
Hallo Leser von Habr. Mit diesem Artikel eröffnen wir einen Zyklus, der sich mit dem von uns entwickelten hyperkonvergenten System AERODISK vAIR befasst. Anfangs wollten wir, dass der erste Artikel alles über alles erzählt, aber das System ist ziemlich komplex, so dass wir einen Elefanten in Teilen essen werden.
Beginnen wir die Geschichte mit der Geschichte des Systems, gehen wir tiefer in das ARDFS-Dateisystem ein, das die Grundlage von vAIR bildet, und sprechen wir auch ein wenig über die Positionierung dieser Lösung auf dem russischen Markt.
In zukünftigen Artikeln werden wir mehr über verschiedene Architekturkomponenten (Cluster, Hypervisor, Load Balancer, Überwachungssystem usw.), den Konfigurationsprozess sprechen, Lizenzierungsprobleme ansprechen, Crashtests separat anzeigen und natürlich über Lasttests und schreiben Dimensionierung. Wir werden auch einen separaten Artikel der Community-Version von vAIR widmen.
Ist eine Airdisc eine Geschichte über Lagerung? Oder warum haben wir überhaupt angefangen, uns zu konvergieren?
Die Idee, ein eigenes Hyperkonvergenz zu schaffen, kam uns etwa im Jahr 2010. Dann gab es keine Aerodisk und ähnliche Lösungen (kommerzielle hyperkonvergente Boxed-Systeme) auf dem Markt. Unsere Aufgabe war wie folgt: Von einer Reihe von Servern mit lokalen Festplatten, die über eine Ethernet-Verbindung verbunden sind, mussten wir erweiterten Speicher erstellen und virtuelle Maschinen und ein Software-Netzwerk an derselben Stelle ausführen. All dies musste ohne Speichersysteme implementiert werden (da es einfach kein Geld für die Speicherung und deren Bindung gab, wir aber noch kein eigenes Speichersystem erfunden hatten).
Wir haben viele Open-Source-Lösungen ausprobiert und dieses Problem trotzdem gelöst, aber die Lösung war sehr kompliziert und schwer zu wiederholen. Darüber hinaus fiel diese Entscheidung aus der Kategorie „Werke? Nicht anfassen! " Nachdem wir dieses Problem gelöst hatten, entwickelten wir die Idee, das Ergebnis unserer Arbeit in ein vollwertiges Produkt umzuwandeln, nicht weiter.
Nach diesem Vorfall haben wir uns von dieser Idee entfernt, aber wir hatten immer noch das Gefühl, dass diese Aufgabe vollständig lösbar war und die Vorteile einer solchen Lösung mehr als offensichtlich waren. In der Folge bestätigten die freigegebenen HCI-Produkte ausländischer Unternehmen dieses Gefühl nur.
Daher sind wir Mitte 2016 im Rahmen der Entwicklung eines vollwertigen Produkts zu dieser Aufgabe zurückgekehrt. Da wir noch keine Beziehungen zu Investoren hatten, mussten wir für unser nicht sehr großes Geld einen Entwicklungsstand kaufen. Nachdem wir auf Avito BU-shyh Servern und Switches getippt hatten, machten wir uns an die Arbeit.

Die Hauptaufgabe bestand darin, ein eigenes, wenn auch einfaches, aber eigenes Dateisystem zu erstellen, mit dem Daten in Form von virtuellen Blöcken auf der n-ten Anzahl von Clusterknoten, die über Ethernet miteinander verbunden sind, automatisch und gleichmäßig verteilt werden können. In diesem Fall sollte der FS gut und leicht skalierbar und unabhängig von benachbarten Systemen sein, d.h. von vAIR in Form von "gerechter Lagerung" entfremdet sein.

VAIR Erstes Konzept

Wir haben uns absichtlich geweigert, vorgefertigte Open-Source-Lösungen für die Organisation von erweitertem Speicher (Ceph, Gluster, Lustre und dergleichen) zugunsten unserer Entwicklung zu verwenden, da wir bereits viel Projekterfahrung mit ihnen hatten. Natürlich sind diese Lösungen selbst wunderbar, und bevor wir an Aerodisk gearbeitet haben, haben wir mehr als ein Integrationsprojekt mit ihnen implementiert. Es ist jedoch eine Sache, die spezifische Aufgabe eines Kunden zu realisieren, Mitarbeiter zu schulen und möglicherweise Support für einen großen Anbieter zu kaufen, und es ist eine ganz andere Sache, ein einfach zu replizierendes Produkt zu erstellen, das für verschiedene Aufgaben verwendet wird, die wir als Anbieter möglicherweise selbst kennen wir werden nicht. Für den zweiten Zweck passten die vorhandenen Open Source-Produkte nicht zu uns, daher entschieden wir uns, das verteilte Dateisystem selbst zu sehen.
