KI auf häuslichem Eisen
Wir sprechen darüber, wie wir unser Framework für neuronale Netze und Gesichtserkennungssysteme auf russische Elbrus-Prozessoren portiert haben.
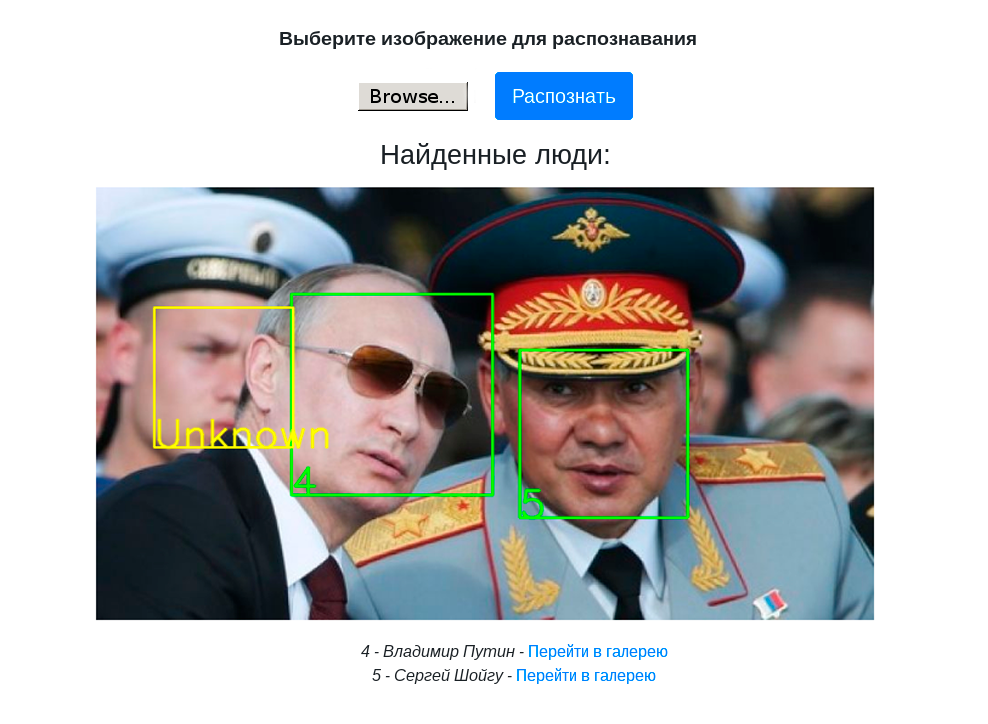
Es war eine interessante Aufgabe, im Frühjahr 2019 haben wir im Yandex-Büro über das große Treffen über Elbrus gesprochen, das wir jetzt mit Habr teilen.
Kurz - was ist Elbrus?
Dies ist ein russischer Prozessor mit eigener Architektur, der am
MCST entwickelt wurde . Maxim Gorshenin spricht auf seinem Kanal gut über ihn:
www.youtube.com/watch?v=H8eBgJ58EPYKurz gesagt - was ist PuzzleLib?
Dies ist unsere Plattform für neuronale Netze, die wir seit 2015 entwickeln und nutzen. Analog zu Google TensorFlow und Facebook PyTorch. Interessanterweise unterstützt PuzzleLib nicht nur NVIDIA- und Intel-Prozessoren, sondern auch AMD-Grafikkarten.
Obwohl wir eine kleine Bibliothek haben (TensorFlow hat ungefähr 2 Millionen Zeilen, wir haben 100.000), sind wir schneller - ein bisschen, aber besser =)
Wir sind noch nicht in Open Source, die Bibliothek wird für unsere Projekte verwendet. Die Bibliothek ist vollständig: Sie unterstützt sowohl die Trainingsphase als auch die Inferenzphase neuronaler Netze. Sie können wiederkehrende, faltungsbedingte neuronale Netze erstellen. Außerdem gibt es eine Schnittstelle zum Erstellen beliebiger Berechnungsgraphen.
