Hallo Habr! Unsere Freunde von Softpoint haben einen interessanten Artikel über Microsoft SQL Server vorbereitet. Es werden zwei praktische Beispiele für die Verwendung der Volltextsuche analysiert:
- Suchen Sie in „unendlichen“ Zeilen (z. B. Kommentare) im Gegensatz zu einer regulären Suche in LIKE.
- Suche nach Dokumentennummern mit Präfixen. Wo normalerweise die Volltextsuche nicht verwendet werden kann: Konstante Präfixe stören sie. Es werden zwei Ansätze analysiert: Vorverarbeitung der Dokumentennummer und Hinzufügen eines eigenen Bibliothekswortbrechers.
Jetzt mitmachen!
 Ich gebe dem Autor das Wort
Ich gebe dem Autor das WortEine effektive Suche in Gigabyte gesammelter Daten ist eine Art „heiliger Gral“ von Buchhaltungssystemen. Jeder möchte ihn finden und unsterblichen Ruhm erlangen, aber bei der Suche immer wieder stellt sich heraus, dass es keine einzige wundersame Lösung gibt.
Die Situation wird durch die Tatsache kompliziert, dass Benutzer normalerweise nach einem Teilstring suchen möchten - irgendwo stellt sich heraus, dass die gewünschte Vertragsnummer in der Mitte des Kommentars "vergraben" ist; irgendwo erinnert sich der Betreiber nicht genau an den Namen des Kunden, aber er erinnerte sich, dass sein Name „Alexey Evgrafovich“ war; Irgendwo müssen Sie nur die wiederkehrende Eigentumsform von BYUBL weglassen und sofort nach dem Namen der Organisation suchen. Für klassische relationale DBMS ist eine solche Suche eine sehr schlechte Nachricht. Am häufigsten wird eine solche Teilstringsuche auf das methodische Scrollen jeder Zeile der Tabelle reduziert. Nicht die effektivste Strategie, insbesondere wenn die Größe der Tabelle auf mehrere zehn Gigabyte ansteigt.
Auf der Suche nach einer Alternative erinnere ich mich oft an die „Volltextsuche“. Die Freude, eine Lösung zu finden, vergeht normalerweise schnell nach einer flüchtigen Überprüfung der bestehenden Praxis. Es stellt sich schnell heraus, dass nach allgemeiner Meinung die Volltextsuche:
- Schwer zu konfigurieren
- Langsam aktualisiert
- Hängt das System beim Update auf
- Hat eine
dumme ungewöhnliche Syntax - Findet nicht, was sie fragen
Die Mythen können noch lange fortgesetzt werden, aber selbst Platon hat uns gelehrt, Skeptiker zu sein und die Meinung eines anderen zum Glauben nicht blind zu akzeptieren. Mal sehen, ob der Teufel so schrecklich ist, wie er gemalt wird?
Und obwohl wir nicht tief in die Studie vertieft sind, werden wir uns
sofort auf eine wichtige Bedingung einigen . Die Volltextsuchmaschine kann viel mehr als eine normale Zeichenfolgensuche. Sie können beispielsweise ein Wörterbuch mit Synonymen definieren und das Wort "Kontakt" verwenden, um "Telefon" zu finden. Oder suchen Sie nach Wörtern ohne Rücksicht auf Form und Endung. Diese Optionen können für Benutzer sehr nützlich sein. In diesem Artikel wird die Volltextsuche jedoch nur als Alternative zur klassischen Zeilensuche betrachtet. Das heißt,
wir werden nur nach dem Teilstring suchen, der in der Suchleiste angegeben wird , ohne Synonyme zu berücksichtigen, ohne Wörter in die „normale“ Form und andere Magie umzuwandeln.
Funktionsweise der MS SQL-Volltextsuche
Die Volltextsuchfunktion in MS SQL wurde teilweise aus dem DBMS-Hauptdienst entfernt (am Ende des Artikels werden wir sehen, warum dies äußerst nützlich sein kann). Für die Suche wird im Gegensatz zu den üblichen ausgeglichenen Bäumen ein spezieller Index mit seiner Struktur gebildet.
Es ist wichtig, dass zum Erstellen eines Volltextsuchindex in der Schlüsseltabelle ein eindeutiger Index vorhanden ist, der nur aus einer Spalte besteht. Die Volltextsuche wird zur Identifizierung von Tabellenzeilen verwendet. Oft hat die Tabelle bereits einen solchen Index für den Primärschlüssel, manchmal muss er jedoch zusätzlich erstellt werden.
