Wenn Cluster Hunderte und manchmal Tausende von Maschinen erreichen, stellt sich die Frage nach der Konsistenz der Serverzustände relativ zueinander. Der Raft Distributed Consensus-Algorithmus bietet die strengste Konsistenzgarantie. In diesem Artikel werden wir Raft aus der Sicht eines Ingenieurs betrachten und versuchen, die Fragen „Wie?“ Zu beantworten. und "warum?" es funktioniert.

Artikelautor : Dmitry Pavlushin (Entwickler Dodo Pizza Engineering).
Raft ist
ein verteilter Konsensalgorithmus , der benötigt wird, damit mehrere Teilnehmer gemeinsam entscheiden können, ob und was passiert ist oder nicht.
Die vom Raft-Cluster bereitgestellten Daten sind ein Protokoll, das aus Datensätzen besteht. Wenn ein Benutzer die in einem Cluster gespeicherten Daten ändern möchte, versucht er, dem Protokoll mit dem folgenden Befehl einen neuen Datensatz hinzuzufügen:
Diese Befehle werden von verteilten Zustandsautomaten ausgeführt. Der Einfachheit und Klarheit halber gehen wir im Rahmen dieses Artikels davon aus, dass diese Datensätze einfach an einen Kunden weitergegeben werden, der basierend auf den aufgetretenen Ereignissen den aktuellen Status des Systems wiederherstellt
(siehe Ereignisbeschaffung) .
Um einen Konsens in Raft zu gewährleisten, wird zunächst ein Leiter ausgewählt, der für die Verwaltung des verteilten Protokolls verantwortlich ist. Der Leiter akzeptiert Anforderungen von Clients und repliziert sie auf andere Server im Cluster. Wenn der Anführer ausfällt, wird ein neuer Anführer im Cluster ausgewählt. Dies ist, wenn für eine Weile in drei Sätzen. Details folgen.
Grundbegriffe
- Serverstatus Im Raft-Cluster befindet sich jeder Server zu einem bestimmten Zeitpunkt in einem von drei Zuständen:
- Leader (Leader) - verarbeitet alle Client-Anfragen, ist die Quelle der Wahrheit aller Daten im Protokoll und unterstützt das Follower-Protokoll.
- Follower (Follower) ist ein passiver Server, der nur neue Protokolleinträge des Leiters „abhört“ und alle eingehenden Anforderungen von Clients an den Leiter umleitet. Tatsächlich handelt es sich um eine Hot-Standby-Nachbildung des Anführers.
- Kandidat (Kandidat) ist ein spezieller Status des Servers, der nur während der Auswahl eines neuen Leiters möglich ist.
Während des normalen Betriebs in einem Cluster ist nur ein Server der Anführer, der Rest sind seine Anhänger.
Über AsynchronismusEs ist erwähnenswert, dass die Bedingung ein relatives Konzept ist. Aufgrund der Tatsache, dass die Server asynchron kommunizieren, können verschiedene Server die Übergänge anderer Server zu unterschiedlichen Zeiten von einem Status in einen anderen beobachten.
- Das Floß unterteilt die Zeit in Segmente beliebiger Länge, die als Fristen bezeichnet werden . Jeder Begriff hat eine monoton ansteigende Anzahl. Die Amtszeit beginnt mit der Wahl eines Leiters, wenn ein oder mehrere Server Kandidaten werden. Wenn der Kandidat die Mehrheit der Stimmen erhält, wird er bis zum Ende dieses Zeitraums führend. Wenn die Stimmen geteilt sind und keiner der Kandidaten die Mehrheit der Stimmen erhalten kann, wird eine Zeitüberschreitung ausgelöst und dieser Zeitraum endet. Danach beginnt eine neue Amtszeit mit neuen Kandidaten und Wahlen. Diese Situation wird als getrennte Abstimmung bezeichnet. Ein Beispiel wird durch den dritten Begriff in der folgenden Abbildung veranschaulicht:

Die Termnummer dient als logischer Zeitstempel im Raft-Cluster. Es hilft Servern zu bestimmen, welche Informationen momentan relevanter sind.
Regeln und Bedingungen für die Serverinteraktion- Jeder Server verfolgt die Nummer seiner aktuellen Laufzeit.
