
Hallo Kollegen! Wie können die Hauptthemen von 20.000 Nachrichten in 30 Sekunden hervorgehoben werden? Überblick über die thematische Modellierung, die wir in TASS durchführen, mit Partnern und Code.
Die in diesem Hinweis enthaltenen Informationen sind zunächst Teil eines Prototyps, der im ITAR-TASS Digital Laboratory entwickelt wird, um die „Digitalisierung“ des Geschäfts zu unterstützen. Die Lösungen werden ständig verbessert, ich werde den aktuellen Abschnitt beschreiben, es wird natürlich nicht die Krone der Schöpfung sein, sondern eine Unterstützung für weitere Entwicklungen.
Große Idee
Neben der Nachrichtenagenda, an der die TASS-Redaktionen täglich arbeiten, ist es gut zu verstehen, welche Themen den Nachrichtenhintergrund in russischen Online-Medien am meisten schaffen. Zu diesem Zweck sammeln wir alle paar Minuten rund um die Uhr die neuesten Nachrichten von den 300 beliebtesten Websites. Dann kommt das Interessanteste - die Auswahl der Modellierungsmethoden und Experimente.
Wenn die magische Sitzung endet, werden meine Kollegen, Redakteure und Manager den Bericht mit Nachrichtenthemen verwenden. Ich glaube, dass für Leute außerhalb des Bereichs Softwareentwicklung und Datenwissenschaft die automatische Verarbeitung, Analyse und Visualisierung von Textdaten ein wenig magisch aussieht. Aufgrund der Entfremdung einer Person von der Hochtechnologie können verschiedene Unvollkommenheiten in ihrer Arbeit zu einem Mangel an Verständnis für das Innere und zu Enttäuschungen führen. Um die negative Reaktion zu minimieren, versuche ich, das Produkt einfacher und zuverlässiger zu machen. Das Verständnis der Essenz der thematischen Modellierung kann auf die Tatsache reduziert werden, dass Nachrichten, die sich auf ein Thema beziehen und sich von Nachrichten in einem anderen Thema unterscheiden, zu einem Thema gehören.
Ich experimentiere seit ungefähr einem Jahr mit thematischer Modellierung. Leider haben mir die meisten Ansätze, die ich ausprobiert habe, eine sehr zweifelhafte Qualität beim Füllen von Nachrichtenthemen verliehen. Gleichzeitig führte ich Aktionen gemäß der Logik der Auswahl von Parametern in Methoden aus gängigen Clustering-Bibliotheken durch. Ich habe aber keinen beschrifteten Datensatz. Daher schaue ich mir jedes Mal eine Auswahl von Texten an, die in ein bestimmtes Thema fallen. Der Fall ist eher trostlos und nicht dankbar.
Eine besondere Besonderheit dieser Aufgabe besteht darin, dass mehrere Spezialisten, die sich die im ausgewählten Thema enthaltenen Nachrichten ansehen, sie bis zu dem einen oder anderen Grad als unangemessen empfinden. Zum Beispiel können die Nachrichten mit Erdogans Aussage über den Beginn der Operation in Syrien und die Nachrichten mit den ersten Berichten nach Beginn der Operation in Syrien als ein oder mehrere Themen verstanden werden. Dementsprechend werden die Medien unter Berufung auf TASS oder eine andere Nachrichtenagentur eine Reihe von Texten über und über dies und das schreiben. Und das Ergebnis meines Algorithmus wird dazu neigen, sie zu kombinieren oder zu trennen, basierend auf ... dem Kosinus des Winkels zwischen den Wortfrequenzvektoren, der Anzahl der a priori akzeptierten oder dem Radius bei der Methode zum Finden der nächsten Nachbarn.
Im Allgemeinen ist diese ganze große Idee ebenso zerbrechlich wie schön.
Warum Faktoranalyse?
Ein genauerer Blick auf die Methoden zum Clustering von Texten zeigt, dass jede von ihnen auf einer Reihe von Annahmen basiert. Wenn die Annahmen nicht dem untersuchten Problem entsprechen, kann das Ergebnis stark zur Seite führen. Die Annahmen der Faktoranalyse scheinen mir - und vielen anderen Forschern - nahe an der Aufgabe zu liegen, Themen zu modellieren.
