
Viele Netzwerkanwendungen bestehen aus einem Webserver, der Echtzeitverkehr verarbeitet, und einem zusätzlichen Handler, der asynchron im Hintergrund ausgeführt wird. Es gibt viele gute Tipps zum Überprüfen des Verkehrsstatus, und die Community hört nicht auf, Tools wie Prometheus zu entwickeln, die bei der Bewertung helfen. Aber Handler sind manchmal nicht weniger - und noch wichtiger -. Sie brauchen auch Aufmerksamkeit und Bewertung, aber es gibt wenig Anleitung, wie dies getan werden kann, während häufige Fallstricke vermieden werden.
Dieser Artikel befasst sich mit den Traps, die bei der Bewertung asynchroner Handler am häufigsten vorkommen. Anhand eines Beispiels eines Vorfalls in einer Produktionsumgebung, in der es trotz Metriken unmöglich war, genau zu bestimmen, was die Handler taten. Die Verwendung von Metriken hat den Fokus so sehr verschoben, dass die Metriken selbst offen gelogen haben, sagen sie, Ihre Handler zur Hölle.
Wir werden sehen, wie Metriken so verwendet werden, dass eine genaue Schätzung bereitgestellt wird, und abschließend werden wir die Referenzimplementierung des Open-Source- Prometheus-Client-Tracers zeigen , den Sie in Ihren Anwendungen verwenden können.
Vorfall
Die Warnungen erreichten eine Maschinengewehrgeschwindigkeit: Die Anzahl der HTTP-Fehler stieg stark an, und die Kontrollfelder bestätigten, dass die Anforderungswarteschlangen größer wurden und die Antwortzeit abgelaufen war. Ungefähr 2 Minuten später wurden die Warteschlangen gelöscht und alles normalisiert.
Bei näherer Betrachtung stellte sich heraus, dass unsere API-Server aufstanden und auf eine DB-Antwort warteten, die dazu führte, dass sie blockierten und plötzlich alle Aktivitäten aufnahmen. Und wenn man bedenkt, dass die schwerste Last häufiger auf asynchrone Prozessoren fällt, sind sie zu den Hauptverdächtigen geworden. Die logische Frage war: Was machen sie dort überhaupt ?!
Die Prometheus-Metrik zeigt, wie lange der Prozess dauert. Hier ist er:
# HELP job_worked_seconds_total Sum of the time spent processing each job class # TYPE job_worked_seconds_total counter job_worked_seconds_total{job}
Indem wir die Gesamtausführungszeit jeder Aufgabe und die Häufigkeit verfolgen, mit der sich die Metrik ändert, ermitteln wir, wie viel Arbeitszeit aufgewendet wurde. Wenn für einen Zeitraum von 15 Sekunden. Wenn die Anzahl um 15 erhöht wird, bedeutet dies, dass 1 Handler beschäftigt ist (eine Sekunde für jede letzte Sekunde), während eine Erhöhung um 30 2 Handler usw. bedeutet.
Ein Arbeitsplan während des Vorfalls zeigt, was uns bevorsteht. Die Ergebnisse sind enttäuschend; Der Zeitpunkt des Vorfalls (16: 02–16: 04) ist durch die alarmierende rote Linie gekennzeichnet:

Handleraktivität während des Vorfalls: Eine merkliche Lücke ist sichtbar.
Es war für mich als Person, die nach diesem Albtraum debuggte, schmerzhaft zu sehen, dass die Aktivitätskurve gerade während des Vorfalls ganz unten war. Dies ist die Zeit für die Arbeit mit Web-Hooks, in denen wir 20 dedizierte Handler haben. Aus den Protokollen weiß ich, dass sie alle im Geschäft waren, und ich erwartete, dass die Kurve bei etwa 20 Sekunden liegen würde, und ich sah eine fast gerade Linie. Sehen Sie außerdem diesen großen blauen Gipfel um 16:05 Uhr? Gemessen am Zeitplan verbrachten 20 Single-Threaded-Prozessoren 45 Sekunden. für jede Sekunde der Aktivität, aber ist das möglich ?!
Wo und was ist schief gelaufen?