PuzzleLib hat
- Module zum Aufbau neuronaler Netze (Aktivierung (Sigmoid, Tanh, ReLU, ELU, LeakyReLU, SoftMaxPlus), AvgPool (1D, 2D, 3D), BatchNorm (1D, 2D, 3D, ND), Conv (1D, 2D, 3D, ND) , CrossMapLRN, Deconv (1D, 2D, 3D, ND), Dropout (1D, 2D) usw.)
- Optimierer (AdaDelta, AdaGrad, Adam, Hooks, LBFGS, MomentumSGD, NesterovSGD, RMSProp usw.)
- Gebrauchsfertige neuronale Netze (Resnet, Inception, YOLO, U-Net usw.)
Dies sind die vertrauten, allen an neuronalen Netzen beteiligten Blöcke für Entwickler neuronaler Netze (da alle Frameworks Konstruktoren sind, die aus typischen Rechenblöcken und Algorithmen bestehen).
Wir hatten die Idee, unsere Bibliothek über Elbrus-Architektur zu starten.
Warum wollten wir Elbrus unterstützen?
- Dies ist der einzige russische Prozessor, ich wollte verstehen, wie die Dinge damit laufen, wie einfach es ist, damit zu arbeiten.
- Wir dachten, dass es für staatliche Organisationen interessant sein könnte, dass die russische Software, die wir entwickeln, auf russischer Hardware funktioniert.
- Und natürlich waren wir nur interessiert, denn Elbrus ist ein VLIW-Prozessor , dh ein Prozessor mit langen Anweisungen, und es gibt keine derart vollwertigen Allzweckprozessoren auf der Welt.
Alles begann mit der Tatsache, dass wir uns mit dem MCST getroffen, gesprochen und den
Elbrus 401- Computer zur Entwicklung ausgeliehen haben.
Was mir gefallen hat : Linux läuft unter Elbrus, es gibt Python in diesem Linux und es funktioniert nicht im Emulationsmodus - es ist eine vollwertige, native Python, die für Elbrus zusammengestellt wurde. Es gibt auch ein Bündel von Standard-Python-Bibliotheken, zum Beispiel numpy, die alle Entwickler sehr lieben.
Es gab einige Aufgaben, für die wir zusätzlich Bibliotheken sammeln mussten: In PuzzleLib verwenden wir beispielsweise das HDF-Format, um die Gewichte neuronaler Netze zu speichern, und dementsprechend mussten wir die Bibliotheken libhdf und h5py mit dem lcc-Compiler erstellen. Wir hatten aber keine Montageprobleme.
Die OpenCV-Computer-Vision-Bibliothek wurde ebenfalls bereits kompiliert, es gab jedoch keine Bindung für Python - wir haben sie separat erstellt.
Die berühmte dlib-Bibliothek ist auch ziemlich einfach zu kompilieren. Es gab nur geringfügige Schwierigkeiten: Einige Dateien dieses Open-Source-Projekts hatten keinen Bom-Marker zur Bestimmung von utf-8, was den lcc-Lexer verärgerte. Eigentlich gab es einfach ein falsches Dateiformat, das in der Quelle korrigiert werden musste.
Wir haben uns entschlossen, zuerst mit der Gesichtserkennung zu beginnen. Dies ist ein verständlicher Anwendungsfall für viele, bei denen diese Technologie verwendet wird. PuzzleLib hat wie andere Bibliotheken einen ziemlich großen Backend-Teil, dh eine Codebasis, die für verschiedene Prozessorarchitekturen spezifisch ist.
