Hallo allerseits! Mein Name ist Lyudmila, ich beschäftige mich mit Lasttests. Ich möchte mit einem unserer Kunden teilen, wie wir die Automatisierung der vergleichenden Analyse des Regressionsprofils des Lasttestsystems aus der Datenbank für das Oracle DBMS durchgeführt haben.
Der Zweck des Artikels besteht nicht darin, einen „neuen“ Ansatz zum Vergleichen der Datenbankleistung zu finden, sondern unsere Erfahrungen zu beschreiben und zu versuchen, den Vergleich der erhaltenen Ergebnisse und zu automatisieren
Reduzieren Sie die Anzahl der Anrufe bei DBA Oracle.
Bei der Durchführung von Lasttests für jede Datenbank sind wir hauptsächlich interessiert an:
- Ist nach der Installation einer neuen Baugruppe etwas kaputt gegangen?
- Die Dynamik der Datenbank während des Tests.
Der Vergleich von AWR-Berichten allein reicht nicht aus, um Ihre Ziele zu erreichen.
Die zentrale Lagerung von AWR-Deponien ist ebenfalls eine gute Praxis. AWR-Dumps behalten alle historischen Ansichten bei (dba_hist).
Diese Praxis wurde bereits von unserem Kunden angewendet.
Nach der nächsten Sitzung des Lasttests vergleichen wir die Ergebnisse:
- aktuelle Testkippe mit Industriedeponie;
- der aktuelle Testspeicherauszug mit dem vorherigen Testspeicherauszug.
Warum wird das benötigt?
Die Ziele sind unterschiedlich:
- Manchmal unterscheidet sich das Befüllen der Basis selbst in einer Testumgebung von der betrieblichen, was bedeutet, dass es Unterschiede gibt, die die Analyse stören ("Interferenz" zur Beantwortung der Hauptfrage "Haben Sie etwas kaputt?"). Ich möchte diese Unterschiede identifizieren.
- Der Vergleich des aktuellen Tests mit der Arbeit der Industriebasis hilft zu verstehen, wie korrekt die aktuellen Stresstests sind (irgendwo laden wir zu viel, aber wir haben überhaupt etwas vergessen);
- Der Vergleich des aktuellen Tests mit dem vorherigen Test hilft zu verstehen, ob das aktuelle Systemverhalten normal ist. Hat sich im Verhalten des Systems im Vergleich zum vorherigen Test etwas geändert?
Um all diese Ziele zu erreichen, lösen wir häufig das Problem, verschiedene Dumps miteinander zu vergleichen. Die Daten sind normalerweise sehr eng, als sie gestern vorgestellt werden sollten! Die Zeit, um jeden Regressionstest vollständig zu überprüfen, fehlt dringend. Und wenn Sie den Zuverlässigkeitstest einen Tag lang durchführen, können Sie viel Zeit damit verbringen, das Ergebnis zu analysieren ...
Natürlich können Sie während des Tests alles online in Enterprise Manager (oder mit der Bitte um gv $ views) ansehen: Gehen Sie nicht rauchen, essen und schlafen ...

Vielleicht haben Sie auch ein eigenes Werkzeug, das Sie selbst angefertigt haben? Sie können in den Kommentaren teilen. Und wir werden teilen, was wir für unsere Aufgaben verwenden.
AWR-Berichte enthalten viele nützliche Informationen:

Hier finden Sie nützliche Informationen, zum Beispiel: Wie viel die Abfrage ausführt, sql_id, Modul und abgekürzter Text. Obwohl der Text vorhanden ist, wird er abgeschnitten und die Vollversion kann dem Absatz "Vollständige Liste des SQL-Textes" entnommen werden.
Was die Minuspunkte betrifft: Im AWR-Bericht ist nicht klar, wann diese Anfragen aufgetreten sind, zu welchem Zeitpunkt mehr und zu welchem Zeitpunkt weniger ... Schließlich ist es wichtig, die Testergebnisse zu analysieren, zu verstehen, was passiert ist und zu welchem ungefähren Zeitpunkt: gleichmäßig für das Ganze Test oder Peak / Surge wie nach einem Zeitplan. Wir werden hier auch nur ein begrenztes Top sehen. Dies kann durch Abfragen historischer Tabellen einfacher angezeigt werden.
