Hallo Habr.
Dieser Artikel wird ein bisschen wie ein "Freitag" -Format sein, heute werden wir uns mit NLP befassen. Nicht das NLP, über das Bücher in Unterführungen verkauft werden, sondern das, bei dem
Natural Language Processing natürliche Sprachen verarbeitet. Als Beispiel für eine solche Verarbeitung wird die Texterzeugung unter Verwendung eines neuronalen Netzwerks verwendet. Wir können Texte in jeder Sprache erstellen, von Russisch oder Englisch bis C ++. Die Ergebnisse sind sehr interessant, können Sie wahrscheinlich aus dem Bild erraten.

Für diejenigen, die daran interessiert sind, was passiert, sind die Ergebnisse und der Quellcode unter dem Schnitt.
Datenaufbereitung
Für die Verarbeitung verwenden wir eine spezielle Klasse neuronaler Netze - die sogenannten wiederkehrenden neuronalen Netze (RNN). Dieses Netzwerk unterscheidet sich von dem üblichen dadurch, dass es zusätzlich zu den üblichen Zellen Speicherzellen hat. Dies ermöglicht es uns, Daten einer komplexeren Struktur und tatsächlich näher am menschlichen Gedächtnis zu analysieren, da wir auch nicht jeden Gedanken „von vorne“ beginnen. Zum Schreiben von Code verwenden wir
LSTM -Netzwerke (Long Short-Term Memory), da diese bereits von Keras unterstützt werden.
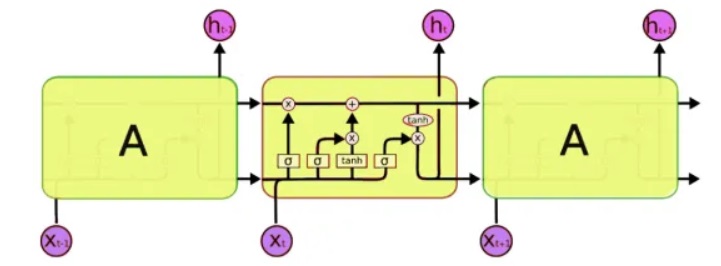
Das nächste Problem, das gelöst werden muss, ist die Arbeit mit Text. Und hier gibt es zwei Ansätze - entweder Symbole oder die ganzen Wörter an die Eingabe zu senden. Das Prinzip des ersten Ansatzes ist einfach: Der Text ist in kurze Blöcke unterteilt, wobei die "Eingaben" ein Fragment des Textes sind und die "Ausgabe" das nächste Zeichen ist. Für den letzten Satz ist "Eingaben sind beispielsweise ein Textstück":
input: output: ""
input: : output: ""
input: : output:""
input: : output: ""
input: : output: "".
Usw. Somit empfängt das neuronale Netzwerk Textfragmente an der Eingabe und an der Ausgabe die Zeichen, die es bilden soll.
Der zweite Ansatz ist im Grunde der gleiche, es werden nur ganze Wörter anstelle von Wörtern verwendet. Zunächst wird ein Wörterbuch mit Wörtern zusammengestellt und am Netzwerkeingang Zahlen anstelle von Wörtern eingegeben.
Dies ist natürlich eine ziemlich vereinfachte Beschreibung. Keras hat
bereits Beispiele für die Texterzeugung, aber erstens werden sie nicht so detailliert beschrieben, und zweitens verwenden alle englischsprachigen Tutorials eher abstrakte Texte wie Shakespeare, die für den Muttersprachler schwer zu verstehen sind. Nun, wir testen ein neuronales Netzwerk an unserem großen und leistungsstarken, was natürlich klarer und verständlicher sein wird.
Netzwerktraining
Als Eingabetext habe ich ... Habrs Kommentare verwendet, die Größe der Quelldatei beträgt 1 MB (es gibt natürlich mehr Kommentare, aber ich musste nur einen Teil verwenden, sonst wäre das neuronale Netzwerk eine Woche lang trainiert worden und die Leser hätten diesen Text bis Freitag nicht gesehen). Ich möchte Sie daran erinnern, dass nur Buchstaben an die Eingabe eines neuronalen Netzwerks gesendet werden. Das Netzwerk „weiß“ nichts über die Sprache oder ihre Struktur. Beginnen wir mit dem Netzwerktraining.
