Es scheint, dass der Bereich der Online-Werbung so technologisch und automatisiert wie möglich sein sollte. In der Tat arbeiten dort Giganten und Experten auf ihrem Gebiet wie Yandex, Mail.Ru, Google und Facebook. Aber wie sich herausstellte, gibt es keine Grenzen für die Perfektion und es gibt immer etwas zu automatisieren.
 Quelle
QuelleDie Kommunikationsgruppe
Dentsu Aegis Network Russia ist der größte Anbieter auf dem digitalen Werbemarkt und investiert aktiv in Technologie, um ihre Geschäftsprozesse zu optimieren und zu automatisieren. Eines der ungelösten Probleme des Online-Werbemarktes war die Erfassung von Statistiken zu Werbekampagnen auf verschiedenen Online-Sites. Die Lösung für dieses Problem führte letztendlich zur Entwicklung des
D1.Digital- Produkts (als DiVan gelesen), über dessen Entwicklung wir sprechen möchten.
Warum?
1. Zum Zeitpunkt des Projektstarts gab es kein einziges fertiges Produkt auf dem Markt, das die Aufgabe der Automatisierung der Erfassung von Statistiken zu Werbekampagnen löste.
Dies bedeutet, dass niemand außer uns unsere Bedürfnisse schließen wird.Dienste wie Improvado, Roistat, Supermetrics, SegmentStream bieten die Integration in Websites, soziale Netzwerke und Google Analitycs sowie die Möglichkeit, analytische Dashboards für die bequeme Analyse und Steuerung von Werbekampagnen zu erstellen. Bevor wir mit der Entwicklung unseres Produkts begannen, haben wir versucht, einige dieser Systeme in unserer Arbeit zu verwenden, um Daten von Websites zu sammeln, aber leider konnten sie unsere Probleme nicht lösen.
Das Hauptproblem bestand darin, dass die getesteten Produkte aus Datenquellen abgestoßen wurden, Statistiken von Platzierungen in Abschnitten nach Websites angezeigt wurden und keine Aggregation von Statistiken zu Werbekampagnen zuließ. Dieser Ansatz ermöglichte es nicht, Statistiken von verschiedenen Standorten an einem Ort anzuzeigen und den Status der Kampagne als Ganzes zu analysieren.
Ein weiterer Faktor war, dass die Produkte in der Anfangsphase auf den westlichen Markt ausgerichtet waren und die Integration mit russischen Standorten nicht unterstützten. Und für die Sites, mit denen die Integration implementiert wurde, wurden nicht immer alle erforderlichen Metriken mit ausreichenden Details hochgeladen, und die Integration war nicht immer bequem und transparent, insbesondere wenn etwas abgerufen werden musste, das sich nicht in der Systemschnittstelle befand.
Im Allgemeinen haben wir beschlossen, uns nicht an Produkte von Drittanbietern anzupassen, sondern haben begonnen, unsere eigenen ...
2. Der Online-Werbemarkt wächst von Jahr zu Jahr und übertraf 2018 traditionell den größten TV-Werbemarkt in Bezug auf das Werbebudget.
Es gibt also eine Skala .
3. Im Gegensatz zum TV-Werbemarkt, auf dem der Verkauf von kommerzieller Werbung monopolisiert ist, arbeitet die Masse der einzelnen Eigentümer von Werbemitteln unterschiedlicher Größe mit ihren Werbebüros im Internet. Da die Werbekampagne in der Regel auf mehreren Websites gleichzeitig ausgeführt wird, müssen zum Sammeln des Status der Werbekampagne Berichte von allen Websites gesammelt und zu einem großen Bericht zusammengefasst werden, der das gesamte Bild zeigt.
Es besteht also Optimierungspotential.4. Es schien uns, dass die Eigentümer von Werbeinventar im Internet bereits über eine Infrastruktur zum Sammeln und Anzeigen von Statistiken in Werbebüros verfügten und eine API für diese Daten bereitstellen konnten.
Es gibt also eine technische Machbarkeit. Wir werden gleich sagen, dass es nicht so einfach war.
Im Allgemeinen waren uns alle Voraussetzungen für die Umsetzung des Projekts klar, und wir liefen, um das Projekt umzusetzen ...