Der Zeitplan des Vorfalls lügt: Er verbirgt die Arbeitsaktivität und zeigt gleichzeitig das Überflüssige - je nachdem, wo gemessen werden soll. Um herauszufinden, warum dies geschieht, müssen Sie die Implementierung der Metrikverfolgung und deren Interaktion mit Prometheus berücksichtigen.
Beginnend mit der Erfassung von Metriken durch Handler können Sie ein ungefähres Workflow-Implementierungsschema skizzieren (siehe unten). Hinweis: Handler aktualisieren Metriken erst nach Abschluss einer Aufgabe .
class Worker JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) def work job = acquire_job start = Time.monotonic_now job.run ensure # run after our main method block duration = Time.monotonic_now - start JobWorkedSecondsTotal.increment(by: duration, labels: { job: job.class }) end end
Prometheus (mit seiner Philosophie, Metriken zu extrahieren) sendet alle 15 Sekunden eine GET-Anfrage an jeden Handler und zeichnet die Werte der Metriken zum Zeitpunkt der Anfrage auf. Handler aktualisieren ständig die Metriken abgeschlossener Aufgaben, und im Laufe der Zeit können wir die Dynamik von Wertänderungen grafisch darstellen.
Das Problem mit Unter- und Neubewertung tritt immer dann auf, wenn die Zeit, die zum Ausführen einer Aufgabe benötigt wird, die Wartezeit für eine Anforderung überschreitet, die alle 15 Sekunden eintrifft. Beispielsweise beginnt eine Aufgabe 5 Sekunden vor der Anforderung und endet 1 Sekunde danach. Ganz und gar dauert es 6 Sekunden, aber diese Zeit ist nur sichtbar, wenn die nach der Anforderung getätigten Zeitkosten geschätzt werden, während 5 dieser 6 Sekunden vor der Anforderung verbracht wurden.
