
Hallo allerseits! Kürzlich fand ein offenes Webinar
"Bereitstellung fehlertoleranter Speicherung" statt . Es wurde untersucht, welche Probleme beim Entwurf von Architekturen auftreten, warum ein Serverausfall keine Entschuldigung für einen Serverabsturz ist und wie Ausfallzeiten auf ein Minimum reduziert werden können. Das Webinar wurde von
Ivan Remen , Leiter der Serverentwicklung bei Citimobil und Lehrer im Kurs
„High Load
Architect“, moderiert.
Warum sich mit Speicherresilienz beschäftigen?
Sie sollten über die Fehlertoleranz von skalierbarem Speicher nachdenken und die grundlegenden Caching-Probleme
beim Start verstehen. Es ist klar, dass Sie beim Schreiben eines Startups ganz am Anfang die Mindestversion des Produkts erstellen. Aber je mehr Sie wachsen, desto schneller wird die Produktivität gesteigert, was zu einem vollständigen Geschäftsstopp führen kann. Und wenn Sie Geld von Investoren erhalten, erfordern diese natürlich auch ein konstantes Wachstum und neue Geschäftsfunktionen. Um die richtige Balance zu finden, müssen Sie zwischen Geschwindigkeit und Qualität wählen. Gleichzeitig können Sie weder das eine noch das andere opfern, und wenn Sie spenden, dann bewusst und in gewissen Grenzen. Hier gibt es jedoch keine universellen Rezepte sowie ideale Lösungen.
Wir lehnen uns zum Lesen an die Basis
Dies ist das erste Szenario. Stellen Sie sich vor, wir haben 1 Server, dessen Auslastung des Prozessors oder der Festplatte 99% beträgt. Dabei:
- 90% der Anfragen werden gelesen;
- 10% der Anfragen sind ein Rekord.
Die beste Lösung in dieser Situation besteht darin, über Replikate nachzudenken. Warum? Dies ist die billigste und einfachste Lösung.
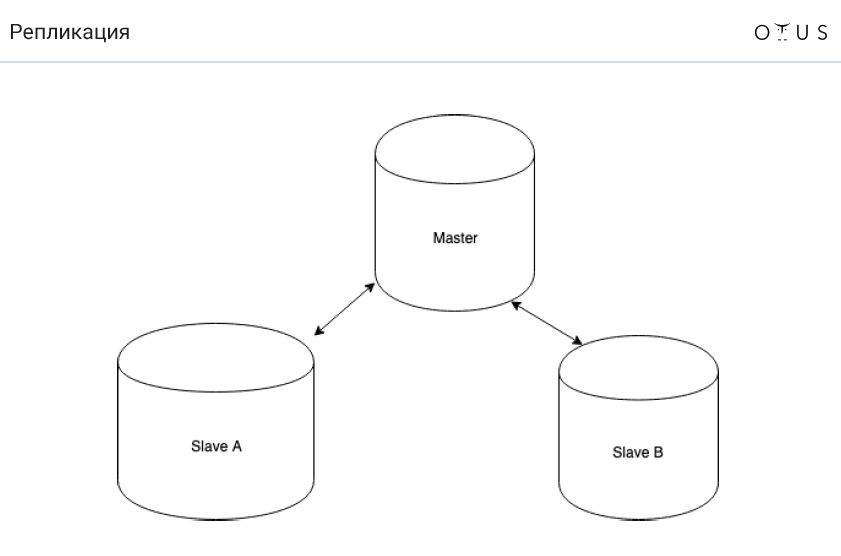
Die Replikation ist klassifiziert:
1. Durch Synchronisation:
- synchron;
- asynchron;
- halbsynchron.
2. Nach tragbaren Daten:
- logisch (zeilenbasiert, anweisungsbasiert, gemischt);
- physisch.
3. Durch die Anzahl der Knoten pro Datensatz:
- Master / Slave;
- Meister / Meister.
4. Vom Initiator:
Und jetzt
geht es um einen Eimer Wasser . Stellen Sie sich vor, wir haben MySQL und asynchrone Master-Slave-Replikation. Die Reinigung wird im DC durchgeführt, wodurch der Reiniger stolpert und einen Eimer Wasser mit der Master-Basis auf den Server schüttet. Die Automatisierung schaltet einen der neuesten Slaves erfolgreich in den Master-Modus. Und alles funktioniert weiter. Wo ist der Haken?
