Im November 2018 wurde in Litauen eine Abteilung für Informationsunterstützung eingerichtet, in der
Andrei Yumashev die Leitung erhielt. Im vergangenen Jahr hilft die Abteilung dem Unternehmen bei der Arbeit und Entwicklung und hält die gesamte Infrastruktur unter Kontrolle. Das war aber nicht immer der Fall. Vor dem Aufbau der Arbeit sah sich Andrei mit Ruinen konfrontiert: halbtoten Nagios, bedingt lebenden Kakteen und komatösen Puppen, 120-seitigem toten Wiki, inkohärenten Aufgabentabellen und Eisenlisten, veralteter Architektur, 340 inaktiven Kernen, 2 TB RAM und 17 TB Speicherplatz, der aus irgendeinem Grund nicht in den Inventartabellen erfasst wurde. Pläne, die nicht funktionieren, Fristen, die brechen, Arbeitsumgebung und Tools, die nicht vorhanden sind - all dies erwartete Andrei in einem neuen Projekt.

Auf der
DevOpsConf 2019 machte Andrei einen Bericht, in dem er anhand von Live-Beispielen zeigte, was es wert ist und was nicht, wenn Sie ein Projekt betreten, das Sie nicht gesehen oder schlecht kennen. Unter dem Schnitt befindet sich eine aktualisierte Version der Geschichte - wie man die Bandbreite der Probleme richtig analysiert und einen Aktivitätsplan erstellt, wie man den KPI richtig berechnet und wann man rechtzeitig anhält.
Andrey Yumashev ist Inhaber seiner eigenen Entwicklungsunternehmen in verschiedenen Bereichen (online und offline), Berater für die Konstruktion von Prozessen und Leiter der Abteilung für Informationsunterstützung bei LiteRes.
Ein bisschen über LiteRes. Dies ist der größte Anbieter von elektronischen und Hörbüchern in Russland, ein Verlag und eine Reihe von Partnerschaftsprojekten. Dies sind Hunderttausende von Perl-Zeilen, mehrere Datenbankcluster und Repositorys. Dies sind 2 GB ausgehender Datenverkehr pro Sekunde, Hunderttausende eindeutiger Anforderungen pro Tag, mehrere Racks in verschiedenen Rechenzentren und mehr als 100 Server. Alles in allem ist dies nicht nur ein E-Bookstore.
Erste Schritte
Ich habe früher stückweise in LiteRes gearbeitet. Das Unternehmen übt die Entwicklung von Mitarbeitern mit der Registrierung von Remote-Mitarbeitern im Staat aus.
Das Aufgabenerfüllungssystem in Litern arbeitet nach dem Prinzip einer „Auktion“. Im internen Task-Tracker beschreiben Manager und Architekten Aufgaben für interne Projekte und bewerten diese in lokaler Währung. Die Währung ist "Pilze, Gras und Baum".
Dann beginnt die "einfache Auktion" - jeder Entwickler kann die Aufgabe übernehmen oder verhandeln. Gut gemacht - du wirst bezahlt. Ich habe überhaupt nicht gearbeitet - du verstehst es nicht. Auf spielerische Weise sind Menschen daran interessiert, Aufgaben zu erledigen. Weitere Informationen zu diesem System finden Sie in der
Präsentation von Dmitry Gribov.
 Arbeite für die Pilze.
Arbeite für die Pilze.Das System passte zu mir - ich unterstützte die Perl-Programmiererfahrung, arbeitete, wenn es zweckmäßig war, und verbrachte nicht zu viel Zeit damit. In diesem Modus verbrachte ich einige Jahre bis November letzten Jahres und dachte, ich verstehe die Struktur des Ökosystems.
Ich habe mich geirrt
Ich wurde in das Unternehmen eingeladen und informiert, dass meine Dienste als Perl-Entwickler nicht benötigt wurden, und mir wurde angeboten, eine neue Abteilung zu leiten. Im November 2018 wurde ich Leiter der Informationsabteilung.
