Manchmal passiert es so:
- Komm, wir sind gefallen. Wenn Sie es jetzt nicht erhöhen, wird es im Fernsehen gezeigt.
Und wir gehen. Nachts. Auf die andere Seite des Landes.
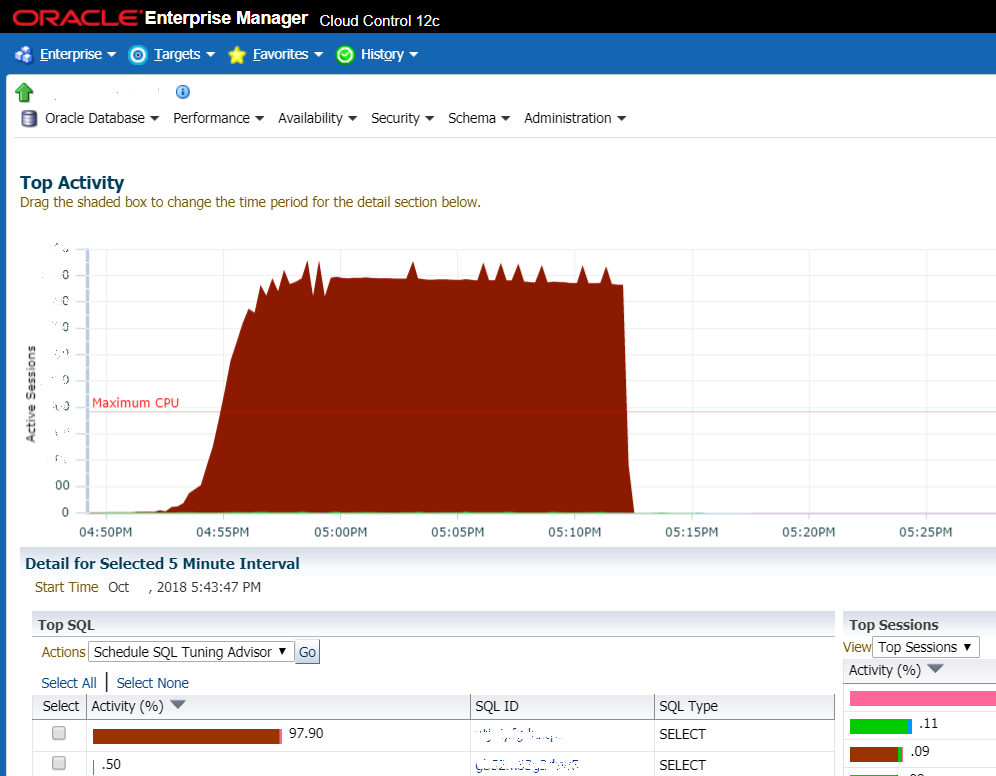 Die Situation ohne Glück: Die Grafik zeigt einen starken Anstieg der Belastung des DBMS. Sehr oft ist dies das erste, was Systemadministratoren betrachten, und dies ist das erste Anzeichen dafür, dass ein Arsch gekommen ist
Die Situation ohne Glück: Die Grafik zeigt einen starken Anstieg der Belastung des DBMS. Sehr oft ist dies das erste, was Systemadministratoren betrachten, und dies ist das erste Anzeichen dafür, dass ein Arsch gekommen istAber öfter sprechen wir über einige typische Dinge. Beispielsweise ist ein Kunde mit einem schlechten Workflow-System konfrontiert. Montags und dienstags stürzte das System ab, der Server wurde neu gestartet, und dann ging alles hoch. Die Datenbank war erstickt. Sie wollten Ausrüstung kaufen (was lang und teuer ist), sie riefen uns an, um die Schätzung zu berechnen. Wir haben ihre Schätzungen berechnet und gleichzeitig angeboten, herauszufinden, was genau langsamer wird. In drei bis vier Stunden wurde die Ursache des Problems lokalisiert. Wir haben herausgefunden, dass dies langsame Datenbankabfragen und suboptimale Indizierungsschemata sind. Wir haben die fehlenden Indizes erstellt, mit dem Abfrageoptimierer in Oracle herumgestöbert. Einige Probleme erforderten das Ändern des Codes. Wir haben die Suchbedingungen geändert (ohne die Funktionalität zu ändern) und einige der Anforderungen durch die Verwendung vorberechneter Ansichten ersetzt. Wenn sie eine normale Person in der Datenbank hätten, könnten sie dasselbe selbst tun. Anstelle einer normalen Person wurde die Datenbank jedoch alle sechs Monate von coolen Orakelisten überprüft - sie gaben allgemeine Empfehlungen zu Einstellungen und Hardware ab.
