- Wie groß ist ein Cluster, den ich brauche?
- Nun, es kommt darauf an ... (wütendes Kichern)
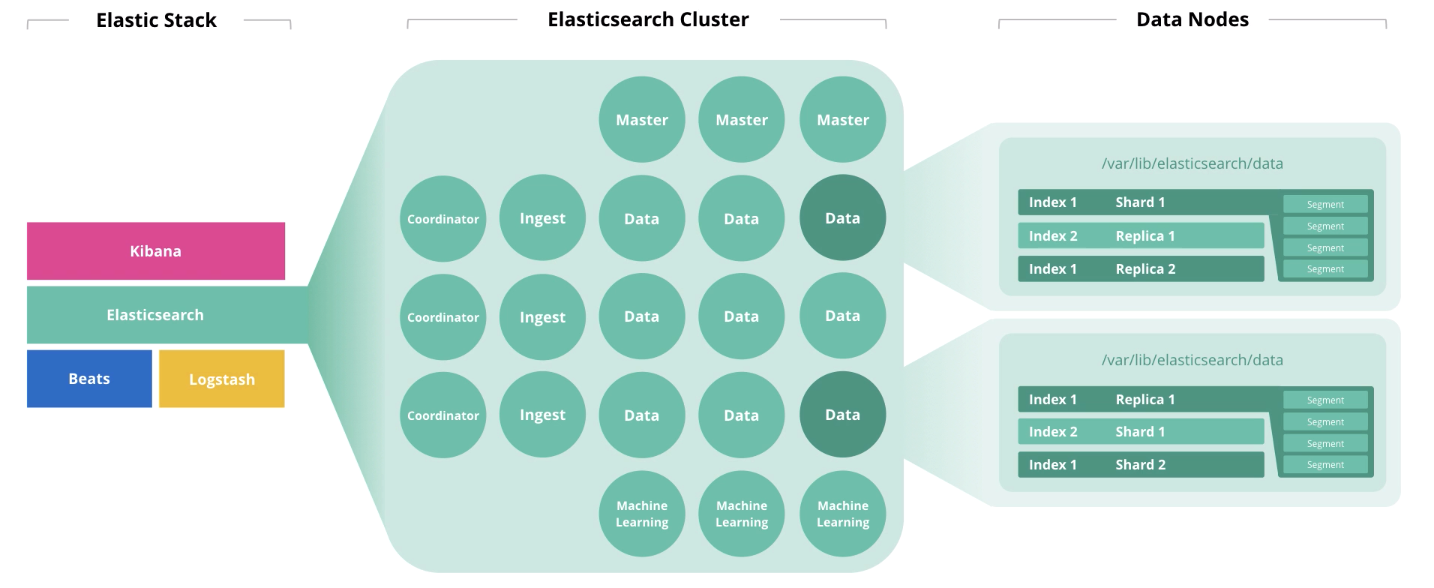
Elasticsearch ist das Herzstück des Elastic Stack, in dem die ganze Magie von Dokumenten stattfindet: Ausstellen, Empfangen, Verarbeiten und Speichern. Die Leistung hängt von der richtigen Anzahl von Knoten und der Architektur der Lösung ab. Und der Preis übrigens auch, wenn Ihr Abonnement Gold oder Platin ist.
Die Hauptmerkmale der Hardware sind Festplatte (Speicher), Speicher (Speicher), Prozessoren (Berechnung) und Netzwerk (Netzwerk). Jede dieser Komponenten ist für die Aktion verantwortlich, die Elasticsearch für Dokumente ausführt, die jeweils gespeichert, gelesen, berechnet und empfangen / gesendet werden. Lassen Sie uns über die allgemeinen Prinzipien der Größenbestimmung sprechen und das „es kommt darauf an“ aufzeigen. Am Ende des Artikels finden Sie Links zu Webinaren und verwandten Artikeln. Lass uns gehen!
Dieser Artikel basiert auf
David Moores Webinar Sizing and Capacity Planning . Wir haben seine Argumentation mit Links und Kommentaren ergänzt, um es ein wenig klarer zu machen. Am Ende des Artikels enthält ein Bonustrack Links zu elastischen Materialien für diejenigen, die besser in das Thema eintauchen möchten. Wenn Sie gute Erfahrungen mit Elasticsearch gemacht haben, teilen Sie uns bitte in den Kommentaren mit, wie Sie einen Cluster entwerfen. Wir und alle Kollegen wären interessiert, Ihre Meinung zu erfahren.
