluent Bit gesammelt, in Kafka geschrieben, Handler arbeiten an einer Eisenmaschine, bauen aus Kafka zusammen und schreiben alles auf die Festplatte. Darüber hinaus ist dies die zweite Version der Protokolle.

Infolgedessen tritt ein langes Suchproblem auf. Diese Protokolle werden mit grep durchsucht. Bei einigen Diensten kann grep Stunden erreichen. Wenn Sie Probleme in der Produktion haben, werden Sie stundenlang nicht nach Ihren Protokollen suchen. Um das Problem zu lösen, hat Yandex beschlossen, ein eigenes Log Delivery Bike für die Suche zu schreiben. Was dabei herauskam, wird
Alexei Danilov (
danevge ) - dem Entwickler des Infrastrukturteams in Yandex.Verticals - mitteilen. Entwickelt, schreibt und unterstützt Auto.ru- und Yandex.Real Estate-Projekte.
Haftungsausschluss. Der Artikel spricht über moderne Entwicklung und ist für die Microservice-Architektur geeignet. Hier werden verschiedene Produkte vorgestellt - dies sind Werkzeuge, die in Yandex.Verticals verwendet werden. Unter anderen Bedingungen sind Analoga erfolgreicher möglich, erfüllen jedoch fast die gleichen Funktionen. Hinweis Der Artikel ist eine erweiterte Version von Alexey Danilovs Bericht „Protokolle werden nicht benötigt“ bei RIT ++ 2019 DevOps Conf, der stilistisch modifiziert und durch neues Material ergänzt wird. Die Videoaufzeichnung von Alexeys Rede finden Sie unter dem Link auf unserem YouTube-Kanal.
Das Yandex.Vertical-Team besteht aus 300 Mitarbeitern, von denen etwa 100 Entwickler sind. In der Entwicklung unterscheiden wir uns nicht von den meisten Unternehmen, die ihre eigenen Produktlösungen entwickeln. Microservices, jeder lebt in Docker, ein Monolith in PHP verstaubt in einer dunklen Ecke, wird über Hashicorp Nomad bereitgestellt und wir haben einen Zoo von Sprachen: Scala, Java, Go, Node.js, Python.
Eines der großen Infrastrukturprobleme in Yandex.Verticals sind Anwendungsprotokolle. Als wir uns diesem Problem ernsthaft näherten, verwendeten wir die dritte Version ihrer Sammlung und Verarbeitung. Vereinfacht funktioniert es so:
- Anwendungen, die in Dateien geschrieben wurden;
- Fluent Bit las Dateien und schickte sie Zeile für Zeile an Kafka Filebeat.
- Auf einer dedizierten Eisenmaschine gab es eine Anwendung, die das Kafka-Thema las und in Dateien auf der Festplatte schrieb.
In der heißen Jahreszeit hatten wir 18 TB Protokolle pro Tag oder 250.000 Zeilen pro Sekunde. Dies ist eine sehr große Menge, die die Arbeit mit diesen Daten erschwert. Die einzige Möglichkeit, dies zu analysieren, ist grep, da alles in Dateien gespeichert ist. Bei großen Anwendungen kann die Analyse Stunden dauern. Bei Problemen in der Produktion haben Sie diese Zeit nicht.
Fertige Lösungen passten nicht zu Preis, Ressourcen oder Geschwindigkeit. Sie konnten unseren Fluss nicht akzeptabel bewältigen. Es ist schwer, die Anzahl der Versuche, Elasticsearch zu kochen, überhaupt zu zählen. Ich nehme an, wir wissen nicht, wie man es kocht. Dies ist jedoch nicht das, was wir brauchen, wenn wir es als Aufbewahrungsort für Protokolle verwenden möchten, sind besondere Fähigkeiten (Fertigkeiten) erforderlich.
In dieser Situation haben wir beschlossen, ein eigenes System zum Sammeln und Analysieren von Protokollen zu implementieren.
