In diesem Artikel werde ich Ihnen am Beispiel der Entwicklung meines Projekts die Geschichte des Übergangs und die Vision der Vertragsprogrammierung erläutern.
Zuerst wollte ich den Artikel „Vertragsprogrammierung“ nennen, sofern der verwendete Ansatz darin besteht, die gesamte Geschäftslogik in Datenverträge und Service-Clients zu unterteilen, die diese Verträge verwenden und über diese Datenstrukturen miteinander interagieren, so dass dies auch der Fall ist Die Struktur wird erfolgreich in verschiedenen Diensten verarbeitet.
Etwas, das ich in meiner eigenen Sprache beschreiben werde.
Die Geschichte meines Übergangs zur Vertragsprogrammierung begann mit der Tatsache, dass ich ein überwachsenes Legacy-Projekt mit einer Vielzahl unterschiedlicher Funktionen innerhalb desselben Geschäftsbereichs hatte. Außerdem war dies immer noch Multithreading und Anpassung für verschiedene Kunden. Der Geschäftsbereich war insbesondere der Austausch elektronischer rechtlich relevanter Dokumente zwischen Buchhaltungssystem, Datei- und Cloud-Diensten.
Während der Entwicklung des Systems traten neue Geschäftsanforderungen auf, und infolgedessen entwickelte sich das Projekt schnell und wurde durch neue Funktionen kompliziert, was zu einer Situation führte, in der die Architektur des Projekts mehreren separaten Anwendungen mit verwandten Funktionen ähnelte. Nur diese Funktionalität wurde implementiert, nicht aus gemeinsamen Elementen, sondern aus ähnlichen, aber unterschiedlich implementierten Strukturen in verschiedenen Assemblys und Namespaces.
Visuell kann eine solche Architektur als mehrere Funktionsbereiche dargestellt werden
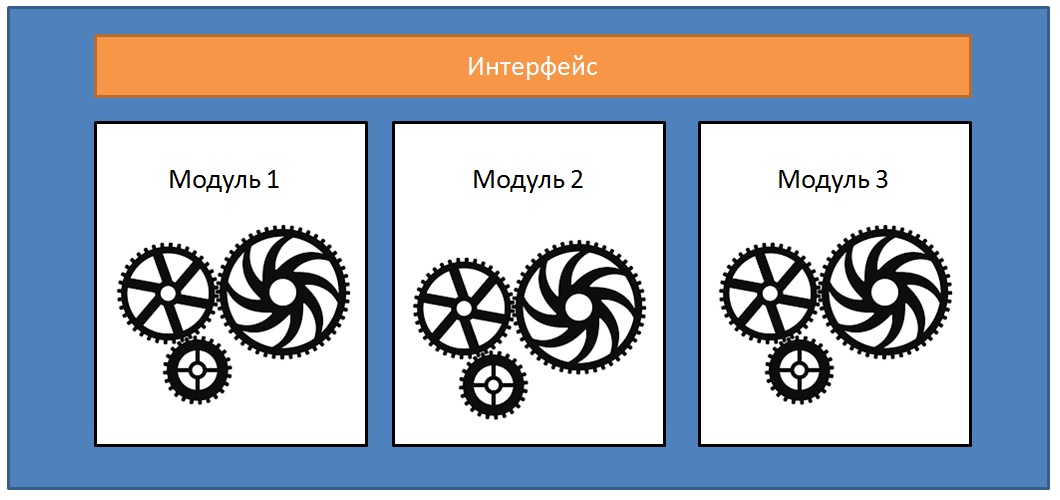
Ein charakteristisches Merkmal einer solchen Architektur war, dass, wenn zusätzliche Anforderungen oder Fehler auftraten, eine solche Aufgabe in allen „Funktionsmodulen“ des Systems und nicht in einem Bereich implementiert werden musste. Ein weiteres charakteristisches Merkmal war die Präsenz einer großen Anzahl von Bauherren im Projekt, die zu einer solchen vertikalen Aufteilung des Geschäftsbereichs führte. Der Entwickler implementiert neue Algorithmen für neue Geschäftsanforderungen in den Code von Buildern, was zur Entstehung neuer Entitäten mit unterschiedlichen Strukturen für dasselbe Geschäftsobjekt führt. Zugegebenermaßen kann dieser Ansatz als objektorientierter angesehen werden als ein einfacher Code-Behind-Ansatz mit Spaghetti-Code. Wenn Sie also eine große Anzahl von Buildern in Ihren Projekten sehen, vereinfacht der Übergang zu einem Kontaktansatz die Unterstützung und beschleunigt die Entwicklung Ihres Projekts.
Einmal im Unternehmen wurden wir mit der Tatsache konfrontiert, dass der Kunde, mit dem wir implementierten, zum Ausdruck brachte, dass das von mir entwickelte System häufig Fehler verursachte. Ich konnte nicht damit streiten, obwohl Fehler regelmäßig auftraten, aber sie wurden behoben und einige der Clients hatten das System installiert und verwendeten es. Ich muss mich bei Ihnen bedanken, dass der Client schädlich und wählerisch war und unser System während des Implementierungszeitraums sehr sorgfältig getestet hat.
Ich selbst mochte auch nicht die Tatsache, dass ich trotz vieler Bemühungen nicht genug Zeit für Entwicklung und Support hatte, und irgendwann hatte ich einfach keine Ahnung, was das System sonst noch verbessern und stabiler machen könnte.
Die Entscheidung kam plötzlich und unerwartet.
