Magst du Java nicht? Ja, Sie wissen nicht, wie man es kocht! Mani Sarkar lädt uns ein, sich mit dem Valohai-Tool vertraut zu machen, mit dem Sie Modellrecherchen in Java durchführen können.
Haftungsausschluss des ÜbersetzersIch hoffe, dies ist keine Werbepublikation. Ich bin nicht mit Valohai verbunden. Ich habe gerade den Artikel übersetzt, auf den ich den Link verweise. Wenn ungeschickt übersetzt - treten Sie PM ein. Bei Bedarf kann ich Links löschen und andere externe Ressourcen erwähnen. Danke für das Verständnis.
Einführung
Vor einiger Zeit bin ich auf einen Cloud-Dienst namens Valohai gestoßen, und ich war mit seiner Benutzeroberfläche und der Einfachheit von Design und Layout zufrieden. Ich bat um den Dienst eines Mitglieds von Valohai und erhielt eine Demoversion. Vorher habe ich eine einfache Pipeline mit GNU Parallel, JavaScript, Python und Bash geschrieben - und eine andere, die nur GNU Parallel und Bash verwendet.
Ich habe auch darüber nachgedacht, gebrauchsfertige Tools für das Aufgaben- / Workflow-Management wie Jenkins X, Jenkins Pipeline, Concourse oder Airflow zu verwenden, aber aus verschiedenen Gründen habe ich mich dagegen entschieden.
Mir ist aufgefallen, dass viele Valohai-Beispiele und -Dokumentationen auf Python und R und ihren jeweiligen Frameworks und Bibliotheken basieren. Ich habe beschlossen, die Gelegenheit nicht zu verpassen und den Mangel an Beispielen und Dokumentation zu korrigieren.
Valohai hat mich dazu gedrängt, etwas mit der berühmten Java-Bibliothek
DL4J - Deep Learning for Java zu implementieren.
Meine erste Erfahrung mit Valohai machte einen guten Eindruck auf mich, nachdem ich mich durch Design, Layout und Workflow gefühlt hatte. Die Entwickler haben bereits verschiedene Aspekte sowohl der Entwickler-Workflows als auch der Infrastruktur berücksichtigt. In unserer Welt wird der Infrastrukturentwicklungsprozess hauptsächlich von den DevOps- oder SysOps-Teams gesteuert, und wir kennen die damit verbundenen Nuancen und Schwachstellen.
Was brauchen wir und wie?
In jedem maschinellen Lernprojekt gibt es zwei wichtige Komponenten (aus Sicht einer höheren Ebene) - einen Code, der mit dem Modell funktioniert, und einen Code, der mit der Infrastruktur funktioniert, in der der gesamte Projektlebenszyklus ausgeführt wird.
Natürlich werden vorher, während und nachher Schritte und Komponenten erforderlich sein, aber der Einfachheit halber benötigen wir Code und Infrastruktur.
Code
Für den Code habe ich ein komplexes Beispiel mit DL4J ausgewählt. Dies ist ein
MNist-Projekt mit einem Trainingssatz von 60.000 Bildern und einem
Testsatz von 10.000 Bildern handgeschriebener Ziffern. Dieser Datensatz ist über die DL4J-Bibliothek verfügbar (genau wie Keras).
Bevor Sie beginnen, wird empfohlen, dass Sie sich den Quellcode ansehen, den wir verwenden werden. Die Haupt-Java-Klasse heißt
org.deeplearning4j.feedforward.mnist.MLPMnistSingleLayerRunner .
Die Infrastruktur
Wir haben uns entschlossen, das Java-Beispiel mit Valohai als Infrastruktur für die Durchführung von Experimenten (Schulung und Modellbewertung) auszuprobieren. Valohai erkennt Git-Repositorys und stellt eine direkte Verbindung zu ihnen her, sodass wir unseren Code unabhängig von Plattform oder Sprache ausführen können. Wir werden also sehen, wie er funktioniert. Wenn Sie GitOps oder Infrastructure-As-Code verwenden, funktioniert auch alles für Sie.
Dazu brauchen wir nur einen Account bei Valohai. Nach dem Erstellen eines kostenlosen Kontos erhalten wir Zugriff auf mehrere Instanzen verschiedener Konfigurationen. Für das, was wir tun möchten, ist Free-Tier mehr als genug.
Deep Learning für Java und Valohai
Wir werden alle Abhängigkeiten zum Docker-Image bereitstellen und es verwenden, um unsere Java-Anwendung zu kompilieren, das Modell zu trainieren und es auf der Valohai-Plattform mithilfe einer einfachen Datei
valohai.yaml zu bewerten, die sich im Stammordner des Projekt-Repositorys befindet.
Deep Learning für Java: DL4J
Der einfachste Teil. Wir müssen nicht viel tun, sondern nur das Glas sammeln und den Datensatz in den Docker-Container laden. Wir haben ein vorgefertigtes Docker-Image, das alle Abhängigkeiten enthält, die zum Erstellen einer Java-Anwendung erforderlich sind. Wir haben dieses Bild in den Docker Hub eingefügt, und Sie können es finden, indem Sie nach dl4j-mnist-single-layer suchen (wir verwenden ein spezielles Tag, wie in der YAML-Datei definiert). Wir haben uns entschieden, GraalVM 19.1.1 als Build- und Laufzeit-Java-Umgebung für dieses Projekt zu verwenden, und es ist in das Docker-Image integriert.