5 Minuten Training:Bisher ist nichts klar, aber Sie können bereits einige erkennbare Buchstabenkombinationen sehen:
. . . «
15 Minuten Training:Das Ergebnis ist bereits spürbar besser:
« » — « » » —Aus irgendeinem Grund erwiesen sich alle Texte als ohne Punkte und ohne Großbuchstaben. Vielleicht wurde die Verarbeitung von utf-8 nicht korrekt durchgeführt. Aber insgesamt ist das beeindruckend. Durch die Analyse und Speicherung nur von Symbolcodes lernte das Programm tatsächlich „unabhängig“ russische Wörter und kann einen glaubwürdig aussehenden Text erzeugen.
Nicht weniger interessant ist die Tatsache, dass sich das Programm den Textstil recht gut merkt. Im folgenden Beispiel wurde der Text eines Gesetzes als Lehre verwendet. Netzwerktrainingszeit 5 Minuten.
"" , , , , , , , ,
Und hier wurden medizinische Anmerkungen für Medikamente als Eingabesatz verwendet. Netzwerktrainingszeit 5 Minuten.
, ,
Hier sehen wir fast ganze Sätze. Dies liegt an der Tatsache, dass der Originaltext kurz ist und das neuronale Netzwerk tatsächlich einige Phrasen als Ganzes "auswendig gelernt" hat. Dieser Effekt wird als „Umschulung“ bezeichnet und sollte vermieden werden. Idealerweise müssen Sie ein neuronales Netzwerk an großen Datenmengen testen, aber das Training kann in diesem Fall viele Stunden dauern, und leider habe ich keinen zusätzlichen Supercomputer.
Ein unterhaltsames Beispiel für die Verwendung eines solchen Netzwerks ist die Namensgenerierung. Nachdem ich eine Liste mit männlichen und weiblichen Namen in die Datei hochgeladen hatte, erhielt ich interessante neue Optionen, die für einen Science-Fiction-Roman gut geeignet wären: Rlar, Laaa, Aria, Arera, Aelia, Ninran, Air. Etwas in ihnen fühlt den Stil von Efremov und dem Andromeda-Nebel ...
C ++
Das Interessante ist, dass ein neuronales Netzwerk im Großen und Ganzen wie das Erinnern ist. Der nächste Schritt bestand darin, zu überprüfen, wie das Programm mit dem Quellcode umgeht. Als Test habe ich verschiedene C ++ - Quellen genommen und sie zu einer Textdatei zusammengefasst.
Ehrlich gesagt überraschte das Ergebnis noch mehr als im Fall der russischen Sprache.
5 Minuten TrainingVerdammt, es ist fast echtes C ++.
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } }
30 Minuten Training void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate);
Wie Sie sehen können, hat das Programm "gelernt", ganze Funktionen zu schreiben. Gleichzeitig wurden die Funktionen durch einen Kommentar mit Sternchen vollständig „menschlich“ getrennt, Kommentare in den Code eingefügt und so weiter. Ich möchte eine neue Programmiersprache mit einer solchen Geschwindigkeit lernen ... Natürlich gibt es Fehler im Code, und natürlich wird er nicht kompiliert. Übrigens habe ich den Code nicht formatiert, das Programm hat auch gelernt, Klammern und Einrückungen "selbst" zu setzen.
Natürlich haben diese Programme nicht die Hauptsache -
Bedeutung und sehen daher surreal aus, als ob sie in einem Traum geschrieben wurden oder nicht von einer völlig gesunden Person geschrieben wurden. Trotzdem sind die Ergebnisse beeindruckend. Und vielleicht hilft eine eingehendere Untersuchung der Generierung verschiedener Texte, einige der psychischen Erkrankungen realer Patienten besser zu verstehen. Übrigens gibt es, wie in den Kommentaren angedeutet, eine solche Geisteskrankheit, bei der eine Person in einem grammatikalisch verwandten, aber völlig bedeutungslosen Text spricht (
Schizophasie ).
Fazit
Neuronale Freizeitnetze gelten als sehr vielversprechend, und dies ist in der Tat ein großer Fortschritt im Vergleich zu „normalen“ Netzen wie MLP, die keinen Speicher haben. In der Tat sind die Fähigkeiten neuronaler Netze zum Speichern und Verarbeiten ziemlich komplexer Strukturen beeindruckend. Nach diesen Tests dachte ich zum ersten Mal, dass Ilon Mask wahrscheinlich in etwas Recht hatte, als ich schrieb, dass KI in Zukunft „das größte Risiko für die Menschheit“ sein könnte - selbst wenn sich ein einfaches neuronales Netzwerk leicht erinnern und reproduzieren kann ziemlich komplexe Muster, was kann ein Netzwerk von Milliarden von Komponenten tun? Vergessen Sie andererseits nicht, dass unser neuronales Netzwerk nicht
denken kann , sondern sich im Wesentlichen nur mechanisch an Zeichenfolgen erinnert und deren Bedeutung nicht versteht. Dies ist ein wichtiger Punkt - selbst wenn Sie ein neuronales Netzwerk auf einem Supercomputer und einem riesigen Datensatz trainieren, wird es bestenfalls lernen, wie man grammatikalisch 100% korrekte, aber völlig bedeutungslose Sätze erzeugt.
