Vor fünf Jahren wurde auf Habré ein Artikel
„Drucken und Wiedergeben von Ton auf Papier“ veröffentlicht - über das System zum Erstellen und Abspielen von
Spektrogrammen . Dann, vor anderthalb Jahren, veröffentlichte
Meklon eine
Quest, bei der ein solches logarithmisches Schwarz-Weiß-Spektrogramm zu einer der Stufen wurde. Entsprechend der Absicht des Autors war es erforderlich, es auf einem Drucker zu drucken, es mit einem Smartphone mit einer Player-Anwendung zu scannen und auf diese Weise das „diktierte“ Passwort zu verwenden.
Zu diesem Zeitpunkt hatte ich weder eine Reichweite für einen Drucker noch für ein Smartphone, daher interessierte mich zwei Aspekt der Aufgabe:
- Was ist der einfachste Weg, um das Spektrogramm ohne zusätzliche Geräte und ohne zusätzliche Software zu dekodieren - vorzugsweise direkt im Browser?
- Ist es möglich, es ohne Software zu entschlüsseln - "per Auge"?
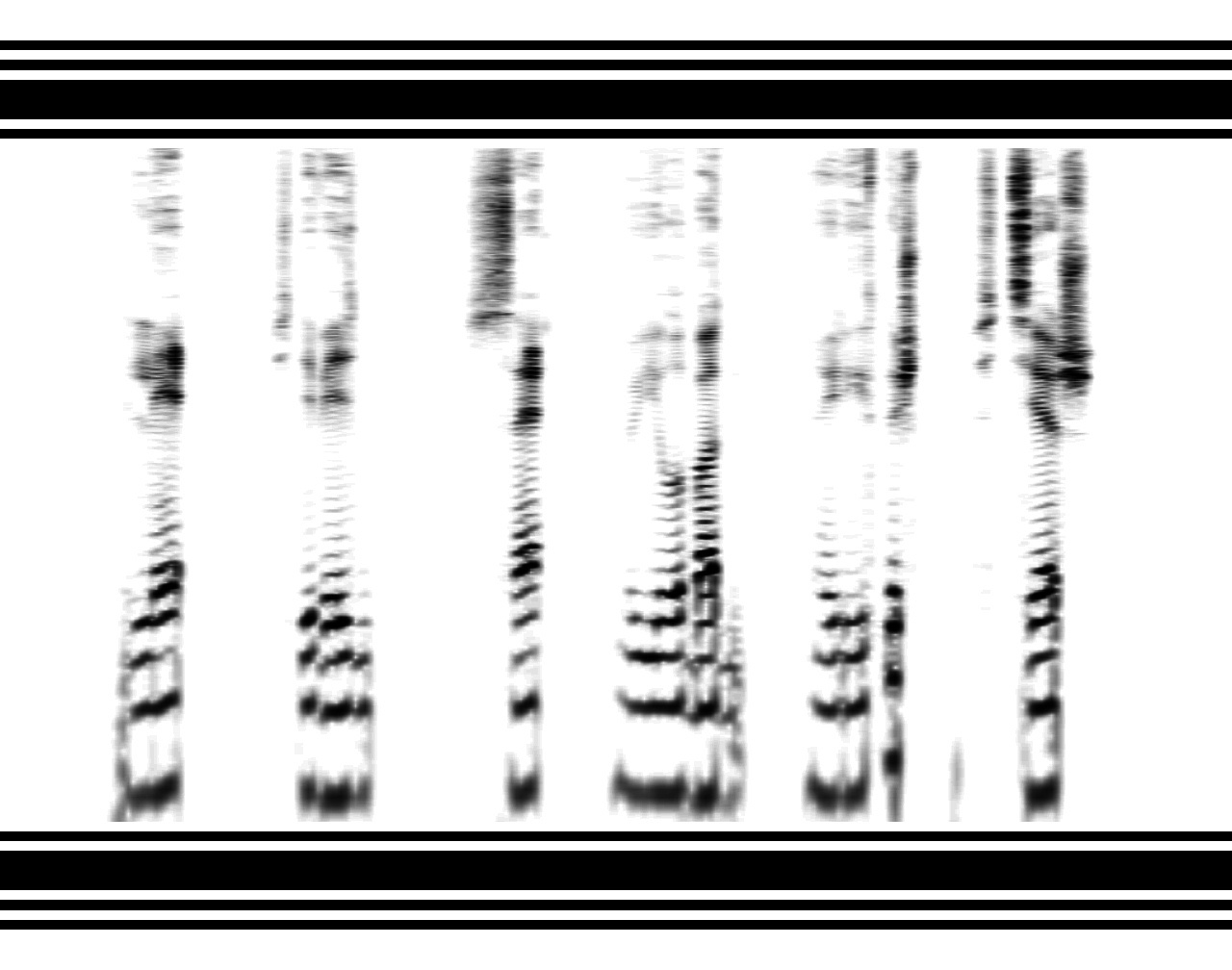
(Für diejenigen, die zum ersten Mal Spektrogramme sehen, ist es sinnvoll zu verdeutlichen, dass dies ein Diagramm ist, in dem die Wiedergabezeit entlang der horizontalen Achse, die Schallfrequenz entlang der vertikalen Achse (logarithmisch) und der Schwärzungsgrad des Punkts die Leistung dieser Frequenz zu einem bestimmten Zeitpunkt angibt.)
Ich habe keine vorgefertigten Skripte zum Reproduzieren von Spektrogrammen gefunden, obwohl Beispiele für die inverse Konvertierung - Ton in Spektrogramm -
leicht zu finden
sind , da die Funktionalität von
AnalyserNode.getByteFrequencyData() in die Web-Audio-API integriert ist. Um ein Frequenzarray für die Wiedergabe in ein
PCM- Array umzuwandeln, müssen Sie jedoch nicht auf die Implementierung einer inversen
Fourier-Transformation (DFT) in einem Skript verzichten.
* Im ersten Beispiel als Audioaufnahme für die Spektralanalyse ein Fragment der Spur " "von Aphex Twin: Als geheime Nachricht hat der Musiker ein Selfie in diese Spur eingebettet, das auf einem logarithmischen Spektrogramm erscheint. Leider wird in diesem Beispiel das Spektrogramm linear angezeigt, so dass das Gesicht oben gedehnt und unten komprimiert wird.
In Bezug auf die Implementierung von DFT ist sofort klar, dass ein solcher „Crasher“ in reinem JavaScript langsam und traurig funktioniert. Glücklicherweise entdeckte ich, dass der
vorgefertigte Port der FFTW-Bibliothek („Schnellste Fourier-Transformation im Westen“) auf asm.js eine Form der Darstellung von Code auf niedriger Ebene ist, der normalerweise in C geschrieben ist und von modernen Browsern mit einer Geschwindigkeit ausgeführt werden soll, die fast wie in Maschinencode kompiliert ist. Die Bindung für FFTW, die ein Schwarzweißbild in eine WAV-Datei verwandelt, habe ich von
ARSS übernommen und persönlich in JavaScript umgeschrieben. ARSS akzeptiert Bilder, die im Vergleich zu PhonoPaper invertiert sind, und ich habe sie nicht geändert.
Das Ergebnis können Sie unter
tyomitch.imtqy.com/#meklon.png bewundern
Unten sind sich wiederholende horizontale Streifen sichtbar -
Formanten , an deren Position Vokale erkannt werden. Oben - vertikale „Bursts“, die
lauten Konsonanten entsprechen : breiter - geschlitzt (frikativ), schmaler - vokal.
Bei den sonoren Konsonanten ([r] und [l]) entsprechen „Wolken“ in den mittleren Frequenzen.