- Der Server enthält seine Ablaufnummer in jeder gesendeten Nachricht.
- Wenn der Server eine Nachricht mit einer geringeren Laufzeitnummer als seiner eigenen empfängt, ignoriert er diese Nachricht.
- Wenn der Server eine Nachricht mit einer längeren Frist als seiner eigenen empfängt, aktualisiert er seine Frist so, dass sie mit der empfangenen übereinstimmt.
- Wenn ein Kandidat oder Leiter eine Nachricht mit einer längeren Frist als seiner eigenen erhält, versteht er, dass andere Server bereits eine neue Frist eingeleitet haben und seine Frist nicht mehr relevant ist. Daher wechselt es zusätzlich zur Aktualisierung seiner Nummer vom aktuellen Status in den Status "Follower".
- Serverkommunikation. Die Server in Raft interagieren, indem sie Anforderungen und Antworten austauschen. Der grundlegende Algorithmus verwendet nur zwei Arten von Aufrufen:
- RequestVote wird von Kandidaten während der Wahlen verwendet. Die Anfrage enthält die Termnummer des Kandidaten und Metadaten zum Protokoll des Kandidaten, die nachstehend ausführlicher erläutert werden. Die Antwort enthält die Deadline-Nummer des antwortenden Servers und den Wert "true", wenn der Server für den Kandidaten stimmt. False, wenn der Server gegen den Kandidaten stimmt.
- AppendEntries wird vom Leader für die Protokollreplikation sowie für den Heartbeat-Mechanismus verwendet. Die Anforderung enthält die Termnummer des Leiters, eine Sammlung von Einträgen, die dem Protokoll hinzugefügt werden müssen (oder eine leere Sammlung im Falle eines Herzschlags), einige Metadaten zum Protokoll des Leiters, die im Folgenden ebenfalls ausführlicher erläutert werden. Die Antwort enthält die Nummer des Follower-Terms und den Wert "true", wenn der Follower erfolgreich Einträge zu seinem Protokoll hinzugefügt hat. "False", wenn das Hinzufügen von Protokolleinträgen fehlgeschlagen ist.
Arbeitsalgorithmus
1. Wählen Sie einen Führer
Um festzustellen, wann es Zeit ist, eine Neuwahl zu beginnen, setzt Raft auf Herzschlag. Der Follower bleibt der Follower, bis er Nachrichten vom aktuellen Anführer oder Kandidaten erhält. Der Leader sendet regelmäßig Heartbeat an alle anderen Server.
Wenn der Follower einige Zeit keine Nachrichten erhält, geht er ganz natürlich davon aus, dass der Anführer tot ist, was bedeutet, dass es Zeit ist, die Initiative in seine Hände zu nehmen. Zu diesem Zeitpunkt leitet der frühere Anhänger die Wahl ein.
Um die Wahl einzuleiten, erhöht der Follower seine Laufzeitnummer, wechselt in den Status "Kandidat", stimmt für sich selbst und sendet dann die Anforderung "RequestVote" an alle anderen Server. Danach wartet der Kandidat auf eines von drei Ereignissen:
- Der Kandidat erhält die Mehrheit der Stimmen (einschließlich seiner eigenen) und gewinnt die Wahl. Jeder Server stimmt nur einmal in jeder Amtszeit ab, damit der erste Kandidat erreicht wird (mit einigen Ausnahmen, die unten erläutert werden). Daher kann nur ein Kandidat die Mehrheit der Stimmen in einer bestimmten Amtszeit erhalten. Der Gewinner-Server wird zum Leader, sendet Heartbeat und bedient Client-Anforderungen an den Cluster.
- Der Kandidat erhält eine Nachricht vom aktuellen Leiter der aktuellen Amtszeit oder von einem Server mit einer älteren Amtszeit . In diesem Fall versteht der Kandidat, dass die Wahlen, an denen er teilnimmt, nicht mehr relevant sind. Er hat keine andere Wahl, als einen neuen Führer / eine neue Amtszeit zu erkennen und in einen Zustand des Nachfolgers zu gelangen.