Zwei Jahre später erzielten mehrere Entwickler (die die Arbeit an vAIR mit der Arbeit an der klassischen Storage Engine kombinierten) ein bestimmtes Ergebnis.
Bis zum Jahr 2018 hatten wir das einfachste Dateisystem geschrieben und es mit der notwendigen Bindung ergänzt. Das System integrierte physische (lokale) Festplatten von verschiedenen Servern über eine interne Verbindung in einen flachen Pool und „schnitt“ sie in virtuelle Blöcke. Anschließend wurden Blockgeräte mit unterschiedlichem Grad an Fehlertoleranz aus virtuellen Blöcken erstellt, auf denen virtuelle KVM-Hypervisoren erstellt und ausgeführt wurden Autos.
Wir haben uns nicht mit dem Namen des Dateisystems beschäftigt und es kurz ARDFS genannt (raten Sie mal, wie es entschlüsselt).
Dieser Prototyp sah gut aus (nicht visuell, natürlich gab es damals kein visuelles Design) und zeigte gute Ergebnisse in Bezug auf Leistung und Skalierung. Nach dem ersten echten Ergebnis haben wir die Weichen für dieses Projekt gestellt, nachdem wir eine vollwertige Entwicklungsumgebung und ein separates Team organisiert hatten, das nur mit vAIR beschäftigt war.
Zu diesem Zeitpunkt war die allgemeine Architektur der Lösung gereift, die bis jetzt keine wesentlichen Änderungen erfahren hatte.
Eintauchen in das ARDFS-Dateisystem
ARDFS ist die Grundlage von vAIR, das verteilten Failover-Speicher für den gesamten Cluster bereitstellt. Ein (aber nicht das einzige) Unterscheidungsmerkmal von ARDFS ist, dass keine zusätzlichen dedizierten Server für Meta und Verwaltung verwendet werden. Dies sollte ursprünglich die Konfiguration der Lösung und ihre Zuverlässigkeit vereinfachen.
Speicherstruktur
Innerhalb aller Clusterknoten organisiert ARDFS einen logischen Pool aus dem gesamten verfügbaren Speicherplatz. Es ist wichtig zu verstehen, dass ein Pool noch keine Daten und kein formatierter Speicherplatz ist, sondern einfach ein Markup, d. H. Alle Knoten, auf denen vAIR installiert ist, wenn sie zum Cluster hinzugefügt werden, werden automatisch zum freigegebenen ARDFS-Pool hinzugefügt, und die Festplattenressourcen werden automatisch für den gesamten Cluster freigegeben (und stehen für die zukünftige Datenspeicherung zur Verfügung). Mit diesem Ansatz können Sie Knoten im laufenden Betrieb hinzufügen und entfernen, ohne dass dies ernsthafte Auswirkungen auf ein bereits ausgeführtes System hat. Das heißt, Das System lässt sich sehr einfach mit „Bausteinen“ skalieren und bei Bedarf Knoten im Cluster hinzufügen oder entfernen.
Über dem ARDFS-Pool werden virtuelle Festplatten (Speicherobjekte für virtuelle Maschinen) hinzugefügt, die aus virtuellen Blöcken mit einer Größe von 4 Megabyte bestehen. Virtuelle Festplatten speichern Daten direkt. Auf der Ebene der virtuellen Festplatte wird auch ein Fehlertoleranzschema definiert.
Wie Sie vielleicht vermutet haben, verwenden wir für die Fehlertoleranz des Festplattensubsystems nicht das Konzept von RAID (Redundantes Array unabhängiger Festplatten), sondern RAIN (Redundantes Array unabhängiger Knoten). Das heißt, Die Fehlertoleranz wird basierend auf Knoten und nicht auf Festplatten gemessen, automatisiert und verwaltet. Festplatten sind natürlich auch ein Speicherobjekt. Sie werden wie alles andere überwacht. Sie können alle Standardvorgänge mit ihnen ausführen, einschließlich der Erstellung lokaler Hardware-RAIDs, aber der Cluster arbeitet mit Knoten.