Architektur und Betrieb von Elasticsearch
Zu Beginn des Artikels haben wir über 4 Komponenten gesprochen, die die Hardware bilden: Festplatte, Speicher, Prozessoren und Netzwerk. Die Rolle eines Knotens wirkt sich auf die Entsorgung jeder dieser Komponenten aus. Ein Knoten kann mehrere Rollen gleichzeitig ausführen. Mit dem Wachstum des Clusters sollten diese Rollen jedoch auf verschiedene Knoten verteilt werden.
Masterknoten überwachen den Zustand des Clusters als Ganzes. Bei der Arbeit des Hauptknotens muss ein Quorum eingehalten werden, d.h. Ihre Anzahl sollte ungerade sein (vielleicht 1, aber besser 3).
Datenknoten führen Speicherfunktionen aus. Um die Clusterleistung zu erhöhen, müssen die Knoten in
"heiß", "heiß" und "kalt" (eingefroren) unterteilt werden . Die ersten sind für den Online-Zugriff, die zweite für die Speicherung und die dritte für die Archivierung. Dementsprechend ist es für "heiß" sinnvoll, lokale SSD-Laufwerke zu verwenden, und für "warm" und "kalt" ist das HDD-Array lokal oder in SAN geeignet.
Um die Speicherkapazität von Knoten für die Speicherung zu bestimmen, empfiehlt Elastic die Verwendung der folgenden Logik: "heiß" → 1:30 (30 GB Speicherplatz pro Gigabyte Speicher), "warm" → 1: 100, "kalt" → 1: 500). Unter dem
JVM-Heap nicht mehr als 50% des gesamten Speichers und nicht mehr als 30 GB, um einen Garbage Collector-Raid zu vermeiden. Der verbleibende Speicher wird als Cache des Betriebssystems verwendet.
Leistungsindikatoren für Elastisearch-Instanzen wie
Thread-Pools und Thread-Warteschlangen sind stärker von der Prozessorkernauslastung betroffen. Die ersten werden auf der Grundlage der Aktionen gebildet, die der Knoten ausführt: Suchen, Analysieren, Schreiben und andere. Die zweite ist die Warteschlange der entsprechenden Anforderungen verschiedener Typen. Die Anzahl der zur Verwendung verfügbaren Elasticsearch-Prozessoren wird automatisch festgelegt. Sie können diesen Wert jedoch manuell in den Einstellungen angeben (dies kann hilfreich sein, wenn zwei oder mehr Elasticsearch-Instanzen auf demselben Host ausgeführt werden). Die maximale Anzahl von Thread-Pools und Thread-Warteschlangen für jeden Typ kann in den Einstellungen festgelegt werden. Die Metrik für Thread-Pools ist die primäre Leistungsmetrik für Elasticsearch.
Aufnahmeknoten nehmen Eingaben von Kollektoren (Logstash, Beats usw.) entgegen, führen Konvertierungen an ihnen durch und schreiben in den Zielindex.
Knoten für
maschinelles Lernen sind für die Datenanalyse vorgesehen. Wie wir in dem
Artikel über maschinelles Lernen in Elastic Stack geschrieben haben , ist der Mechanismus in C ++ geschrieben und funktioniert außerhalb der JVM, in der sich Elasticsearch selbst dreht. Daher ist es sinnvoll, solche Analysen auf einem separaten Knoten durchzuführen.
Koordinatorknoten akzeptieren eine Suchanforderung und leiten sie weiter. Das Vorhandensein dieses Knotentyps beschleunigt die Verarbeitung von Suchanfragen.
Wenn wir die Belastung der Knoten in Bezug auf die Infrastrukturkapazitäten betrachten, wird die Verteilung ungefähr so aussehen:
Als Nächstes stellen wir in Elasticsearch vier Haupttypen von Operationen vor, für die jeweils eine bestimmte Art von Ressource erforderlich ist.
Index - Verarbeitung und Speicherung eines Dokuments im Index. Das folgende Diagramm zeigt die in jeder Phase verwendeten Ressourcen.
