Mein Name ist Azat Razetdinov, ich bin seit 12 Jahren in Yandex und leite den Schnittstellenentwicklungsservice in Y. Real Estate. Heute möchte ich über ein Monorepository sprechen. Wenn Sie nur ein Repository am Werk haben - herzlichen Glückwunsch, leben Sie bereits in einem einzigen Repository. Nun darüber, warum andere es brauchen.
Laut Marina Pereskokova, der Leiterin des Yandex.Mart API-Entwicklungsdienstes, hat mein Großvater eine Monorepa gepflanzt, und eine Monorepa ist groß geworden.
- Wir bei Yandex haben verschiedene Arten der Arbeit mit mehreren Diensten ausprobiert und festgestellt - sobald Sie mehr als einen Dienst haben, werden unweigerlich gemeinsame Teile angezeigt: Modelle, Dienstprogramme, Tools, Codeteile, Vorlagen, Komponenten. Die Frage ist: Wo soll das alles hingelegt werden? Natürlich können Sie kopieren und einfügen, wir können es tun, aber ich möchte es schön.
Wir haben sogar eine Entität wie SVN externals für diejenigen ausprobiert, die sich erinnern. Wir haben Git-Submodule ausprobiert. Wir haben npm-Pakete ausprobiert, als sie erschienen. Aber das alles war irgendwie lang oder so. Sie unterstützen jedes Paket, finden einen Fehler und nehmen Korrekturen vor. Dann müssen Sie eine neue Version veröffentlichen, die Dienste durchgehen, auf diese Version aktualisieren, überprüfen, ob alles funktioniert, die Tests ausführen, den Fehler finden, zum Bibliotheksrepository zurückkehren, den Fehler beheben, die neue Version freigeben, die Dienste durchgehen, aktualisieren und so weiter Kreis. Es wurde einfach zu Schmerz.

Dann überlegten wir, ob wir in einem Repository zusammenkommen sollten. Nehmen Sie alle unsere Dienste und Bibliotheken, übertragen und entwickeln Sie sie in einem Repository. Es gab viele Vorteile. Ich sage nicht, dass dieser Ansatz ideal ist, aber aus Sicht des Unternehmens und sogar der Abteilung mehrerer Gruppen ergeben sich erhebliche Vorteile.
Für mich persönlich ist das Wichtigste die Atomizität der Commits, dass ich als Entwickler die Bibliothek reparieren, alle Dienste umgehen, Änderungen vornehmen, Tests ausführen, überprüfen kann, ob alles funktioniert, sie in den Master übertragen und all dies mit einer Änderung. Sie müssen nichts neu erstellen, veröffentlichen oder aktualisieren.
Aber wenn alles so gut ist, warum sind noch nicht alle in das Mono-Repository umgezogen? Natürlich gibt es auch Nachteile.