Fahrrad
 Hinweis: Wenn das nächste Fahrrad nicht interessant ist, fahren Sie sofort mit dem Abschnitt "Typisierung" fort.
Hinweis: Wenn das nächste Fahrrad nicht interessant ist, fahren Sie sofort mit dem Abschnitt "Typisierung" fort.Formatieren
Wir verwenden mehrere PLs und lieben Microservices. Um mit den Protokollen arbeiten zu können, haben wir einheitlich unser eigenes JSON-Format erstellt. Es deckt den größten Teil des Bedarfs für die weitere Arbeit mit Protokollen ab.
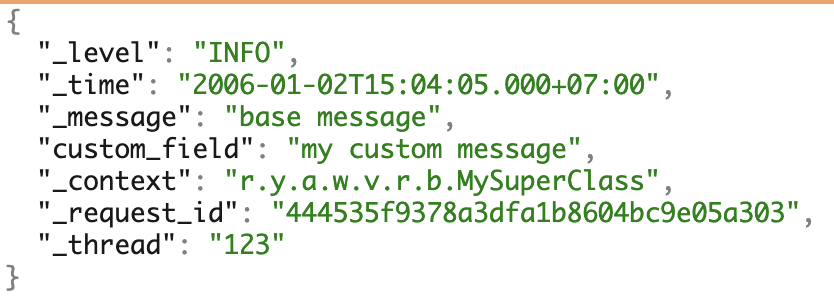 Ein Beispiel für Protokolle mit allen möglichen Feldern.
Ein Beispiel für Protokolle mit allen möglichen Feldern.Docker-Protokolltreiber
Um die Protokolle zu sammeln, haben wir unseren eigenen
Docker-Protokolltreiber geschrieben - eine Anwendung auf Go. Es wird auf spezielle Weise zusammengestellt, von Docker-Plugin-Befehlen bereitgestellt, in der Registrierung gespeichert und in einer einzelnen Instanz ausgeführt, in der Docker ausgeführt wird.
Da sich Probleme mit dem Protokolltreiber negativ auf die gesamte Arbeit auswirken können, haben wir versucht, eine minimale Implementierung zu schreiben. Unser Fahrer hört auf die Standardausgabe des Containers und leitet die Protokolle sofort an die Anwendung in der Nähe weiter. Es befasst sich bereits mit dem komplexeren Teil der Lieferung.
Die Probleme
Ich werde die Probleme beim Aktualisieren der Version des Docker-Protokolltreibers separat erwähnen.
 Screenshot von der internen Grafana.
Screenshot von der internen Grafana.Links ist das Verhältnis von installierten Versionen zu Maschinen. Jetzt sind drei Versionen auf der gesamten Hardware installiert - es gehen nirgendwo Autos verloren und es gibt keine unnötigen Installationen. Rechts ist die Anzahl der Container angegeben, die diese oder jene Version verwenden.
Der Docker-Treiber kann nicht sofort aktualisiert werden. Dazu müssten Sie alle Container und alle Dienste neu starten, was zu Problemen führen könnte. Um die neue Version zu installieren, warten wir nur darauf, dass sich alle Container selbst aktualisieren.
Allgemeines Schema
Betrachten Sie das allgemeine Schema eines neuen Systems zum Sammeln und Bereitstellen von Protokollen. Andere Details sind nicht so interessant.