Großartiger Plan
Zunächst formulierten wir eine Vision eines idealen Systems:
- Es sollte automatisch Werbekampagnen aus dem 1C-Unternehmenssystem mit ihren Namen, Zeiträumen, Budgets und Platzierungen auf verschiedenen Plattformen laden.
- Für jede Platzierung innerhalb der Werbekampagne sollten alle möglichen Statistiken von den Websites, auf denen die Platzierung durchgeführt wird, automatisch heruntergeladen werden, z. B. die Anzahl der Impressionen, Klicks, Ansichten usw.
- Einige Werbekampagnen werden von Dritten durch sogenannte Adserving-Systeme wie Adriver, Weborama, DCM usw. überwacht. In Russland gibt es auch einen industriellen Internet-Zähler - Mediascope. Nach unserer Vorstellung sollten die Daten der unabhängigen und industriellen Überwachung auch automatisch in die entsprechenden Werbekampagnen hochgeladen werden.
- Die meisten Werbekampagnen im Internet zielen auf bestimmte gezielte Aktionen (Kaufen, Anrufen, Aufzeichnen für eine Probefahrt usw.) ab, die mithilfe von Google Analytics verfolgt werden, und Statistiken, die ebenfalls wichtig für das Verständnis des Kampagnenstatus sind und in unser Tool hochgeladen werden sollten .
Der erste Pfannkuchen ist klumpig
In Anbetracht unseres Engagements für flexible Prinzipien der Softwareentwicklung (agil, alles in allem) haben wir uns entschlossen, zuerst MVP zu entwickeln und dann iterativ auf das angestrebte Ziel hinzuarbeiten.
Wir haben uns entschlossen, MVP auf Basis unseres Produkts
DANBo (Dentsu Aegis Network Board) zu erstellen , einer Webanwendung mit allgemeinen Informationen zu den Werbekampagnen unserer Kunden.
Für MVP wurde das Projekt hinsichtlich der Implementierung maximal vereinfacht. Wir haben eine begrenzte Liste von Websites für die Integration ausgewählt. Dies waren die Hauptplattformen wie Yandex.Direct, Yandex.Display, RB.Mail, MyTarget, AdWords, DBM, VK, FB und die Haupt-Adserving-Systeme Adriver und Weborama.
Für den Zugriff auf Statistiken zu den Websites über die API haben wir ein einzelnes Konto verwendet. Der Kundengruppenmanager, der die automatische Erfassung von Statistiken zur Werbekampagne nutzen wollte, musste zunächst den Zugriff auf die erforderlichen Werbekampagnen auf den Websites an das Plattformkonto delegieren.
Ferner musste der Benutzer des
DANBo- Systems eine Datei eines bestimmten Formats in das Excel-System hochladen, in der alle Informationen über die Platzierung (Werbekampagne, Website, Format, Platzierungszeitraum, geplante Indikatoren, Budget usw.) und die Kennungen der entsprechenden Werbekampagnen auf den Websites geschrieben wurden und Zähler in Adserving-Systemen.
Es sah ehrlich gesagt erschreckend aus:

Die heruntergeladenen Daten wurden in der Datenbank gespeichert, und dann sammelten einzelne Dienste Kampagnenkennungen von ihnen von den Websites und luden Statistiken über sie herunter.
Für jede Site wurde ein separater Windows-Dienst geschrieben, der einmal täglich unter einem Dienstkonto in der API der Site abgelegt und Statistiken zu den angegebenen Kampagnen-IDs heruntergeladen wurde. Dasselbe geschah mit Adserving-Systemen.
