Was ist End2End-Spracherkennung und warum wird sie benötigt? Was ist der Unterschied zum klassischen Ansatz? Und warum, um ein gutes End2End-basiertes Modell zu trainieren, benötigen wir eine große Datenmenge - in unserem heutigen Beitrag.
Der klassische Ansatz zur Spracherkennung
Bevor Sie über den End2End-Ansatz sprechen, sollten Sie zunächst über den klassischen Ansatz zur Spracherkennung sprechen. Wie ist er?

Merkmalsextraktion
Tatsächlich ist dies keine vollständig lineare Folge von Aktionsblöcken. Lassen Sie uns näher auf jeden Block eingehen. Wir haben eine Art Eingabesprache, die auf den ersten Block fällt - Feature Extraction. Dies ist ein Block, der Zeichen aus der Sprache zieht. Es muss bedacht werden, dass die Sprache selbst eine ziemlich komplizierte Sache ist. Sie müssen in der Lage sein, irgendwie damit zu arbeiten, daher gibt es Standardmethoden zum Isolieren von Merkmalen aus der Signalverarbeitungstheorie. Zum Beispiel Mel-Cepstral-Koeffizienten (MFCC) und so weiter.
Akustisches Modell
Die nächste Komponente ist das akustische Modell. Es kann auf tiefen neuronalen Netzen oder auf Mischungen von Gaußschen Verteilungen und versteckten Markov-Modellen basieren. Sein Hauptziel ist es, aus einem Abschnitt des akustischen Signals die Wahrscheinlichkeitsverteilungen verschiedener Phoneme in diesem Abschnitt zu erhalten.
Als nächstes kommt der Decoder, der anhand des Ergebnisses aus dem letzten Schritt nach dem wahrscheinlichsten Pfad im Diagramm sucht. Rescoring ist der letzte Schliff bei der Anerkennung, dessen Hauptaufgabe darin besteht, die Hypothesen neu abzuwägen und das Endergebnis zu erzielen.
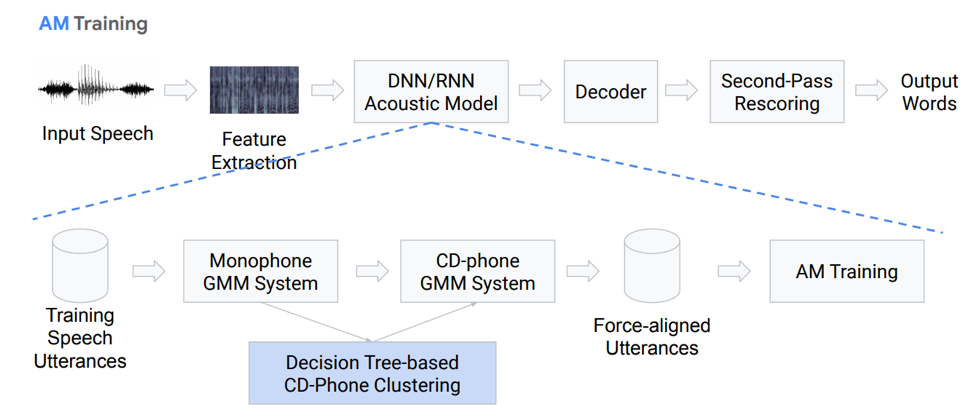
Lassen Sie uns näher auf das akustische Modell eingehen. Wie ist sie Wir haben einige Sprachaufnahmen, die in ein bestimmtes System eingegeben werden, das auf GMM (monauraler Gausovy-Mix) oder HMM basiert. Das heißt, wir haben Darstellungen in Form von Phonemen, wir verwenden Monophone, dh kontextunabhängige Phoneme. Weiter von diesen machen wir Mischungen von Gaußschen Verteilungen basierend auf kontextsensitiven Phonemen. Es verwendet Clustering basierend auf Entscheidungsbäumen.