Wenn das uber jar über die Befehlszeile aufgerufen wird, erstellen wir die Klasse MLPMnistSingleLayerRunner, die uns die beabsichtigte Aktion in Abhängigkeit von den übergebenen Parametern mitteilt:
public static void main(String[] args) throws Exception { MLPMnistSingleLayerRunner mlpMnistRunner = new MLPMnistSingleLayerRunner(); JCommander.newBuilder() .addObject(mlpMnistRunner) .build() .parse(args); mlpMnistRunner.execute(); }
An uber jar übergebene Parameter werden von dieser Klasse akzeptiert und von der Methode execute () verarbeitet.
Wir können ein Modell mit dem Parameter --action train erstellen und das erstellte Modell mit dem Parameter --action evalu bewerten, der an die Java-Anwendung übergeben wird.
Die Hauptteile der Java-Anwendung, die diese Arbeit ausführt, befinden sich in den beiden in den folgenden Abschnitten genannten Java-Klassen.
Modelltraining
Rufen Sie an
./runMLPMnist.sh --action train --output-dir ${VH_OUTPUTS_DIR} or java -Djava.library.path="" \ -jar target/MLPMnist-1.0.0-bin.jar \ --action train --output-dir ${VH_OUTPUTS_DIR}
Dieser Befehl erstellt ein Modell mit dem Namen mlpmnist-single-layer.pb in dem Ordner, der durch den zu Beginn der Ausführung übergebenen Parameter --output-dir angegeben wird. Aus Sicht von Valohai sollte es in $ {VH_OUTPUTS_DIR} platziert werden, was wir tun (siehe die Datei
valohai.yaml ).
Den Quellcode finden Sie in der Klasse
MLPMNistSingleLayerTrain.java .
Modellbewertung
Rufen Sie an
./runMLPMnist.sh --action evaluate --input-dir ${VH_INPUTS_DIR}/model or java -Djava.library.path="" \ -jar target/MLPMnist-1.0.0-bin.jar \ --action evaluate --input-dir ${VH_INPUTS_DIR}/model
Es wird davon ausgegangen, dass das Modell (das während der Trainingsphase erstellt wurde) mit dem Namen mlpmnist-single-layer.pb in dem Ordner vorhanden ist, der im Parameter --input-dir angegeben ist, der beim Aufruf der Anwendung übergeben wurde.
Den Quellcode finden Sie in der Klasse
MLPMNistSingleLayerEvaluate.java .
Ich hoffe, diese kurze Abbildung verdeutlicht, wie eine Java-Anwendung funktioniert, die ein Modell lehrt und bewertet.
Dies ist alles, was von uns verlangt wird, aber zögern Sie nicht, mit den restlichen
Quellen (zusammen mit
README.md und Bash-Skripten) zu spielen und Ihre Neugier und Ihr Verständnis dafür zu befriedigen, wie dies getan wird!
Valohai
Mit Valohai können wir unsere Laufzeit, unseren Code und unseren Datensatz frei verknüpfen, wie Sie aus der folgenden YAML-Dateistruktur ersehen können. Somit können sich verschiedene Komponenten unabhängig voneinander entwickeln. Folglich werden nur Assembly- und Laufzeitkomponenten in unseren Docker-Container gepackt.
Zur Laufzeit sammeln wir die Uber-JAR in einem Docker-Container, laden sie in einen internen oder externen Speicher und laden dann mit dem anderen Ausführungsschritt die Uber-JAR und den Datensatz aus dem Speicher (oder einem anderen Ort), um mit dem Training zu beginnen. Somit werden die zwei Ausführungsschritte getrennt; Zum Beispiel können wir ein Glas einmal kompilieren und Hunderte von Trainingsschritten für ein einzelnes Glas ausführen. Da sich Assembly- und Laufzeitumgebungen nicht so oft ändern müssen, können wir sie zwischenspeichern und auf Code, Datasets und Modelle kann zur Laufzeit dynamisch zugegriffen werden.
