Zabbix ist ein Überwachungssystem. Wie bei jedem anderen System treten bei allen Überwachungssystemen drei Hauptprobleme auf: Datenerfassung und -verarbeitung, Verlaufsspeicherung und Reinigung.
Die Schritte zum Erfassen, Verarbeiten und Aufzeichnen von Daten benötigen Zeit. Nicht viel, aber bei einem großen System kann dies zu großen Verzögerungen führen. Das Speicherproblem ist ein Datenzugriffsproblem. Sie werden für Berichte, Überprüfungen und Auslöser verwendet. Verzögerungen beim Zugriff auf Daten wirken sich auch auf die Leistung aus. Wenn die Datenbank wächst, müssen irrelevante Daten gelöscht werden. Das Entfernen ist eine schwierige Operation, die auch einen Teil der Ressourcen verschlingt.

Die Probleme von Verzögerungen beim Sammeln und Speichern in Zabbix werden durch Caching gelöst: verschiedene Arten von Caches, Caching in der Datenbank. Um das dritte Problem zu lösen, ist das Caching nicht geeignet, daher verwendete Zabbix TimescaleDB.
Andrey Gushchin , technischer
Supportingenieur bei
Zabbix SIA, wird darüber sprechen. Andrey unterstützt Zabbix seit mehr als 6 Jahren und steht direkt vor der Leistung.
Wie funktioniert TimescaleDB, welche Leistung kann es im Vergleich zu normalem PostgreSQL bieten? Welche Rolle spielt Zabbix in TimescaleDB? Wie läuft man von Grund auf neu und wie migriert man mit PostgreSQL und welche Leistung ist besser? Über all das unter dem Schnitt.
Leistungsherausforderungen
Jedes Überwachungssystem steht vor spezifischen Leistungsherausforderungen. Ich werde über drei davon sprechen: Sammeln und Verarbeiten von Daten, Speichern, Bereinigen des Verlaufs.
Schnelle Datenerfassung und -verarbeitung. Ein gutes Überwachungssystem sollte schnell alle Daten empfangen und nach Triggerausdrücken verarbeiten - nach eigenen Kriterien. Nach der Verarbeitung sollte das System diese Daten auch schnell in der Datenbank speichern, um sie später verwenden zu können.
Eine Geschichte behalten. Ein gutes Überwachungssystem sollte den Verlauf in der Datenbank speichern und einen bequemen Zugriff auf Metriken ermöglichen. Eine Story wird benötigt, um sie in Berichten, Grafiken, Triggern, Schwellenwerten und berechneten Datenelementen für Warnungen zu verwenden.
Klare Geschichte. Manchmal kommt ein Tag, an dem Sie keine Metriken speichern müssen. Warum benötigen Sie die Daten, die vor 5 Jahren, ein oder zwei Monaten erfasst wurden: Einige Knoten werden gelöscht, einige Hosts oder Metriken werden nicht mehr benötigt, da sie veraltet sind und nicht mehr erfasst werden. Ein gutes Überwachungssystem sollte historische Daten speichern und von Zeit zu Zeit löschen, damit die Datenbank nicht wächst.
Das Löschen veralteter Daten ist ein heißes Problem, das einen großen Einfluss auf die Datenbankleistung hat.
Zabbix Caching
In Zabbix werden der erste und der zweite Aufruf mithilfe von Caching aufgelöst. RAM wird zur Datenerfassung und -verarbeitung verwendet. Zur Speicherung von Storys in Triggern, Diagrammen und berechneten Datenelementen. Auf der Datenbankseite gibt es ein bestimmtes Caching für die Hauptbeispiele, z. B. Diagramme.
Das Caching auf der Seite des Zabbix-Servers selbst ist:
- ConfigurationCache;
- ValueCache;
- HistoryCache;
- TrendsCache.
Betrachten wir sie genauer.
Konfigurationscache
Dies ist der Hauptcache, in dem wir Metriken, Hosts, Datenelemente und Trigger speichern - alles, was für die Vorverarbeitung und das Sammeln von Daten benötigt wird.
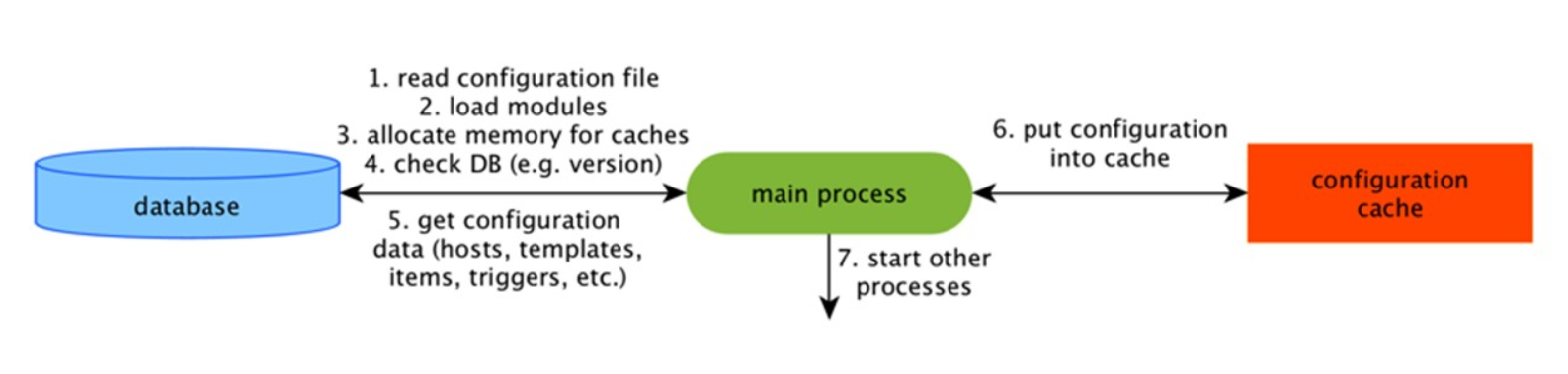
All dies wird im ConfigurationCache gespeichert, um keine unnötigen Abfragen in der Datenbank zu erstellen. Nach dem Start des Servers aktualisieren wir diesen Cache, erstellen und aktualisieren regelmäßig Konfigurationen.
Datenerfassung
Das Schema ist ziemlich groß, aber die Hauptsache darin sind die
Monteure . Dies sind die verschiedenen "Poller" - Montageprozesse. Sie sind für verschiedene Arten von Assemblys verantwortlich: Sie erfassen Daten über SNMP, IPMI und übertragen sie alle an PreProcessing.
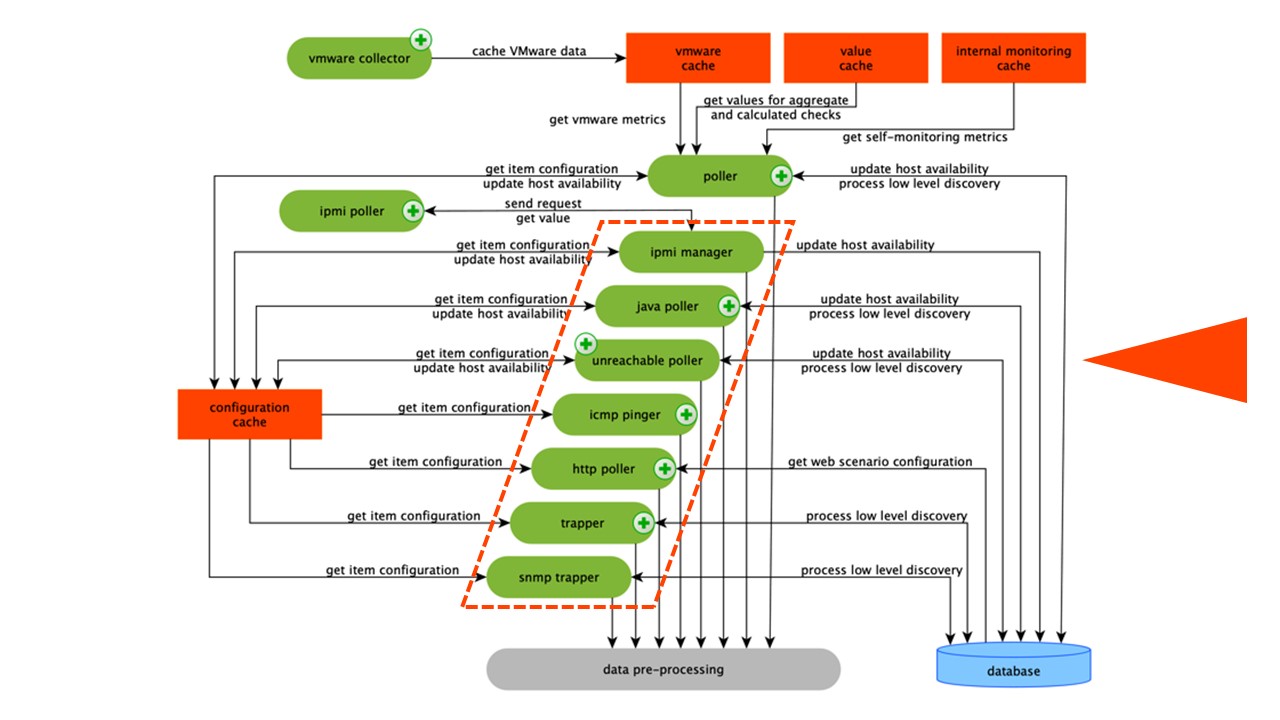 Sammler sind orange eingekreist.