Laut Marina Pereskokova, der Leiterin des Yandex.Map API-Entwicklungsdienstes, hat mein Großvater eine Monorepa gepflanzt, und eine Monorepa ist groß geworden. Dies ist eine Tatsache, kein Witz. Wenn Sie viele Dienste in einem einzigen Repository sammeln, wächst es unweigerlich. Und wenn es sich um Git handelt, das alle Dateien sowie deren gesamten Verlauf für die gesamte Existenz Ihres Codes abruft, ist dies ein ziemlich großer Speicherplatz.
Das zweite Problem ist die Injektion in den Master. Sie haben eine Poolanfrage vorbereitet, eine Überprüfung durchlaufen und sind bereit, sie zusammenzuführen. Und es stellt sich heraus, dass es jemandem gelungen ist, vor Ihnen zu kommen, und Sie Konflikte lösen müssen. Sie haben die Konflikte gelöst, waren wieder bereit, sich darauf einzulassen, und hatten erneut keine Zeit. Dieses Problem wird gelöst, es gibt Zusammenführungswarteschlangensysteme, wenn ein spezieller Roboter diese Arbeit automatisiert, Poolanforderungen verfolgt und versucht, Konflikte zu lösen, wenn dies möglich ist. Wenn er nicht kann, ruft er den Autor an. Ein solches Problem besteht jedoch. Es gibt Lösungen, die dies ausgleichen, aber Sie müssen dies berücksichtigen.
Dies sind technische, aber auch organisatorische Punkte. Angenommen, Sie haben mehrere Teams, die verschiedene Dienste erbringen. Wenn sie in ein einzelnes Repository wechseln, beginnt ihre Verantwortung zu schwinden. Weil sie eine Veröffentlichung gemacht haben, die in der Produktion eingeführt wurde - etwas ist kaputt gegangen. Wir beginnen mit der Nachbesprechung. Es stellt sich heraus, dass es sich um einen Entwickler eines anderen Teams handelt, der etwas für den allgemeinen Code festgelegt hat. Wir haben es gezogen, unveröffentlicht, nicht gesehen, alles ist kaputt gegangen. Und es ist nicht klar, wer dafür verantwortlich ist. Es ist wichtig, alle möglichen Methoden zu verstehen und anzuwenden: Komponententests, Integrationstests, Linter - alles, was möglich ist, um dieses Problem des Einflusses eines Codes auf alle anderen Dienste zu verringern.
Interessanterweise nutzt außer Yandex und anderen Spielern noch jemand das Mono-Repository? Sehr viele Leute. Dies sind React, Jest, Babel, Ember, Meteor, Angular. Die Leute verstehen - es ist einfacher, billiger und schneller, npm-Pakete aus einem einzigen Repository zu entwickeln und zu veröffentlichen als aus mehreren kleinen Repositorys. Das Interessanteste ist, dass sich zusammen mit diesem Prozess Werkzeuge für die Arbeit mit einem Monorepository entwickelten. Nur über sie und ich möchte reden.
Alles beginnt mit der Erstellung eines Monorepositorys. Das weltweit bekannteste Front-End-Tool dafür heißt lerna.

Öffnen Sie einfach Ihr Repository, führen Sie npx lerna init aus. Es werden Ihnen einige interessante Fragen gestellt und Ihrer Arbeitskopie einige Entitäten hinzugefügt. Die erste Entität ist die Konfiguration lerna.json, die mindestens zwei Felder angibt: die End-to-End-Version aller Ihrer Pakete und den Speicherort Ihrer Pakete im Dateisystem. Standardmäßig werden alle Pakete zum Paketordner hinzugefügt, aber Sie können dies nach Belieben konfigurieren, Sie können sie sogar zum Stammverzeichnis hinzufügen, lerna kann es auch abholen.
Der nächste Schritt ist, wie Sie Ihre Repositorys zum Mono-Repository hinzufügen und wie Sie sie übertragen.
Was wollen wir erreichen? Höchstwahrscheinlich haben Sie bereits eine Art Repository, in diesem Fall A und B.

Dies sind zwei Dienste, jeder in seinem eigenen Repository, und wir möchten sie in das neue Mono-Repository im Paketordner übertragen, vorzugsweise mit einem Verlauf von Commits, damit Sie Git-Schuld, Git-Protokoll usw. machen können.

Hierfür gibt es ein Herna-Import-Tool. Sie geben einfach den Speicherort Ihres Repositorys an und lerna überträgt ihn an Ihren Monorepo. Gleichzeitig erstellt sie zunächst eine Liste aller Commits, ändert jedes Commit, ändert den Pfad zu den Dateien vom Stammverzeichnis zu packages / package_name, wendet sie nacheinander an und überlagert sie in Ihrem Mono-Repository. Tatsächlich wird jedes Commit vorbereitet und die darin enthaltenen Dateipfade geändert. Im Wesentlichen macht Herna Git-Magie für Sie. Wenn Sie den Quellcode lesen, werden dort einfach Git-Befehle in einer bestimmten Reihenfolge ausgeführt.
Dies ist der erste Weg. Es hat einen Nachteil: Wenn Sie in einem Unternehmen arbeiten, in dem es Produktionsprozesse gibt, in dem bereits Code geschrieben wird, und Sie diese in einen Monorep übersetzen, ist es unwahrscheinlich, dass Sie dies an einem Tag tun. Sie müssen herausfinden, konfigurieren, überprüfen, ob alles startet, testen. Aber die Leute haben keine Arbeit, sie machen weiter etwas.

