Täglich erstellen immer mehr Geräte mehr Daten. Sie müssen an verschiedenen Stellen verwaltet werden und nicht in mehreren zentralen Cloud-Rechenzentren. Mit anderen Worten, der Verwaltungsprozess geht über die Grenzen herkömmlicher Rechenzentren hinaus und bewegt sich an den Ort, an dem die Daten erstellt werden - an die Peripherie des Netzwerks, näher an den Endbenutzern. Hier werden Daten von verschiedenen Sensoren, Kameras, Geräten und Internet of Things (IoT) -Geräten generiert. Wenn die Ergebnisse ihrer Arbeit direkt an der Netzwerkgrenze gesammelt und verarbeitet werden, können sie viel schneller analysiert und verwendet werden.

Laut
Gartner-Experten werden bis 2020 mehr als 50% aller von Unternehmen generierten Daten außerhalb der traditionellen Rechenzentren oder der Cloud-Umgebung verarbeitet (heute sind es nur noch 10%). In dieser Architektur funktionieren 5,6 Milliarden IoT-Geräte (Internet of Things). Gleichzeitig werden die von Geräten erzeugten Datenmengen in Terabyte berechnet und müssen häufig in Echtzeit interpretiert und analysiert werden.
Um Partnern und Kunden dabei zu helfen, diesen Trend zu erkunden, hat sich Seagate mit einem Konsortium von Unternehmen zusammengetan, die sich auf Peripherie-Computing spezialisiert haben, und den
Data at the Edge- Bericht veröffentlicht. Es wurden auch die Ergebnisse einer von IDC durchgeführten
Studie verwendet . Ziel des Berichts war es, einige der Datenprobleme zu veranschaulichen, die für Unternehmen heute relevant sind, und zu zeigen, wie Unternehmen ihre IT-Ressourcen besser verwalten können.
Peripheres Rechnen
„Die Akteure auf dem Speichermarkt haben mehrere Phasen in der Entwicklung ihres Geschäfts durchlaufen. Vor einigen Jahrzehnten galten Speicher für Serversysteme als vielversprechend, dann standen lokale Rechenzentren im Rampenlicht. Dies spiegelte sich in den Produktlinien der Anbieter wider: Sie begannen, Laufwerke für dieses Segment zu produzieren. Dann begann die Entwicklung von Cloud-Speicher, Cloud-Computing. Der nächste Schritt ist das Peripherie-Computing “, sagt Alexander Malinin, Direktor der Seagate-Repräsentanz in Russland und der GUS. - Da es viele Daten gibt, die nicht nur von Menschen, sondern auch von Maschinen generiert werden, ist es nicht immer optimal, all dies an das Rechenzentrum zu senden. Es ist sinnvoll, einen Teil der Berechnungen außerhalb der Rechenzentren durchzuführen und die verarbeiteten Ergebnisse in das Rechenzentrum zu übertragen. Tatsächlich ist dies die Schaffung einer weiteren Berechnungsschaltung, in der Daten gesammelt, einige Zeit gespeichert, verarbeitet und zur weiteren Speicherung und zum Zugriff auf das Hauptdatenzentrum übertragen werden. "
Da weiterhin Milliarden von Geräten eine Verbindung zum Netzwerk herstellen und Zettabyte an Daten sammeln und generieren, erfordern die heutigen zentralisierten Cloud-Umgebungen die Unterstützung einer neuen peripheren IT-Architektur. Indem Sie Computer-, Netzwerk- und Speicherressourcen in unmittelbarer Nähe dieser Geräte platzieren, können Sie Daten direkt vor Ort analysieren.
Aufgrund der Tatsache, dass die Daten an derselben Stelle, an der sie erstellt wurden, einer Primärverarbeitung unterzogen werden, kann ein Teil der Verwaltungsentscheidungen (z. B. zur Anpassung der Betriebsart von Industrieanlagen) mit minimaler Verzögerung lokal getroffen werden.
Die Peripherie kann sich überall befinden: von Fabrikgeschäften bis zu Bauernhöfen, auf Dächern von Häusern und auf Zelltürmen, in allen Fahrzeugen an Land, auf See und in der Luft. Als Außengrenze eines Netzwerks befindet es sich häufig Hunderte von Kilometern vom nächsten Unternehmens- oder Cloud-Rechenzentrum entfernt und sehr nahe an der Datenquelle.