Sammler sind orange eingekreist.Zabbix hat Aggregationsdatenelemente berechnet, die zum Aggregieren von Validierungen benötigt werden. Wenn wir sie haben, nehmen wir die Daten für sie direkt aus ValueCache.
PreCrocessing HistoryCache
Alle Kollektoren verwenden ConfigurationCache, um Jobs zu empfangen. Dann übergeben sie sie an PreProcessing.

PreProcessing verwendet ConfigurationCache, um PreProcessing-Schritte zu empfangen. Es verarbeitet diese Daten auf verschiedene Weise.
Nachdem wir die Daten mit PreProcessing verarbeitet haben, speichern wir sie im HistoryCache, um sie zu verarbeiten. Damit ist die Datenerfassung beendet und wir fahren mit dem Hauptprozess in Zabbix fort - dem
History Syncer , da es sich um eine monolithische Architektur handelt.
Hinweis: Die Vorverarbeitung ist ziemlich schwierig. Seit Version 4.2 wurde es dem Proxy vorgelegt. Wenn Sie einen sehr großen Zabbix mit einer großen Anzahl von Datenelementen und einer Häufigkeit der Erfassung haben, erleichtert dies die Arbeit erheblich.ValueCache, Verlaufs- und Trendcache
Der Verlaufssynchronisator ist der Hauptprozess, der jedes Datenelement, dh jeden Wert, atomar verarbeitet.
Der Verlaufssynchronisator übernimmt Werte aus dem Verlaufscache und sucht in der Konfiguration nach Triggern für Berechnungen. Wenn ja, berechnet es.
Der Verlaufssynchronisator erstellt ein Ereignis, eine Eskalation, um bei Bedarf Warnungen zu erstellen, und zeichnet auf. Wenn es Auslöser für die nachfolgende Verarbeitung gibt, merkt er sich diesen Wert in ValueCache, um nicht auf die Verlaufstabelle zuzugreifen. ValueCache wird also mit Daten gefüllt, die für die Berechnung von Triggern und berechneten Elementen erforderlich sind.
Der Verlaufssyncer schreibt alle Daten in die Datenbank und sie werden auf die Festplatte geschrieben. Der Verarbeitungsprozess endet hier.
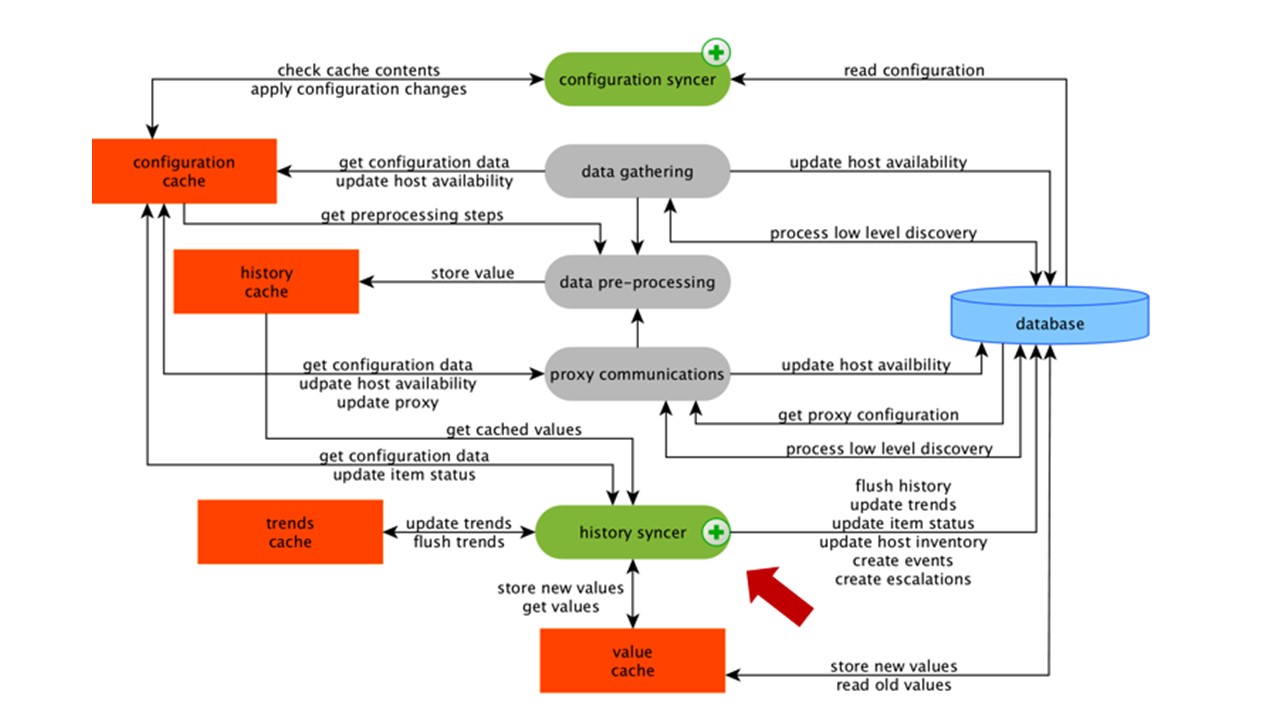
DB-Caching
Auf der DB-Seite gibt es verschiedene Caches, wenn Sie Diagramme oder Ereignisberichte anzeigen möchten:
Innodb_buffer_pool auf der MySQL-Seite;shared_buffers auf der PostgreSQL-Seite;effective_cache_size auf der Oracle-Seite;shared_pool auf der DB2-Seite.
Es gibt viele andere Caches, aber dies sind die wichtigsten für alle Datenbanken. Mit ihnen können Sie die Daten speichern, die häufig für Abfragen benötigt werden. Sie haben ihre eigenen Technologien dafür.
Die Datenbankleistung ist entscheidend
Der Zabbix-Server sammelt ständig Daten und schreibt sie. Beim Neustart wird auch aus dem Verlauf gelesen, um ValueCache zu füllen. Skripte und Berichte verwenden die
Zabbix-API , die auf der Webschnittstelle basiert. Die Zabbix-API kontaktiert die Datenbank und erhält die erforderlichen Daten für Diagramme, Berichte, Ereignislisten und aktuelle Probleme.
Zur Visualisierung -
Grafana . Bei unseren Anwendern ist dies eine beliebte Lösung. Es kann Anforderungen direkt über die Zabbix-API und an die Datenbank senden und schafft eine gewisse Wettbewerbsfähigkeit für den Empfang von Daten. Daher benötigen wir eine feinere und bessere Optimierung der Datenbank, um der schnellen Ausgabe von Ergebnissen und Tests zu entsprechen.
Haushälterin
Die dritte Leistungsherausforderung in Zabbix besteht darin, mit Housekeeper die Geschichte zu klären. Es folgt allen Einstellungen - die Datenelemente geben an, wie stark die Dynamik von Änderungen (Trends) in Tagen beibehalten werden soll.
Wir berechnen TrendsCache im laufenden Betrieb. Wenn die Daten eintreffen, aggregieren wir sie in einer Stunde und schreiben sie in Tabellen für die Dynamik von Trendänderungen.
Die Haushälterin startet und löscht Informationen aus der Datenbank mit den üblichen "Auswahlen". Dies ist nicht immer effektiv, was aus den Leistungsdiagrammen interner Prozesse hervorgeht.
