Dieser Artikel ist mein Versuch, meine Meinung zu folgenden Aspekten zu äußern:
- Was ist ein Lerngeschwindigkeitsfaktor und welchen Wert hat er?
- Wie wählt man diesen Koeffizienten beim Training von Modellen?
- Warum ist es notwendig, den Koeffizienten der Lerngeschwindigkeit während des Trainings von Modellen zu ändern?
- Was tun mit einem Lerngeschwindigkeitsfaktor bei Verwendung eines vorab trainierten Modells?
Der größte Teil dieses Beitrags basiert auf Materialien, die von
fast.ai erstellt wurden: [1], [2], [5] und [3] - eine prägnante Version ihrer Arbeit, die zum schnellsten Verständnis des Wesens des Problems bestimmt ist. Um sich mit den Details vertraut zu machen, wird empfohlen, auf die unten angegebenen Links zu klicken.
Was ist ein Lerngeschwindigkeitsfaktor?
Der Lerngeschwindigkeitskoeffizient ist ein Hyperparameter, der die Reihenfolge bestimmt, in der wir unsere Skalen unter Berücksichtigung der Verlustfunktion beim Gradientenabstieg anpassen. Je niedriger der Wert, desto langsamer bewegen wir uns entlang der Neigung. Wenn wir einen niedrigen Lerngeschwindigkeitskoeffizienten verwenden, können wir zwar einen positiven Effekt erzielen, indem wir kein einziges lokales Minimum verpassen. Dies kann jedoch auch bedeuten, dass wir viel Zeit für die Konvergenz aufwenden müssen, insbesondere wenn wir uns in der Hochebene befinden.
Die Beziehung wird durch die folgende Formel veranschaulicht
 Gradientenabstieg mit kleinen (oben) und großen (unten) Lerngeschwindigkeitsfaktoren. Quelle: Andrew Ngs Kurs über maschinelles Lernen auf Coursera
Gradientenabstieg mit kleinen (oben) und großen (unten) Lerngeschwindigkeitsfaktoren. Quelle: Andrew Ngs Kurs über maschinelles Lernen auf Coursera
Meistens wird der Lerngeschwindigkeitsfaktor vom Benutzer willkürlich eingestellt. Im besten Fall kann er sich für ein intuitives Verständnis dessen, welcher Wert für die Bestimmung des Lerngeschwindigkeitskoeffizienten am besten geeignet ist, auf frühere Experimente (oder eine andere Art von Trainingsmaterial) verlassen.
Im Grunde ist es schwierig genug, den richtigen Wert zu wählen. Das folgende Diagramm zeigt verschiedene Szenarien, die auftreten können, wenn der Benutzer die Lerngeschwindigkeit unabhängig anpasst.
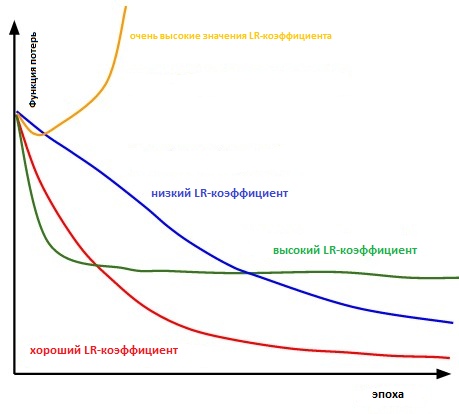 Der Einfluss verschiedener Lernratenfaktoren auf die Konvergenz. (Bildnachweis: cs231n)
Der Einfluss verschiedener Lernratenfaktoren auf die Konvergenz. (Bildnachweis: cs231n)
Darüber hinaus beeinflusst der Lerngeschwindigkeitsfaktor, wie schnell unser Modell ein lokales Minimum erreicht (auch bekannt als die beste Genauigkeit). Die richtige Wahl von Anfang an garantiert somit weniger Zeitverschwendung für das Training des Modells. Je weniger Schulungszeit, desto weniger Geld wird für die GPU-Rechenleistung in der Cloud ausgegeben.
Gibt es eine bequemere Möglichkeit, den Lernkoeffizienten zu bestimmen?
In Absatz 3.3. "
Zyklische Lernratenkoeffizienten für neuronale Netze " Leslie Smith verteidigte den folgenden Punkt: Die Effektivität der Lerngeschwindigkeit kann geschätzt werden, indem das Modell mit einer anfänglich festgelegten niedrigen Lerngeschwindigkeit trainiert wird, die dann in jeder Iteration (linear oder exponentiell) zunimmt.