Vor mir lagen Freiräume: mehrere Gestelle mit Eisen in mehreren Rechenzentren in Moskau, veraltete Architektur, ausländische Ressourcen und das fast vollständige Fehlen relevanter Dokumentation für alles. Die Einführung klang ungefähr so: "Nun ist dies Ihr Erbe, verbessern Sie sich, brechen Sie nicht und unterstützen Sie." Es gab eine vorgefertigte Liste von Aufgaben und groben Plänen für das kommende Jahr. Es war notwendig, all dies zu verstehen und in eine menschliche Form zu bringen.
Ich hatte das Gefühl, in den Abgrund zu schauen, und der Abgrund sah mich an.
Die Erfahrung der letzten Jahre hat mir sehr geholfen, als ich eine klare Position bei der Arbeit mit einem Fremden oder unverständlich entwickelte. Zuallererst ist dies eine gründliche Studie und ein minimaler Aktionsplan. Hier habe ich angefangen.
Sauberkeit ist der Schlüssel zur Gesundheit
Ordnung ist in erster Linie.
Für den ersten Monat gelang es zu finden:
- verstreute Google Sheets mit aktuellen Aufgaben und einer Prise nützlicher Informationen;
- verstreute Dokumente: Wörter, Texte, Fetzen des alten Wikis 120 Seiten;
- halb toter alter Nagios;
- bedingte Live-Überwachung von Kakteen;
- sehr alte Marionette mit seltenen Lebenszeichen.
Alle diese Ruinen sammelten auch 400 Metriken.
 Die Ruinen, die ich im ersten Monat gefunden habe.
Die Ruinen, die ich im ersten Monat gefunden habe.Ich habe ein bisschen Spaß gemacht, alles fließend gelesen und mich an die Trello-Prozesse gehalten. Er übertrug die aktuellen Aufgaben seiner Kollegen auf ihn und begann zu träumen - einen Plan für das Quartal und das Jahr zu schreiben.
Erster Fehler
Keine Pläne, bis Sie die Gegend erkunden.
Der Plan strahlte vor Hitze und Gesundheit, berücksichtigte jedoch nicht die Realität. Es war schön und einfach: Überwachung implementieren, Protokolle analysieren und Bereitstellung auf CI / CD übertragen. Irgendwann am Ende gab es eine träge „Analyse der Schwächen des Projekts“. Klassische erste Schritte.
Ich habe die Hauptsache vergessen. Meine erste Priorität ist nicht die Implementierung von Tools für die Implementierung von Tools, sondern die Gewährleistung der Lebensfähigkeit und Stabilität des gesamten Dienstes.
Während ich den Plan schrieb und von den Fragen meiner Kollegen gequält wurde, kamen die ersten Probleme. Einer der Knoten eines der Cluster-Cluster hatte nicht mehr genügend Speicherplatz, und die SSD als Ganzes endete auf dem anderen Knoten desselben Clusters. Ich kaufte dringend neue größere Festplatten und unsere Abteilung sammelte schnell Erfahrung beim Ersetzen dieser Festplatten, indem sie das System von Festplatte zu Festplatte kopierte. Nach dem Ersetzen der Festplatten haben wir den Cluster über SST von Grund auf neu erstellt. Der Cluster basiert auf Percona und Galera, und solche Unterhaltung geht ihm nicht umsonst.
Während ich zwischen Rechenzentren unterwegs war, entstanden die
ersten Zweifel an dem Plan.
