Das von
mir geschriebene Befehlszeilentool Sloc Cloc and Code (scc) , das jetzt fertiggestellt und von vielen großartigen Personen unterstützt wird, zählt Codezeilen, Kommentare und bewertet die Komplexität von Dateien in einem Verzeichnis. Hier wird eine gute Auswahl benötigt. Das Tool zählt Verzweigungsoperatoren im Code. Aber was ist Komplexität? Zum Beispiel ist die Aussage "Diese Datei hat Schwierigkeit 10" ohne Kontext nicht sehr nützlich. Um dieses Problem zu lösen, habe ich
scc auf allen Quellen im Internet ausgeführt. Auf diese Weise können Sie auch einige Extremfälle finden, die ich im Tool selbst nicht berücksichtigt habe. Leistungsstarker Brute-Force-Test.
Wenn ich den Test jedoch für alle Quellen der Welt ausführen möchte, sind viele Rechenressourcen erforderlich, was ebenfalls eine interessante Erfahrung ist. Deshalb habe ich beschlossen, alles aufzuschreiben - und dieser Artikel erschien.
Kurz gesagt, ich habe viele Quellen heruntergeladen und verarbeitet.
Nackte Figuren:
- Insgesamt 9.985.051 Repositories
- 9.100.083 Repositorys mit mindestens einer Datei
- 884 968 leere Repositorys (ohne Dateien)
- 3.500.000.000 Dateien in allen Repositorys
- Verarbeitet 40 736 530 379 778 Bytes (40 TB)
- 1.086.723.618.560 Zeilen identifiziert
- 816.822.273.469 Zeilen mit erkanntem Code
- 124 382 152 510 Leerzeilen
- 145 519 192 581 Kommentarzeilen
- Gesamtkomplexität nach scc-Regeln: 71 884 867 919
- 2 neue Fehler in scc gefunden
Lassen Sie uns nur ein Detail erwähnen. Es gibt nicht 10 Millionen Projekte, wie im hochkarätigen Titel angegeben. Ich habe 15.000 verpasst und es abgerundet. Ich entschuldige mich dafür.
Es dauerte ungefähr fünf Wochen, um alles herunterzuladen, scc durchzugehen und alle Daten zu speichern. Dann etwas mehr als 49 Stunden, um 1 TB JSON zu verarbeiten und die folgenden Ergebnisse zu erhalten.
Beachten Sie auch, dass ich mich bei einigen Berechnungen irren könnte. Ich werde Sie umgehend informieren, wenn ein Fehler festgestellt wird, und einen Datensatz bereitstellen.
Inhaltsverzeichnis
Methodik
Seit dem Start von
searchcode.com habe ich bereits eine Sammlung von mehr als 7.000.000 Projekten zu Git, Mercurial, Subversion usw. gesammelt. Warum also nicht verarbeiten? Die Arbeit mit Git ist normalerweise die einfachste Lösung. Deshalb habe ich diesmal Quecksilber und Subversion ignoriert und eine vollständige Liste der Git-Projekte exportiert. Es stellt sich heraus, dass ich tatsächlich 12 Millionen Git-Repositories verfolgt habe, und ich muss wahrscheinlich die Hauptseite aktualisieren, um dies widerzuspiegeln.
Jetzt habe ich 12 Millionen Git-Repositories zum Herunterladen und Verarbeiten.
Wenn Sie scc ausführen, können Sie die Ausgabe in JSON auswählen, indem Sie die Datei auf der Festplatte speichern:
scc --format json --output myfile.json main.go Die Ergebnisse sind wie folgt (für eine einzelne Datei):
[ { "Blank": 115, "Bytes": 0, "Code": 423, "Comment": 30, "Complexity": 40, "Count": 1, "Files": [ { "Binary": false, "Blank": 115, "Bytes": 20396, "Callback": null, "Code": 423, "Comment": 30, "Complexity": 40, "Content": null, "Extension": "go", "Filename": "main.go", "Hash": null, "Language": "Go", "Lines": 568, "Location": "main.go", "PossibleLanguages": [ "Go" ], "WeightedComplexity": 0 } ], "Lines": 568, "Name": "Go", "WeightedComplexity": 0 } ]
Ein größeres Beispiel finden Sie in den Ergebnissen für das redis-Projekt:
redis.json . Alle folgenden Ergebnisse werden aus einem solchen Ergebnis ohne zusätzliche Daten erhalten.
Es sollte beachtet werden, dass scc normalerweise Sprachen basierend auf der Erweiterung klassifiziert (es sei denn, die Erweiterung ist üblich, wie Verilog und Coq). Wenn Sie also eine HTML-Datei mit der Java-Erweiterung speichern, wird sie als Java-Datei betrachtet. Dies ist normalerweise kein Problem, denn warum tun Sie das? Aber natürlich macht sich das Problem im großen Maßstab bemerkbar. Ich entdeckte dies später, als einige Dateien als andere Erweiterung getarnt wurden.
Vor einiger Zeit habe ich
Code zum Generieren von scc-basierten Github-Tags geschrieben . Da der Prozess zum Zwischenspeichern der Ergebnisse erforderlich war, habe ich ihn ein wenig geändert, um sie im JSON-Format in AWS S3 zwischenzuspeichern.