Die heruntergeladenen Daten wurden auf der Benutzeroberfläche in Form eines kleinen selbstgeschriebenen Dashboards angezeigt:
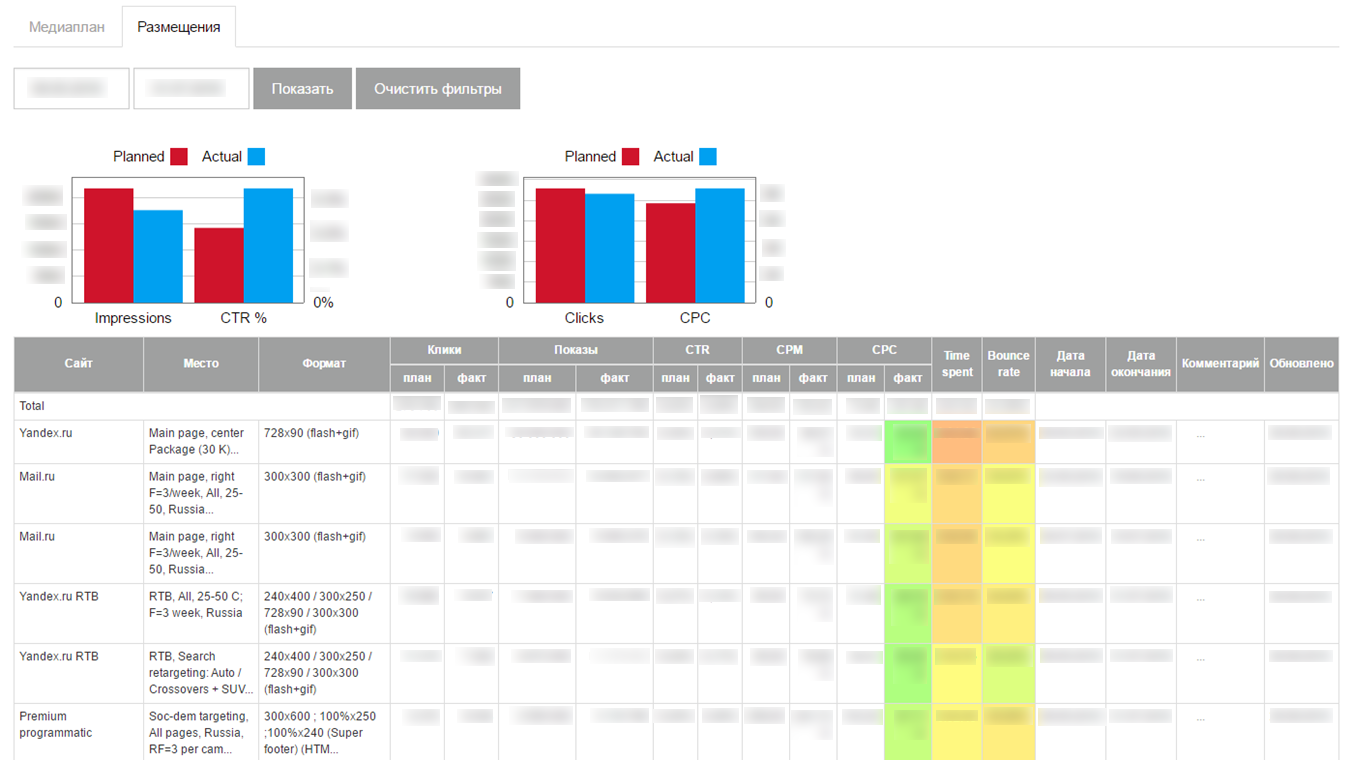
Unerwartet für uns verdiente MVP und begann, aktuelle Statistiken über Werbekampagnen im Internet herunterzuladen. Wir haben das System auf mehreren Clients implementiert, aber als wir versuchten, es zu skalieren, stießen wir auf ernsthafte Probleme:
- Das Hauptproblem war die mühsame Vorbereitung der Daten zum Laden in das System. Außerdem mussten die Platzierungsdaten vor dem Herunterladen auf ein streng festes Format reduziert werden. In der Datei zum Laden mussten die Kennungen von Entitäten von verschiedenen Standorten registriert werden. Wir sind mit der Tatsache konfrontiert, dass es für technisch nicht geschulte Benutzer sehr schwierig ist zu erklären, wo diese Kennungen auf der Website zu finden sind und wo sie in die Datei aufgenommen werden sollen. Angesichts der Anzahl der Mitarbeiter in den Abteilungen, die Kampagnen auf den Standorten durchführen, und des Umsatzes führte dies zu einer enormen Unterstützung auf unserer Seite, die kategorisch nicht zu uns passte.
