Mikhail Konovalov, Leiter der Supportabteilung für Integrationsprojekte, ICD IT-DirektionGuten Tag, Chabrowiten!
Zweck
Ein systematischer Ansatz zur Verwaltung von Downloads. Wir möchten Ihnen zeigen, wie Sie das Füllen des Repositorys mit Informationen optimieren und automatisieren und gleichzeitig nicht in den Flüssen aus verschiedenen Quellen verwechselt werden können.
Präambel
Früher oder später taucht in der Unternehmensdatenbank eines Unternehmens ein Moment auf, in dem das Auge des Architekten die Unsicherheit (das Chaos) des Systems nicht mehr erfasst und sich in eine unkontrollierbare Masse aller Arten von Downloads aus verschiedenen Quellen verwandelt.
Sie haben Glück, wenn Ihr System von Grund auf neu entwickelt wurde (ab der ersten Tabelle) und von einem Architekten, einem Team von Entwicklern und Analysten betrieben wurde. Außerdem leitete dieser Architekt das Data-Warehouse-Modell kompetent. Aber das Leben ist vielfältig, in den meisten Fällen wächst DWH spontan, zuerst gab es 30 Tische, dann haben wir nach Bedarf etwas mehr hinzugefügt, und dann hat es uns gefallen und wir haben begonnen, für jede Gelegenheit etwas hinzuzufügen, und jetzt haben wir mehr als fünftausend, ja Schichten, Inszenierungen und Vitrinen erschienen immer noch. Und all dieses „Glück“ fiel auf uns als Ergebnis eines, aber sehr bequemen Prozesses, der ein harter Kausalzusammenhang ist:
- Das Unternehmen sagt: „Wir brauchen solche und solche Daten. Benötigen Sie einen neuen Bericht »
- Der Analyst sucht
- Entwickler implementiert
- Der Architekt koordiniert und trägt zum Datenmodell bei
Aber in der Regel existiert der letzte Punkt in der Realität nicht. Und es tritt nur zu einem bestimmten Zeitpunkt in großen Unternehmen auf, die zu ihrem DWH herangewachsen sind, wo ein ordentlicher Architekt die Integrität der Informationen in der Datenbank kompetent verwaltet. Solche Repositorys sind eine Überprüfung der vorherigen Struktur, die mit Blick auf die vorherige (nicht dokumentierte) Version neu dokumentiert und häufig neu erstellt wurde.
Also eine kurze Zusammenfassung:- Es gibt kein DWH, das sofort geboren wurde und zuvor keine reguläre Datenbank mit einer Reihe von Tabellen darstellte.
- Alles, was jetzt existiert und eine klar algorithmisierte und dokumentierte Struktur ist, wurde als Ergebnis „bitterer Erfahrung“ aus früheren Entwicklungen erhalten.
Wenn Sie der glückliche Besitzer des „richtigen“ DWH sind oder Teil des Teams dieses glücklichen Besitzers sind, scheint Ihnen dieser Artikel „theoretisch“ interessant zu sein. Und wenn Sie nur eine Überprüfung durchführen oder (Ihnen verbieten) neu erstellen müssen, kann dieser Artikel Ihr Leben erheblich vereinfachen.
Da es eine unvorstellbare Menge an Informationsquellen geben kann, gibt es mindestens die gleiche Anzahl von Download- und Überlastungsströmen verschiedener Objekte und oft noch viel mehr, da jedes Datenbankobjekt mehr als eine Transformation durchlaufen kann, bevor seine Daten vom Endbenutzer zum Erstellen verwendet werden können Geschäftsberichte. Aber es ist für ihn, geschäftlich und nicht zu seinem eigenen Vergnügen, dass dieses gesamte Ökosystem für die „Transfusion von Schiff zu Schiff“ gebaut wurde.