Unsere Backends:- CUDA (NVIDIA)
- Öffnen Sie CL + MI Open (AMD)
- mlkDNN (Intel)
- CPU (numpy)
Auf Elbrus haben wir ein numpy Backend gestartet, das sehr einfach war, da die Plattform ein Minimum von allem erfordert:
Plattform -> c90-Compiler -> Python -> NumpyWir haben eine Bibliothek ohne komplizierende Faktoren (zum Beispiel ohne spezielle Montagesysteme) - zusätzlich zu der Tatsache, dass wir bestimmte Ordner sammeln mussten. Wir haben die Tests durchgeführt, alles funktioniert - sowohl Faltungsgitter als auch wiederkehrende. Die Gesichtserkennung, die wir gestartet haben, ist ziemlich einfach und basiert auf Inception-ResNet.
Erste ArbeitsergebnisseAuf dem Intel Core i7 7700 betrug die Verarbeitungszeit für ein Bild 0,1 Sekunden und hier - 15. Es war eine Optimierung erforderlich.
Zu hoffen, dass Numpy im laufenden Betrieb gut funktioniert, wäre natürlich falsch.
Wie wir das Computing optimiert haben
Wir haben die Inferenzgeschwindigkeit über den Python-Profiler gemessen und festgestellt, dass fast die gesamte Zeit damit verbracht wurde, Matrizen in Numpy zu multiplizieren. Für das Beispiel haben sie die einfachste manuelle Multiplikation der Matrix geschrieben, und es hat sich bereits als schneller herausgestellt, obwohl nicht klar war, warum.
Es scheint, dass numpy.dot etwas weniger naiv geschrieben sein sollte als eine so einfache Multiplikation. Trotzdem haben wir überzeugt, überprüft - es stellte sich heraus, schneller (12 Sekunden pro Bild statt 15).
Als nächstes lernten wir die lineare Algebra-Bibliothek EML kennen, die bei ICST entwickelt wird, und ersetzten np.dot-Aufrufe durch cblas_sgemm. Es wurde 10 mal schneller (1,5 Sekunden) - wir waren sehr zufrieden.
Es folgten mehrere schrittweise Optimierungen. Da wir nur die Gesichtserkennung und im Allgemeinen keine willkürlichen Daten ausführen, haben wir beschlossen, unsere Operationen nur unter 4d-Tensoren zu schärfen und Fusion - danach verringerte sich die Verarbeitungszeit um das Zweifache - auf 0,75 Sekunden.
Erläuterung: Fusion ist, wenn mehrere Operationen zu einer zusammengefasst werden, z. B. Faltung, Normalisierung und Aktivierung. Anstatt einen Durchgang in drei Zyklen durchzuführen, wird ein Durchgang durchgeführt.
Solche Bibliotheken sind bei NVIDIA (
TensorRT ) erhältlich. Ein Rechengraph wird in ihn geladen, und die Bibliothek erzeugt einen optimierten, beschleunigten Graphen, insbesondere aufgrund der Tatsache, dass Operationen zu einem zusammengefasst werden können. Intel hat auch eine ähnliche (nGraph und
OpenVINO ).
Dann haben wir gesehen, dass wir, da es in Inception-ResNet viele 1x1-Faltungen gab, zusätzliche Daten kopieren mussten. Wir haben uns auf die Tatsache spezialisiert, dass wir Stapel von 1 Foto bearbeiten (dh nicht 100 Fotos in Stapeln verarbeiten, sondern Streaming-Modus bereitstellen). Es gibt solche Anwendungsfälle, in denen Sie nicht mit Archiven, sondern mit einem Stream arbeiten müssen (z. B. zur Videoüberwachung oder ACS). Wir haben eine spezielle Passage ohne
im2col erstellt (große Kopien entfernt) - es wurden 0,45 Sekunden.
Dann sahen wir uns noch einmal den Profiler an, wir hatten alles auf die gleiche Weise - obwohl alle Stufen mit der Zeit schrumpften, verbrachten wir immer noch 80% der Zeit mit der Berechnung von Faltungsinferenzblöcken.