- Ein weiteres Problem bestand darin, dass nicht alle Werbeplattformen über Mechanismen verfügten, um den Zugriff auf Werbekampagnen auf andere Konten zu delegieren. Aber selbst wenn der Delegierungsmechanismus verfügbar war, waren nicht alle Werbetreibenden bereit, Drittanbieter-Kontozugriff auf ihre Kampagnen zu gewähren.
- Ein wichtiger Faktor war die Empörung, die dazu führte, dass Benutzer alle geplanten Indikatoren und Platzierungsdetails, die sie bereits zu unserem 1C-Buchhaltungssystem beitragen, erneut in DANBo eingeben sollten .
Dies brachte uns auf die Idee, dass die Hauptinformationsquelle über den Standort unser 1C-System sein sollte, in dem alle Daten genau und pünktlich eingegeben werden (der Punkt ist, dass basierend auf den 1C-Daten Konten gebildet werden, daher ist die korrekte Eingabe der Daten in 1C für alle in KPI). So erschien ein neues Systemkonzept ...
Konzept
Als erstes haben wir beschlossen, das System zur Erfassung von Statistiken über Werbekampagnen im Internet in ein separates Produkt zu unterteilen -
D1.Digital .
In dem neuen Konzept haben wir beschlossen, Informationen zu Werbekampagnen und darin enthaltenen Placements von 1C in
D1.Digital zu
laden und dann Statistiken von Websites und von AdServing-Systemen auf diese Placements zu ziehen. Dies sollte das Leben der Benutzer erheblich vereinfachen (und wie üblich den Entwicklern Arbeit hinzufügen) und den Support reduzieren.
Das erste Problem, auf das wir stießen, war organisatorischer Natur und hing mit der Tatsache zusammen, dass wir keinen Schlüssel oder kein Attribut finden konnten, anhand dessen wir Entitäten aus verschiedenen Systemen mit Kampagnen und Placements von 1C vergleichen konnten. Tatsache ist, dass der Prozess in unserem Unternehmen so gestaltet ist, dass Werbekampagnen von verschiedenen Personen (Mediaplayer, Kauf usw.) in unterschiedliche Systeme eingegeben werden.
Um dieses Problem zu lösen, mussten wir einen eindeutigen Hash-Schlüssel, DANBoID, erfinden, der Entitäten in verschiedenen Systemen miteinander verbindet und der in den geladenen Datensätzen recht einfach und eindeutig identifiziert werden kann. Diese Kennung wird im internen 1C-System für jede einzelne Platzierung generiert und in Kampagnen, Platzierungen und Zähler an allen Standorten und in allen AdServing-Systemen verwendet. Die Implementierung der Praxis, DANBoID an allen Placements anzubringen, hat einige Zeit gedauert, aber wir haben es geschafft :)
Dann haben wir festgestellt, dass nicht alle Websites über eine API für die automatische Erfassung von Statistiken verfügen und selbst diejenigen mit einer API nicht alle erforderlichen Daten zurückgeben.
Zu diesem Zeitpunkt haben wir beschlossen, die Liste der zu integrierenden Websites erheblich zu reduzieren und uns auf die Hauptwebsites zu konzentrieren, die an der überwiegenden Mehrheit der Werbekampagnen beteiligt sind. Diese Liste enthält alle größten Akteure auf dem Werbemarkt (Google, Yandex, Mail.ru), soziale Netzwerke (VK, Facebook, Twitter), die wichtigsten AdServing- und Analysesysteme (DCM, Adriver, Weborama, Google Analytics) und andere Plattformen.
Der Großteil der von uns ausgewählten Websites verfügte über eine API, die uns die erforderlichen Metriken lieferte. In den Fällen, in denen die API nicht vorhanden war oder nicht über die erforderlichen Daten verfügte, verwendeten wir Berichte, die täglich per Geschäftspost eingingen, um die Daten herunterzuladen (in einigen Systemen ist es möglich, solche Berichte zu konfigurieren, in anderen stimmten sie der Entwicklung solcher Berichte für uns zu).
Bei der Analyse von Daten von verschiedenen Standorten haben wir festgestellt, dass die Hierarchie der Entitäten in verschiedenen Systemen nicht gleich ist. Darüber hinaus müssen Informationen aus verschiedenen Systemen unterschiedlich detailliert geladen werden.