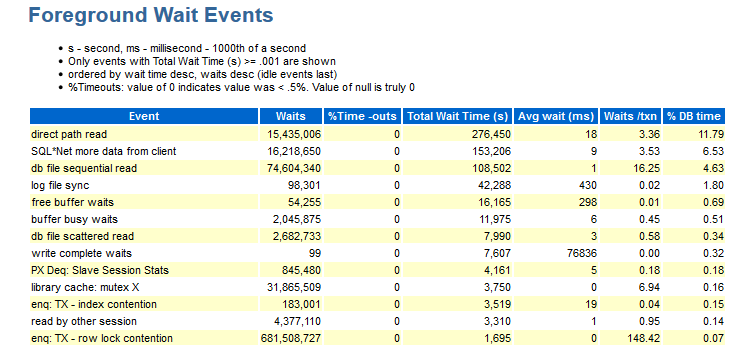
Hier können Sie sehen, welche Ereignisse während des Tests aufgetreten sind. Die Daten in diesem Abschnitt sind nach DB-Zeit geordnet.
In diesem Abschnitt fehlen mir folgende Informationen:
- Wait_class (ja, Sie erinnern sich mit Erfahrung daran, zu welchen Erwartungen dieses Ereignis gehört).
- Verteilungen nach Modulen (wenn ich zum Beispiel sehe, dass auf enq: TX gewartet wird - Zeilensperrkonflikt: Informationen werden benötigt, unter welchem Modul dies passiert ist).
Es gibt Jobs, bei denen es Zahlen gibt, die keinen semantischen Teil enthalten. Das heißt, Sie müssen dieselben Module gruppieren und eine Antwort für die Gruppe erhalten, z. B. Modul_A_1, Modul_A_2, Modul_A_3 und Modul_B_1, Modul_B_2, Modul_B_3. Das heißt, es gab zwei semantische Module, die jedoch alle unterschiedliche Namen haben.
- Das Objekt, auf das wir uns beziehen (CURRENT_OBJ # - Wenn beispielsweise der Ereignis enq: TX - Indexkonflikt auftritt, wäre es schön zu wissen, welcher Index schuld ist).
- Sql_id - welche Anforderung der Text dieser Anforderung versucht auszuführen.
- Informationen zur Mengenverteilung pro Schnappschuss (wie oben beschrieben ...).
Um die beiden Tests zu vergleichen, können Sie den Vergleich von AWR-Berichten verwenden:
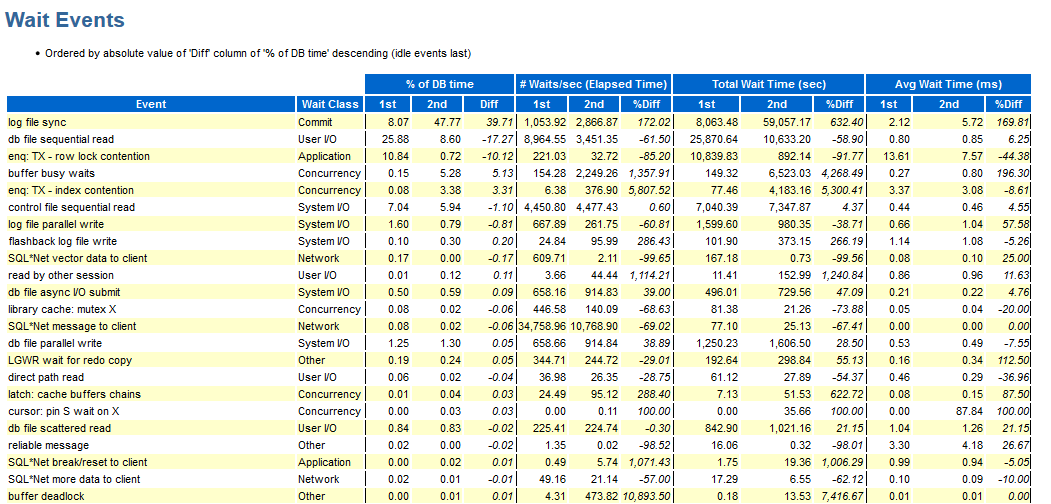
Hurra, hier haben wir wait_class angezeigt, ansonsten sind die Minuspunkte die gleichen wie oben beschrieben.