Dann versuchen wir, eine Ausrichtung aufzubauen. Eine solche völlig nicht triviale Methode ermöglicht es uns, ein akustisches Modell zu erhalten. Es klingt nicht sehr einfach, es ist sogar noch komplizierter, es gibt viele Nuancen und Funktionen. Infolgedessen kann ein Modell, das in Hunderten von Stunden trainiert wurde, die Akustik sehr gut simulieren.

Decoder
Was ist ein Decoder? Dies ist das Modul, das den wahrscheinlichsten Übergangspfad gemäß dem HCLG-Diagramm auswählt, das aus 4 Teilen besteht:
H-Modul basierend auf HMM
C-Kontextabhängigkeitsmodul
L Aussprachemodul
G Sprachmodellmodul
Wir bauen ein Diagramm auf diesen vier Komponenten auf, auf dessen Grundlage wir unsere akustischen Merkmale in bestimmte verbale Konstruktionen dekodieren.
Plus oder Minus, es ist klar, dass der klassische Ansatz ziemlich umständlich und schwierig ist, es ist schwierig zu trainieren, da er aus einer großen Anzahl separater Teile besteht, für die Sie jeweils Ihre eigenen Daten für das Training vorbereiten müssen.
II End2End-Ansatz
Was ist End2End-Spracherkennung und warum wird sie benötigt? Dies ist ein bestimmtes System, das die Folge von akustischen Zeichen in der Folge von Graphemen (Buchstaben) oder Wörtern direkt widerspiegeln soll. Sie können auch sagen, dass dies ein System ist, das Kriterien optimiert, die sich direkt auf die endgültige Metrik der Qualitätsbewertung auswirken. Zum Beispiel ist unsere Aufgabe speziell die Wortfehlerrate. Wie gesagt, es gibt nur eine Motivation - diese komplexen mehrstufigen Komponenten in Form einer einfachen Komponente darzustellen, die Wörter oder Grapheme direkt aus der Eingabesprache anzeigt, ausgibt.
Simulationsproblem
Hier haben wir sofort ein Problem: Tonsprache ist eine Sequenz, und am Ausgang müssen wir auch eine Sequenz angeben. Und bis 2006 gab es keine adäquate Möglichkeit, dies zu modellieren. Was ist das Problem der Modellierung? Für jede Aufnahme musste ein komplexes Markup erstellt werden, was impliziert, in welcher Sekunde wir einen bestimmten Ton oder Buchstaben aussprechen. Dies ist ein sehr umständliches komplexes Layout, und daher wurde eine große Anzahl von Studien zu diesem Thema nicht durchgeführt. 2006 wurde ein interessanter Artikel von Alex Graves „Connectionist Temporal Classification“ (CTC) veröffentlicht, in dem dieses Problem im Prinzip gelöst wird. Der Artikel wurde jedoch veröffentlicht, und zu diesem Zeitpunkt war nicht genügend Rechenleistung vorhanden. Und echte funktionierende Spracherkennungsalgorithmen erschienen viel später.
Insgesamt haben wir: Der CTC-Algorithmus wurde vor dreizehn Jahren von Alex Graves als Werkzeug vorgeschlagen, mit dem Sie akustische Modelle trainieren / trainieren können, ohne dass dieses komplexe Markup erforderlich ist - die Ausrichtung der Eingabe- und Ausgabesequenzrahmen. Basierend auf diesem Algorithmus erschienen zunächst Arbeiten, die nicht vollständig end2end waren, und als Ergebnis wurden Phoneme ausgegeben. Es ist erwähnenswert, dass kontextsensitive Phoneme, die auf STS basieren, eines der besten Ergebnisse bei der Erkennung der Redefreiheit erzielen. Es ist aber auch erwähnenswert, dass dieser Algorithmus, der direkt auf die Wörter angewendet wird, im Moment irgendwo zurückbleibt.

Was ist STS?
