pprof ist das Hauptprofilierungswerkzeug in Go. Der Profiler ist in der Go-Standardbibliothek enthalten, und im Laufe der Jahre wurde viel darüber geschrieben. Um pprof mit einer vorhandenen Anwendung zu verbinden, müssen Sie nur eine Codezeile hinzufügen:
import _ “net/http/pprof”
Im Standard-HTTP-Server - net/http.DefaultServeMux - werden Handler, die Profilerstellungsergebnisse senden, unter dem Pfad /debug/pprof/ .
curl -o cpu-profile.pb.gz http://<server-addr>/debug/pprof/profile
(Weitere Informationen finden Sie unter https://godoc.org/net/http/pprof )
Aber aus Erfahrung ist es nicht immer so einfach und in der Praxis gibt es Fallstricke, wenn man pprof im Kampf einsetzt.
Zunächst möchten wir nicht, dass die Profiler-Handler im Internet herausragen. Die Profilerstellung ist in Bezug auf den Overhead billig, aber nicht kostenlos, und das Profil selbst enthält Informationen über die interne Struktur der Anwendung, die für Außenstehende häufig nicht ratsam sind. Sie müssen sicherstellen, dass der Pfad /debug nicht für nicht autorisierte Benutzer zugänglich ist. Der Zugriff kann auf der Seite des Proxyservers eingeschränkt werden, oder der pprof-Server kann an einen separaten Port verschoben werden, auf den nur über den privilegierten Host zugegriffen werden kann.
Was aber, wenn die Anwendung überhaupt keinen HTTP-Zugriff beinhaltet - ist es beispielsweise ein Offline-Warteschlangenprozessor?
Je nach Zustand der Infrastruktur im Unternehmen kann ein „plötzlicher“ HTTP-Server innerhalb des Anwendungsprozesses Fragen der Betriebsabteilung aufwerfen;) Der Server schränkt zusätzlich die Möglichkeiten der horizontalen Skalierung ein, weil Es funktioniert nicht nur, um mehrere Instanzen der Anwendung auf demselben Host auszuführen. Die Prozesse stehen in Konflikt und versuchen, denselben TCP-Port für den pprof-Server zu öffnen.
Es ist „einfach“ zu lösen, indem jeder Anwendungsprozess im Container isoliert wird (oder der pprof-Server an einem eindeutigen Port oder UNIX-Socket ausgeführt wird). Sie werden niemanden mehr mit einem Service überraschen, der horizontal in Hunderte von Instanzen skaliert und auf mehrere Rechenzentren verteilt ist. In einer sehr dynamischen Infrastruktur können Container mit der Anwendung regelmäßig angezeigt und ausgeblendet werden. Und wir müssen uns trotzdem irgendwie an den Profiler wenden. Dies bedeutet, dass unabhängig von der ausgewählten Skalierungsmethode Suchmechanismen für eine bestimmte Anwendungsinstanz und den entsprechenden pprof-Server-Port benötigt werden.
Abhängig von den Merkmalen des Unternehmens kann das Vorhandensein der Fähigkeit, auf etwas zuzugreifen, das nicht mit der Hauptproduktionstätigkeit des Dienstes zusammenhängt, Fragen der Sicherheitsabteilung aufwerfen;) Ich habe in einem Unternehmen gearbeitet, in dem aus objektiven Gründen der Zugang zu irgendetwas nebenbei ist Die Produktion erfolgte ausschließlich in der Betriebsabteilung. Die einzige Möglichkeit, den Profiler in einer laufenden Anwendung auszuführen, bestand darin, eine Aufgabe im Operations Bug Tracker zu öffnen, in der beschrieben wurde, welcher Curl-Befehl, in welchem DC, auf welchem Server Sie ausgeführt werden sollen, welches Ergebnis zu erwarten ist und was damit zu tun ist.