Manchmal gibt es keinen Enterprise Manager für Projekte, und Sie können beispielsweise Enterprise Manager Express oder ASH Viewer verwenden. In Enterprise Manager verwenden viele Top Activity für Verlaufsdaten, aber für mich sind viele Dinge mit den Abfragen selbst einfacher zu betrachten. Alle oben genannten Punkte sollten mit anderen Tests / Arbeitslasten verglichen werden. Wir hatten bereits einen benutzerdefinierten Vergleich in Bezug auf die Laufzeit, aber keinen benutzerdefinierten Vergleich. Wir haben manuell nach Abfragen in historischen Tabellen gesucht.
Nach jedem Regressionstest war es notwendig, die Ergebnisse in historischen Tabellen mit Abfragen an die Datenbank zu vergleichen, AWR-Berichte anzuzeigen, die problematische Erwartung zu lokalisieren (auf welchem Modul es auftritt, zu welchen Zeiten, an welchem Objekt es hing), damit ein Fehler für das richtige Entwicklungsteam generiert werden konnte.
Die Kundendatenbank hat 190 TB erreicht, eine große Anzahl von Anforderungen wird im System verarbeitet: Die Anzahl der parallelen Module beträgt 16237.
Und dann hatte ich eine Idee, wie ich den Vergleich von AWR-Dumps vereinfachen kann. Mit dieser Idee ging ich zu
Fred . Gemeinsam haben wir ein praktisches Portal erstellt.
Die Aussage des Problems von mir sah zunächst so aus:

Dann entschied ich mich dennoch, zunächst zu systematisieren, welche Abfragen zu historischen Tabellen ich am häufigsten verwende ... Fred fing an, diese am Portal zu befestigen, und dann fing es an ...
Zunächst war ich an einem Vergleich von Ereignissen interessiert, da bereits ein Vergleich der Geschwindigkeit der Abfrageausführung in irgendeiner Form existierte. Im nächsten Schritt benötigte ich detaillierte Informationen zu jedem Ereignis: Wenn es sich bei dem Ereignis beispielsweise um einen Indexkonflikt handelt, müssen Sie verstehen, an welchem Index wir tatsächlich hängen.
Außerdem war ich interessiert, zu welchen Zeitpunkten diese Ereignisse am meisten waren, da in der Implementierung viele Aufgaben (Jobs) geplant waren und es notwendig war zu verstehen, zu welchem Zeitpunkt alles aus allen Nähten brach.
Im Allgemeinen wollte ich Folgendes bekommen:
- quantitativer Vergleich von Ereignissen zwischen verschiedenen Tests (ohne zusätzliche Kniebeugen);
- alle zugehörigen Informationen, die ich für die Analyse benötige: sql_id, Abfragetext, Verteilung während des Tests, welche Objekte die Sitzungen betreffen, Modul;
- bequeme Filter für Sie selbst, um zu sehen, was sich geändert hat;
- GUI GUI, alles ist so bunt, dass es sofort sichtbar ist (Sie können Interessenten von der Entwicklungsseite aus überprüfen)
- Gruppierung von Modulen: wie zuvor beschrieben, 16237 Module, aber aus Sicht der ausgeführten Funktionen um ein Vielfaches weniger.
Fred und ich haben ein Portal für den Vergleich von AWR-Dumps von Lasttests erstellt, auf das ich weiter unten näher eingehen werde.
Über das Portal
So werden im System AWR-Dumps erstellt, die in die Datenbank eingegossen und auf dem Portal verglichen werden.