Dieser zu Beginn des 20. Jahrhunderts entwickelte Ansatz basierte auf der Idee, dass es neben den Variablen, die die Beobachtungen der Stichprobe charakterisieren, versteckte Faktoren gibt, die leicht informell mit einigen beobachtbaren Variablen korrelieren. Zum Beispiel werden die Antworten auf die Fragen „Glaubst du an Gott?“ Und „Gehst du in die Kirche?“ Eher zusammenfallen als sich unterscheiden. Es kann davon ausgegangen werden, dass es einen „Faktor der Religiosität“ gibt, der sich in einer Reihe miteinander verbundener Variablen manifestiert. Gleichzeitig besteht auch die Möglichkeit zu messen, wie stark die Variablen mit ihrem versteckten Faktor zusammenhängen.
Für Texte lautet die Problemstellung wie folgt. In den Nachrichten, die dasselbe Thema beschreiben, werden dieselben Wörter vorkommen. Zum Beispiel werden die Wörter "Syrien", "Erdogan", "Operation", "USA", "Verurteilung" häufiger zusammen in den Nachrichten gefunden, die sich mit dem Einsatz militärischer Interventionen in Syrien durch die Türkei und der damit verbundenen Reaktion der Vereinigten Staaten auf diese Angelegenheit befassen ( als geopolitischer Akteur auf demselben Gebiet).
Es bleibt für einen bestimmten Zeitraum, alle wichtigen Faktoren der Nachrichtenagenda herauszufischen. Dies werden Nachrichtenthemen sein. Aber das ist noch nicht alles ...
Ein bisschen Mathe
Für Leute, die Erfahrung mit Themenmodellierungstechniken haben, kann ich eine solche Aussage machen. Die Version der Faktoranalyse, die ich ausprobiert habe, ist eine stark vereinfachte Version der
ARTM-Methodik .
Aber ich habe mich entschlossen, mit Methoden zu experimentieren, bei denen es weniger Freiheitsgrade gibt, damit das, was im Inneren passiert, besser verstanden wird.
(Big) ARTM entstand aus pLSA, einer probabilistischen latenten semantischen Analyse, die wiederum eine Alternative zu LSA war, basierend auf einer singulären Matrixzerlegung - SVD.
Die Intelligenzfaktoranalyse geht weiter als die SVD, da sie eine „einfache Struktur“ der Beziehung zwischen Variablen und Faktoren liefert, was für die SVD möglicherweise keine einfache Angelegenheit ist, jedoch insofern begrenzt ist, als sie nicht darauf ausgelegt ist, Faktorwerte (Scores) genau zu berechnen Es gibt Vektoren von Faktorwerten, die zwei oder mehr beobachtbare Variablen ersetzen können.
Formal ist die Aufgabe der Intelligenzfaktoranalyse wie folgt:
Wo sind die beobachteten Variablen?
linear mit versteckten Faktoren verbunden
Müssen finden
Das ist alles! Diese Beta-Koeffizienten werden in der Welt der Faktoranalyse als Belastungen bezeichnet. Betrachten Sie ihre Bedeutung etwas später.
Um zum Ergebnis der Analyse zu gelangen, kann man sich auf verschiedene Arten bewegen. Eine davon, die ich verwendet habe, besteht darin, die Hauptkomponenten im klassischen Sinne zu finden, die sich dann drehen, um die „einfache Struktur“ hervorzuheben. Die Hauptkomponenten erstrecken sich nur von der singulären Zerlegung der Matrix oder durch die Zerlegung der Variations-Kovarianz-Matrix in Eigenvektoren und Werte. Das Problem wird auch durch Maximieren der Wahrscheinlichkeitsfunktion gelöst. Im Allgemeinen handelt es sich bei der Faktoranalyse um einen großen „Zoo“ von Methoden, von denen mindestens 10 unterschiedliche Ergebnisse liefern. Es wird empfohlen, die für die Aufgabe am besten geeignete Methode auszuwählen.