Laut einer IDC-Studie werden bis 2020 45% aller von IoT-Geräten generierten Daten in oder in der Nähe der Grenzsegmente des Netzwerks gespeichert und verarbeitet. In vielen Fällen ist es besser, den Rechenprozess an die Peripherie zu verlagern. In „Smart Cities“ reduziert die Verarbeitung und Analyse von Daten, die näher an der Quelle liegen, die Verzögerungszeit und ermöglicht es verschiedenen Diensten, schneller auf die Situation zu reagieren.
In intelligenten Transportsystemen können Sie mit Peripherie-Computing Informationen lokal verarbeiten und nur die wichtigsten Daten an die Cloud senden. Diese Technologie wird bereits in intelligenten Verkehrssystemen eingesetzt. Dieser Ansatz verbessert auch die Sicherheit und Effizienz des Transports. Selbstfahrende Autos müssen sofort auf die empfangenen Daten reagieren, da selbst die geringste Verzögerung gefährlich sein kann.
Die Verbreitung von Peripherie-Computing erfordert eine neue Infrastruktur zum Speichern und Verwalten von Daten. Beispielsweise erstellt eine Smart Factory etwa 5 Petabyte Video pro Tag, eine Smart City mit 1 Million Einwohnern - 200 Petabyte Daten pro Tag und ein autonomes Auto - 4 Terabyte.