Mit dem Code für Beschriftungen in AWS auf Lambda nahm ich eine exportierte Liste von Projekten, schrieb ungefähr 15 Python-Zeilen, um das Format zu löschen, das meinem Lambda entspricht, und stellte eine Anfrage an dieses. Mit Python-Multiprocessing habe ich Anforderungen an 32 Prozesse parallelisiert, sodass der Endpunkt schnell genug reagierte.
Alles hat hervorragend funktioniert. Das Problem bestand jedoch erstens in den Kosten, und zweitens hat Lambda eine Zeitüberschreitung von 30 Sekunden für API Gateway / ALB, sodass große Repositorys nicht schnell genug verarbeitet werden können. Ich wusste, dass dies nicht die wirtschaftlichste Lösung war, aber ich dachte, dass der Preis ungefähr 100 Dollar betragen würde, was ich ertragen würde. Nachdem ich eine Million Repositories verarbeitet hatte, überprüfte ich sie - und die Kosten betrugen ungefähr 60 US-Dollar. Da ich mit der Aussicht auf ein endgültiges AWS-Konto von 700 US-Dollar nicht zufrieden war, beschloss ich, meine Entscheidung zu überdenken. Beachten Sie, dass dies im Grunde der Speicher und die CPU waren, die zum Sammeln all dieser Informationen verwendet wurden. Jede Verarbeitung und jeder Export von Daten erhöhte den Preis erheblich.
Da ich bereits in AWS war, bestand eine schnelle Lösung darin, die URLs als Nachrichten in SQS zu löschen und sie mithilfe von EC2- oder Fargate-Instanzen zur Verarbeitung abzurufen. Dann skaliere wie verrückt. Trotz der alltäglichen Erfahrung mit AWS habe ich immer an die
Prinzipien der Taco Bell-Programmierung geglaubt. Außerdem gab es nur 12 Millionen Repositorys, sodass ich mich entschied, eine einfachere (billigere) Lösung zu implementieren.
Das Starten der Berechnung vor Ort war aufgrund des schrecklichen Internets in Australien nicht möglich. Mein searchcode.com arbeitet jedoch mit den dedizierten Servern von Hetzner. Dies sind ziemlich leistungsstarke i7 Quad Core 32-GB-RAM-Computer, häufig mit 2 TB Speicherplatz (normalerweise nicht verwendet). Sie verfügen normalerweise über eine gute Rechenleistung. Beispielsweise berechnet der Front-End-Server die meiste Zeit die Quadratwurzel von Null. Warum also nicht dort mit der Verarbeitung beginnen?
Dies ist nicht wirklich Taco Bell-Programmierung, da ich die Bash- und Gnu-Tools verwendet habe. Ich habe ein
einfaches Programm für Go geschrieben , um 32 Go-Routinen auszuführen, die Daten von einem Kanal lesen, Git- und Scc-Unterprozesse generieren, bevor die Ausgabe in S3 in JSON geschrieben wird. Ich habe die Lösung tatsächlich zuerst in Python geschrieben, aber die Notwendigkeit, Pip-Abhängigkeiten auf meinem sauberen Server zu installieren, schien eine schlechte Idee zu sein, und das System stürzte auf seltsame Weise ab, die ich nicht debuggen wollte.
Das Ausführen all dessen auf dem Server führte zu den folgenden Metriken in htop, und mehrere ausgeführte git / scc-Prozesse (scc wird in diesem Screenshot nicht angezeigt) gingen davon aus, dass alles wie erwartet funktionierte, was durch die Ergebnisse in S3 bestätigt wurde.

Präsentation und Berechnung der Ergebnisse
Ich habe
diese Artikel kürzlich gelesen und hatte daher die Idee, das Format dieser Beiträge in Bezug auf die Präsentation von Informationen auszuleihen. Ich wollte jedoch auch große Tabellen mit
jQuery DataTables versehen , um die Ergebnisse zu sortieren und zu suchen / filtern. Daher können Sie im
Originalartikel auf die Überschriften klicken, um sie zu sortieren, und das Suchfeld zum Filtern verwenden.
Die Größe der Daten, die verarbeitet werden mussten, warf eine andere Frage auf. Wie werden 10 Millionen JSON-Dateien verarbeitet, die etwas mehr als 1 TB Speicherplatz im S3-Bucket belegen?
Der erste Gedanke war AWS Athena. Da es für einen solchen Datensatz etwa 2,50 USD
pro Abfrage kosten würde, suchte ich schnell nach einer Alternative. Wenn Sie die Daten dort speichern und nur selten verarbeiten, ist dies möglicherweise die günstigste Lösung.
Ich habe im Unternehmenschat eine Frage gestellt (warum Probleme alleine lösen).
Eine Idee war, Daten in eine große SQL-Datenbank zu sichern. Dies bedeutet jedoch, dass die Daten in der Datenbank verarbeitet und dann mehrmals Abfragen ausgeführt werden. Außerdem bedeutet die Datenstruktur mehrere Tabellen, dh Fremdschlüssel und Indizes, um ein bestimmtes Leistungsniveau bereitzustellen. Dies scheint verschwenderisch zu sein, da wir die Daten einfach so verarbeiten können, wie wir sie von der Festplatte lesen - in einem Durchgang. Ich war auch besorgt darüber, eine so große Datenbank zu erstellen. Nur mit Daten ist die Größe vor dem Hinzufügen von Indizes größer als 1 TB.