Jetzt werden wir etwas detaillierter darüber sprechen, was das STS ist und warum es benötigt wird, welche Funktion es ausführt. STS ist erforderlich, um das akustische Modell zu trainieren, ohne dass eine bildweise Ausrichtung zwischen Ton und Transkription erforderlich ist. Bild für Bild ist die Ausrichtung, wenn wir sagen, dass ein bestimmtes Bild aus einem Ton einem solchen Bild aus der Transkription entspricht. Wir haben einen konventionellen Encoder, der akustische Zeichen als Eingabe akzeptiert - er gibt eine Art Verschleierung des Zustands aus, auf deren Grundlage wir mit softmax bedingte Wahrscheinlichkeiten erhalten. Der Encoder besteht normalerweise aus mehreren Schichten von LSTMs oder anderen Variationen von RNNs. Es ist erwähnenswert, dass STS zusätzlich zu normalen Zeichen mit einem Sonderzeichen arbeitet, das als leeres Zeichen oder leeres Symbol bezeichnet wird. Um das Problem zu lösen, das sich aus der Tatsache ergibt, dass nicht jeder akustische Rahmen einen Rahmen in der Transkription hat und umgekehrt (dh wir haben Buchstaben oder Töne, die viel länger klingen und es gibt kurze Töne, sich wiederholende Töne) und dort dieses leere Symbol.
Das STS selbst soll die endgültige Wahrscheinlichkeit von Zeichenfolgen maximieren und eine mögliche Ausrichtung verallgemeinern. Da wir diesen Algorithmus in neuronalen Netzen verwenden möchten, müssen wir verstehen, wie seine Vorwärts- und Rückwärtsbetriebsarten funktionieren. Wir werden uns nicht mit der mathematischen Rechtfertigung und den Merkmalen der Funktionsweise dieses Algorithmus befassen, da dies sonst sehr lange dauern wird.
Was haben wir: Die erste ASR, die auf dem STS-Algorithmus basiert, erscheint 2014. Wieder präsentierte Alex Graves eine Publikation, die auf dem zeichenweisen STS basiert und die Eingabesprache direkt in einer Folge von Wörtern anzeigt. Einer der Kommentare in diesem Artikel ist, dass die Verwendung eines externen Soundmodells wichtig ist, um ein gutes Ergebnis zu erzielen.
5 Möglichkeiten zur Verbesserung des Algorithmus
Es gibt viele verschiedene Variationen und Verbesserungen des obigen Algorithmus. Hier sind zum Beispiel die fünf beliebtesten in letzter Zeit.
• Das Sprachmodell wird beim ersten Durchgang in die Dekodierung einbezogen
o [Hannun et al., 2014] [Maas et al., 2015]: Direkte First-Pass-Decodierung mit einem LM im Gegensatz zur erneuten Bewertung wie in [Graves & Jaitly, 2014]
o [Miao et al., 2015]: EESEN-Framework für die Dekodierung mit WFSTs, Open Source Toolkit
• Umfangreiches Training auf der GPU; Datenerweiterung mehrere Sprachen
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: GPU-Training in großem Maßstab; Datenerweiterung; Mandarin und Englisch
• Verwendung langer Einheiten: Wörter anstelle von Zeichen
o [Soltau et al., 2017]: CTC-Ziele auf Wortebene, die auf 125.000 Sprachstunden trainiert wurden. Leistung nahe oder besser als ein herkömmliches System, auch ohne Verwendung eines LM!
o [Audhkhasi et al., 2017]: Direkte Akustik-zu-Wort-Modelle auf der Telefonzentrale
Es lohnt sich, auf die Implementierung von DeepSpeach als gutes Beispiel für eine end2end CTC-Lösung und auf eine Variante zu achten, die eine verbale Ebene verwendet. Aber es gibt eine Einschränkung: Um ein solches Modell zu trainieren, benötigen Sie 125.000 Stunden beschriftete Daten, was in rauen Realitäten tatsächlich ziemlich viel ist.