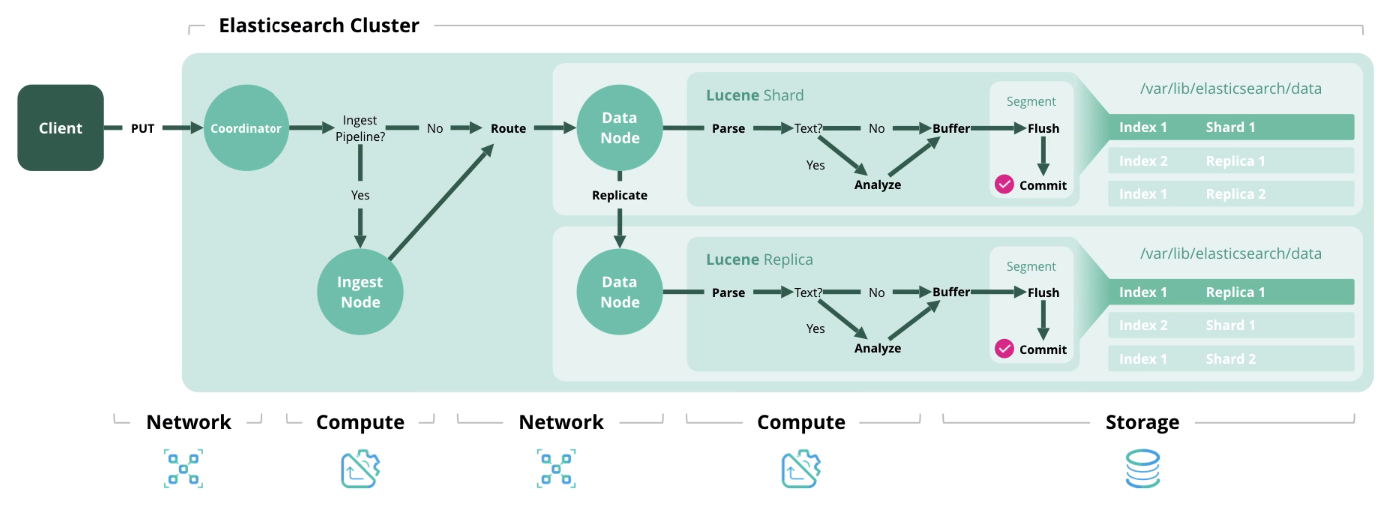 Löschen
Löschen - Löscht ein Dokument aus dem Index.
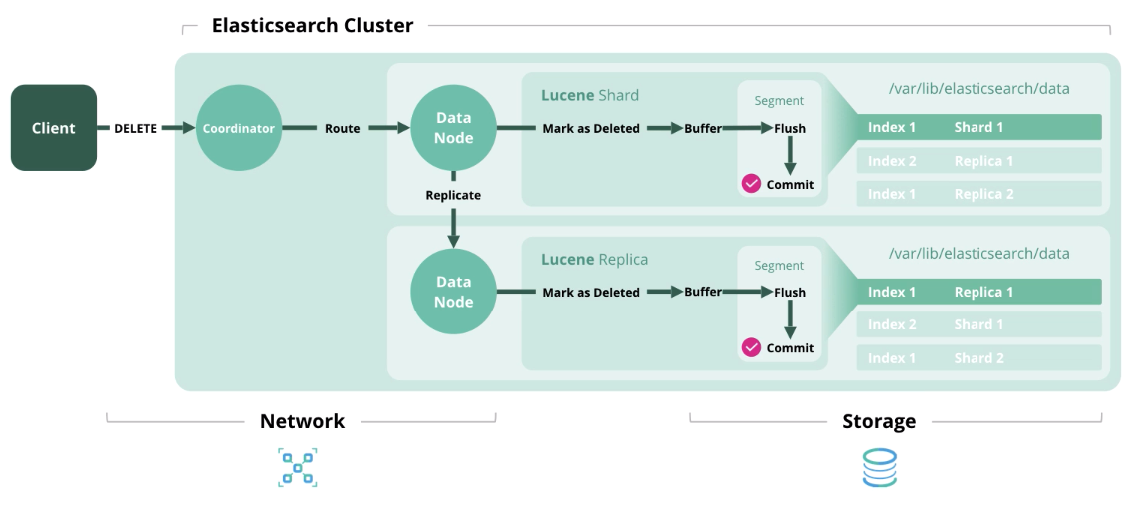 Aktualisieren
Aktualisieren - Funktioniert wie Indexieren und Löschen, da Dokumente in Elasticsearch unveränderlich sind.
Suche - Abrufen eines oder mehrerer Dokumente oder deren Aggregation aus einem oder mehreren Indizes.