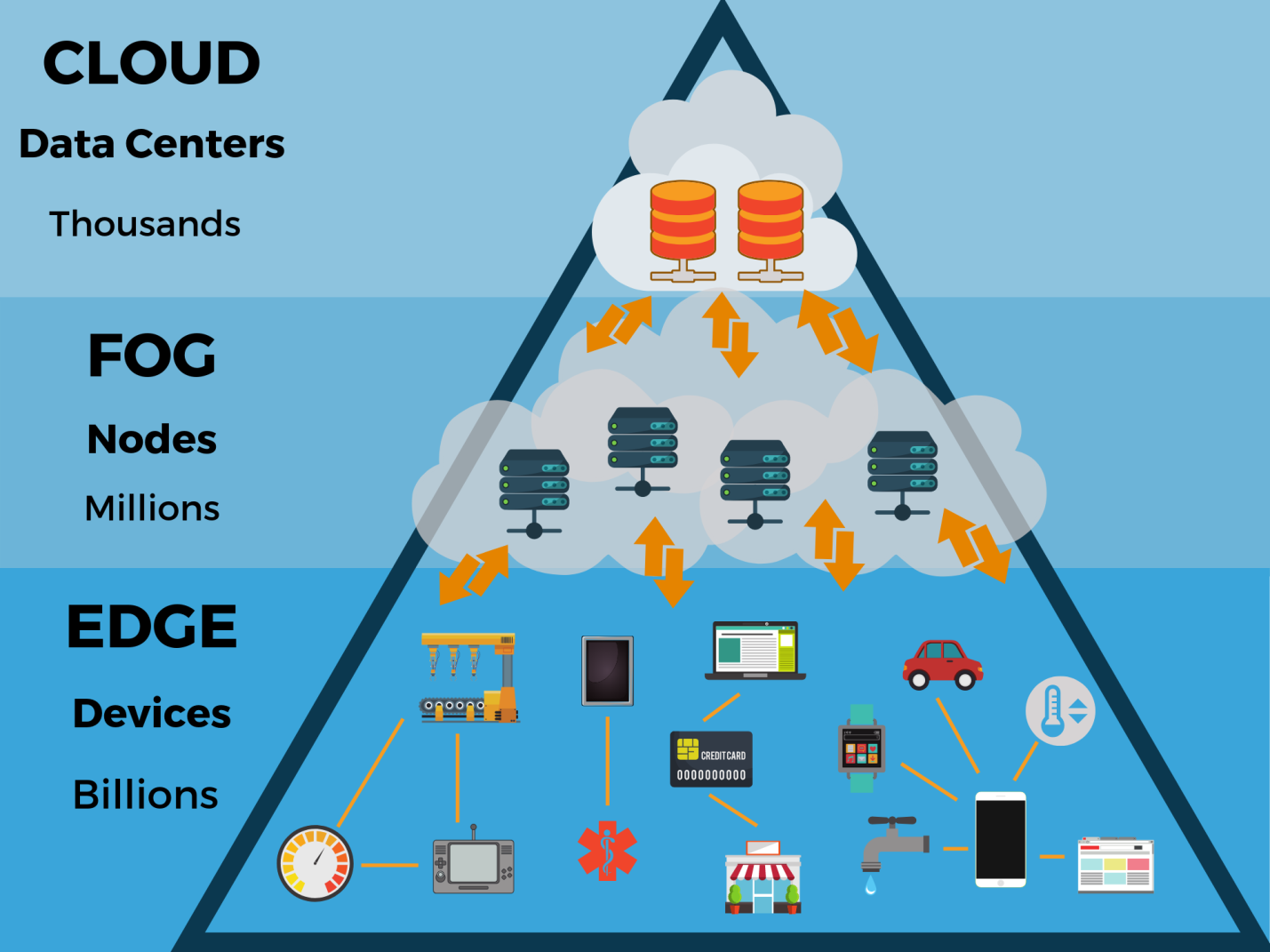
Was bedeuten diese Daten an der Grenze? Wie wird sich eine solche Entwicklung auf die Struktur und Funktionsweise bestehender Rechenzentren und Cloud-Rechenzentren auswirken? Könnte Cloud Computing, das heute vorherrscht, das Peripherie-Computing ersetzen, weil es flexibler und in Bezug auf Anwendungen skalierbar ist?
Wolken und Peripheriegeräte
Die Autoren des Berichts „
Data at the Edge “ betonen, dass Peripherie-Computing zwar eine effizientere Nutzung von Daten ermöglicht, die traditionelle Infrastruktur jedoch nicht an Bedeutung verliert. Da große Datenmengen außerhalb traditioneller Zentren ihrer Verarbeitung erstellt werden, wird die Cloud bis zur Peripherie erweitert. Das heißt, es geht nicht um das Szenario „Wolke gegen die Peripherie“, sondern um die „Wolke mit der Peripherie“.
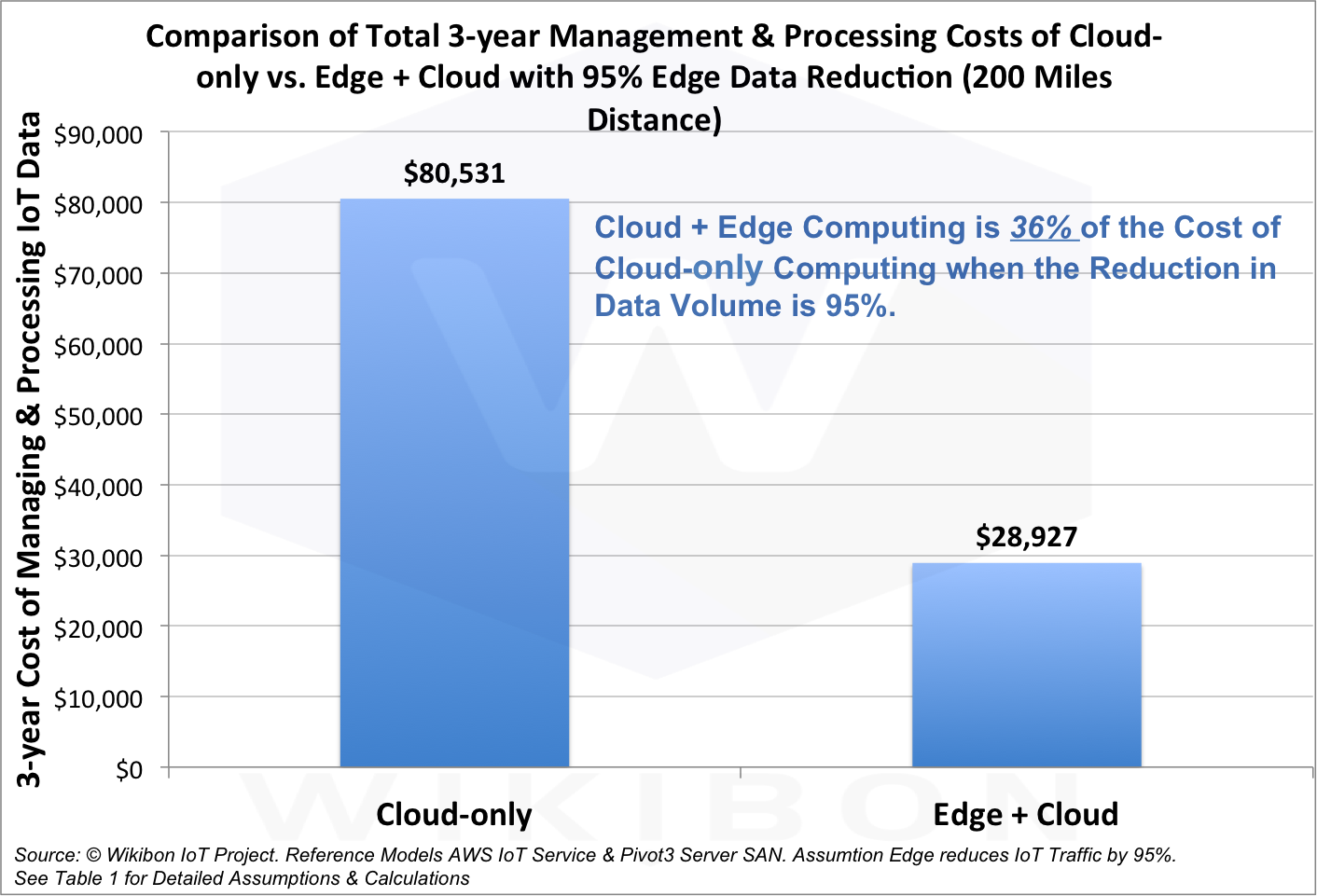
Laut Analysten kostet die Kombination von Cloud- und Peripherie-Computing nur 36% der Kosten einer reinen Cloud-Version, und die übertragene Datenmenge wird um 95% reduziert.