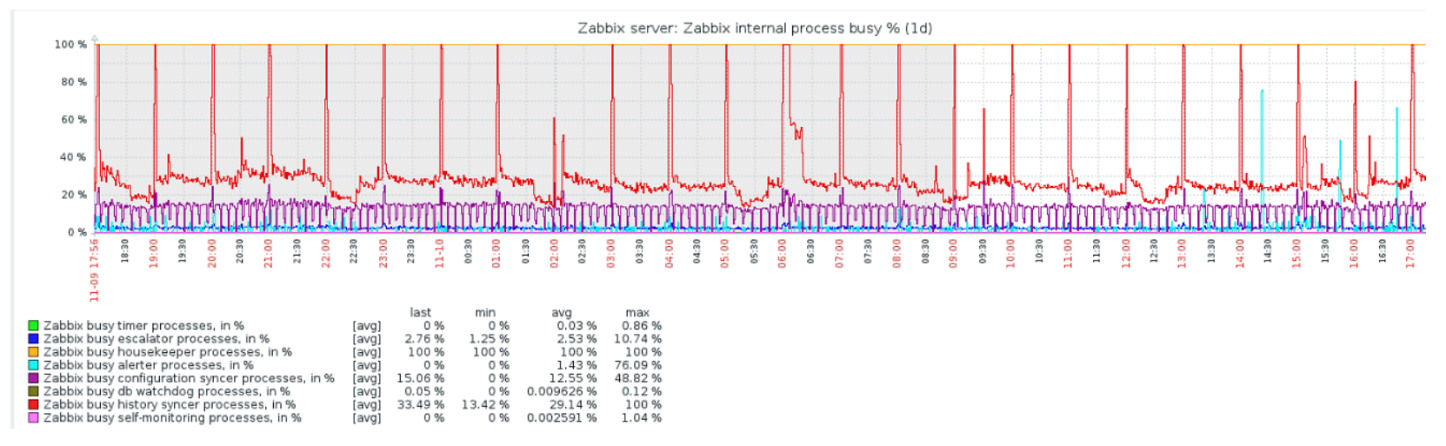
Ein rotes Diagramm zeigt an, dass der Verlaufssyncer ständig beschäftigt ist. Die orangefarbene Tabelle oben zeigt die Haushälterin, die ständig läuft. Er erwartet, dass die Datenbank alle von ihm angegebenen Zeilen löscht.
Wann soll die Haushälterin ausgeschaltet werden? Zum Beispiel gibt es eine "Artikel-ID" und Sie müssen die letzten fünftausend Zeilen in einer bestimmten Zeit löschen. Dies geschieht natürlich nach Index. Normalerweise ist das Dataset jedoch sehr groß, und die Datenbank liest immer noch von der Festplatte und hebt sie in den Cache. Dies ist immer eine sehr teure Operation für die Datenbank und kann je nach Größe der Datenbank zu Leistungsproblemen führen.
Haushälterin ist nur eine Trennung. In der Weboberfläche gibt es eine Einstellung in der "Administration general" für Housekeeper. Deaktivieren Sie die interne Verwaltung für den internen Trendverlauf und dies wird nicht mehr verwaltet.
Die Haushälterin wurde ausgeschaltet, die Grafiken wurden geebnet - was könnte in diesem Fall das Problem sein und was könnte bei der Lösung des dritten Leistungsaufrufs helfen?
Partitionierung - Partitionierung oder Partitionierung
Normalerweise wird die Partitionierung in jeder von mir aufgelisteten relationalen Datenbank anders konfiguriert. Jedes hat seine eigene Technologie, aber sie sind im Allgemeinen ähnlich. Das Erstellen einer neuen Partition führt häufig zu bestimmten Problemen.
Partitionen werden normalerweise abhängig vom „Setup“ konfiguriert - der Datenmenge, die an einem Tag erstellt wird. In der Regel ist die Partitionierung an einem Tag verfügbar, dies ist ein Minimum. Für Trends der neuen Partition - für 1 Monat.
Bei einem sehr großen „Setup“ können sich die Werte ändern. Wenn das kleine „Setup“ bis zu 5.000 nvps (neue Werte pro Sekunde) beträgt, liegt der Durchschnitt zwischen 5.000 und 25.000, das große über 25.000 nvps. Dies sind große und sehr große Installationen, die eine sorgfältige Konfiguration der Datenbank erfordern.
Bei sehr großen Installationen ist ein eintägiger Lauf möglicherweise nicht optimal. Ich habe auf MySQL-Partitionen 40 GB oder mehr pro Tag gesehen. Dies ist eine sehr große Datenmenge, die zu Problemen führen kann und reduziert werden muss.
Was gibt Partitionierung?
Partitionierungstabellen . Oft sind dies separate Dateien auf der Festplatte. Der Abfrageplan wählt eine Partition optimaler aus. Partitionierung wird normalerweise über einen Bereich verwendet - für Zabbix gilt dies auch. Wir verwenden dort "Zeitstempel" - Zeit vom Beginn der Ära. Wir haben gewöhnliche Zahlen. Sie legen den Anfang und das Ende des Tages fest - dies ist eine Partition.
Schnell löschen -
DELETE . Es wird eine einzelne Datei / Untertabelle ausgewählt, keine Auswahl der zu löschenden Zeilen.
Beschleunigt das Abrufen von SELECT Daten sichtbar - verwendet eine oder mehrere Partitionen, nicht die gesamte Tabelle. Wenn Sie vor zwei Tagen nach Daten fragen, werden diese schneller aus der Datenbank ausgewählt, da Sie sie in den Cache laden und nur eine Datei und keine große Tabelle ausgeben müssen.
Häufig beschleunigen viele Datenbanken auch
INSERT Einfügungen in die untergeordnete Tabelle.
Timescaledb
In Version 4.2 haben wir unsere Aufmerksamkeit auf TimescaleDB gerichtet. Dies ist eine Erweiterung für PostgreSQL mit einer nativen Schnittstelle. Die Erweiterung arbeitet effektiv mit Zeitreihendaten, ohne die Vorteile relationaler Datenbanken zu verlieren. TimescaleDB partitioniert auch automatisch.
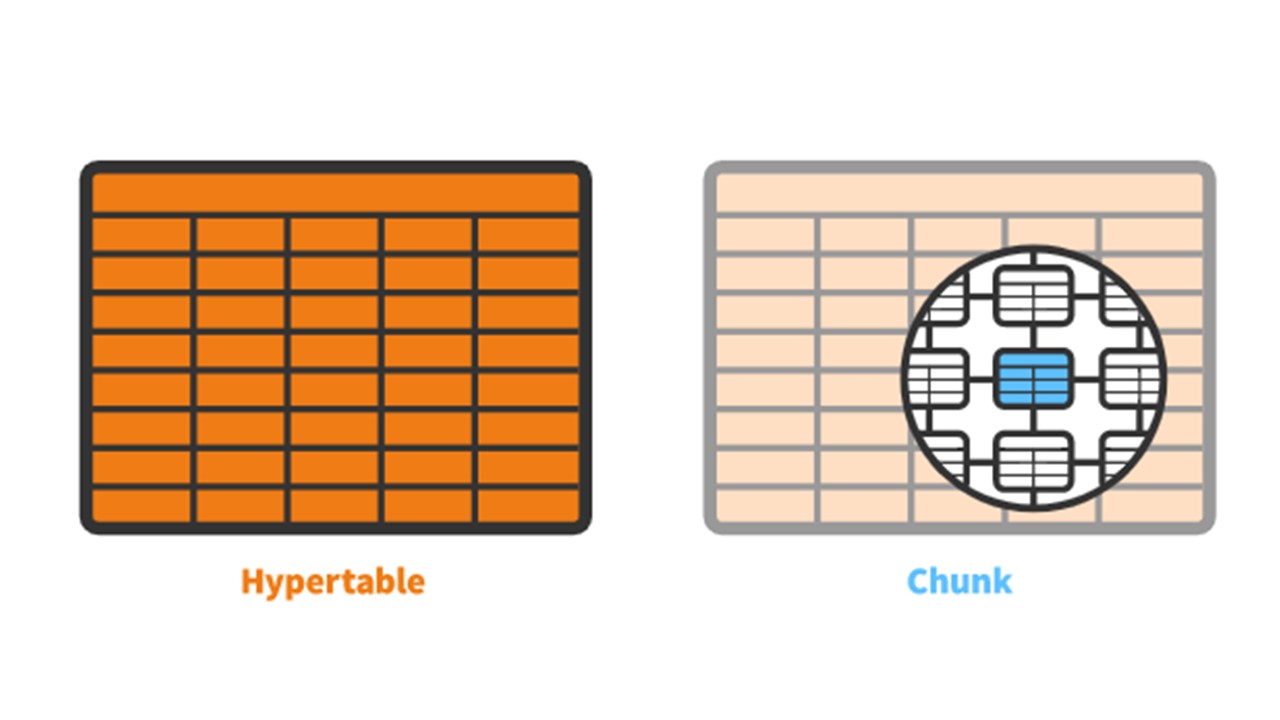
TimescaleDB hat das Konzept einer
von Ihnen erstellten
Hypertabelle . Es enthält
Chunks - Partitionen. Chunks sind automatisch gesteuerte Fragmente einer Hypertabelle, die andere Fragmente nicht beeinflussen. Jeder Block hat seinen eigenen Zeitbereich.