Für einen reibungsloseren Übergang zu Mono-Rap gibt es ein Tool wie den Git-Teilbaum. Dies ist eine komplexere Sache, aber gleichzeitig in git integriert, wodurch Sie nicht nur einzelne Repositorys mit einem Präfix in ein Mono-Repository importieren, sondern auch Änderungen hin und her austauschen können. Das heißt, das Team, das den Service erstellt, kann problemlos in seinem eigenen Repository weiterentwickelt werden, während Sie die Änderungen durch das Ziehen von Git-Teilbäumen abrufen, Ihre eigenen Änderungen vornehmen und sie durch das Drücken von Git-Teilbäumen zurückschieben können. Und leben Sie in der Übergangszeit so lange, wie Sie möchten.
Wenn Sie alles eingerichtet und überprüft haben, ob alle Tests ausgeführt werden, die Bereitstellung funktioniert, das gesamte CI / die gesamte CD konfiguriert ist, können Sie sagen, dass es Zeit ist, fortzufahren. Für die Übergangszeit empfehle ich eine tolle Lösung.
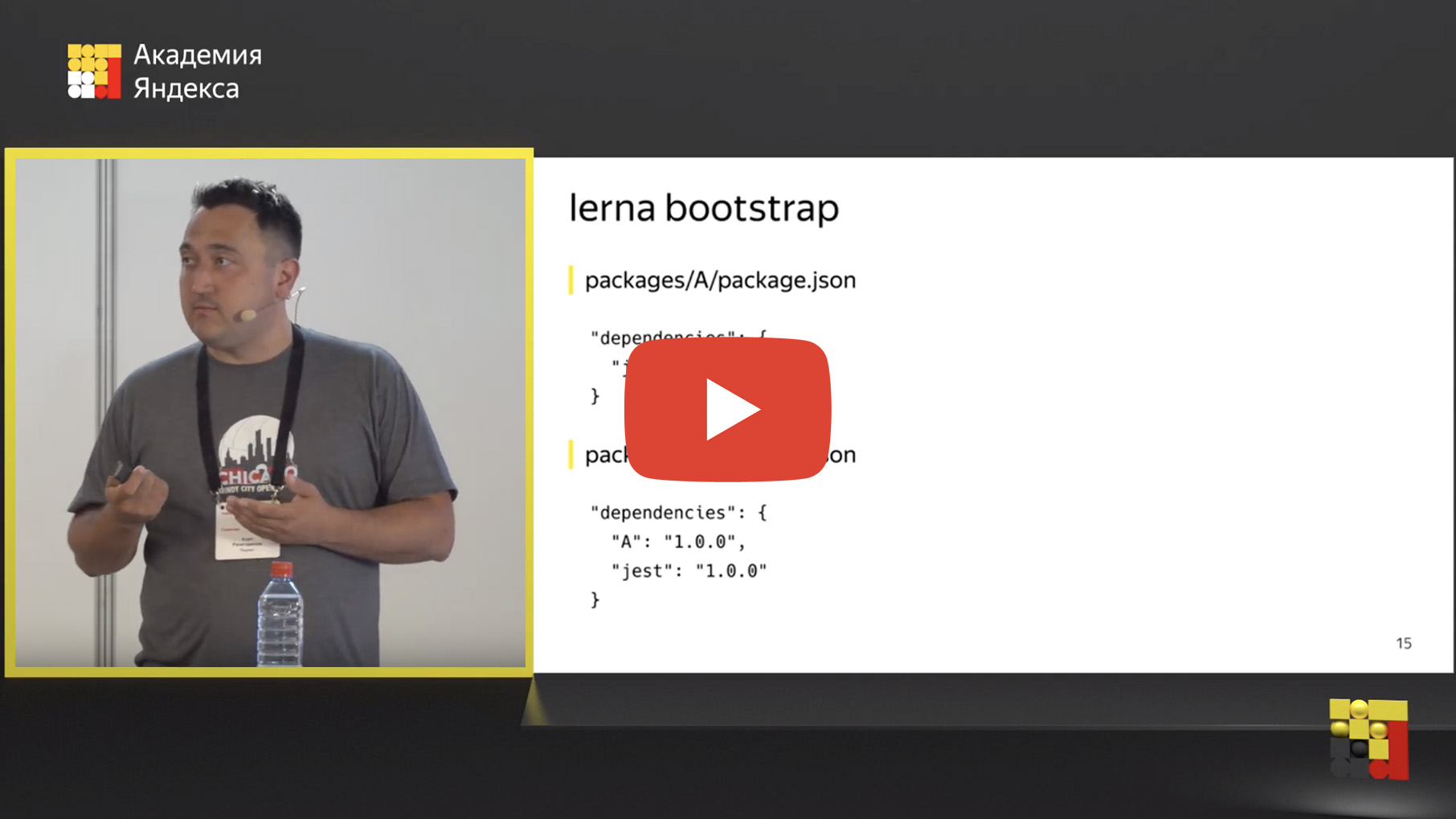
Nun, wir haben unsere Repositories in ein Mono-Repository verschoben, aber wo ist die Magie irgendwo? Aber wir wollen die gemeinsamen Teile hervorheben und sie irgendwie verwenden. Und dafür gibt es einen "Abhängigkeitsbindungsmechanismus". Was ist Abhängigkeitsbindung? Es gibt ein lerna-Bootstrap-Tool, ein Befehl, der der npm-Installation ähnelt und nur die npm-Installation in all Ihren Paketen ausführt.

