Ich heiße Ivan Bondarenko. Ich arbeite seit ungefähr 2005 an Algorithmen für maschinelles Lernen für Textanalyse und gesprochene Sprache. Jetzt arbeite ich in Moskau PhysTech als führender wissenschaftlicher Entwickler des Labors für Geschäftslösungen, das auf dem NTI-Kompetenzzentrum für künstliche Intelligenz MIPT basiert, und in der Firma Data Monsters, die sich mit der praktischen Entwicklung interaktiver Systeme zur Lösung verschiedener Probleme in der Branche befasst. Ich unterrichte auch ein wenig an unserer Universität. Meine Geschichte widmet sich dem, was ein Chat-Bot ist, wie Algorithmen für maschinelles Lernen und andere Ansätze zur Automatisierung der Mensch-Computer-Kommunikation verwendet werden und wo sie implementiert werden können.
Die Vollversion meiner Rede bei der „Nacht der wissenschaftlichen Geschichten“ ist im
Video zu sehen, und ich werde im folgenden Text kurze Zusammenfassungen geben.

Algorithmusfunktionen
Zunächst werden menschliche Interaktionsalgorithmen in Call Centern erfolgreich eingesetzt. Die Arbeit eines Call-Center-Betreibers ist sehr schwierig und teuer. Darüber hinaus ist es in vielen Situationen fast unmöglich, das Problem der Mensch-Computer-Kommunikation vollständig zu lösen. Dies ist eine Sache, wenn wir mit einer Bank zusammenarbeiten, die normalerweise mehrere tausend Kunden hat. Sie können die Mitarbeiter des Callcenters einstellen, die diese Kunden bedienen und mit ihnen sprechen. Wenn wir jedoch ehrgeizigere Aufgaben lösen (z. B. Smartphones oder andere Unterhaltungselektronikprodukte), sind unsere Kunden nicht mehrere Tausend, sondern mehrere zehn Millionen auf der ganzen Welt. Und wir wollen verstehen, welche Probleme Menschen mit unseren Produkten haben. Benutzer teilen in der Regel Informationen in den Foren miteinander oder schreiben an den Support-Service des Herstellers von Smartphones. Live-Betreiber werden nicht in der Lage sein, die Arbeit auf einem riesigen Kundenstamm zu bewältigen, und hier helfen Algorithmen, die im Mehrkanalmodus arbeiten können und eine große Anzahl von Menschen bedienen.
Um solche Probleme zu lösen, Algorithmen für Dialogsysteme zu entwickeln, die mit einer Person interagieren und wichtige Informationen aus beliebigen Nachrichten extrahieren können, gibt es auf dem Gebiet der Computerlinguistik einen ganzen Bereich - die Analyse von Texten in natürlicher Sprache. Ein Roboter muss lesen, verstehen, zuhören, sprechen und so weiter können. Dieser Bereich - Natural Language Processing - gliedert sich in mehrere Teile.
Den Text verstehen (Natural Language Understanding, NLU).
Wenn ein Bot mit einer Person kommuniziert und eine Person etwas an den Bot schreibt, müssen Sie verstehen, was geschrieben steht, was der Benutzer wollte, was er in seiner Rede erwähnt hat. Die Absichten des Benutzers verstehen, die sogenannte Absicht - was eine Person will: eine Bankkarte erneut ausstellen oder Pizza bestellen. Und die Zuweisung benannter Entitäten, dh Dinge, über die der Benutzer speziell spricht: Wenn es sich um Pizza handelt, dann um „Margarita“ oder „Hawaiianer“, wenn die Karte, dann um welches System - MasterCard, World und so weiter.

Und schließlich ein Verständnis der Tonalität der Botschaft - in welchem emotionalen Zustand sich eine Person befindet. Der Algorithmus muss erkennen können, in welchen Schlüssel die Nachricht geschrieben ist. Dies ist entweder ein Nachrichtentext oder diese Nachricht stammt von einer Person, die mit unserem Bot kommuniziert, um angemessen auf den Schlüssel zu reagieren.