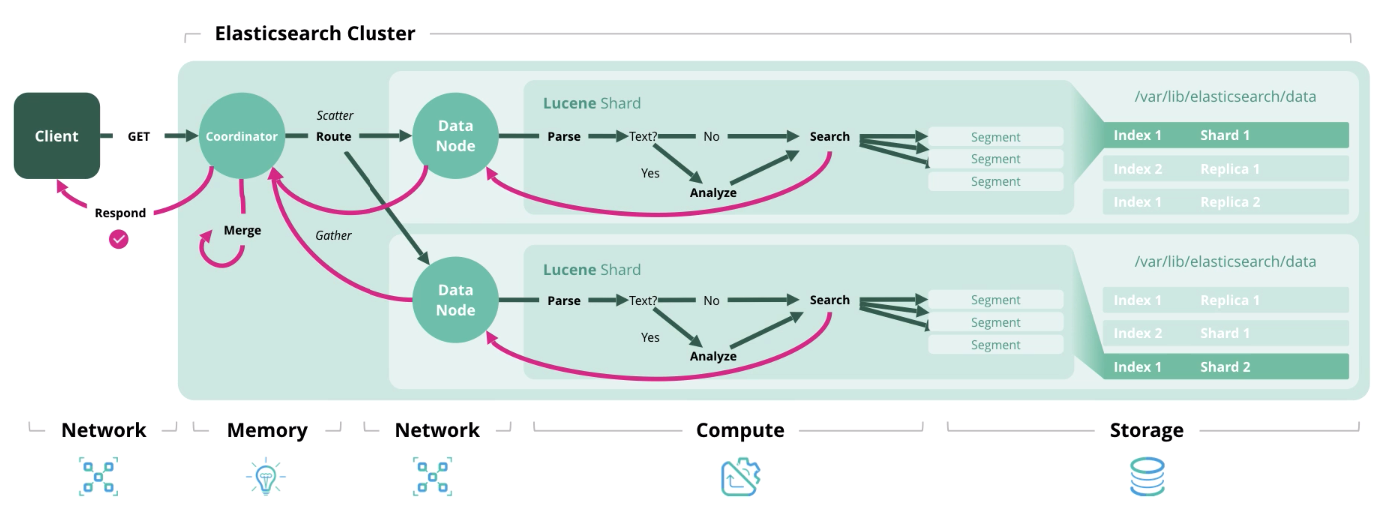
Wir haben die Architektur und die Arten der Lasten herausgefunden und gehen nun zur Bildung eines Größenmodells über.
Dimensionierung Elasticsearch und Fragen vor seiner Bildung
Elastic empfiehlt die Verwendung von zwei Größenstrategien: speicherorientiert und Durchsatz. Im ersten Fall sind Festplattenressourcen und Speicher von größter Bedeutung, und im zweiten Fall Speicher, Prozessorleistung und Netzwerk.
Größe der Elasticsearch-Architektur basierend auf der Speichergröße
Vor den Berechnungen erhalten wir die Anfangsdaten. Bedarf:
- Die Menge der Rohdaten pro Tag;
- Die Dauer der Datenspeicherung in Tagen;
- Datentransformationsfaktor (JSON-Faktor + Indexierungsfaktor + Komprimierungsfaktor);
- Anzahl der Shard-Replikationen;
- Die Anzahl der Speicherdatenknoten;
- Das Verhältnis von Speicher zu Daten (1:30, 1: 100 usw.).
Leider wird der Datentransformationsfaktor nur empirisch berechnet und hängt von verschiedenen Faktoren ab: dem Format der Rohdaten, der Anzahl der Felder in Dokumenten usw. Um dies herauszufinden, müssen Sie einen Teil der Testdaten in den Index laden. Zum Thema solcher Tests gibt es ein
interessantes Video von der Konferenz und eine
Diskussion in der Elastic Community . Im Allgemeinen können Sie es gleich 1 belassen.
Standardmäßig
komprimiert Elasticsearch Daten mit dem LZ4-Algorithmus, aber es gibt auch DEFLATE, das 15% mehr drückt. Im Allgemeinen kann eine Kompression von 20-30% erreicht werden, dies wird jedoch auch empirisch berechnet. Beim Umschalten auf den DEFLATE-Algorithmus steigt die Rechenleistung.
Es gibt noch weitere Empfehlungen:
- Zahlen Sie 15% ein, um eine Reserve auf dem Speicherplatz zu haben.