Wie passiert das?
Details werden auf Wunsch der Sicherheit ein wenig geändert. In Hunderten von Industrieanlagen gibt es ein Dokumentenmanagementsystem. Sie fällt manchmal und die Arbeit steigt. Das heißt, Objekte können funktionieren, aber kein einziges Dokument wird übergeben und ist nicht signiert. Und dies insbesondere der Versand von Rohstoffen, Gehältern und Bestellungen, was und wie viel pro Schicht produziert werden soll. Jeder Sturz ist ein Schmerz, Tränen, Cognac für den CIO, denn es ist schwer für ihn: viele Verluste.
Der Regisseur ist übrigens erst sechs Monate alt an diesem Ort nach der Vergangenheit. Und letztes Jahr dauerte. Und beide arbeiten an einem System, das der Regisseur vor drei Generationen eingeführt hat. Der zweite vom Ende versuchte, seine eigene vorzustellen, hatte aber keine Zeit vor der Entlassung. Die Situation ist sehr realistisch.
Auf den ersten Blick nicht genug Leistung. Das Lastprofil ist Sperren (Warteklasse "Anwendung"). Das heißt, Wettbewerb um die Linien. Wir beginnen den Vorfall zu untersuchen. Für jede Benutzertransaktion wird eine Sitzung geöffnet. Es geht schnell in den Zustand, einen Auftrag zu blockieren, gemäß dem Aufgaben und Anweisungen für die Ausführung ausgeschrieben werden, da der Benutzer mindestens ein "Vertrautes" Visum beantragen muss.
Der letzte Fall - sie haben einen neuen Standard festgelegt, wie oft Mitarbeiter einer medizinischen Untersuchung unterzogen werden sollen. Der hochrangige Personalreferent schrieb einen Auftrag und schickte ihn an alle Organisationen. Das heißt, jeder Mitarbeiter jeder Produktion. Zehntausende Benutzer erhielten Visa-Transaktionen. Sie begannen fast gleichzeitig, Bestellungen zu öffnen und eine lange Kette von Schlössern in die Datenbank aufzunehmen. Aufgrund des nicht optimalen Codes kam es zu einem „kleinen“ Überlauf, und alles wurde verstopft. Ungefähr 40.000 Benutzer arbeiten nicht. Aus dem Backup-Schema - nur Telefone und Mail. Die Produktion stoppt nicht, aber die Effizienz sinkt stark, was zu spezifischen finanziellen Verlusten führt. Und dann beginnen die Anrufe von jedem Unternehmen persönlich mit einer Rede an den IT-Direktor. In der Praxis haben sie eine SLA, aber es gibt noch keine Einigung. Und die Situation nimmt die letzten Merkmale der rein russischen Geschichte an.
Das Problem der schnellen Lösung wurde durch Profilerstellung, Analyse der Logik zum Blockieren von Objekten und Eliminieren unnötiger Objekte, für die die Sperre festgelegt wurde, gelöst. Dies war jedoch nicht erforderlich, da sich das Objekt nicht geändert hat (z. B. Verzeichnisse, Zugriffsrechte usw.). Dann, in ein paar Monaten, wurden die Hauptabschnitte des Codes überarbeitet.
Wie werden diese Codeabschnitte durchsucht?
Zusätzlich zu Standardtools (Thread-Dumps, Protokolle, Metriken, AWR, Daten aus Systemdarstellungen usw.) verwenden wir mehr zivile Tools, einschließlich kommerzieller Tools.
Beispiel 1: Langsames TransaktionsprotokollEs sind Beschwerden von Benutzern über den langsamen Betrieb des Journals eingegangen (ein bekanntes und häufiges Problem).
Wir finden die Problemansicht und suchen dann in den Operationen nach der Anforderung für die Ansicht deal_journal_view. Wir suchen nach allen Transaktionen, bei denen eine solche Anfrage vorliegt.

Für jede der Operationen können Sie ihre Details überprüfen und die Anforderung selbst mit den Ausführungsparametern finden, wodurch Sie die Operation der Anforderung analysieren, den Plan validieren und anpassen können. Es wurde eine bestimmte langsame Anfrage gefunden.