- Ein Kandidat erhält für eine bestimmte Zeit keine Mehrheit der Stimmen. Dies kann passieren, wenn mehrere Anhänger Kandidaten werden und die Stimmen unter ihnen aufgeteilt werden, so dass nicht einer die Mehrheit erhält. In diesem Fall endet die Amtszeit ohne Führer, und der Kandidat beginnt sofort mit Neuwahlen für die nächste Amtszeit.
2. Wir replizieren Protokolle
Wenn ein Leiter ausgewählt wird, ist er für die Verwaltung des verteilten Protokolls verantwortlich. Der Leiter akzeptiert Anfragen von Kunden, die einige Teams enthalten. Der Anführer fügt in sein Protokoll einen neuen Datensatz ein, der den Befehl enthält, und sendet dann "AppendEntries" an alle Follower, um den Datensatz mit dem neuen Datensatz zu replizieren.
Wenn der Datensatz auf den meisten Servern erfolgreich repliziert wurde, betrachtet der Leiter den Datensatz als geschlossen und antwortet dem Client. Der Anführer verfolgt, welcher Datensatz der letzte ist. Es sendet die Nummer dieses Datensatzes an AppendEntries (einschließlich Heartbeat), damit Follower den Datensatz für sich selbst festschreiben können.
Falls der Anführer einige Follower nicht erreichen kann, wird er die AppendEntries bis ins Unendliche zurückverfolgen. Das folgende Bild zeigt, wie die Protokolle im Raft-Cluster organisiert sind:

Jedes Feld ist ein Eintrag im Protokoll. Jeder Datensatz speichert einen Befehl, z. B. x ← 3 weist der Taste x den Wert 3 zu. Der Datensatz speichert auch die Nummer des Begriffs, in dem er generiert wurde. Auf dem Bild wird dies durch eine Zahl am oberen Rand des Quadrats angezeigt. Die Farbanzeige der Quadrate bedeutet auch die Termnummer. Jeder Datensatz hat eine Seriennummer (Protokollindex).
3. Wir garantieren die Zuverlässigkeit des Algorithmus
Bisher ist nach unseren Untersuchungen nicht klar, wie Raft zumindest einige Garantien geben kann. Der Algorithmus bietet jedoch eine Reihe von Eigenschaften, die zusammen die Zuverlässigkeit seiner Ausführung gewährleisten:
- Wahlsicherheit : Innerhalb einer Amtszeit kann nicht mehr als ein Führer ausgewählt werden. Diese Eigenschaft ergibt sich aus der Tatsache, dass jeder Server innerhalb jeder Amtszeit nur einmal abstimmt und für die Bildung eines Leiters eine Mehrheit der Stimmen erforderlich ist
- Nur Anführer anhängen : Der Anführer überschreibt oder löscht niemals, verschiebt keine Einträge in seinem Protokoll, fügt nur neue Einträge hinzu. Diese Eigenschaft folgt direkt aus der Beschreibung des Algorithmus. Die einzige Operation, die ein Leiter mit seinem Protokoll ausführen kann, besteht darin, am Ende Einträge hinzuzufügen. Und alle.
- Protokollabgleich: Wenn die Protokolle von zwei Servern einen Eintrag mit demselben Index und derselben Ablaufnummer enthalten, sind beide Protokolle bis einschließlich dieses Datensatzes identisch.
Beweis mit mathematischer Induktion und BildernDie mathematische Induktion ist ein Beweis dafür, wann der erste Schritt darin besteht, eine Aussage für einen einfachen Fall zu beweisen. Im zweiten Schritt akzeptieren wir die Aussage wahr für einen Fall X. Auf dieser Grundlage versuchen wir, die Aussage für einen benachbarten Fall X + 1 zu beweisen. Zusammen helfen diese beiden Schritte, die Aussage für alle Fälle zu beweisen.
In unserer Situation sind leere Protokolle ein einfacher Fall. Es gibt keine Aufzeichnungen, daher gibt es nichts, was die Eigenschaft verletzen könnte.
Nehmen wir nun an, dass die Protokolle einige Einträge enthalten, die unserer Eigenschaft entsprechen. Raft verfügt über einen Mechanismus, der verhindert, dass die Eigenschaft beschädigt wird, wenn sich ein Protokoll ändert. Dieser Mechanismus wird als
Konsistenzprüfung bezeichnet . Schauen wir uns die Beispiele sofort an.
