Diese und die folgenden Anleitungen führen Sie durch den Prozess der Erstellung einer Lösung basierend auf dem Discovery.js- Projekt. Unser Ziel ist es, einen Inspektor für NPM-Abhängigkeiten zu erstellen, node_modules eine Schnittstelle zur Untersuchung der Struktur von node_modules .
Hinweis: Discovery.js befindet sich in einem frühen Entwicklungsstadium, sodass sich im Laufe der Zeit etwas vereinfacht und nützlicher wird. Wenn Sie Ideen zur Verbesserung haben, schreiben Sie uns .
Anmerkung
Im Folgenden finden Sie eine Übersicht über die wichtigsten Konzepte von Discovery.js. Sie können den gesamten manuellen Code im Repository auf GitHub lernen oder versuchen, wie er online funktioniert .
Ausgangsbedingungen
Zunächst müssen wir ein Projekt für die Analyse auswählen. Dies kann ein frisch erstelltes oder ein vorhandenes Projekt sein. Hauptsache, es enthält node_modules (das Objekt unserer Analyse).
Installieren Sie zunächst das Kernpaket von discoveryjs und seine Konsolentools:
npm install @discoveryjs/discovery @discoveryjs/cli
Starten Sie als Nächstes den Discovery.js-Server:
> npx discovery No config is used Models are not defined (model free mode is enabled) Init common routes ... OK Server listen on http://localhost:8123
Wenn Sie http://localhost:8123 im Browser öffnen, sehen Sie Folgendes:

Dies ist ein Modus ohne Modell, dh ein Modus, in dem nichts konfiguriert ist. Mit der Schaltfläche "Daten laden" können Sie jetzt eine beliebige JSON-Datei auswählen oder einfach auf die Seite ziehen und die Analyse starten.
Wir brauchen jedoch etwas Bestimmtes. Insbesondere müssen wir uns einen Überblick über die Struktur node_modules . Fügen Sie dazu die Konfiguration hinzu.
Konfiguration hinzufügen
Wie Sie vielleicht bemerkt haben, No config is used beim Start des Servers die Meldung No config is used angezeigt. Erstellen wir eine Konfigurationsdatei .discoveryrc.js mit den folgenden Inhalten:
module.exports = { name: 'Node modules structure', data() { return { hello: 'world' }; } };
Hinweis: Wenn Sie eine Datei im aktuellen Arbeitsverzeichnis (dh im Stammverzeichnis des Projekts) erstellen, ist nichts anderes erforderlich. Andernfalls müssen Sie den Pfad mit der Option --config an die Konfigurationsdatei --config oder den Pfad in package.json :
{ ... "discovery": "path/to/discovery/config.js", ... }
Starten Sie den Server neu, damit die Konfiguration angewendet wird:
> npx discovery Load config from .discoveryrc.js Init single model default Define default routes ... OK Cache: DISABLED Init common routes ... OK Server listen on http://localhost:8123
Wie Sie sehen können, wird jetzt die von uns erstellte Datei verwendet. Und das von uns beschriebene Standardmodell wird angewendet (Discovery kann im Modus vieler Modelle funktionieren, wir werden in den folgenden Handbüchern auf diese Funktion eingehen). Mal sehen, was sich im Browser geändert hat:
Was ist hier zu sehen:
name als Seitentitel verwendet;- Das Ergebnis des Aufrufs der Datenmethode wird als Hauptinhalt der Seite angezeigt.
Hinweis: Die Datenmethode muss Daten oder Promise zurückgeben, die in Daten aufgelöst werden.
Grundeinstellungen werden vorgenommen, Sie können weitermachen.
Kontext
Schauen wir uns die Seite mit den benutzerdefinierten Berichten an (klicken Make report ):
Auf den ersten Blick unterscheidet sich dies nicht sehr von der Startseite ... Aber hier können Sie alles ändern! Zum Beispiel können wir das Erscheinungsbild der Startseite einfach neu erstellen:
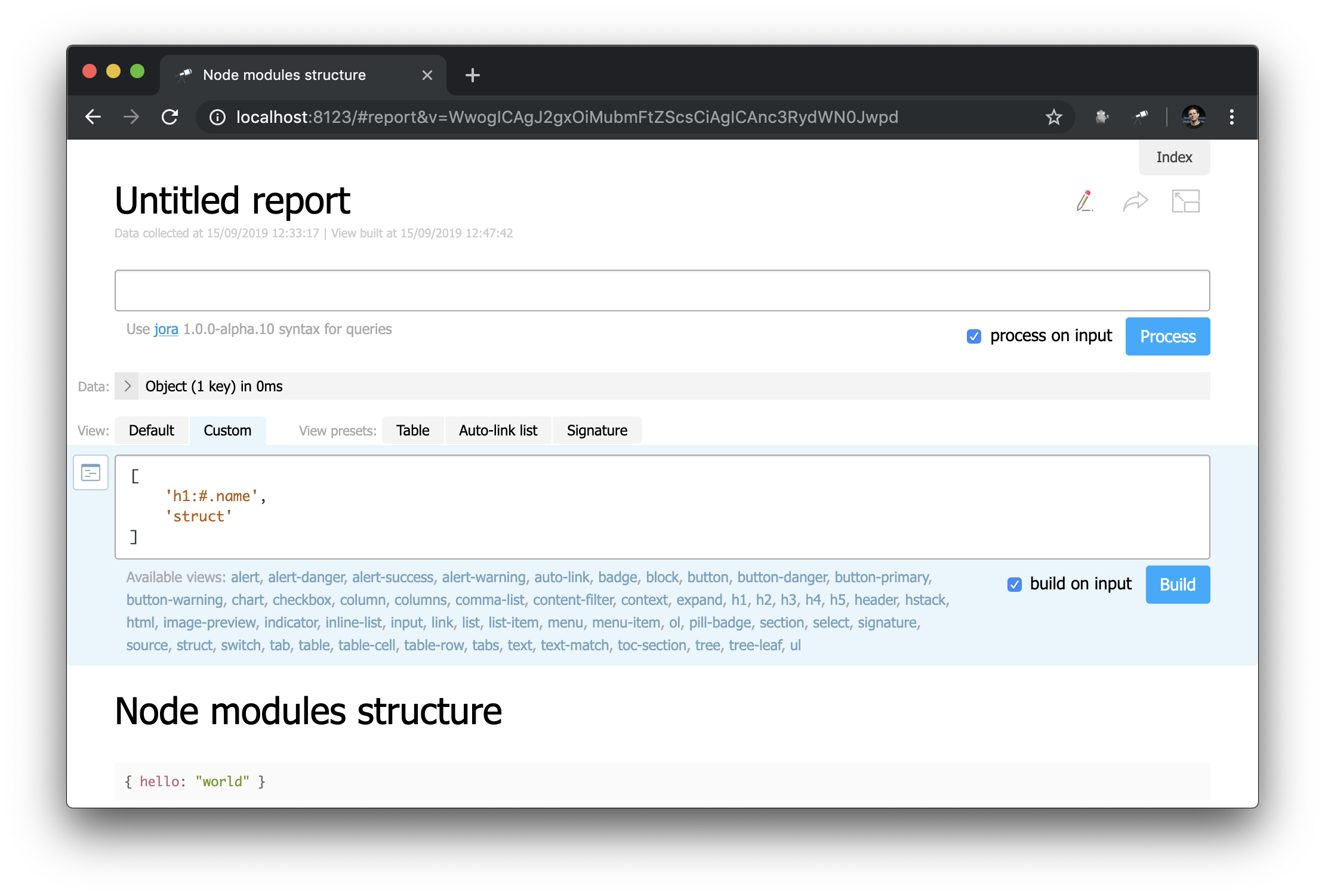
Beachten Sie, wie der Header definiert ist: "h1:#.name" . Dies ist der Header der ersten Ebene mit dem Inhalt von #.name , einer Jora- Anforderung. # bezieht sich auf den Anforderungskontext. Um den Inhalt anzuzeigen, geben Sie einfach # in den Abfrageeditor ein und verwenden Sie die Standardanzeige:
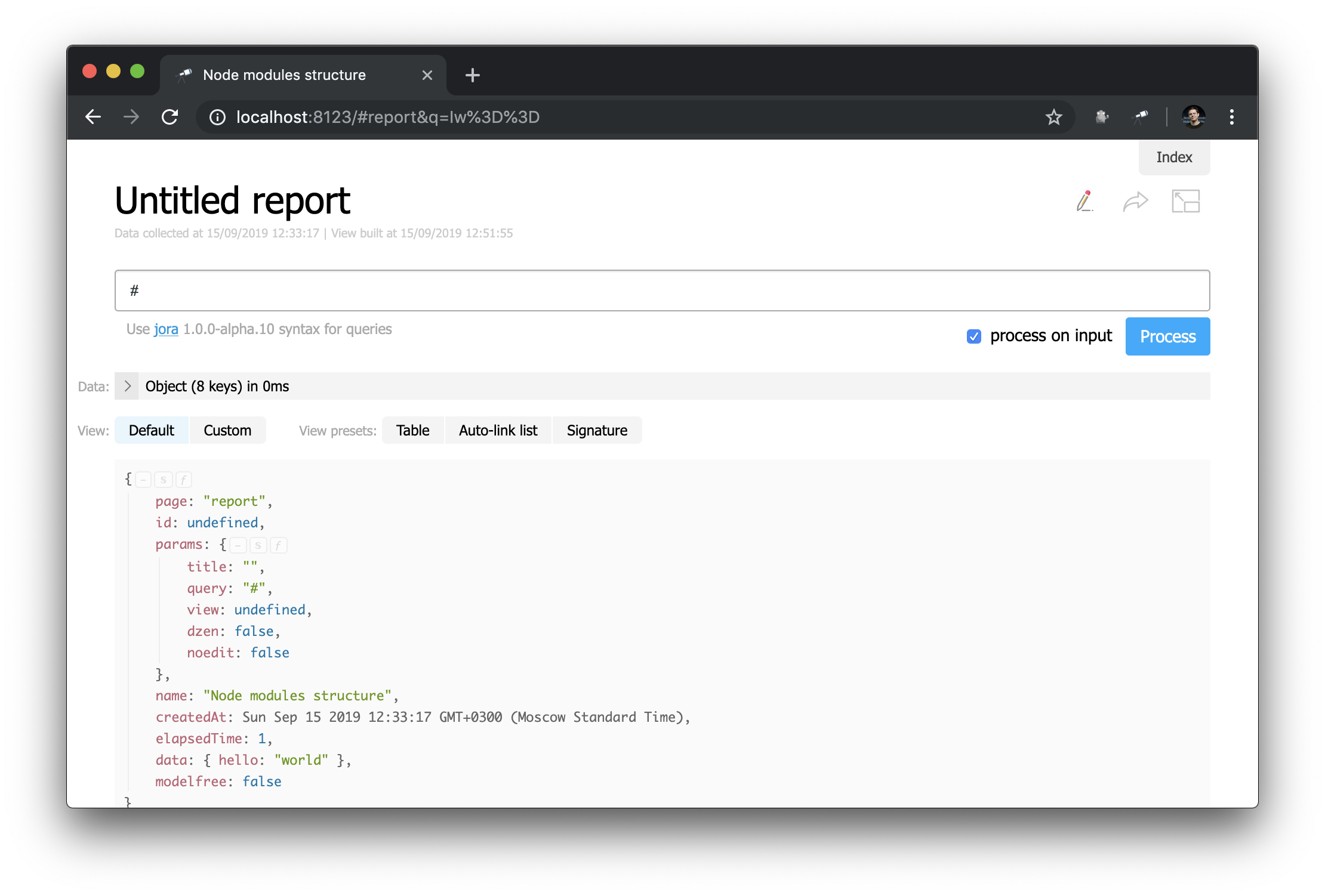
Jetzt wissen Sie, wie Sie die ID der aktuellen Seite, ihre Parameter und andere nützliche Werte erhalten.