Um dieses Problem zu lösen, wurde das SubDANBoID-Konzept entwickelt. Die Idee von SubDANBoID ist recht einfach. Wir kennzeichnen das Hauptaugenmerk der Kampagne auf der Site mit der generierten DANBoID. Wir laden alle verschachtelten Entitäten mit eindeutigen Kennungen der Site hoch und bilden die SubDANBoID gemäß dem DANBoID-Prinzip + Kennung der verschachtelten Entität der ersten Ebene + Kennung der verschachtelten Entität der zweiten Ebene Werbekampagnen in verschiedenen Systemen und laden Sie detaillierte Statistiken darüber hoch.
Wir mussten auch das Problem des Zugriffs auf Kampagnen an verschiedenen Standorten lösen. Wie oben beschrieben, ist der Mechanismus zum Delegieren des Zugriffs auf die Kampagne an ein separates technisches Konto nicht immer anwendbar. Daher mussten wir eine Infrastruktur für die automatische Autorisierung durch OAuth unter Verwendung von Token und Aktualisierungsmechanismen für diese Token entwickeln.
Weiter im Artikel werden wir versuchen, die Architektur der Lösung und die technischen Details der Implementierung detaillierter zu beschreiben.
Lösungsarchitektur 1.0
Als wir mit der Implementierung eines neuen Produkts begannen, war uns klar, dass es sofort notwendig war, die Möglichkeit zum Verbinden neuer Standorte vorzusehen, und beschlossen daher, den Weg der Microservice-Architektur zu beschreiten.
Bei der Gestaltung der Architektur haben wir separate Service-Konnektoren für alle externen Systeme ausgewählt - 1C, Werbeplattformen und Adserving-Systeme.
Die Hauptidee ist, dass alle Konnektoren zu den Sites dieselbe API haben und Adapter sind, die die Site-APIs zu unserer praktischen Oberfläche bringen.
Im Zentrum unseres Produkts steht eine Webanwendung, bei der es sich um einen Monolithen handelt, der so konzipiert ist, dass er leicht in Services zerlegt werden kann. Diese Anwendung ist dafür verantwortlich, heruntergeladene Daten zu verarbeiten, Statistiken von verschiedenen Systemen zu vergleichen und sie den Benutzern des Systems zu präsentieren.
Um Konnektoren mit einer Webanwendung zu kommunizieren, mussten wir einen zusätzlichen Dienst erstellen, den wir Connector Proxy nannten. Es führt die Funktionen von Service Discovery und Task Scheduler aus. Dieser Dienst führt jede Nacht Datenerfassungsaufgaben für jeden Connector aus. Das Schreiben einer Service-Schicht war einfacher als das Verbinden eines Nachrichtenbrokers, und für uns war es wichtig, das Ergebnis so schnell wie möglich zu erhalten.
Aus Gründen der Einfachheit und Geschwindigkeit der Entwicklung haben wir außerdem beschlossen, dass alle Dienste eine Web-API sind. Dies ermöglichte es, schnell einen Proof-of-Concept zusammenzustellen und zu überprüfen, ob das gesamte Design funktionierte.
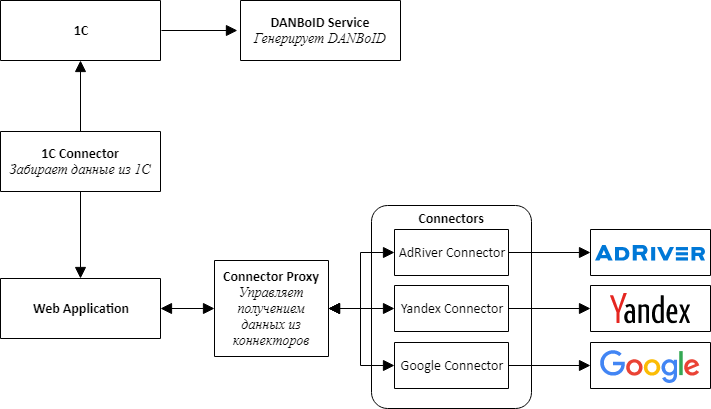
Eine separate, ziemlich schwierige Aufgabe bestand darin, den Zugriff zum Sammeln von Daten aus verschiedenen Schränken einzurichten, die, wie wir beschlossen hatten, von den Benutzern über eine Weboberfläche ausgeführt werden sollten. Es besteht aus zwei separaten Schritten: Zuerst fügt der Benutzer über OAuth ein Token hinzu, um auf das Konto zuzugreifen, und richtet dann die Datenerfassung für den Client von einem bestimmten Konto aus ein. Das Abrufen eines Tokens über OAuth ist erforderlich, da es, wie bereits geschrieben, nicht immer möglich ist, den Zugriff auf das gewünschte Kabinett auf der Site zu delegieren.