Gutes Beispiel . Es gibt zum Beispiel einen Führer der 4. Amtszeit, es gibt einen Anhänger. Beide haben übereinstimmende Protokolle aus drei Einträgen.
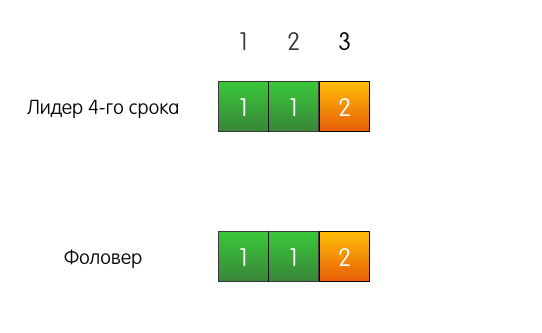
Eine Anfrage des Kunden kommt an den Leiter, er fügt seinem Protokoll einen Eintrag hinzu.

Der Anführer sendet AppendEntries an den Follower. Zusätzlich zu dem am häufigsten hinzugefügten Datensatz gibt der Leiter in der Anforderung an, dass der Datensatz bei Index 4 hinzugefügt werden muss, und bei Index 3 davor muss ein Datensatz aus Term 2 vorhanden sein.
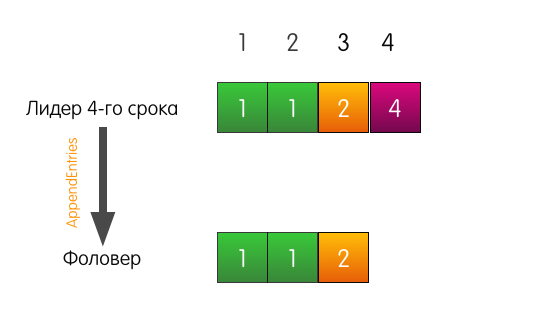
Der Protokolleintrag bei Index 3 im Follower-Protokoll stimmt mit dem in der Anforderung angegebenen überein, sodass der Follower den Eintrag zu seinem Protokoll hinzufügt und dem Leiter mit Erfolg antwortet. Das Ende.
 Auch ein gutes Beispiel, aber mit einem tragischen Anfang.
Auch ein gutes Beispiel, aber mit einem tragischen Anfang. Jetzt unterscheidet sich das Protokoll des Followers vom Protokoll des aktuellen Anführers.

Wenn der Leiter eine Anforderung zum Hinzufügen eines Eintrags zum Protokoll erhält, sendet er dieselben AppendEntries wie im vorherigen Beispiel.

Diesmal schlägt der Follower jedoch fehl, da der Follower nicht mit dem vorherigen Datensatz übereinstimmt.
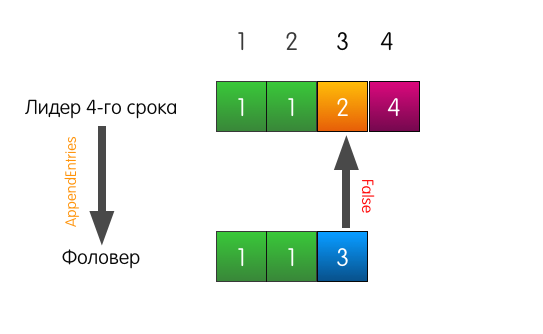
Was macht der Anführer in diesem Fall? Der Anführer rollt einfach ein wenig zurück und versucht, dem Follower den Datensatz zuzuführen, den er selbst für Index 3 hält. Er nimmt auch den vorherigen Datensatz in die Anfrage auf.
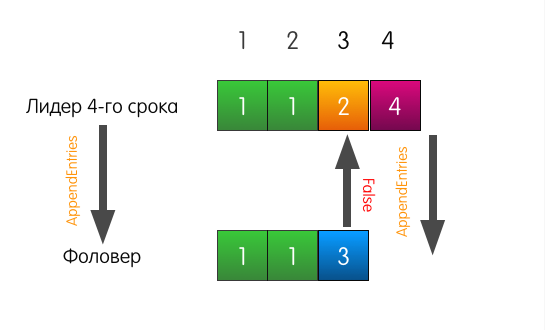
Jetzt antwortet der Follower mit Erfolg und überschreibt die Einträge in seinem Protokoll ab Index 3.