Sie selbst analysierten und schlugen Optimierungsoptionen vor. Um diese Gruppe von Geschäftsvorgängen zu verfolgen (Transaktionsprotokoll anzeigen), erstellen Sie erst dann einen Transaktionstyp und konfigurieren Sie Warnungen.
 Beispiel 2: Finden der Gründe für langsame Benutzerarbeit 1
Beispiel 2: Finden der Gründe für langsame Benutzerarbeit 1Benutzer 1 erhielt Beschwerden über den langsamen Betrieb der Anwendung. Wir schauen:

Alle Benutzeroperationen wurden durchsucht und nach Dauer sortiert. Als nächstes wurden die langsamsten Vorgänge analysiert und langsame Abfragen an das externe System (SAP) erkannt.

Richtete es auf das benachbarte Team, reparierte es.
Beispiel 3: Ein anderer Benutzer beschwert sich über den langsamen Betrieb der AnwendungWir sehen genauso aus. Diesmal sehen wir eine große Anzahl von Anrufen bei einem externen Signaturdienst. Es stellte sich heraus, dass sie unter bestimmten Bedingungen einige Dokumente zweimal unterschrieben hatten. Korrigiert.
 Beispiel 4: Wenn nicht genügend Details vorhanden sind
Beispiel 4: Wenn nicht genügend Details vorhanden sindUm komplexere Teile des Codes zu analysieren, verwenden wir manchmal benutzerdefinierte Profiler, mit denen wir das Verhalten der Anwendung genauer untersuchen können. Zum Beispiel wie hier: viel unverständliche Logik während des Betriebs der Logik im System. Wir haben die Logik herausgefunden, ein paar Caches hinzugefügt und die Anforderungen optimiert.
 Beispiel 5: mehr Bremsen
Beispiel 5: mehr BremsenDer Benutzer beschwerte sich über die langsame Arbeit mit den Vertragskarten.

Langsame Benutzeroperationen (Parameter = 'userlogin = ”...”') für eine Woche werden analysiert. Die meisten Probleme betrafen Suchanfragen im Rahmen von Verträgen, es wurden jedoch auch Vorgänge mit einer Dokumentenkarte gefunden. Die meiste Zeit wird für die Erstellung einer großen Anzahl von Aufgaben für Aufgaben aufgewendet. Es wurden Kennungen (die Spalte Parameterwert im Screenshot) der gespeicherten Aufgaben und der Zeitpunkt ihrer Speicherung gefunden.
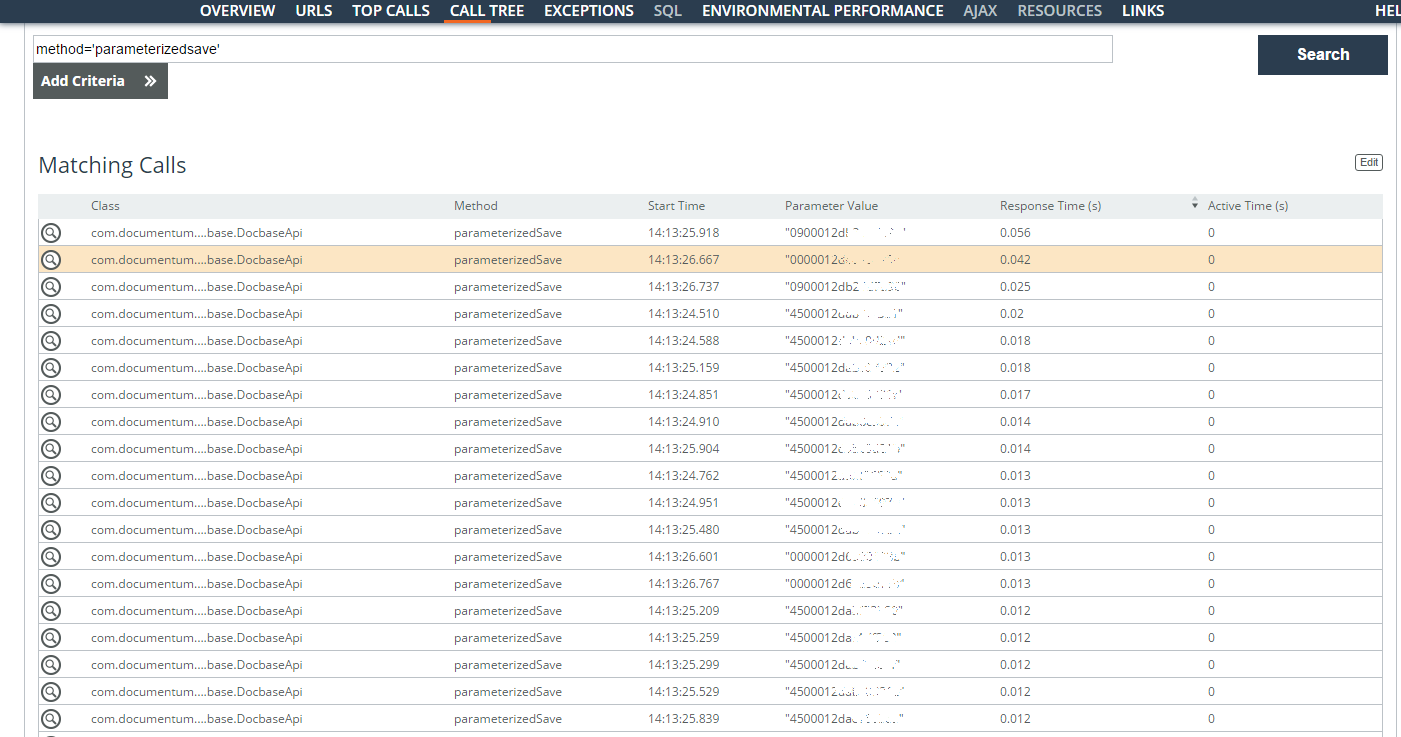
Logischerweise, wenn sie asynchron erstellt werden können, aber jetzt in der Warteschlange stehen und außergewöhnliche Sperren erfordern. Hier müssen Sie bereits tiefer in die Architektur eintauchen.
So einfach ist das: Sie müssen einen Engpass finden - und das war's?
Nein.
Und wieder nein.
Dies ist alles eine Behandlung für die Symptome.