In einer Situation, in der Sie wirklich RAID benötigen (z. B. ein Szenario, das mehrere Fehler in kleinen Clustern unterstützt), hindert Sie nichts daran, lokale RAID-Controller zu verwenden und darüber hinaus Stretched Storage und eine RAIN-Architektur auszuführen. Dieses Szenario ist recht lebhaft und wird von uns unterstützt. Daher werden wir in einem Artikel über typische Szenarien für die Verwendung von vAIR darüber sprechen.
Speicher-Failover-Schemata
Möglicherweise gibt es zwei Ausfallsicherheitsschemata für virtuelle vAIR-Festplatten:
1) Replikationsfaktor oder nur Replikation - diese Methode der Fehlertoleranz ist einfach „wie ein Stock und ein Seil“. Eine synchrone Replikation zwischen Knoten mit einem Faktor von 2 (2 Kopien pro Cluster) oder 3 (3 Kopien) wird durchgeführt. Mit RF-2 kann die virtuelle Festplatte dem Ausfall eines Knotens im Cluster standhalten, „frisst“ jedoch die Hälfte des verwendbaren Volumes, und RF-3 hält dem Ausfall von 2 Knoten im Cluster stand, reserviert jedoch 2/3 des nützlichen Volumes für seine Anforderungen. Dieses Schema ist RAID-1 sehr ähnlich, dh eine in RF-2 konfigurierte virtuelle Festplatte ist resistent gegen den Ausfall eines Knotens des Clusters. In diesem Fall sind die Daten in Ordnung und selbst die E / A werden nicht gestoppt. Wenn ein heruntergefallener Knoten wieder in Betrieb genommen wird, beginnt die automatische Datenwiederherstellung / -synchronisation.
Das Folgende sind Beispiele für die Verteilung von RF-2- und RF-3-Daten im normalen Modus und in einer Fehlersituation.
Wir haben eine virtuelle Maschine mit einer Kapazität von 8 MB eindeutiger (nützlicher) Daten, die auf 4 vAIR-Knoten ausgeführt wird. Es ist klar, dass es in der Realität unwahrscheinlich ist, dass es eine so geringe Menge geben wird, aber für ein Schema, das die Logik von ARDFS widerspiegelt, ist dieses Beispiel am verständlichsten. AB sind virtuelle 4-MB-Blöcke, die eindeutige Daten der virtuellen Maschine enthalten. Mit RF-2 werden zwei Kopien dieser Blöcke A1 + A2 bzw. B1 + B2 erstellt. Diese Blöcke werden von Knoten „angelegt“, wobei der Schnittpunkt derselben Daten auf demselben Knoten vermieden wird, dh Kopie A1 befindet sich nicht auf derselben Note wie Kopie A2. Bei B1 und B2 ist es ähnlich.
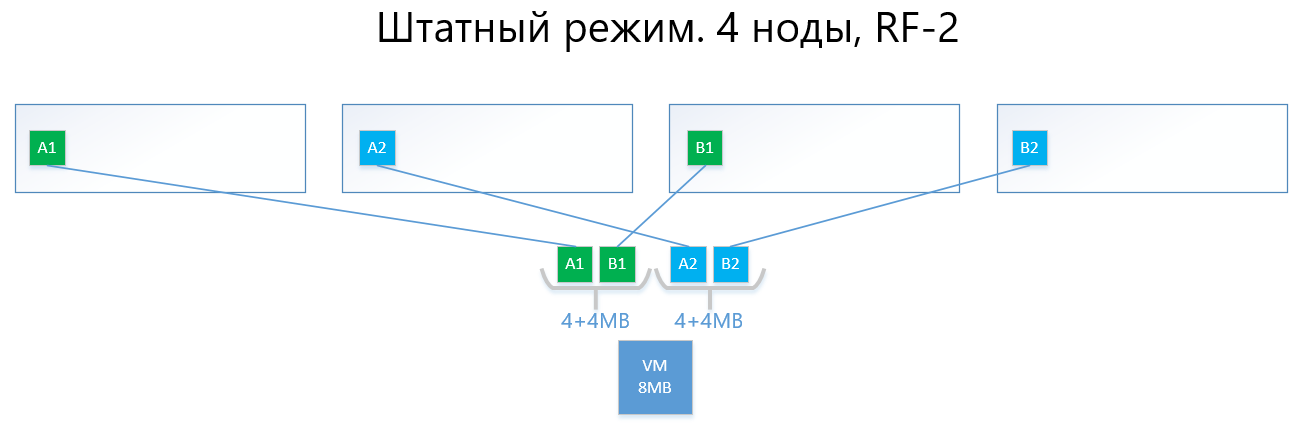
Bei einem Ausfall eines der Knoten (z. B. Knoten 3, der eine Kopie von B1 enthält) wird diese Kopie automatisch auf dem Knoten aktiviert, auf dem keine Kopie seiner Kopie vorhanden ist (dh Kopie B2).