Die Indikatoren sind noch gottloser, wenn die Aufgaben länger als der Berichtszeitraum (15 Sekunden) dauern. Während der Ausführung der Aufgabe für 1 Minute hat Prometheus Zeit, 4 Anforderungen an die Prozessoren zu senden, aber die Metrik wird erst nach der vierten aktualisiert.
Nachdem wir einen Zeitplan für die Arbeitsaktivität erstellt haben, werden wir sehen, wie sich der Moment der Aktualisierung der Metrik auf das auswirkt, was Prometheus sieht. In der folgenden Abbildung teilen wir die Zeitachse zweier Handler in mehrere Segmente auf, in denen Aufgaben unterschiedlicher Dauer angezeigt werden. Rote (15 Sekunden) und blaue (30 Sekunden) Tags zeigen 2 Prometheus-Datenproben an. Die Aufgaben, die als Datenquelle für die Bewertung dienten, sind jeweils farblich hervorgehoben.
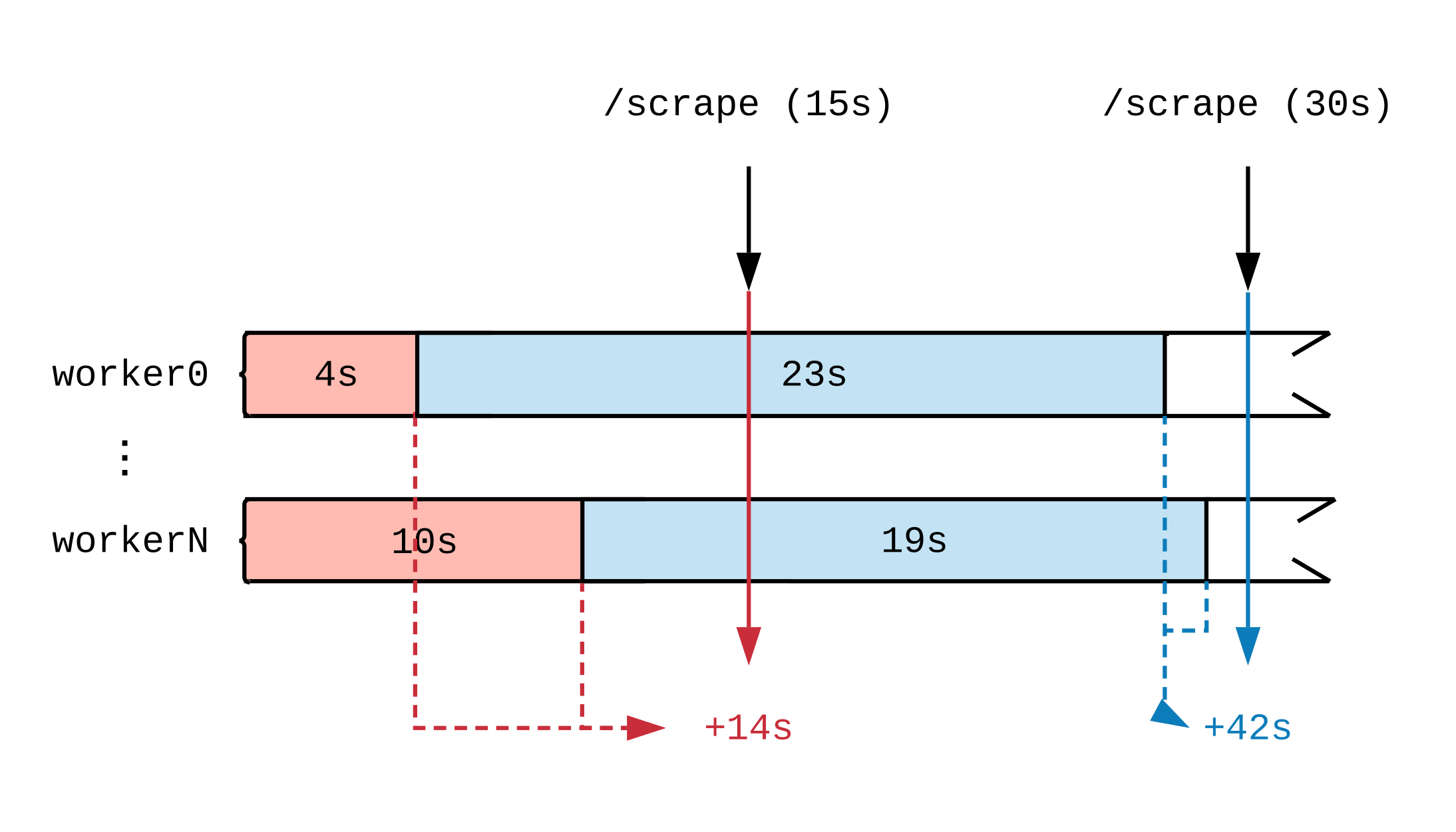
Unabhängig davon, was die Handler bei Volllast tun, erledigen sie alle 15 Sekunden 30 Sekunden Arbeit. Da Prometheus die Arbeit erst nach Abschluss sieht, wurden nach den Metriken 14 Sekunden Arbeit im ersten Zeitintervall und 42 Sekunden im zweiten Zeitintervall erledigt. Wenn jeder Handler eine umfangreiche Aufgabe übernimmt, werden wir auch nach einigen Stunden bis zum Ende keine Berichte darüber sehen, dass die Arbeit läuft.
Um diesen Effekt zu demonstrieren, führte ich ein Experiment mit zehn Handlern durch, die an Aufgaben beteiligt waren, deren Länge unterschiedlich und halbnormal zwischen 0,1 Sekunden und einem etwas höheren Wert verteilt war (siehe zufällige Aufgaben ). Unten sind 3 Diagramme dargestellt, die die Arbeitsaktivität darstellen. Die Zeitdauer wird in aufsteigender Reihenfolge angezeigt.