Um einen universellen Mechanismus für die Auswahl eines Schranks aus Sites zu erstellen, mussten wir der Connectors-API eine Methode hinzufügen, mit der das JSON-Schema gerendert wird, das mithilfe einer modifizierten JSONEditor-Komponente in das Formular gerendert wird. So konnten Benutzer die Konten auswählen, von denen Daten heruntergeladen werden sollen.
Um die auf den Websites geltenden Anforderungslimits einzuhalten, kombinieren wir die Anforderung von Einstellungen innerhalb desselben Tokens, können jedoch verschiedene Token parallel verarbeiten.
Wir haben MongoDB als Repository für herunterladbare Daten sowohl für eine Webanwendung als auch für Konnektoren ausgewählt, sodass wir uns in den ersten Entwicklungsphasen, wenn sich das Anwendungsmodell nach einem Tag ändert, nicht viel um die Datenstruktur kümmern mussten.
Bald stellten wir fest, dass nicht alle Daten gut in MongoDB passen und beispielsweise tägliche Statistiken bequemer in einer relationalen Datenbank zu speichern sind. Daher haben wir für Konnektoren, deren Datenstruktur besser für eine relationale Datenbank geeignet ist, begonnen, PostgreSQL oder MS SQL Server als Speicher zu verwenden.
Die ausgewählte Architektur und Technologie ermöglichte es uns, das Produkt D1.Digital relativ schnell zu entwickeln und auf den Markt zu bringen. In den zwei Jahren der Produktentwicklung haben wir 23 Site-Konnektoren entwickelt, wertvolle Erfahrungen mit APIs von Drittanbietern gesammelt, gelernt, wie die Fallstricke verschiedener Sites mit jeweils eigenen Sites umgangen werden können, zur Entwicklung der API mindestens 3 Sites beigetragen, automatisch Informationen zu fast 15.000 Kampagnen heruntergeladen und In mehr als 80.000 Placements haben wir viele Rückmeldungen von Benutzern zum Produkt gesammelt und es geschafft, den Hauptprozess des Produkts basierend auf diesen Rückmeldungen mehrmals zu ändern.
Lösungsarchitektur 2.0
Seit Beginn der Entwicklung von
D1.Digital sind zwei Jahre vergangen. Die stetig zunehmende Belastung des Systems und das Aufkommen immer neuer Datenquellen zeigten allmählich Probleme in der bestehenden Lösungsarchitektur.
Das erste Problem hängt mit der Datenmenge zusammen, die von den Websites heruntergeladen wurde. Wir waren mit der Tatsache konfrontiert, dass das Sammeln und Aktualisieren aller erforderlichen Daten von den größten Standorten zu lange dauerte. Das Sammeln von Daten auf dem AdRiver-Adserving-System, mit dem wir Statistiken für die meisten Placements verfolgen, dauert beispielsweise etwa 12 Stunden.
Um dieses Problem zu lösen, haben wir begonnen, alle Arten von Berichten zum Herunterladen von Daten von den Websites zu verwenden. Wir versuchen, deren APIs zusammen mit den Websites so zu entwickeln, dass ihre Geschwindigkeit unseren Anforderungen entspricht, und das Laden von Daten so weit wie möglich zu parallelisieren.