Oder stellen Sie sich eine Situation vor: einen Arbeitsmorgen. Sie haben Slack geöffnet und festgestellt, dass am Abend in einem der Produktionsserviceprozesse „etwas schief gelaufen ist“, „irgendwo etwas heruntergefahren wurde“, „Speicher zu fließen begann“, „CPU-Grafiken hochgekrochen“ oder Die App geriet gerade in Panik. Die diensthabenden Betriebsteams (oder OOM Killer) haben nicht tief gegraben und einfach die Anwendung neu gestartet oder die neueste Version des Vortages zurückgesetzt.
Im Nachhinein ist es nicht einfach, solche Situationen zu verstehen. Es ist großartig, wenn das Problem in einer Testumgebung (oder in einem isolierten Teil der Produktion, auf den Sie Zugriff haben) reproduziert werden kann. Sie können die erforderlichen Daten mit allen verfügbaren Tools erfassen und dann herausfinden, um welche Komponente es sich handelt.
Wenn es jedoch keinen offensichtlichen Weg gibt, das Problem zu reproduzieren, bleiben uns dann nur die Protokolle und Metriken von gestern? In solchen Situationen ist es immer eine Schande, dass Sie die Zeit nicht bis zu dem Zeitpunkt zurückspulen können, an dem das Problem in der Produktion sichtbar war, und schnell alle erforderlichen Profile erfassen können, um später in einem ruhigen Modus eine Analyse durchzuführen.
Wenn pprof jedoch relativ günstig ist, können Sie Profildaten in bestimmten Abständen automatisch erfassen und an einem von der Produktion getrennten Ort speichern, an dem Sie allen Interessierten Zugriff gewähren können.
Im Jahr 2010 veröffentlichte Google das Dokument Google-Wide Profiling: Eine kontinuierliche Profiling-Infrastruktur für Rechenzentren , in dem ein Ansatz zur kontinuierlichen Profilerstellung von Unternehmenssystemen beschrieben wird. Und nach einigen Jahren startete das Unternehmen einen kontinuierlichen Profiling-Service - Stackdriver Profiler - der allen zur Verfügung steht.
Das Funktionsprinzip ist einfach: Anstelle eines pprof-Servers ist ein Stackdriver-Agent mit der Anwendung verbunden, der mithilfe der runtime/pprof API regelmäßig verschiedene Arten von Profilen aus der Anwendung sammelt und Profile an die Cloud sendet. Alles, was der Entwickler benötigt, wählen Sie über das Stackdriver-Bedienfeld die gewünschte Anwendungsinstanz in der gewünschten AZ aus, und Sie können die Anwendung nachträglich jederzeit in der Vergangenheit analysieren.
Andere SaaS-Anbieter bieten ähnliche Funktionen. Die Sicherheitsregeln Ihres Unternehmens können jedoch den Export von Daten über die eigene Infrastruktur hinaus verbieten. Und die Dienste, mit denen Sie ein kontinuierliches Profilierungssystem auf Ihren eigenen Servern bereitstellen können, habe ich nicht gesehen.
Alle oben beschriebenen Schwierigkeiten und Ideen sind nicht nur für Go alles andere als neu und spezifisch. Mit ihnen sind Entwickler in der einen oder anderen Form in fast allen Unternehmen konfrontiert, in denen ich gearbeitet habe.
Irgendwann war ich neugierig zu versuchen, ein Analogon des Stackdriver Profiler für einen beliebigen Go-Service zu erstellen, der die beschriebenen Probleme lösen könnte. Als Hobbyprojekt arbeite ich in meiner Freizeit an profefe ( https://github.com/profefe/profefe ) - einem offenen Dienst für die kontinuierliche Profilerstellung. Das Projekt befindet sich noch in der Phase von Experimenten und regelmäßigen Diskussionen, ist jedoch bereits zum Testen geeignet.
Die Aufgaben, die ich für das Projekt festgelegt habe:
- Der Service wird in der internen Infrastruktur des Unternehmens bereitgestellt.