Die Drehung der Lastmatrix kann auch auf verschiedene Arten erfolgen, ich habe versucht, Varimax - orthogonale Drehung.
Warum ist alles so kompliziert?Tatsache ist, dass unter Statistikern und Antragstellern die Diskussion über die Unterschiede und Ähnlichkeiten der Methode der Hauptkomponenten, der Faktoranalyse und ihrer Kombination nicht aufhört. Die Methodik wird auch nach mehr als 100 Jahren ab dem Zeitpunkt der Entdeckung mit neuem Wissen ergänzt. Ein angesehener Statistiker brachte mir das folgende Bild, um das Verständnis mit den Worten zu erleichtern: "Das ist es, klären Sie es."
 Quelle
Quelle .
Alles in Ordnung!
Nur ein Scherz). Um die nächsten Schritte zu verstehen, reicht es aus, die Hauptkomponenten nach dem Isolieren zu drehen, von der Erklärung der Varianz innerhalb von Variablen zur Erklärung der Kovarianz von Variablen und Faktoren.
Außerdem mache ich das alles mit atomaren Funktionen und nicht nur mit einem „großen roten Knopf“. Dieser Ansatz ermöglicht es uns, die Transformation in den Daten in Zwischenstadien zu verstehen.
Wo ist die LDA geblieben?
UpdateIch beschloss, meine Gedanken zu latenten Dirichlet-Arrangements hinzuzufügen. Ich habe diese beliebte Methode ausprobiert, konnte aber in kurzer Zeit kein sauberes Ergebnis erzielen. Einfache Beispiele für die Verwendung und die „Teilen wir die Nachrichten in Politik, Wirtschaft und Kultur“ funktionieren wirklich, aber ... In meinem Fall muss ich beispielsweise die Politik in 50 Tagesthemen unterteilen, in denen Russland, Putin und der Iran sein werden und so enge Themen wie "die Befreiung von Kokorin und Mamaev". All dies in der Tat 1-2 Nachrichten von Nachrichtenagenturen, die mehrere Dutzend Mal in den Medien zitiert wurden.
Darüber hinaus erscheint mir die Annahme über die Art der Daten, die für die Hypothese charakteristisch ist, dass jeder Text eine Wahrscheinlichkeitsverteilung nach Themen darstellt, im Kontext meiner Arbeit ein wenig künstlich. Kein Herausgeber stimmt zu, dass die Nachricht von der „Abweisung des Falls gegen Golunov“ eine Mischung aus Themen ist. Für uns ist dies 1 Thema. Vielleicht lasse ich diese Frage für die Zukunft, wenn ich Hyperparameter wähle, um eine solche Fragmentierung von der LDA zu erreichen.
Code
Ich versuche mich wieder in der R-Sprache, also wird dieses kleine Experiment arisch sein.
Wir arbeiten mit 3 Paaren korrelierter Zufallswerte. Dieses Set enthält 3 versteckte Faktoren - nur zur Verdeutlichung.
set.seed(1) x1 = rnorm(1000) x2 = x1 + rnorm(1000, 0, 0.2) x3 = rnorm(1000) x4 = x3 + rnorm(1000, 0, 0.2) x5 = rnorm(1000) x6 = x5 + rnorm(1000, 0, 0.2) dt <- data.frame(cbind(x1,x2,x3,x4,x5,x6)) M <- as.matrix(dt) sing <- svd(M, nv = 3) loadings <- sing$v rot <- varimax(loadings, normalize = TRUE, eps = 1e-5) r <- rot$loadings loading_1 <- r[,1] loading_2 <- r[,2] loading_3 <- r[,3] plot(loading_1, type = 'l', ylim = c(-1,1), ylab = 'loadings', xlab = 'variables'); lines(loading_2, col = 'red'); lines(loading_3, col = 'blue'); axis(1, at = 1:6, labels = rep('', 6)); axis(1, at = 1:6, labels = paste0('x', 1:6))
Wir erhalten die folgende Lastmatrix:
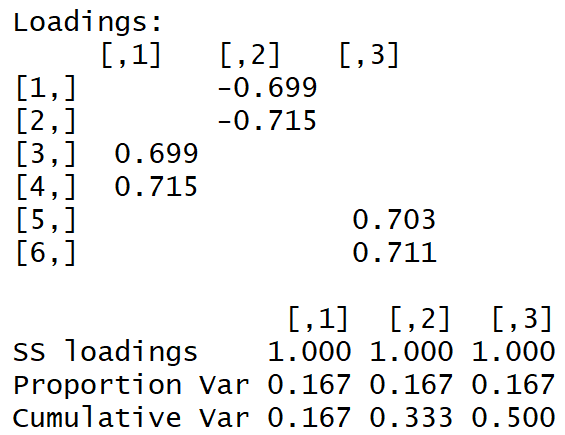
Die "einfache Struktur" ist mit bloßem Auge sichtbar.