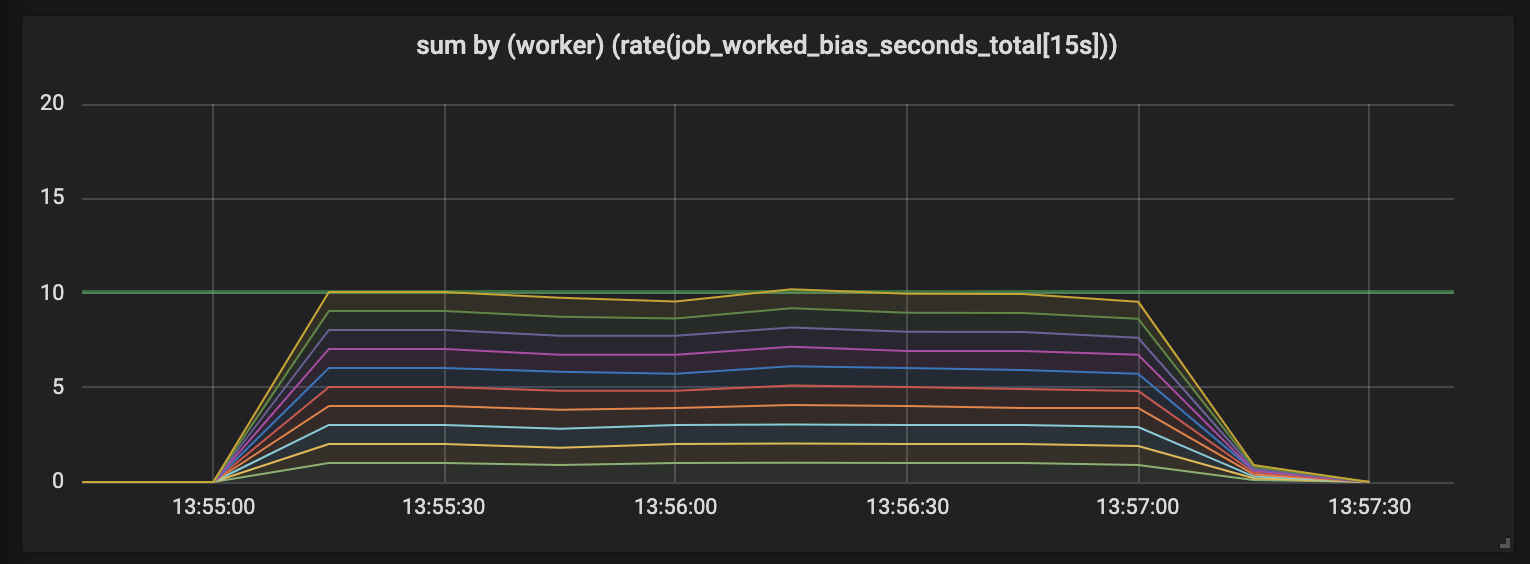
Aufgaben bis zu 1 Sekunde.
Die erste Grafik zeigt, dass jeder Handler in jeder Sekunde ungefähr 1 Sekunde Arbeit erledigt - dies ist auf flachen Linien sichtbar, und der Gesamtarbeitsaufwand entspricht unseren Fähigkeiten (10 Handler geben eine Sekunde Arbeit pro Sekunde Zeit aus). Tatsächlich erwarten wir dies unabhängig von der Länge der Aufgabe: Gerade bei kurzen und langen Aufgaben sollten Prozessoren mit konstanter Last so viel ausgeben.