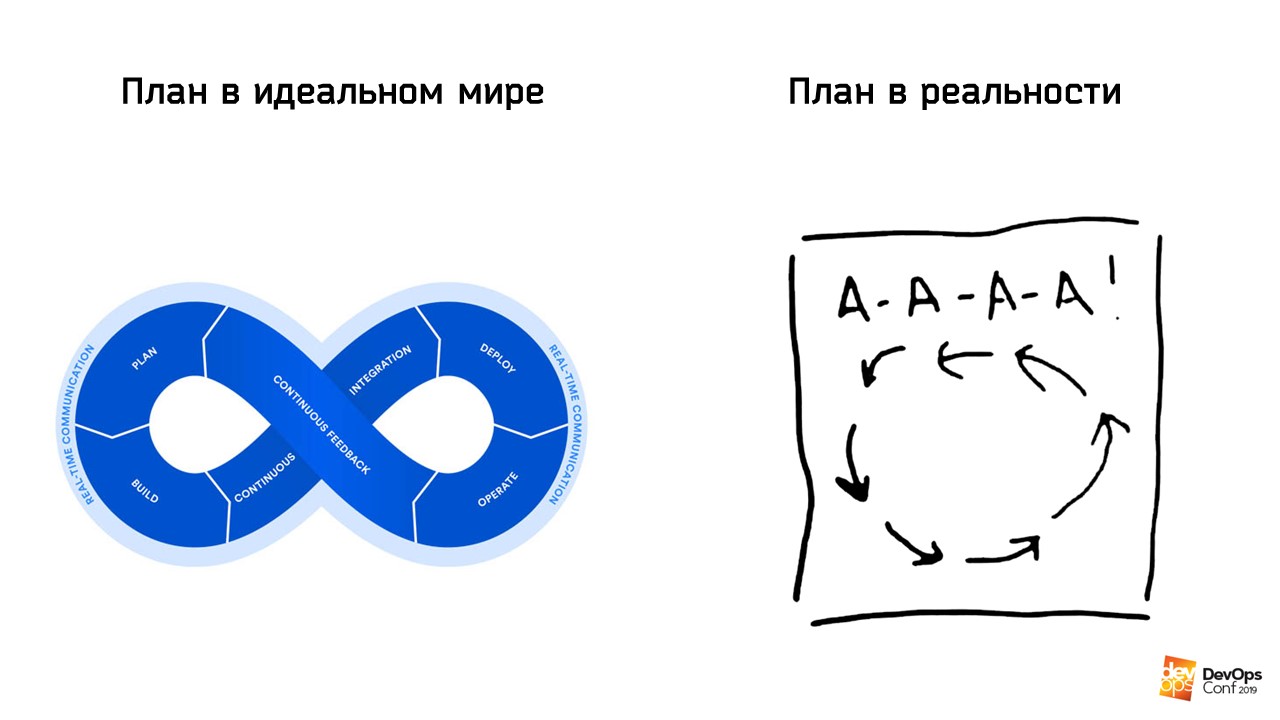 Ahhhhhh!
Ahhhhhh!Gleichzeitig war die Intensität der Schwarzarbeit so hoch, dass ich nicht einmal daran dachte, eine vollständige Krankengeschichte zu sammeln, sondern einfach ein paar Fotos für weitere Studien machte.
Parallel dazu erschien eine weitere Einführung. In Litern gibt es Audioversionen von Büchern. Damit der Hörer die Aufnahme nicht jedes Mal zurückspult, haben wir einen Mechanismus, der den Moment des Stopps verfolgt. Beim nächsten Hören wird die Audioversion aus dem gewünschten Bereich wiedergegeben. Für diese Aufgabe wurden etwa 500 Kerne schneller gefunden, ein Terabyte RAM und ein wenig Analyse in Java.
Ich begann, Azure, Google, DigitalOcean und alles andere, was Droplet-Lösungen bieten, zu informieren. Containerisierung bittet, warum nicht fröhlich umsetzen? Darüber hinaus gab es im "großen" Plan einen separaten Punkt.
Ein Monat in Korrespondenz und Ausschreibung ist vergangen, alles wurde zu den Aufgaben in Trello hinzugefügt, von denen ich einen bedeutenden Teil generiert habe, aber das Ergebnis hat sich nicht weiterentwickelt. Ich fragte mich, ob ich dorthin gehen würde. Vor mir hat alles irgendwie funktioniert und wird nicht aufhören, egal wie viel leere Aktivität ich zeige. Ich setzte mich sorgfältig hin, um das Inventar zu studieren, das ich Stück für Stück sammeln konnte. Dann stand er auf und ging in die zweite Runde der Rechenzentren.