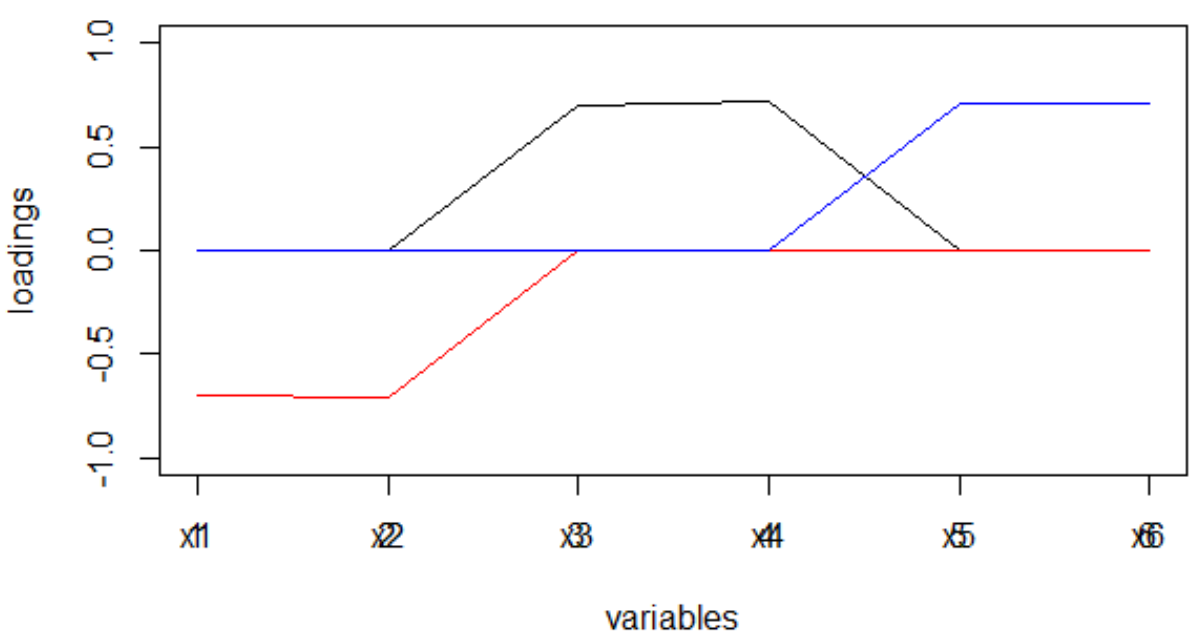
Und so sahen die Ladungen direkt nach Fertigstellung des MGK aus:
Es ist für Menschen nicht leicht zu verstehen, welche Faktoren mit welchen Variablen verbunden sind. Darüber hinaus führen solche modulo genommenen Gewichte und bei der Interpretation der Maschine zu einer sehr merkwürdigen Verteilung von Wörtern zu Themen.
Aber, bo!, Der Anteil der erklärten Dispersion in den ersten drei Hauptkomponenten (vor der Rotation) erreichte 99%.

Was ist mit den Nachrichten?