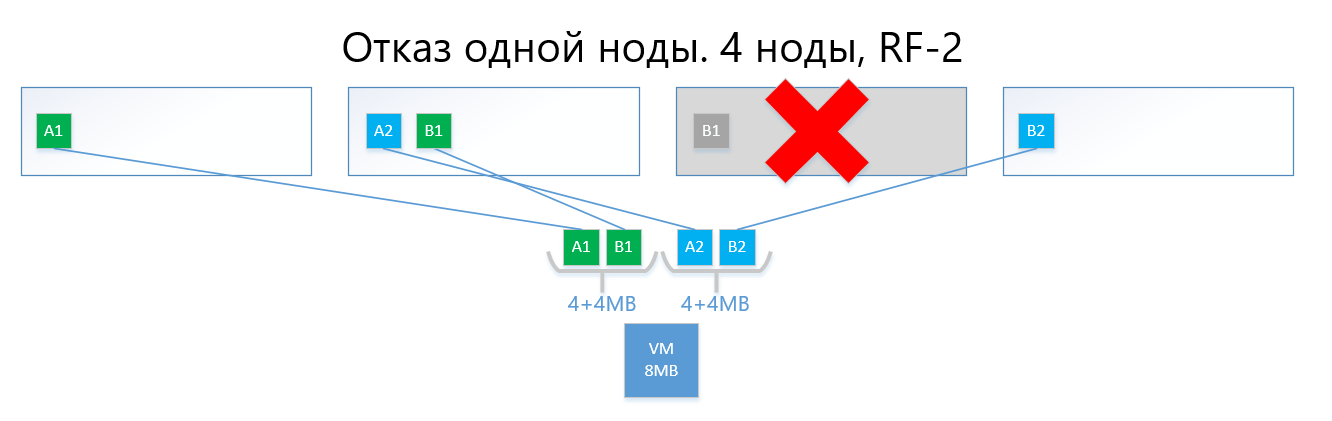
Somit überlebt die virtuelle Festplatte (bzw. die VMs) leicht den Ausfall eines Knotens im RF-2-Schema.
Eine Schaltung mit Replikation leidet aufgrund ihrer Einfachheit und Zuverlässigkeit unter denselben Schmerzen wie RAID1 - es gibt wenig nutzbaren Speicherplatz.
2) Löschcodierung oder Löschcodierung (auch als "redundante Codierung", "Löschcodierung" oder "Redundanzcode" bekannt) existiert nur, um das obige Problem zu lösen. EC ist ein Redundanzschema, das im Vergleich zur Replikation eine hohe Datenverfügbarkeit bei geringerem Festplatten-Overhead bietet. Das Funktionsprinzip dieses Mechanismus ähnelt RAID 5, 6, 6P.
Bei der Codierung unterteilt der EC-Prozess den virtuellen Block (standardmäßig 4 MB) in Abhängigkeit vom EC-Schema in mehrere kleinere „Datenelemente“ (z. B. teilt ein 2 + 1-Schema jeden 4-MB-Block in 2 Teile von 2 MB). Ferner erzeugt dieser Prozess "Paritätsblöcke" für "Datenstücke" von nicht mehr als einem der zuvor getrennten Teile. Beim Decodieren generiert die EC die fehlenden Teile und liest die "überlebenden" Daten im gesamten Cluster.
Beispielsweise kann eine virtuelle Festplatte mit einem EC-Schema 2 + 1, die auf 4 Knoten eines Clusters implementiert ist, einem Ausfall eines einzelnen Knotens in einem Cluster auf dieselbe Weise wie RF-2 problemlos standhalten. Gleichzeitig werden die Gemeinkosten niedriger sein, insbesondere beträgt der Kapazitätsfaktor bei RF-2 2 und bei EC 2 + 1 1,5.
Wenn es einfacher zu beschreiben ist, ist die Quintessenz, dass der virtuelle Block in 2-8 (warum von 2 bis 8 siehe unten) "Teile" unterteilt ist, und für diese Teile werden die "Teile" der Parität desselben Volumens berechnet.