Der zweite ruhige Besuch in den Rechenzentren brachte alles an seinen Platz. Als ich das alles nicht in der Konsole, nicht in Excel, sondern lebendig sah, änderte sich mein Bewusstsein für die Realität radikal. Mir wurde klar, dass ich überhaupt nicht mit dem beschäftigt bin, was ich sollte. Denn zuerst musst du verstehen, womit ich arbeite.
Bis ich verstehe, womit ich arbeite, sind alle Pläne Zeitverschwendung.
Ich studierte die Racks, verglich die Realität mit Listen, nahm Änderungen vor und stieß auf eine Halbeinheit mit 20 Klingen. Von 20 arbeiteten nur 4. Ich ruckte mit den Klingen und stellte fest, dass wir keine Tröpfchen für die Lösung brauchten. Weil ich 340 ruhende Kerne, 2 Terabyte RAM und 17 Terabyte Speicherplatz gefunden habe! Dies sind alte Backends, alte Knoten von Clustern, die einfach nicht mehr verwendet wurden, und die Zeit hat die Erinnerung an ihre Existenz gelöscht. Ich habe Kubernetes auf diese Klingen gerollt und eine wichtige Aufgabe erledigt.
Erste Fehlerausgabe
Analysieren und studieren. Ohne eine vorläufige Analyse der Situation fährt der Zug nicht.
Dank einer nachdenklichen Reise zu den Feldern hatte ich bereits einen ziemlich relevanten Plan für die Ausrüstung und die Gesamtarchitektur des Systems in der Hand. Auf dem Hof war Januar. Ich verbrachte zwei Monate damit, von denen ich die Hälfte nur hin und her schoss. Ich wusste nicht, welche Art von Feuer zuerst gelöscht werden sollte, welches Problem zuerst gelöst werden sollte - die Routine mit Unterstützung ging nirgendwo hin.
Parallel dazu habe ich drei Regeln abgeleitet. Dies sind die Folgen des ersten Fehlers.
 Drei Folgerungen.
Drei Folgerungen.Zweiter Plan
Ich habe sekundäre Aufgaben aus dem Vordergrund geworfen - Protokollanalyse und CI / CD-Implementierung. Im Ausmaß einer allgemeinen Katastrophe sind diese kleinen Dinge nicht wichtig. Liter hat jahrelang gearbeitet und eine eigene Logik für die Arbeit mit Protokollen entwickelt und einen selbstgemachten rollenden Dämon erworben. Ich habe in den fünften Plan hineingeschoben, was funktionierte und keine Intervention erforderte.
Der zweite Plan sah ungefähr so aus.
Beschäftige dich mit der Überwachung . In seiner jetzigen Form spiegelte es nicht mindestens ein Drittel der Probleme wider, obwohl es funktionierte.
Beschreiben Sie die allgemeine Logik der gesamten Liter . Servernamen sind großartig, aber Schlüsselpakete sind ein wichtiges Wissen: Was, Wo, Wo, Warum und Warum. Der vorherige Fehler machte deutlich, dass ohne dies in keiner Weise.
Skalieren . Fast die letzten freien Ressourcen nahmen Kubernetes. Nach minimalen Schätzungen sollte er den gesamten Arbeitspool in sechs Monaten fertigstellen.
Inventar und Zustand der Ausrüstung . Als Teil der Reise habe ich buchstäblich ein Web von einer Reihe von Servern gesäubert, die Angst vor ihren Tags hatten - "Backup", "Abonnieren", "BGP". Wieder Scheiben, fallende Scheiben.
Anleitungen an die Realität anpassen . Die meisten Anweisungen sind veraltet oder unvollständig.