Datenerfassung
Jetzt verwenden wir im Projekt einen Stub anstelle von realen Daten, aber wir benötigen reale Daten. Erstellen Sie dazu ein Modul und ändern Sie den data in der Konfiguration (nach diesen Änderungen muss der Server übrigens nicht neu gestartet werden):
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data') };
Der Inhalt von collect-node-modules-data.js :
const path = require('path'); const scanFs = require('@discoveryjs/scan-fs'); module.exports = function() { const packages = []; return scanFs({ include: ['node_modules'], rules: [{ test: /\/package.json$/, extract: (file, content) => { const pkg = JSON.parse(content); if (pkg.name && pkg.version) { packages.push({ name: pkg.name, version: pkg.version, path: path.dirname(file.filename), dependencies: pkg.dependencies }); } } }] }).then(() => packages); };
Ich habe das Paket @discoveryjs/scan-fs , das das Scannen von Dateisystemen vereinfacht. Ein Beispiel für die Verwendung des Pakets ist in der Readme-Datei beschrieben. Ich habe dieses Beispiel als Grundlage genommen und nach Bedarf fertiggestellt. Jetzt haben wir einige Informationen über den Inhalt von node_modules :
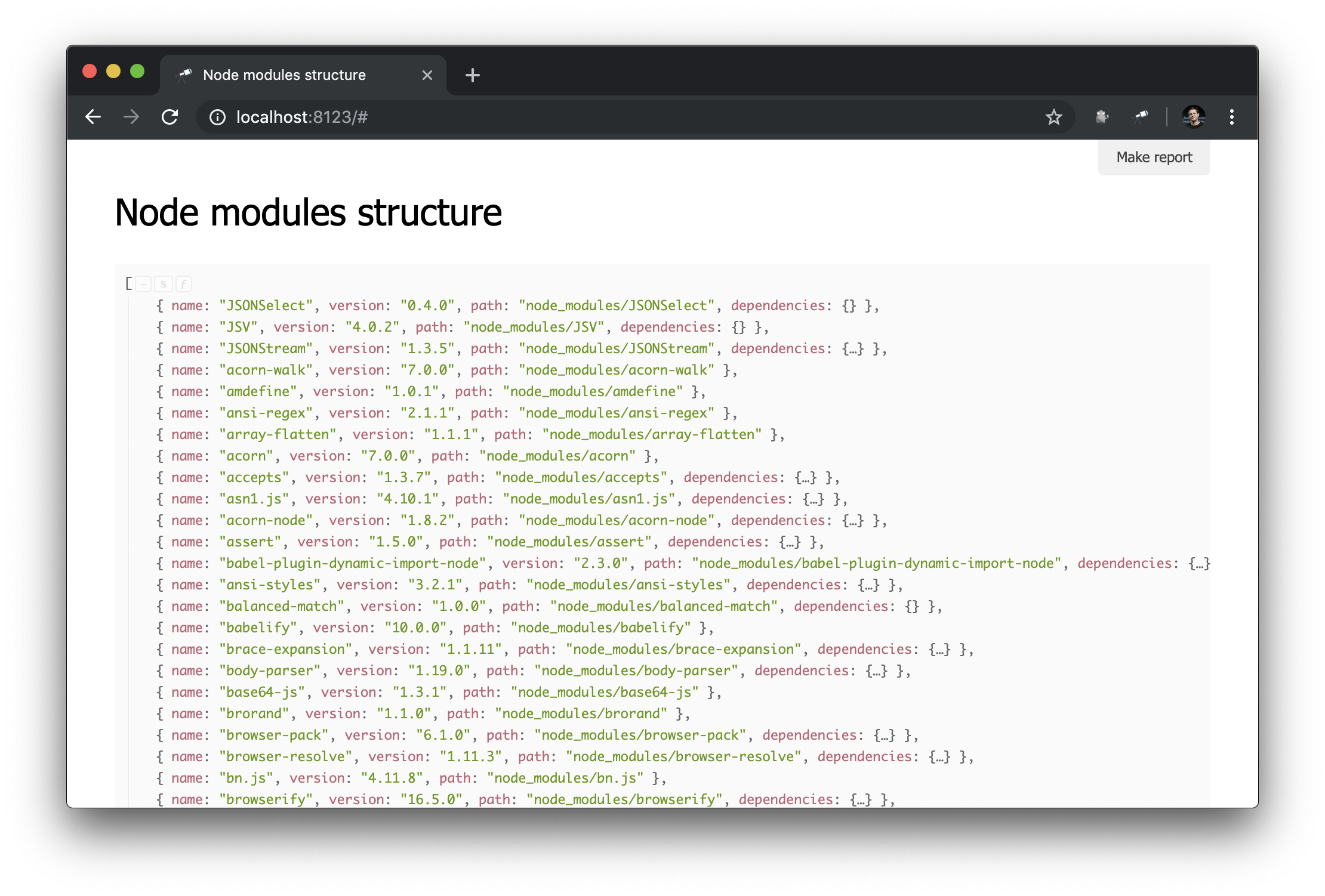
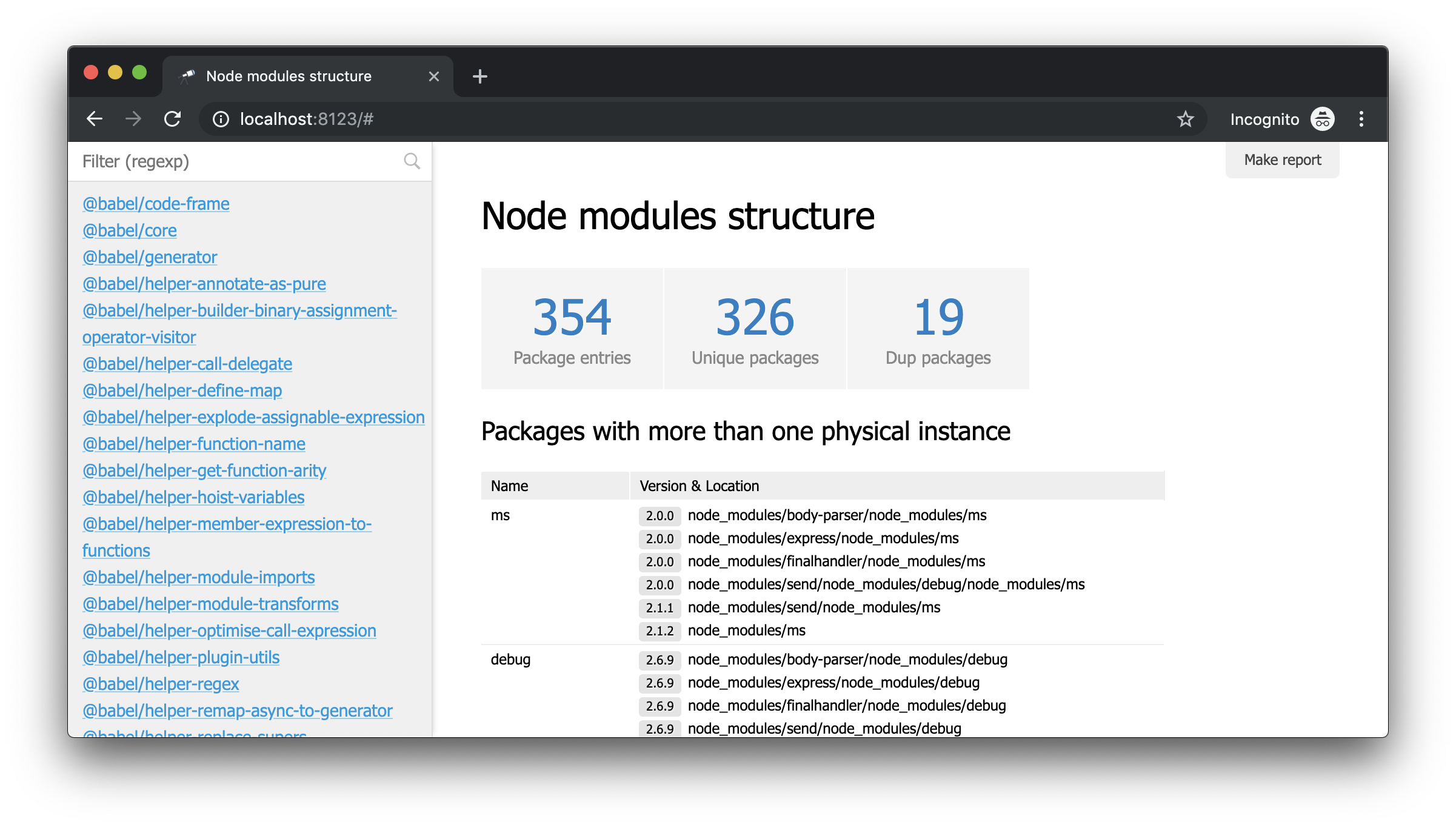
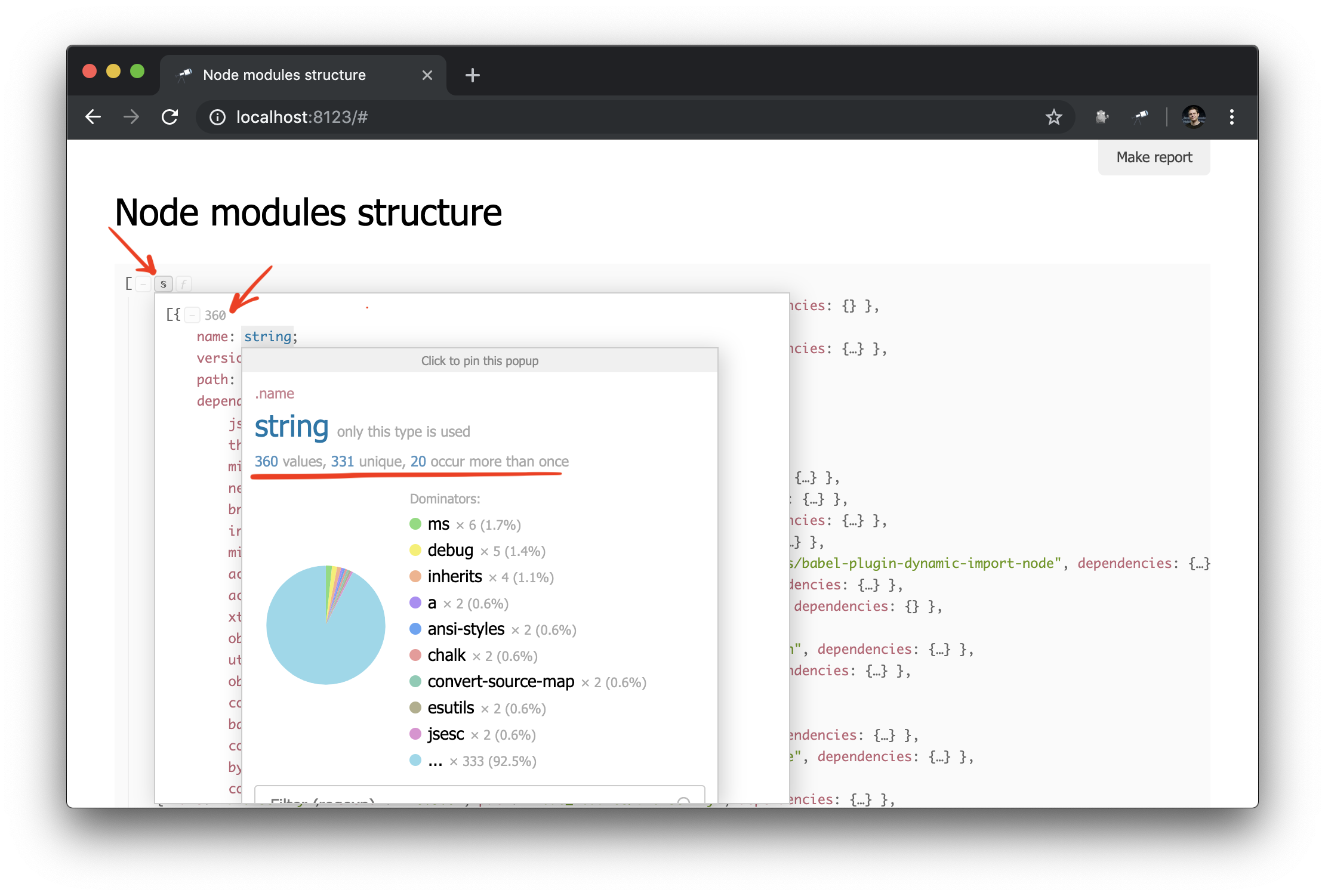
Was du brauchst! Und trotz der Tatsache, dass dies gewöhnlicher JSON ist, können wir ihn bereits analysieren und einige Schlussfolgerungen ziehen. Mithilfe des Popups der Datenstruktur können Sie beispielsweise die Anzahl der Pakete ermitteln und herausfinden, wie viele von ihnen mehr als eine physische Instanz haben (aufgrund unterschiedlicher Versionen oder Probleme bei der Deduplizierung).