Was ist wichtig an STS zu beachten
- Probleme oder Auslassungen. Für die Effizienz ist es wichtig, Annahmen über die Unabhängigkeit zu treffen. Das heißt, der STS geht davon aus, dass die Ausgabe des Netzwerks in verschiedenen Frames bedingt unabhängig ist, was tatsächlich falsch ist. Diese Annahme soll jedoch vereinfachen, ohne sie wird alles viel komplizierter.
- Um eine gute Leistung des STS-Modells zu erzielen, ist die Verwendung eines externen Sprachmodells erforderlich, da die direkte gierige Dekodierung nicht sehr gut funktioniert.
Achtung
Welche Alternative haben wir für dieses STS? Es ist wahrscheinlich für niemanden ein Geheimnis, dass es so etwas wie Aufmerksamkeit oder „Aufmerksamkeit“ gibt, die sich bis zu einem gewissen Grad revolutioniert haben und direkt von den Aufgaben der maschinellen Übersetzung ausgegangen sind. Und jetzt basieren vor allem Entscheidungen zur Sequenz-Sequenz-Modellierung auf diesem Mechanismus. Wie ist er? Versuchen wir es herauszufinden. Zum ersten Mal über Aufmerksamkeit bei Spracherkennungsaufgaben erschienen 2015 Veröffentlichungen. Jemand Chen und Cherowski gab gleichzeitig zwei ähnliche und unterschiedliche Veröffentlichungen heraus.
Lassen Sie uns auf das erste eingehen - es heißt Hören, teilnehmen und buchstabieren. In unserer klassischen Simulation wird in der Sequenz, in der wir einen Codierer und Decodierer haben, ein weiteres Element hinzugefügt, das als Aufmerksamkeit bezeichnet wird. Der Echnoder führt die Funktionen aus, die das akustische Modell verwendet hat. Seine Aufgabe ist es, die eingegebene Sprache in akustische Merkmale auf hohem Niveau umzuwandeln. Unser Decoder führt die Aufgaben aus, die wir zuvor für das Sprachmodell und das Aussprachemodell (Lexikon) ausgeführt haben. Er sagt jedes Ausgabe-Token autoregressiv als Funktion der vorherigen voraus. Und die Aufmerksamkeit selbst wird direkt sagen, welcher Eingaberahmen am relevantesten / wichtigsten ist, um diese Ausgabe vorherzusagen.
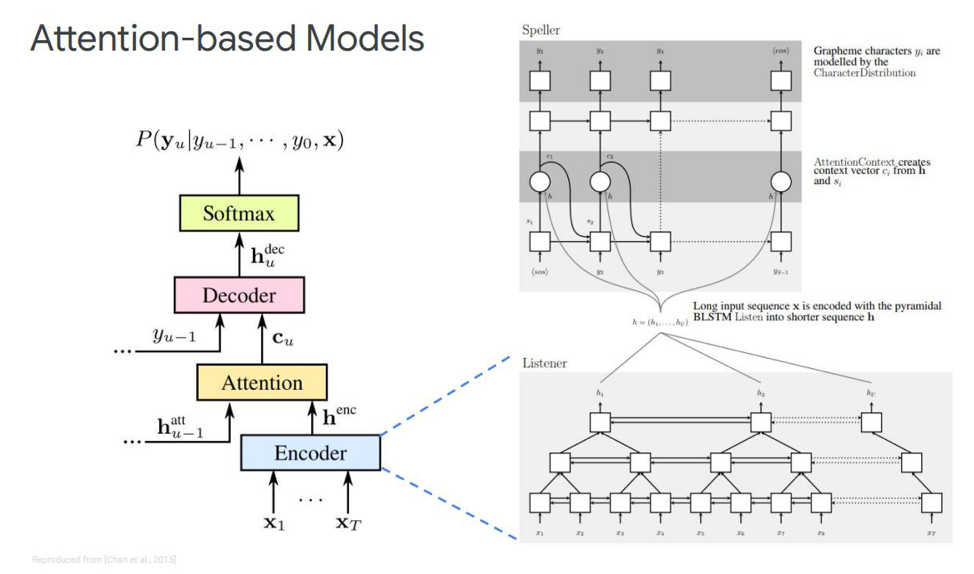
Was sind diese Blöcke? Der Öko-Encoder im Artikel wird als Listener beschrieben. Es handelt sich um klassische bidirektionale RNNs, die auf LSTMs oder etwas anderem basieren. Im Allgemeinen nichts Neues - das System simuliert einfach die Eingabesequenz in komplexe Merkmale.