Aber das ist noch nicht alles. Darüber hinaus sucht sie nach internen Abhängigkeiten. Sie können ein anderes in einem Paket in Ihrem Repository verwenden. Wenn Sie beispielsweise Paket A haben, das in diesem Fall von Jest abhängt, gibt es Paket B, das von Jest und Paket A abhängt. Wenn Paket A ein allgemeines Tool ist, eine gemeinsame Komponente, dann ist Paket B ein Dienst, der es hat verwendet.
Lerna definiert solche internen Abhängigkeiten und ersetzt diese Abhängigkeit physisch durch eine symbolische Verknüpfung im Dateisystem.


Nachdem Sie lerna bootstrap direkt im Ordner node_modules anstelle des physischen Ordners A ausgeführt haben, wird ein symbolischer Link angezeigt, der zum Ordner mit Paket A führt. Dies ist sehr praktisch, da Sie den Code in Paket A bearbeiten und das Ergebnis in Paket B sofort überprüfen können , führen Sie Tests, Integration, Einheiten, was auch immer Sie wollen. Die Entwicklung ist stark vereinfacht. Sie müssen Paket A nicht mehr neu zusammensetzen, veröffentlichen und Paket B verbinden. Es wurde nur hier behoben und dort überprüft.
Bitte beachten Sie, dass wir das installierte Modul dupliziert haben, wenn Sie sich die Ordner node_modules ansehen und dort und dort ein Scherz ist. Im Allgemeinen dauert es ziemlich lange, bis Sie lerna bootstrap starten und warten, bis alles aufhört, da es jede Menge wiederholter Arbeiten gibt. In jedem Paket werden doppelte Abhängigkeiten erhalten.
Um die Installation von Abhängigkeiten zu beschleunigen, wird der Mechanismus zum Auslösen von Abhängigkeiten verwendet. Die Idee ist sehr einfach: Sie können die allgemeinen Abhängigkeiten zu den Stammknotenmodulen übernehmen.

Wenn Sie die Option --hoist angeben (dies ist ein Upgrade von Englisch), werden fast alle Abhängigkeiten einfach in die Stammknotenmodule verschoben. Und es funktioniert fast immer. Noda ist so arrangiert, dass sie, wenn sie die Abhängigkeiten auf ihrer Ebene nicht gefunden hat, beginnt, eine Ebene höher zu suchen, wenn nicht dort, eine andere Ebene höher und so weiter. Fast nichts ändert sich. Tatsächlich haben wir unsere Abhängigkeiten übernommen und dedupliziert und die Abhängigkeiten an die Wurzel übertragen.
Gleichzeitig ist lerna klug genug. Wenn es einen Konflikt gibt, zum Beispiel wenn Paket A Jest Version 1 und Paket B Version 2 verwendet, wird einer von ihnen angezeigt und der zweite bleibt auf seiner Ebene. Dies ist ungefähr das, was npm tatsächlich im normalen Ordner node_modules tut. Es versucht auch, Abhängigkeiten zu deduplizieren und sie maximal zum Stamm zu übertragen.
Leider funktioniert diese Magie nicht immer, besonders bei Werkzeugen, bei Babel, bei Jest. Es kommt oft vor, dass er startet, weil Jest ein eigenes System zum Auflösen von Modulen hat, Noda anfängt zu verzögern, einen Fehler zu werfen. Insbesondere in solchen Fällen, in denen das Tool die Abhängigkeiten, die zum Stammverzeichnis gegangen sind, nicht bewältigt, gibt es die Option nohoist, mit der Sie darauf hinweisen können, dass diese Pakete nicht zum Stammverzeichnis übertragen werden, sondern an Ort und Stelle bleiben.