 Generierung des Textes (Natural Language Generation)
Generierung des Textes (Natural Language Generation) - eine angemessene Antwort auf eine menschliche Anfrage in derselben menschlichen Sprache (natürlich) und keine komplexe Platte und keine formalen Phrasen.
Spracherkennung und Sprachsynthese (Speech-to-Text und Text-to-Speech). Wenn der Chatbot nicht nur mit der Person korrespondiert, sondern spricht und zuhört, müssen Sie sie lehren, die gesprochene Sprache zu verstehen, Schallschwingungen in Text umzuwandeln, diesen Text dann mit einem Textverständnismodul zu analysieren und wiederum Schallschwingungen aus dem Antworttext zu generieren was dann die Person, die der Teilnehmer hört.
Arten von Chat-Bots
Chatbots enthalten mehrere Schlüsselarchitekturen.
Der Chatbot, der die am häufigsten gestellten Fragen beantwortet (FAQ-Chatbot), ist die einfachste Option. Wir können immer eine Reihe von Modellfragen formulieren, die die Leute stellen. Bei einem Standort für die Lieferung von Fertiggerichten handelt es sich in der Regel um folgende Fragen: „Wie viel kostet die Lieferung?“, „Liefern Sie in den Distrikt Pervomaisky?“ Usw. Sie können sie nach verschiedenen Klassen, Absichten und Benutzerabsichten gruppieren. Wählen Sie für jede Absicht typische Antworten aus.
Gezielter Chat-Bot (zielorientierter Bot). Hier habe ich versucht, die Architektur eines solchen Chatbots zu zeigen, der im iPavlov-Projekt implementiert ist. iPavlov ist ein Projekt zur Schaffung künstlicher Konversationsintelligenz. Insbesondere hilft ein fokussierter Chatbot dem Benutzer, ein Ziel zu erreichen (z. B. einen Tisch in einem Restaurant reservieren oder Pizza bestellen oder etwas über Probleme bei der Bank erfahren). Es geht nicht nur um die Antwort auf die Frage (Frage-Antwort - ohne Kontext). Der gezielte Chatbot verfügt über ein Modul zum Verstehen von Text, zur Dialogverwaltung und ein Modul zum Generieren von Antworten.
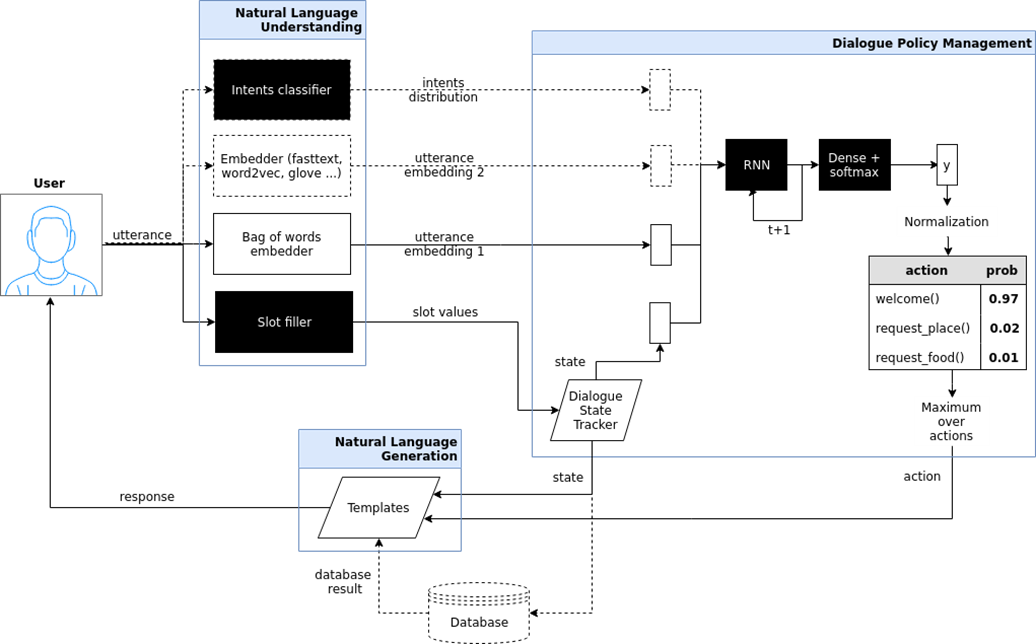 Chat-Bots des Frage-Antwort-Systems Frage-Antwort-System und nur "Sprecher" (Chit-Chat-Bot).