- Versprechen Sie 5% für zusätzlichen Bedarf;
- Legen Sie 1 Äquivalent eines Datenknotens fest, um eine schnelle Migration sicherzustellen.
Kommen wir nun zu den Formeln. Hier ist nichts kompliziert, und wir glauben, dass es für Sie interessant sein wird, Ihren Cluster auf Übereinstimmung mit diesen Empfehlungen zu überprüfen.
Gesamtdatenmenge (GB) = Rohdaten pro Tag * Anzahl der Speichertage * Datentransformationsfaktor * (Anzahl der Replikate - 1)
Gesamtdatenspeicher (GB) = Gesamtdaten (GB) * (1 + 0,15 Lager + 0,05 zusätzlicher Bedarf)
Gesamtzahl der Knoten = OK (Gesamtdatenspeicher (GB) / Speichervolumen pro Knoten / Verhältnis von Speicher zu Daten + 1 Äquivalent Datenknoten)
Größe der Elasticsearch-Architektur zur Bestimmung der Anzahl der Shards und Datenknoten in Abhängigkeit von der Speichergröße
Vor den Berechnungen erhalten wir die Anfangsdaten. Bedarf:
- Die Anzahl der Indexmuster, die Sie erstellen werden.
- Die Anzahl der Kernsplitter und Replikate;
- Nach wie vielen Tagen wird die Indexrotation durchgeführt, wenn überhaupt;
- Die Anzahl der Tage zum Speichern der Indizes;
- Die Speichermenge für jeden Knoten.
Es gibt noch weitere Empfehlungen:
- Überschreiten Sie nicht 20 Shards pro 1 GB JVM-Heap auf jedem Knoten.
- Überschreiten Sie nicht 40 GB Shard-Speicherplatz.
Die Formeln lauten wie folgt:
Anzahl der Shards = Anzahl der Indexmuster * Anzahl der Hauptshards * (Anzahl der replizierten Shards + 1) * Anzahl der Lagertage
Anzahl der Datenknoten = OK (Anzahl der Shards / (20 * Speicher für jeden Knoten))
Elasticsearch-Bandbreitengröße
Der häufigste Fall, wenn eine hohe Bandbreite benötigt wird, ist häufig und in großer Anzahl Suchanfragen.
Notwendige Anfangsdaten für die Berechnung:
- Spitzensuche pro Sekunde;
- Durchschnittliche zulässige Antwortzeit in Millisekunden;
- Die Anzahl der Kerne und Threads pro Prozessorkern auf Datenknoten.
Spitzenwert der Threads = OK (Spitzenwert der Suchanfragen pro Sekunde * durchschnittliche Anzahl der Antworten auf eine Suchanfrage in Millisekunden / 1000 Millisekunden)
Volume-Thread-Pool = OKRUP ((Anzahl der physischen Kerne pro Knoten * Anzahl der Threads pro Kern * 3/2) +1)
Anzahl der Datenknoten = OK (Peak-Thread-Wert / Thread-Pool-Volumen)
Möglicherweise sind beim Entwerfen der Architektur nicht alle anfänglichen Daten in Ihren Händen, aber nach dem Betrachten des
Webinars oder dem Lesen dieses Artikels wird ein Verständnis angezeigt, das sich im Prinzip auf die Menge der Hardwareressourcen auswirkt.
Bitte beachten Sie, dass es nicht erforderlich ist, die angegebene Architektur einzuhalten (z. B. Koordinatenkoordinatenknoten und Handlerknoten erstellen). Es reicht zu wissen, dass eine solche Referenzarchitektur vorhanden ist, und sie kann zu einer Leistungssteigerung führen, die Sie mit anderen Mitteln nicht erreichen könnten.
In einem der folgenden Artikel veröffentlichen wir eine vollständige Liste der Fragen, die zur Bestimmung der Clustergröße beantwortet werden müssen.
Um mit uns in Kontakt zu treten, können Sie persönliche Nachrichten auf Habré oder das
Feedback-Formular auf der Website verwenden .
Zusätzliche MaterialienWebinar "Elasticsearch Dimensionierung und Kapazitätsplanung"Webinar zur Kapazitätsplanung für ElasticsearchRede bei ElasticON zum Thema „Quantitative Cluster Sizing“Webinar zum Rallye-Dienstprogramm zur Ermittlung von Cluster-LeistungsindikatorenElasticsearch GrößenartikelElastic Stack Webinar