Wenn Sie --nohoist = jest angeben, werden alle Abhängigkeiten außer jest an den Stamm gesendet, und jest bleibt auf Paketebene. Kein Wunder, dass ich ein solches Beispiel gegeben habe - es ist ein Scherz, der Probleme mit diesem Verhalten hat, und Nohoist hilft dabei.
Ein weiteres Plus der Abhängigkeitswiederherstellung:

Wenn Sie zuvor für jeden Dienst, für jedes Paket, eine separate package-lock.json hatten, wird beim Hochfahren alles nach oben verschoben, und die einzige package-lock.json bleibt erhalten. Dies ist unter dem Gesichtspunkt des Eingießens in den Master und der Lösung von Konflikten praktisch. Sobald alle getötet wurden, und das war's.
Aber wie erreicht lerna das? Sie ist ziemlich aggressiv mit npm. Wenn Sie hoist angeben, wird Ihre package.json im Stammverzeichnis gespeichert, gesichert, durch eine andere ersetzt, alle Ihre Abhängigkeiten darin zusammengefasst, npm install ausgeführt und fast alles im Stammverzeichnis abgelegt. Dann wird dieses temporäre package.json entfernt und Ihr wiederhergestellt. Wenn Sie danach einen Befehl mit npm ausführen, z. B. npm remove, wird npm nicht verstehen, was passiert ist, warum plötzlich alle Abhängigkeiten im Stammverzeichnis angezeigt wurden. Lerna verletzt die Abstraktionsebene, sie kriecht in das Werkzeug, das unter ihrer Ebene liegt.
Die Jungs von Yarn waren die ersten, die dieses Problem bemerkten und sagten: Was quälen wir, lassen Sie uns alles für Sie tun, damit alles sofort funktioniert.

Garn kann bereits das Gleiche sofort tun: Abhängigkeiten binden. Wenn er sieht, dass Paket B von Paket A abhängt, erstellt er kostenlos einen Symlink für Sie. Er weiß, wie man Abhängigkeiten aufwirft, macht es standardmäßig, alles summiert sich zur Wurzel. Wie bei lerna kann es die einzige Garnverriegelung im Stammverzeichnis des Repositorys belassen. Alle anderen Garn.Lock brauchen Sie nicht mehr.

Es ist auf ähnliche Weise konfiguriert. Leider geht Garn davon aus, dass alle Einstellungen zu package.json hinzugefügt wurden. Ich weiß, dass es Leute gibt, die versuchen, alle Einstellungen der Werkzeuge von dort wegzunehmen, wobei nur ein Minimum übrig bleibt. Leider hat Garn noch nicht gelernt, dies in einer anderen Datei anzugeben, nur in package.json. Es gibt zwei neue Optionen, eine neue und eine obligatorische. Da davon ausgegangen wird, dass das Root-Repository niemals veröffentlicht wird, muss für Garn private = true angegeben werden.
Die Einstellungen für Arbeitsbereiche werden jedoch in derselben Taste gespeichert. Die Einstellung ist den Lerna-Einstellungen sehr ähnlich, es gibt ein Paketfeld, in dem Sie den Speicherort Ihrer Pakete angeben, und es gibt eine Nohoist-Option, die der Nohoist-Option in Lerna sehr ähnlich ist. Geben Sie einfach diese Einstellungen an und erhalten Sie die gleiche Struktur wie in lerna. Alle gängigen Abhängigkeiten gingen an die Wurzel, und die im Nohoist-Schlüssel angegebenen blieben auf ihrer Ebene.