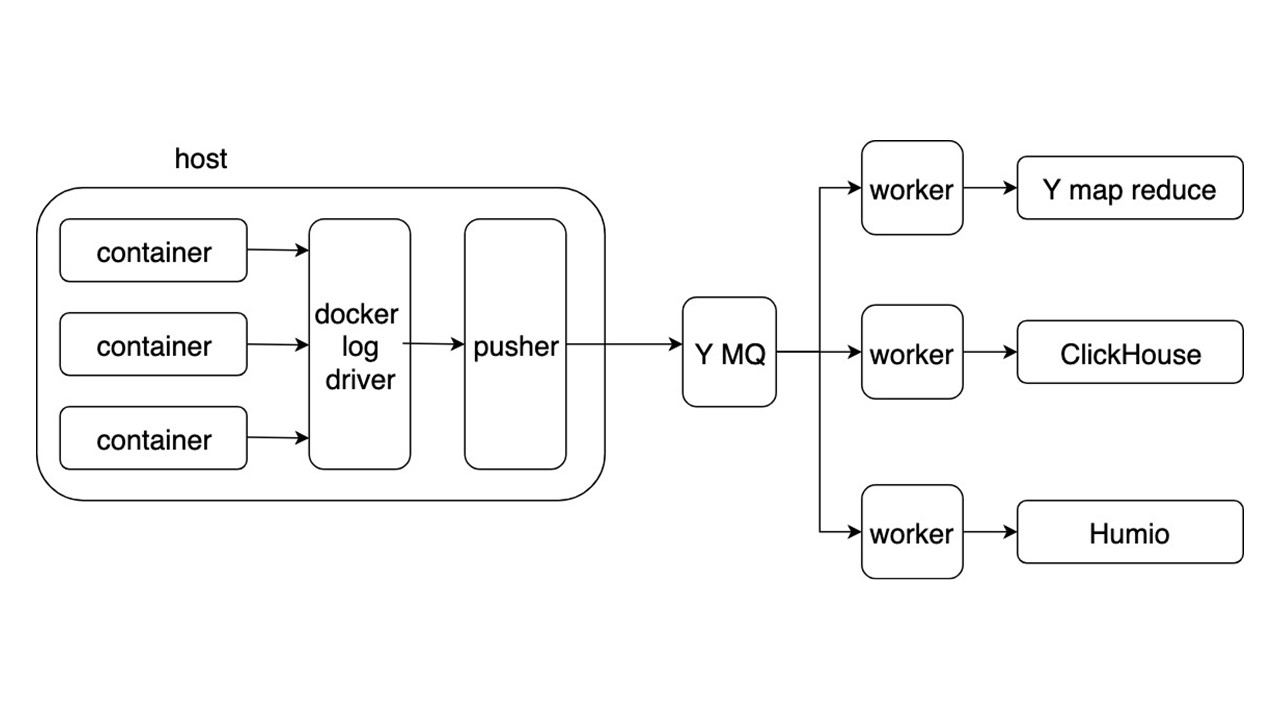
Anwendungen schreiben Protokolle im JSON-Format in stdout. Docker hört zu, wie Pipe vom Container geleitet wird, und leitet sie an den Docker-Treiber weiter. Der Docker-Treiber liest alles in Pusher und schmilzt es asynchron neu.
Drücker steht auf jedem Eisenauto. Er bereitet Protokolle vor, sättigt sie, dreht sie um und schiebt sie in die Yandex Message Queue. Der Protokolldatenstrom von MQ wird von drei Arten von Workern analysiert und in die Repositorys geschrieben.
Es gibt drei Repositorys zum Aufzeichnen von Protokollen.
- Yandex mapReduce zum Speichern und Analysieren von Protokollen über einen langen Zeitraum. Dies ist ein Analogon von Hadoop.
- ClickHouse zum Speichern von Protokollen am letzten Tag.
- Humio (als Experiment) zum Speichern von Protokollen für den letzten Tag.
Gewinn
Mit dem allgemeinen Format können Sie Protokolle auf dieselbe Weise schreiben und verarbeiten. Die Protokollerfassung erfolgt automatisch ohne Verwendung einer Festplatte, und die Zustellung erfolgt innerhalb weniger Sekunden. Tastensuche von 2 Sekunden bis 5 Sekunden. Lagerung und Abruf über einen langen Zeitraum.
Bei kleineren Volumina sollten Sie Alternativen in Betracht ziehen: Humio, Splunk und Elastic. Die letzten beiden haben offizielle Docker-Treiber. Wenn Sie in AWS leben, ist dies Amazon CloudWatch.