Oracle wird als Datenbank unseres Speichers verwendet. In der Erstellungsphase bestand der zentrale Kern unserer Datenbank aus mehreren hundert Tabellen. Wir haben nicht an Inszenierungen und Schaufenster gedacht. Aber wie sie sagen, "alles fließt, alles ändert sich", und jetzt sind wir gewachsen! Das Unternehmen schreibt neue Anforderungen vor, und die Integration in verschiedene MS SQL-, SyBASE-, Vertica- und Access-Datenbanken ist bereits erschienen. Von dort, wo keine Informationen zu uns fließen, sind auch exotische Daten wie XML- und JSON-Austausch mit Systemen von Drittanbietern aufgetreten, und die XLS-Datei als Informationsquelle ist vollständig anachronistisch.
Das Leben hat uns dazu gebracht, die Überprüfung zu durchlaufen und das Datenmodell zu aktualisieren, zu pflegen und zu pflegen. Hier ist einer der Teile des Hauptkerns:
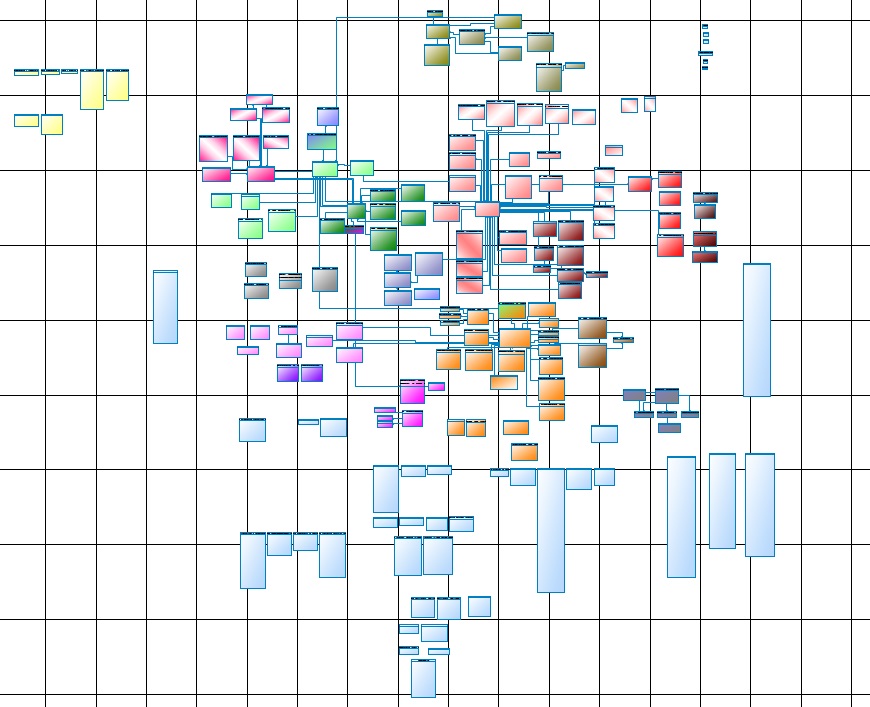 Abb. 1
Abb. 1Für wen es ist, aber für mich - es ist nur auf einem Whatman-Papier lesbar, und A0 wird ein wenig klein sein, besser als 4A0, auf dem Bildschirm ist es für das Auge oder die Vorstellungskraft unmöglich.
Denken Sie nun daran, dass dies nur der Kern (Core Data Layer) oder vielmehr sein Hauptteil ist. Der vollständige Kern besteht aus mehreren Subsystemen, die dem Hauptteil nicht viel unterlegen sind. Dazu
kommen auch die primäre Datenschicht und die
Data Mart-Schicht . Darüber hinaus erhält die primäre Schicht ihre Informationen aus Datenquellen, und dies, wie oben erwähnt, aus verschiedenen Datenbanken und Dateien. Auf der anderen Seite werden vom Verbraucher verschiedene Berichtssysteme mit der Ebene der Schaufenster verbunden.