Das Beste daran ist, dass lerna mit Garn arbeiten und seine Einstellungen übernehmen kann. Es reicht aus, zwei Felder in lerna.json anzugeben. Lerna wird sofort verstehen, dass Sie Garn verwenden, in package.json gehen, alle Einstellungen von dort abrufen und mit ihnen arbeiten. Diese beiden Tools kennen sich bereits und arbeiten zusammen.

Und warum wurde bei npm noch keine Unterstützung geleistet, wenn so viele große Unternehmen ein Mono-Repository verwenden?

Sie sagen, dass alles sein wird, aber in der siebten Version. Grundlegende Unterstützung im siebten, erweitert - im achten. Dieser Beitrag wurde vor einem Monat veröffentlicht, aber gleichzeitig ist das Datum noch nicht bekannt, an dem die siebte npm veröffentlicht wird. Wir warten darauf, dass er endlich das Garn einholt.
Wenn Sie mehrere Dienste in einem Mono-Repository haben, stellt sich unweigerlich die Frage, wie diese verwaltet werden sollen, um nicht zu jedem Ordner zu wechseln und keine Befehle auszuführen. Dafür gibt es massive Operationen.


Garn hat einen Garnarbeitsbereichsbefehl, gefolgt vom Namen des Pakets und dem Namen des Befehls. Da Garn aus der Box im Gegensatz zu npm alle drei Dinge tun kann: eigene Befehle ausführen, eine Abhängigkeit von Scherz hinzufügen, Skripte aus package.json wie test ausführen und auch ausführbare Dateien aus dem Ordner node_modules / .bin ausführen. Er wird mit Hilfe von Heuristiken für Sie unterrichten, er wird verstehen, was Sie wollen. Es ist sehr praktisch, den Garnarbeitsbereich für Punktoperationen an einem Paket zu verwenden.
Es gibt einen ähnlichen Befehl, mit dem Sie einen Befehl für alle vorhandenen Pakete ausführen können.

Geben Sie nur Ihre Befehle mit allen Argumenten an.

Von den Profis ist es sehr praktisch, verschiedene Teams zu leiten. Von den Minuspunkten ist es beispielsweise unmöglich, Shell-Befehle auszuführen. Angenommen, ich möchte alle Ordner der Knotenmodule löschen. Ich kann keine Garnarbeitsbereiche ausführen, die rm ausführen.
Es ist nicht möglich, eine Liste von Paketen anzugeben. Ich möchte beispielsweise die Abhängigkeit in nur zwei Paketen entfernen, jeweils nur in einem oder separat.
Nun, er stürzt beim ersten Fehler ab. Wenn ich die Abhängigkeit von allen Paketen entfernen möchte - und tatsächlich haben nur zwei von ihnen sie, aber ich möchte nicht darüber nachdenken, wo sie sich befindet, sondern ich möchte sie nur entfernen -, lässt das Garn dies nicht zu, es stürzt in der ersten Situation ab wo dieses Paket nicht in den Abhängigkeiten ist. Dies ist nicht sehr praktisch. Manchmal möchten Sie Fehler ignorieren und alle Pakete durchlaufen.

Lerna hat ein viel interessanteres Toolkit, es gibt zwei separate Run- und Exec-Befehle. Run kann Skripte aus package.json ausführen und im Gegensatz zu Garn alles nach Paket filtern. Sie können --scope angeben, Sie können Sternchen und Globs verwenden, alles ist ziemlich universell. Sie können diese Vorgänge parallel ausführen und Fehler über den Schalter --no-jail ignorieren.

Exec ist sehr ähnlich. Im Gegensatz zu Garn können Sie damit nicht nur ausführbare Dateien aus node_modules.bin ausführen, sondern auch beliebige Shell-Befehle ausführen. Sie können beispielsweise node_modules entfernen oder make ausführen, was immer Sie möchten. Und die gleiche Option wird unterstützt.