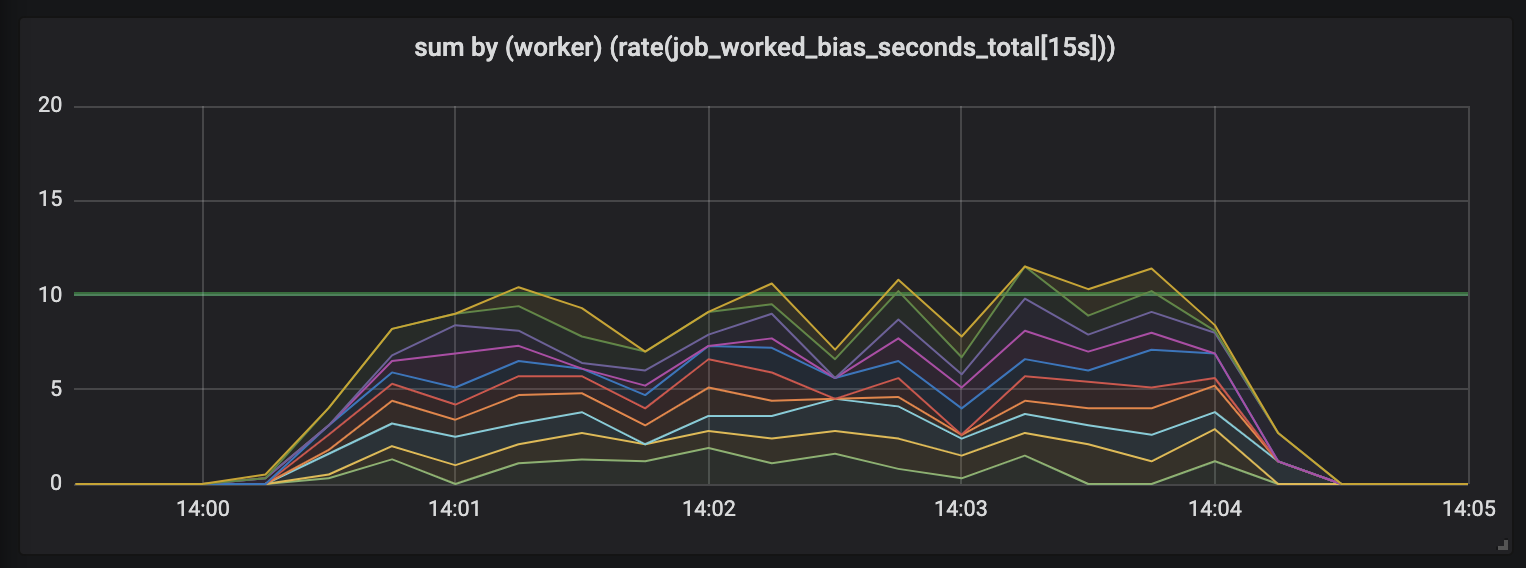
Aufgaben bis zu 15 Sekunden.
Die Dauer der Aufgaben nimmt zu, und im Zeitplan wird ein Durcheinander angezeigt: Wir haben immer noch 10 Prozessoren, die alle voll belegt sind, aber die Gesamtmenge der Arbeit überspringt - entweder niedriger oder höher als die Grenze der Nutzkapazität (10 Sekunden).
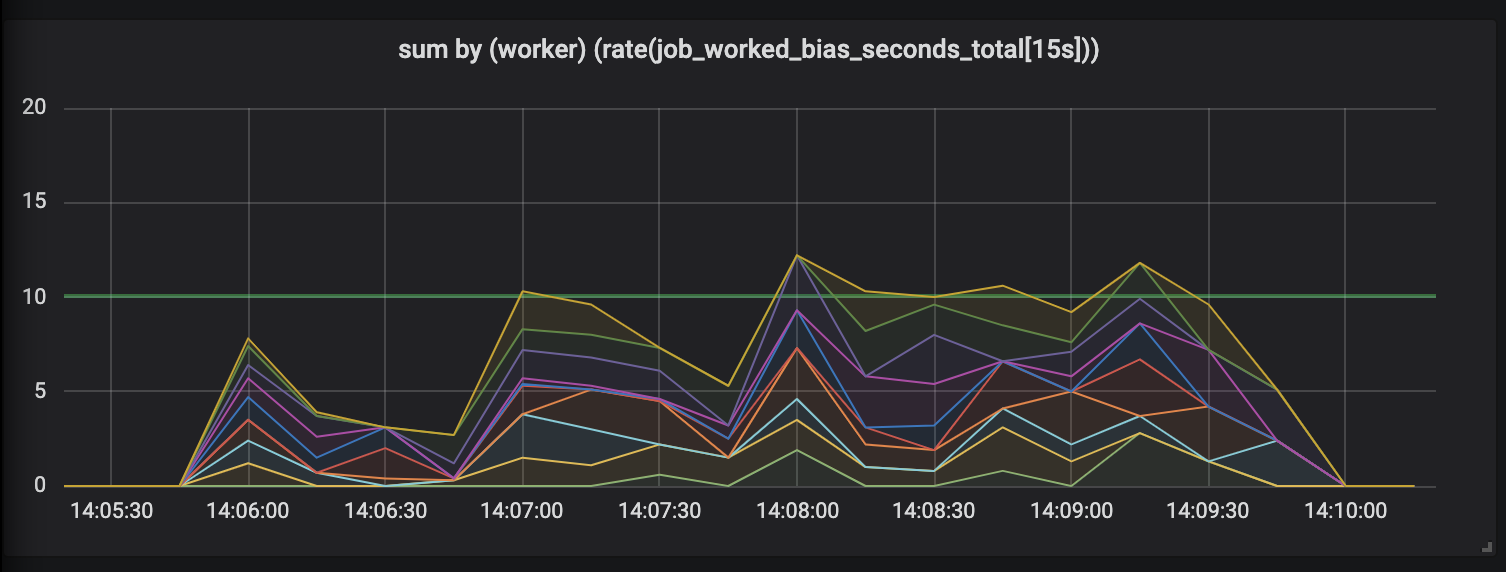
Aufgaben bis zu 30 Sekunden.