valohai.yamlDer Hauptteil der Integration unseres Java-Projekts in die Valohai-Infrastruktur besteht darin, die Reihenfolge der Ausführungsschritte in der Datei valohai.yaml im Stammverzeichnis Ihres Projektordners zu bestimmen. Unser valohai.yaml sieht so aus:
--- - step: name: Build-dl4j-mnist-single-layer-java-app image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - cd ${VH_REPOSITORY_DIR} - ./buildUberJar.sh - echo "~~~ Copying the build jar file into ${VH_OUTPUTS_DIR}" - cp target/MLPMnist-1.0.0-bin.jar ${VH_OUTPUTS_DIR}/MLPMnist-1.0.0.jar - ls -lash ${VH_OUTPUTS_DIR} environment: aws-eu-west-1-g2-2xlarge - step: name: Run-dl4j-mnist-single-layer-train-model image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - echo "~~~ Unpack the MNist dataset into ${HOME} folder" - tar xvzf ${VH_INPUTS_DIR}/dataset/mlp-mnist-dataset.tgz -C ${HOME} - cd ${VH_REPOSITORY_DIR} - echo "~~~ Copying the build jar file from ${VH_INPUTS_DIR} to current location" - cp ${VH_INPUTS_DIR}/dl4j-java-app/MLPMnist-1.0.0.jar . - echo "~~~ Run the DL4J app to train model based on the the MNist dataset" - ./runMLPMnist.sh {parameters} inputs: - name: dl4j-java-app description: DL4J Java app file (jar) generated in the previous step 'Build-dl4j-mnist-single-layer-java-app' - name: dataset default: https://github.com/neomatrix369/awesome-ai-ml-dl/releases/download/mnist-dataset-v0.1/mlp-mnist-dataset.tgz description: MNist dataset needed to train the model parameters: - name: --action pass-as: '--action {v}' type: string default: train description: Action to perform ie train or evaluate - name: --output-dir pass-as: '--output-dir {v}' type: string default: /valohai/outputs/ description: Output directory where the model will be created, best to pick the Valohai output directory environment: aws-eu-west-1-g2-2xlarge - step: name: Run-dl4j-mnist-single-layer-evaluate-model image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - cd ${VH_REPOSITORY_DIR} - echo "~~~ Copying the build jar file from ${VH_INPUTS_DIR} to current location" - cp ${VH_INPUTS_DIR}/dl4j-java-app/MLPMnist-1.0.0.jar . - echo "~~~ Run the DL4J app to evaluate the trained MNist model" - ./runMLPMnist.sh {parameters} inputs: - name: dl4j-java-app description: DL4J Java app file (jar) generated in the previous step 'Build-dl4j-mnist-single-layer-java-app' - name: model description: Model file generated in the previous step 'Run-dl4j-mnist-single-layer-train-model' parameters: - name: --action pass-as: '--action {v}' type: string default: evaluate description: Action to perform ie train or evaluate - name: --input-dir pass-as: '--input-dir {v}' type: string default: /valohai/inputs/model description: Input directory where the model created by the previous step can be found created environment: aws-eu-west-1-g2-2xlarge
So funktioniert die Build-dl4j-mnist-Single-Layer-Java-App
Aus der YAML-Datei geht hervor, dass wir diesen Schritt definieren, indem wir zuerst das Docker-Image verwenden und dann das Skript zum Erstellen der Uber-JAR ausführen. In unserem Docker-Image können Abhängigkeiten der Build-Umgebung (z. B. GraalVM JDK, Maven usw.) angepasst werden, um eine Java-Anwendung zu erstellen. Wir geben keine Eingaben oder Parameter an, da dies die Montagephase ist. Sobald der Build erfolgreich ist, kopieren wir das Uber-JAR mit dem Namen MLPMnist-1.0.0-bin.jar (ursprünglicher Name) in den Ordner / valohai / output (dargestellt als $ {VH_OUTPUTS_DIR}). Alles in diesem Ordner wird automatisch im Speicher Ihres Projekts gespeichert, z. B. im AWS S3-Papierkorb. Schließlich definieren wir unsere Arbeit für AWS.
HinweisDas kostenlose Valohai-Konto hat keinen Netzwerkzugriff über den Docker-Container (dies ist standardmäßig deaktiviert). Wenden Sie sich an den Support, um diese Option zu aktivieren (ich musste dasselbe tun). Andernfalls können wir unseren Maven und andere Abhängigkeiten nicht herunterladen während der Montage.
Wie Run-dl4j-mnist-single-layer-train-model funktioniert
Die Semantik der Definition ähnelt dem vorherigen Schritt, außer dass wir zwei Eingaben angeben: eine für uber jar (MLPMnist-1.0.0.jar) und die andere für den Datensatz (entpackt in den Ordner $ {HOME} /. Deeplearning4j). Wir werden zwei Parameter übergeben - --action train und --output-dir / valohai / output. Das in diesem Schritt erstellte Modell ist in / valohai / output / model (dargestellt als $ {VH_OUTPUTS_DIR} / model) erstellt.
HinweisIn den Eingabefeldern auf der Registerkarte "Ausführen" der Valohai-Weboberfläche können wir die Ausgabe aus vorherigen Läufen unter Verwendung der Laufnummer, d. H. Nr. 1 oder Nr. 2, zusätzlich zu den URLs datum: // oder http: / auswählen / Wenn Sie einige Buchstaben des Dateinamens eingeben, können Sie auch die gesamte Liste durchsuchen.
Wie Run-dl4j-mnist-single-layer -valu-model funktioniert
Auch dieser Schritt ähnelt dem vorherigen Schritt, außer dass wir zwei Parameter übergeben werden - action evalu und --input-dir / valohai / input / model. Außerdem haben wir in der Eingabe erneut angegeben: die in der YAML-Datei definierten Abschnitte mit dem Namen dl4j-java-app und model ohne die Standardeinstellung für beide. Auf diese Weise können wir das Uber-Jar und das Modell auswählen, das wir bewerten möchten. Dieses wurde mithilfe des Schrittes Run-dl4j-mnist-single-layer-train-model über die Weboberfläche erstellt.
Ich hoffe, dies erklärt die Schritte in der obigen Definitionsdatei. Wenn Sie jedoch weitere Hilfe benötigen, können Sie sich die
Dokumentation und die
Tutorials ansehen.
Valohai Webinterface
Nach Erhalt des Kontos können wir uns anmelden und das Projekt mit dem Namen mlpmnist-single-layer erstellen und git repo
github.com/valohai/mlpmnist-dl4j-example mit dem Projekt verknüpfen und das Projekt speichern.
Jetzt können Sie den Schritt abschließen und sehen, wie es ausgeht!