TimescaleDB vs PostgreSQL
TimescaleDB arbeitet sehr effizient. Erweiterungshersteller behaupten, dass sie einen korrekteren Anforderungsverarbeitungsalgorithmus verwenden, insbesondere <code> Einfügungen </ code>. Wenn die Abmessungen der Datensatzeinfügung zunehmen, behält der Algorithmus eine konstante Leistung bei.
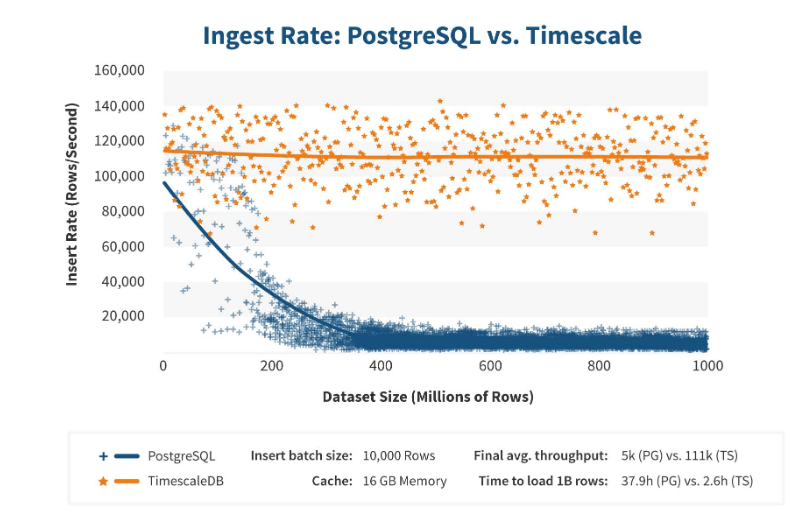
Nach 200 Millionen Zeilen beginnt PostgreSQL normalerweise stark zu sinken und verliert an Leistung bis zu 0. Mit TimescaleDB können Sie effizient „Einfügungen“ für jede Datenmenge einfügen.
Installation
Die Installation von TimescaleDB ist für alle Pakete einfach genug. Die
Dokumentation beschreibt alles im Detail - es hängt von den offiziellen PostgreSQL-Paketen ab. TimescaleDB kann auch manuell kompiliert und kompiliert werden.
Für die Zabbix-Datenbank aktivieren wir einfach die Erweiterung:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
Sie aktivieren die
extension und erstellen sie für die Zabbix-Datenbank. Der letzte Schritt besteht darin, eine Hypertabelle zu erstellen.
Verlaufstabellen nach TimescaleDB migrieren
create_hypertable gibt es eine spezielle Funktion
create_hypertable :
SELECT create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); UPDATE config SET db_extension='timescaledb', hk_history_global=1, hk_trends_global=1
Die Funktion hat drei Parameter. Die erste ist eine
Tabelle in der Datenbank, für die Sie eine Hypertabelle erstellen müssen. Das zweite ist das
Feld , in dem
chunk_time_interval - das Intervall der Partitionsblöcke, die Sie verwenden möchten. In meinem Fall beträgt das Intervall einen Tag - 86.400.
Der dritte Parameter ist
migrate_data . Wenn
true , werden alle aktuellen Daten in zuvor erstellte Chunks übertragen. Ich selbst habe
migrate_data . Ich hatte ungefähr 1 TB, was mehr als eine Stunde dauerte. Selbst in einigen Fällen habe ich beim Testen die historischen Daten von Zeichentypen gelöscht, die für die Speicherung optional waren, um sie nicht zu übertragen.
Der letzte Schritt ist
UPDATE : Wir setzen
db_extension in
db_extension damit die Datenbank versteht, dass es diese Erweiterung gibt. Zabbix aktiviert es und verwendet die Syntax und Abfragen, die bereits an die Datenbank gesendet wurden, korrekt - die Funktionen, die für TimescaleDB erforderlich sind.
Eisenkonfiguration
Ich habe zwei Server benutzt. Der erste ist ein
VMware-Computer . Es ist klein genug: 20 Intel® Xeon® Prozessoren E5-2630 v 4 bei 2,20 GHz, 16 GB RAM und eine 200 GB SSD.
Ich habe PostgreSQL 10.8 mit Debian 10.8-1.pgdg90 + 1 und dem xfs-Dateisystem darauf installiert. Ich habe alles minimal konfiguriert, um diese bestimmte Datenbank zu verwenden, abzüglich dessen, was Zabbix selbst verwenden wird.
Auf demselben Computer befanden sich ein Zabbix-Server, PostgreSQL und
Ladeagenten . Ich hatte 50 Wirkstoffe, die das
LoadableModule um sehr schnell verschiedene Ergebnisse zu generieren: Zahlen, Zeichenfolgen. Ich habe die Datenbank mit vielen Daten verstopft.
Anfänglich enthielt die Konfiguration
5.000 Datenelemente pro Host. Fast jedes Element enthielt einen Trigger, so dass es realen Installationen ähnelte. In einigen Fällen gab es mehr als einen Auslöser. Es gab
3.000-7.000 Trigger pro Netzwerkknoten.
Das Intervall zum Aktualisieren von Datenelementen beträgt
4-7 Sekunden . Ich habe die Last selbst reguliert, indem ich nicht nur 50 Agenten verwendet habe, sondern auch mehr hinzugefügt habe. Außerdem habe ich mithilfe von Datenelementen die Last dynamisch angepasst und das Aktualisierungsintervall auf 4 s reduziert.
PostgreSQL 35.000 nvps
Der erste Lauf auf dieser Hardware hatte ich auf reinem PostgreSQL - 35.000 Werte pro Sekunde. Wie Sie sehen, dauert das Einfügen von Daten Sekundenbruchteile - alles ist in Ordnung und schnell. Das einzige, was eine 200-GB-SSD schnell auffüllt.
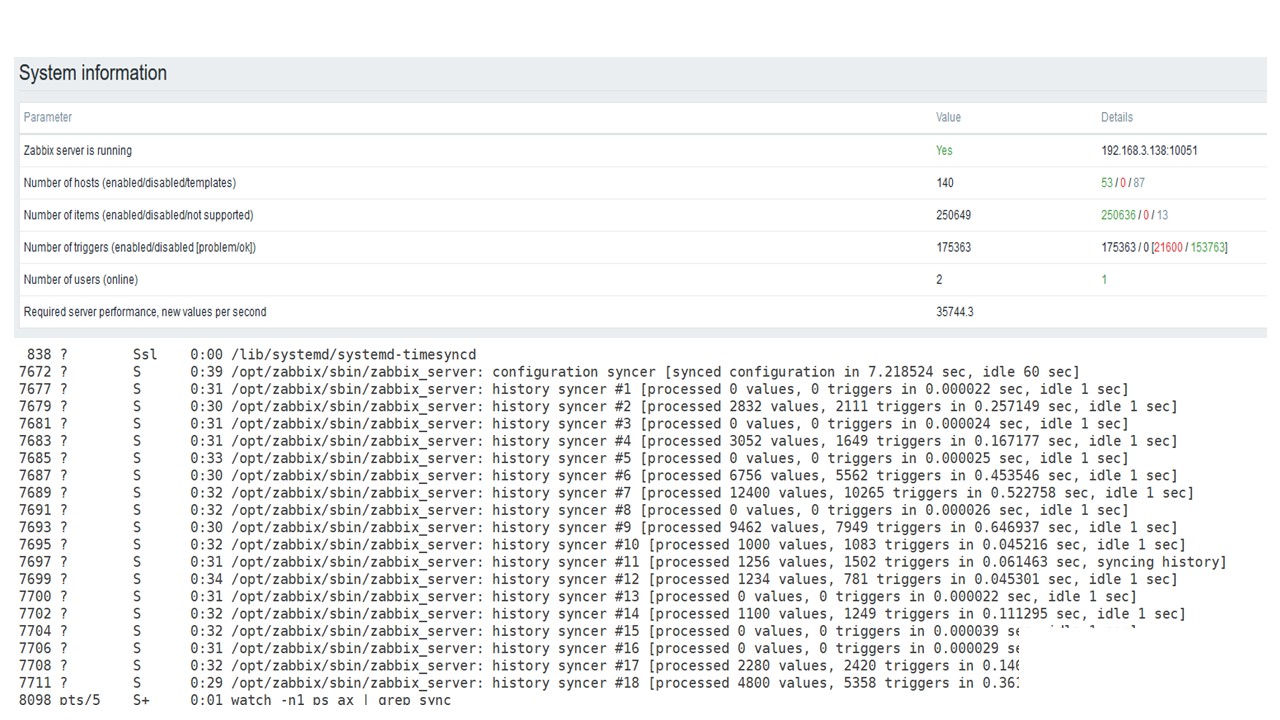
Dies ist das Standard-Dashboard für die Leistung von Zabbix-Servern.