Infolgedessen werden Daten und Parität gleichmäßig auf alle Knoten des Clusters verteilt. Gleichzeitig verteilt ARDFS wie bei der Replikation Daten automatisch auf Knoten, so dass die Speicherung derselben Daten (Kopien von Daten und deren Parität) auf einem Knoten verhindert wird, um die Möglichkeit eines Datenverlusts aufgrund der Tatsache, dass die Daten und ihre Daten ausgeschlossen sind, auszuschließen Die Parität endet plötzlich auf demselben Speicherknoten, was fehlschlägt.
Unten sehen Sie ein Beispiel mit derselben virtuellen Maschine mit 8 MB und 4 Knoten, jedoch bereits mit dem EC 2 + 1-Schema.
Die Blöcke A und B sind in zwei Teile von jeweils 2 MB unterteilt (zwei, weil 2 + 1), dh A1 + A2 und B1 + B2. Im Gegensatz zum Replikat ist A1 keine Kopie von A2, sondern ein virtueller Block A, der in zwei Teile unterteilt ist, ebenfalls mit Block B. Insgesamt erhalten wir zwei Sätze von 4 MB, von denen jeder zwei Zwei-Megabyte-Teile enthält. Ferner erhalten wir für jeden dieser Sätze Parität mit einem Volumen von nicht mehr als einem Stück (d. H. 2 MB) zusätzliche + 2 Paritätsstücke (AP und BP). Insgesamt haben wir 4x2 Daten + 2x2 Parität.
Als nächstes werden die Teile von Knoten „angeordnet“, damit sich die Daten nicht mit ihrer Parität überschneiden. Das heißt, A1 und A2 liegen nicht mit AP auf demselben Knoten.

Im Falle eines Ausfalls eines Knotens (zum Beispiel auch des dritten) wird der heruntergefallene Block B1 automatisch aus der Parität BP wiederhergestellt, die auf Knoten Nr. 2 gespeichert ist, und wird auf dem Knoten aktiviert, auf dem keine B-Parität vorliegt, d. H. Stücke von BP. In diesem Beispiel ist dies Knoten 1

Ich bin sicher, der Leser hat eine Frage:
"Alles, was Sie beschrieben haben, wurde seit langem sowohl von Wettbewerbern als auch von Open Source-Lösungen implementiert. Was ist der Unterschied zwischen Ihrer Implementierung von EC in ARDFS?"
Und dann wird es interessante Funktionen des ARDFS geben.
Löschcodierung mit Schwerpunkt auf Flexibilität
Anfangs haben wir ein ziemlich flexibles EC X + Y-Schema bereitgestellt, wobei X gleich einer Zahl von 2 bis 8 und Y gleich einer Zahl von 1 bis 8 ist, aber immer kleiner oder gleich X. Ein solches Schema ist aus Gründen der Flexibilität vorgesehen. Durch Erhöhen der Anzahl der Daten (X), in die die virtuelle Einheit unterteilt ist, kann der Overhead reduziert, dh der nutzbare Speicherplatz erhöht werden.
Eine Erhöhung der Anzahl der Paritätsblöcke (Y) erhöht die Zuverlässigkeit der virtuellen Festplatte. Je größer der Y-Wert ist, desto mehr Knoten im Cluster können ausfallen. Das Erhöhen der Paritätsmenge verringert natürlich die Menge der nutzbaren Kapazität, aber dies ist eine Gebühr für die Zuverlässigkeit.
Die Abhängigkeit der Leistung von EC-Schaltkreisen ist nahezu direkt: Je mehr „Teile“ vorhanden sind, desto geringer ist die Leistung. Hier benötigen Sie natürlich ein ausgewogenes Erscheinungsbild.
Mit diesem Ansatz können Administratoren den erweiterten Speicher am flexibelsten konfigurieren. Innerhalb des ARDFS-Pools können Sie beliebige Fehlertoleranzschemata und deren Kombinationen verwenden, was unserer Meinung nach ebenfalls sehr nützlich ist.
In der folgenden Tabelle werden mehrere (nicht alle möglichen) HF- und EC-Schaltkreise verglichen.