Die Antwort ist einfach: Wir verlieren Transaktionen, die wir nicht replizieren konnten. Folglich wird die Eigenschaft D der ACID verletzt.
Lassen Sie uns nun darüber sprechen, wie die asynchrone Replikation (MySQL) funktioniert:
- Aufzeichnen einer Transaktion in der Speicher-Engine (InnoDB);
- Aufzeichnen einer Transaktion in einem binären Protokoll;
- Transaktionsabschluss in der Speicher-Engine;
- Rückbestätigung an den Kunden;
- Übertragen eines Teils des Protokolls auf das Replikat;
- Ausführung einer Transaktion auf einem Replikat (S. 1-3).
Und jetzt stellt sich die Frage, was in den oben genannten Elementen geändert werden muss, damit wir nie mit der Replikation enden.
Und es müssen nur zwei Punkte ausgetauscht werden: 4. und 5. ("Übertragen eines Teils des Protokolls auf das Replikat" und "Zurücksenden der Bestätigung an den Client"). Wenn also der Masterknoten ausfliegt, haben wir immer irgendwo ein Transaktionsprotokoll (Punkt 2). Und wenn die Transaktion im Binärprotokoll aufgezeichnet wird, wird die Transaktion auch irgendwann stattfinden.
Als Ergebnis erhalten wir eine halbsynchrone Replikation (MySQL), die wie folgt funktioniert:
- Aufzeichnen einer Transaktion in der Speicher-Engine (InnoDB);
- Aufzeichnen einer Transaktion in einem binären Protokoll;
- Transaktionsabschluss in der Speicher-Engine;
- Übertragen eines Teils des Protokolls auf das Replikat;
- Rückbestätigung an den Kunden;
- Ausführung einer Transaktion auf einem Replikat (S. 1-3).
Sync vs Semi-Sync und Async vs Semi-Sync
Aus irgendeinem Grund haben die meisten Menschen in Russland nichts von halbsynchroner Replikation gehört. Übrigens ist es gut in PostgreSQL implementiert und nicht sehr in MySQL. Lesen Sie hier mehr darüber, aber die These kann wie folgt formuliert werden:
- Die halbsynchrone Replikation ist immer noch im Rückstand (aber nicht so stark) wie die asynchrone.
- Wir verlieren keine Transaktionen.
- Es reicht aus, die Daten nur einem Slave zuzuführen.
Übrigens wird auf Facebook die halbsynchrone Replikation verwendet.
Wir ruhen uns gegen die Rekordbasis aus
Lassen Sie uns über ein diametral entgegengesetztes Problem sprechen, wenn wir haben:
- 90% der Anfragen - Rekord;
- 10% der Anfragen werden gelesen;
- 1 Server;
- Last - 99% (Prozessor oder Festplatte).
Hier hilft bekanntes Splittern. Aber jetzt reden wir über etwas anderes:

In solchen Fällen beginnen sie sehr oft, Master-Master zu verwenden. In
dieser Situation hilft es jedoch nicht . Warum? Es ist ganz einfach: Der Datensatz auf dem Server wird nicht kleiner. Replikation bedeutet schließlich, dass auf allen Knoten Daten vorhanden sind. Bei der anweisungsbasierten Replikation wird SQL tatsächlich auf ALLEN Knoten ausgeführt. C-reihenbasiert ist etwas einfacher, aber immer noch teuer. Und auch Master-Master hat Probleme mit Konflikten.
In der Tat ist es sinnvoll, Master-Master in den folgenden Situationen zu verwenden:
- Durchschreibfehlertoleranz (die Idee ist, dass Sie immer nur an einen Master schreiben). Sie können mithilfe der virtuellen IP-Adresse implementieren.
- geoverteilte Systeme.
Denken Sie jedoch daran, dass die Master-Master-Replikation immer schwierig ist. Und oft bringt Master-Master mehr Probleme als es löst.
Scherben
Wir haben bereits Scherben erwähnt. Kurz gesagt, Sharding ist ein sicherer Weg, um einen Datensatz zu skalieren. Die Idee ist, dass wir Daten auf unabhängige (aber nicht immer) Server verteilen. Jeder Shard kann unabhängig replizieren.
