Es ist nicht erforderlich, die FIAS-Basis spezifisch darzustellen:

Sie können es herunterladen, indem Sie auf den
Link klicken. Diese Datenbank ist geöffnet und enthält alle Adressen von Objekten in Russland (Adressregister). Das Interesse an dieser Datenbank wird durch die Tatsache verursacht, dass die darin enthaltenen Dateien ziemlich umfangreich sind. So ist beispielsweise das kleinste 2,9 GB. Es wird empfohlen, einen Zwischenstopp einzulegen und zu prüfen, ob Pandas damit umgehen können, wenn Sie auf einem Computer mit nur 8 GB RAM arbeiten. Und wenn Sie nicht damit fertig werden, welche Optionen gibt es, um Pandas mit dieser Datei zu füttern?
Hand aufs Herz, ich bin dieser Basis noch nie begegnet und dies ist ein zusätzliches Hindernis, weil Das Format der darin dargestellten Daten ist absolut unklar.
Nach dem Herunterladen des Archivs fias_xml.rar mit der Basis erhalten wir die Datei daraus - AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. Die Datei ist im XML-Format.
Für eine bequemere Arbeit in Pandas wird empfohlen, XML in CSV oder JSON zu konvertieren.
Alle Konvertierungsversuche mit Programmen von Drittanbietern und Python selbst führen jedoch zu einem "MemoryError" -Fehler oder einem Einfrieren.
Hm. Was ist, wenn ich die Datei ausschneide und in Teile konvertiere? Es ist eine gute Idee, aber alle "Cutter" versuchen auch, die gesamte Datei in den Speicher zu lesen und zu hängen. Python selbst, das dem Pfad der "Cutter" folgt, schneidet sie nicht. Reichen 8 GB offensichtlich nicht aus? Nun, mal sehen.
Vedit-Programm
Sie müssen ein vedit-Programm eines Drittanbieters verwenden.
Mit diesem Programm können Sie eine 2,9-GB-XML-Datei lesen und damit arbeiten.
Sie können es auch teilen. Aber es gibt einen kleinen Trick.
Wie Sie beim Lesen einer Datei sehen können, hat sie unter anderem ein öffnendes AddressObjects-Tag:

Wenn Sie also Teile dieser großen Datei erstellen, dürfen Sie nicht vergessen, sie zu schließen (Tag).
Das heißt, der Anfang jeder XML-Datei sieht folgendermaßen aus:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
und Ende:
</AddressObjects>
Schneiden Sie nun den ersten Teil der Datei ab (für die übrigen Teile sind die Schritte gleich).
Im vedit-Programm:
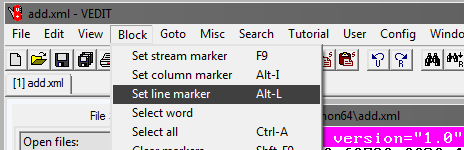
Wählen Sie als Nächstes Springen und Zeilennummer. Schreiben Sie in das sich öffnende Fenster die Zeilennummer, z. B. 1.000.000:

Als Nächstes müssen Sie den ausgewählten Block so anpassen, dass das Objekt in der Datenbank vor dem schließenden Tag bis zum Ende erfasst wird:
Es ist in Ordnung, wenn sich das nachfolgende Objekt leicht überlappt.
Speichern Sie als Nächstes im vedit-Programm das ausgewählte Fragment - Datei, Speichern unter.
Auf die gleiche Weise erstellen wir die verbleibenden Teile der Datei und markieren den Anfang des Auswahlblocks und das Ende in Schritten von 1 Million Zeilen.
Als Ergebnis sollten Sie die 4. XML-Datei mit einer Größe von ca. 610 MB erhalten.
Wir finalisieren die XML-Teile
Jetzt müssen Sie den neu erstellten XML-Dateien Tags hinzufügen, damit sie als XML gelesen werden.
Öffnen Sie die Dateien in vedit nacheinander und fügen Sie sie am Anfang jeder Datei hinzu:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
und am Ende:
</AddressObjects>
Somit haben wir jetzt 4 XML-Teile der geteilten Quelldatei.
Xml-to-csv
Übersetzen Sie nun XML in CSV, indem Sie ein Python-Programm schreiben.
Programmcode
.
Mit dem Programm müssen Sie alle 4 Dateien in CSV konvertieren.
Die Dateigröße nimmt ab und beträgt jeweils 236 MB (vergleiche mit 610 MB in XML).
Im Prinzip können Sie jetzt bereits mit ihnen arbeiten, über Excel oder Notepad ++.
Die Dateien sind jedoch immer noch die 4. statt einer, und wir haben das Ziel nicht erreicht - die Datei in Pandas zu verarbeiten.
Kleben Sie die Dateien in eine
Unter Windows kann sich dies als schwierige Aufgabe herausstellen. Daher verwenden wir das Konsolendienstprogramm in Python namens csvkit. Als Python-Modul installiert:
pip install csvkit
* Eigentlich ist dies eine ganze Reihe von Dienstprogrammen, aber eines wird von dort benötigt.
Nachdem Sie den Ordner mit den Dateien zum Kleben in der Konsole eingegeben haben, führen wir das Kleben in eine Datei durch. Da alle Dateien keine Überschriften haben, weisen wir beim Kleben die Standardspaltennamen zu: a, b, c usw.:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csv
Die Ausgabe ist eine fertige CSV-Datei.
Lassen Sie uns in Pandas an der Optimierung der Speichernutzung arbeiten
Wenn Sie die Datei sofort auf Pandas hochladen
import pandas as pd import numpy as np gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a') print (gl.info(memory_usage='deep'))
und überprüfen Sie, wie viel Speicher benötigt wird, das Ergebnis kann unangenehm überraschen:

3 GB! Und dies trotz der Tatsache, dass beim Lesen von Daten die erste Spalte als Indexspalte * "ging" und das Volumen sogar noch größer wäre.
* Standardmäßig legt pandas einen eigenen Spaltenindex fest.
Wir werden die Optimierung mit Methoden aus dem vorherigen
Beitrag und
Artikel durchführen :
- Objekt in Kategorie;
- int64 in uint8;
- float64 in float32.
Fügen Sie dazu beim Lesen der Datei dtypes hinzu, und das Lesen der Spalten im Code sieht folgendermaßen aus:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' })
Wenn Sie nun die Pandas-Datei öffnen, ist die Speichernutzung sinnvoll:

Falls erforderlich, müssen der CSV-Datei die zeilenspezifischen Spaltennamen hinzugefügt werden, damit die Daten sinnvoll sind:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE
* Sie können die Spaltennamen durch diese Zeile ersetzen, müssen dann aber den Code ändern.
Speichern Sie die ersten Zeilen der Datei von Pandas
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
und sehen, was in Excel passiert ist:

Programmcode zum optimierten Öffnen einer CSV-Datei mit einer Datenbank:
Code import os import time import pandas as pd import numpy as np # : object-category, float64-float32, int64-int gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' }) pd.set_option('display.notebook_repr_html', False) pd.set_option('display.max_columns', 8) pd.set_option('display.max_rows', 10) pd.set_option('display.width', 80) #print (gl.head()) print (gl.info(memory_usage='deep')) # def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , , usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} " .format(usage_mb)
Lassen Sie uns abschließend die Größe des Datensatzes betrachten:
gl.shape
(3348644, 28)
3,3 Millionen Zeilen, 28 Spalten.
Fazit: Mit der anfänglichen CSV-Dateigröße von 890 MB, die für die Arbeit mit Pandas "optimiert" wurde, belegt sie 1,2 GB Arbeitsspeicher.
Bei einer groben Berechnung können wir daher davon ausgehen, dass eine Datei mit einer Größe von 7,69 GB in Pandas geöffnet werden kann, nachdem sie zuvor „optimiert“ wurde.