Aber es wird nicht in der Philosophie entfernt, der Artikel ist noch mehr für Praktiker. Für diejenigen, die alleine experimentieren möchten, befindet sich der
Quellcode in Python 3.7 unter dem Spoiler. Dieser Code ist eine Zusammenstellung aus verschiedenen Github-Projekten und kein Beispiel für den besten Code, scheint aber seine Aufgabe zu erfüllen.
Die Verwendung des Programms erfordert keine Programmierkenntnisse. Sie müssen lediglich wissen, wie Python installiert wird. Beispiele für das Starten über die Befehlszeile:
- Erstellen und Trainieren von Modellen und Textgenerierung:
Python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000
- Nur Texterstellung ohne Modelltraining:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000 --generate
Ich denke, es hat sich als sehr
funky funktionierender Textgenerator herausgestellt,
der nützlich ist, um Artikel über Habr zu schreiben . Besonders interessant ist das Testen großer Texte und einer großen Anzahl von Trainingsiterationen. Wenn jemand Zugang zu schnellen Computern hat, wäre es interessant, die Ergebnisse zu sehen.
Wenn jemand das Thema genauer untersuchen möchte, finden Sie eine gute Beschreibung der Verwendung von RNN mit detaillierten Beispielen unter
http://karpathy.imtqy.com/2015/05/21/rnn-effectiveness/ .
PS: Und zum Schluss noch ein paar Verse;) Es ist interessant festzustellen, dass nicht ich die Formatierung des Textes oder sogar das Hinzufügen von Sternen vorgenommen habe. "Ich bin es selbst." Der nächste Schritt ist interessant, um die Möglichkeit zu prüfen, Bilder zu zeichnen und Musik zu komponieren. Ich denke, neuronale Netze sind hier sehr vielversprechend.
xxx
für einige in Keksen gefangen zu sein - alles in viel Glück auf einem Brotplatz.
und unter dem Abend von Tamaki
unter einer Kerze einen Berg nehmen.
xxx
bald Söhne Mons in Petachas in der Straßenbahn
Das unsichtbare Licht riecht nach Freude
deshalb klopfe ich zusammen wächst
Sie werden wegen eines Unbekannten nicht krank sein.
Herz in gestaffelten Ogora zu zupfen,
es ist nicht so alt, dass das Getreide isst,
Ich bewache die Brücke zum Ball, um zu stehlen.
auf die gleiche Weise Darina in Doba,
Ich höre in meinem Herzen Schnee auf meiner Hand.
unsere singen weiß wie viele sanfte dumina
Ich wandte mich von der Erzbestie ab.
xxx
Tierarzt Kreuziger mit einem Zauber
und unter den Vergessenen verschüttet.
und du, wie bei den Zweigen Kubas
darin glänzen.
o Spaß bei Zakoto
mit dem Flug der Milch.
Oh, du bist eine Rose, Licht
Wolkenlicht zur Hand:
und rollte im Morgengrauen
Wie geht es dir, mein Reiter?
Er dient abends, nicht bis auf die Knochen.
Nachts in Tanya das blaue Licht
wie eine Art Traurigkeit.Und die letzten Verse zum Lernen im Wortmodus. Hier verschwand der Reim, aber es erschien eine Bedeutung (?).
und du, von der Flamme
die Sterne.
sprach mit entfernten Personen.
Sorgen Sie rus ,, Sie ,, in morgen.
"Taubenregen,
und Heimat der Mörder,
für das Prinzessinnenmädchen
sein Gesicht.
xxx
Oh Hirte, winke den Kammern zu
auf einem Hain im Frühjahr.
Ich gehe durch das Herz des Hauses zum Teich,
und Mäuse frech
Nischni Nowgorod Glocken.
aber fürchte dich nicht, der Morgenwind,
mit einem Weg, mit einem eisernen Knüppel,
und dachte mit der Auster
auf einem Teich beherbergt
in verarmtem Rakit.