Die ersten sechs Monate vergingen unbemerkt beim Umsatz, beim Kauf von Ausrüstung und bei Problemen, und ich etablierte mich schließlich im zweiten Fehler.
Zweiter Fehler
Unterschätzen Sie nicht.
Jeder Begriff, der mir in den Sinn kommt, wird unterschätzt . Natürlich können Sie schnell von dem Projekt profitieren. Um die Rendite zu maximieren, multiplizieren Sie die geplante Zeit
mindestens zweimal . Besonders bei einem komplexen und hoch belasteten Projekt, dessen Verkehr um mehr als 100% pro Jahr stetig wächst.
Warum mindestens zweimal? Wenn das Projekt instabil und nicht erforscht ist, sollten Sie darauf vorbereitet sein, dass jede Aktivität zu anderen Aktivitäten an benachbarten Orten führt. Es scheint, dass das Ersetzen von Festplatten - was ist einfacher? Das Verfahren ist einfach, bis Sie auf einen Kauf stoßen, dann die Zeit für ausfallzeitspezifische Knoten planen und nach dem Ersetzen einer Festplatte warten. Ich schätzte diese einfache Operation eine Woche. Am Ende dauerte es zweieinhalb Wochen - selbst mit einem einfachen Beschaffungsschema.
Ein weiteres Beispiel ist der Kauf und die Installation neuer Geräte. Kaufen und bleiben, was ist so schwer? Ich habe nicht mehr als einen Monat dafür gebraucht, ohne die Lieferzeit zu berücksichtigen. Tatsächlich steht immer noch eines der drei Chassis vor meinem Schreibtisch. Dies liegt daran, dass die Ausrüstung einfach nicht genügend Platz hatte - wir haben den Platz in den Löchern zwischen der aktuellen Installation berechnet. Als wir in einem der Rechenzentren ankamen, um das Rack zu erschüttern, stellten wir plötzlich fest, dass die beiden Server „unantastbar“ waren. Der erste ist der Host, und es ist einfach nicht sicher, ihn zu berühren. Der zweite ist ein Korb mit 16 Festplatten, der heruntergefahren wird und mit einem Haufen Datenhaufen behaftet ist. Die Strohhalme wurden nicht gelegt, die Analyse wurde nicht durchgeführt, und es ist gut, dass sie zwei von drei kleben konnten.
Wenn es so aussieht, als ob alles einfach sein wird, werden Sie bald Probleme haben . Diese Installation warf eine neue Frage auf: Wenn mit dem Ort alles so schlecht ist, wie werden wir dann expandieren? Eine kleine Aufgabe brachte jetzt einen riesigen Schweiß hervor. Im Jahr 2020 laut Plan die Übertragung eines Rechenzentrums in ein anderes und die Erweiterung des Restes durch Racks. Dies bedeutet eine Migration innerhalb des Rechenzentrums zwischen den Modulen. Die Migration wurde durch die Umstrukturierung des Netzwerks und dessen Übertragung auf 10G ergänzt.
Unterschätzen Sie nicht das Timing, die Eintrittsschwelle und die Konsequenzen.
Grundbegriffe
Natürlich wird das Wesen von Fehlern bereits im Wiki als Grundkonzept beschrieben.
Jeder bürokratische Prozess dauert mindestens einen Monat . Dies gilt für die Beschaffung, den Abschluss neuer Bedingungen mit einem Rechenzentrum oder anderen Auftragnehmern - für alles. Nehmen Sie es als Tatsache.
Nach Vertragsschluss und Zahlung dauert jede Lieferung mindestens eineinhalb Wochen , von den Festplatten bis zu den Verarbeitern. Erfahren Sie, wie Sie mit Lieferanten über Vorliefertermine verhandeln. Beispielsweise werden Datenträger jetzt bis zur Zahlung und sogar vor der Genehmigung des Antrags in kleinen Mengen an uns versendet.