Der Volltextsuchindex wird asynchron und außerhalb der Transaktion ausgefüllt. Nach dem Ändern einer Tabellenzeile wird diese zur Verarbeitung in die Warteschlange gestellt. Beim Aktualisieren des Index werden von der Tabellenzeile (Zeile) alle Zeichenfolgenwerte empfangen, die den Index "abonniert" haben, und in separate Wörter unterteilt. Danach können die Wörter auf eine „Standardform“ reduziert werden (z. B. ohne Endungen), so dass die Suche nach Wortformen einfacher ist. "Stoppwörter" werden weggeworfen (Präpositionen, Artikel und andere Wörter, die keine Bedeutung haben). Die verbleibenden Wort-zu-Zeichenfolge-Verknüpfungsübereinstimmungen werden in den Volltextsuchindex geschrieben.
Es stellt sich heraus, dass jede im Index enthaltene Spalte der Tabelle eine solche Pipeline durchläuft:
Lange Zeile -> Wortbrecher -> Satz von Teilen (Wörtern) -> Stemmer -> normalisierte Wörter -> [optional] Stoppwortausnahme -> In Index schreiben
Wie bereits erwähnt, ist der Indexaktualisierungsprozess asynchron. Daraus folgt:
- Update blockiert keine Benutzeraktionen
- Das Update wartet auf den Abschluss der Zeilenänderungstransaktion und beginnt, die Änderungen frühestens beim Festschreiben anzuwenden
- Änderungen am Volltextindex werden mit einer gewissen Verzögerung gegenüber der Haupttransaktion angewendet. Das heißt, zwischen dem Hinzufügen einer Zeile und dem Zeitpunkt, zu dem sie gefunden werden kann, tritt abhängig von der Länge der Indexaktualisierungswarteschlange eine Verzögerung auf
- Die Anzahl der im Index enthaltenen Elemente kann durch die Abfrage überwacht werden:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
Praktische Tests. Suche nach physischen Personen mit Namen
Füllen Sie die Tabelle mit Daten
Für Experimente erstellen wir eine neue leere Basis mit einer Tabelle, in der die „Gegenparteien“ gespeichert werden. Im Feld "Beschreibung" befindet sich eine Zeile mit dem Namen des Vertrags, in der der Name der Gegenpartei angegeben wird. Irgendwie so:
"Vertrag mit Borovik Demyan Emelyanovich"
Oder so:
„Hund. mit Borovik-Romanov Anatoly Avdeevich "
Ja, ich möchte mich sofort von einer solchen „Architektur“ abschießen, aber leider ist eine solche Anwendung von „Kommentaren“ oder „Beschreibungen“ häufig bei Geschäftsanwendern anzutreffen.
Zusätzlich fügen wir einige Felder "für Gewicht" hinzu: Wenn die Tabelle nur 2 Spalten enthält, wird sie in wenigen Augenblicken durch einen einfachen Scan gelesen. Wir müssen den Tisch „aufblasen“, damit der Scan lang ist. Dies bringt uns näher an reale Geschäftsfälle: Wir speichern nicht nur die „Beschreibung“ in der Tabelle, sondern auch viele andere [teuflische] nützliche Informationen.
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
Die nächste Frage ist, wo man so viele eindeutige Nachnamen, Vornamen und Patronymien bekommt. Ich habe nach alter Gewohnheit als normaler russischer Student gehandelt, d.h. ging zu Wikipedia:
- Namen aus der Seite Kategorie: Russische männliche Namen
- Manuelle Umschreibung von Zweitnamen aus Namen, Änderung der Endungen
- Bei Nachnamen stellte sich heraus, dass es etwas komplizierter war. Am Ende wurde die Kategorie "Namensvetter" gefunden. Ein wenig Schamanismus mit Python und in einer separaten Tabelle ergab 46,5 Tausend Namen. (Ein Skript zum Herunterladen von Nachnamen finden Sie hier)
Natürlich gab es merkwürdige Unterschiede zwischen den Nachnamen, aber für die Zwecke der Studie war dies durchaus akzeptabel.
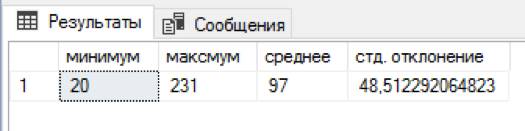
Ich habe ein SQL-Skript geschrieben, das jedem Nachnamen eine zufällige Anzahl von Namen und Patronymien hinzufügt. 5 Minuten warten und in einem separaten Tisch gab es bereits 4,5 Millionen Kombinationen. Nicht schlecht! Für jeden Nachnamen gab es 20 bis 231 Kombinationen des Namens + des zweiten Vornamens, durchschnittlich wurden 97 Kombinationen erhalten. Die Verteilung nach Namen und Patronym stellte sich als leicht nach links voreingenommen heraus, aber es schien überflüssig, einen ausgewogeneren Algorithmus zu entwickeln.
Die Daten werden vorbereitet, wir können mit unseren Experimenten beginnen.
Einrichtung der Volltextsuche
Erstellen Sie einen Volltextindex auf MS SQL-Ebene. Zuerst müssen wir ein Repository für diesen Index erstellen - einen Volltextkatalog.
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
Es gibt einen Katalog, wir versuchen, einen Volltextindex für unsere Tabelle hinzuzufügen ... und nichts funktioniert.