Die Bewertung von Arbeiten mit einer Dauer von bis zu 30 Sekunden ist einfach lächerlich. Eine zeitgebundene Metrik zeigt für die längsten Aufgaben keine Aktivität an und zeichnet uns erst nach Abschluss der Aufgaben Aktivitätsspitzen.
Stellen Sie das Vertrauen wieder her
Dies hat uns nicht gereicht, daher gibt es ein weiteres, viel heimtückischeres Problem mit diesen langfristigen Aufgaben, die unsere Metriken beeinträchtigen. Wann immer eine langfristige Aufgabe abgeschlossen ist - beispielsweise wenn Kubernetes einen Pod aus einem Pool wirft oder wenn ein Knoten stirbt, was passiert dann mit den Metriken? Es lohnt sich, sie sofort nach Abschluss der Aufgabe zu aktualisieren, da sie zeigen, dass sie die Arbeit überhaupt nicht erledigt haben .
Metriken sollten nicht lügen. Der Laptop heult ungläubig und verursacht existenziellen Horror. Überwachungstools, die das Bild der Welt verzerren, sind eine Falle und für die Arbeit ungeeignet.
Glücklicherweise ist die Angelegenheit behebbar. Datenverzerrungen treten auf, weil Prometheus Messungen vornimmt, unabhängig davon, wann Prozessoren Metriken aktualisieren. Wenn wir die Handler bitten, die Metriken zu aktualisieren, wenn Prometheus Anforderungen sendet, werden wir feststellen, dass Prometheus nicht mehr eigenartig ist und die aktuelle Aktivität anzeigt.
Wir stellen vor ... Tracer
Eine Lösung für das Problem der verzerrten Metriken ist der Tracer , ein abstrakt gestalteter Tracer , der die Aktivität bei Aufgaben mit langer Laufzeit bewertet, indem Prometheus-bezogene Metriken schrittweise aktualisiert werden.
class Tracer def trace(metric, labels, &block) ... end def collect(traces = @traces) ... end end
Tracer bieten eine Verfolgungsmethode, die die Prometheus-Metriken und die zu verfolgende Aufgabe übernimmt. Der Befehl trace führt den angegebenen Block aus (anonyme Ruby-Funktionen) und stellt sicher, dass Anforderungen an tracer.collect während der Ausführung die zugehörigen Metriken schrittweise aktualisieren, unabhängig davon, wie viel Zeit seit der letzten Anforderung zum collect vergangen ist.
Wir müssen den tracer mit den Handlern verbinden, um die Dauer der Aufgabe und den Endpunkt zu verfolgen, der die Prometheus-Metrikanforderungen bedient. Wir beginnen mit den Handlern, initialisieren einen neuen Tracer und bitten ihn, die Ausführung von acquire_job.run .
class Worker def initialize @tracer = Tracer.new(self) end def work @tracer.trace(JobWorkedSecondsTotal, labels) { acquire_job.run } end # Tell the tracer to flush (incremental) trace progress to metrics def collect @tracer.collect end end
Zu diesem Zeitpunkt aktualisiert der Tracer die Metriken nur in Sekunden, die für die abgeschlossene Aufgabe aufgewendet wurden - wie bei der ersten Implementierung der Metriken. Wir müssen den Tracer bitten, unsere Metriken zu aktualisieren, bevor wir eine Anfrage von Prometheus ausführen. Dies kann durch Einrichten des Middleware-Racks erfolgen.