Erstellen Sie eine DL4J-Java-Anwendung
Gehen Sie in der Weboberfläche zur Registerkarte „Ausführung“ und kopieren Sie entweder die vorhandene Ausführung oder erstellen Sie eine neue über die Schaltfläche [Ausführung erstellen]. Alle notwendigen Standardparameter werden ausgefüllt. Wählen Sie Schritt Build-dl4j-mnist-single-layer-java-app.
Für die
Umgebung habe ich AWS eu-west-1 g2.2xlarge ausgewählt und unten auf der Seite auf die Schaltfläche [Ausführung erstellen] geklickt, um den Start der Ausführung anzuzeigen.
Modelltraining
Gehen Sie in der Weboberfläche zur Registerkarte „Ausführung“ und gehen Sie wie im vorherigen Schritt vor und wählen Sie Run-dl4j-mnist-single-layer-train-model aus. Sie müssen die Java-Anwendung auswählen (geben Sie einfach jar in das Feld ein), die im vorherigen Schritt erstellt wurde. Der Datensatz wurde bereits mit der Datei valohai.yaml vorab ausgefüllt:
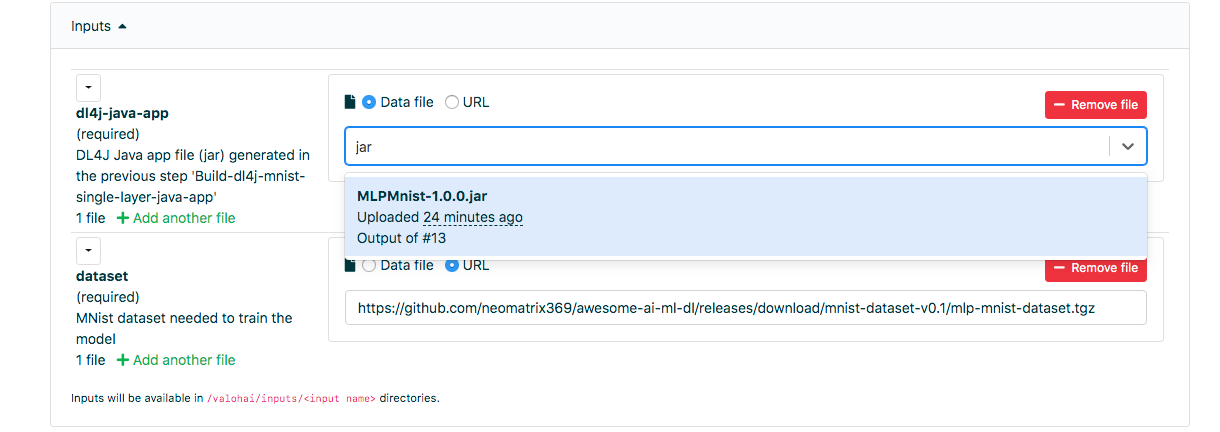
Klicken Sie zum Starten auf [Ausführung erstellen].
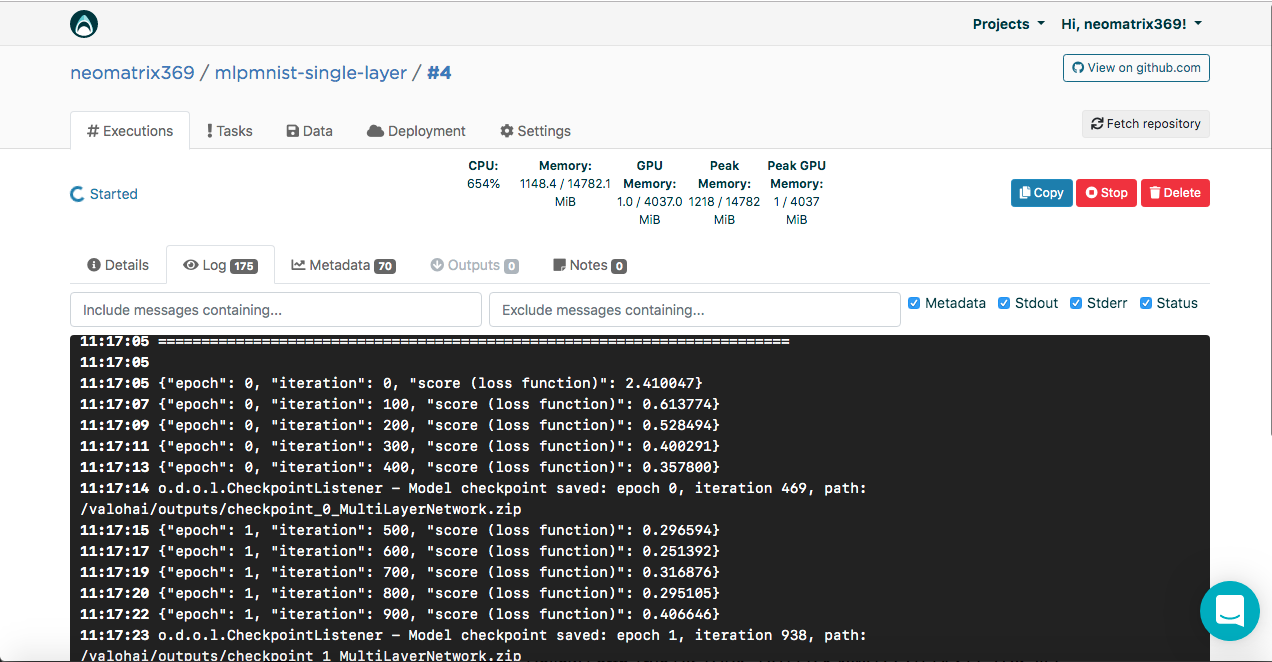
Sie sehen das Ergebnis in der Konsole:
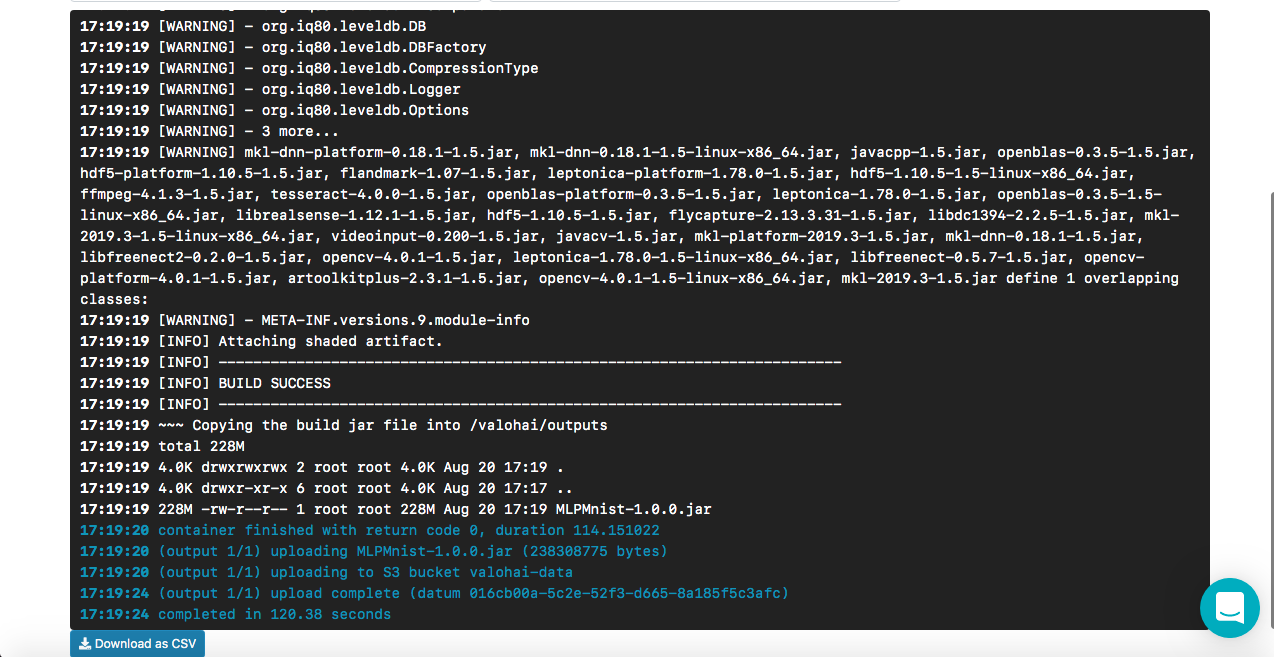
[<--- snipped --->] 11:17:05 ======================================================================= 11:17:05 LayerName (LayerType) nIn,nOut TotalParams ParamsShape 11:17:05 ======================================================================= 11:17:05 layer0 (DenseLayer) 784,1000 785000 W:{784,1000}, b:{1,1000} 11:17:05 layer1 (OutputLayer) 1000,10 10010 W:{1000,10}, b:{1,10} 