Wir haben den folgenden Stapel verwendet:
- Oracle DB - zum Speichern von AWR-Dumps
- Python 2+
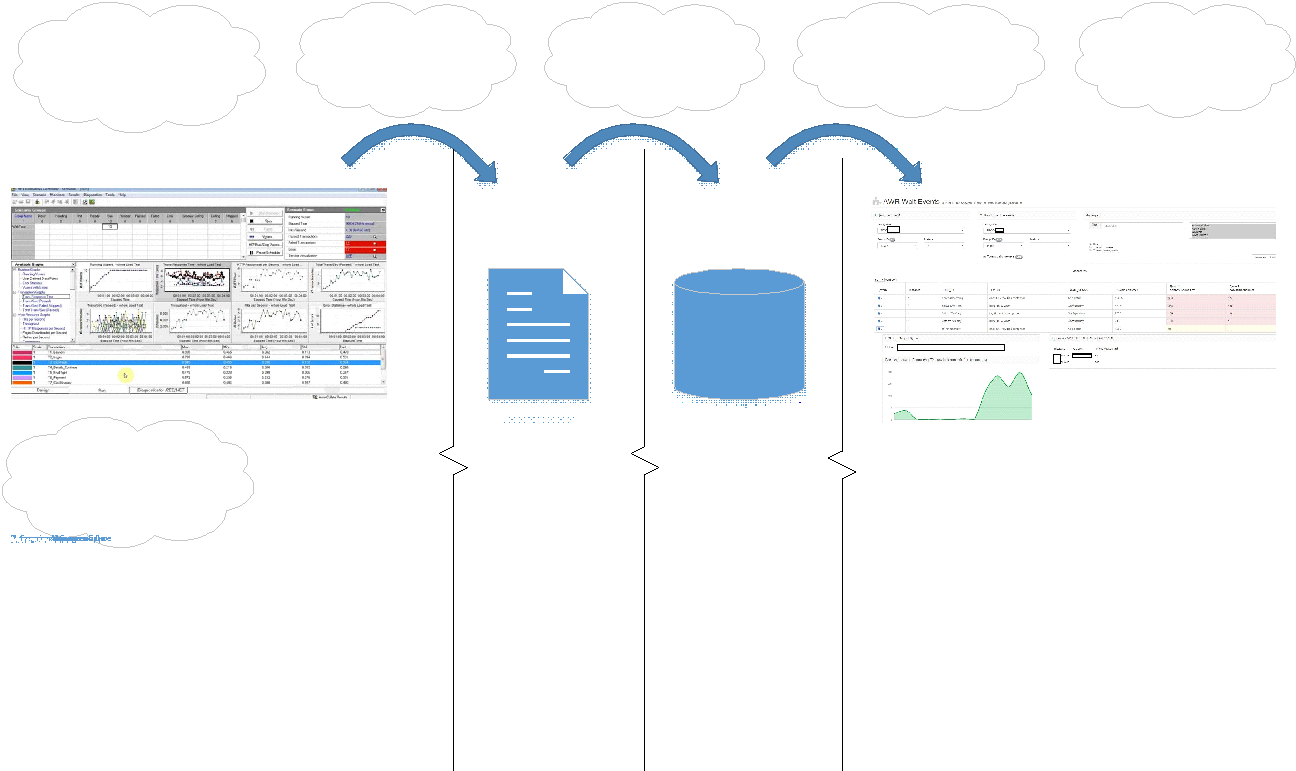
Die Portaloberfläche sieht folgendermaßen aus:

Auf dem Portal können Sie die Arten der verglichenen Dumps, Testtests oder Testabschlüsse auswählen.
Jeder Speicherauszug hat eine eigene eindeutige Kennung - DBID.
Sie können auch nach folgenden Parametern filtern:
- Instanz (Instanz) - Wir hatten eine Cluster-Datenbank.
- Anfrage (Sql_id);
- Art der Wartezeit (Wait_Class);
- Ereignis
Oben links wählen Sie Speicherauszüge aus, und rechts können Sie die erforderlichen Filter einstellen, um das gewünschte Modul sofort auszuwählen. Auf diese Weise können Sie Probleme in der Funktionalität lokalisieren, die in der vorherigen Version geändert / verbessert wurden, sodass keine Probleme mit der Verschlechterung auftreten.
Die Tabelle in der Mitte ist das Ergebnis des Vergleichs der Dumps. Die Spaltenüberschriften zeigen sofort, welche Daten ausgegeben werden. Die beiden rechten Spalten zeigen die Unterschiede zwischen den beiden Dumps:
- Rot hervorgehobene Ereignisse sind mehr als im Vergleich zu einem vergleichenden Speicherauszug für Schnappschüsse.
- gelb - neue Ereignisse;
- grün - Ereignisse, die sich bereits im ursprünglichen Speicherauszug befanden.
Es ist sofort klar, wie gut wir getestet haben. Wenn das Ereignis sehr oft aufgetreten ist, dann höchstwahrscheinlich:
- das System überlastet;
- oder die Bedingungen für die Ausführung von Hintergrundjobs änderten sich und das Ereignis begann häufiger zu spielen. Einmal auf diese Weise wurde ein Fehler im Code gefunden: Das Ereignis trat ständig auf und nicht im gewünschten Bedingungszweig.
Wenn wir ein neues Ereignis haben - gelb -, deutet dies auf eine Änderung des Systems hin, und wir müssen dessen Folgen analysieren. Hier können Sie die Verteilung von Ereignissen anhand von Schnappschüssen anzeigen und detaillierte Informationen zum Warten anzeigen.