Als ich sah, wie ich JSON auf einfache Weise erstellt habe, dachte ich mir, warum nicht die Ergebnisse auf die gleiche Weise verarbeiten? Natürlich gibt es ein Problem. Das Abrufen von 1 TB Daten aus S3 kostet viel. Wenn das Programm abstürzt, ist es ärgerlich. Um die Kosten zu senken, wollte ich alle Dateien lokal herausziehen und zur weiteren Verarbeitung speichern. Guter Rat: Es ist besser, nicht
viele kleine Dateien in einem Verzeichnis zu speichern. Dies beeinträchtigt die Laufzeitleistung, und Dateisysteme mögen das nicht.
Meine Antwort darauf war ein weiteres einfaches
Go-Programm, mit dem Dateien aus S3 abgerufen und dann in einer TAR-Datei gespeichert werden konnten. Dann könnte ich diese Datei immer wieder verarbeiten. Der Prozess selbst führt ein
sehr hässliches Go-Programm aus , um die TAR-Datei zu verarbeiten, sodass ich die Abfragen erneut ausführen kann, ohne immer wieder Daten aus S3 abrufen zu müssen. Ich habe mich hier aus zwei Gründen nicht mit Go-Routinen beschäftigt. Erstens wollte ich den Server nicht so oft wie möglich laden, daher beschränkte ich mich auf einen Kern, damit die CPU hart arbeiten konnte (der andere war größtenteils auf dem Prozessor gesperrt, um die TAR-Datei zu lesen). Zweitens wollte ich die Gewindesicherheit gewährleisten.
Als dies erledigt war, wurde eine Reihe von Fragen benötigt, um zu beantworten. Ich nutzte wieder den kollektiven Verstand und verband meine Kollegen, während ich meine eigenen Ideen einbrachte. Das Ergebnis dieser Verschmelzung der Gedanken wird unten dargestellt.
Sie finden den
gesamten Code , den ich zur Verarbeitung von JSON verwendet habe, einschließlich des Codes für die lokale Verarbeitung, und das
hässliche Python-Skript , mit dem ich etwas Nützliches für diesen Artikel vorbereitet habe: Bitte kommentieren Sie es nicht, ich weiß, dass der Code hässlich ist und es ist für eine einmalige Aufgabe geschrieben, da ich es wahrscheinlich nie wieder anschauen werde.
Wenn Sie den Code sehen möchten, den ich für den allgemeinen Gebrauch geschrieben habe, schauen Sie sich die
scc-Quellen an .
Kosten
Ich habe ungefähr 60 Dollar für Computer ausgegeben, als ich versucht habe, mit Lambda zu arbeiten. Ich habe mir die Kosten für die Speicherung von S3 noch nicht angesehen, aber sie sollten je nach Größe der Daten nahe bei 25 US-Dollar liegen. Dies beinhaltet jedoch nicht die Übertragungskosten, die ich auch nicht gesehen habe. Bitte beachten Sie, dass ich den Eimer gereinigt habe, als ich damit fertig war. Dies sind also keine festen Kosten.
Aber nach einer Weile habe ich AWS immer noch verlassen. Was sind die tatsächlichen Kosten, wenn ich es noch einmal tun wollte?
Alle Software, die wir haben, ist kostenlos und kostenlos. Es gibt also nichts, worüber man sich Sorgen machen müsste.
In meinem Fall wären die Kosten Null, da ich die "freie" Rechenleistung von searchcode.com verwendet habe. Allerdings hat nicht jeder solche freien Ressourcen. Nehmen wir daher an, dass die andere Person dies wiederholen möchte und den Server erhöhen muss.
Dies kann für 73 € mit dem billigsten neuen
dedizierten Server von Hetzner erfolgen , einschließlich der Kosten für die Installation eines neuen Servers. Wenn Sie warten und sich
mit Auktionen befassen , finden Sie viel billigere Server ohne Installationsgebühren. Zum Zeitpunkt des Schreibens fand ich ein Auto, das perfekt für dieses Projekt geeignet ist, für 25,21 € pro Monat ohne Installationsgebühren.
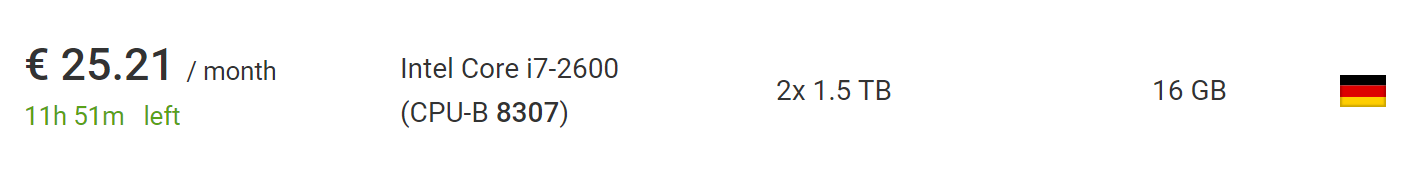
Was noch besser ist, außerhalb der Europäischen Union wird die Mehrwertsteuer von diesem Preis abgezogen. Nehmen Sie also weitere 10%.