11:17:05 ----------------------------------------------------------------------- 11:17:05 Total Parameters: 795010 11:17:05 Trainable Parameters: 795010 11:17:05 Frozen Parameters: 0 11:17:05 ======================================================================= [<--- snipped --->]
Erstellte Modelle finden Sie während und nach der Ausführung auf der Registerkarte "Ausgänge" der Hauptregisterkarte "Ausführung":
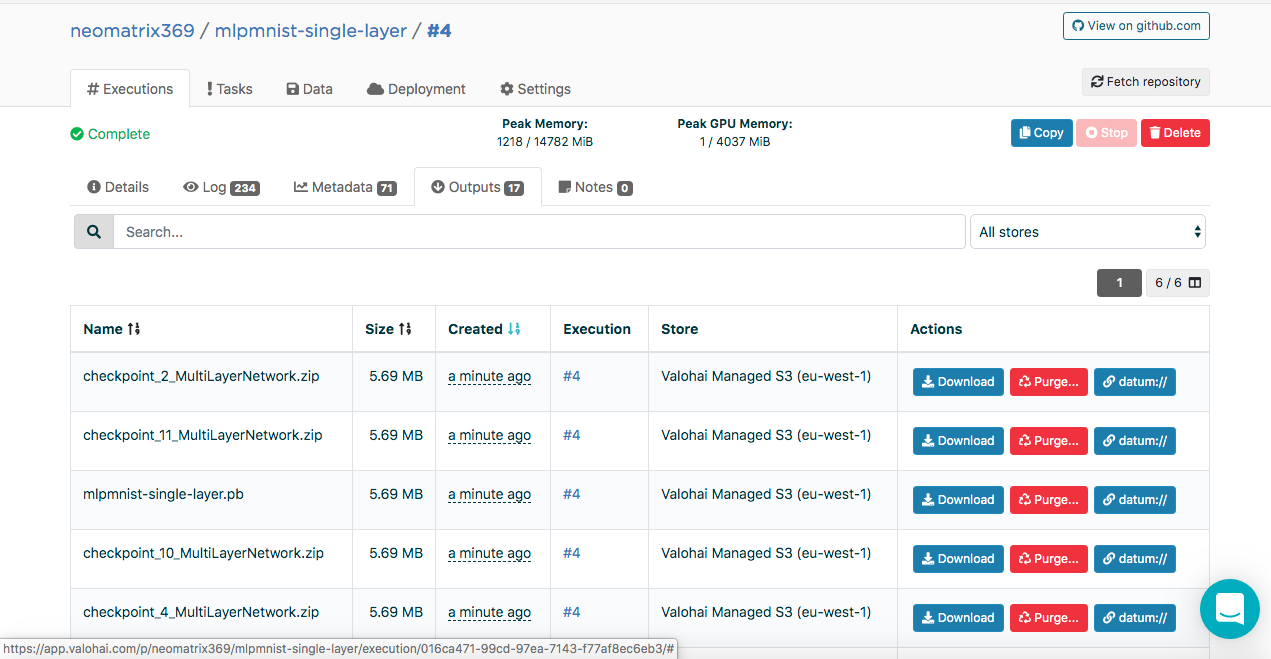
Möglicherweise stellen Sie auf der Unterregisterkarte "Ausgaben" mehrere Artefakte fest. Dies liegt daran, dass wir am Ende jeder Ära Kontrollpunkte beibehalten. Schauen wir uns das in den Protokollen an:
[<--- snipped --->] 11:17:14 odolCheckpointListener - Model checkpoint saved: epoch 0, iteration 469, path: /valohai/outputs/checkpoint_0_MultiLayerNetwork.zip [<--- snipped --->]
Der Prüfpunkt enthält den Status des Modells in drei Dateien:
configuration.json coefficients.bin updaterState.bin
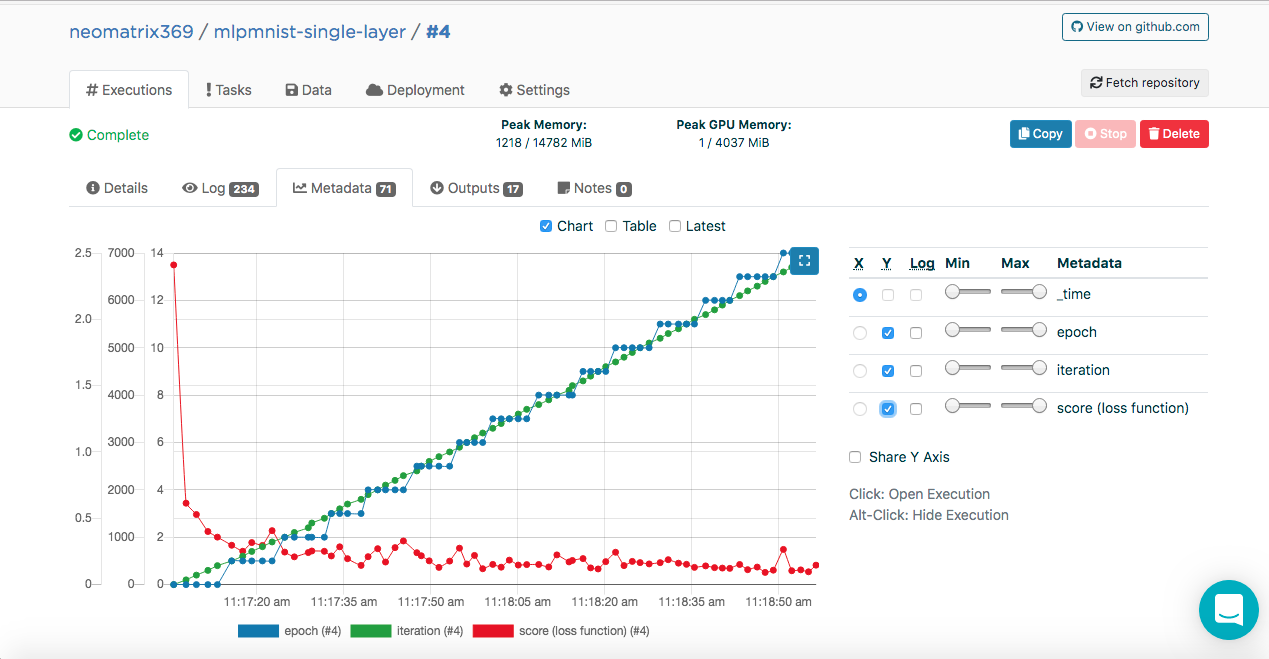
Modelltraining. Metadaten
Möglicherweise haben Sie diese Einträge in den Ausführungsprotokollen bemerkt:
[<--- snipped --->] 11:17:05 {"epoch": 0, "iteration": 0, "score (loss function)": 2.410047} 11:17:07 {"epoch": 0, "iteration": 100, "score (loss function)": 0.613774} 11:17:09 {"epoch": 0, "iteration": 200, "score (loss function)": 0.528494} 11:17:11 {"epoch": 0, "iteration": 300, "score (loss function)": 0.400291} 11:17:13 {"epoch": 0, "iteration": 400, "score (loss function)": 0.357800} 11:17:14 odolCheckpointListener - Model checkpoint saved: epoch 0, iteration 469, path: /valohai/outputs/checkpoint_0_MultiLayerNetwork.zip [<--- snipped --->]