Sehr praktische Werkzeuge, einige Pluspunkte. Dies ist der Fall, wenn Lerna Garn zerreißt und sich auf der richtigen Abstraktionsebene befindet. Genau das braucht lerna: vereinfachen sie die arbeit mit mehreren paketen in monorepe.
Bei Monoreps gibt es noch ein Minus. Wenn Sie eine CI / CD haben, können Sie diese nicht optimieren. Je mehr Dienste Sie haben, desto länger dauert alles. Angenommen, Sie testen alle Services für jede Poolanforderung. Je mehr Services vorhanden sind, desto länger dauert die Arbeit. Selektive Operationen können verwendet werden, um diesen Prozess zu optimieren. Ich werde drei verschiedene Arten nennen. Die ersten beiden können nicht nur in Monorep, sondern auch in Ihren Projekten verwendet werden, wenn Sie diese Methoden aus irgendeinem Grund nicht verwenden.
Das erste sind Flusenstufen, mit denen Sie Linter, Tests und alles, was Sie wollen, nur für Dateien ausführen können, die sich geändert haben oder in diesem Commit festgeschrieben werden. Führen Sie die gesamten Flusen nicht für Ihr gesamtes Projekt aus, sondern nur für die Dateien, die sich geändert haben.


Das Setup ist sehr einfach. Setzen Sie fusselförmige, heisere Pre-Commit-Hooks und sagen Sie, dass Sie beim Ändern einer js-Datei eslint ausführen müssen. Somit wird die Prüfung vor dem Festschreiben stark beschleunigt. Besonders wenn Sie viele Dienste haben, ein sehr großes Mono-Repository. Dann ist es zu teuer, eslint für alle Dateien auszuführen, und Sie können auf diese Weise Pre-Commit-Hooks für Lint optimieren.

Wenn Sie Tests auf Jest schreiben, stehen auch Tools zum selektiven Ausführen von Tests zur Verfügung.

Mit dieser Option können Sie eine Liste der Quelldateien erstellen und alle Tests finden, die sich auf die eine oder andere Weise auf diese Dateien auswirken. Was kann in Verbindung mit Fusseln verwendet werden? Bitte beachten Sie, dass ich hier nicht alle js-Dateien spezifiziere, sondern nur die Quelle. Wir schließen die js-Dateien selbst mit Tests darin aus, wir betrachten nur die Quelle. Wir starten findRelatedTests und beschleunigen den Lauf der Einheit erheblich, um sie nach Ihren Wünschen vorab festzulegen oder vorab zu pushen.
Und die dritte Methode ist mit Monorepositories verbunden. Dies ist lerna, die bestimmen kann, welche Pakete sich im Vergleich zum Basis-Commit geändert haben. Hier geht es eher nicht um Hooks, sondern um Ihr CI / CD: Travis oder einen anderen Dienst, den Sie verwenden.


Die Befehle run und exec haben die Option Since, mit der Sie jeden Befehl nur in den Paketen ausführen können, die sich seit einer Art Festschreibung geändert haben. In einfachen Fällen können Sie einen Assistenten angeben, wenn Sie alles hineingießen. Wenn Sie genauer wollen, ist es besser, das Basis-Commit Ihrer Pool-Anfrage über Ihr CI / CD-Tool anzugeben. Dies ist ein ehrlicherer Test.
Da lerna alle Abhängigkeiten in den Paketen kennt, kann es auch indirekte Abhängigkeiten erkennen. Wenn Sie die Bibliothek A ändern, die in der Bibliothek B verwendet wird, die in Dienst C verwendet wird, wird lerna dies verstehen.
Angenommen, Sie ändern den Code in Bibliothek A. Anschließend wird transitiv festgelegt, dass Paket C getestet werden muss - beispielsweise mithilfe des von Ihnen geschriebenen Integrationstests. Und lerna führt diesen Befehl für Paket C aus.Hier sind einige Links, die nützlich sein können: die lerna-Website , eine Empfehlung zu Garnarbeitsbereichen und eine theoretische Beschreibung der Vor- und Nachteile eines Monorepositorys im Prinzip., . , . . ? , , , . , , . , - . , Babel. , , . . , .
Ich möchte mich bei meinen Kollegen bedanken : Mischa Mischanga Troshev und Gosha Besedin. Sie haben viel Zeit damit verbracht, die Tools zu studieren, die wir heute überprüft haben, und ihre Erfahrungen und Kenntnisse geteilt. Das ist alles, danke.