Chat-Bots des Frage-Antwort-Systems Frage-Antwort-System und nur "Sprecher" (Chit-Chat-Bot). Wenn die beiden vorherigen Arten von Chat-Bots entweder die am häufigsten gestellten Fragen beantworten oder den Benutzer durch das Dialogfeld führen, um am Ende ein Restaurant zu buchen, herauszufinden, was der Benutzer möchte, chinesische oder italienische Küche usw., dann die Frage-Antwort Ein System ist eine andere Art von Chat-Bot. Das Ziel eines solchen Chat-Bots besteht nicht darin, sich entlang der Spalte des Dialogs zu bewegen und nicht nur die Absichten des Benutzers zu klassifizieren, sondern eine Informationssuche durchzuführen, um das relevanteste Dokument zu finden, das der Frage der Person und der Stelle im Dokument entspricht, an der die Antwort enthalten ist. Beispielsweise stellen Mitarbeiter eines großen Einzelhändlers, anstatt sich Arbeitsanweisungen zu merken oder nach einer Antwort zu suchen, wo Buchweizen abgelegt werden soll, einem solchen Chatbot eine Frage, die auf einem Frage-Antwort-System basiert.
Arten des maschinellen Lernens
Das Erkennen von Absichten, die Zuweisung benannter Entitäten, die Suche in Dokumenten und die Suche nach Stellen in einem Dokument, die der Semantik einer Frage entsprechen - all dies ist ohne maschinelles Lernen und ohne statistische Analyse nicht möglich. Daher ist die Grundlage moderner Chat-Bots maschinelles Lernen - Aufgabenmethoden, Annäherungen an einige versteckte Muster, die in großen Datenmengen vorhanden sind, und die Identifizierung dieser Muster. Es ist sinnvoll, diesen Ansatz anzuwenden, wenn es Muster und Aufgaben gibt, aber es ist unmöglich, eine einfache Formel zu finden, den Formalismus, um dieses Muster zu beschreiben.
Es gibt verschiedene Arten des maschinellen Lernens: mit einem Lehrer (überwachtes Lernen), ohne Lehrer (unbeaufsichtigtes Lernen), mit Verstärkung (verstärkendes Lernen). Wir sind in erster Linie an der Aufgabe interessiert, mit einem Lehrer zu unterrichten - wenn Eingabebilder und Anweisungen (Etiketten) des Lehrers vorhanden sind und diese Bilder klassifiziert werden. Oder geben Sie Sprachsignale und deren Klassifizierung ein. Und wir bringen unserem Bot bei, unserem Algorithmus, um die Arbeit eines Lehrers zu reproduzieren.
Okay, alles scheint cool zu sein. Und wie bringt man einem Computer bei, Texte zu verstehen? Text ist ein komplexes Objekt, und wie werden Buchstaben zu Zahlen und erhalten eine Vektorbeschreibung des Textes? Es gibt die einfachste Option - eine "Tasche voller Wörter". Wir fragen das Wörterbuch des gesamten Systems, zum Beispiel alle Wörter, die in der russischen Sprache sind, und formulieren solche sehr spärlichen Vektoren mit Worthäufigkeiten. Diese Option eignet sich für einfache Fragen, ist jedoch für komplexere Aufgaben nicht geeignet.