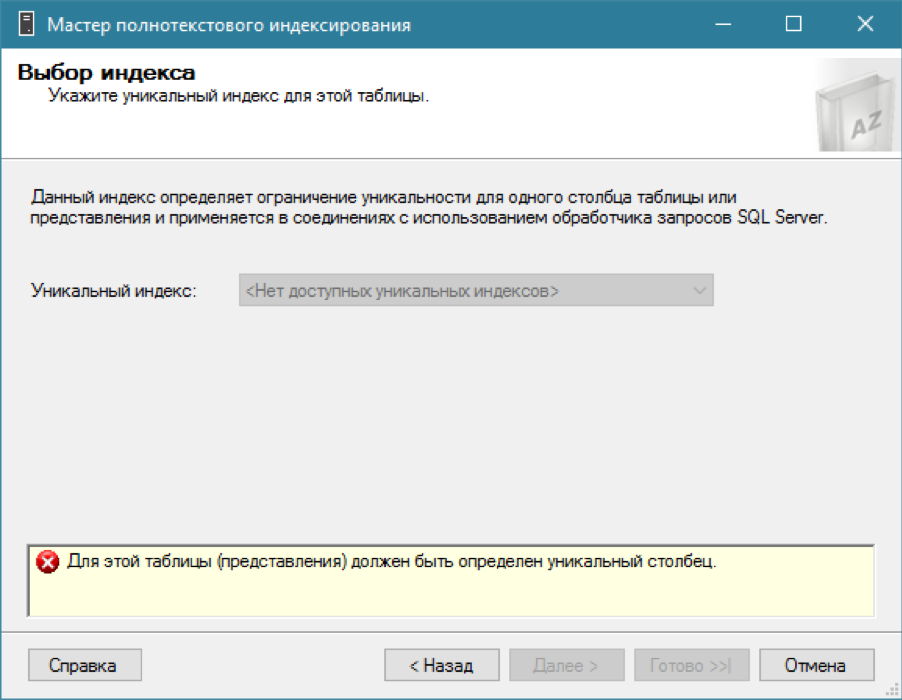
Wie gesagt, für einen Volltextindex benötigen Sie einen regulären Index mit einer eindeutigen Spalte. Wir erinnern uns, dass wir bereits das erforderliche Feld haben - eine eindeutige ID. Erstellen wir einen eindeutigen Clusterindex (obwohl ein nicht gruppierter Index ausreichen würde):
create unique clustered index ndx1 on partners (id)
Nachdem wir einen neuen Index erstellt haben, können wir endlich den Volltextsuchindex hinzufügen. Warten wir einige Minuten, bis der Index voll ist (denken Sie daran, dass er asynchron aktualisiert wird!). Sie können mit den Tests fortfahren.
Testen
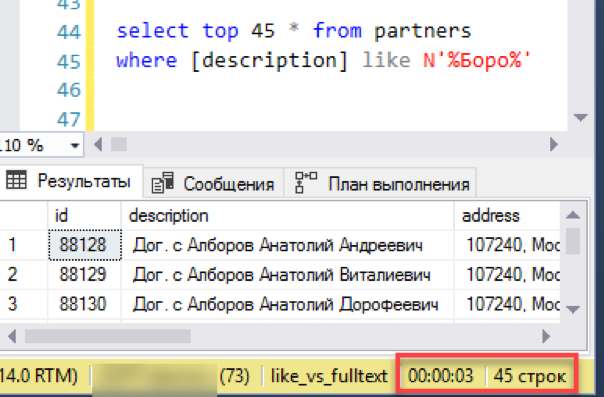
Beginnen wir mit dem einfachsten Szenario, das der tatsächlichen Anwendung der Suche nahe kommt. Wir simulieren eine „Listenansicht“ - eine Fensterauswahl von 45 Zeilen mit Auswahl nach Suchmaske. Wir führen die Anfrage mit einem neuen Volltextindex aus, wir notieren die Zeit - 0 Sekunden - ausgezeichnet!
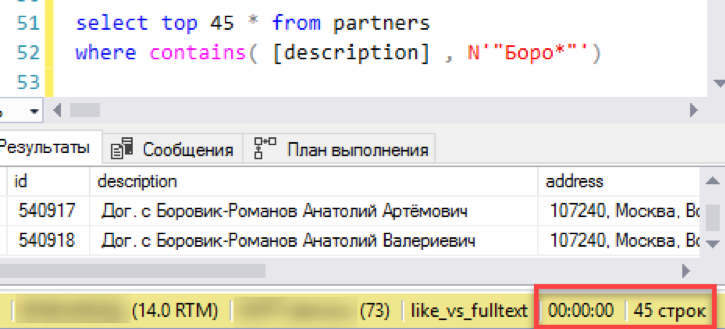
Jetzt eine alte, bewährte Suche durch "Gefällt mir". Es dauerte 3 Sekunden, um das Ergebnis zu bilden. Nicht so schlimm, die totale Niederlage hat nicht funktioniert. Vielleicht macht es dann keinen Sinn, eine Volltextsuche einzurichten - funktioniert alles einwandfrei?