Trotz der Tatsache, dass wir bereits einige Daten haben, benötigen wir weitere Details. Zum Beispiel wäre es schön zu wissen, welche physische Instanz jede der deklarierten Abhängigkeiten eines bestimmten Moduls auflöst. Die Arbeit zur Verbesserung der Datenextraktion geht jedoch über den Rahmen dieses Handbuchs hinaus. Daher werden wir es durch das Paket @discoveryjs/node-modules (das ebenfalls auf @discoveryjs/scan-fs basiert) ersetzen, um die Daten abzurufen und die erforderlichen Details zu den Paketen abzurufen. Infolgedessen wird collect-node-modules-data.js erheblich vereinfacht:
const fetchNodeModules = require('@discoveryjs/node-modules'); module.exports = function() { return fetchNodeModules(); };
Die Informationen zu node_modules aus:
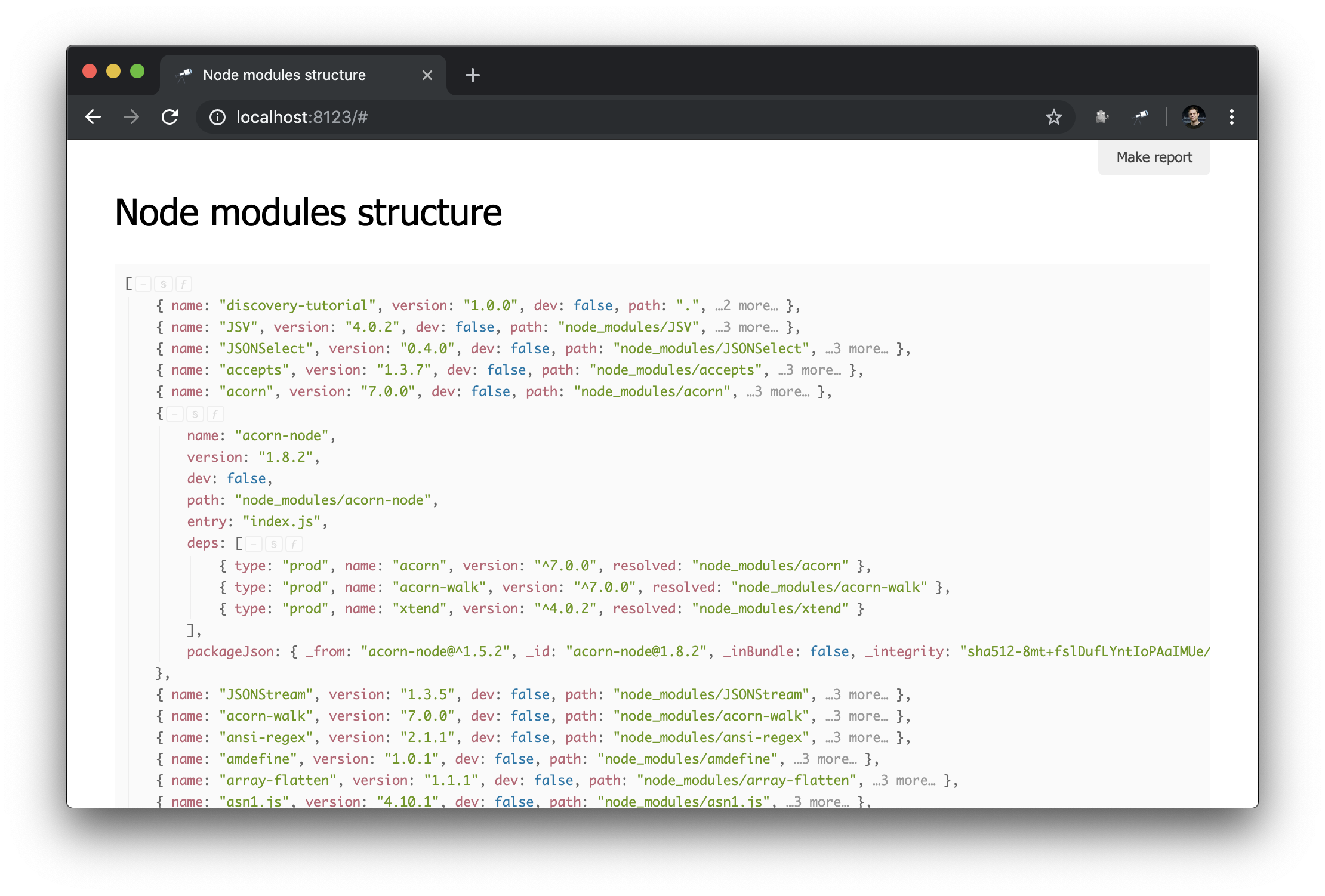
Vorbereitungsskript
Wie Sie vielleicht bemerkt haben, enthalten einige Objekte, die Pakete beschreiben, deps - eine Liste von Abhängigkeiten. Jede Abhängigkeit hat ein resolved Feld, dessen Wert eine Referenz auf eine physische Instanz des Pakets ist. Ein solcher Link ist der path eines der Pakete, er ist eindeutig. Um den Link zum Paket aufzulösen, müssen Sie zusätzlichen Code verwenden (z. B. #.data.pick(<path=resolved>) ). Und natürlich wäre es viel bequemer, wenn solche Links bereits in Objektreferenzen aufgelöst würden.