2013 fand eine Art Revolution in der Modellierung von Wörtern und Texten statt. Thomas Mikolov schlug einen speziellen Ansatz zur effektiven Vektordarstellung von Wörtern vor, der auf der Verteilungshypothese basiert. Wenn verschiedene Wörter im selben Kontext gefunden werden, haben sie etwas gemeinsam. Zum Beispiel: "Wissenschaftler haben eine Analyse der Algorithmen durchgeführt" und "Wissenschaftler haben eine Studie der Algorithmen durchgeführt". "Analyse" und "Forschung" sind also Synonyme und bedeuten ungefähr dasselbe. Daher können Sie einem speziellen neuronalen Netzwerk beibringen, ein Wort nach Kontext oder Kontext nach Wort vorherzusagen.
Wie trainieren wir schließlich? Um den Bot zu trainieren, Absichten und wahre Absichten zu verstehen, müssen Sie eine Reihe von Texten mit speziellen Programmen manuell markieren. Um dem Bot beizubringen, benannte Entitäten zu verstehen - den Namen der Person, den Namen des Unternehmens, den Standort - müssen Sie auch Texte platzieren. Dementsprechend ist einerseits der Lernalgorithmus mit dem Lehrer am effektivsten, es ermöglicht Ihnen, ein effektives Erkennungssystem zu erstellen, andererseits tritt ein Problem auf: Sie benötigen große, beschriftete Datensätze, und dies ist teuer und zeitaufwändig. Beim Markieren von Datensätzen können Fehler auftreten, die durch den menschlichen Faktor verursacht werden.
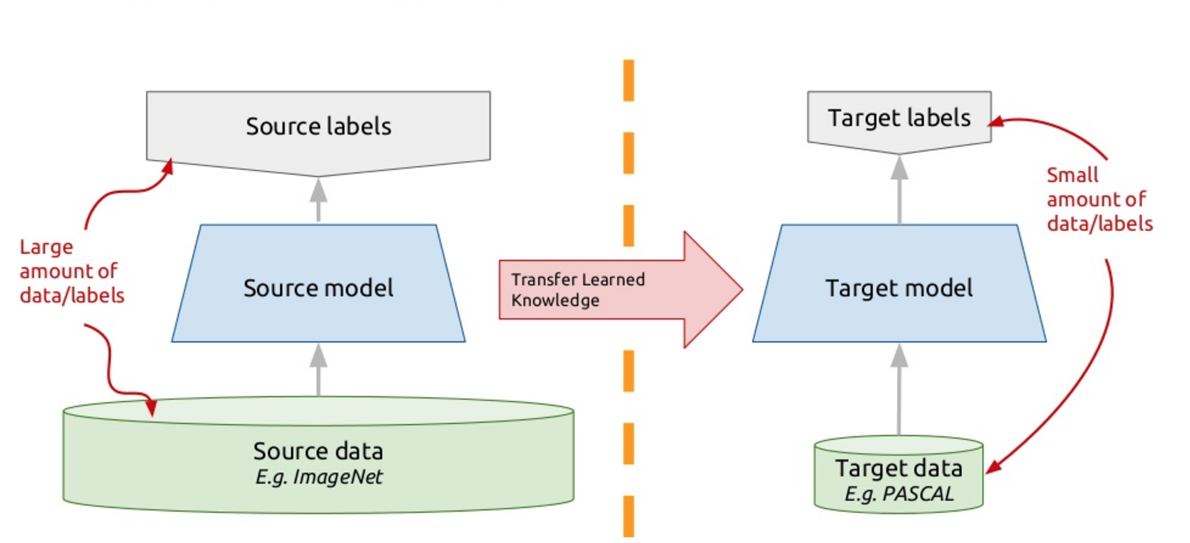
Um dieses Problem zu lösen, verwenden moderne Chatbots das sogenannte Transferlernen - Transferlernen. Diejenigen, die viele Fremdsprachen beherrschen, haben wahrscheinlich eine solche Nuance bemerkt, dass es einfacher ist, eine andere Fremdsprache als die erste zu lernen. Wenn Sie eine neue Aufgabe studieren, versuchen Sie tatsächlich, Ihre bisherigen Erfahrungen dafür zu nutzen. Das Transferlernen basiert also auf diesem Prinzip: Wir bringen dem Algorithmus bei, ein Problem zu lösen, für das wir einen großen Datensatz haben. Und dann trainieren wir diesen trainierten Algorithmus (das heißt, wir nehmen den Algorithmus nicht von Grund auf neu, sondern trainiert, um ein anderes Problem zu lösen), um unser Problem zu lösen. So erhalten wir eine effektive Lösung mit einer kleinen Datenvielfalt.