Die Zukunft liegt also in der gemeinsamen Arbeit von Peripherie und Cloud. Auf diese Weise können Unternehmen sofort fundiertere Entscheidungen treffen, ihre Produktivität steigern, effizienter arbeiten und die Kundenbedürfnisse besser erfüllen.
Datenbasiertes Geschäft
Heutzutage ist fast jedes Unternehmen oder jede Organisation mit der Verarbeitung und Speicherung von Daten verbunden. Innovationen im Informationsmanagement ebneten den Weg für effizientere Einsatzmöglichkeiten. Dies gilt auch für Peripheriedaten.
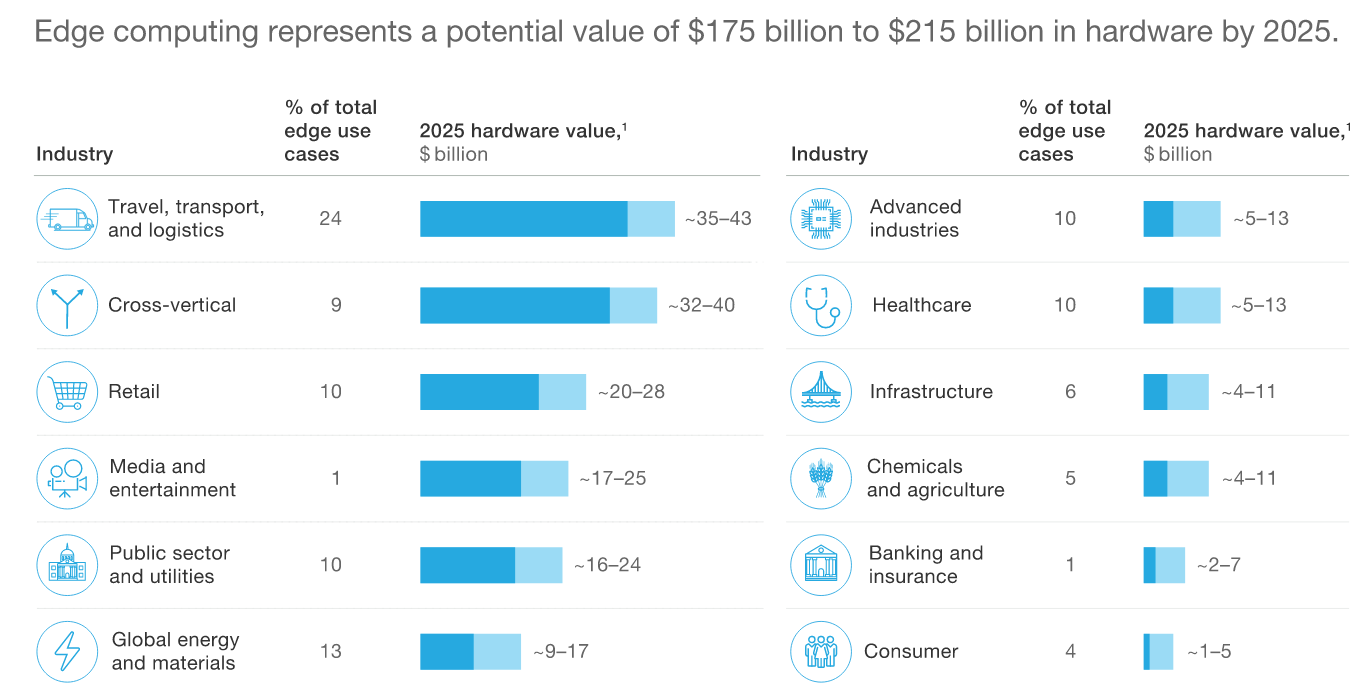
Laut
McKinsey wird der weltweite Markt für Peripheriegeräte bis 2025 175 bis 215 Milliarden US-Dollar erreichen.
Peripheriegeräte und Leben
Was bedeutet dies für große Unternehmen, Städte, kleine Unternehmen und einzelne Verbraucher, was sind die Vorteile? Wie helfen uns Daten an der Peripherie, besser zu arbeiten, uns zu entspannen, zu leben und zu reisen? Welche Möglichkeiten zur Datenanalyse ergeben sich am Rande des Netzwerks? Dies sind die Fragen, die der Seagate-Bericht beantwortet.