Als in PL / SQL nur wenige Datenbanktabellen und Ladealgorithmen implementiert waren, gab es zunächst keine besonderen Schwierigkeiten beim Verständnis von Datenaktualisierungen. Mit dem Aufstieg von DWH war es jedoch eine strategische Entscheidung, Informatica PowerCenter zu kaufen. Mit dem Komfort dieses Tools, sowohl hinsichtlich der Zuverlässigkeit des Ladens als auch der Visualisierung der Entwicklung, weist dieses Tool mehrere Nachteile auf. Die folgende Abbildung zeigt ein Modell für die Startsequenz zum Laden eines DWH.
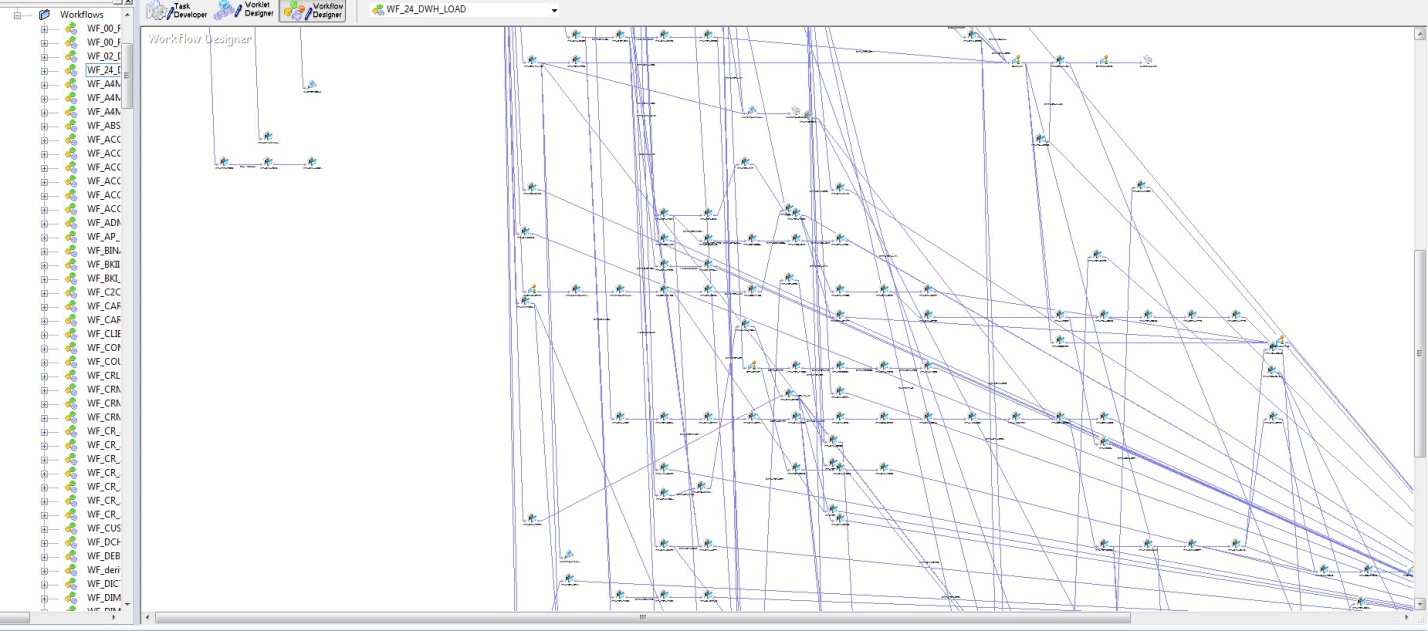 Abb. 2
Abb. 2Der wichtigste Nachteil ist die Subjektivität, oder vielmehr kann nur der Architekt garantieren, dass die Buchungen nicht vor den Rechnungen geladen werden. Leider nimmt mit dem Wachstum von DWH auch die Entropie von Informationen zu. Unter Berücksichtigung des physikalischen Datenmodells (Abb. 1) und der Logik zum Laden dieser Daten (Abb. 2) wird die Konstruktion weiterhin erhalten.