Tatsächlich haben wir ein wichtiges Detail übersehen: Die Anforderung wurde ohne Sortierung ausgeführt. Erstens liefert eine solche Abfrage, gepaart mit "Auswählen der ersten N Datensätze", ein ungerechtfertigtes Ergebnis. Jeder Start kann N zufällige Datensätze zurückgeben, und es gibt keine Garantie dafür, dass zwei aufeinanderfolgende Starts denselben Datensatz ergeben. Zweitens, wenn wir über das "Anzeigen der Liste mit einem Schiebefenster" sprechen - normalerweise wird dieses "Fenster" nach einer beliebigen Spalte sortiert, beispielsweise nach Namen. Schließlich muss der Bediener wissen, was er erhält, wenn er zum nächsten „Fenster“ wechselt.
Korrigieren Sie das Experiment. Fügen Sie beispielsweise die Sortierung nach Telefonnummer hinzu:
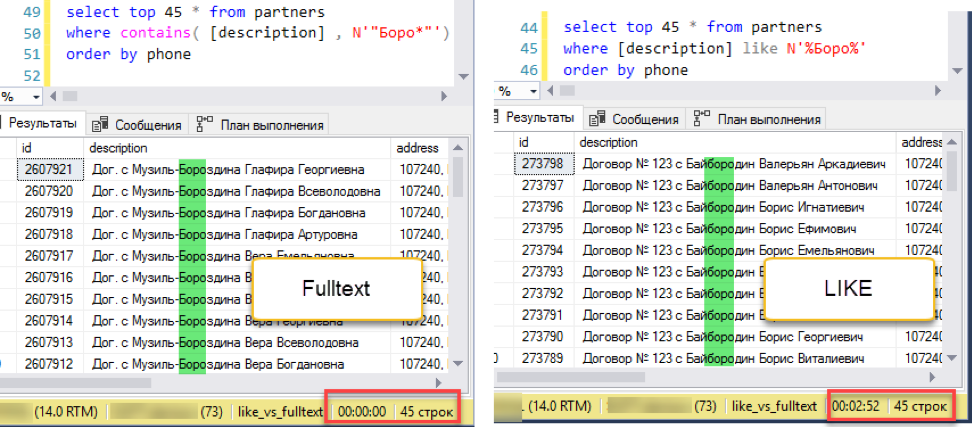 Die Volltextsuche gewinnt mit einer ohrenbetäubenden Punktzahl: 0 Sekunden gegenüber 172 Sekunden!
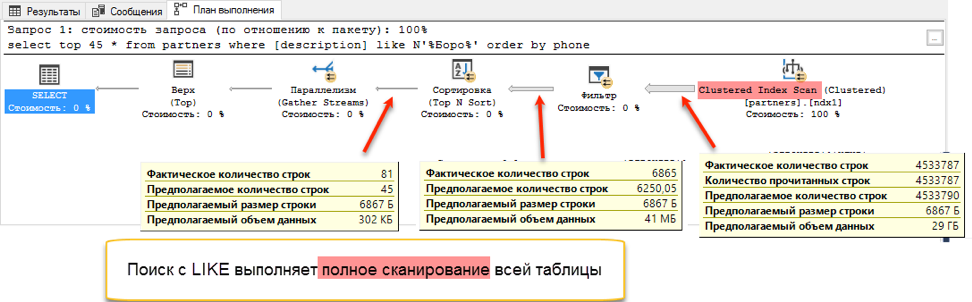
Die Volltextsuche gewinnt mit einer ohrenbetäubenden Punktzahl: 0 Sekunden gegenüber 172 Sekunden!Wenn Sie sich die Abfragepläne ansehen, wird klar, warum dies so ist. Aufgrund der Hinzufügung der Reihenfolge zum Abfragetext wurde während der Ausführung eine Sortieroperation angezeigt. Dies ist die sogenannte "Blockierungs" -Operation, bei der die Anforderung erst abgeschlossen werden kann, wenn die gesamte Datenmenge zum Sortieren empfangen wurde. Wir können nicht die ersten 45 Datensätze abrufen, sondern müssen den gesamten Datensatz sortieren.
Und in der Phase des Erhaltens von Daten zum Sortieren tritt ein dramatischer Unterschied auf. Eine Suche mit "Gefällt mir" muss die gesamte verfügbare Tabelle durchsuchen. Dies dauert 172 Sekunden. Die Volltextsuche hat jedoch eine eigene optimierte Struktur, die sofort Links zu allen erforderlichen Einträgen zurückgibt.