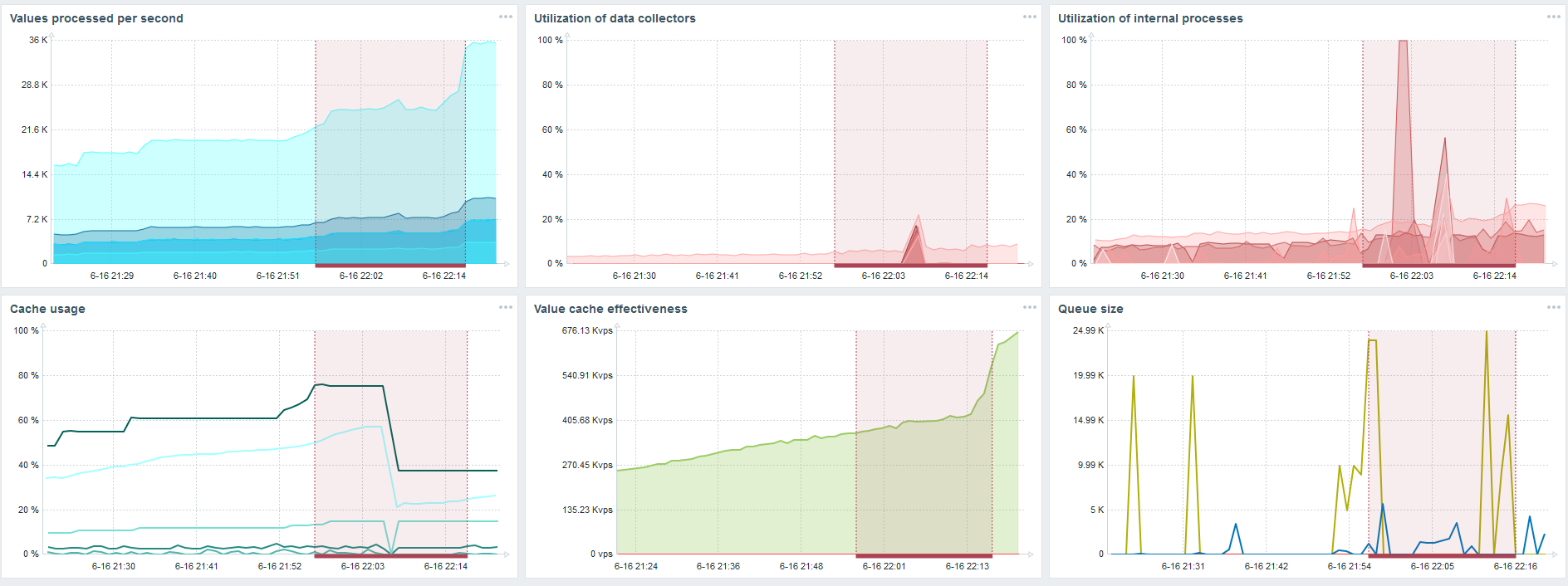
Das erste blaue Diagramm gibt die Anzahl der Werte pro Sekunde an. Das zweite Diagramm rechts zeigt das Laden von Montageprozessen. Der dritte ist das Laden der internen Montageprozesse: Verlaufssynchronisierer und Housekeeper, die hier schon seit einiger Zeit ausgeführt werden.
Das vierte Diagramm zeigt die Verwendung von HistoryCache. Dies ist ein Puffer vor dem Einfügen in die Datenbank. Das grüne fünfte Diagramm zeigt die Verwendung von ValueCache, dh wie viele ValueCache-Treffer für Trigger mehrere tausend Werte pro Sekunde sind.
PostgreSQL 50.000 nvps
Dann habe ich die Last auf derselben Hardware auf 50.000 Werte pro Sekunde erhöht.
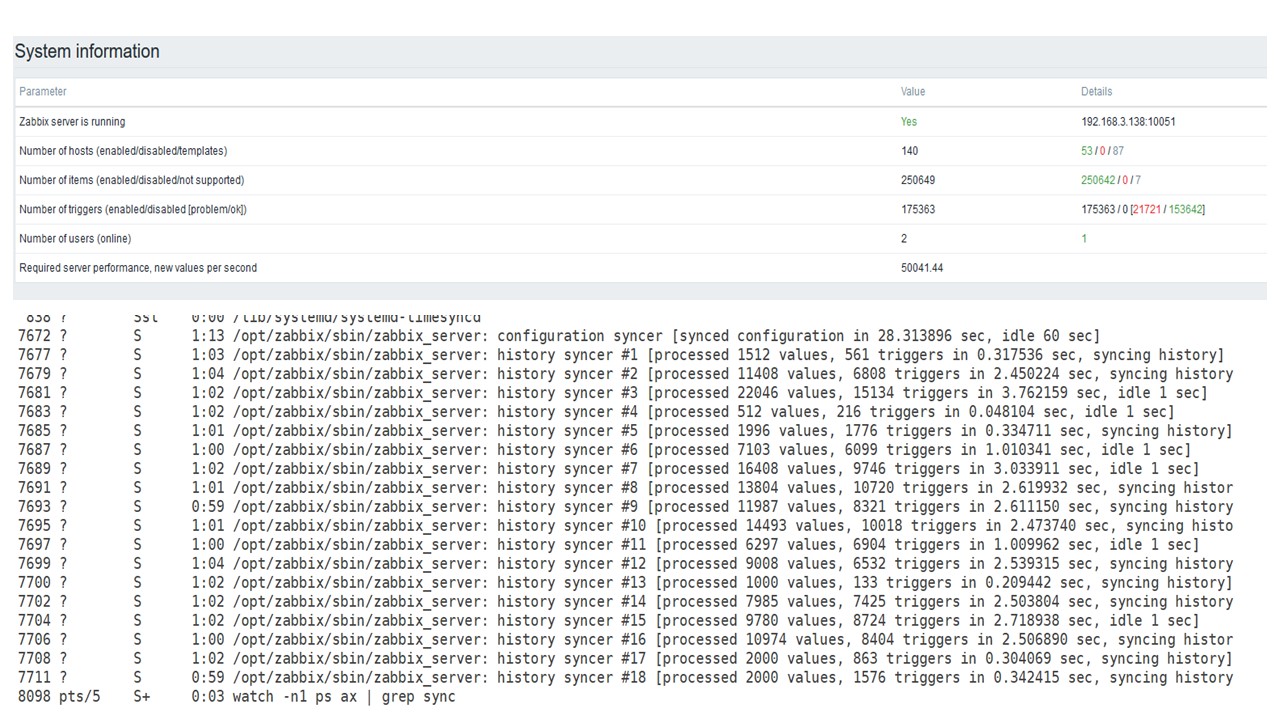
Beim Laden von der Haushälterin wurde für 2-3 s eine Einfügung von 10 Tausend Werten aufgezeichnet.
 Die Haushälterin beginnt bereits, sich in den Weg zu stellen.
Die Haushälterin beginnt bereits, sich in den Weg zu stellen.Die dritte Grafik zeigt, dass die Belastung von Trappern und Verlaufssynchronisierern im Allgemeinen immer noch bei 60% liegt. In der vierten Tabelle füllt sich HistoryCache bereits während der Arbeit von Housekeeper ziemlich aktiv. Es ist zu 20% voll - es sind ungefähr 0,5 GB.