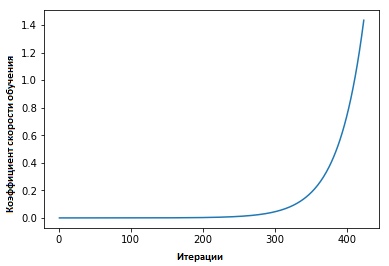 Der Lerngeschwindigkeitsfaktor erhöht sich nach jedem Minipaket.
Der Lerngeschwindigkeitsfaktor erhöht sich nach jedem Minipaket.
Wenn wir die Werte der Indikatoren bei jeder Iteration festlegen, werden wir sehen, dass mit zunehmender Lerngeschwindigkeit ein Punkt erreicht wird (an dem), an dem die Werte der Verlustfunktion nicht mehr abnehmen und zunehmen. In der Praxis sollte unsere Lerngeschwindigkeit idealerweise irgendwo links vom unteren Punkt des Diagramms liegen (wie im folgenden Diagramm gezeigt). In diesem Fall (der Wert wird sein) von 0,001 bis 0,01.
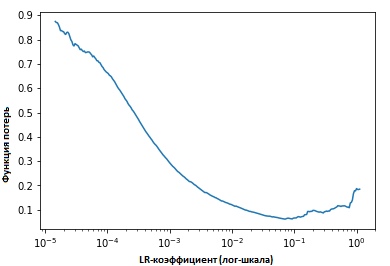
Das obige sieht nützlich aus. Wie fange ich an, es zu benutzen?
Momentan
enthält das von Jeremy Howard entwickelte
fast.ia- Paket eine vorgefertigte Funktion. Dies ist eine Art Abstraktion / Add-On über der Pytorch-Bibliothek (ähnlich wie bei Keras und Tensorflow).
Es ist nur erforderlich, den folgenden Befehl einzugeben, um mit der Suche nach dem optimalen Lerngeschwindigkeitskoeffizienten zu beginnen, bevor das neuronale Netzwerk (gestartet) wird.
learn.lr_find() learn.sched.plot_lr()
Das Modell verbessern
Wir haben also darüber gesprochen, wie hoch der Lerngeschwindigkeitskoeffizient ist, welchen Wert er hat und wie er seinen optimalen Wert erreicht, bevor er mit dem Training des Modells selbst beginnt.
Jetzt konzentrieren wir uns darauf, wie der Lerngeschwindigkeitsfaktor zum Optimieren von Modellen verwendet werden kann.
Konventionelle Weisheit
Wenn der Benutzer seinen Lerngeschwindigkeitskoeffizienten festlegt und mit dem Training des Modells beginnt, muss er normalerweise warten, bis der Lerngeschwindigkeitskoeffizient zu fallen beginnt und das Modell den optimalen Wert erreicht.
Ab dem Moment, in dem der Gradient ein Plateau erreicht, wird es jedoch schwieriger, die Werte der Verlustfunktion beim Training des Modells zu verbessern. In [3] weist Dauphin darauf hin, dass die Schwierigkeit bei der Minimierung der Verlustfunktion vom Sattelpunkt und nicht vom lokalen Minimum herrührt.
 Ein Sattelpunkt auf der Oberfläche von Fehlern. Ein Sattelpunkt ist ein Punkt aus dem Definitionsbereich einer Funktion, der für eine bestimmte Funktion stationär ist, aber nicht ihr lokales Extremum ist
Ein Sattelpunkt auf der Oberfläche von Fehlern. Ein Sattelpunkt ist ein Punkt aus dem Definitionsbereich einer Funktion, der für eine bestimmte Funktion stationär ist, aber nicht ihr lokales Extremum ist . (ImgCredit: safaribooksonline)
Wie kann dies vermieden werden?
Ich schlage vor, mehrere Optionen in Betracht zu ziehen. Einer von ihnen, allgemein, unter Verwendung des Zitats aus [1],
... anstatt einen festen Wert für den Lerngeschwindigkeitskoeffizienten zu verwenden und ihn im Laufe der Zeit zu verringern, werden wir den Lerngeschwindigkeitskoeffizienten in jeder Iteration gemäß einer zyklischen Funktion f ändern, wenn das Training unseren Verlust nicht mehr glättet. Jede Schleife hat - gemessen an der Anzahl der Iterationen - eine feste Länge. Diese Methode ermöglicht es, den Lerngeschwindigkeitskoeffizienten zwischen vernünftigen Grenzwerten zu variieren. Dies hilft wirklich, denn wenn wir in den Sattelpunkten stecken bleiben, erhalten wir durch Erhöhen des Lerngeschwindigkeitskoeffizienten einen schnelleren Schnittpunkt des Plateaus der Sattelpunkte
In [2] schlägt Leslie die „Dreiecksmethode“ vor, bei der der Lerngeschwindigkeitskoeffizient nach jeder von mehreren Iterationen überarbeitet wird.