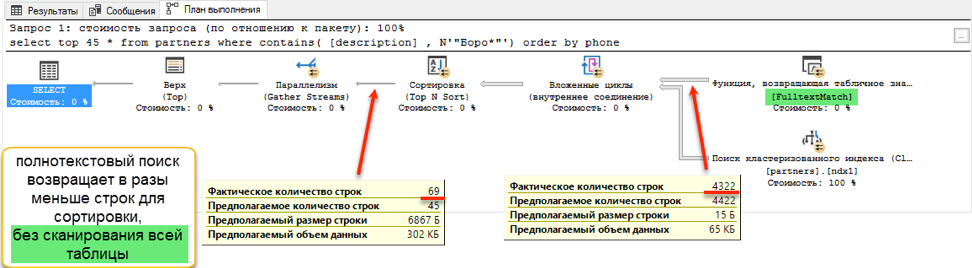
Aber sollte es eine Fliege in der Salbe geben? Da ist einer. Wie eingangs erwähnt, kann eine Volltextsuche nur am Anfang eines Wortes suchen. Und wenn wir "Ivan Poddubny" durch den Teilstring "* oak *" finden wollen, zeigt eine Volltextsuche nichts Nützliches.
Glücklicherweise ist die Suche nach Namen nicht das beliebteste Szenario.
Suchen Sie nach einem Dokument nach Nummer
Versuchen wir etwas komplizierteres. Der zweite beliebte Anwendungsfall für die Suche besteht darin, ein Dokument anhand eines Teils seiner Nummer zu finden. Darüber hinaus besteht die Dokumentennummer häufig aus zwei Teilen: dem Buchstabenpräfix und der tatsächlichen Nummer, die führende Nullen enthält.
Zwischen diesen Teilen befinden sich keine Leerzeichen oder Servicezeichen. Gleichzeitig ist die Suche nach der vollständigen Zahl ungeheuer unpraktisch - Sie müssen sich daran erinnern, wie viele führende Nullen nach dem Präfix vor dem Beginn des signifikanten Teils stehen sollten. Es stellt sich heraus, dass die Volltextsuche "out of the box" in einem solchen Szenario einfach nutzlos ist. Versuchen wir es zu beheben.
Für den Test habe ich eine neue Tabelle mit dem Namen document erstellt, in der ich 13,5 Millionen Datensätze mit eindeutigen Nummern vom Typ „ORG“ hinzugefügt habe. Die Nummerierung ging in Ordnung, alle Nummern begannen mit "ORG". Du kannst anfangen.
Eine Nummer vorab teilen
Die Volltextsuche kann effizient nach Wörtern suchen. Nun, helfen wir ihm und teilen die „unangenehme“ Zahl im Voraus in bequeme Wörter auf. Der Aktionsplan lautet wie folgt:
- Fügen Sie der Quelltabelle eine zusätzliche Spalte hinzu, in der die speziell konvertierte Nummer gespeichert wird
- Fügen Sie einen Auslöser hinzu, der beim Ändern der Nummer in mehrere kleine Teile unterteilt wird, die durch ein Leerzeichen getrennt sind
- Die Volltextsuche weiß bereits, wie man eine Zeichenfolge durch Leerzeichen in Teile aufteilt, damit unsere geänderte Nummer problemlos indiziert wird
Mal sehen, wie das funktioniert.
Fügen Sie der Tabelle eine zusätzliche Spalte hinzu.
alter table document add number_parts nvarchar(128) not null default ''
Ein Trigger, der eine neue Spalte füllt, kann als „Stirn“ geschrieben werden, wobei mögliche Duplikate ignoriert werden (wie viele sich wiederholende Tripel enthält die Zahl „0000012“?). Außerdem können Sie XML-Magie hinzufügen und nur eindeutige Teile aufzeichnen. Die erste Implementierung ist schneller, die zweite liefert ein kompakteres Ergebnis. In der Tat ist die Wahl zwischen Schreibgeschwindigkeit und Lesegeschwindigkeit, wählen Sie, was in Ihrer Situation wichtiger ist. Gehen Sie jetzt einfach ein
Skript durch , das vorhandene Zahlen verarbeitet.
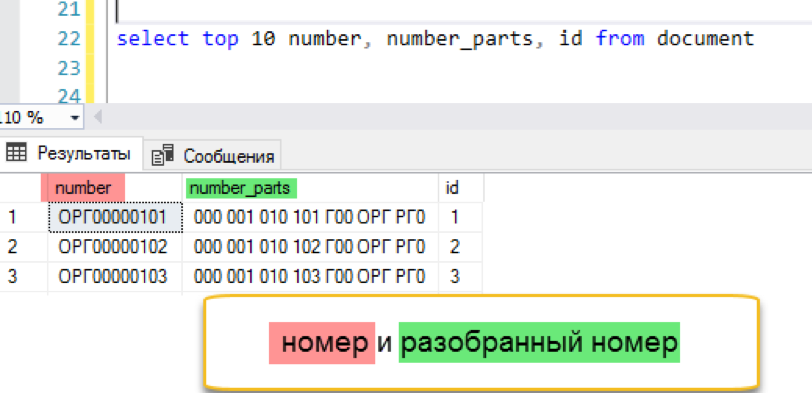
Volltextindex hinzufügen
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
Und überprüfen Sie das Ergebnis. Das Experiment ist das gleiche - Modellierung einer „Fenster“ -Auswahl aus einer Liste von Dokumenten. Wir wiederholen die vorherigen Fehler nicht und führen die Anforderung sofort mit Sortierung aus, in diesem Fall nach Datum.