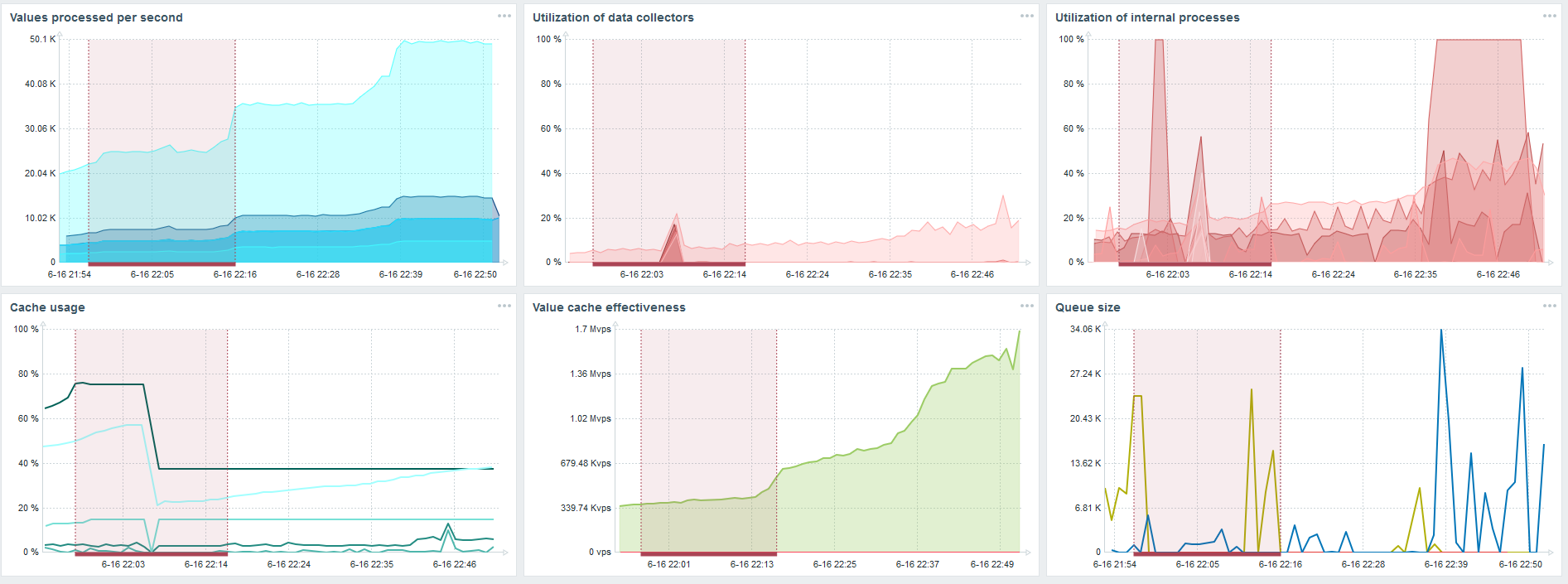
PostgreSQL 80.000 nvps
Dann habe ich die Last auf 80.000 Werte pro Sekunde erhöht. Dies sind ungefähr 400.000 Datenelemente und 280.000 Trigger.
 Der Einsatz zum Laden von 30 Verlaufssynchronisatoren ist bereits recht hoch.
Der Einsatz zum Laden von 30 Verlaufssynchronisatoren ist bereits recht hoch.Ich habe auch verschiedene Parameter erhöht: Verlaufssyncer, Caches.
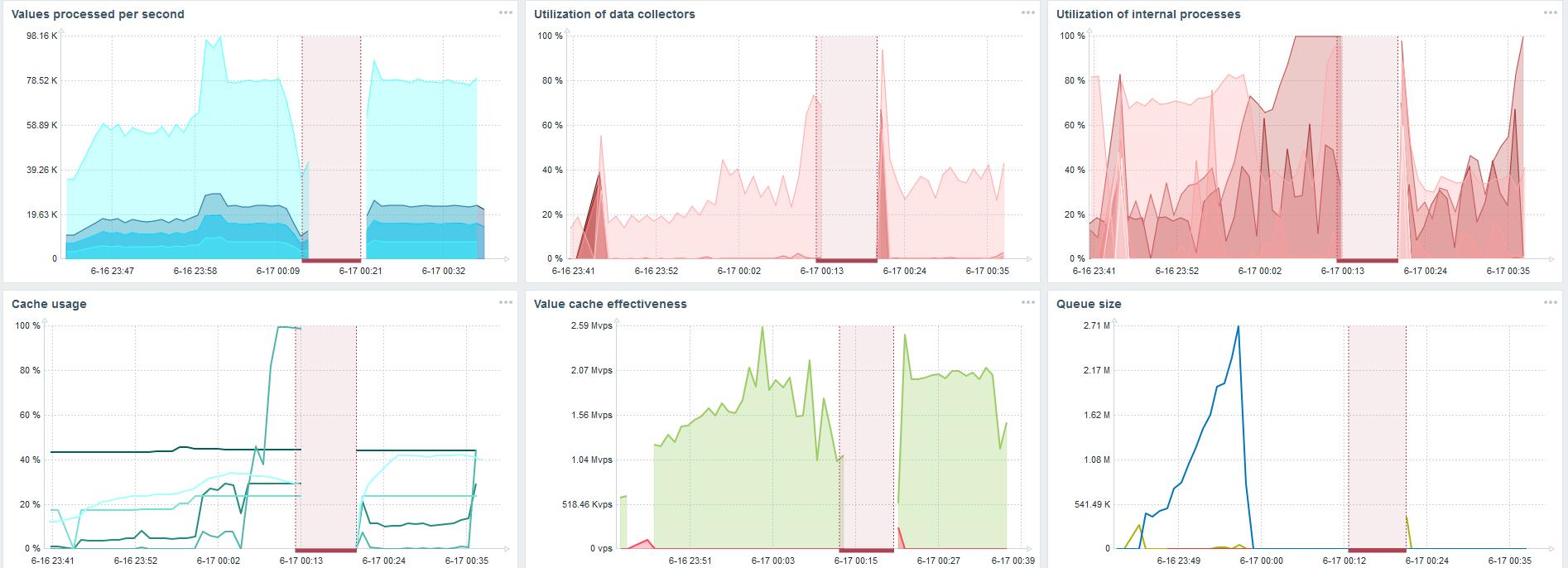
Auf meiner Hardware hat sich die Last der Verlaufssynchronisatoren auf das Maximum erhöht. HistoryCache schnell mit Daten gefüllt - die Daten für die Verarbeitung im Puffer gesammelt.
Während dieser ganzen Zeit habe ich beobachtet, wie der Prozessor, der Arbeitsspeicher und andere Systemparameter verwendet wurden, und festgestellt, dass die Festplattenauslastung maximiert wurde.
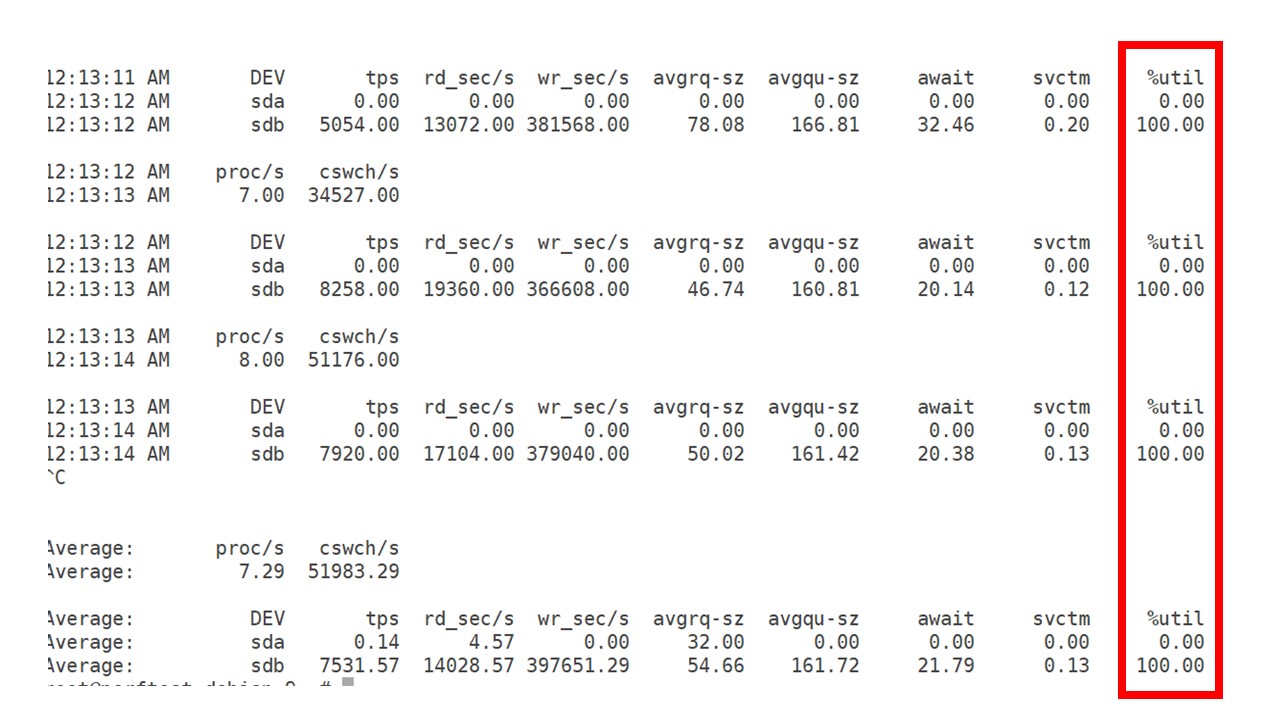
Ich habe das
Beste aus dem Laufwerk dieser Hardware und dieser virtuellen Maschine herausgeholt. Bei dieser Intensität begann PostgreSQL, Daten ziemlich aktiv zu sichern, und die Festplatte hatte keine Zeit mehr, um zu schreiben und zu lesen.