Ein solches Modell ist ELMo (Embeddings from Language Models), wie ELMo aus der Sesamstraße. Wir verwenden wiederkehrende neuronale Netze, sie haben Speicher und können Sequenzen verarbeiten. Zum Beispiel: „Der Programmierer Vasya liebt Bier. Jeden Abend nach der Arbeit geht er zum Jonathan und vermisst ein oder zwei Gläser. " Also, wer ist er? Ist er heute Abend, ist er ein Bier oder ist er ein Programmierer Vasya? Ein neuronales Netzwerk, das Wörter als Elemente einer Sequenz verarbeitet, kann angesichts des Kontexts, eines wiederkehrenden neuronalen Netzwerks, die Beziehungen verstehen, dieses Problem lösen und eine Art Semantik hervorheben.
Wir trainieren ein so tiefes neuronales Netzwerk, um Texte zu modellieren. Formal ist dies die Aufgabe, mit einem Lehrer zu lernen, aber der Lehrer ist der nicht platzierte Text selbst. Das nächste Wort im Text ist ein Lehrer in Bezug auf alle vorherigen. So können wir Gigabyte, Dutzende von Gigabyte an Texten verwenden und effektive Modelle trainieren, die die Semantik in diesen Texten hervorhebt. Wenn wir dann die Einbettungen aus Sprachmodellen (ELMo) im Ausgabemodus verwenden, geben wir das Wort basierend auf dem Kontext an. Nicht nur ein Stock, sondern lass uns bleiben. Wir schauen uns an, was das neuronale Netzwerk zu diesem Zeitpunkt erzeugt, was signalisiert. Wir katanieren diese Signale und erhalten eine Vektordarstellung des Wortes in einem bestimmten Text unter Berücksichtigung seiner spezifischen sematischen Bedeutung.
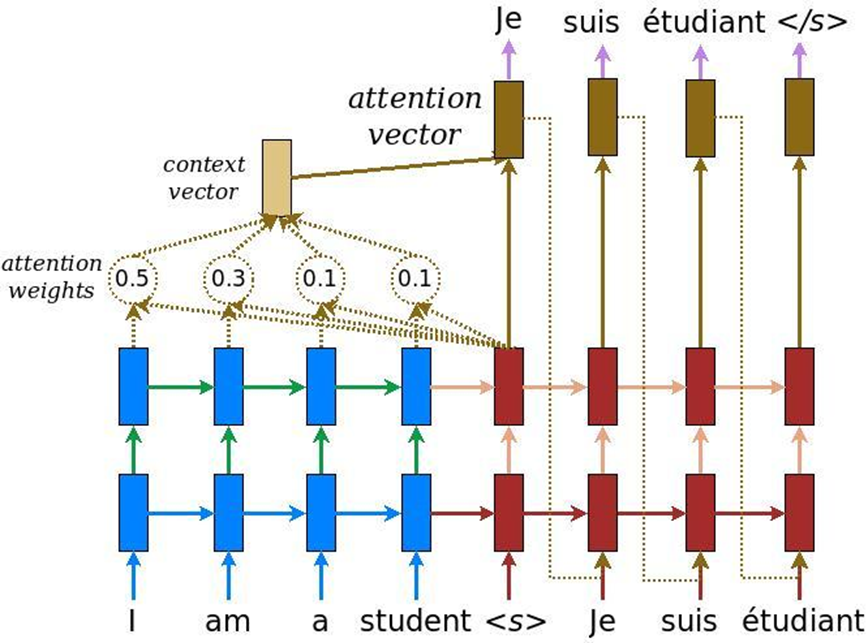
Bei der Analyse von Texten gibt es noch ein weiteres Merkmal: Wenn die Aufgabe der maschinellen Übersetzung gelöst ist, kann dieselbe Bedeutung durch eine Anzahl von Wörtern auf Englisch und eine andere Anzahl von Wörtern auf Russisch vermittelt werden. Dementsprechend gibt es keinen linearen Vergleich, und wir brauchen einen Mechanismus, der sich auf bestimmte Textteile konzentriert, um sie angemessen in eine andere Sprache zu übersetzen. Ursprünglich wurde die Aufmerksamkeit für die maschinelle Übersetzung erfunden - die Aufgabe, einen Text mit herkömmlichen wiederkehrenden neuronalen Systemen in einen anderen umzuwandeln. Dazu fügen wir eine besondere Aufmerksamkeitsebene hinzu, die zu jedem Zeitpunkt bewertet, welches Wort für uns jetzt wichtig ist.