Leider können wir die Links zum Zeitpunkt der Datenerfassung nicht auflösen, da dies zu zirkulären Verbindungen führt, die das Problem der Übertragung solcher Daten in Form von JSON verursachen. Es gibt jedoch eine Lösung: Dies ist ein spezielles prepare . Sie wird in der Konfiguration definiert und jedes Mal aufgerufen, wenn der Discovery-Instanz neue Daten zugewiesen werden. Beginnen wir mit der Konfiguration:
module.exports = { ... prepare: __dirname + '/prepare.js',
Definieren Sie prepare.js :
discovery.setPrepare(function(data) {
In diesem Modul haben wir die prepare für die Discovery-Instanz definiert. Diese Funktion wird jedes Mal aufgerufen, bevor Daten auf die Discovery-Instanz angewendet werden. Dies ist ein guter Ort, um Werte in Objektreferenzen zuzulassen:
discovery.setPrepare(function(data) { const packageIndex = data.reduce((map, pkg) => map.set(pkg.path, pkg), new Map()); data.forEach(pkg => pkg.deps.forEach(dep => dep.resolved = packageIndex.get(dep.resolved) ) ); });
Hier haben wir einen Paketindex erstellt, in dem der Schlüssel der Paketpfadwert (eindeutig) ist. Dann gehen wir alle Pakete und ihre Abhängigkeiten durch und ersetzen in den Abhängigkeiten den resolved Wert durch einen Verweis auf das Paketobjekt. Ergebnis:
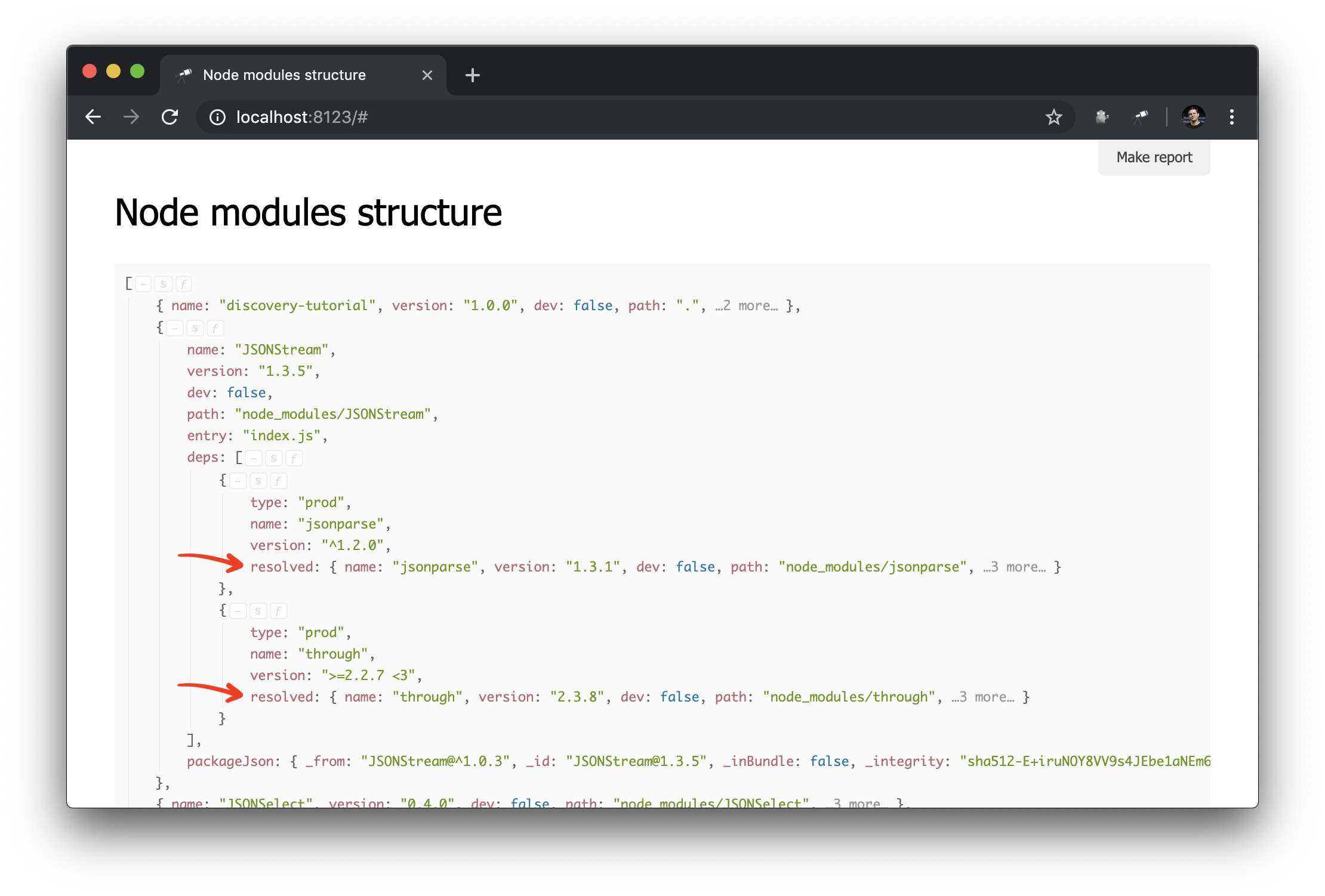
Jetzt ist es viel einfacher, Abhängigkeitsdiagrammabfragen durchzuführen. Auf diese Weise können Sie einen Cluster von Abhängigkeiten (d. H. Abhängigkeiten, Abhängigkeitsabhängigkeiten usw.) für ein bestimmtes Paket abrufen:
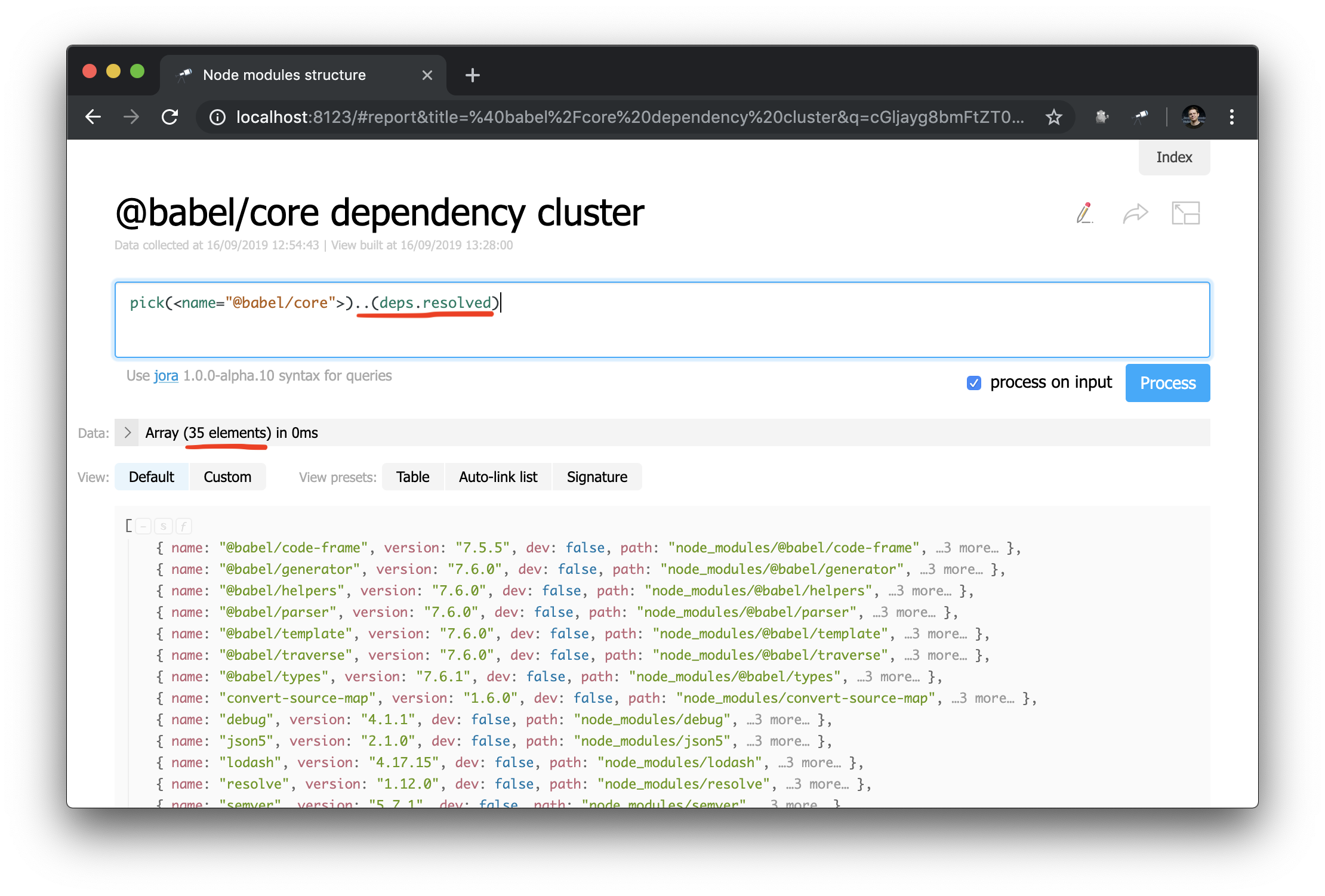
Eine unerwartete Erfolgsgeschichte: Während ich die Daten während des Schreibens des Handbuchs studierte, fand ich ein Problem in @discoveryjs/cli (unter Verwendung der Abfrage .[deps.[not resolved]] ), das einen Tippfehler in PeerDependencies hatte. Das Problem wurde sofort behoben . Der Fall ist ein gutes Beispiel dafür, wie solche Tools helfen.
Vielleicht ist es an der Zeit, auf der Startseite mehrere Nummern und Pakete mit Takes anzuzeigen.