Es ist richtig, die Situation, die jetzt in Flammen steht, schnell zu retten. Und dann setzen Sie die Prozesse. Es ist selten, dass Menschen, die mit einem System arbeiten, nicht verstehen, was sie tun. Es ist nur so, dass sie entweder die Mittel zum Abbau der technischen Verschuldung rechtfertigen müssen (und niemand glaubt ihnen) oder die Prozesse auf modernere umstellen müssen (für die es auch keine Ressourcen gibt) oder etwas anderes tun müssen.
Im Allgemeinen kommen wir von der obersten Ebene und sehen Schmerzen beim Kunden. Dann fangen wir den Engpass. Manchmal endet es mit der Einführung eines Überwachungssystems. Und wenn der Kunde versteht, dass es notwendig ist, die Prozesse der Softwareentwicklung zu ändern, beginnt die Phase "lang, teuer und überhaupt nicht großartig".
Wir schauen uns zwei oder drei Projekte an, wählen alle Dokumente, Repositories aus und interviewen Leute. Als Nächstes bereiten wir Vorlagen für neue Dokumente vor, bereiten Verfahren vor, sehen uns Tools zum Verwalten von Anforderungen an und testen. Und wir helfen bei der Umsetzung. Manchmal reicht es aus, nur eine Meinung darüber abzugeben, was geändert werden soll, und der geflügelte CIO mit Papier erhält ein Budget. Manchmal ist es notwendig, Blut und Tränen direkt zu injizieren.
Alles kann sich als schmerzhaft herausstellen, angefangen von der falschen Wahl der Architektur bis hin zu einigen Funktionen des Workflows.
In diesen Beispielen geht es um Spielprozesse in verschiedenen Unternehmen im ganzen Land.
In Bezug auf die Datenbankoptimierung ist hier ein typisches Beispiel. Es gibt ein medizinisches System (eines von denen, die gefallen sind). Sie riefen uns an, um zuzusehen. Wir kamen an, als sie bereits alle Module außer dem Workflow der Ärzte ausgeschaltet hatten, so dass zumindest irgendwie die Analysen verlaufen und die Aufzeichnung durch die Registrierung erfolgen würde. Insbesondere die Online-Aufzeichnung gehörte zu den deaktivierten Modulen. Ich habe es geschafft, alles in einer Woche zu reparieren. Anfänglich glaubte der Kunde, dass die Probleme auf der Anwendungsebene lagen: Es gab Timeout-Fehler und Threads hingen. Wir haben herausgefunden, dass das Problem bei der Datenbank liegt. Es gab eine komplexe Struktur, eine Reihe von Abschnitten nach Tag und Monat. Es stellte sich heraus, dass sie einige Indizes vergessen hatten, die Entwickler wussten nicht genau, wie es sich im Laufe der Zeit entwickeln würde - und hier ist das Ergebnis. Ungefähr die gleichen Vorgänge und Sucheinschränkungen (wenn Sie etwas in einem Datumsbereich entladen müssen, ist es hilfreich, zwischen diesen Daten und nicht in der gesamten Datenbank zu suchen).