Wenn Sie einen solchen Service in meiner Software von Grund auf neu erstellen, kostet er letztendlich bis zu 100 US-Dollar, aber bis zu 50 US-Dollar, wenn Sie ein wenig geduldig oder erfolgreich sind. Dies setzt voraus, dass Sie den Server seit weniger als zwei Monaten verwenden, was zum Herunterladen und Verarbeiten ausreicht. Es bleibt auch genügend Zeit, um eine Liste mit 10 Millionen Repositories zu erstellen.
Wenn ich einen gezippten Teer verwenden würde (was eigentlich gar nicht so schwierig ist), könnte ich zehnmal mehr Repositorys auf demselben Computer verarbeiten, und die resultierende Datei bleibt immer noch klein genug, um auf dieselbe Festplatte zu passen. Der Vorgang kann zwar mehrere Monate dauern, da der Download länger dauert.
Um weit über die 100 Millionen Repositories hinauszugehen, ist jedoch eine Art Sharding erforderlich. Trotzdem kann man mit Sicherheit sagen, dass Sie den Vorgang in meinem Maßstab oder viel größer auf demselben Gerät ohne großen Aufwand oder Codeänderungen wiederholen werden.
Datenquellen
So viele Projekte kamen aus drei Quellen: Github, Bitbucket und Gitlab. Bitte beachten Sie, dass dies vor dem Ausschluss leerer Repositorys erfolgt. Daher überschreitet der Betrag die Anzahl der Repositorys, die tatsächlich verarbeitet und in den folgenden Tabellen berücksichtigt werden.
Ich entschuldige mich bei den Mitarbeitern von GitHub / Bitbucket / GitLab, wenn Sie dies lesen. Wenn mein Skript Probleme verursacht hat (obwohl ich es bezweifle), trinke ich einen Drink Ihrer Wahl, wenn ich mich treffe.
Wie viele Dateien befinden sich im Repository?
Kommen wir zu den eigentlichen Themen. Beginnen wir mit einem einfachen. Wie viele Dateien befinden sich im durchschnittlichen Repository? Die meisten Projekte haben nur ein paar Dateien oder mehr? Nach dem Durchlaufen der Repositorys erhalten wir den folgenden Zeitplan:

Hier zeigt die X-Achse Buckets mit der Anzahl der Dateien und die Y-Achse zeigt die Anzahl der Projekte mit dieser Anzahl von Dateien. Begrenzen Sie die horizontale Achse auf tausend Dateien, da sich das Diagramm dann zu nahe an der Achse befindet.
Es scheint, dass die meisten Repositorys weniger als 200 Dateien haben.
Aber was ist mit der Visualisierung bis zum 95. Perzentil, die das reale Bild zeigt? Es stellt sich heraus, dass in der überwiegenden Mehrheit (95%) der Projekte weniger als 1000 Dateien vorhanden sind. Während 90% der Projekte weniger als 300 Dateien und 85% weniger als 200 haben.

Wenn Sie selbst ein Diagramm erstellen und es besser als ich machen möchten, finden Sie hier einen
Link zu den Rohdaten in JSON .
Was ist die Sprachaufteilung?
Wenn beispielsweise eine Java-Datei identifiziert wird, erhöhen wir die Anzahl der Java-Dateien in den Projekten um eins und tun nichts für die zweite Datei. Dies gibt eine schnelle Vorstellung davon, welche Sprachen am häufigsten verwendet werden. Es überrascht nicht, dass die häufigsten Sprachen Markdown, .gitignore und Klartext sind.
Markdown ist die am häufigsten verwendete Sprache und wird in mehr als 6 Millionen Projekten verwendet, was etwa 2⁄3 der Gesamtzahl entspricht. Dies ist sinnvoll, da fast alle Projekte README.md enthalten, das in HTML für Repository-Seiten angezeigt wird.
Wie viele Dateien befinden sich nach Sprache im Repository?
Ergänzung zur vorherigen Tabelle, jedoch gemittelt über die Anzahl der Dateien für jede Sprache im Repository. Das heißt, wie viele Java-Dateien existieren durchschnittlich für alle Projekte, in denen Java vorhanden ist?
Wie viele Codezeilen enthält eine typische Sprachdatei?
Ich nehme an, es ist immer noch interessant zu sehen, welche Sprachen im Durchschnitt die größten Dateien haben. Die Verwendung des arithmetischen Mittelwerts generiert aufgrund von Projekten wie sqlite.c, die in vielen Repositorys enthalten sind und ungewöhnlich viele Dateien zu einer kombinieren, ungewöhnlich hohe Zahlen, aber niemand arbeitet jemals an dieser einen großen Datei (ich hoffe!).Daher habe ich den Durchschnitt des Medians berechnet. Sprachen mit absurd hohen Werten wie Bosque und JavaScript blieben jedoch weiterhin erhalten.Also dachte ich mir, warum nicht einen Ritterzug machen? Auf Vorschlag von Darrell (ein in Kablamo ansässiger und ausgezeichneter Datenwissenschaftler) nahm ich eine kleine Änderung vor und änderte das arithmetische Mittel, indem ich Dateien über 5.000 Zeilen ablegte, um Anomalien zu beseitigen.Durchschnittliche Dateikomplexität in jeder Sprache?