Amazon Cloudwatch
Amazon CloudWatch verarbeitet Metriken, Ereignisse und Protokolle. Er sucht nicht nach letzterem, gibt keine Supersuchelemente an und verarbeitet sie nicht in der üblichen Form. Amazon CloudWatch verarbeitet Protokolle, Analysen, Filter und Anzeigen in Diagrammen.
 Amazon CloudWatch konvertiert Protokolle in Metriken und Grafiken.
Amazon CloudWatch konvertiert Protokolle in Metriken und Grafiken.Was tun mit Protokollen?
Zurück zu unserem Fahrrad - befriedigt es alle Fälle? Nein, mit unserer Lösung können Sie die Protokolle finden, aber sie erfordern eine viel größere Heterogenität der Informationen und ihrer Typen. Protokolle werden in viel mehr Fällen verwendet.
Sobald Sie die Protokolle gesammelt haben, lautet der folgende Satz: „Lassen Sie uns etwas analysieren, irgendwie verarbeiten, irgendwo aufschreiben und in Diagrammen oder Dashboards anzeigen.“ Dies ist der Weg zur Hölle. Vor allem, wenn es sich um gängige Tools handelt.
Wenn Sie sich die Protokolle als ein bestimmtes Chaos- oder Ereignisprotokoll von Daten vorstellen, funktionieren sie nicht.
Dies wird ein großes Durcheinander von Informationen sein, die nicht verarbeitet werden können. Ein Spiel beginnt mit der Formalisierung von Protokollen: „Schreiben wir diese Zeilen in einem speziellen Format, damit sie später analysiert werden können!“ Das funktioniert auch nicht. Glauben Sie uns, wir haben es versucht.
Tippen
Wenn Sie die Protokolle in Typen aufteilen und separat verarbeiten, finden Sie Tools, die die Arbeit mit ihnen erleichtern. Arbeiten nicht mehr wie bei Protokollen, sondern wie bei nützlichen Daten - solche Arbeiten sind transparenter und bequemer. Einige Arten von Protokollen können vollständig weggeworfen werden.
Nur für den Fall
Diese Art von Protokollen "zu sein" ist mein Favorit. Wenn es unmöglich ist, klar zu beantworten, warum diese oder jene Zeile benötigt wird, dann sind sie es. Dieser Typ kann auch als "Protokolle für alle Fälle" bezeichnet werden.
// validate customer func Validate(customer Customer) { // ??? log.debug(“Validate customer %v”, customer) … log.Error(“Customer not valid %v. Reason: %s”, ...) …. }
Protokolle sind keine Kommentare, die gelöscht werden können. Dies ist Teil des Codes, der schwieriger zu ändern, zu warten und noch schwieriger zu löschen ist.
Im besten Fall kann ein solches Protokoll zu einem Debug oder Trace werden. Dieser Typ
überfrachtet den Code . Aufgrund der vorschnellen Protokollierung kann ich persönliche Daten, Passwörter und Cookies von Benutzern darin abrufen.
Der richtige Weg ist
, sie wegzuwerfen und zu vergessen . Aber dann stehen wir vor einem neuen Problem. Wie kann man die Situation mit einem Fehler analysieren?
Schwerwiegender / kritischer Fehler
Zunächst betrachten wir nur kritische Fehler. Dies sind Fehler, unter denen Benutzer und Entwickler leiden. Die erste - wenn sie den Vorgang nicht abschließen können. Die zweite - wenn Sie Korrekturen von Hand vornehmen müssen.
Warum passen Protokolle nicht?
Keine schnelle Antwort . Wenn das Entwicklungsteam von den Benutzern über den Support oder über Twitter von dem Fehler erfährt, ist es Zeit, etwas zu ändern.
Es gibt keinen Kontext . Eine separate Zeile des Fehlerprotokolls ist unbrauchbar. Wir müssen den Kontext Stück für Stück sammeln. Trotzdem reicht es möglicherweise nicht aus, da dies der Kontext des Prozesses ist, nicht der Fehler.
Es gibt kein großes Bild . Keine Antwort auf die Fragen:
- wie oft ein solcher Fehler auftritt;
- es trat auf den verbleibenden Replikaten des Dienstes auf;
- war es vorher?