Für Nachrichten werden unsere Variablen x1, x2 ... xm zur Häufigkeit (oder tf-idf) des Token-Auftretens im Text. Es gibt viele Wörter! Zum Beispiel sind 50.000 eindeutige Wörter pro Woche normal. Das Bi-Gramm wird verständlicherweise noch größer. Die Komplexität der singulären Zerlegung ist der Durchschnitt:
Das heißt, es ist riesig. Die Zerlegung einer Matrix von 20.000 * 50.000 Werten in einem Strom dauert mehrere Stunden ...
Um Themen in Echtzeit lesen und Shiny auf einem Dashboard anzeigen zu können, bin ich zu folgenden schmerzhaften Grenzwerten gekommen:
- Top-10% der häufigsten Wörter
- zufällige Auswahl von Texten nach der sich selbst erfüllenden Formel:
Dabei ist n alle Texte.
Infolgedessen verarbeite ich wöchentliche Daten in 30 Sekunden, einen Tag in 5 Sekunden. Nicht schlecht! Sie müssen jedoch verstehen, dass Nachrichtentrends nur von den am besten genährten Personen erfasst werden.
Nachdem ich Lasten erhalten habe, die, wie ich bemerke, Schätzungen der Kovarianz der beobachteten Variablen mit den Faktoren sind, löse ich sie vom Vorzeichen (durch das Modul, nicht durch den Grad), das sich je nach verwendeter Rotationsmethode tendenziell ändert.
Erinnern Sie sich daran, wie sich die Lastmatrix nach Durchführung des MHC und nach Drehung mit Varimax unterschied. Die Spärlichkeit der Lasten sowie die Tatsache, dass ihre Streuung für jeden Faktor maximiert wurde: Es gibt sehr große und sehr kleine, führt dazu, dass die Wörter ziemlich sauber auf den Faktor verteilt werden, was wiederum zu weiteren führt und die Verteilung der Faktoren im Nachrichtentext wird einen ausgeprägten Höhepunkt haben.
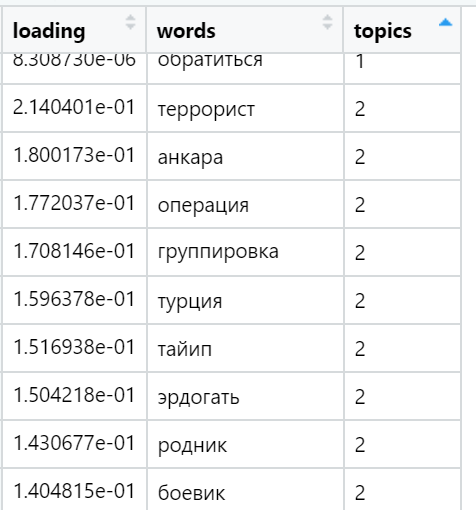
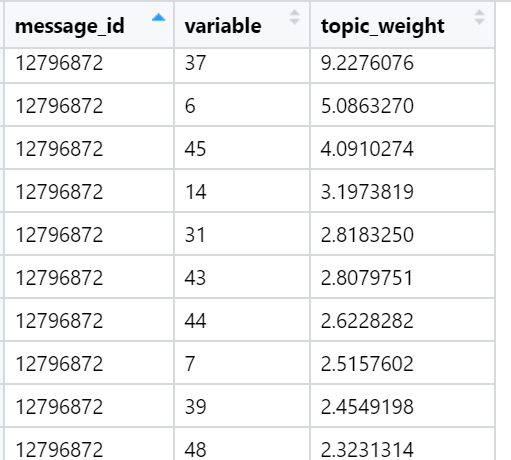
Beispiele für die am häufigsten geladenen Wörter in verschiedenen gefundenen Themen (zufällig ausgewählt):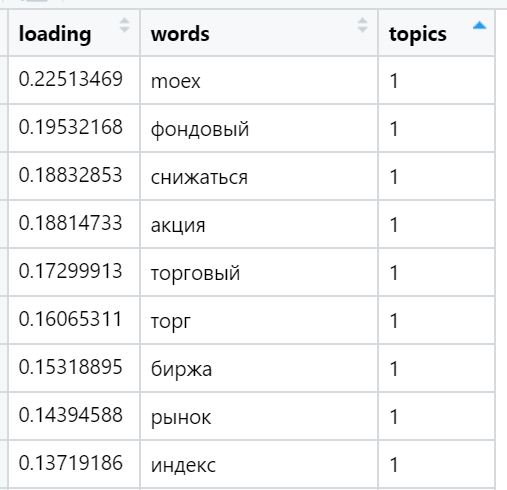

Und schließlich betrachte ich die Summe der Belastungen in den Texten in Bezug auf jeden Faktor. Der stärkste Gewinn: Für jeden Text wird ein Faktor ausgewählt, dessen Summe der Lasten maximiert wird - unter Berücksichtigung der Anzahl der im Dokument enthaltenen Wörter, die - wie wir während der Rotation angegeben haben - eine sehr ungleichmäßige Verteilung zwischen den Lastfaktoren aufweisen. In dieser Iteration sind bereits alle Texte (n) beteiligt, dh das vollständige Beispiel.