Data at the Edge bietet mehrere Beispiele dafür, wie Peripherie-Computing das globale Geschäft heute verändert und den Menschen zugute kommt. In Chile beispielsweise reduziert ein mit Sensoren ausgestattetes Bewässerungssystem mit künstlicher Intelligenz den Wasserverbrauch um 70%.
Aber was passiert in den eigenen Fabriken von Seagate? Das Unternehmen produziert vierteljährlich Millionen von Einheiten und jährlich Milliarden von Sensoren. Dies erfordert die Einführung hochautomatisierter Prozesse, und das System muss 20 bis 30 Entscheidungen pro Sekunde treffen. Bei dieser Geschwindigkeit bleibt keine Zeit zu warten, bis die auf der Produktionslinie gesammelten Daten zur Verarbeitung an das Zentrum gesendet werden, und von dort kommt eine Lösung.

Wir können die Produktionslinie nicht stoppen: Wir müssen das Produktionstempo beibehalten und gleichzeitig die hohe Qualität sicherstellen. Entscheidungen müssen also an derselben Stelle getroffen werden, an der die Daten generiert werden. Zu diesem Zweck hat Seagate eine eigene Technologie zur Erkennung von Anomalien und zur Analyse von Bildern auf dem Werksgelände entwickelt. Dies reduziert die Latenz von Hunderten auf weniger als 10 Millisekunden.