Verwenden Sie zur Behebung dieser Probleme ein geeignetes Tool, z. B.
sentry.io . Sie können mit repräsentativen, vollständigen (kontextbezogenen) Fehlerinformationen mit anpassbaren
alerting rule .
Die Sentry-Website beschreibt die Unterschiede in den Protokollen zur Verwendung von sentry.io.
Kein kritischer Fehler
Wir haben schwerwiegende und kritische Fehler gemacht und jetzt sind sie in Sentry geschrieben. Es gab jedoch interne Fehler - verschiedene Bibliotheken oder Antworten von Drittanbieterdiensten.
Ein gutes Beispiel ist ein erfolgreicher Wiederholungsversuch. Angenommen, Dienst A hat sich an Dienst B gewandt, konnte jedoch aufgrund von Netzwerkproblemen keine Antwort erhalten. Nach dem Fehler wandte sich Service A erneut an Service B und erhielt eine gültige Antwort. Ist der Fehler beim ersten Anruf kritisch? Nein. In diesem Fall wurde der Vorgang erfolgreich abgeschlossen und der Benutzer konnte den Dienst nutzen.
Wenn solche Fehler für das Funktionieren des Dienstes nicht kritisch sind und den Benutzer nicht mit einer seltenen Wiederholung betreffen, handelt es sich überhaupt nicht um Fehler. Dies ist eine Verschlechterung des Dienstes, obwohl die Antwort an den Benutzer 50 ms später erfolgte. Diese Art von Protokoll bezieht sich auf Warnungen - Warnung.
Warnung
Warnungen sind Informationen über die Verschlechterung eines Dienstes.
Hier sehen wir die gleichen Probleme, die mit kritischen Fehlern verbunden sind, jedoch mit Vorbehalt. Die Reaktion auf ein einzelnes Ereignis ist nicht wichtig - ihre Menge im Laufe der Zeit ist wichtig.
Stellen Sie sich ein Beispiel vor, in dem ein Dienst keinen Cache-Eintrag abrufen kann und auf den Kühlraum zugreift. Wenn dies einmal pro Minute geschieht, kann dies für den normalen Betrieb des Dienstes verwendet werden.
Seltene Emissionen sind nicht wichtig .
Gleichzeitig benötigen Sie ein Tool, um das Gesamtbild zu betrachten. Sie benötigen eine
Echtzeitanalyse . Um Änderungen über einen langen Zeitraum zu verfolgen, wäre es auch schön, eine
retrospektive Analyse durchzuführen . Eine Verschlechterung über einem bestimmten Niveau (Schwellenwerte) kann sich nachteilig auf die Benutzer auswirken. Sie benötigen eine
Reaktion mit starker Verschlechterung .
Wir brauchen nicht die mit Warnung gekennzeichneten Protokolle, sondern die Verschlechterungsmetriken.
Das beliebteste Tool zum Sammeln von Metriken ist Prometheus, und Sie können Grafana zur Visualisierung verwenden. Wenn Sie einen großen Kontext benötigen (der gleiche wie der Fehler), reicht derselbe Sentry aus, jedoch mit deaktivierten Warnungen. In den meisten Fällen wird jedoch genügend Kontext vorhanden sein. Es wird für Grafiken verwendet - Prometheus-Beschriftungen.
Beispiele.
Im bedingten
user_service drei Ereignisse aufgetreten. Sie wirken sich auf den Betrieb des Dienstes aus: Eine lange Anforderung an die Datenbank, wiederholter Zugriff auf die Dienst-API
service_b und keine Benutzerrechte im Cache. Diagramme und Warnungen werden aufgrund des Kontexts für die Entwickler des Dienstes als wichtig konfiguriert.
Rückverfolgung
Dies ist der erste Schritt, wenn wir den Pfad auswählen, in dem Sie die Protokolle analysieren müssen. Diese Informationen in den Protokollen sind für sich genommen nutzlos, da Sie Anrufketten erstellen, die Daten in den Anforderungen, Fehler in den Anrufketten, Antwortzeiten und die Anzahl der RPS anzeigen müssen.