Startseite anpassen
Zuerst müssen wir ein Seitenmodul erstellen, zum Beispiel pages/default.js . Wir verwenden die default , da dies die Kennung für die Startseite ist, die wir überschreiben können (in Discovery.js können Sie viel überschreiben). Beginnen wir mit etwas Einfachem, zum Beispiel:
discovery.page.define('default', [ 'h1:#.name', 'text:"Hello world!"' ]);
In der Konfiguration müssen Sie nun das Seitenmodul anschließen:
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data'), view: { assets: [ 'pages/default.js'
Überprüfen Sie im Browser:
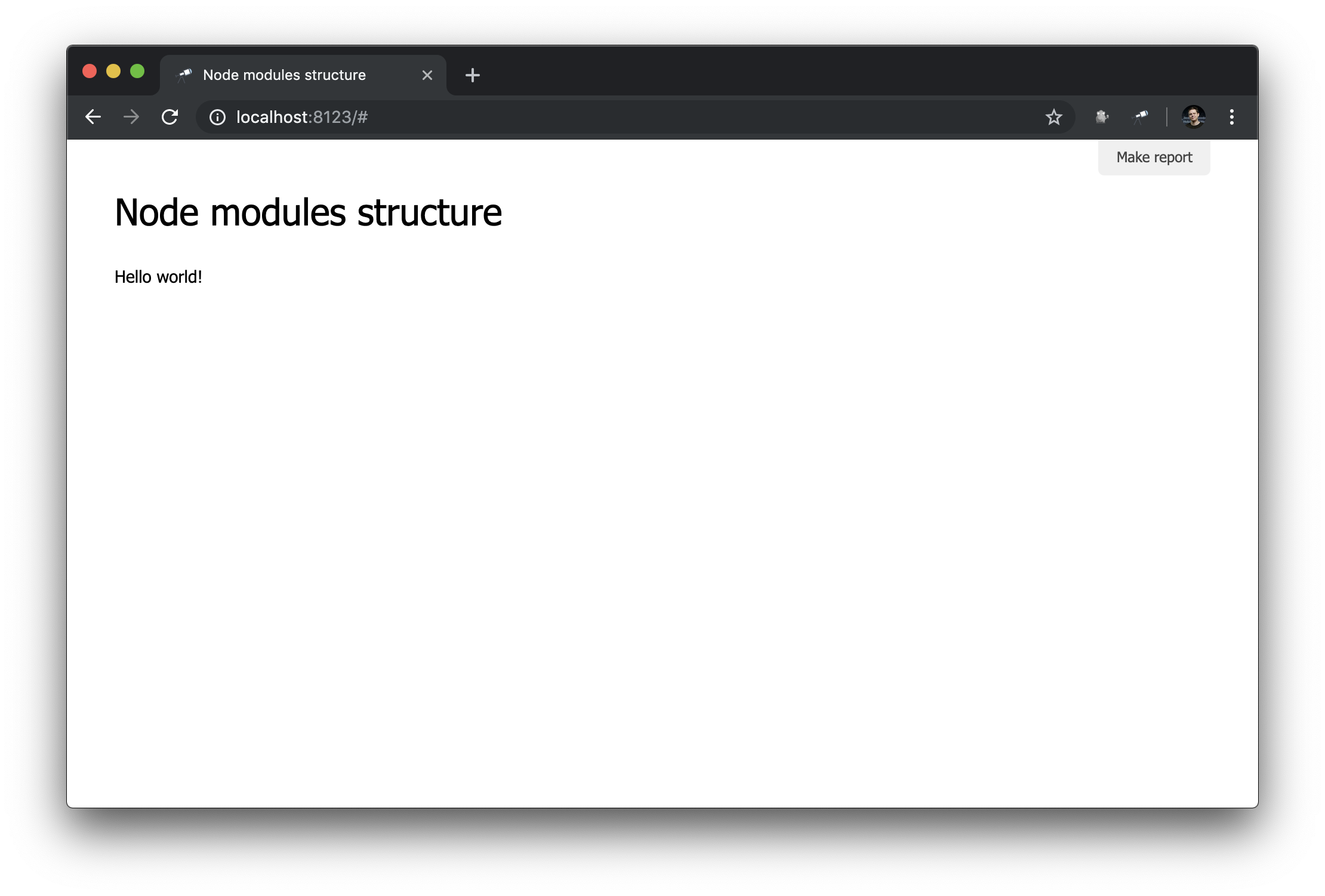
Es funktioniert!
Jetzt holen wir uns ein paar Zähler. Nehmen Sie dazu Änderungen an pages/default.js :
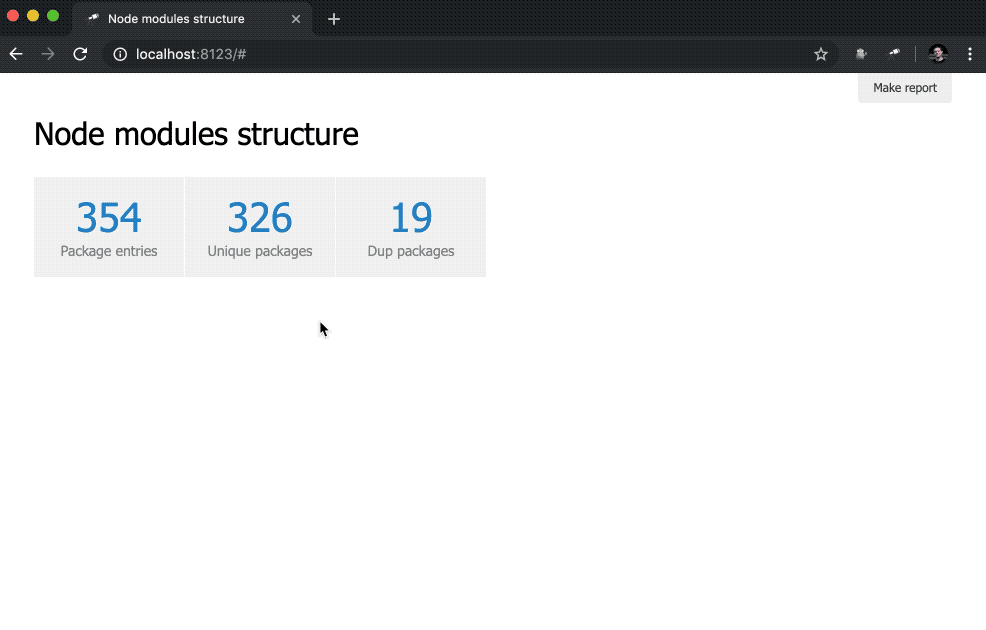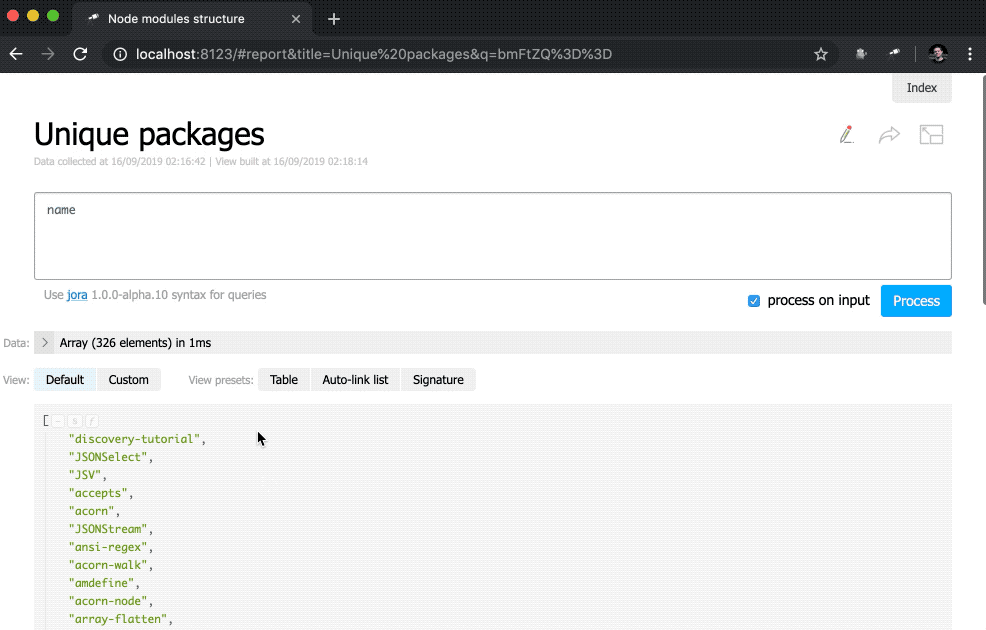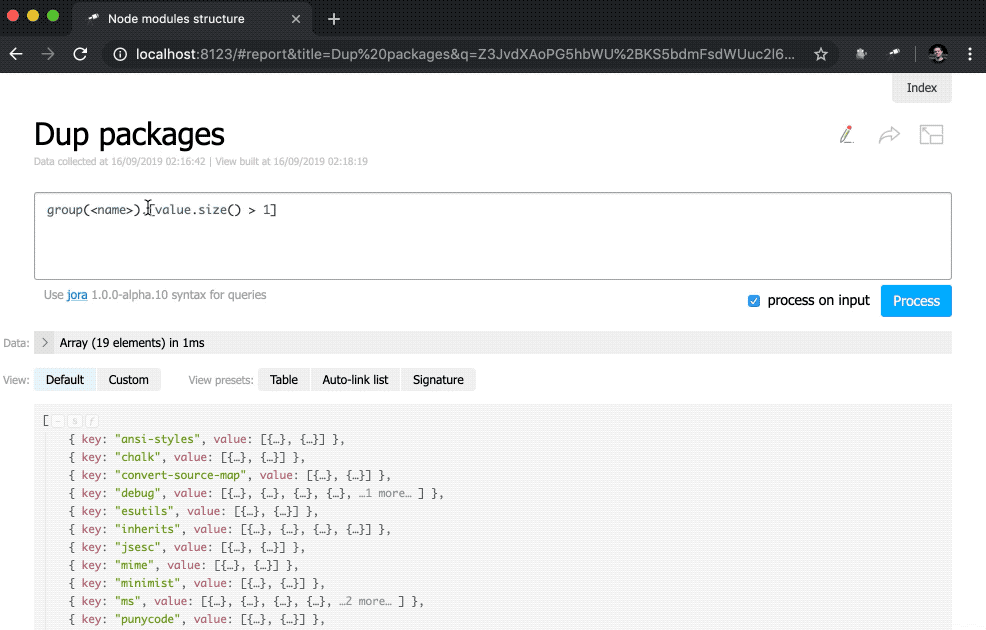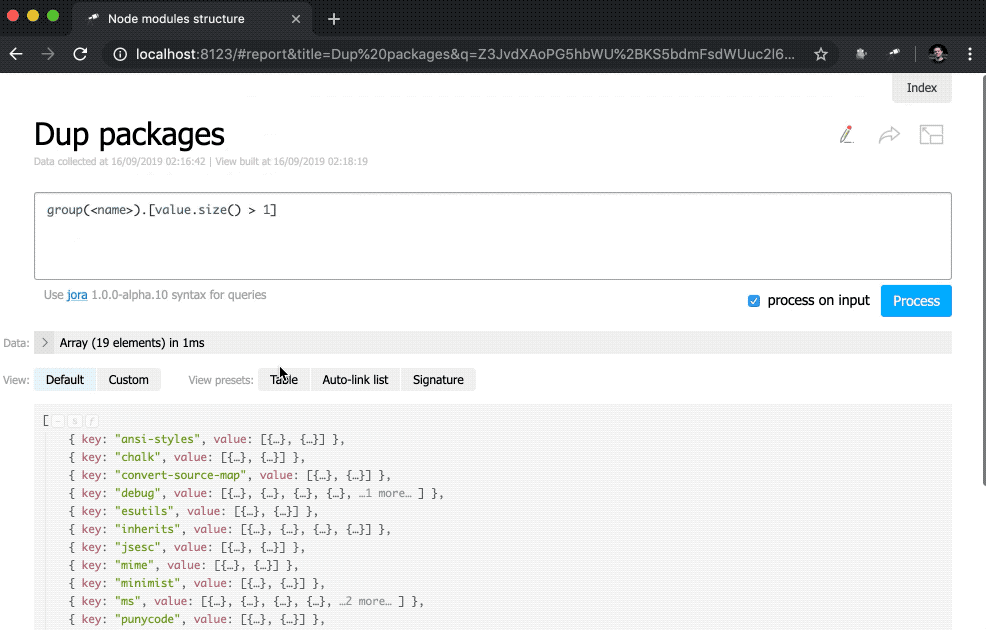
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', item: 'indicator', data: `[ { label: 'Package entries', value: size() }, { label: 'Unique packages', value: name.size() }, { label: 'Dup packages', value: group(<name>).[value.size() > 1].size() } ]` } ]);
Hier definieren wir eine Inline-Liste von Indikatoren. Der data ist eine Jora-Abfrage, die ein Array von Datensätzen erstellt. Die Liste der Pakete (Datenstamm) wird als Grundlage für Abfragen verwendet, sodass wir die name.size() size() ), die Anzahl der eindeutigen Paketnamen ( name.size() ) und die Anzahl der Paketnamen mit Duplikaten ( group(<name>).[value.size() > 1].size() ).