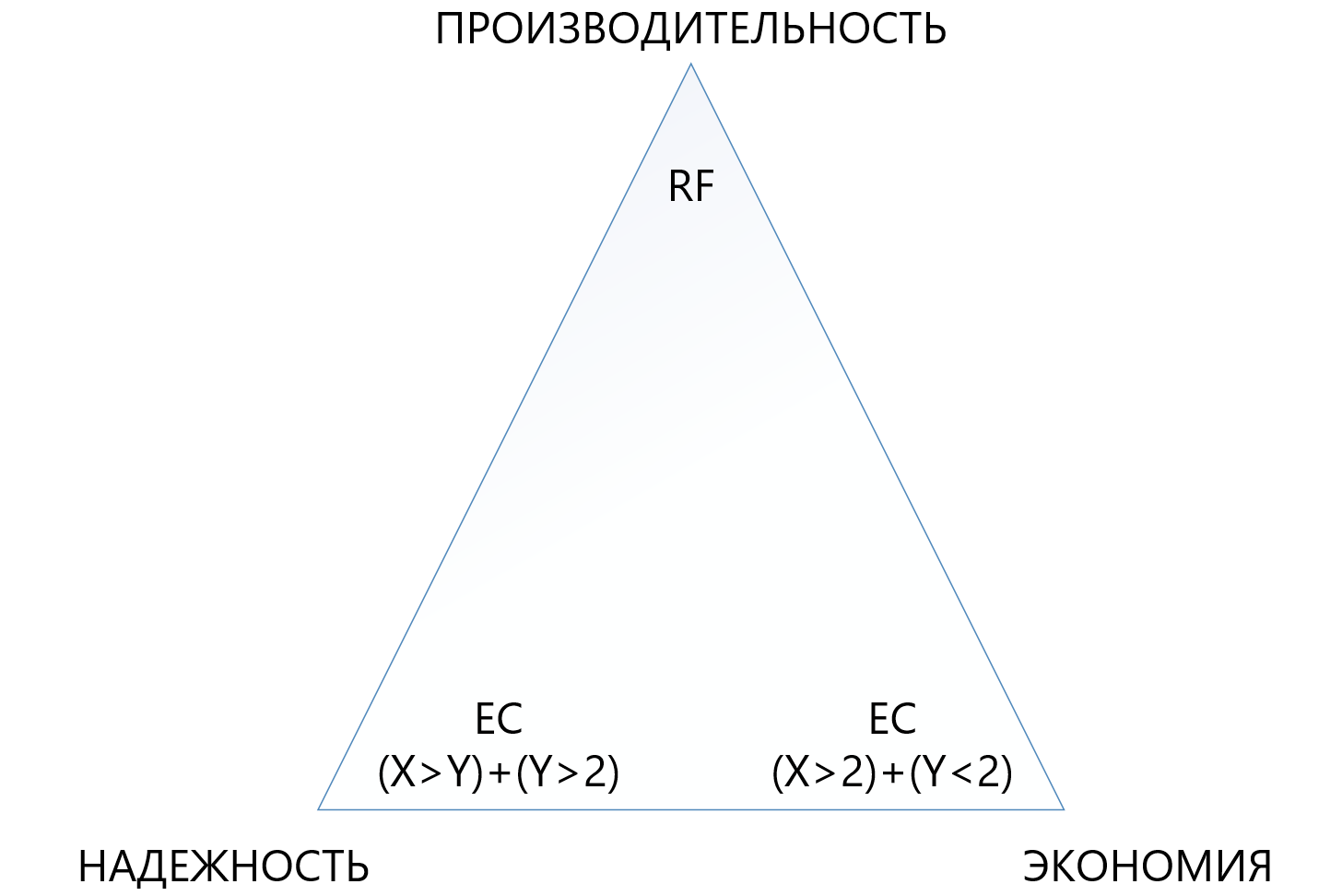
Die Tabelle zeigt, dass selbst die meiste „Frottee“ -Kombination von EC 8 + 7, die den Verlust von bis zu 7 Knoten gleichzeitig in einem Cluster ermöglicht, weniger nutzbaren Speicherplatz (1.875 gegenüber 2) als die Standardreplikation „verbraucht“ und siebenmal besser schützt. Dies macht diesen Schutzmechanismus zwar komplexer, aber in Situationen, in denen Sie unter Bedingungen mangelnden Speicherplatzes maximale Zuverlässigkeit gewährleisten müssen, viel attraktiver. Gleichzeitig müssen Sie verstehen, dass jedes „Plus“ für X oder Y einen zusätzlichen Overhead für die Produktivität darstellt. Daher müssen Sie im Dreieck zwischen Zuverlässigkeit, Wirtschaftlichkeit und Leistung sehr sorgfältig auswählen. Aus diesem Grund widmen wir der Codierung der Größenlöschung einen separaten Artikel.