- Der Service wird als internes Tool des Unternehmens verwendet. Sie können Lieferanten und Verbrauchern von Daten vertrauen: In einem frühen Stadium können Sie die Autorisierung von Schreib- / Leseanfragen weglassen und nicht versuchen, sich vor böswilliger Verwendung im Voraus zu schützen.
- Der Service sollte keine besonderen Erwartungen an die Infrastruktur des Unternehmens haben: Alles kann in der Cloud oder in seinen eigenen DCs leben. Profilanwendungen können in Containern ausgeführt werden ("alles wird von den Kubernetes gesteuert") oder auf Bare-Metal ausgeführt werden.
- Der Dienst sollte einfach zu bedienen sein (Prometheus scheint bis zu einem gewissen Grad ein gutes Beispiel zu sein).
- Es versteht sich, dass die ausgewählte Architektur möglicherweise nicht die Bedingungen erfüllt, unter denen der Dienst verwendet wird. Höchstwahrscheinlich benötigen Sie die Möglichkeit, Systemkomponenten zu erweitern / zu ersetzen, um sie "vor Ort" zu skalieren.
- In Übereinstimmung mit (4) müssen wir versuchen, die erforderlichen externen Abhängigkeiten zu minimieren. Zum Beispiel muss ein Dienst irgendwie nach Instanzen profilierter Anwendungen suchen, aber zumindest in der Anfangsphase möchte ich auf eine explizite Diensterkennung verzichten.
- Der Dienst speichert und katalogisiert Profile von Go-Anwendungen. Wir erwarten, dass eine pprof-Datei 100 KB - 2 MB belegt ( Heap-Profile sind normalerweise viel größer als CPU-Profile ). Von einer Profilinstanz aus macht es keinen Sinn, mehr als N Profile pro Minute zu senden (ein Stackdriver-Agent sendet durchschnittlich 2 Profile pro Minute). Es lohnt sich sofort zu berechnen, dass eine einzelne Anwendung mehrere bis mehrere hundert Instanzen haben kann.
- Über den Dienst suchen Benutzer für einen bestimmten Zeitraum nach verschiedenen Profiltypen (CPU, Heap, Mutex usw.) der Anwendung oder einer bestimmten Instanz der Anwendung.
- Vom Dienst fordert der Benutzer ein separates pprof-Profil aus den Suchergebnissen an.
Jetzt besteht profefe aus zwei Komponenten:
profefe-collector ist ein Service Collector mit einer einfachen RESTful-API.
Die Aufgabe des Sammlers besteht darin, die pprof-Datei und einige Metadaten abzurufen und im permanenten Speicher zu speichern. Die API ermöglicht es Kunden auch, Profile anhand von Metadaten in einem bestimmten Zeitfenster zu durchsuchen oder ein bestimmtes Profil (oder eine Gruppe von Profilen desselben Typs) aus dem Geschäft zu lesen.
agent - eine optionale Bibliothek, die anstelle des pprof-Servers mit der Anwendung verbunden werden sollte. Innerhalb der Anwendung startet der Agent in einer separaten Goroutine regelmäßig den Profilierungsprozess (unter Verwendung von runtime/pprof ) und sendet die empfangenen pprof-Profile zusammen mit den Metadaten an den Collector.
Metadaten sind beliebige Schlüsselwertsätze, die eine Anwendung oder ihre einzelne Instanz beschreiben. Beispiel: Dienstname, Version, Rechenzentrum und Host, auf dem die Anwendung ausgeführt wird.

Profefe-Komponenteninteraktionsdiagramm
Ich habe oben erwähnt, dass der Agent eine optionale Komponente ist. Wenn es nicht möglich ist, eine Verbindung zu einer vorhandenen Anwendung net/http/pprof , der net/http/pprof Server jedoch bereits in der Anwendung verbunden ist, können Profile mit externen Tools entfernt und pprof-Dateien über die HTTP-API an den Collector gesendet werden.