Es gab einmal einen Fall: Es wurde ein neues Ereignis entdeckt, das ziemlich selten war und nicht in den Top-Ereignissen enthalten war, aber aufgrund dessen gab es Verlangsamungen in der Funktion, die kritische SLAs hatten. Die Analyse nur der wichtigsten Abfragen im AWR-Bericht konnte dies nicht ergeben.
Für jede Anfrage erhalten Sie detailliertere Informationen:
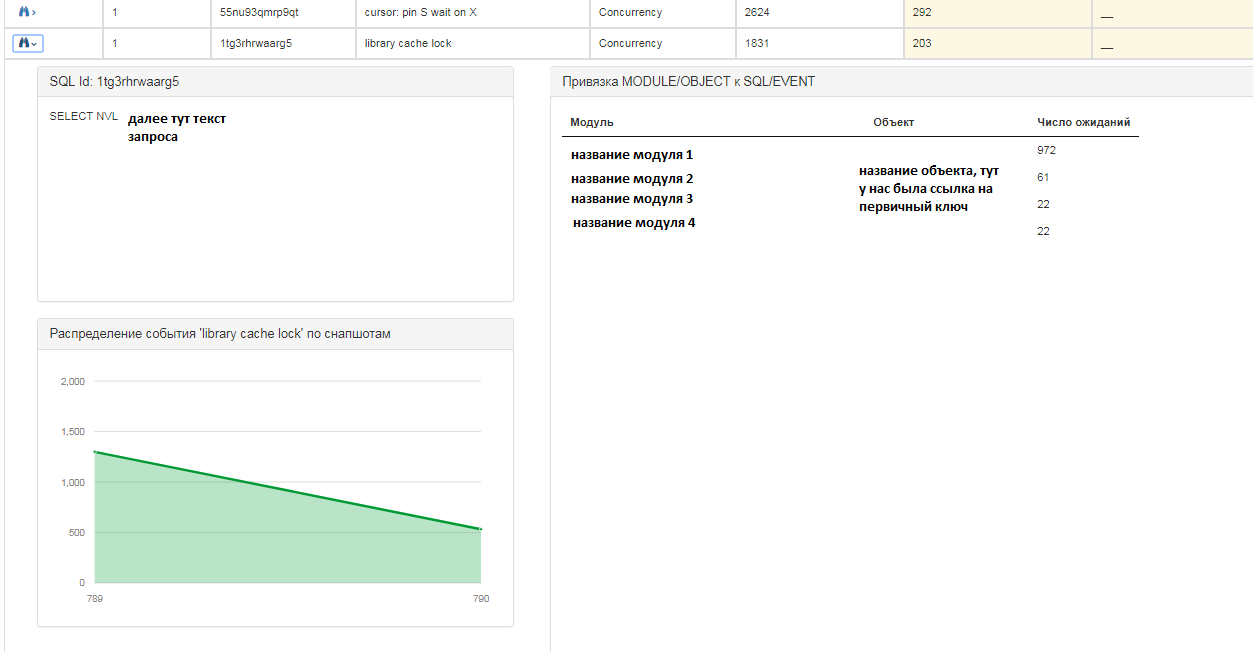
Für jeden Eintrag sehen Sie auch die folgenden Informationen:
- SQL-Text abfragen;
- die Verteilung von Ereignissen auf einem Schnappschuss in einem quantitativen Verhältnis, d.h. zu welchem Zeitpunkt gab es mehr / weniger Ereignisse;
- Auf welche Module und Objekte warten die "Hängenden".
Die Systemansichten von Oracle werden verwendet, um die Ergebnisse zu vergleichen:
DBA_HIST_ACTIVE_SESS_HISTORY, DBA_HIST_SEG_STAT, DBA_HIST_SNAPSHOT, DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED - eine eigene Servicetabelle (wurde bereits vom Kunden implementiert), die Informationen zu geladenen Dumps enthält.