Andererseits erzeugt die Aufmerksamkeit aus diesen Vektoren einen bestimmten Kontextvektor C, der dabei hilft, den Decoder direkt korrekt zu decodieren, den Decoder selbst, der beispielsweise auch einige LSTMs sind, die in die Eingabesequenz von dieser Aufmerksamkeitsschicht decodiert werden, die bereits die wichtigsten Zustandszeichen hervorgehoben hat. eine Ausgabesequenz von Zeichen.
Es gibt auch unterschiedliche Darstellungen dieser Aufmerksamkeit selbst - was den Unterschied zwischen diesen beiden Veröffentlichungen von Chen und Charowski ausmacht. Sie verwenden unterschiedliche Aufmerksamkeit. Chen verwendet die Aufmerksamkeit des Punktprodukts und Charowski die additive Aufmerksamkeit.

Wohin als nächstes?
Dies ist ein Plus oder Minus aller wichtigen Erfolge, die bisher in Fragen der Nicht-Online-Spracherkennung erzielt wurden. Welche Verbesserungen sind hier möglich? Wohin als nächstes? Am offensichtlichsten ist die Verwendung eines Modells für Wortstücke anstelle der direkten Verwendung von Graphemen. Es können einige separate Morpheme oder etwas anderes sein.
Was ist die Motivation für die Verwendung von Wortscheiben? Typischerweise weisen Sprachmodelle der verbalen Ebene im Vergleich zur Graphemebene eine viel geringere Verwirrung auf. Durch das Modellieren von Wortstücken können Sie einen stärkeren Decoder des Sprachmodells erstellen. Die Modellierung längerer Elemente kann die Speichereffizienz in einem auf LSTMs basierenden Decoder verbessern. Außerdem können Sie sich möglicherweise an das Auftreten von Frequenzwörtern erinnern. Längere Elemente ermöglichen die Dekodierung in weniger Schritten, was die Inferenz dieses Modells direkt beschleunigt.
Ein Modell für Wortstücke ermöglicht es uns auch, das Problem von OOV-Wörtern (außerhalb des Wortschatzes) zu lösen, die in einem Sprachmodell auftreten, da wir jedes Wort mit Wortstücken modellieren können. Es ist erwähnenswert, dass solche Modelle trainiert werden, um die Wahrscheinlichkeit eines Sprachmodells über einen Trainingsdatensatz zu maximieren. Diese Modelle sind positionsabhängig, und wir können den Greedy-Algorithmus zum Decodieren verwenden.
Welche anderen Verbesserungen neben dem Modell der Wortstücke können sein? Es gibt einen Mechanismus, der als Mehrkopfaufmerksamkeit bezeichnet wird. Es wurde erstmals 2017 für die maschinelle Übersetzung beschrieben. Multi-Head-Aufmerksamkeit impliziert einen Mechanismus mit mehreren sogenannten Köpfen, mit denen Sie eine unterschiedliche Verteilung derselben Aufmerksamkeit erzeugen können, wodurch die Ergebnisse direkt verbessert werden.
Online-Modelle
Wir kommen zum interessantesten Teil - dies sind Online-Modelle. Es ist wichtig zu beachten, dass LAS kein Streaming ist. Das heißt, dieses Modell kann nicht im Online-Decodierungsmodus arbeiten. Wir werden die beiden bislang beliebtesten Online-Modelle betrachten. RNN-Wandler und neuronaler Wandler.