Wir erkannten, dass wir
gemm parallelisieren
mussten (allgemeine Matrixmultiplikation). Dieser Edelstein, der sich in EML als Single-Threaded herausstellte. Dementsprechend mussten wir selbst Multithread-Edelsteine schreiben. Die Idee ist folgende: Eine große Matrix wird in Unterblöcke unterteilt, und dann gibt es eine Multiplikation dieser kleinen Matrizen. Wir haben ein Gemm mit OpenMP geschrieben, aber es hat nicht funktioniert, Fehler sind abgestürzt. Wir haben einen manuellen Pool von Threads erstellt, die Parallelisierung ergab 0,33 Sekunden pro Frame.
Als nächstes erhielten wir Fernzugriff auf einen leistungsstärkeren Server mit
Elbrus 8C , bei dem die Geschwindigkeit auf 0,2 Sekunden pro Frame erhöht wurde.
Das folgende Video zeigt die Arbeit des Demo-Ständers mit Gesichtserkennung auf einem Elbrus 401-PC mit einem Elbrus 4C-Prozessor:
Schlussfolgerungen und Zukunftspläne
- Wir arbeiten nicht nur an der Gesichtserkennung, sondern im Prinzip an einem neuronalen Netzwerk-Framework, damit wir alle Detektoren und Klassifikatoren sammeln und auf Elbrus ausführen können.
- Wir haben einen Demo-Stand mit Web-UI zusammengestellt, um die Gesichtserkennung auf PuzzleLib zu demonstrieren.
- Die Gesichtserkennung auf Elbrus ist bereits schnell genug für praktische Aufgaben, dann können Sie sie bei Bedarf beschleunigen.
- Sie können mit Elbrus arbeiten. Früher haben wir mit exotischen Prozessoren gearbeitet - zum Beispiel mit russischen Tensorprozessoren, die sich noch in der Entwicklung befinden, mit AMD-Grafikkarten und deren Software. Dort ist nicht alles so gut und einfach. Das heißt, wenn wir die MI Open- Bibliothek von AMD nehmen, ist dies eine sehr schlecht geschriebene Bibliothek, in der nicht alle Kombinationen von Schritten, Auffüllungen und Filtergrößen zu erfolgreichen Berechnungen führen. Die Qualität der Tools von Elbrus ist gut - wenn Sie ein Projekt in Python, C oder C ++ haben, ist es überhaupt nicht schwierig, es auf Elbrus auszuführen.
- Es ist auch erwähnenswert, dass die Arbeit an der schrittweisen Optimierung, über die wir gesprochen haben, keine spezifischen Operationen für die Arbeit in Elbrus sind. Dies sind Standard-Multi-Core-Prozessoroperationen. Unserer Meinung nach ist dies ein gutes Zeichen dafür, dass der Prozessor wie ein normaler Prozessor von Intel / NVIDIA betrieben werden kann.
Pläne:
- Da Elbrus insofern eine Besonderheit aufweist, als es sich um einen VLIW-Prozessor handelt, können einige für Elbrus spezifische Optimierungen durchgeführt werden.
- Führen Sie eine Quantisierung durch (arbeiten Sie mit int8 anstelle von float32), wodurch Speicherplatz gespart und die Geschwindigkeit erhöht wird. Dementsprechend kann es in diesem Fall natürlich zu einem Qualitätsverlust der Berechnungen kommen - dies ist jedoch möglicherweise nicht der Fall. Wir haben beide Fälle in der Praxis bemerkt.
Wir planen, die Funktionen des VLIW-Prozessors besser zu verstehen und zu erkunden. Im Moment haben wir dem Compiler nur vertraut, dass der Compiler ihn gut optimiert, wenn wir guten Code schreiben, da er die Funktionen von Elbrus kennt.
Im Allgemeinen war es interessant, wir werden weiter verstehen. Dies dauerte nicht lange - alle Portierungsvorgänge dauerten insgesamt eine Woche.
Im Januar 2020 planen wir, PuzzleLib in Open Source zu bringen, wir werden hier mehr darüber schreiben =)
Vielen Dank für Ihre Aufmerksamkeit!