Auf Hosts können Sie beispielsweise eine Cron-Task konfigurieren, die regelmäßig Profile von laufenden Instanzen sammelt und zur Speicherung an profefe sendet;)
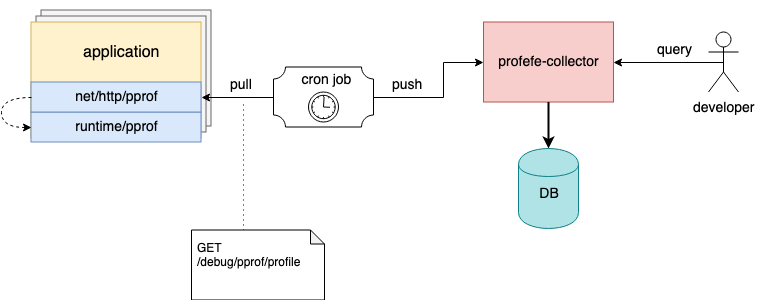
Die Cron-Aufgabe sammelt Anwendungsprofile und sendet sie an profefe collector
Weitere Informationen zur profefe API finden Sie in der Dokumentation zu GitHub .
Pläne
Bisher ist die HTTP-API die einzige Möglichkeit, mit dem profefe-Kollektor zu interagieren. Eine der Aufgaben für die Zukunft besteht darin, einen separaten UI-Dienst zusammenzustellen, über den die gespeicherten Daten visuell angezeigt werden können: Suchergebnisse, ein allgemeiner Überblick über die Clusterleistung usw.
Das Sammeln und Speichern von Profildaten ist nicht schlecht, aber "ohne Anwendung sind Daten nutzlos." Das Team, in dem ich arbeite, verfügt über eine Reihe von experimentellen Tools zum Sammeln grundlegender Statistiken für mehrere pprof-Profile aus dem Dienst. Dies hilft sehr bei der Analyse der Konsequenzen der Aktualisierung der wichtigsten Abhängigkeiten der Anwendung oder der Ergebnisse umfangreicher Umgestaltungen ( leider entspricht die Leistung in der Produktion nicht immer den Erwartungen, die auf der Einführung isolierter Benchmarks und der Profilerstellung in einer Testumgebung beruhen ). Ich möchte ähnliche Funktionen hinzufügen, um gespeicherte Profile in der profefe-API zu vergleichen und zu analysieren.
Trotz der Tatsache, dass das Hauptaugenmerk von profefe auf der kontinuierlichen Profilerstellung von Go-Diensten liegt, ist das pprof-Profilformat überhaupt nicht an Go gebunden. Für Java, JavaScript, Python usw. gibt es Bibliotheken, mit denen Sie Profildaten in diesem Format abrufen können. Vielleicht wird profefe ein nützlicher Dienst für Anwendungen, die in anderen Sprachen geschrieben sind.
Das Repository enthält unter anderem eine Reihe offener Fragen, die im Projekt-Tracker auf GitHub beschrieben sind .
Fazit
In den letzten Jahren hat sich unter Entwicklern eine beliebte Idee festgesetzt: Um die „ Beobachtbarkeit “ eines Dienstes zu erreichen, sind drei Komponenten erforderlich: Metriken, Protokolle und Ablaufverfolgung („ drei Säulen der Beobachtbarkeit “). Sichtbarkeit ist für mich die Fähigkeit, Fragen zum Zustand des Systems und seiner Komponenten effektiv zu beantworten. Metriken und Ablaufverfolgung ermöglichen es, das System als Ganzes zu verstehen. Protokolle decken die absichtlich beschriebenen Teile des Systems ab. Die Profilerstellung ist ein weiteres Signal, um Sichtbarkeit zu erreichen und das System auf Mikroebene zu verstehen. Die kontinuierliche Profilerstellung über einen bestimmten Zeitraum hinweg hilft auch zu verstehen, wie die einzelnen Komponenten und die Umgebung die Bedienbarkeit und Produktivität des gesamten Systems beeinflusst und beeinflusst haben.