Zuverlässigkeit und Autonomie des Dateisystems
ARDFS wird lokal auf allen Knoten des Clusters ausgeführt und synchronisiert sie auf eigene Weise über dedizierte Ethernet-Schnittstellen. Ein wichtiger Punkt ist, dass ARDFS nicht nur Daten, sondern auch speicherbezogene Metadaten unabhängig voneinander synchronisiert. Während der Arbeit an ARDFS haben wir gleichzeitig eine Reihe vorhandener Lösungen untersucht und festgestellt, dass viele Dateisystem-Metasynchronisierungen mithilfe eines externen verteilten DBMS durchführen, das wir auch zum Synchronisieren verwenden, jedoch nur Konfigurationen, keine FS-Metadaten (zu diesem und anderen verwandten Subsystemen) im nächsten Artikel).
Die Synchronisation von FS-Metadaten mit einem externen DBMS ist natürlich eine funktionierende Lösung, aber dann würde die Konsistenz der in ARDFS gespeicherten Daten vom externen DBMS und seinem Verhalten abhängen (und sie ist ehrlich gesagt eine launische Frau), was unserer Meinung nach schlecht ist. Warum? Wenn die FS-Metadaten beschädigt sind, können die FS-Daten selbst auch als „Auf Wiedersehen“ bezeichnet werden. Daher haben wir uns für einen komplizierteren, aber zuverlässigeren Weg entschieden.
Wir haben das Metadatensynchronisations-Subsystem für ARDFS unabhängig gemacht und es lebt völlig unabhängig von den benachbarten Subsystemen. Das heißt, Kein anderes Subsystem kann ARDFS-Daten beschädigen. Unserer Meinung nach ist dies der zuverlässigste und korrekteste Weg, und ist es wirklich so - die Zeit wird es zeigen. Darüber hinaus ergibt sich bei diesem Ansatz ein zusätzlicher Vorteil. ARDFS kann unabhängig von vAIR verwendet werden, genau wie erweiterter Speicher, den wir sicherlich in zukünftigen Produkten verwenden werden.
Als Ergebnis der Entwicklung von ARDFS haben wir ein flexibles und zuverlässiges Dateisystem erhalten, mit dem Sie die Wahl haben, Kapazität zu sparen oder alles an Leistung zu verlieren oder Speicher für eine moderate Gebühr hochzuverlässig zu machen, aber die Leistungsanforderungen zu reduzieren.
Zusammen mit einer einfachen Lizenzierungsrichtlinie und einem flexiblen Bereitstellungsmodell (in Zukunft wird es von vAIR von Knoten lizenziert und entweder von Software oder als PAC bereitgestellt) können Sie die Lösung sehr genau auf die unterschiedlichsten Anforderungen der Kunden zuschneiden, und in Zukunft ist es einfach, dieses Gleichgewicht aufrechtzuerhalten.
Wer braucht dieses Wunder?
Einerseits können wir sagen, dass es bereits Akteure auf dem Markt gibt, die ernsthafte Entscheidungen im Bereich der Hyperkonvergenz treffen und wohin wir tatsächlich gehen. Diese Aussage scheint wahr zu sein, ABER ...
Auf der anderen Seite sehen wir und unsere Partner, wenn wir auf die Felder gehen und mit Kunden kommunizieren, dass dies überhaupt nicht der Fall ist. Es gibt viele Probleme für die Hyperkonvergenz, irgendwo wussten die Leute einfach nicht, dass es solche Lösungen gibt, irgendwo schien es teuer, irgendwo gab es erfolglose Tests alternativer Lösungen, aber irgendwo verbieten sie den Kauf aufgrund von Sanktionen im Allgemeinen. Im Allgemeinen wurde das Feld nicht gepflügt, also gingen wir, um das jungfräuliche Land zu erheben))).
Wann ist Speicher besser als GCS?
Während der Arbeit mit dem Markt werden wir oft gefragt, wann es besser ist, das klassische Schema mit Speichersystemen zu verwenden, und wann es hyperkonvergent ist. Viele Unternehmen - Hersteller von GCS (insbesondere solche, die keinen Speicher in ihrem Portfolio haben) sagen: "Speicher ist überlebt, nur hyperkonvergent!" Dies ist eine kühne Aussage, die jedoch die Realität nicht ganz widerspiegelt.
In Wahrheit schwimmt der Speichermarkt zwar in Richtung hyperkonvergenter und ähnlicher Lösungen, aber es gibt immer ein „Aber“.