Mit diesen Daten kann Valohai diese Werte (im JSON-Format) abrufen, die zum Erstellen der Metriken verwendet werden, die während und nach der Ausführung auf der zusätzlichen Registerkarte Metadaten auf der Hauptregisterkarte Ausführungen angezeigt werden:
Wir konnten dies tun, indem wir die ValohaiMetadataCreator-Klasse mit dem Modell verbanden, sodass Valohai während des Trainings auf diese Klasse verweist. Bei dieser Klasse leiten wir mehrere Epochen ab, die Anzahl der Iterationen und den Score (Wert der Verlustfunktion). Hier ist ein Codeausschnitt aus der Klasse:
public void iterationDone(Model model, int iteration, int epoch) { if (printIterations <= 0) printIterations = 1; if (iteration % printIterations == 0) { double score = model.score(); System.out.println(String.format( "{\"epoch\": %d, \"iteration\": %d, \"score (loss function)\": %f}", epoch, iteration, score) ); } }
Modellbewertung
Nachdem das Modell im vorherigen Schritt erfolgreich erstellt wurde, sollte es ausgewertet werden. Wir erstellen eine neue Ausführung auf die gleiche Weise wie zuvor, wählen diesmal jedoch den Schritt Run-dl4j-mnist-single-layer -valu-model aus. Wir müssen die Java-Anwendung (MLPMnist-1.0.0.jar) und das erstellte Modell (mlpmnist-single-layer.pb) erneut auswählen, bevor wir mit der Ausführung beginnen (wie unten gezeigt):