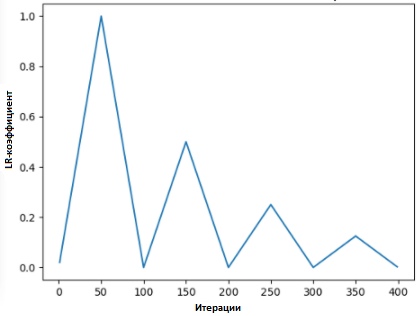 "Die Methode der Dreiecke" und "Die Methode der Dreiecke-2" sind Methoden zum zyklischen Testen von Lernratenkoeffizienten, die von Leslie N. Smith vorgeschlagen wurden. In der oberen Grafik werden das minimale und maximale Ir gleich gehalten.
"Die Methode der Dreiecke" und "Die Methode der Dreiecke-2" sind Methoden zum zyklischen Testen von Lernratenkoeffizienten, die von Leslie N. Smith vorgeschlagen wurden. In der oberen Grafik werden das minimale und maximale Ir gleich gehalten.Eine andere Methode, die nicht weniger beliebt ist und als „stochastischer Gradientenabstieg mit warmem Reset“ bezeichnet wird, wurde von Lonchilov & Hutter [6] vorgeschlagen. Diese Methode, die auf der Verwendung der Kosinusfunktion als zyklische Funktion basiert, startet den Koeffizienten der Lerngeschwindigkeit am Maximalpunkt in jedem Zyklus neu. Das Auftreten des "Hot" -Bits beruht auf der Tatsache, dass der Lernratenkoeffizient beim Neustart nicht von der Nullstufe ausgeht, sondern von den Parametern, zu denen das Modell den vorherigen Schritt erreicht hat.
Da diese Methode Variationen aufweist, zeigt die folgende Grafik eine der Methoden ihrer Anwendung, bei der jeder Zyklus an dasselbe Zeitintervall gebunden ist.
 SGDR - Grafik, Lernratenkoeffizient vs. Iterationen
SGDR - Grafik, Lernratenkoeffizient vs. Iterationen
Auf diese Weise können wir die Dauer des Trainings verkürzen, indem wir von Zeit zu Zeit einfach über die „Spitzen“ springen (wie unten gezeigt).
 Vergleich von festen und zyklischen Lernratenkoeffizienten
Vergleich von festen und zyklischen Lernratenkoeffizienten (img credit:
arxiv.org/abs/1704.00109Diese Methode spart nicht nur Zeit, sondern verbessert laut Studien auch die Klassifizierungsgenauigkeit ohne Optimierung und für weniger Iterationen.
Transfer-Lernverhältnis in Transfer-Lernen
Im Verlauf von
fast.ai liegt der Schwerpunkt auf der Verwaltung eines vorab trainierten Modells zur Lösung von Problemen der künstlichen Intelligenz. Bei der Lösung von Bildklassifizierungsproblemen werden die Schüler beispielsweise darin geschult, vorab trainierte Modelle wie VGG und Resnet50 zu verwenden und diese mit der Stichprobe der Bilddaten zu verknüpfen, die vorhergesagt werden müssen.
Um zusammenzufassen, wie das Modell im Programm
fast.ai erstellt wird (nicht zu verwechseln mit dem Paket
fast. Ai - das Paket aus dem Programm), werden im Folgenden die Schritte aufgeführt, die wir in einer normalen Situation ausführen werden:
- Datenerweiterung aktivieren und Vorberechnung = True
- Verwenden Sie Ir_find (), um den höchsten Lernratenkoeffizienten zu ermitteln, bei dem sich der Verlust noch deutlich verbessert.
- Trainiere die letzte Ebene vorberechneter Aktivierungen für die 1-2-Ära.
- Trainieren Sie die letzte Schicht mit Datenverstärkung (d. H. Berechnen = falsch) für 1-2 Epochen mit dem Zyklus _len 1.
- Alle Schichten auftauen.
- Platzieren Sie frühere Ebenen mit einem Lerngeschwindigkeitsfaktor, der 3x-10x unter der nächsthöheren Ebene liegt
- Ir_find () wiederverwenden
- Trainiere ein komplettes Netzwerk mit dem Zyklus _mult = 2 = 2, bis es mit der Umschulung beginnt.