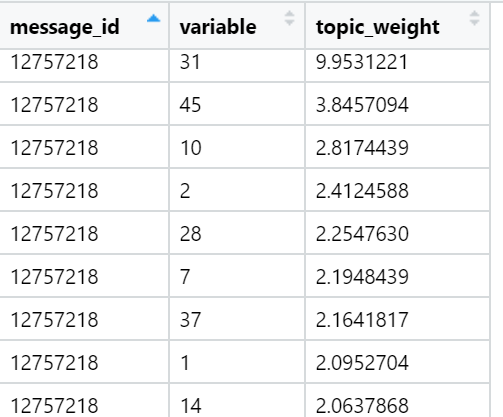
Beispiele für Themen, die in Bezug auf die Summe der Lasten in bestimmten Nachrichtentexten (zufällig ausgewählt) am besten sind: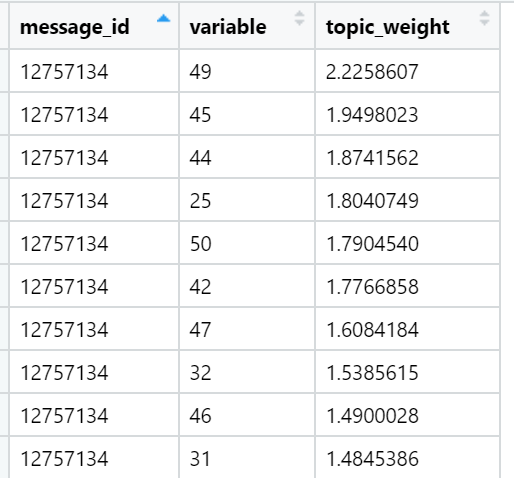
 Das Ergebnis für heute.
Das Ergebnis für heute. Weitere Informationen.