Es ist klar, dass eine solche Optimierung das Problem nicht immer löst. Zum Beispiel (nach Architektur) der Energiesektor: Der Kunde fragt, womit das System aufhängt. Und dort flog alles bei Lieferung, aber nach ein paar Jahren gab es viel mehr Dokumente und alles bremste gut. Der Kunde saß mit einer Stoppuhr am Arbeitsplatz des Bedieners und sagte: Dieser Vorgang dauert jetzt 31 Sekunden, wir wollen 3. Dieser ist 40 Sekunden, wir wollen 2. Und so weiter. Es ist klar, dass das Messen auf diese Weise nicht sehr korrekt ist, aber die Aufgabe ist sehr spezifisch und kann leicht in Form objektiver Kriterien dargestellt werden. Wir haben nicht alles getan, es dauerte ungefähr sechs Monate, um "sauber" zu machen. Zum größten Teil wurde die Logik auf asynchrone Ausführung übertragen, einige der Datenbanken wurden auf noSQL geändert, die Solar-Suchmaschine wurde installiert, in einem Abschnitt musste die heißeste Datenbank ausgewählt und im Speicher gespeichert werden. Infolgedessen wurden etwa 90% des Bedarfs geschlossen, aber an einigen Stellen konnten sie die Verzögerungen nicht verringern. Dies ist die Arbeit von Bibliotheken von Drittanbietern, die physischen Einschränkungen der Plattform usw. All dies wurde durch Überwachung überwacht und konnte genau nachweisen, wo und was langsamer wird.
Warum könnte eine solche Überwachung sonst erforderlich sein?
Wir verwenden verschiedene Überwachungssoftware, um hemmende Prozesse schnell zu finden und zu optimieren. Das IT-Team eines der Hauptkunden untersuchte, wie wir dies tun, und bat darum, es in einer der Einrichtungen als permanentes Tool zu implementieren. OK, überwachte alle Prozesse und Knoten, passte ihr System an Aufgaben an, arbeitete fast vier Monate lang, erstellte jedoch eine Reihe von Tools, um sie zu unterstützen. Und es gibt 80.000 Benutzer, es gibt die erste und zweite Zeile innerhalb und die dritte häufig - mit Auftragnehmern oder auch innerhalb.
In der zweiten Zeile finden Sie nur diese Tools. In etwa 50% der Fälle verwenden sie die Überwachung zur Diagnose, Suche nach Engpässen und Ursachen von Einfrierungen, damit ihre eigenen Entwickler sie sehen, verstehen und optimieren können. Durch die schnelle Identifizierung der Problemursache wird viel Supportzeit gespart. Nachdem der Pilot durch Transaktion skaliert wurde. Das hat vier Monate gedauert: Für jede Aktion gibt es einen Geschäftsbetrieb. Das Öffnen einer Dokumentenkarte ist ein Geschäftsvorgang. Das Anmelden in einem Workflow-System ist ein Geschäftsvorgang. Auch Upload oder Suche melden. 1.500 solcher Geschäftsvorgänge in vier Monaten werden beschrieben, um zu verstehen, wo und was funktioniert. Bei der Überwachung zuvor wurden http-Aufrufe und die aufgerufenen Methoden und Funktionen sowie bestimmte Anforderungen angezeigt. Zuvor hatten nur die Entwickler verstanden, dass dies eine Vereinbarung oder Suche war. Damit das Überwachungssystem relevante Daten für verschiedene Supportlinien und für Unternehmen anzeigen kann, haben wir alle diese Bundles eingerichtet.

Das Unternehmen begann auch, Berichte über seine eigene IT-Entwicklung zu kürzen. Mehr auf den Protokollen gibt es niemand besonders aus.
Übrigens werden wir
am 1. Oktober in einem
Webinar über alles sprechen, warum
APM- Klassensysteme überhaupt benötigt werden und wie man sie
auswählt .