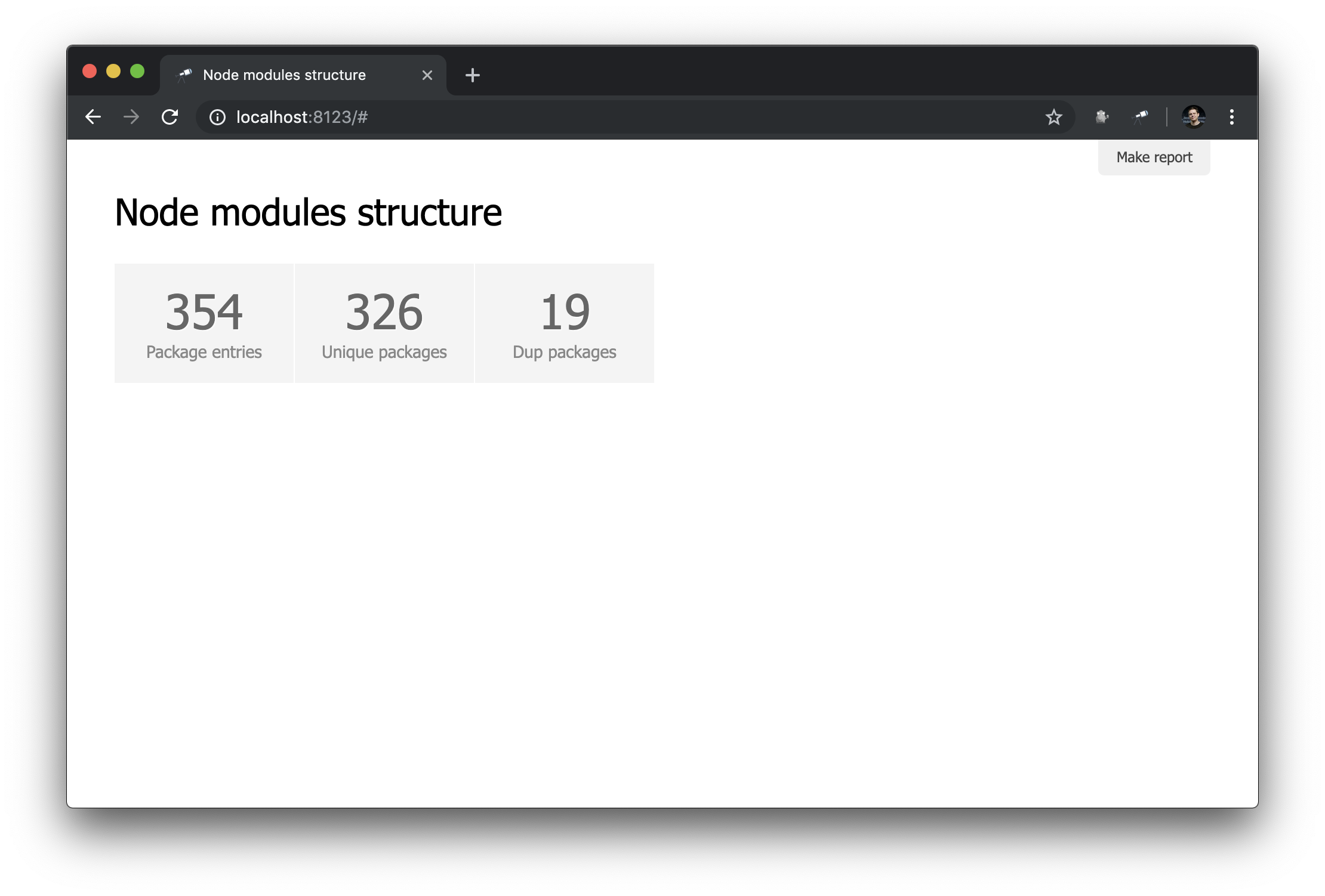
Nicht schlecht. Trotzdem wäre es besser, zusätzlich zu den Zahlen Links zu den entsprechenden Stichproben zu haben:
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', data: [ { label: 'Package entries', value: '' }, { label: 'Unique packages', value: 'name' }, { label: 'Dup packages', value: 'group(<name>).[value.size() > 1]' } ], item: `indicator:{ label, value: value.query(#.data, #).size(), href: pageLink('report', { query: value, title: label }) }` } ]);
Zuerst haben wir den Wert von data geändert, jetzt ist es ein reguläres Array mit einigen Objekten. Außerdem wurde die size() -Methode aus Wertanforderungen entfernt.
Zusätzlich wurde der indicator eine Unterabfrage hinzugefügt. Diese Abfragetypen erstellen für jedes Element ein neues Objekt, in dem value und href berechnet werden. Für den value wird eine Abfrage mit der query() -Methode ausgeführt, auf die Daten aus dem Kontext übertragen werden, und anschließend wird die size() -Methode auf das Abfrageergebnis angewendet. Für href wird die pageLink() -Methode verwendet, die einen Link zur Berichtsseite mit einer bestimmten Anforderung und einem bestimmten Header generiert. Nach all diesen Änderungen wurden die Indikatoren anklickbar (beachten Sie, dass ihre Werte blau geworden sind) und funktionaler.
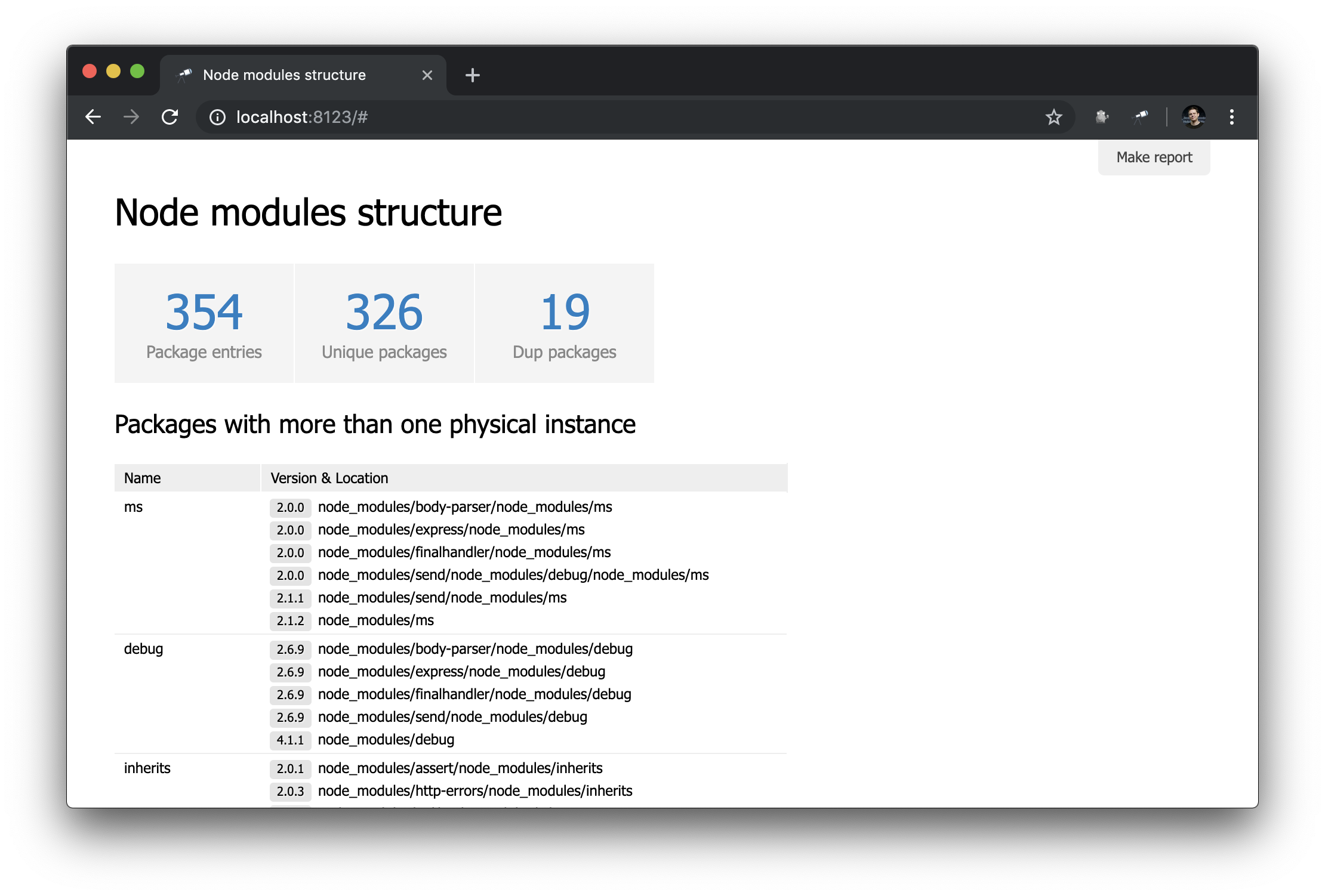
Fügen Sie eine Tabelle mit Paketen mit Duplikaten hinzu, um die Startseite nützlicher zu gestalten.
discovery.page.define('default', [
Die Tabelle verwendet dieselben Daten wie der Indikator für Dup packages . Die Liste der Pakete wurde nach Gruppengröße in umgekehrter Reihenfolge sortiert. Der Rest des Setups bezieht sich auf die Spalten (normalerweise müssen sie normalerweise nicht optimiert werden). Für die Spalte Version & Location haben wir eine verschachtelte Liste (sortiert nach Version) definiert, in der jedes Element ein Paar aus der Versionsnummer und dem Pfad zur Instanz ist.