Was ist die durchschnittliche Dateikomplexität für jede Sprache?Tatsächlich können Komplexitätsbewertungen nicht direkt zwischen Sprachen korreliert werden. Auszug aus der Readme-Datei selbst scc:Der Komplexitätswert ist nur eine Zahl, die nur zwischen Dateien in derselben Sprache abgeglichen werden kann. Es sollte nicht verwendet werden, um Sprachen direkt zu vergleichen. Der Grund dafür ist, dass die Berechnung erfolgt, indem für jede Datei nach Verzweigungs- und Schleifenoperatoren gesucht wird.
Daher können Sprachen hier nicht miteinander verglichen werden, obwohl dies zwischen ähnlichen Sprachen wie beispielsweise Java und C erfolgen kann.Dies ist eine wertvollere Metrik für einzelne Dateien in derselben Sprache. So können Sie die Frage beantworten: "Arbeitet diese Datei, mit der ich arbeite, einfacher oder schwerer als der Durchschnitt?"Ich muss erwähnen, dass ich mit Vorschlägen zur Verbesserung dieser Metrik in scc zufrieden sein werde . Für ein Commit reicht es normalerweise aus, nur wenige Schlüsselwörter zur Datei language.json hinzuzufügen, damit jeder Programmierer helfen kann.Durchschnittliche Anzahl von Kommentaren für Dateien in jeder Sprache?
Was ist die durchschnittliche Anzahl von Kommentaren in Dateien in jeder Sprache?Vielleicht kann die Frage umformuliert werden: Die Entwickler, in welcher Sprache die meisten Kommentare schreiben, deuten auf ein Missverständnis des Lesers hin.Was sind die häufigsten Dateinamen?
Welche Dateinamen sind in allen Codebasen am häufigsten, wobei Erweiterung und Groß- / Kleinschreibung ignoriert werden?Wenn Sie mich früher gefragt hätten, würde ich sagen: README, main, index, license. Die Ergebnisse spiegeln meine Annahmen ziemlich gut wider. Obwohl es viele interessante Dinge gibt. Ich habe keine Ahnung, warum so viele Projekte eine Datei namens 15oder enthalten s15.Das häufigste Makefile hat mich ein wenig überrascht, aber dann fiel mir ein, dass es in vielen neuen JavaScript-Projekten verwendet wurde. Eine weitere interessante Sache: Es scheint, dass jQuery immer noch auf dem Pferd ist und die Berichte über seinen Tod stark übertrieben sind und er auf Platz vier der Liste steht.Bitte beachten Sie, dass ich diesen Vorgang aufgrund von Speicherbeschränkungen etwas ungenauer gemacht habe. Nach jeweils 100 Projekten überprüfte ich die Karte und löschte die Namen von Dateien, die weniger als zehnmal vorkamen, aus der Liste. Sie konnten zum nächsten Test zurückkehren, und wenn sie sich mehr als zehn Mal trafen, blieben sie auf der Liste. Möglicherweise weisen einige Ergebnisse einen Fehler auf, wenn ein gebräuchlicher Name selten in der ersten Gruppe von Repositorys angezeigt wird, bevor er allgemein verwendet wird. Kurz gesagt, dies sind keine absoluten Zahlen, sondern sollten nahe genug an ihnen liegen.Ich könnte den Präfixbaum verwenden, um das Leerzeichen zu "quetschen" und die absoluten Zahlen zu erhalten, aber ich wollte es nicht schreiben, also habe ich die Karte leicht missbraucht, um genügend Speicherplatz zu sparen und das Ergebnis zu erhalten. Es wird jedoch sehr interessant sein, den Präfixbaum später auszuprobieren.Wie vielen Repositorys fehlt eine Lizenz?
Es ist sehr interessant. Wie viele Repositorys haben mindestens eine explizite Lizenzdatei? Bitte beachten Sie, dass das Fehlen einer Lizenzdatei hier nicht bedeutet, dass das Projekt diese nicht hat, da sie in der README-Datei vorhanden sein kann oder durch SPDX-Kommentar-Tags in Zeilen angezeigt werden kann. Dies bedeutet lediglich, dass sccdie explizite Lizenzdatei anhand ihrer eigenen Kriterien nicht gefunden werden konnte. Derzeit werden solche Dateien als "Lizenz", "Lizenz", "Kopieren", "Kopieren3", "Unlizenz", "Unlizenz", "Lizenz-Mit", "Lizenz-Mit" oder "Urheberrecht" betrachtet.Leider hat die überwiegende Mehrheit der Repositories keine Lizenz. Ich würde sagen, dass es viele Gründe gibt, warum eine Software eine Lizenz benötigt, aber jemand anderes hat es für mich gesagt .
Wie viele Projekte verwenden mehrere Gitignore-Dateien?