Was zu tun ist und wie es zu steuern ist, fragen Sie. Natürlich: einen brillanten Architekten zu haben, der alle Zusammenhänge dieser Feinheiten verstehen kann. Dadurch werden alle Flows überwacht, neue Flows koordiniert und verhindert, dass die Buchungstabelle früher als die Kontotabelle geladen wird. Natürlich wird all dies in die Algorithmen eingenäht und durch Download-Cutoffs reguliert, aber zunächst kann nur ein Architekt die Downloads verstehen und auf eine strenge Reihenfolge einstellen, und bei einer solchen Verzweigung ist die Wahrscheinlichkeit von Fehlern sehr hoch.
Theorie
Jetzt werde ich versuchen, die Hauptideen des Datenmodellwörterbuchs sowie die zu lösenden Aufgaben anzugeben.
Da sich die Daten im Speicher in Tabellen befinden und die Datenquellen teilweise Tabellen und teilweise Ansichten sind, sind letztere selbst Tabellen. Dann folgt eine einfache Idee - eine
TABLE-TABLE- Abhängigkeitsstruktur zu erstellen. Die
3NF- Form ist dafür perfekt geeignet.
Erstens, wenn wir die DWH-Entitätsdaten füllen, nennen wir sie
(Ziel) , im allgemeinsten Fall kann sie als
Auswahl aus verschiedenen Tabellen dargestellt werden. Ob es sich um Oracle-Tabellen, SyBase, MSSQL, XLS-Dateien oder etwas anderes handelt, es ist nicht so wichtig, all dies nennen wir ihre Quellen
(Quelle) . Das heißt, wir haben eine
Quelle , die ins
Ziel fließt.
Zweitens hat jede DWH-Entität Verweise aufeinander.
Drittens gibt es eine Chronologie zum Starten von Downloads verschiedener DWH-Entitäten.
Es bleibt der Fall für kleine, umzusetzen - wie? Es scheint sehr einfach zu sein, dass der Architekt von der Grundlage Ihres DWH aus, wenn die nächste Tabelle der Entität
(Ziel) angezeigt wird, die Empfängerentität und alle Entitäten, die als Quellen dienen, betrachten und in das Wörterbuch aufnehmen muss. Geben Sie außerdem in der zweiten Tabelle des Wörterbuchs die Verknüpfungen zwischen diesen Entitätsquellen in select sowie alle untergeordneten Tabellen an, auf die durch Referenzen verwiesen wird. Als Nächstes können Sie das Laden dieser Entität in die Speicher-Download-Kette einbetten. Nur zwei Tabellen - und die Möglichkeit, die Reihenfolge des Füllens der Daten mit dem Algorithmus im Algorithmus zu berücksichtigen, ist gelöst.
Das Wörterbuchdatenmodell löst die folgenden Probleme:
- Abhängigkeiten anzeigen. Sie können sehen, aus welchen Daten sie stammen. Dies ist praktisch für Analysten, die immer von Fragen gequält werden: "Wo, was liegt und woher kommt alles?" Präsentieren Sie dies in der Anwendung in Form eines Baums, sowohl von Quelle zu Ziel als auch umgekehrt: von Ziel zu Quelle .
- Bruch von Schleifen. Wenn Sie die nächste Ladung in einen bereits funktionierenden gemeinsam genutzten Stream einbetten, ohne über ein Datenmodellwörterbuch zu verfügen, können Sie durchaus einen Fehler machen und eine Startzeit für das Laden des nächsten Ziels vor einer seiner Quellen zuweisen. Dies erzeugt eine Schleife. Ein Datenmodellwörterbuch wird dies leicht vermeiden.
- Sie können einen Algorithmus zum Füllen des Speichers basierend auf dem Modellwörterbuch schreiben. In diesem Fall muss der nächste Download nirgendwo eingebettet werden. Geben Sie ihn einfach in das Wörterbuch ein, und der Algorithmus bestimmt seinen Platz. Es bleibt noch auf die begehrte Schaltfläche "Make ALL" zu klicken. Der Bootloader startet Lawinen-ähnliche Downloads aller Speichereinheiten - von einfach (unabhängig) bis komplex (abhängig).