RNN Transducer wurde von Graves in den Jahren 2012-2017 vorgeschlagen. Die Hauptidee besteht darin, unser STS-Modell mithilfe eines rekursiven Modells etwas zu komplizieren.
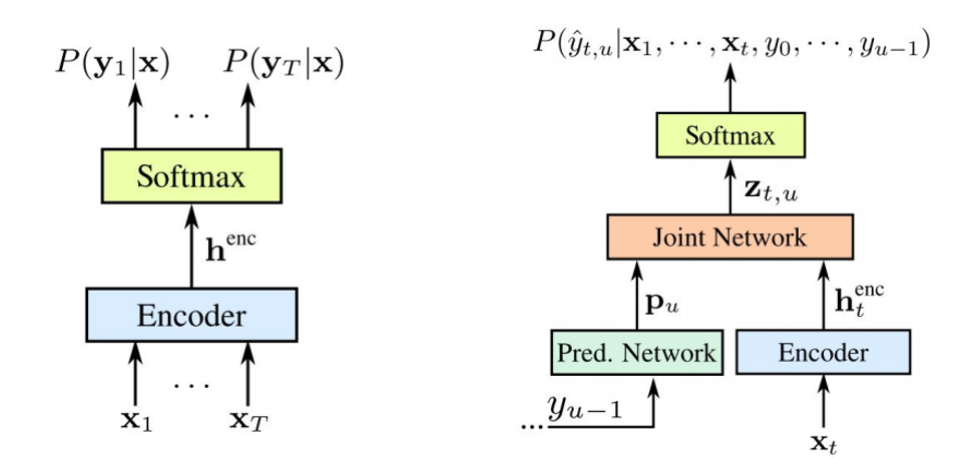
Es ist erwähnenswert, dass beide Komponenten gemeinsam auf verfügbare akustische Daten trainiert werden. Wie bei STS erfordert dieser Ansatz keine Rahmenausrichtung im Trainingsdatensatz. Wie wir auf dem Bild sehen: Links ist unser klassischer STS und rechts der RNN-Wandler. Und wir haben zwei neue Elemente - das
vorhergesagte Netzwerk und das
Join-Netzwerk .
Der STS-Encoder ist genau der gleiche - es ist der Eingangspegel RNN, der die Verteilung über alle Ausrichtungen mit allen Ausgangssequenzen bestimmt, die die Länge der Eingangssequenz nicht überschreiten - dies wurde 2006 von Graves beschrieben. Die Aufgabe solcher Text-zu-Sprache-Konvertierungen ist jedoch auch ausgeschlossen, wenn die Eingabesequenz, die länger als die Eingabesequenz des STS ist, die Beziehung zwischen den Ausgaben nicht modelliert. Der Wandler erweitert genau dieses STS, bestimmt die Verteilung der Ausgangssequenzen aller Längen und modelliert gemeinsam die Abhängigkeit von Eingabe-Ausgabe und Ausgabe-Ausgabe.
Es stellt sich heraus, dass unser Modell letztendlich in der Lage ist, die Abhängigkeiten der Ausgabe von der Eingabe und der Ausgabe von der Ausgabe des letzten Schritts zu verarbeiten.
Was ist ein
vorhergesagtes Netzwerk oder ein
vorhergesagtes Netzwerk? Sie versucht, jedes Element unter Berücksichtigung der vorherigen zu modellieren, daher ähnelt es dem Standard-RNN mit der Vorhersage des nächsten Schritts. Nur mit der zusätzlichen Fähigkeit, Nullhypothesen zu erstellen.
Wie wir auf dem Bild sehen, haben wir ein vorhergesagtes Netzwerk, das den vorherigen Wert des Ausgangs empfängt, und es gibt einen Encoder, der den aktuellen Wert des Eingangs empfängt. Und am Ausgang haben wir wieder so den aktuellen Wert
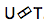
.