Zweiter Server
Ich habe einen anderen Server genommen, der bereits 48 Prozessoren und 128 GB RAM hatte. Optimieren Sie es - stellen Sie den 60-Verlaufs-Syncer ein und erzielen Sie eine akzeptable Leistung.
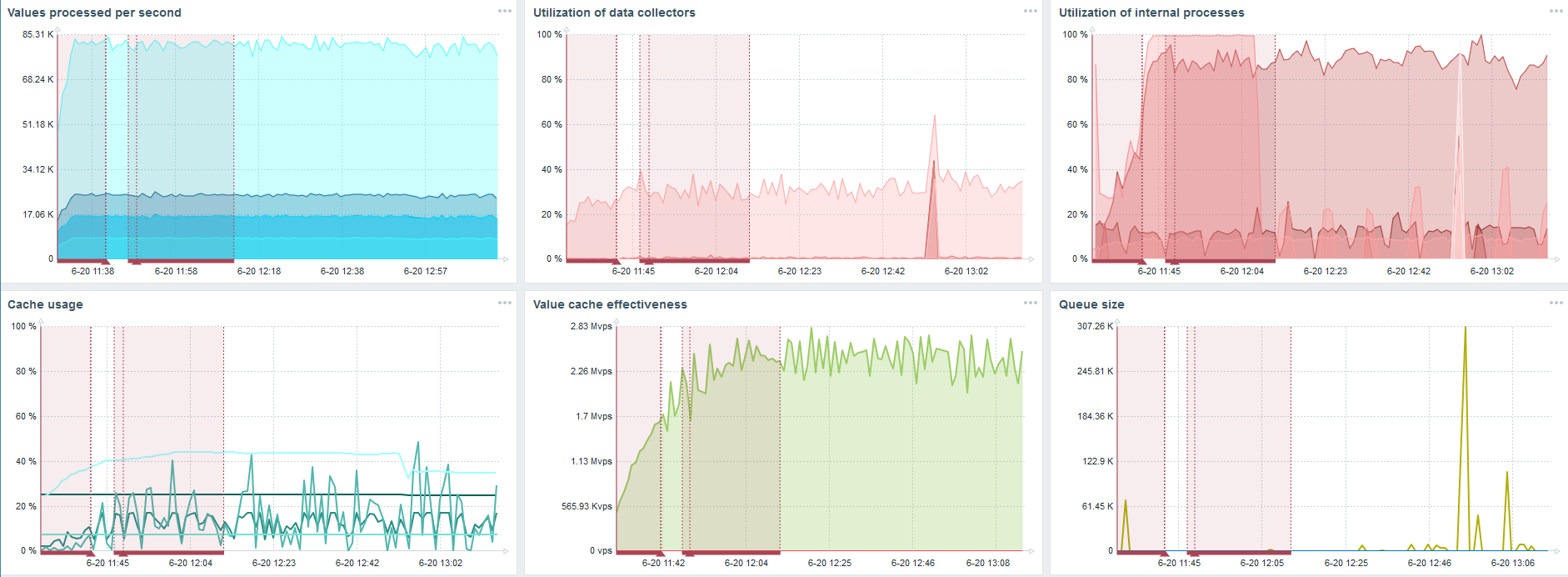
Tatsächlich ist dies bereits eine Leistungsbeschränkung, bei der etwas getan werden muss.
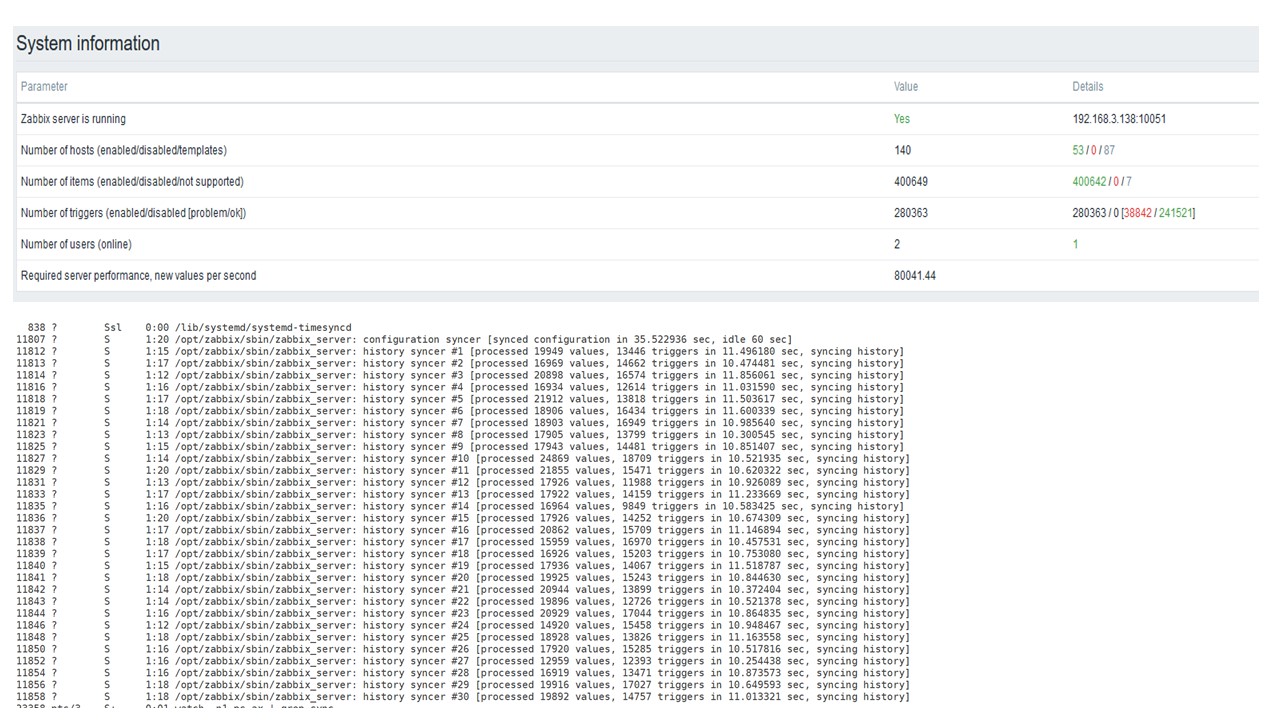
TimescaleDB. 80.000 nvps
Meine Hauptaufgabe ist es, die Funktionen von TimescaleDB anhand der Zabbix-Last zu testen. 80.000 Werte pro Sekunde sind eine Menge, die Häufigkeit der Erfassung von Metriken (außer natürlich Yandex) und ein ziemlich großes "Setup".