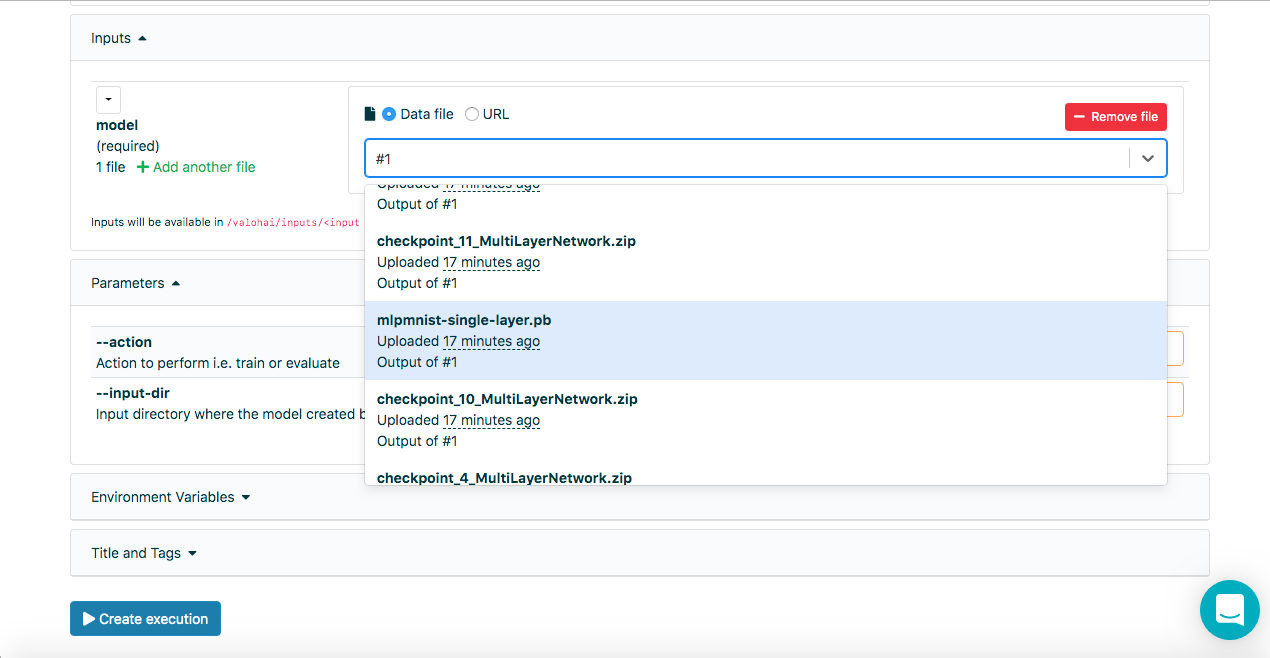
Nachdem Sie das gewünschte Modell als Eingabe ausgewählt haben, klicken Sie auf die Schaltfläche [Ausführung erstellen]. Es wird schneller ausgeführt als das vorherige, und wir werden das folgende Ergebnis sehen:
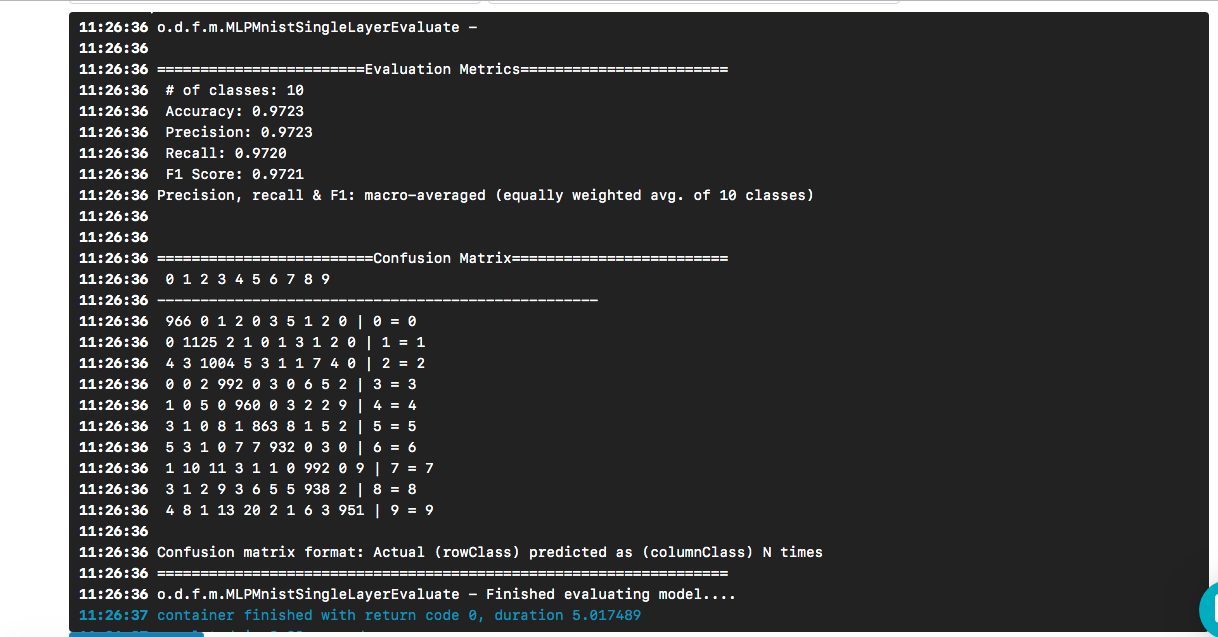
Wir sehen, dass unsere "Hallo Welt" zu einem Modell führte, dessen Genauigkeit basierend auf einem Testdatensatz etwa 97% beträgt. Die Verwirrungsmatrix hilft dabei, Fälle zu finden, in denen eine Ziffer fälschlicherweise als andere Ziffer vorhergesagt wurde.
Die Frage bleibt (und geht über den Rahmen dieses Beitrags hinaus): Wie gut ist das Modell, wenn es mit realen Daten konfrontiert wird?
Um ein Git-Repository zu klonen, müssen Sie Folgendes tun:
$ git clone https://github.com/valohai/mlpmnist-dl4j-example
Dann müssen wir unser Valohai-Projekt, das über die Weboberfläche im obigen Abschnitt erstellt wurde, mit dem Projekt verknüpfen, das auf unserem lokalen Computer gespeichert ist (dem, den wir gerade geklont haben). Führen Sie dazu die folgenden Befehle aus:
$ cd mlpmnist-dl4j-example $ vh project --help ### to see all the project-specific options we have for Valohai $ vh project link
Ihnen wird ungefähr so gezeigt:
[ 1] mlpmnist-single-layer ... Which project would you like to link with /path/to/mlpmnist-dl4j-example? Enter [n] to create a new project.:
Wählen Sie 1 (oder diejenige, die zu Ihnen passt) und Sie sollten diese Meldung sehen:
Success! Linked /path/to/mlpmnist-dl4j-example to mlpmnist-single-layer.
Bevor Sie fortfahren, stellen Sie sicher, dass Ihr Valohai-Projekt mit dem neuesten Git-Projekt synchronisiert ist.
$ vh project fetch
Jetzt können wir die Schritte von der CLI aus ausführen mit:
$ vh exec run Build-dl4j-mnist-single-layer-java-app
Nachdem die Ausführung abgeschlossen ist, können wir dies überprüfen mit:
$ vh exec info $ vh exec logs $ vh exec watch
Fazit
Wie wir gesehen haben, ist es sehr praktisch, mit DL4J und Valohai zusammenzuarbeiten. Darüber hinaus können wir die verschiedenen Komponenten, aus denen unsere Experimente (Forschung) bestehen, dh die Build- / Laufzeitumgebung, den Code und den Datensatz, entwickeln und in unser Projekt integrieren.
Die in diesem Beitrag verwendeten Beispielvorlagen sind eine gute Möglichkeit, komplexere Projekte zu erstellen. Und Sie können die Web- oder Befehlszeilenschnittstelle verwenden, um Ihre Arbeit mit Valohai zu erledigen. Mit der CLI können Sie sie auch in Ihre Installationen und Skripte (oder sogar in CRON- oder CI / CD-Jobs) integrieren.
Darüber hinaus ist klar, dass ich mich bei der Arbeit an einem Projekt im Zusammenhang mit AI / ML / DL nicht um die Erstellung und Wartung einer End-to-End-Pipeline kümmern muss (was viele andere in der Vergangenheit tun mussten).
Referenzen
- Das mlpmnist-dl4j-Beispielprojekt auf GitHub
- Fantastische AI / ML / DL-Ressourcen
- Java AI / ML / DL-Ressourcen
- Deep Learning und DL4J-Ressourcen
Vielen Dank für Ihre Aufmerksamkeit!