Einige wissen dies möglicherweise nicht, aber in einem Git-Projekt befinden sich möglicherweise mehrere Gitignore-Dateien. Wie viele Projekte verwenden vor diesem Hintergrund mehrere Gitignore-Dateien? Und wie viele haben gleichzeitig keinen einzigen?Ich habe ein ziemlich interessantes Projekt mit 25.794 Gitignore-Dateien im Repository gefunden. Das nächste Ergebnis war 2547. Ich habe keine Ahnung, was dort los ist. Ich warf einen kurzen Blick darauf: Es sieht so aus, als würden sie zum Überprüfen von Verzeichnissen verwendet, aber ich kann dies nicht bestätigen.Zurück zu den Daten: Hier ist ein Diagramm der Repositorys mit bis zu 20 Gitignore-Dateien, das 99% aller Projekte abdeckt. Wie erwartet haben die meisten Projekte 0 oder 1 Gitignore-Dateien. Dies wird durch einen massiven zehnfachen Rückgang der Anzahl von Projekten mit 2 Dateien bestätigt. Was mich überraschte, war, wie viele Projekte mehr als eine Gitignore-Datei haben. Der lange Schwanz ist in diesem Fall besonders lang.Ich war neugierig, warum einige Projekte Tausende solcher Dateien haben. Einer der Hauptstörer ist die Abzweigung https://github.com/PhantomX/slackbuilds : Jeder von ihnen hat ungefähr 2547 .gitignore-Dateien. Andere Repositorys mit mehr als tausend Gitignore-Dateien sind unten aufgeführt.
Wie erwartet haben die meisten Projekte 0 oder 1 Gitignore-Dateien. Dies wird durch einen massiven zehnfachen Rückgang der Anzahl von Projekten mit 2 Dateien bestätigt. Was mich überraschte, war, wie viele Projekte mehr als eine Gitignore-Datei haben. Der lange Schwanz ist in diesem Fall besonders lang.Ich war neugierig, warum einige Projekte Tausende solcher Dateien haben. Einer der Hauptstörer ist die Abzweigung https://github.com/PhantomX/slackbuilds : Jeder von ihnen hat ungefähr 2547 .gitignore-Dateien. Andere Repositorys mit mehr als tausend Gitignore-Dateien sind unten aufgeführt.?
Dieser Abschnitt ist keine exakte Wissenschaft, sondern gehört zur Klasse der Probleme der Verarbeitung natürlicher Sprache. Die Suche nach missbräuchlichen oder missbräuchlichen Begriffen in einer bestimmten Liste von Dateien ist niemals effektiv. Wenn Sie mit einer einfachen Suche suchen, finden Sie viele gewöhnliche Dateien wie assemble.shund so weiter. Also nahm ich eine Liste von Flüchen und überprüfte dann, ob Dateien in jedem Projekt mit einem dieser Werte beginnen, gefolgt von einem Punkt. Dies bedeutet, dass die genannte Datei gangbang.javaberücksichtigt wird, jedoch assemble.shnicht. Er wird jedoch viele verschiedene Optionen vermissen, wie zum Beispiel pu55syg4rgle.javaandere ebenso unhöfliche Namen.Meine Liste enthält einige Wörter auf leetspeak, wie b00bsund b1tch, um einige der interessanten Fälle zu erfassen . Vollständige Liste hier.Obwohl dies, wie bereits erwähnt, nicht ganz korrekt ist, ist es unglaublich interessant, das Ergebnis zu betrachten. Beginnen wir mit der Liste der Sprachen, in denen die meisten Flüche auftreten. Sie sollten das Ergebnis wahrscheinlich mit der Gesamtmenge an Code in jeder Sprache korrelieren. Also hier sind die Führer.Interessant!
Mein erster Gedanke war: "Oh, diese ungezogenen C-Entwickler!" Trotz der großen Anzahl solcher Dateien schreiben sie so viel Code, dass der Prozentsatz der Flüche in der Gesamtmenge verloren geht. Es ist jedoch ziemlich klar, dass Dart-Entwickler ein paar Worte in ihrem Arsenal haben! Wenn Sie einen der Dart-Programmierer kennen, können Sie ihm die Hand geben.Ich möchte auch wissen, was die am häufigsten verwendeten Flüche sind. Schauen wir uns einen gemeinsamen schmutzigen kollektiven Geist an. Einige der besten, die ich gefunden habe, waren normale Namen (wenn Sie schielen), aber die meisten anderen werden sicherlich Kollegen und einige Kommentare in den Pool-Anfragen überraschen.Bitte beachten Sie, dass einige der anstößigeren Wörter auf der Liste übereinstimmende Dateinamen hatten, was ich ziemlich schockierend finde. Glücklicherweise sind sie nicht sehr häufig und nicht in der obigen Liste enthalten, die auf Dateien mit einer Anzahl von mehr als 100 beschränkt ist. Ich hoffe, dass diese Dateien nur zum Testen von Zulassungs- / Verweigerungslisten und dergleichen existieren.Die größten Dateien nach Anzahl der Zeilen in jeder Sprache
Wie erwartet nehmen Klartext, SQL, XML, JSON und CSV die Spitzenpositionen ein: Sie enthalten normalerweise Metadaten, Datenbankspeicherauszüge und dergleichen.Hinweis Einige der folgenden Links funktionieren möglicherweise aufgrund zusätzlicher Informationen beim Erstellen von Dateien nicht. Die meisten sollten funktionieren, aber für einige müssen Sie möglicherweise die URL leicht ändern.Was ist die komplexeste Datei in jeder Sprache?