Paketseite
Jetzt haben wir nur noch einen allgemeinen Überblick über Pakete. Es wäre jedoch nützlich, eine Seite mit Details zu einem bestimmten Paket zu haben. Erstellen Sie dazu ein neues Modul pages/package.js und definieren Sie eine neue Seite:
discovery.page.define('package', { view: 'context', data: `{ name: #.id, instances: .[name = #.id] }`, content: [ 'h1:name', 'table:instances' ] });
In diesem Modul haben wir die Seite mit dem Bezeichnerpaket definiert. Die Kontextkomponente wurde als anfängliche Darstellung verwendet. Dies ist eine nicht visuelle Komponente, mit der Sie Daten für verschachtelte Zuordnungen definieren können. Beachten Sie, dass wir #.id , um den Namen des Pakets abzurufen, das von einer URL wie dieser abgerufen wird http://localhost:8123/#package:{id} .
Vergessen Sie nicht, das neue Modul in die Konfiguration aufzunehmen:
module.exports = { ... view: { assets: [ 'pages/default.js', 'pages/package.js'
Ergebnis im Browser:
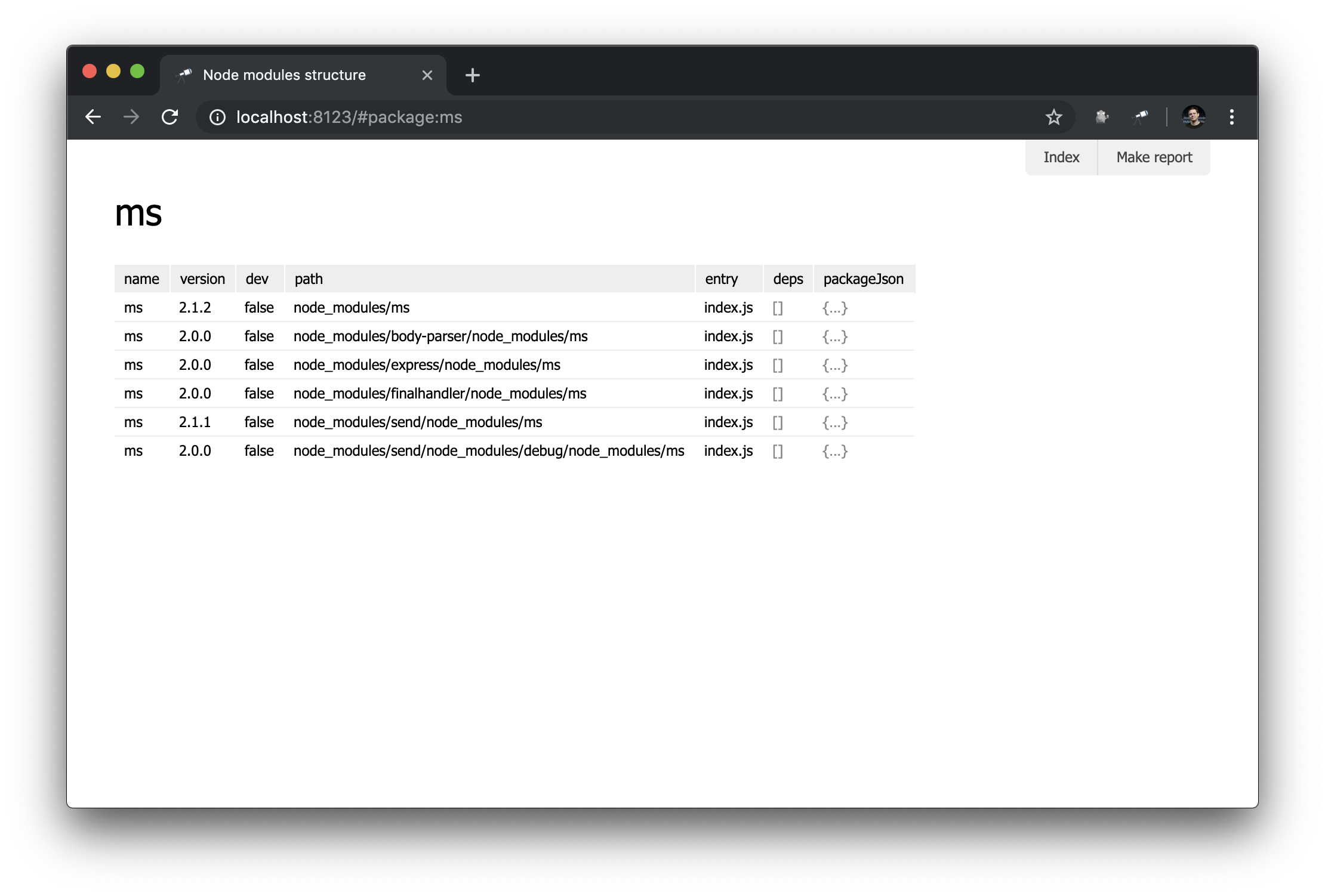
Nicht allzu beeindruckend, aber vorerst. In den folgenden Handbüchern werden komplexere Zuordnungen erstellt.
Seitenwand
Da wir bereits eine Paketseite haben, wäre es schön, eine Liste aller Pakete zu haben. Zu diesem Zweck können Sie eine spezielle Ansichtseitenleiste definieren, die angezeigt wird, wenn sie definiert ist (nicht standardmäßig definiert). Erstellen Sie eine neue views/sidebar.js :
discovery.view.define('sidebar', { view: 'list', data: 'name.sort()', item: 'link:{ text: $, href: pageLink("package") }' });
Jetzt haben wir eine Liste aller Pakete:
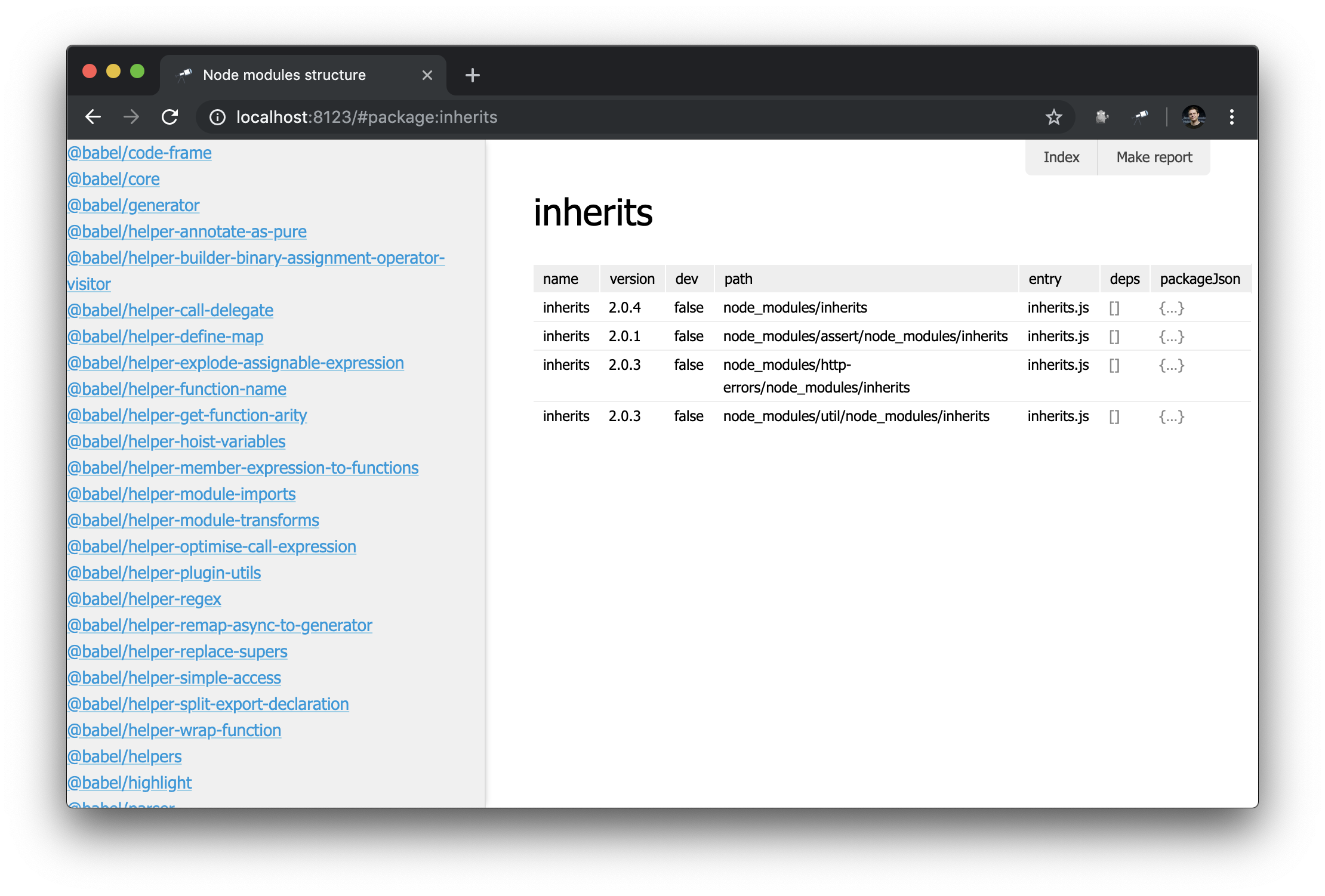
Es sieht gut aus. Aber mit einem Filter wäre es noch besser. Wir erweitern die Definition der sidebar :
discovery.view.define('sidebar', { view: 'content-filter', content: { view: 'list', data: 'name.[no #.filter or $~=#.filter].sort()', item: { view: 'link', data: '{ text: $, href: pageLink("package"), match: #.filter }', content: 'text-match' } } });
Hier haben wir die Liste in eine content-filter , die den Eingabewert im Eingabefeld in reguläre Ausdrücke konvertiert (oder null wenn das Feld leer ist) und als filter im Kontext speichert (der Name kann mit der Option name geändert werden). #.filter die Daten für die Liste zu filtern, haben wir #.filter . Schließlich haben wir die Linkzuordnung angewendet, um übereinstimmende Teile mit text-match hervorzuheben. Ergebnis:

Falls Ihnen das Standarddesign nicht gefällt, können Sie die Stile nach Ihren Wünschen anpassen. Angenommen, Sie möchten die Breite der Seitenleiste ändern. Dazu müssen Sie eine views/sidebar.css erstellen (z. B. views/sidebar.css ):
.discovery-sidebar { width: 300px; }
Fügen Sie in der Konfiguration einen Link zu dieser Datei sowie zu JavaScript-Modulen hinzu:
module.exports = { ... view: { assets: [ ... 'views/sidebar.css',
AutoLinks
Das letzte Kapitel dieses Handbuchs ist Links gewidmet. Zuvor haben wir mithilfe der pageLink() -Methode einen Link zur pageLink() erstellt. Zusätzlich zum Link müssen Sie aber auch den Linktext festlegen. Aber wie würden wir es einfacher machen?