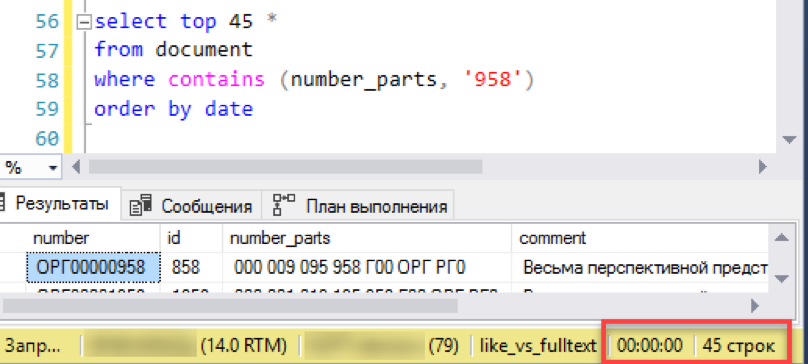
Es funktioniert! Versuchen wir nun eine authentischere Nummer:
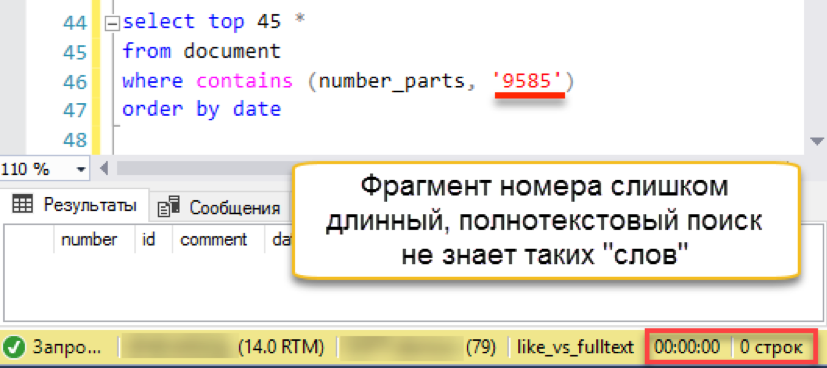
Und dann passiert eine Fehlzündung. Die Länge der Suchzeichenfolge ist länger als die Länge der gespeicherten "Wörter". Tatsächlich enthält die Suchdatenbank einfach keine einzige Zeile mit 4 Zeichen, sodass ehrlich gesagt ein leeres Ergebnis zurückgegeben wird. Wir müssen den Suchstring in Teile zerlegen:
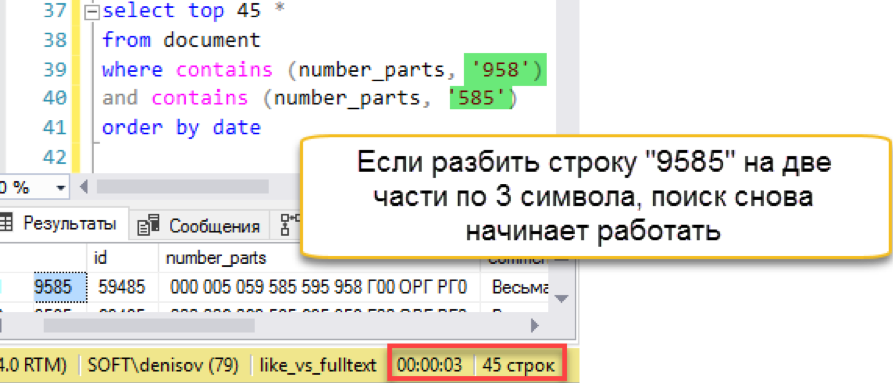
Eine andere Sache! Wir haben wieder eine schnelle Suche. Ja, er erlegt der Wartung seinen Overhead auf, aber das Ergebnis ist hunderte Male schneller als die klassische Suche. Wir notieren den gezählten Versuch, versuchen aber, die Wartung irgendwie zu vereinfachen - im nächsten Abschnitt.
Wir werden es auf unsere eigene Weise in Worte fassen!
Wer hat gesagt, dass Wörter durch Leerzeichen getrennt werden sollen? Vielleicht möchte ich Nullen zwischen Wörtern! (und, wenn möglich, das Präfix, damit es auch irgendwie ignoriert wird und nicht unter den Füßen stört). Im Allgemeinen ist daran nichts unmöglich. Erinnern wir uns an das Volltextsuchschema vom Anfang des Artikels - eine separate Komponente, Wordbreaker, ist für das Aufteilen in Wörter verantwortlich, und glücklicherweise können Sie mit Microsoft Ihren eigenen „Word Breaker“ implementieren.