Erstens können Rechenzentren und IT-Infrastrukturen, die nach dem klassischen Schema mit Speichersystemen gebaut wurden, nicht einfach so wieder aufgebaut werden, weshalb die Modernisierung und Fertigstellung solcher Infrastrukturen immer noch ein 5-7-jähriges Erbe ist.
Zweitens werden die Infrastrukturen, die derzeit größtenteils gebaut werden (dh die Russische Föderation), nach dem klassischen Schema unter Verwendung von Speichersystemen gebaut, und zwar nicht, weil die Menschen nichts über Hyperkonvergenz wissen, sondern weil der Markt für Hyperkonvergenz neu ist, Lösungen und Standards noch nicht festgelegt wurden , IT-Mitarbeiter wurden noch nicht geschult, es gibt wenig Erfahrung und wir müssen hier und jetzt Rechenzentren bauen. Und dieser Trend hält noch 3-5 Jahre an (und dann ein weiteres Erbe, siehe Absatz 1).
Drittens eine rein technische Einschränkung bei zusätzlichen kleinen Verzögerungen von 2 Millisekunden pro Schreibvorgang (natürlich ohne den lokalen Cache), die Gebühren für verteilten Speicher sind.
Vergessen wir nicht, große physische Server zu verwenden, die die vertikale Skalierung des Festplattensubsystems lieben.
Es gibt viele notwendige und beliebte Aufgaben, bei denen sich das Speichersystem besser verhält als das GCS. Hier sind natürlich diejenigen Hersteller nicht einverstanden, die keine Speichersysteme in ihrem Produktportfolio haben, aber wir sind bereit, vernünftig zu argumentieren. Natürlich werden wir als Entwickler beider Produkte in einer der zukünftigen Veröffentlichungen definitiv einen Vergleich von Speichersystemen und GCS anstellen, wo wir klar zeigen werden, was unter welchen Bedingungen besser ist.
Und wo funktionieren hyperkonvergente Lösungen besser als Speichersysteme?
Basierend auf den obigen Thesen gibt es drei offensichtliche Schlussfolgerungen:
- Wenn zusätzliche 2 Millisekunden Aufzeichnungsverzögerungen, die in einem Produkt stabil auftreten (jetzt sprechen wir nicht mehr über Kunststoffe, Sie können Nanosekunden auf Kunststoffen anzeigen), nicht kritisch sind, reicht eine hyperkonvergente Funktion aus.
- Wenn die Last von großen physischen Servern in viele kleine virtuelle Server umgewandelt und von Knoten verteilt werden kann, funktioniert der Hyperkonvergent auch dort gut.
- Wo horizontale Skalierung wichtiger ist als vertikale Skalierung, funktioniert GCS auch dort einwandfrei.
Was sind diese Lösungen?
- Alle Standardinfrastrukturdienste (Verzeichnisdienst, Mail, EDS, Dateiserver, kleine oder mittlere ERP- und BI-Systeme usw.). Wir nennen dies "General Computing".
- Die Infrastruktur von Cloud-Anbietern, bei der es erforderlich ist, eine große Anzahl virtueller Maschinen für Clients schnell und standardisiert horizontal zu erweitern und einfach zu „schneiden“.
- Infrastruktur für virtuelle Desktops (VDI), bei der viele Virtuala für kleine Benutzer gestartet werden und leise in einem einheitlichen Cluster "schweben".
- Filialnetzwerke, in denen Sie in jeder Filiale eine standardmäßige, fehlertolerante und gleichzeitig kostengünstige Infrastruktur mit 15 bis 20 virtuellen Maschinen benötigen.
- Jedes verteilte Computing (z. B. Big Data-Dienste). Wo die Ladung nicht "tief" geht, sondern "breit".
- Testumgebungen, in denen zusätzliche kleine Verzögerungen akzeptabel sind, aber Budgetbeschränkungen bestehen, da es sich um Tests handelt.
Derzeit haben wir für diese Aufgaben AERODISK vAIR erstellt und konzentrieren uns darauf (bisher erfolgreich). Vielleicht wird sich das bald ändern. Die Welt steht nicht still.
Also ...
Damit ist der erste Teil einer großen Reihe von Artikeln abgeschlossen. Im nächsten Artikel werden wir über die Architektur der Lösung und die verwendeten Komponenten sprechen.
Wir freuen uns über Fragen, Vorschläge und konstruktive Streitigkeiten.