Es gibt großartige Werkzeuge zum Aufspüren - Jaeger oder Zipkin. Ich empfehle die Verwendung von OpenTracing, das beide unterstützen.
Sie können die Ablaufverfolgung aus drei Quellen erfassen.
- Wenn Sie Shared Balancer verwenden , analysieren Sie die Protokolle von ihnen und senden Sie sie an Jaeger.
- Services selbst , wenn sie Adressen über Service Discovery erhalten und direkt gehen. In diesem Fall wird der Trace von den Diensten direkt an Jaeger gesendet.
- Smart Service Mesh . Er weiß, wie man eine Spur sammelt und sendet, zum Beispiel Istio.
Erste Informationen
Diese Informationen beziehen sich auf API-Dienstaufrufe, Cron-Start, Datenbankabfragen oder Aufrufe anderer Dienste.
{ "_message": "Request: ...; request_id: ...,... ", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcHandler", "_tread": "785534" }
Diese Informationen gehören zum Block "Nur für den Fall", sind jedoch getrennt, da sie häufiger vorkommen. Diese Informationen werden benötigt, um den Fehler zu analysieren, und
Sie können ihn wegwerfen .
Wenn Informationen über Aufrufe interner Methoden von entscheidender Bedeutung sind und Sie auch im gesammelten Kontext im Fehlerfall nicht darauf verzichten können, lohnt es sich, Methodenaufrufe als Trace zu instrumentieren.
Ausführungszeit
Diese Informationen beziehen sich auf die Ausführungszeit von Methoden, APIs, Datenbankabfragen oder anderen Diensten.
{ "_message": "Get customer 12ms", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcCustomerRepository", "_tread": "785534" }
Die Protokolle enthalten keinen Wert, da Sie diese Informationen analysieren, in Diagrammen anzeigen und Schwellenwerte konfigurieren müssen. Diese Art von Protokollen muss beispielsweise in Prometheus durch
Metriken ersetzt werden.
Geschäftsinformationen
Diese Informationen werden für Geschäftsanalysen, Kundenverhaltensanalysen und Finanzberechnungen benötigt. An dieser Stelle haben wir in der Vergangenheit den umgekehrten Ansatz verwendet - analysierte Protokolle. Dies ist jedoch ein gutes Beispiel dafür, was die Anwendungsprotokolle degenerieren können, wenn Sie auf diese Weise mit ihnen arbeiten.
Für Protokolle mit Geschäftsdaten wurden Vereinbarungen mit festen Feldern im TSKV-Format getroffen, die für die Analyse erforderlich sind. Anwendungen haben Geschäftsprotokolle in eine dedizierte Datei geschrieben. Dann wurden die Protokolle gelesen und Zeile für Zeile an MQ gesendet, und eine separate Anwendung verarbeitete sie und schrieb sie in die Datenbank. Dies ist ein Beispiel dafür, was aus einer Analyse wird.
Es wird nicht funktionieren, den gesamten Protokollstrom zu analysieren, in der Hoffnung, dass die Daten konvergieren.
Konventionen, Formate, Regeln und Zuverlässigkeitsanforderungen entstehen. Dies sieht bereits ein wenig wie die Anwendungsprotokolle aus. In diesem Fall wird das Protokoll zur Datenübermittlungswarteschlange mit allen sich daraus ergebenden Anforderungen für MQ. Auffällig ist, dass Middleware in Form eines Logs hier überflüssig ist.
Eine gute Lösung besteht darin, diese Daten direkt an MQ zu senden. Bereits dort werden sie verarbeitet, im entsprechenden Speicher gespeichert und vom Analyseteam verwendet. Für die Anzeige verwenden wir beispielsweise Tableau.