Und hier beginnt das Interessante. Wordbreaker ist eine separate DLL, die eine Verbindung zur Volltextsuchmaschine herstellt. Die
offizielle Dokumentation besagt, dass das Erstellen dieser Bibliothek sehr einfach ist - implementieren Sie einfach die IWordBreaker-Schnittstelle. Und hier sind einige kurze Initialisierungslisten in C ++. Sehr erfolgreich habe ich gerade ein passendes Tutorial gefunden!

(
Quelle )
Im Ernst, die Dokumentation zum Erstellen eines eigenen Worbreakers im Internet ist verschwindend klein. Noch weniger Beispiele und Vorlagen. Aber ich habe immer noch
ein Projekt einer freundlichen Person gefunden, das eine C ++ - Implementierung geschrieben hat, die Wörter nicht in Trennzeichen, sondern einfach in Dreiergruppen aufteilt (ja, genau wie im vorherigen Abschnitt!). Außerdem enthält der Projektordner bereits eine sorgfältig kompilierte Binärdatei, die Sie nur benötigen Verbindung zur Suchmaschine herstellen.
Einfach einstecken ... Eigentlich nicht ganz einfach. Gehen wir die Schritte durch:
Sie müssen die Bibliothek mit SQL Server in den Ordner kopieren:

Registrieren Sie eine neue „Sprache“ in der Volltextsuche
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
Bearbeiten Sie mehrere Schlüssel in der Registrierung manuell (der Autor wollte den Prozess automatisieren, aber seit 2016 gibt es keine Neuigkeiten mehr. Dies war jedoch ursprünglich ein „Implementierungsbeispiel“, danke auch dafür).
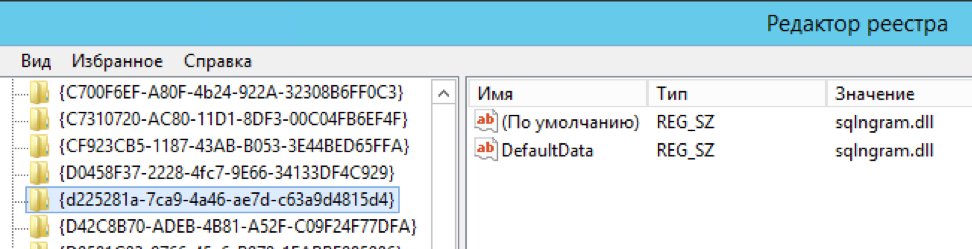
Die Schritte werden auf der Projektseite ausführlich beschrieben.
Fertig. Löschen wir den alten Volltextindex, da es nicht zwei Volltextindizes für eine Tabelle geben kann. Erstellen Sie eine neue und indizieren Sie unsere Dokumentennummern. Als Schlüsselspalte geben wir die Zahlen selbst an. Es werden keine Ersatzspalten mehr benötigt. Stellen Sie sicher, dass Sie "Sprachnummer 1" angeben, um den frisch installierten Wordbreaker zu verwenden.
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
Überprüfen?
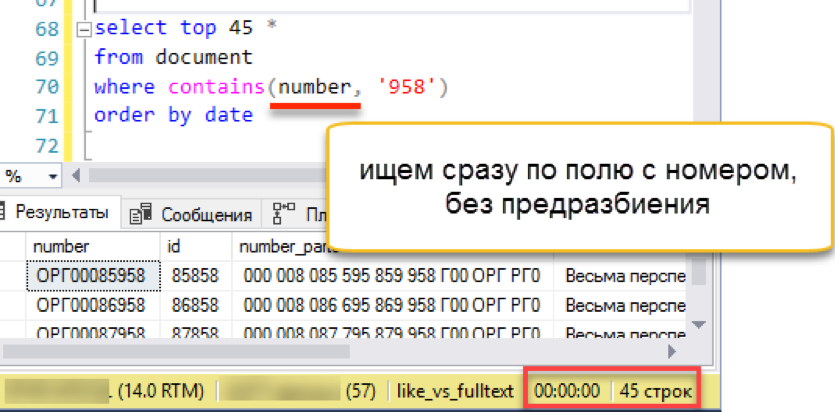
Es funktioniert! Es funktioniert so schnell wie alle oben diskutierten Beispiele.