Weitere Informationen.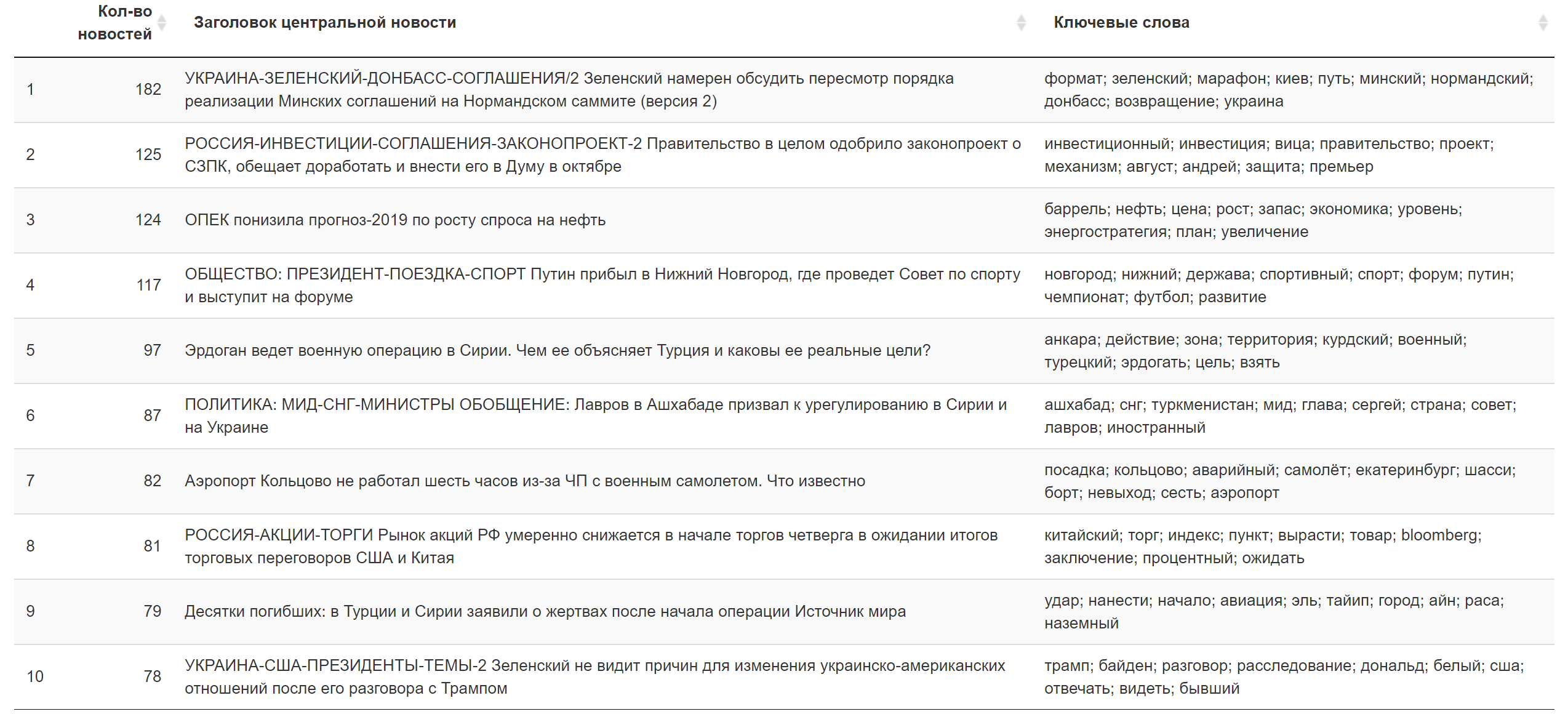
Was zu tun ist?
Hier das erste, was ich tun werde, wenn ... Wenn Inspiration kommt, werde ich im Allgemeinen versuchen, den Job für das stündliche Training eines neuronalen Netzwerks mit einem schmalen Hals zu konfigurieren, was mir nur eine nichtlineare Annäherung von Faktoren - verzerrten Hauptkomponenten - in Form von Neuronen mit versteckter Schicht gibt. Theoretisch kann mit der erhöhten Lerngeschwindigkeit schnell gelernt werden. Danach spielen die Gewichte der verborgenen Ebene (irgendwie normalisiert) die Rolle der Token-Ladevorgänge. Sie können bereits schnell und mit akzeptabler Geschwindigkeit in die endgültige Verarbeitungsumgebung geladen werden. Vielleicht kann dieser Trick dazu führen, dass die Woche in 10 Sekunden in allen Texten verarbeitet wird: die normale Zeit für einen so schwierigen Fall.
Alles in allem war das alles, was ich behandeln wollte. Ich hoffe, dass dieser kurze Ausflug in die Themenmodellierungsmethode es Ihnen ermöglicht, besser zu verstehen, was unter dem „großen roten Knopf“ getan wird, die Entfremdung von der Technologie zu verringern und Zufriedenheit zu bringen. Wenn Sie dies bereits wussten, würde ich mich freuen, die Meinungen eines technischen oder Produktsinns zu hören. Unser Experiment entwickelt sich ständig weiter und verändert sich ständig!