Neuronaler Wandler . Dies ist eine Komplikation des klassischen seq-2seq-Ansatzes. Die akustische Eingangssequenz wird vom Codierer verarbeitet, um bei jedem Zeitschritt verborgene Zustandsvektoren zu erzeugen. Es scheint alles wie gewohnt zu sein. Es gibt jedoch ein zusätzliches Transducer-Element, das bei jedem Schritt einen Block von Eingaben empfängt und bis zu M-Ausgabe-Token unter Verwendung eines Modells generiert, das auf seq-2seq über dieser Eingabe basiert. Der Wandler behält seinen Zustand in Blöcken bei, indem er periodische Verbindungen mit den vorherigen Zeitschritten verwendet.
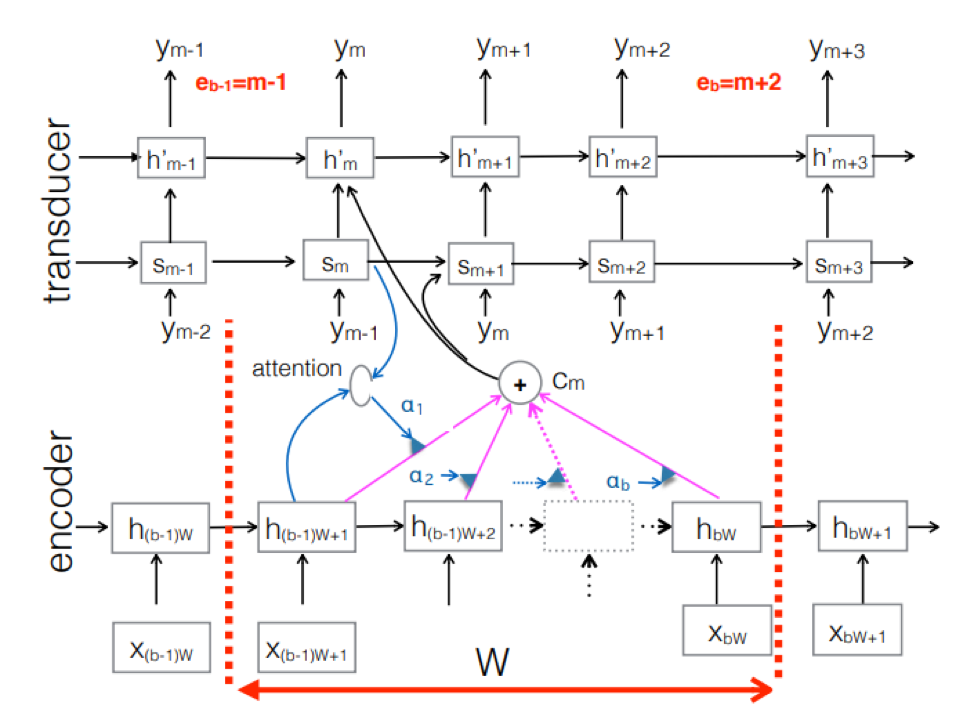 Die Abbildung zeigt den Wandler, der Token für den Block für die im Block des entsprechenden Ym verwendete Sequenz erzeugt.
Die Abbildung zeigt den Wandler, der Token für den Block für die im Block des entsprechenden Ym verwendete Sequenz erzeugt.Daher haben wir den aktuellen Status der Spracherkennung basierend auf dem End2End-Ansatz untersucht. Es ist erwähnenswert, dass diese Ansätze heute leider eine große Datenmenge erfordern. Und die tatsächlichen Ergebnisse, die mit dem klassischen Ansatz erzielt werden und 200 bis 500 Stunden Tonaufnahmen erfordern, die für das Training eines guten Modells auf der Basis von End2End vorgesehen sind, erfordern mehrere oder vielleicht zehnmal mehr Daten. Dies ist das größte Problem bei diesen Ansätzen. Aber vielleicht wird sich bald alles ändern.
Führender Entwickler des AI MTS-Zentrums Nikita Semenov.