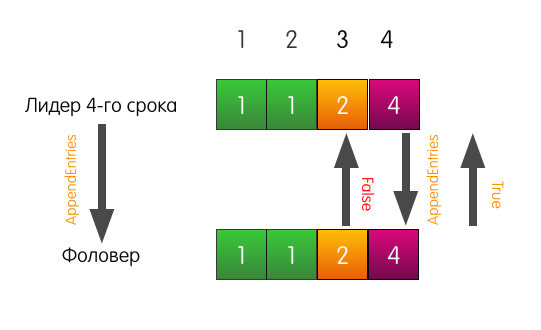
Das Protokoll des Followers kann nach Belieben vom Protokoll des Anführers abweichen. Es sind möglicherweise nicht genügend Einträge enthalten, möglicherweise sind zusätzliche Einträge enthalten. In jedem Fall stellt die Konsistenzprüfung sicher, dass die Protokolle der Follower früher oder später mit dem Protokoll des Anführers übereinstimmen.
- Vollständigkeit des Leiters : Wenn der Protokolleintrag zu einem bestimmten Zeitpunkt festgeschrieben wird, enthalten die Protokolle der Leiter aller nachfolgenden Perioden diesen Datensatz. Diese Eigenschaft bietet uns Haltbarkeitsgarantien.
Beweis und BilderStellen Sie sich folgende Situation vor: Drei Server in einem Cluster. Server S1 ist der Anführer der aktuellen ersten Amtszeit. Alle Server haben drei Protokolleinträge.

Leader S1 empfängt eine Anfrage vom Client, fügt seinem Protokoll einen neuen Datensatz hinzu und sendet AppendEntries an andere S2- und S3-Server.
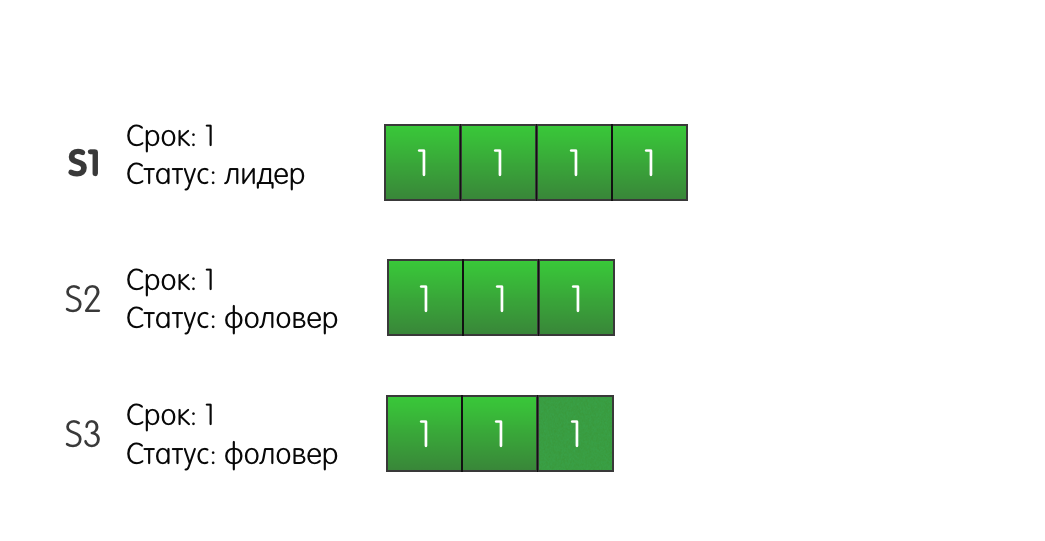
Die Aufzeichnung erreicht erfolgreich S2, aber das Netzwerk zwischen S1 und S3 blinkt und die Anforderung geht verloren. Da S1 weiß, dass der Datensatz auf zwei der drei Server vorhanden ist, kann es feststellen, dass der Datensatz festgeschrieben ist, und erfolgreich auf den Client reagieren.
