Im letzten Jahr war ich oft genug mit der Notwendigkeit konfrontiert, Histogramme und Balkendiagramme zu zeichnen, um mich dazu zu bringen, darüber schreiben zu wollen. Außerdem fehlten mir selbst solche Informationen so ziemlich. Dieser Artikel bietet einen Überblick über drei Methoden zum Erstellen solcher Diagramme in Python.
Anfangs wusste ich selbst lange nicht von meiner Unerfahrenheit: Balkendiagramme und Histogramme sind verschiedene Dinge. Der Hauptunterschied besteht darin, dass das Histogramm die Häufigkeitsverteilung zeigt - wir geben eine Reihe von Werten für die Ox-Achse an, und die Häufigkeit wird immer auf Oy aufgezeichnet. Im Balkendiagramm (das in der englischen Literatur als Balkendiagramm bezeichnet werden sollte) geben wir sowohl die Abszissenachse als auch die Ordinatenachse an.
Zur Demonstration werde ich den Datensatz der geschlagenen Iris-Bibliothek verwenden. Beginnen wir mit Importen:
import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt from sklearn import datasets iris = datasets.load_iris()
Wir werden das Iris-Dataset in einen Datenrahmen umwandeln, damit wir in Zukunft bequemer damit arbeiten können.
data = pd.DataFrame(data= np.c_[iris['data'], iris['target']], columns= iris['feature_names'] + ['target'])
Von den Parametern, an denen wir interessiert sind, enthalten die Daten Informationen über die Länge der Kelchblätter und Blütenblätter und die Breite der Kelchblätter und Blütenblätter.
Matplotlib verwendenHistogrammLassen Sie uns ein regelmäßiges Histogramm erstellen, das die Häufigkeitsverteilung der Längen der Blütenblätter und Kelchblätter zeigt:
fig, axs = plt.subplots(1, 2) n_bins = len(data) axs[0].hist(data['sepal length (cm)'], bins=n_bins) axs[0].set_title('sepal length') axs[1].hist(data['petal length (cm)'], bins=n_bins) axs[1].set_title('petal length')
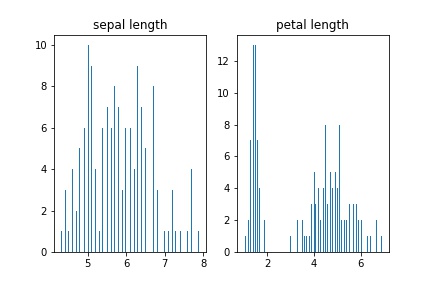 Erstellen eines Balkendiagramms
Erstellen eines BalkendiagrammsWir verwenden Matplotlib-Methoden, um die Breite von Blättern und Kelchblättern zu vergleichen. Dies scheint auf einem einzelnen Diagramm am bequemsten zu sein:
x = np.arange(len(data[:50])) width = 0.35
Nehmen Sie zum Beispiel und um das Bild zu vereinfachen, die ersten 50 Zeilen des Datenrahmens.
fig, ax = plt.subplots(figsize=(40,5)) rects1 = ax.bar(x - width/2, data['sepal width (cm)'][:50], width, label='sepal width') rects2 = ax.bar(x + width/2, data['petal width (cm)'][:50], width, label='petal width') ax.set_ylabel('cm') ax.set_xticks(x) ax.legend()
 Mit seegeborenen Methoden
Mit seegeborenen MethodenMeiner Meinung nach sind viele Aufgaben zum Erstellen von Histogrammen mit Seaborn-Methoden einfacher und effizienter durchzuführen
(außerdem gewinnt Seaborn meiner Meinung nach auch mit seinen grafischen Fähigkeiten) .
Ich werde ein Beispiel für Aufgaben geben, die in Seaborn mit einer einzigen Codezeile gelöst wurden. Besonders Seaborn ist ein Gewinner, wenn Sie eine Distribution aufbauen müssen. Nehmen wir an, wir müssen eine Kelchlängenverteilung erstellen. Die Lösung für dieses Problem lautet wie folgt:
sns_plot = sns.distplot(data['sepal width (cm)']) fig = sns_plot.get_figure()
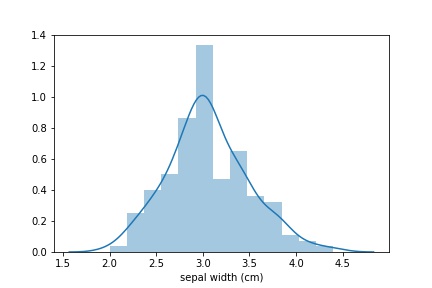
Wenn Sie nur einen Verteilungsplan benötigen, können Sie dies folgendermaßen tun:
snsplot = sns.kdeplot(data['sepal width (cm)'], shade=True) fig = snsplot.get_figure()
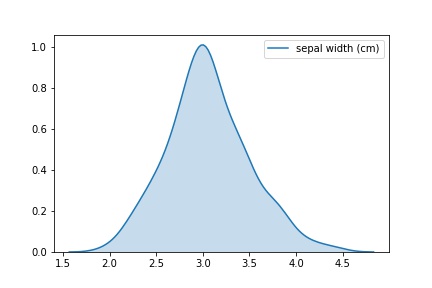
Lesen Sie hier mehr über Gebäudeverteilungen in Seaborn
.Pandas BalkendiagrammeHier ist alles einfach. Tatsächlich ist dies die Shell von matplotlib.pyplot.hist (), aber das Aufrufen einer Funktion über pd.hist () ist manchmal bequemer als die weniger agilen Konstruktionen von matplotlib-a.
Weitere Informationen finden Sie in der Dokumentation zur Pandas-Bibliothek.Es funktioniert so:
h = data['petal width (cm)'].hist() fig = h.get_figure()

Vielen Dank für das Lesen bis zum Ende! Ich freue mich über Bewertungen und Kommentare!