Peripherie-Computing in Russland
„Wie weit verbreitet sind Peripheriegeräte in Russland? Erstens braucht die Einführung neuer Technologien Zeit. Zweitens ist der Begriff "Peripherie-Computing" selbst noch nicht in Gebrauch gekommen. Das heißt, auch wenn das Unternehmen diesen Ansatz verwendet, nennt es ihn anders “, erklärt Alexander Malinin. - In der Zwischenzeit wird Peripherie-Computing häufig eingesetzt, beispielsweise in der Geodäsie, in der Öl- und Gasindustrie. Vermessungsdaten werden in einem kleinen lokalen Rechenzentrum gesammelt und verarbeitet und dann an ein zentrales Repository gesendet. Peripherie-Computing wird auch in der Öl- und Gasindustrie eingesetzt, wo eine große Datenmenge gesammelt wird und nicht alle gespeichert werden müssen. “
„Mit der Entwicklung der Telekommunikation und der zunehmenden Geschwindigkeit der Datenübertragung wird die Anzahl der peripheren Rechenzentren nur noch zunehmen“, fährt Alexander Malinin fort. - Ja, und der Begriff "Peripherie-Computing" selbst wird weiter verbreitet sein. Die Datenspeicherbranche hat etwas zu bieten. Es gibt verschiedene Speichertechnologien, die unterschiedliche Aufgaben erfüllen, es gibt mathematische Algorithmen für die Datenanalyse. Das Hauptproblem liegt nun in der Telekommunikationstechnologie beim Erhalten von Daten. Beispielsweise bietet das Internet der Dinge eine weit verbreitete Nutzung drahtloser Verbindungen. Dies erfordert die Bereitstellung von drahtlosen Netzwerken wie 5G. Ähnliche Prozesse fanden mit der Einführung der Big-Data-Technologie statt. Sie haben bereits damit begonnen, aber sie haben es anders genannt: Es ist eine Frage der Terminologie. "
Wachstumsfaktoren
Was treibt die Nachfrage nach einer neuen Computerarchitektur an? Basierend auf Untersuchungen und Umfragen unter IT-Managern bei Seagate wurden
vier Schlüsselfaktoren identifiziert, die die Nachfrage nach Peripherie-Computing bestimmen. Dies ist die Netzwerklatenz (Latenz); unzureichende Bandbreite der Kommunikationskanäle für die Lieferung großer Datenmengen an das Rechenzentrum; Effizienz und Kosten der Lösung; Datenhoheit und Compliance.
1. Latenz
Der wichtigste Faktor ist die Latenz. Aufgrund der physischen Einschränkungen der IT- und Telekommunikationsinfrastruktur dauert es zu lange, um die Daten von ihrem Erstellungsort an den zentralen Standort zu verschieben. Die Latenz wird somit zu einem Schlüsselfaktor: Das Senden von Daten zum und vom zentralen Standort kann sowohl 100 als auch 200 Millisekunden dauern.
2. Bandbreite
Faktor Nummer zwei ist das Bandbreitenproblem. Das gesamte Datenvolumen beträgt nicht mehr Exabyte, sondern Zettabyte. Und sie wachsen weiter, schon allein aufgrund des Auftretens neuer Sensoren - nicht nur Temperatur-, Wetter-, Vibrations- oder andere Sensoren, die relativ wenig Daten erfassen, sondern auch Kameras, Radargeräte, Lidare und andere Geräte, die viele Informationen generieren. In Zukunft wird es noch mehr solcher Sensoren geben. Die 5G-Infrastruktur kann Millionen von Geräten pro Quadratkilometer unterstützen. Wo finde ich jedoch die Bandbreite, um alle Daten an ein zentrales Cloud-Rechenzentrum zu senden?
3. Effizienz
Drittens Effizienz. Selbst wenn Sie alle Daten an ein zentrales Rechenzentrum senden können, sind die Kosten und die Komplexität der Architektur für die Verarbeitung einer so großen Informationsmenge so hoch, dass das System schlecht verwaltet wird. Mit einem System, das Daten an der Peripherie, näher an der Quelle, intensiv verarbeitet, sind die Dinge viel besser.
4. Regulatorische Anforderungen und Unternehmensstandards
Der vierte Faktor ist schließlich die Anforderung, dass die Daten gemäß den von den Kunden akzeptierten Normen und Standards verarbeitet werden müssen. Wenn Sie sich mit Informationssicherheit befassen, können Sie häufig keine Daten aus einer bestimmten Region oder einem bestimmten Land im Ausland zur zentralen Verarbeitung senden. Dies gilt beispielsweise für personenbezogene Daten.