Auch diese Werte sind nicht direkt miteinander vergleichbar, aber es ist interessant zu sehen, was in jeder Sprache als das Schwierigste angesehen wird.Einige dieser Dateien sind absolute Monster. Betrachten Sie zum Beispiel die komplexeste C ++ - Datei, die ich gefunden habe: COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp : Es sind 28,3 Megabyte Compiler-Hölle (und zum Glück scheint sie automatisch generiert zu werden).Hinweis Einige der folgenden Links funktionieren möglicherweise aufgrund zusätzlicher Informationen beim Erstellen von Dateien nicht. Die meisten sollten funktionieren, aber für einige müssen Sie möglicherweise die URL leicht ändern.Die komplizierteste Datei bezüglich der Anzahl der Zeilen?
Theoretisch klingt es gut, aber tatsächlich ... verzerrt etwas Minimiertes oder ohne Zeilenumbrüche die Ergebnisse und macht sie bedeutungslos. Daher veröffentliche ich die Ergebnisse der Berechnungen nicht. Allerdings habe ich ein Ticket in sccUnterstützung minification Erkennung es aus den Berechnungsergebnissen entfernen war.Sie können wahrscheinlich anhand der verfügbaren Daten einige Schlussfolgerungen ziehen, aber ich möchte, dass alle Benutzer von dieser Funktion profitieren scc.Was ist die am meisten kommentierte Datei in jeder Sprache?
Ich habe keine Ahnung, welche wertvollen Informationen Sie daraus extrahieren können, aber es ist interessant zu sehen.Hinweis Einige der folgenden Links funktionieren möglicherweise aufgrund zusätzlicher Informationen beim Erstellen von Dateien nicht. Die meisten sollten funktionieren, aber für einige müssen Sie möglicherweise die URL leicht ändern.Wie viele "saubere" Projekte
Unter dem "reinen" in den Arten von Projekten sind nur in einer Sprache. Natürlich ist dies an sich nicht sehr interessant, also schauen wir sie uns im Kontext an. Wie sich herausstellte, hat die überwiegende Mehrheit der Projekte weniger als 25 Sprachen und die meisten weniger als zehn.Der Peak in der folgenden Grafik ist in vier Sprachen.Natürlich kann es in sauberen Projekten nur eine Programmiersprache geben, aber es werden auch andere Formate wie Markdown, JSON, YML, CSS, Gitignore unterstützt, die berücksichtigt werden scc. Es ist wahrscheinlich anzunehmen, dass jedes Projekt mit weniger als fünf Sprachen „sauber“ ist (für ein gewisses Maß an Sauberkeit), und dies ist etwas mehr als die Hälfte des gesamten Datensatzes. Natürlich kann Ihre Definition von Sauberkeit von meiner abweichen, sodass Sie sich auf eine beliebige Zahl konzentrieren können.Was mich überrascht, ist ein merkwürdiger Anstieg um 34-35 Sprachen. Ich habe keine vernünftige Erklärung dafür, woher es kam, und dies ist wahrscheinlich einer gesonderten Untersuchung wert.
Projekte mit TypeScript, aber nicht mit JavaScript
Ah, die moderne Welt von TypeScript. Aber wie viele von TypeScript-Projekten sind nur in dieser Sprache?Ich muss zugeben, ich bin ein wenig überrascht von dieser Nummer. Obwohl ich verstehe, dass das Mischen von JavaScript mit TypeScript ziemlich häufig ist, würde ich denken, dass es mehr Projekte in der neuen Sprache geben würde. Es ist jedoch möglich, dass neuere Repositorys ihre Anzahl dramatisch erhöhen.Verwendet jemand CoffeeScript und TypeScript?
Ich habe das Gefühl, dass einige TypeScript-Entwickler schon bei dem Gedanken daran krank werden. Wenn dies ihnen hilft, kann ich davon ausgehen, dass die meisten dieser Projekte Programme wie sccmit Beispielen aller Sprachen zu Testzwecken sind.Was ist die typische Pfadlänge in jeder Sprache?
Was ist die typische Pfadlänge und Anzahl der Verzeichnisse, da Sie entweder alle benötigten Dateien in ein Verzeichnis hochladen oder ein Verzeichnissystem erstellen können?Zählen Sie dazu die Anzahl der Schrägstriche im Pfad für jede Datei und den Durchschnitt. Ich wusste nicht, was mich hier erwarten würde, außer dass Java ganz oben auf der Liste stehen könnte, da es normalerweise lange Dateipfade gibt.YAML oder YML?
Es gab einmal eine "Diskussion" bei Slack - mit .yaml oder .yml. Viele wurden dort auf beiden Seiten getötet.Die Debatte kann endlich (?) Beenden. Obwohl ich vermute, dass einige es immer noch vorziehen werden, in einem Streit zu sterben.Groß-, Klein- oder Mischbuchstaben?