Aber dann dachten die Leute von Google, warum nicht den Aufmerksamkeitsmechanismus überhaupt ohne wiederkehrende neuronale Netze nutzen - nur Aufmerksamkeit. Und sie entwickelten eine Architektur namens Transformator (BERT (Bidirectional Encoder Representations from Transformers)).
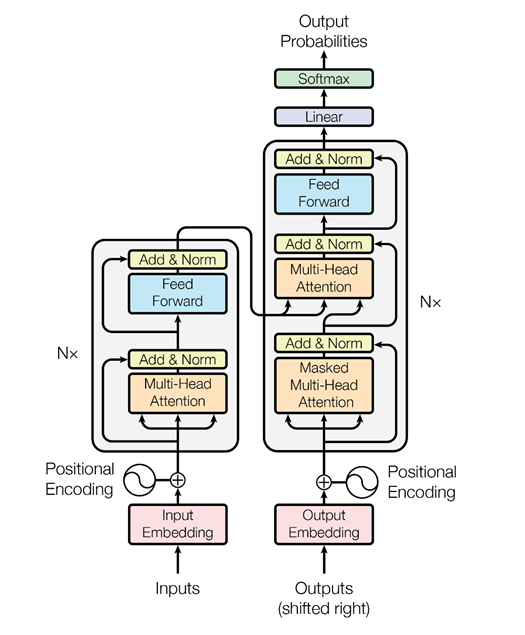
Basierend auf einer solchen Architektur wurden spezielle Algorithmen erfunden, die auch die Beziehung von Wörtern in Texten und die Beziehung von Texten untereinander analysieren können - wie ELMo es nur schlauer macht. Erstens ist es ein cooleres und komplexeres Netzwerk. Zweitens lösen wir zwei Probleme gleichzeitig und nicht eines, wie im Fall der ELMo - Sprachmodellierung, Prognose. Wir versuchen, versteckte Wörter im Text wiederherzustellen und Verknüpfungen zwischen Texten wiederherzustellen. Das heißt, sagen wir: „Der Programmierer Vasya liebt Bier. Jeden Abend geht er zur Bar. “ Zwei Texte sind miteinander verbunden. „Programmierer Vasya liebt Bier. Kraniche fliegen im Herbst nach Süden “- das sind zwei nicht verwandte Texte. Auch diese Informationen können aus nicht zugewiesenen Texten extrahiert, BERT geschult und sehr coole Ergebnisse erzielt werden.
Dies wurde im letzten November in dem Artikel „Aufmerksamkeit ist alles, was Sie brauchen“ veröffentlicht, den ich sehr empfehlen kann. Im Moment ist dies das coolste Ergebnis auf dem Gebiet der Textanalyse zur Lösung verschiedener Probleme: zur Textklassifizierung (Erkennung der Tonalität, Absichten des Benutzers); für Frage- und Antwortsysteme; zum Erkennen benannter Entitäten und so weiter. Moderne Dialogsysteme verwenden vorab trainierte kontextbezogene BERT-Einbettungen (ELMo oder BERT), um zu verstehen, was der Benutzer möchte. Das Dialogverwaltungsmodul basiert jedoch häufig auf Regeln, da ein bestimmter Dialog sehr stark vom Thema oder sogar von der Aufgabe abhängen kann.