Ich habe gut verstanden, dass dieselben Geschäftsobjekte in verschiedenen Modulen des Systems unterschiedlich implementiert sind - Dokumente verschiedener Typen, Belege, Mitarbeiter, Service-Clients, Datenbank-Clients, Datei-Clients mit der Fähigkeit, Dokumente in verschiedenen Formaten zu speichern (Anpassung für verschiedene Clients;) )
Ein Teil der Logik wurde in Entitäten implementiert, wodurch die Verwendung derselben Entitäten in verschiedenen Algorithmen verhindert wurde.
Dann entschied ich mich - es war notwendig, so etwas wie einen einzelnen Konstruktor mit Details zu erstellen, aus denen alle im System implementierten Algorithmen zusammengesetzt werden können. Das ist logisch, weil es die Anzahl ähnlicher Klassen reduziert und die Unterstützung vereinfacht.
Ich beschloss, das "Universum" meiner Anwendung streng zu unterteilen
- Datenverträge - Datenstrukturen, die Datenspeicher enthalten und nur zur Datenspeicherung verwendet werden
Docs
Umschläge
Quittungen
EP
...
- Kunden-Services - Ich schreibe speziell, dass Kunden Services sind, da ich bei der Implementierung jedes Systems, das im Geschäftsbereich interagierte, dieses als Umschlag für dieses System darstellte, in dem die Methoden für die Arbeit mit Datumsverträgen implementiert wurden. Neben der Tatsache, dass diese Klassen Wrapper über Services sind, enthielten sie auch die erforderliche Bindungslogik, Konvertierungen und Transformationen, um die Geschäftslogik zu vereinfachen
Außerdem hielten sich Logger an diesen Clients fest. So konnten Sie den Fehlerpunkt schnell im Protokoll finden. (In Zukunft verschwanden viele Anrufe, als die Benutzer anhand der Protokolle zu verstehen begannen, wo sie einen Fehler hatten - ein Dateisystem, ein Netzwerk, ein Buchhaltungssystem oder ein Webdienst des Betreibers.)
Zum Beispiel
CloudClient - ein Client eines Cloud-Dienstes, an den Dokumente gesendet und verarbeitet werden
- Herunterladen
- senden
- Holen Sie sich
- Herunterladen
- Stimme zu
...
FileSystemClient - Dateisystem-Client
ERPClient - Kundenbuchhaltungssystem
Die Clients implementierten alle zuvor in den Algorithmen verwendeten Methoden in allen Modulen, wodurch es möglich wurde, neu implementierte Algorithmen aus denselben Teilen schnell und einfach zu implementieren.
Die Zuweisung ähnlicher Funktionsmethoden in den jeweiligen Clients führte zu einer stärkeren Spezialisierung und Wiederverwendung des Codes.
Architektur war jetzt ein Diagramm wie auf dem Bild
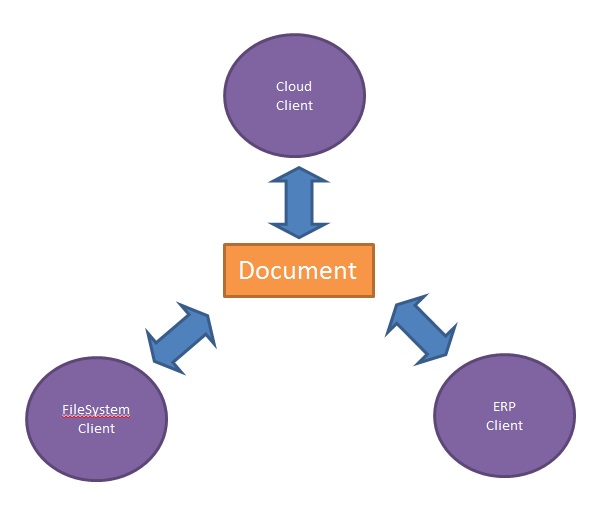
Mit dem Ende des SDK (Software Developers Kit) habe ich alle grundlegenden Objekte meines Designers der Baugruppe zugewiesen, und es wurde einfacher zu arbeiten und vor allem angenehmer. Die Arbeit hat bereits aufgehört, Krücken und temporäre Lösungen zu schaffen, und jetzt ist die Einstellung zum Projekt von innen ernster geworden, weil ich jetzt einen großen Spielraum für Skalierbarkeit und Wettbewerbsfähigkeit der Architektur gesehen habe. Dies liegt daran, dass eine solche Tatsache die Motivation erheblich steigerte und neue berufliche Horizonte eröffnete.
Basierend auf dem erstellten SDK habe ich eine Schicht Geschäftslogik implementiert, die die Implementierung direkter Geschäftsaufgaben automatisiert. Da alle technischen Nuancen in die unteren Schichten der Clients gebracht wurden, wurde die Implementierung derselben Algorithmen vereinfacht und sah viel angenehmer aus.
Der Ansatz ist einfach und ermöglicht eine Vereinfachung der Weiterentwicklung. Wichtig ist, die Flexibilität der Architektur zu erhöhen. Ja, dies erfordert ein umfangreiches Refactoring. In meinem Fall dauerte die Entwicklung im fanatischen Modus 2 Wochen. Aber danach habe ich fast nicht mehr codiert, weil alles stabil funktioniert hat.
Dank der Trennung von Verantwortlichkeiten (SPR) und Protokollen konnte ich Fehler von Diensten von Drittanbietern schnell unterdrücken, was zu Fehlern auf meiner Seite führte. Zuvor waren dafür Analysen erforderlich, die viel Zeit in Anspruch nahmen.
Dieser Ansatz eignet sich gut für bestimmte Ebenen. Auf höheren Ebenen der Anwendung kann ein anämisches Modell bequemer sein, nur ist es besser, ein anämisches Modell zu implementieren, das auf einem vertraglichen Ansatz basiert.