Ein paar Fragen:
Verteilung von Ereignissen auf Bildern:
SELECT S.SNAP_ID, COUNT(*) RCOUNT FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V. WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 GROUP BY S.SNAP_ID ORDER BY S.SNAP_ID ASC
Gruppierung nach Modulen (Module, die eine einzelne logische Gruppe bilden, werden darin kombiniert), wobei das Objekt blockiert wird:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT (SELECT CASE (WHEN INSTR(S.MODULE, ' 1')>0 THEN ' 1' WHEN INSTR(S.MODULE, ' 2')>0 THEN ' 2' … ELSE S.MODULE END) MODULE, O.OBJECT_NAME FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 AND S.CURRENT_OBJ
Was hast du am Ende bekommen?
Dank des Portals konnten wir beim Vergleich von AWR-Dumps Zeit sparen. Der manuelle Vergleich dauerte 4-6 Stunden, und jetzt verbringen wir 2-3 Stunden. Wir haben immer die Möglichkeit, die Ergebnisse verschiedener Tests sowohl untereinander als auch mit einem Industriedump schnell zu vergleichen und die Filter einzustellen, die wir jetzt benötigen. Das heißt, wir können bequem historische Daten untereinander vergleichen und nicht nur das aktuelle Ergebnis online ansehen.
Zuvor war es nach jeder Regression erforderlich, die Ergebnisse in historischen Tabellen mit Abfragen an die Datenbank zu vergleichen, AWR-Berichte anzuzeigen, die problematische Erwartung zu lokalisieren (auf welchem Modul es auftritt, zu welchen Zeiten es passiert ist, an welchem Objekt es hängt), damit es am Ende zu einem Defekt im richtigen Entwicklungsteam führen kann. Und jetzt wählen Sie einfach die Dumps zum Vergleich aus, stellen die Filter ein - und die Ergebnisse des Vergleichs sind sofort fertig. Sie können Entwicklern auch einen Link zum Portal senden, der die DBID des Testdumps angibt, und sie selbst werden nach ihrem Modul gefiltert.
Die Erstellung des Portals dauerte nur zwei Wochen, da ein Teil davon bereits fertig war: das Laden von Dumps in die Datenbank. Natürlich wird eine solche Portallösung für kein Projekt mit einer Oracle-Basis benötigt. Es ist nützlich für Produkte, die in zahlreiche Module mit unterschiedlichen Namen unterteilt sind. Bei einfachen Systemen oder bei Systemen, bei denen dem Ausfüllen des Moduls keine Bedeutung beigemessen wurde, ist das Portal redundant.
Da das Portal Bilder analysiert, die in einem bestimmten Zeitraum einmal aufgenommen wurden, ist das Portal nicht vollständig von der Online-Überwachung der Datenbank ausgenommen, da einige Ereignisse möglicherweise nicht in das Bild gelangen können.
Dies ist ein praktisches Tool zum Analysieren historischer Daten aus den Testergebnissen. Es kann jedoch auch in anderen Situationen hilfreich sein, wenn viele Bilder erstellt werden und große Datenmengen überprüft werden müssen. Dank der Kombination von Filtern und Diagrammen können Sie sofort Ereignisausbrüche sehen, die in normalen AWR-Berichten (nicht zu verwechseln mit Speicherauszügen) in den gruppierten Informationen ausgeblendet werden. Es reicht aus, Dumps zum Vergleich auszuwählen, Filter zu setzen - und die Vergleichsergebnisse sind sofort fertig, oder Sie können einen Link an die Entwickler auf dem Portal mit der DBID des Testdumps senden, sie selbst werden von ihrem Modul gefiltert.
Wenn Sie ein ähnliches Portal für Ihr Projekt entwickeln möchten, wählen Sie die für Sie geeigneten Filter aus. Wenn Sie jedes Mal nach unterschiedlichen Bedingungen filtern, ist es viel einfacher, einen geeigneten Filter dafür zu erstellen.
Die resultierende Lösung kann noch finalisiert werden, zum Beispiel:
- Vergleichen der Dauer der Anfrage;
- Abfragepläne vergleichen;
- Vergleichen von Anfragen mit demselben Plan, jedoch mit unterschiedlichem Text;
- Entladen in Testberichte (Ausführung als Word / Exel-Dokument).
Oder weisen Sie das Portal im Allgemeinen an, eine Verbindung zur getesteten Datenbank herzustellen, damit ähnliche Online-Bilder mit In-Memory-Ansichten und nicht nur mit historischen Daten erstellt werden. Und speichern Sie sie in Ihrer Datenbank.
Wir nutzen das Portal seit mehr als einem Jahr. Fred, vielen Dank!
Gepostet von Lyudmila Matskus,
Jet Infosystems