Implementierung
Theoretisch ist immer alles einfach und schön, in der Praxis sieht es etwas anders aus. Was im vorherigen Abschnitt geschrieben wurde, ist eine ideale Situation, als sich DWH von Grund auf neu entwickelte, als ein Architekt untrennbar damit verbunden war. Wenn Sie kein Glück haben, haben Sie das alles sicher bestanden, es gibt keinen Architekten, aber es gibt eine riesige Reihe von Tischen, und trotzdem gibt es einen Ausweg.
In der Tat werde ich Ihnen jetzt sagen, wie wir es geschafft haben, die Überprüfung und den Wiederaufbau billig genug nachzuholen. Unser DWH begann sich mit einer Führungsentscheidung über einen bevorstehenden Bedarf (DWH) zu entwickeln. Als Tool wurde zuerst PL / SQL verwendet. Wenig später wechselte er zu Informatica. Die Priorität war natürlich der Zeitpunkt der Schöpfung. Das Datenmodell in PowerDesigner erschien einige Zeit später, als das Vertrauen klar wurde, dass sich niemand ein vollständiges und klares Bild von DWH vorstellen konnte. Wir haben einige Zeit mit dem Modell an der Wand gelebt. Als klar wurde, dass wir mit der Verwaltung dieses gesamten Systems nicht fertig werden konnten, suchten wir nach einer Lösung, die ich hier kurz beschreiben möchte.
Das Datenmodellwörterbuch selbst ist so einfach wie ein Stick. Aber das Auffüllen ist ein Problem. N Monate sorgfältiger und vor allem sorgfältiger Prüfung der drei oben genannten Teile:
- Aus welchen Quellen (Quelle) besteht jede Entität des Repositorys (Ziels)?
- Welche Beziehungen bestehen zwischen Speicherobjekten (Referenzen)?
- die Chronologie des Starts der Downloads und des Füllens des Repositorys.
Glücklicherweise haben Oracle und Informatica uns geholfen, und es stellte sich als sehr erfolgreich heraus, dass sich das Informatica-Repository in der Oracle-Datenbank befindet. Auf der Grundlage, dass eine Informatica-Sitzung das Ladeatom einer DWH-Entität ist und ein wenig im Repository gräbt, haben wir alle Quellen und Ziele gefunden. Das heißt, im Rahmen einer Sitzung sind für alle Ziele (in der Regel eine) alle Quellen Quellen. Somit können wir die erste Bedingung des Problems ausfüllen. Aber beeilen Sie sich nicht, sich zu freuen, die Quelle kann in Form einer sehr cleveren Auswahl dargestellt werden. Sie mussten also einen Parser schreiben, der alle in select angegebenen Tabellen herausholt - es war überhaupt nicht schwierig. Dies ist jedoch noch nicht alles. Diese Tabellen selbst können tatsächlich Darstellungen sein. Mit DBA_VIEWS (oder über DBA_DEPENDENCIES) wurde dieses Problem ebenfalls behoben. Wir haben die zweite Bedingung dieser Trilogie aus dem Datenmodell (Abb. 1) und DBA_CONSTRAINTS gezogen. Wir haben auch die dritte Bedingung aus dem Informatica-Repository basierend auf (Abb. 2) erhalten.
Was ist aus all dem geworden?- Erstens haben wir alle Schleifen entwirrt, die wir in der Entwicklung unseres DWH gewickelt haben.
- Zweitens haben wir einen wunderbaren Baum für Analysten:

Abb. 3 - Drittens unser Superloader, dargestellt in Abb. 2 wurde elegant (sorry, Kollegen, aber die Unschärfe des Bildes ist beabsichtigt, da es sich um Arbeitsdaten handelt):
Abb. 4
Möglicherweise haben Sie noch viele weitere Möglichkeiten, das Datenmodellwörterbuch anzuwenden.
Danke an alle!