# config.ru # https://rack.imtqy.com/ class WorkerCollector def initialize(@app, workers: @workers); end def call(env) workers.each(&:collect) @app.call(env) # call Prometheus::Exporter end end # Rack middleware DSL workers = start_workers # Array[Worker] # Run the collector before serving metrics use WorkerCollector, workers: workers use Prometheus::Middleware::Exporter
Rack ist eine Schnittstelle für Ruby-Webserver, mit der Sie mehrere Rack-Handler zu einem einzigen Endpunkt kombinieren können. Der config.ru Befehl config.ru bestimmt, dass die Rack-Anwendung - wann immer sie die Anforderung empfängt - den Befehl collect an die Handler sendet und erst dann den Prometheus-Client anweist, die Erfassungsergebnisse zu zeichnen.
In unserem Diagramm aktualisieren wir die Metriken immer dann, wenn die Aufgabe abgeschlossen ist oder wenn wir eine Anfrage nach Metriken erhalten. Aufgaben mit mehreren Abfragen senden gleichermaßen Daten in allen Segmenten: Dies wird durch Aufgaben gezeigt, deren Dauer in Intervalle von 15 Sekunden unterteilt wurde.

Ist es besser
Die Verwendung von Tracer 24 Stunden am Tag wirkt sich darauf aus, wie die Aktivität protokolliert wird. Im Gegensatz zu den anfänglichen Messungen, die eine „Säge“ zeigten, liefert das Experiment mit zehn Prozessoren ein Diagramm, das deutlich zeigt, dass jeder Prozessor in die gleichmäßig überwachte Arbeit eingebettet ist, wenn die Anzahl der Peaks die Anzahl der laufenden Prozessoren und die Perioden dumpfer Stille überschreitet.

Auf Vergleich basierende Metriken (links), die vom Tracer (rechts) gesteuert werden und aus einem Arbeitsexperiment stammen.
Verglichen mit dem offen gesagt ungenauen und chaotischen Zeitplan der anfänglichen Messungen sind die vom Tracer gesammelten Metriken glatt und konsistent. Wir verknüpfen die Arbeit jetzt nicht nur genau mit jeder Metrikanforderung, sondern sorgen uns auch nicht um den plötzlichen Tod eines der Handler: Prometheus zeichnet die Metriken auf, bis der Handler verschwindet, und bewertet alle seine Arbeiten.
Kann das verwendet werden?
Ja! Die Tracer Oberfläche hat sich in vielen Projekten als nützlich erwiesen. Dies ist also ein separates Ruby-Juwel, Prometheus-Client-Tracer . Wenn Sie den Prometheus-Client in Ihren Ruby-Anwendungen verwenden, fügen Sie einfach den prometheus-client-tracer zu Ihrer Gemfile hinzu:
require "prometheus/client" require "prometheus/client/tracer" JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) Prometheus::Client.trace(JobWorkedSecondsTotal) do sleep(long_time) end
Wenn sich dies als nützlich für Sie herausstellt und Sie möchten, dass der offizielle Prometheus Ruby-Client in Tracer angezeigt wird , hinterlassen Sie eine Bewertung in client_ruby # 135 .
Und zum Schluss noch ein paar Gedanken
Ich hoffe, dies hilft anderen dabei, Metriken für langfristige Aufgaben bewusster zu sammeln und eines der häufigsten Probleme zu lösen. Machen Sie keinen Fehler, es ist nicht nur mit der asynchronen Verarbeitung verbunden: Wenn Ihre HTTP-Anforderungen verlangsamt werden, profitieren sie auch von der Verwendung des Tracers bei der Bewertung der für die Verarbeitung aufgewendeten Zeit.
Feedback und Korrekturen sind wie gewohnt willkommen: Schreiben Sie an Twitter oder öffnen Sie PR . Wenn Sie zu Tracer Gem beitragen möchten, befindet sich der Quellcode auf prometheus-client-tracer-ruby .