Ein weiteres Problem ist die Verarbeitung heruntergeladener Daten. Mit der Einführung neuer Statistiken zur Platzierung wird nun ein mehrstufiger Prozess zur Neuberechnung von Metriken gestartet, der das Laden von Rohdaten, das Berechnen aggregierter Metriken für jede Site, das Vergleichen von Daten aus verschiedenen Quellen und das Berechnen von zusammenfassenden Metriken für die Kampagne umfasst. Dies führt zu einer hohen Belastung der Webanwendung, die alle Berechnungen durchführt. Während des Nachzählens verbraucht die Anwendung mehrmals den gesamten Speicher auf dem Server, etwa 10 bis 15 GB, was sich am nachteiligsten auf die Arbeit des Benutzers mit dem System auswirkt.
Die identifizierten Probleme und großartigen Pläne für die Weiterentwicklung des Produkts führten dazu, dass die Anwendungsarchitektur überarbeitet werden musste.
Wir haben mit Steckverbindern begonnen.
Wir haben festgestellt, dass alle Konnektoren nach demselben Modell arbeiten. Deshalb haben wir einen Pipeline-Förderer gebaut, in dem Sie zum Erstellen des Konnektors nur die Logik der Schritte programmieren mussten. Der Rest war universell. Wenn ein Konnektor verbessert werden muss, werden wir ihn sofort auf ein neues Framework übertragen, während der Konnektor fertiggestellt wird.
Parallel dazu haben wir begonnen, Konnektoren in Docker und Kubernetes zu platzieren.
Wir hatten vor, lange Zeit auf Kubernetes umzusteigen, experimentierten mit CI / CD-Einstellungen, begannen jedoch erst, als ein Connector aufgrund eines Fehlers mehr als 20 GB Speicher auf dem Server verbrauchte und den Rest der Prozesse fast zum Erliegen brachte. Während der Untersuchung wurde der Konnektor in den Kubernetes-Cluster verschoben, wo er schließlich auch dann blieb, wenn der Fehler behoben wurde.
Sehr schnell stellten wir fest, dass Kubernetes praktisch war, und in sechs Monaten haben wir 7 Connectors und Connectors Proxy in den Produktionscluster verschoben, die die meisten Ressourcen verbrauchen.
Im Anschluss an die Konnektoren haben wir beschlossen, die Architektur der restlichen Anwendung zu ändern.
Das Hauptproblem bestand darin, dass die Daten von Konnektoren zu Proxys in großen Bündeln stammen und dann auf DANBoID schlagen und zur Verarbeitung an eine zentrale Webanwendung übertragen werden. Aufgrund der großen Anzahl von Neuberechnungen von Metriken tritt eine große Belastung für die Anwendung auf.
, , web , , , - .
2.0.
, Web API RabbitMQ MassTransit . Connectors Proxy, Connectors Hub. , , .
web , . .
Kubernetes, .
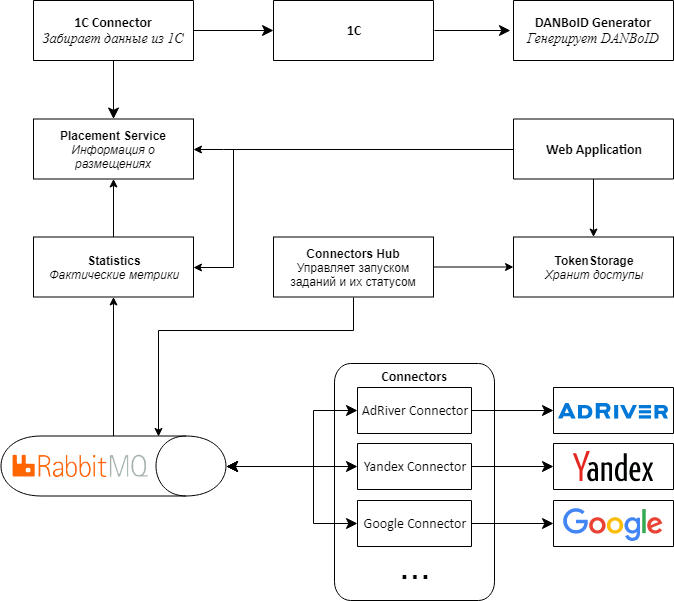
Proof-of-concept 2.0
D1.Digital . — 20 , , , , .
, API, .
, , adserving .
, web , Kubernetes. , , .
, MongoDB. SQL-, , , , .
, , :)
R&D Dentsu Aegis Network Russia: ( shmiigaa ), ( hitexx )