Lassen Sie uns die lange Zeile überprüfen, auf die die vorherige Option gestoßen ist:
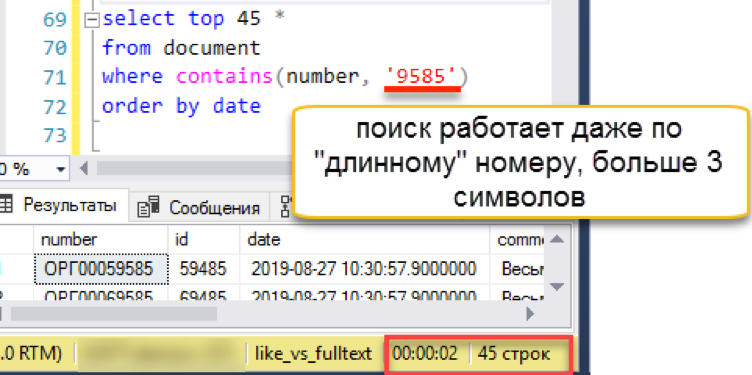
Die Suche funktioniert für den Benutzer und den Programmierer transparent. Wordbreaker zerlegt die Suchzeichenfolge unabhängig voneinander in Teile und findet das gewünschte Ergebnis.
Es stellt sich heraus, dass wir jetzt keine zusätzlichen Spalten und Trigger benötigen, dh die Lösung ist einfacher (sprich: zuverlässiger) als unser vorheriger Versuch. In Bezug auf die Unterstützung ist eine solche Implementierung einfacher und transparenter, es besteht eine geringere Wahrscheinlichkeit von Fehlern.
Also, hör auf, ich sagte "zuverlässiger"? Wir haben gerade eine Bibliothek eines Drittanbieters mit unserem DBMS verbunden! Und was passiert, wenn sie fällt? Auch versehentlich zieht sich der gesamte Datenbankdienst heraus!
Hier müssen Sie sich daran erinnern, wie ich am Anfang des Artikels den Volltextsuchdienst erwähnt habe, der vom Haupt-DBMS-Prozess getrennt ist. Hier wird klar, warum dies wichtig ist. Die Bibliothek stellt eine Verbindung zum Volltext-Indizierungsdienst her, der mit reduzierten Rechten betrieben werden kann. Und was noch wichtiger ist: Wenn Komponenten von Drittanbietern ausfallen, fällt nur der Indexdienst. Die Suche wird für eine Weile angehalten (ist jedoch bereits asynchron), und das Datenbankmodul funktioniert weiterhin so, als wäre nichts passiert.
Zusammenfassend. Das Hinzufügen eines eigenen Wortbrechers kann eine ziemliche Herausforderung sein. Wenn Sie jedoch "auf lange Sicht" spielen, zahlen sich diese Bemühungen mit größerer Flexibilität und einfacher Wartung aus. Die Wahl liegt wie immer bei Ihnen.
Warum ist das alles notwendig?
Ein neugieriger Leser hat sich wahrscheinlich mehr als einmal gefragt: "Das alles ist großartig, aber wie kann ich diese Funktionen verwenden, wenn ich die Suchanfragen in meiner Anwendung nicht ändern kann?" Vernünftige Frage. Die Einbeziehung der Volltext-MS SQL-Suche erfordert eine Änderung der Syntax der Abfragen. In der vorhandenen Architektur ist dies häufig einfach nicht möglich.
Sie können versuchen, die Anwendung auszutricksen, indem Sie eine gleichnamige Tabellenwertfunktion anstelle einer regulären Tabelle „verschieben“, wodurch die Suche bereits wie gewünscht ausgeführt wird. Sie können versuchen, die Suche als eine Art externe Datenquelle zu binden. Es gibt eine andere Lösung - Softpoint Data Cluster - einen speziellen Dienst, der eine "Weiterleitung" zwischen der Quellanwendung und dem SQL Server-Dienst installiert, auf Datenverkehr wartet und Anforderungen "on the fly" nach speziellen Regeln ändern kann. Mit diesen Regeln können wir mit LIKE regelmäßige Abfragen finden und diese mit Volltextsuche in CONTAINS konvertieren.
Warum solche Schwierigkeiten? Trotzdem ist die Suchgeschwindigkeit faszinierend. In einem stark ausgelasteten System, in dem Bediener häufig in Millionen von Tabellen nach Datensätzen suchen, ist die Antwortgeschwindigkeit von entscheidender Bedeutung. Das Sparen von Zeit beim häufigsten Betrieb führt zu Dutzenden von zusätzlich verarbeiteten Anwendungen, und dies ist echtes Geld, mit dem jedes Unternehmen zufrieden ist. Am Ende zahlen sich einige Tage oder sogar Wochen für das Studium und die Implementierung der Technologie mit einer höheren Bedienereffizienz aus.
Alle im Artikel erwähnten Skripte sind im Repository
github.com/frrrost/mssql_fulltext verfügbar
Über den Autor
 Alexander Denisov
Alexander Denisov - MS SQL Server-Datenbankleistungsanalyst. In den letzten 6 Jahren habe ich als Teil des Softpoint-Teams dazu beigetragen, Engpässe bei den Anfragen anderer zu finden und das Beste aus den Kundendatenbanken herauszuholen.