Die erste Regel beim Sharding lautet, dass sich die Daten, die zusammen verwendet werden, im selben Shard befinden müssen. Hier
sharding_key -> shard_id Formel
sharding_key -> shard_id . Dementsprechend muss
sharding_key für die Daten, die zusammen verwendet werden, übereinstimmen. Die erste Schwierigkeit besteht darin, dass es für Sie sehr schwierig sein wird, alles neu zu mischen, wenn Sie den falschen
sharding_key auswählen. Zweitens, wenn Sie eine Art
sharding_key , sind einige Anforderungen sehr schwer auszuführen. Beispielsweise können Sie den Durchschnittswert nicht finden.
Um dies zu demonstrieren, stellen wir uns vor, wir haben zwei Scherben mit jeweils drei Werten: (1; 2; 3) (0; 0; 500). Der Durchschnittswert ist gleich (1 + 2 + 3 + 500) / 6 = 84,333333.
Stellen Sie sich nun vor, wir haben zwei unabhängige Server. Berechnen Sie den Durchschnittswert für jeden Splitter separat neu. Beim ersten bekommen wir 2, beim zweiten - 166.66667. Und selbst wenn wir diese Werte dann mitteln, erhalten wir immer noch eine Zahl, die von der richtigen abweicht: (2 + 166.66667) / 2 = 86.33334.
Das heißt, der
Durchschnitt der Mittel ist nicht gleich dem Durchschnitt von allem: avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))
Einfache Mathematik, aber es ist wichtig, sich daran zu erinnern.
Splitteraufgabe
Angenommen, wir haben ein Dialogsystem in einem sozialen Netzwerk. Es können nur 2 Personen in einem Dialog sein. Alle Nachrichten befinden sich in einer Tabelle, in der Folgendes enthalten ist:
- Nachrichten-ID
- Absender-ID
- Empfänger-ID
- Nachrichtentext;
- Datum, an dem die Nachricht gesendet wurde;
- einige Fahnen.
Welcher Sharding-Schlüssel sollte aufgrund der Tatsache gewählt werden, dass wir die erste oben beschriebene Sharding-Regel haben?
Es gibt verschiedene Möglichkeiten, um dieses klassische Problem zu lösen:
- crc32 (id_src // id_dst);
- crc32 (1 // 2)! = crc32 (2 // 1);
- crc32 (von + bis)% n;
- crc32 (min (von, bis). max (von, bis))% n.
Caches
Und ein paar Worte zu Caches. Wir können sagen, dass
Caches ein Antipattern sind , obwohl man mit dieser Aussage argumentieren kann (viele Leute benutzen gerne Caches). Im Großen und Ganzen werden Caches jedoch nur benötigt, um die Antwortrate zu erhöhen. Und sie können nicht so eingestellt werden, dass sie die Last halten.
Die Schlussfolgerung ist einfach - wir sollten ruhig ohne Caches leben. Der einzige Grund, warum sie möglicherweise benötigt werden, ist genau derselbe, warum sie im Prozessor benötigt werden: um die Antwortgeschwindigkeit zu erhöhen. Wenn die Datenbank der Last aufgrund des Verschwindens des Caches nicht standhält, ist dies fehlerhaft. Dies ist ein äußerst erfolgloses Architekturmuster, daher sollte dies nicht der Fall sein. Und welche Ressourcen Sie auch haben, eines Tages wird Ihr Cache sicherlich herunterfallen, was auch immer Sie tun.
Die Cache-Probleme sind These:- Beginnen Sie mit einem kalten Cache.
- Problem mit der Ungültigmachung des Caches;
- Cache-Konsistenz.
Wenn Sie weiterhin Caches verwenden, hilft Ihnen konsistentes Hashing. Auf diese Weise können verteilte Hash-Tabellen erstellt werden, bei denen der Ausfall eines oder mehrerer Speicherserver nicht dazu führt, dass alle gespeicherten Schlüssel und Werte vollständig verschoben werden müssen. Hier können Sie jedoch mehr darüber lesen.

Danke fürs Zuschauen! Um nichts von der letzten Vorlesung zu verpassen, ist es besser,
das gesamte Webinar anzuschauen .