Was gibt es sonst noch "Stecker" von der technischen Seite?
Noch ein paar Beispiele. Eine große ausländische Bank mit Repräsentanzen in Russland. Wir unterstützen Oracle DB und Oracle Weblogic. Im System wurde ein allmählicher Rückgang der Produktivität beobachtet, der Geschäftsbetrieb wurde langsamer ausgeführt, die Arbeit des Bedieners wurde immer weniger effektiv, und während der Zeiträume der Importe und der Synchronisation mit dem NSI war alles vollständig gefroren. In solchen Fällen verwenden wir Standard-Java- und Oracle-Tools, um Daten zu erfassen: Wir erfassen Thread-Dumps, analysieren sie in kostenlosen Diensten oder verwenden selbst geschriebene Analysetools, betrachten AWR, verfolgen die Ausführung von SQL-Abfragen, analysieren Pläne und Ausführungsstatistiken. Aus diesem Grund haben wir zusätzlich zu Standardaufgaben wie der Optimierung der Zusammensetzung von Indizes und der Anpassung von Abfrageplänen die Einführung einer Partitionierung durch Aufteilung der Daten vorgeschlagen. Es stellte sich heraus, dass zwei Segmente: historisch (auf der Festplatte belassen) und betriebsbereit - auf der SSD platziert. Zuvor war es ziemlich schwierig zu verstehen, welche Daten sich auf was beziehen, da historische Daten sowohl in langen Berichten als auch im normalen Betrieb immer noch regelmäßig abgerufen werden mussten. Aufgrund der korrekten Trennung gingen mehr als 98% der Hauptoperationen nicht in langsame historische Daten. Was wichtig ist, es gab keinen Einstieg in den Systemcode. Es kommt vor, dass einige unserer Empfehlungen Änderungen am Anwendungscode erfordern, die von uns nicht unterstützt werden. Dann stimmen wir normalerweise zu.
Das zweite Beispiel: ein internationaler Hersteller im Bereich der Leichtindustrie und des FMCG-Segments im Allgemeinen. Die Ausfallzeit des Hauptstandorts kostet etwa 20 Millionen Rubel. Die durchschnittliche Belastung der Basis beträgt 200 AS (aktive Sitzungen) mit Spitzenwerten von bis zu 800-1000. Es ist nicht ungewöhnlich, dass ein Abfrageoptimierer den Kopf verliert, Pläne nicht zum Besseren schweben und eine wilde Konkurrenz um den Puffercache beginnt. Niemand ist davor sicher, aber Sie können die Wahrscheinlichkeit verringern: Zwei Monate lang haben wir das System überwacht, das Lastprofil analysiert, Brände auf dem Weg gelöscht, die Indizierungs- und Partitionierungsschemata angepasst und die Datenverarbeitungslogik von der Seite des PL / SQL-Codes aus überprüft. Hier müssen Sie verstehen, dass in einem lebenden, sich entwickelnden System ein solches Audit regelmäßig durchgeführt werden sollte, obwohl Stresstests hilfreich sind, aber nicht immer. Und Unternehmen führen ein Audit durch, indem sie Orakelisten von Drittanbietern einladen, aber selten fällt einer von ihnen auf die Ebene der Geschäftslogik und ist bereit, sich mit den Daten zu befassen und mit Entwicklern zu interagieren. Wir machen es
Nun, ich möchte sagen, dass das Problem nicht immer der Mangel an regelmäßiger Reinigung oder angemessener Unterstützung ist. Oft sind Probleme in den Prozessen.
Warum brauchen wir solche Dienste mit ihren Live-Entwicklern?
Weil Unternehmen Entscheidungen lieben, keine Prozesse. Dies ist der Hauptgrund.
Das zweite ist, dass nicht jeder Ressourcen zuweisen kann, um nach einem Engpass in einer Anwendung zu suchen, insbesondere wenn es sich um eine Drittanbieteranwendung handelt. Und weit davon entfernt, immer in einem Team zu sein, gibt es Menschen mit den notwendigen Kompetenzen. Derzeit haben wir einen Systemingenieur, Netzwerktechniker, Spezialisten für Oracle und 1C, Mitarbeiter, die Java optimieren können, und das Frontend in unserem Team.
Wenn Sie sich für Details interessieren, wird
am 1. Oktober unser Webinar darüber stattfinden, was Sie im Voraus tun können, bevor alles fällt. Und hier ist meine Mail für Fragen - sstrelkov@croc.ru.