Wir möchten allgemein die ersten Erfolge mit tiefem Lernen in der Charakteranimation für unser
Cascadeur- Programm skizzieren.
Während der Arbeit an
Shadow Fight 3 haben wir viele Kampfanimationen gesammelt - ungefähr 1100 Bewegungen mit einer durchschnittlichen Dauer von ungefähr 4 Sekunden. Es schien uns vor langer Zeit, dass dies ein guter Datensatz für das Training einer Art neuronalen Netzwerks sein könnte.
Sobald wir bemerkten, dass die Animatoren, wenn sie die ersten Skizzen von Ideen auf Papier machen, nur einen Mann mit einem wörtlichen Stock zeichnen müssen, um sich die Pose des Charakters vorzustellen. Wir dachten, da ein erfahrener Animator eine Pose in einem einfachen Muster gut einstellen kann, ist es durchaus möglich, dass ein neuronales Netzwerk dies kann. Aus dieser Beobachtung entstand eine einfache Idee: Nehmen wir nur 6 Schlüsselpunkte von jeder Pose - Handgelenke, Knöchel, Becken und Halsbasis. Wenn das neuronale Netzwerk nur die Positionen dieser Punkte kennt, kann es dann den Rest der Pose vorhersagen - die Position der 37 verbleibenden Punkte des Charakters?
Wie man den Lernprozess anordnet, war von Anfang an klar: Am Eingang erhält das Netzwerk die Positionen von 6 Punkten aus einer bestimmten Pose, am Ausgang gibt es die Positionen der verbleibenden 37 Punkte an und wir vergleichen sie mit den Positionen, die sich an der Ausgangsposition befanden. In der Auswertungsfunktion können Sie die Methode der kleinsten Quadrate für die Abstände zwischen den vorhergesagten Positionen von Punkten und der Quelle verwenden.
Für den Trainingsdatensatz hatten wir alle Bewegungen der Charaktere aus Shadow Fight 3. Wir haben Posen von jedem Frame genommen und ungefähr 115.000 Posen erhalten. Aber dieses Set war spezifisch - der Charakter schaute fast immer entlang der X-Achse und das linke Bein war zu Beginn der Bewegung immer vorne. Um dieses Problem zu lösen, haben wir den Datensatz künstlich erweitert, indem wir Spiegelposen generiert und jede Pose zufällig im Raum gedreht haben. Außerdem konnten wir den Datensatz auf zwei Millionen Posen erhöhen. Wir haben 95% unseres Datensatzes für das Netzwerktraining und 5% für die Parametrisierung und das Testen verwendet.
Wir haben eine ziemlich einfache neuronale Netzwerkarchitektur verwendet - ein vollständig verbundenes fünfschichtiges Netzwerk mit einer Aktivierungsfunktion und einer Initialisierungsmethode von
selbstnormalisierenden neuronalen Netzwerken . Auf der letzten Ebene wird die Aktivierung nicht verwendet. Mit 3 Koordinaten für jeden Knoten erhalten wir eine Eingabeschicht mit 6 * 3 Elementen und eine Ausgabeschicht mit 37 * 3 Elementen. Wir suchten nach der optimalen Architektur für verborgene Schichten und konzentrierten uns auf eine Fünf-Schichten-Architektur mit 300, 400, 300, 200 Neuronen auf jeder verborgenen Schicht. Netzwerke mit weniger verborgenen Schichten lieferten jedoch auch gute Ergebnisse.
Die L2-Regularisierung von Netzwerkparametern war ebenfalls sehr nützlich, da sie die Vorhersagen reibungsloser und kontinuierlicher machte.
Ein neuronales Netzwerk mit solchen Parametern sagt die Position von Punkten mit einem durchschnittlichen Fehler von 3,5 cm voraus. Dies ist ein sehr hoher Fehler, aber die Besonderheiten des Problems müssen berücksichtigt werden. Für einen Satz von Eingabewerten kann es viele mögliche Ausgabewerte geben. Daher lernte das neuronale Netzwerk schließlich, die wahrscheinlichsten gemittelten Vorhersagen zu treffen. Wenn jedoch die Anzahl der Eingabepunkte auf 16 anstieg, verringerte sich der Fehler um die Hälfte, was in der Praxis eine sehr genaue Vorhersage der Pose ergab.
Gleichzeitig konnte das neuronale Netzwerk jedoch keine vollständig korrekte Pose abgeben, wobei die Länge aller Knochen und die korrekten Gelenkgelenke erhalten blieben. Aus diesem Grund starten wir zusätzlich einen Optimierungsprozess, bei dem alle Festkörper und Gelenke unseres physikalischen Modells ausgerichtet werden.