Welches Register wird für Dateinamen verwendet? Da es noch eine Verlängerung gibt, können wir hauptsächlich einen gemischten Fall erwarten.Das ist natürlich nicht sehr interessant, da Dateierweiterungen normalerweise in Kleinbuchstaben geschrieben sind. Was ist, wenn Erweiterungen ignoriert werden?Nicht das, was ich erwartet hatte. Wieder meistens gemischt, aber ich hätte gedacht, dass der Boden populärer sein würde.Fabriken in Java
Eine weitere Idee, die Kollegen beim Betrachten eines alten Java-Codes hatten. Ich dachte, warum nicht nach Java-Code suchen, bei dem Factory, FactoryFactory oder FactoryFactoryFactory im Titel erscheinen. Die Idee ist, die Anzahl solcher Fabriken zu schätzen.Etwas mehr als 2% des Java-Codes erwiesen sich als Fabrik oder Fabrikfabrik. Glücklicherweise wurde keine Fabrikfabrikfabrik gefunden. Vielleicht stirbt dieser Witz endgültig, obwohl ich sicher bin, dass mindestens eine ernsthafte rekursive Multifabrik der dritten Ebene noch irgendwo in einer Art Java 5-Monolith funktioniert und jeden Tag mehr Geld verdient, als ich in meiner gesamten Karriere gesehen habe. ..Ignore-Dateien
Die Idee von .ignore-Dateien wurde von burntsushi und ggreer in einer Diskussion über Hacker News entwickelt . Vielleicht ist dies eines der besten Beispiele für "konkurrierende" Open-Source-Tools, die mit guten Ergebnissen zusammenarbeiten und in Rekordzeit abgeschlossen werden. Es ist zum De-facto-Standard für das Hinzufügen von Code geworden, den Tools ignorieren. sccErfüllt auch die .ignore-Regel, weiß aber auch, wie man sie zählt. Mal sehen, wie gut sich die Idee verbreitet hat.Ideen für die Zukunft
Ich mache gerne Analysen für die Zukunft. Es wäre schön, Dinge wie AWS AKIA-Schlüssel und dergleichen zu scannen. Ich möchte auch die Abdeckung von Bitbucket- und Gitlab-Projekten mit Analysen für jedes erweitern, um zu sehen, ob dort möglicherweise Entwicklungsteams aus verschiedenen Bereichen hängen.Wenn ich das Projekt jemals wiederhole, möchte ich die folgenden Mängel beseitigen und die folgenden Ideen berücksichtigen.- Speichern Sie URLs irgendwo in Metadaten korrekt. Die Verwendung eines Dateinamens zum Speichern war eine schlechte Idee, da Informationen verloren gehen und es schwierig sein kann, die Quelle und den Speicherort der Datei zu bestimmen.
- Kümmere dich nicht um S3. Es macht wenig Sinn, für den Datenverkehr zu bezahlen, wenn ich ihn nur zur Speicherung verwende. Es war von Anfang an besser, alles in eine Teerdatei zu hämmern.
- , .
- -n , , , .
- scc, , . , CIDE.C C, , HTML. .
- , scc, , , . .
- Ich möchte scc eine Shebang-Erkennung hinzufügen .
- Es wäre schön, irgendwie die Anzahl der Sterne auf Github und die Anzahl der Commits zu berücksichtigen.
- Ich möchte irgendwie eine Berechnung des Wartbarkeitsindex hinzufügen. Es wäre sehr schön zu sehen, welche Projekte je nach Größe als am reparabelsten gelten.
Warum ist das alles?
Nun, ich kann einige dieser Informationen in meiner Suchmaschine und meinem Programm für searchcode.com verwenden scc. Zumindest einige nützliche Datenpunkte. Zu diesem Zweck wurde das Projekt zunächst in vielerlei Hinsicht konzipiert. Darüber hinaus ist es sehr nützlich, Ihr Projekt mit anderen zu vergleichen. Es war auch eine interessante Möglichkeit, mehrere Tage damit zu verbringen, einige interessante Probleme zu lösen. Und eine gute Zuverlässigkeitsprüfung für scc.Darüber hinaus arbeite ich derzeit an einem Tool, mit dem führende Entwickler oder Manager Code analysieren, nach bestimmten Sprachen, großen Dateien, Fehlern usw. suchen können. Dabei wird davon ausgegangen, dass Sie mehrere Repositorys analysieren müssen. Sie geben eine Art Code ein und das Tool gibt an, wie wartbar er ist und welche Fähigkeiten erforderlich sind, um ihn zu warten. Dies ist hilfreich, wenn Sie entscheiden, ob Sie eine Codebasis kaufen, diese pflegen oder sich ein Bild über Ihr eigenes Produkt machen möchten, das das Entwicklungsteam herausgibt. Theoretisch sollte dies den Teams helfen, über gemeinsam genutzte Ressourcen zu skalieren. So etwas wie AWS Macie, aber für den Code - so etwas arbeite ich gerade. Ich selbst brauche das für die tägliche Arbeit, und ich vermute, dass andere für ein solches Instrument Anwendung finden, zumindest ist das die Theorie.Vielleicht lohnt es sich, hier eine Form der Registrierung für Interessierte anzugeben ...Unverarbeitete / verarbeitete Dateien
Wenn jemand seine eigene Analyse vornehmen und Korrekturen vornehmen möchte, finden Sie hier einen Link zu den verarbeiteten Dateien (20 MB). Wenn jemand Rohdateien öffentlich zugänglich machen möchte, lass es mich wissen. Dies ist 83 GB tar.gz und im Inneren ist etwas mehr als 1 TB. Der Inhalt besteht aus etwas mehr als 9 Millionen JSON-Dateien unterschiedlicher Größe.UPD
Mehrere gute Seelen schlugen vor, die Datei zu platzieren. Die Orte sind unten angegeben:Durch das Hosten dieser tar.gz-Datei danke ich CNCF für den Server für xet7 aus dem Wekan- Projekt .