"Peripheral Computing erfordert spezielle Ansätze zur Regulierung der Datenspeicherung und zur Gewährleistung der Sicherheit, einschließlich der Sicherheit des physischen Zugriffs auf Daten", betont Alexander Malinin. "Aber wir werden in den nächsten zwei bis drei Jahren definitiv eine Zunahme des Peripherie-Computing sehen, da die Anzahl der Anfragen von Unternehmen nach kleinen Rechenzentren wächst, die sowohl einzelne Branchen als auch große nationale Unternehmen bedienen würden." Das heißt, die Anzahl der Anfragen zur Organisation der lokalen Datenspeicherung wächst. “
Neue Architektur
Was bedeutet das für IT-Architekten, was sollten sie anders machen? Zunächst unterscheidet sich der Entwurf der traditionellen Infrastruktur eines Rechenzentrums oder Cloud-Rechenzentrums stark von der Entwicklung der Peripheriearchitektur. Zu den traditionellen Rechenzentren gehören Kühl- und Klimaanlagen, doppelt redundante unterbrechungsfreie Stromversorgungen und physische Sicherheitssysteme. Sie werden von einem ganzen Team von Spezialisten bedient.
Das periphere Rechenzentrum (oder vielmehr der Knoten) der Datenverarbeitung kann sich auf einem Telekommunikationsturm oder in einem kleinen Raum befinden. Es ist häufig der äußeren Umgebung ausgesetzt, daher ist seine Klimatisierung eine schwierige Aufgabe.
In Bezug auf die physische Sicherheit muss die Architektur einen speziellen Datenschutz für Naturkatastrophen oder böswillige Handlungen enthalten. Darüber hinaus müssen Peripheriesysteme aufgrund des Personalmangels, der schnell alles reparieren kann, besonders zuverlässig sein. Wenn etwas passiert, sollte sich das periphere Rechenzentrum selbst wiederherstellen und weiterarbeiten.
Mit anderen Worten, wenn wir Daten an der Peripherie verarbeiten möchten, müssen wir die Funktionalität des Rechenzentrums perfektionieren: Kühlung, Sicherheit usw. Systemarchitekten arbeiten bereits daran, Lösungen zu finden. Ziel ist es, periphere Rechenzentren zu vereinfachen und eine ausreichende Telemetrie bereitzustellen.
Außerdem bleiben einige der Daten, die an der Peripherie verarbeitet werden, nicht dort. Sie werden zur weiteren Analyse oder längeren Lagerung ins Zentrum gebracht. Ein IT-Architekt muss diesen Prozess durchdenken, indem er eine Datenverwaltungsstrategie definiert.
Unternehmen müssen sich auf ihre Cloud-Computing-Architektur verlassen, lernen, mehr Daten am Rande zu verarbeiten und vor allem sicher zu speichern.
Der
Peripheriedatenbericht von Seagate und Vapor IO besagt, dass jedes Unternehmen einen Wert hat, den es nicht einmal vermutet. Dies sind ihre eigenen Daten. Die Art und Weise, wie wir Daten erstellen und mit der Peripherie des Netzwerks arbeiten, gibt ihm eine besondere Bedeutung. Um weiter zu wachsen, müssen Unternehmen dies nutzen.
„Die Probleme bei der Implementierung von Peripherie-Computern hängen jetzt hauptsächlich mit der Telekommunikation und der Geschwindigkeit des Datenzugriffs zusammen. Je schneller die Einführung von Telekommunikationstechnologien der nächsten Generation in Russland beginnt, desto schneller wird sich das Peripherie-Computing entwickeln “, sagt Alexander Malinin. - Gleichzeitig wird sich das Peripherie-Computing parallel zu bestehenden Rechenzentren entwickeln und diese ergänzen. Eine radikale Umstrukturierung ist nicht erforderlich. “
Gartner prognostiziert, dass bis 2021 40% der Unternehmen weltweit umfassende Strategien für periphere Computer entwickeln werden. Daher haben es die Anbieter jetzt eilig, eine vielversprechende Nische zu besetzen. In den nächsten fünf Jahren wird der Markt aktiv gestaltet, neue Plattformen und schlüsselfertige Lösungen erscheinen, die sich auf verschiedene Aufgaben und Branchen konzentrieren. Unternehmen, die sich mit der Entwicklung von Peripherie-Computern befassen, können in neuen Geschäftsbereichen führend werden.