Um mit dem Spektrogramm zu spielen, habe ich eine primitive Zeichnung angehängt, die fast vollständig aus dem
Tutorial für Leinwandzeichnungen kopiert wurde. Mit der Schaltfläche „Kopieren“ können Sie das Bild auf den roten Kanal übertragen (es wird vom Synthesizer ignoriert) und versuchen, die Töne zu „kreisen“.
Wikipedia schreibt:
"Es wird angenommen, dass die Zuordnung von vier Formanten ausreicht, um die Sprachlaute zu charakterisieren .
" Wir kreisen die Formanten F
2 -F
4 ein (aus irgendeinem Grund wird F
1 vom Synthesizer ignoriert) und stellen
sicher, dass die Vokale vollständig erkannt werden:

Dann umkreisen wir die lauten Konsonanten: Das
Affrikat [h] ist [t] und verwandelt sich sanft in [w]; und stimmhaft [d] von taub [t] wird durch das Vorhandensein von Mittelfrequenz-Formanten unterschieden. Jetzt können
Sie zwischen den Zahlen "sechs" und "de'it" unterscheiden:
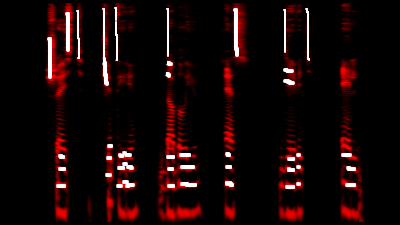
Wir fügen dunkelgraue sonore Konsonanten hinzu: Gleichzeitig stellen wir fest, dass [p] die Vokalformanten leicht „anhebt“ und [l] - im Gegenteil - sie weglässt.

Nur die labialen Konsonanten [b] und [c] blieben missverstanden, aber auch ohne sie ist das Passwort
mehr oder weniger klar .
Ist es möglich, Ton von Grund auf neu zu zeichnen, ohne das Spektrogramm der Audioaufnahme zu verfolgen? Ehrlich gesagt war ich nicht erfolgreich. Vielleicht möchten Sie es selbst versuchen?