Möglicherweise stellen Sie fest, dass die Schritte zwei, fünf und sieben (oben) mit der Lernrate zusammenhängen. In einem früheren Teil unseres Beitrags haben wir den Punkt der zweitgenannten Schritte hervorgehoben - wo wir angesprochen haben, wie Sie den besten Lerngeschwindigkeitskoeffizienten erhalten, bevor Sie mit dem Training des Modells beginnen.
Im nächsten Abschnitt haben wir darüber gesprochen, wie Sie die Trainingszeit mithilfe von SGDR verkürzen und den Lerngeschwindigkeitsfaktor regelmäßig neu starten können, um die Genauigkeit zu verbessern und Bereiche zu vermeiden, in denen der Gradient nahe Null liegt.
Im letzten Abschnitt werden wir das Konzept des differenzierten Lernens ansprechen und erklären, wie es verwendet wird, um den Lerngeschwindigkeitskoeffizienten zu bestimmen, wenn ein trainiertes Modell mit einem vorab trainierten ...
Was ist differenzielles Lernen?
Dies ist eine Methode, bei der während des Trainings verschiedene Trainingsgeschwindigkeitsfaktoren im Netzwerk eingestellt werden. Es bietet eine Alternative zu der Art und Weise, wie Benutzer normalerweise Lerngeschwindigkeitsfaktoren anpassen - nämlich die Verwendung des gleichen Lerngeschwindigkeitsfaktors über das Netzwerk während des Trainings.
 Der Grund, warum ich Twitter liebe, ist eine direkte Antwort von der Person selbst.
Der Grund, warum ich Twitter liebe, ist eine direkte Antwort von der Person selbst.
(Während er diesen Beitrag schrieb, veröffentlichte Jeremy einen Artikel mit Sebastian Ruder, der sich noch tiefer mit diesem Thema befasste. Ich glaube, der differenzielle Koeffizient der Lerngeschwindigkeit hat jetzt einen anderen Namen - diskriminierende exakte Abstimmung :)
Um das Konzept klarer zu demonstrieren, können wir uns auf das folgende Diagramm beziehen, in dem das zuvor trainierte Modell in drei Gruppen „aufgeteilt“ ist, wobei jede mit zunehmendem Wert des Lerngeschwindigkeitskoeffizienten angepasst wird.
 CNN-Beispiel mit differenziertem Lernratenkoeffizienten
CNN-Beispiel mit differenziertem Lernratenkoeffizienten . Bildnachweis von [3]
Diese Konfigurationsmethode basiert auf dem folgenden Verständnis: Die ersten Ebenen enthalten normalerweise sehr kleine Details der Daten, wie z. B. Linien und Winkel. Wir werden nicht versuchen, viel zu ändern und die darin enthaltenen Informationen zu speichern. Im Allgemeinen besteht keine ernsthafte Notwendigkeit, ihr Gewicht auf eine große Anzahl zu ändern.
Im Gegenteil, für nachfolgende Ebenen - wie die auf dem Bild grün gestrichenen, in denen wir detaillierte Anzeichen der Daten erhalten, wie z. B. Weiß der Augen, des Mundes oder der Nase - verschwindet die Notwendigkeit, sie zu speichern.
Wie ist dies im Vergleich zu anderen Feinabstimmungsmethoden?
In [9] wurde bewiesen, dass die Feinabstimmung des gesamten Modells zu kostspielig wäre, da Benutzer über 100 Schichten erhalten können. In den meisten Fällen wird das Modell schichtweise optimiert.
Dies ist jedoch der Grund für eine Reihe von Anforderungen, die sogenannten Beeinträchtigung der Parallelität und erfordert mehrere Eingaben über einen Datensatz, was zu einem Übertraining kleiner Sätze führt.
Wir haben auch gezeigt, dass die in [9] vorgestellten Methoden sowohl die Genauigkeit verbessern als auch die Anzahl der Fehler bei verschiedenen Aufgaben im Zusammenhang mit der NRL-Klassifizierung verringern können.
 Ergebnisse aus der Quelle [9]
Ergebnisse aus der Quelle [9]Referenzen:
[1] Verbesserung der Art und Weise, wie wir mit der Lernrate arbeiten.
[2] Die zyklische Lernratentechnik.
[3] Transferlernen mit unterschiedlichen Lernraten.
[4] Leslie N. Smith. Zyklische Lernraten für das Training neuronaler Netze.
[5] Schätzung einer optimalen Lernrate für ein tiefes neuronales Netzwerk
[6] Stochastischer Gradientenabstieg mit Warmstart
[7] Optimierung für Deep Learning-Highlights im Jahr 2017
[8] Lektion 1 Notizbuch, fast.ai Teil 1 V2
[9] Fein abgestimmte Sprachmodelle für die Textklassifizierung