S1 wird auch erneut versuchen, einen Eintrag zu S3 hinzuzufügen, bis dies erfolgreich ist. Aber was passiert, wenn S1 ausfällt und herunterfährt? Was passiert außerdem, wenn S3 als erster das Warten satt hat und ein Kandidat wird? S2 wird dafür stimmen, S3 wird der Anführer der zweiten Amtszeit und bei der nächsten Aufforderung, einen Datensatz hinzuzufügen, wird S3 unseren aufgezeichneten Datensatz überschreiben?
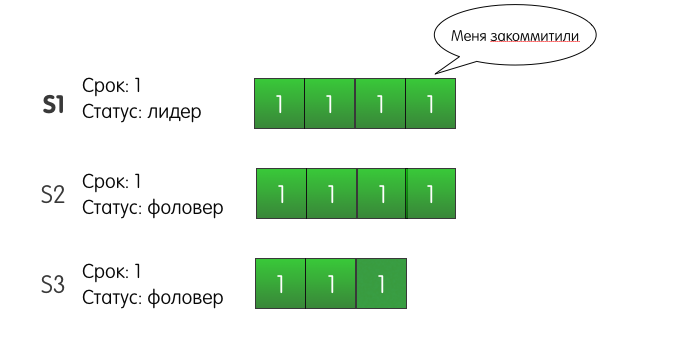
Tatsächlich kann diese Situation im Raft-Cluster nicht auftreten. Der Haken dabei ist, dass S2 nicht für S3 stimmen würde. Warum? Weil das S3-Serverprotokoll zum Zeitpunkt der Abstimmung weniger relevant ist als das S2-Serverprotokoll. Dieser Mechanismus wird als
Wahlbeschränkung bezeichnet. Der Server wählt nur dann für einen anderen Server, wenn das Protokoll des Kandidaten nicht weniger relevant ist als das Protokoll des Wählers.
Raft vergleicht die Relevanz von Protokollen auf zwei Arten:
- Nummer des letzten Aufnahmedatums
- Protokolllänge
Die Kandidaten nehmen diese beiden Parameter in die RequestVote-Anfrage auf, damit die Follower die Relevanz ihres Protokolls mit dem Protokoll des Kandidaten vergleichen können.
"Am wichtigsten" ist das Protokoll, in dem der letzte Datensatz älter ist.

Wenn die Nummern des Begriffs der letzten Einträge übereinstimmen, ist das Hauptprotokoll das längere Protokoll.

Wenn beide übereinstimmen, sind die Protokolle gleichermaßen relevant und, wie aus der vorherigen Eigenschaft hervorgeht, absolut identisch.
Es stellt sich heraus, dass das Serverprotokoll, in dem sich ein gesicherter Datensatz befindet, immer relevanter ist als das Protokoll, in dem es nicht vorhanden ist. Und ein Server mit einem gesicherten Datensatz stimmt nicht für einen Server, der diesen nicht hat. Und da auf den meisten Servern ein Datensatz aufgezeichnet ist, kann ein Kandidat ohne diesen Datensatz nicht die Mehrheit der Stimmen erhalten und führend werden, um diesen Datensatz von anderen Servern zu entfernen.
- Sicherheit von Zustandsautomaten: Diese Eigenschaft wird im Original in Bezug auf verteilte Zustandsautomaten beschrieben. In unserem Artikel kann diese Eigenschaft wie folgt beschrieben werden: Wenn ein Server einen Datensatz mit einem bestimmten Index festschreibt, schreibt kein anderer Server einen anderen Datensatz für diesen Index fest.
Diese Eigenschaft folgt aus der Vergangenheit. Wenn der Follower einen Datensatz bei Index N festlegt, ist sein Protokoll identisch mit dem Protokoll des Anführers bis einschließlich N. Die Leader-Vollständigkeitseigenschaft garantiert, dass alle nachfolgenden Leader auch diesen gesicherten Datensatz bei Index N enthalten. Dies bedeutet, dass Follower, die in nachfolgenden Perioden einen Datensatz bei Index N festschreiben, denselben Wert festschreiben.
Links zu Materialien für weitere Studien