Leistung
Diese Art von Protokoll wird selten in Anwendungsprotokollen gefunden und häufiger als Metrik erfasst. Separat füge ich hinzu, dass es ausreicht, die Prometheus-Bibliothek zu verwenden, um die sprachspezifischen Grundmetriken zu erfassen. Sie wird standardmäßig alles sammeln, was sie erreicht. Die Kosten für das Hinzufügen dieser Metriken sind gering.

Tippergebnis
Nachdem wir die Protokolle nach Typ sortiert haben, können wir leistungsfähigere Tools für die Arbeit mit ihnen auswählen. Es gibt keine komplexen Systeme oder Weltraumtechnologien wie Amazon, es gibt nichts, was morgen nicht angesprochen werden kann. Sie haben wahrscheinlich bereits einige dieser Systeme oder Analoga: Sentry verstaubt irgendwo, Prometheus arbeitet irgendwo.

Das Problem liegt nicht in der Technologie, sondern in einer kognitiven Falle, wenn wir Protokollen als Mittel zur zuverlässigen Darstellung des Zustands unseres Systems vertrauen. Dies ist nicht so, Protokolle sind eine Reihe von chaotischen Ereignissen.
Es gibt eine Ausnahme - Debug-Protokolle, die in seltenen Fällen verwendet werden können.
Debug-Protokoll
Debug-Protokolle sollten detaillierte Informationen sein. Sie sollten nicht duplizieren, was bereits an die oben beschriebenen Systeme gesendet wurde. Dieser Typ dient zum Parsen von Sonderfällen. Beispielsweise tritt in der Produktion ein unverständlicher Fehler auf, und im Moment ist anhand von Metriken nicht klar, was passiert.
Aktivieren Sie Debug-Protokolle im laufenden Betrieb, ohne den Dienst neu zu starten . Da es sich um mehrere Dienste handelt, wird es nicht viele davon geben. Eine ausgefeilte Infrastruktur ist nicht erforderlich. Genug ELK-Stapel ohne komplizierte "Vorbereitung". Es ist auch sinnvoll, Sentry eine Warnung mit allen erforderlichen Kontexten hinzuzufügen.
Debug-Protokolle können für die Entwicklung verwendet werden . Sie werden jedoch perfekt durch das Debuggen ersetzt.
Zusammenfassend
Wir haben unser Fahrradprotokoll für die Suche geschrieben . Wir haben die Kunden des Dienstes nicht zufrieden gestellt - sie alle kommen zu uns, um sie irgendwo zu analysieren, zu sammeln und zu aggregieren. Dies kann vermieden werden - komplexe Protokollverarbeitungssysteme werden nicht benötigt.
Rohprotokolle sind nutzlos, können jedoch in nützliche Metriken umgewandelt werden.
Es reicht aus, eine Infrastruktur für die Bereitstellung nützlicher Metriken und Daten rund um Services zu erstellen. Infolgedessen werden nützliche Metriken angezeigt, die über Dienste sprechen und alles, was mit ihnen passiert, transparent anzeigen.
Fehler müssen den Kontext des Fehlers selbst enthalten.
Dies wird helfen, damit umzugehen und es sofort zu beheben.
Fehler und Verschlechterungen sollten zu Maßnahmen führen , damit Entwickler sofort von Problemen erfahren und diese beheben können, noch bevor verärgerte Benutzeranfragen gestellt werden.
Mit den richtigen Tools wird die Arbeit mit Ihren Diensten angenehmer und transparenter . Debug hat einen Platz, an dem man sein muss, aber man muss streng damit umgehen.
Auf der HighLoad ++ 2019 im November wird es einen DevOps-Bereich geben - 13 Berichte über Lasten in AWS, ein Überwachungssystem in Lamoda, Förderer für die Modelllieferung, Leben ohne Kubernetes und vieles mehr. Die vollständige Liste der Themen und Abstracts finden Sie auf der separaten Seite „ Berichte “. Und wir werden uns im Frühjahr auf der DevOpsConf treffen - abonnieren Sie den Newsletter und teilen Sie uns mit, wann wir Datum und Ort festlegen.