Um die Arbeit von Links zu vereinfachen, müssen wir eine Regel zum Generieren von Links definieren. Dies geschieht am besten im prepare :
discovery.setPrepare(function(data) { ... const packageIndex = data.reduce( (map, item) => map .set(item, item)
Wir haben eine neue Karte (Index) von Paketen hinzugefügt und diese für den Entity Resolver verwendet. Der Entity Resolver versucht nach Möglichkeit, den an ihn übergebenen Wert in einen Entity Deskriptor umzuwandeln. Der Deskriptor enthält:
type - Entitätstypid - Ein eindeutiger Verweis auf eine Entitätsinstanz, die in Links als ID verwendet wirdname - wird als Linktext verwendet
Schließlich müssen Sie diesen Typ einer bestimmten Seite zuweisen (der Link sollte irgendwohin führen, oder?).
discovery.page.define('package', { ... }, { resolveLink: 'package'
Die erste Folge dieser Änderungen ist, dass einige Werte in der struct jetzt mit einem Link zur struct gekennzeichnet sind:
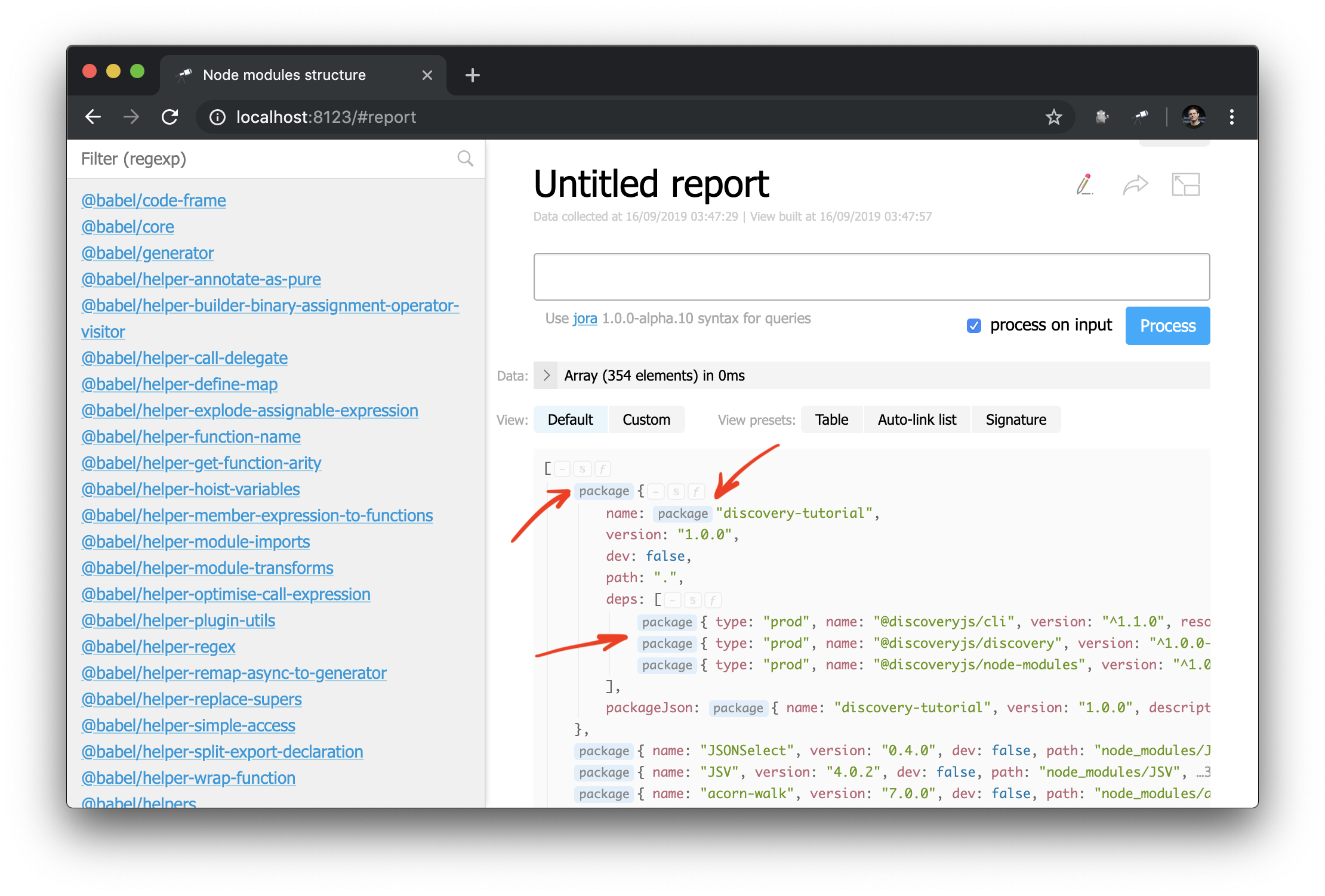
Und jetzt können Sie die auto-link Komponente auch auf einen Objekt- oder Paketnamen anwenden:
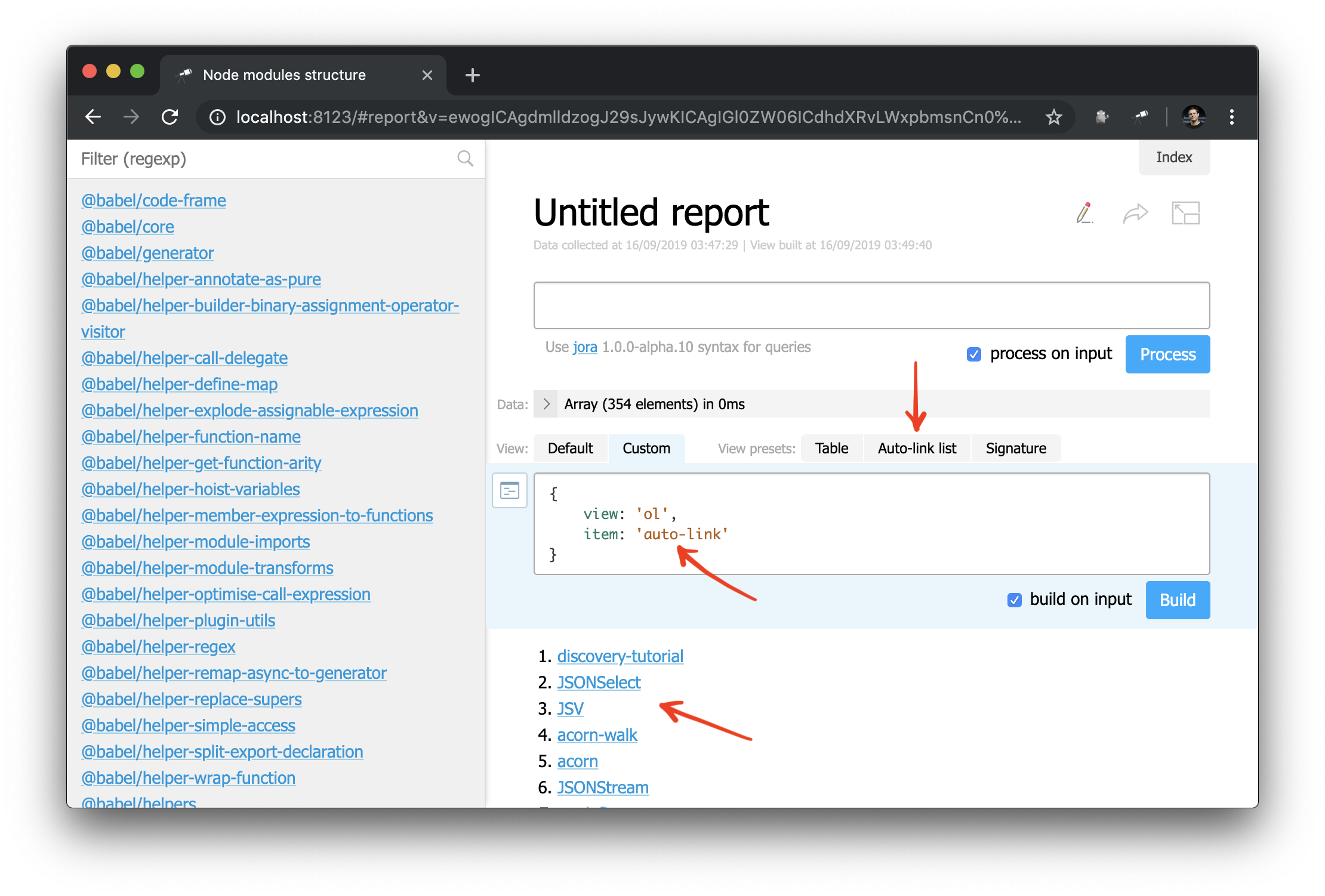
Und als Beispiel können Sie die Seitenleiste leicht überarbeiten:
Fazit
Sie haben jetzt ein grundlegendes Verständnis der Schlüsselkonzepte von Discovery.js . In den folgenden Handbüchern werden wir uns die behandelten Themen genauer ansehen.
Sie können den gesamten Quellcode des Handbuchs im Repository auf GitHub anzeigen oder versuchen, wie es online funktioniert .
Folgen Sie @js_discovery auf Twitter, um über die neuesten Nachrichten auf dem Laufenden zu bleiben!