Obwohl es kein klares Verständnis der Implementierung gibt, bleibt jeder Plan, etwas zu implementieren, ein Plan. Je kürzer die Schritte, desto besser.
Um beispielsweise von MySQL zu ClickHouse zu wechseln, sieht ein großer Schritt folgendermaßen aus: "Lassen Sie uns einen Server füllen, dann ein Ticket für die Wiedereingliederung ziehen und fliegen!" Tatsächlich führte eine detaillierte Untersuchung des Problems zu neuen Schritten: zusätzlicher Kauf von Geräten, z. B. Prozessoren und Festplatten, detaillierte Tickets zum Ändern der Logik des Benutzerverhaltens-Trackers, Aufrechterhaltung der umgekehrten Integration, Warteschlangenserver und viele andere.
Je detaillierter der Plan ist, desto besser. Mit einem breiten Pinselstrich zu schreiben ist eine Garantie für 100% Fehler in der Frist.
Setzen Sie jeden Plan maximaler Kritik aus und erwarten Sie ein maximales Risiko . Stellen Sie sicher, dass Sie den Plan aus geschäftlicher Sicht betrachten - welchen Gewinn jeder Schritt bringt.
Wir mussten obligatorische Implementierungen durchführen: Überwachung, Ansible, aber wir haben die Geschäftskomponente nicht vergessen.
- Durch Ändern der Netzwerkarchitektur können wir zusätzlichen Datenverkehr akzeptieren und viele aktuelle Probleme lösen.
- Durch Ändern der Art der Speicherung von Inhalten reduzieren wir die Anzahl der Fehler bei der Rückgabe von Büchern und beschleunigen die Arbeit mit Daten.
- Verschieben Sie das Backend in die Cloud - skalieren Sie die Last während Marketingkampagnen sofort.
- Die Übersetzung von Tracking in ClickHouse bietet Analysten die Möglichkeit, die Bedürfnisse unserer geliebten Leser und Zuhörer besser zu verstehen.
Der beste Weg, um mit einer Situation umzugehen, in der Sie sich mit dem Thema nicht auskennen, besteht darin, sich an Spezialisten zu wenden, nicht an einen Stapelüberlauf . Sprachkontakt löst das Problem um ein Vielfaches schneller als lange Korrespondenz oder das Lesen von Dokumentationen.
Sechs Monate später
Trotz der Tatsache, dass die Grundaufgaben, auf die ich mich zu Beginn konzentrierte, dank Recherchen und Korrekturen immer noch ins Schleudern gerieten, erschien etwas Gutes auf meinen Händen.
Selbstgeschriebenes Tool zur Bestandsaufnahme von Netzwerken und Adressen. Er tippte regelmäßig auf alle unsere Subnetze und überprüfte zusätzlich die Daten mit der BIND-Konfiguration. Dies machte es einfach und schnell, neue Dienste in Betrieb zu nehmen und die tatsächliche Last der Netzwerkpools zu verstehen. Ich wollte wirklich keine Zeit damit verbringen, aber ich konnte keine fertige Alternative finden, und es dauerte viel Zeit, eine Adresse zu finden, die einer neuen Ressource zugewiesen werden konnte. Während des Schreibens des Tools wurde der erste Entwurf des Plans im Netzwerk angezeigt.
Puppe ist nicht mehr so tot und verwirrt . Ich war mit einer Schlussfolgerung aus Fehler Nummer eins bewaffnet und habe nicht einmal versucht, zu Ansible zu wechseln, was für mich angenehmer ist.
Mehr oder weniger manipulierte Nagios . Ich habe es vom Büro in das Rechenzentrum verlegt und an drei Stellen verteilt. Es war viel schneller und billiger als die Implementierung von Zabbix. Wir haben ein Loch mit Warnungen geschlossen, die zeitlich und ereignismäßig falsch sind, eine einfache Neukonfiguration der Regeln und die Einführung zusätzlicher Steuerknoten.