In der Praxis waren die Ergebnisse sehr überzeugend - Sie können sie in unserem Video sehen. Es gibt aber auch eine Besonderheit aufgrund der Tatsache, dass der Trainingsdatensatz Kampfanimationen aus einem Kampfspiel mit Waffen enthält. Zum Beispiel scheint ein Charakter anzunehmen, dass er sich wie in einer Kampfhaltung mit einer Schulter zum Feind dreht und dementsprechend seine Füße und seinen Kopf dreht. Und wenn Sie seine Hand ausstrecken, dreht sich der Pinsel nicht so, als wäre er mit einer Faust getroffen worden, sondern wie wenn er von einem Schwert getroffen wird.
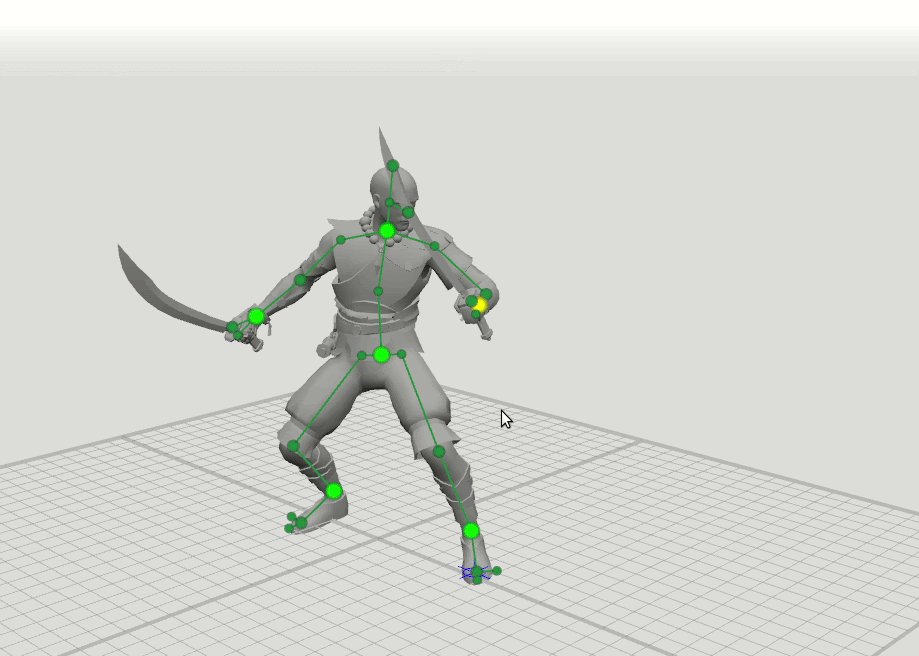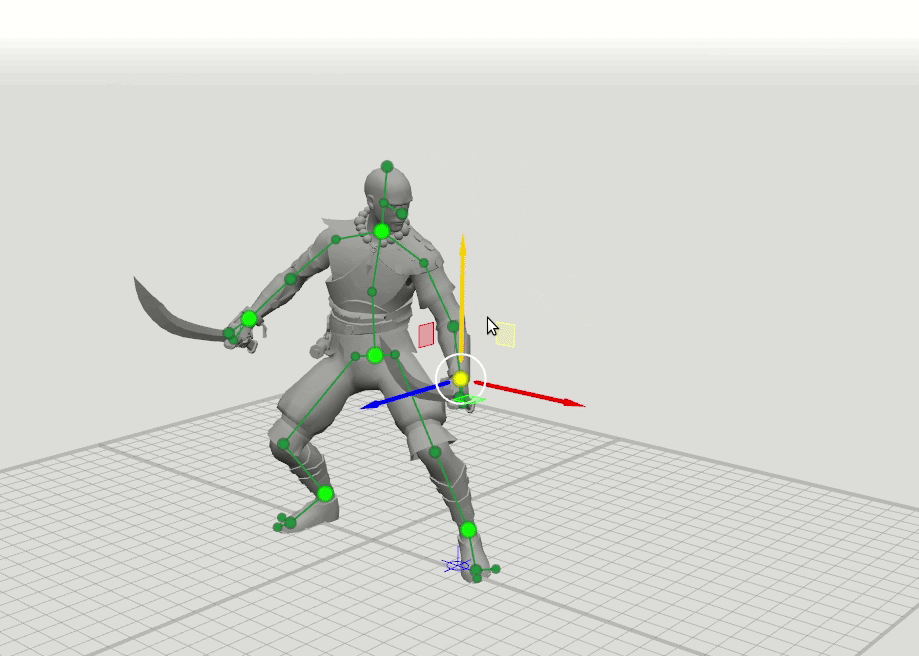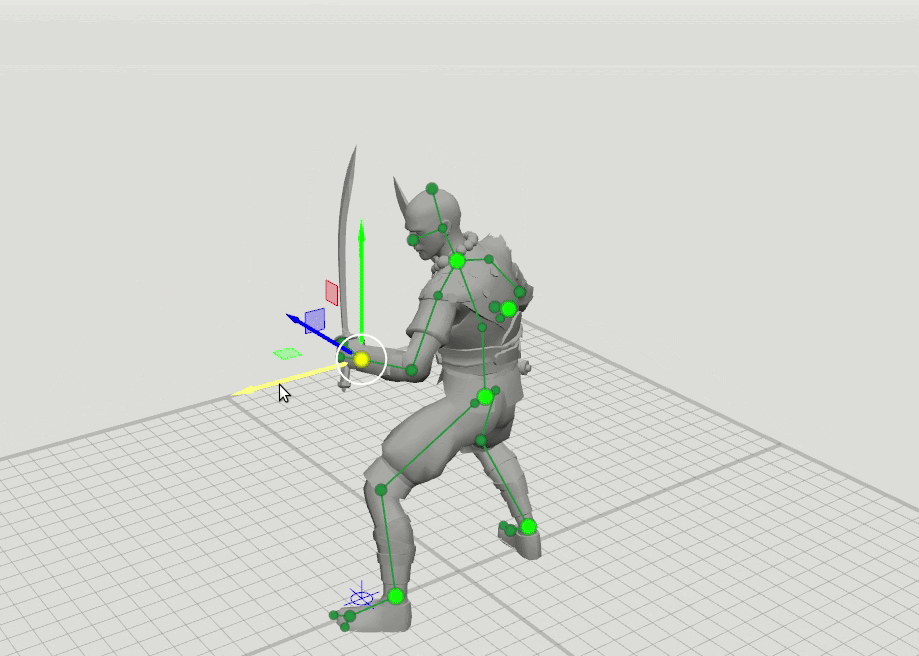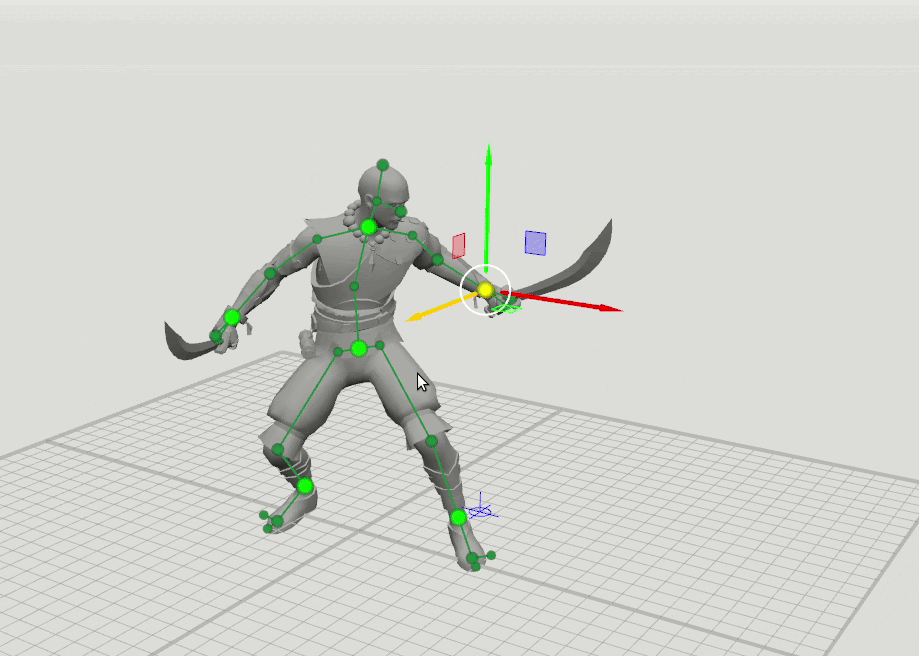
Die logische Idee für den nächsten Schritt ergab sich daraus, einige weitere Netzwerke mit einem erweiterten Satz von Punkten zu trainieren, die die Ausrichtung der Hände, Füße und des Kopfes sowie die Position der Knie und Ellbogen festlegen. Wir haben 16-Punkte- und 28-Punkte-Schemata hinzugefügt. Es stellte sich heraus, dass die Ergebnisse dieser Netzwerke kombiniert werden können, so dass der Benutzer Positionen auf einen beliebigen Satz von Punkten setzen kann. Zum Beispiel entschied sich der Benutzer, den linken Ellbogen zu bewegen, berührte aber nicht den rechten. Dann wird die Position des rechten Ellbogens und der rechten Schulter in einem 6-Punkt-Muster vorhergesagt, und die Position der linken Schulter wird in einem 16-Punkt-Muster vorhergesagt.

Es scheint, dass dies ein wirklich interessantes Werkzeug für die Arbeit mit der Pose eines Charakters ist. Sein Potenzial wurde noch nicht bis zum Ende offenbart, und wir haben Ideen, wie wir es verbessern und nicht nur für die Arbeit mit einer Pose anwenden können. Die erste Version dieses Tools ist bereits in der aktuellen Version von Cascadeur verfügbar. Sie können es versuchen, wenn Sie sich für einen Closed Beta-Test auf unserer Website
cascadeur.com anmeldenWir freuen uns über Ihre Meinung und beantworten Fragen.
Das Banzai Games-Team benötigt einen Deep-Learning-Forscher. Lesen Sie hier mehr über die freie Stelle.