Grundlegendes zur Wartung der verwendeten Datenbankcluster.
Stark geschwollenes Wiki . Sie "wurde fett" durch Kommentare und Anweisungen zum Arbeiten mit Umgebungen.
Drei HP-Chassis , die wir für die zukünftige Installation gekauft haben.
Den Weg zum Rest des Jahres 2019 klarer
verstehen .
Recyceltes Ökosystem für Abteilungsarbeiten.
In all diesen sechs Monaten habe ich fast alleine gearbeitet. Die Mitarbeiter, die geerbt haben, waren mehr Systemadministratoren. Sie waren nicht wirklich bestrebt, sich mit der Essenz von DevOps zu befassen.
Mit großen Schwierigkeiten fand ich zwei Spezialisten im Team - Junior und Middle. Ich habe die maximale Menge an Wissen, Aussehen und Passwörtern von aktuellen Administratoren gesammelt und mich schweren Herzens von ihnen getrennt.
Arbeitssystem, Umgebung und Werkzeuge
Ich werde Ihnen sagen, wie wichtig es ist, ein funktionierendes Ökosystem und eine funktionierende Umwelt einzuführen. Ich habe Trello bereits erwähnt, aber nicht gesagt, warum und warum ich es implementiert habe. Ohne die Festlegung von Zielen und strukturierten Daten wird keine Arbeit erstellt. Dies wird teilweise durch den ersten Fehler belegt - sammeln Sie alles, was ist.
Nimm alles, gib nichts.
Der Prozess ist der Motor des Fortschritts . Daher habe ich die ganze Zeit an dem System gearbeitet, trotz der Behinderung von Forschung und Arbeitsabläufen. Dank des Systems stellte ich sechs Monate später die Dampflokomotive der Abteilung auf stabile Schienen.
Die Einführung unterstützender Tools und ein kurzer Kurs zu deren Verwendung sparen Ihnen und Ihren Kollegen viel Zeit. Vor allem, wenn Sie selbst an der Spitze das Management verstehen und ein wenig in der Lage sind, Ordnung auf dem Desktop und im Leben aufrechtzuerhalten.
Wir erschweren die Werkzeuge nicht, wir gehen vom Einfachen aus und führen das Notwendige ein . Anfang des Jahres dachte ich, welcher Task-Tracker zu uns passen würde. Jira und Redmine sofort entlassen - zu viel Kontrolle. Wir würden Zeit damit verbringen, die Formulare auszufüllen, keine Aufgaben. Google Sheets - Ich denke, es lohnt sich nicht zu erklären, warum nicht.
Trello war perfekt . Ein paar einfache Spalten: "Backlog" - in dem sich alle festgestellten Fehler oder Aufgaben für die Zukunft summieren, "Bis zum Abschluss" - die wichtigsten zu erledigenden Aufgaben und "Fertig stellen". Wenig später gab es fünf Spalten: "Backlog", "Pause", "Sprint", "Finish" und "Study".
In der "Pause" trugen Dinge, die im Sprintprozess an Relevanz verloren haben. In „Lernen“ - Aufgaben, die Forschung erfordern und erst verloren gehen sollten, wenn Wissen verstanden und in das Wiki übertragen wurde. Der Sprint ist ein Beweis dafür, dass wir auf das Sprint-System umgestellt haben. — 2 . , .
.
— , Trello. . , , . 2-3 , . , .
. — Puppet, Nagios, DNS — SVN GitLab. Jenkins. DNS , Puppet - . , 1Password. .
, .
Die Probleme
: , , . , .
— . . , , . , — «.».
( ) - DDoS- . , , DDoS. DNS , 10 DNS . , — , , — . , 20 .
Cloudflare . Anti-DDoS . , Cloudflare . . , DDoS' , .
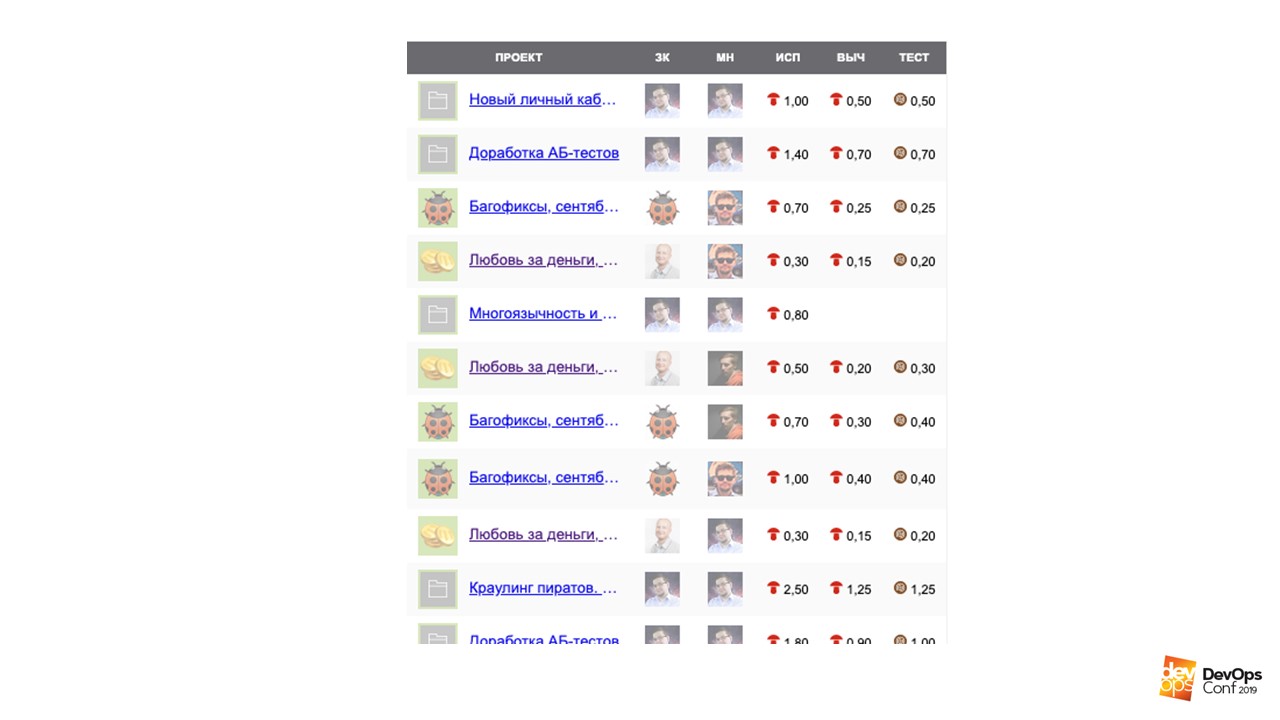
. KPI.
KPI
. . , , .
KPI. — .
- . — .
- Downtime. — .
- . , --, , . , .
KPI, — . , , KPI, .
. 90%. , . — , . . , .
-Nagios -Puppet Zabbix Grafana Ansible. « ».
Prometheus , Zabbix. Zabbix, Prometheus — . — . .
, , .
. ,
, . — . , .
. - -, - . , . . . . .
, .
2 . 3 « », — . .
. : , , , Ansible, .
. , . . .
.
— , , . .
. — , .
. , . . 2019. , , , — . .
. .
.
, - , . .
- , , .
- , .
- , , — .
- , , , — , .
. , - . , , , .
.
— , , . , , .

, — - . , .
« , ». , — , , , .
, , .
—
Ansible? , , Puppet ? — .

CI/CD? , . CI/CD , — .
., , . - ? , KPI? , -.
- — , , .
.
:DevOpsConf . — , , . DevOps- HighLoad++ 2019 . DevOps 13 AWS, Lamoda, , Kubernetes, Kubernetes, Kubernetes . « » . HighLoad++ — , -. . — .