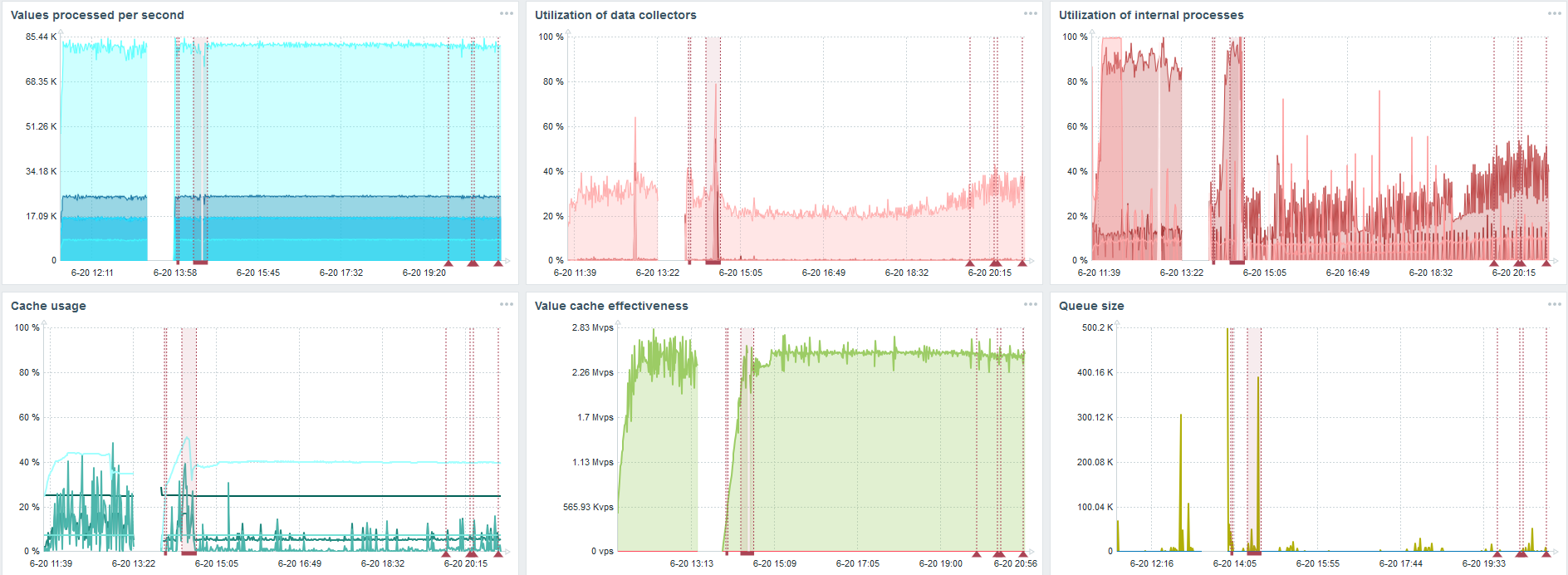
In jedem Diagramm ist ein Fehler aufgetreten - dies ist nur eine Datenmigration. Nach Fehlern auf dem Zabbix-Server hat sich das Boot-Profil des Verlaufssyncers stark geändert - es ist dreimal gesunken.
Mit TimescaleDB können Sie Daten fast dreimal schneller einfügen und weniger HistoryCache verwenden.
Dementsprechend werden Ihnen die Daten rechtzeitig zugestellt.
TimescaleDB. 120.000 nvps
Dann habe ich die Anzahl der Datenelemente auf 500.000 erhöht. Die Hauptaufgabe bestand darin, die Funktionen von TimescaleDB zu überprüfen. Ich habe den berechneten Wert von 125.000 Werten pro Sekunde erhalten.
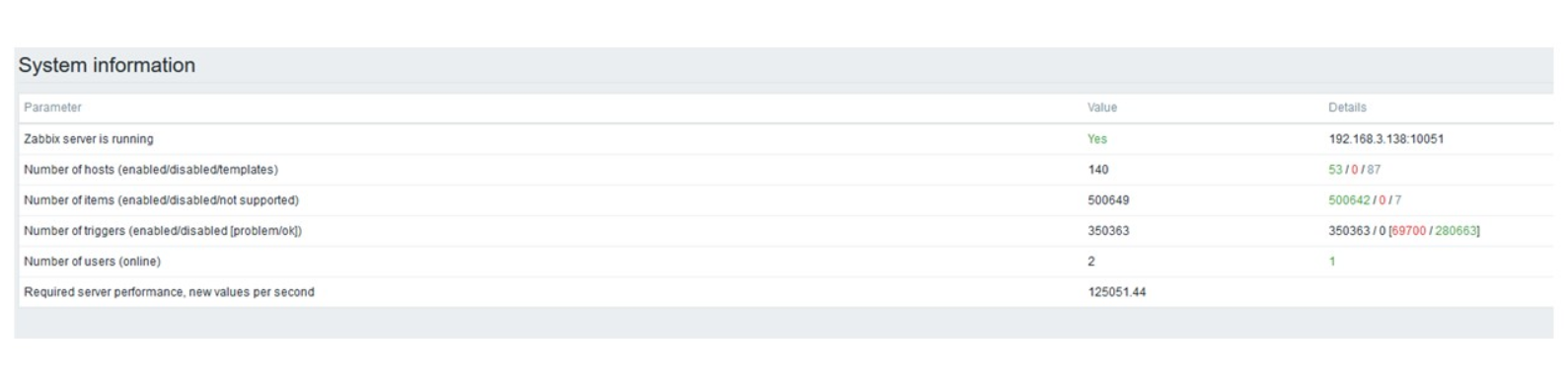
Dies ist ein funktionierendes „Setup“, das lange funktionieren kann. Da meine Festplatte jedoch nur 1,5 TB groß war, habe ich sie in ein paar Tagen gefüllt.
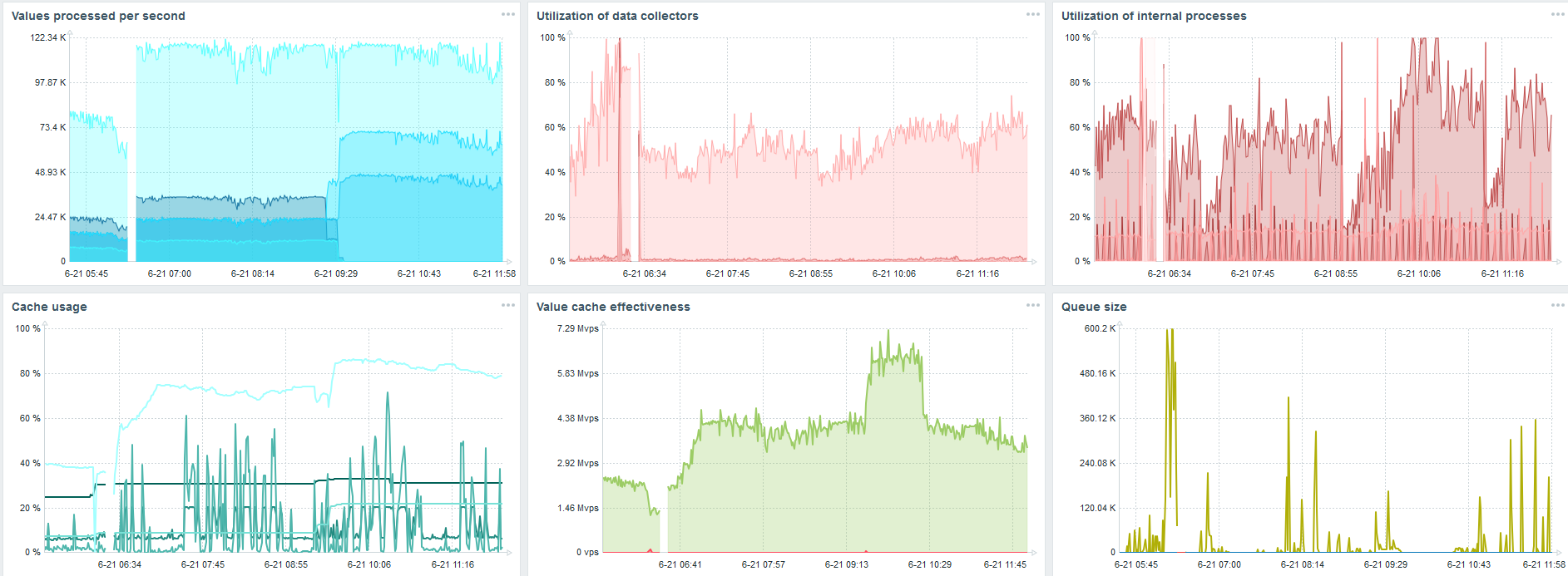
Gleichzeitig wurden gleichzeitig neue TimescaleDB-Partitionen erstellt.
Für die Leistung ist dies völlig unsichtbar. Wenn beispielsweise Partitionen in MySQL erstellt werden, ist alles anders. Normalerweise geschieht dies nachts, weil es das allgemeine Einfügen blockiert, mit Tabellen arbeitet und zu einer Verschlechterung des Dienstes führen kann. Bei TimescaleDB ist dies nicht der Fall.
Als Beispiel zeige ich ein Diagramm aus dem Set in der Community. TimescaleDB ist im Bild enthalten, wodurch die Belastung für die Verwendung von io.weight auf dem Prozessor gesunken ist. Die Verwendung von Elementen interner Prozesse hat ebenfalls abgenommen. Und dies ist eine normale virtuelle Maschine auf normalen Pfannkuchenplatten, keine SSD.
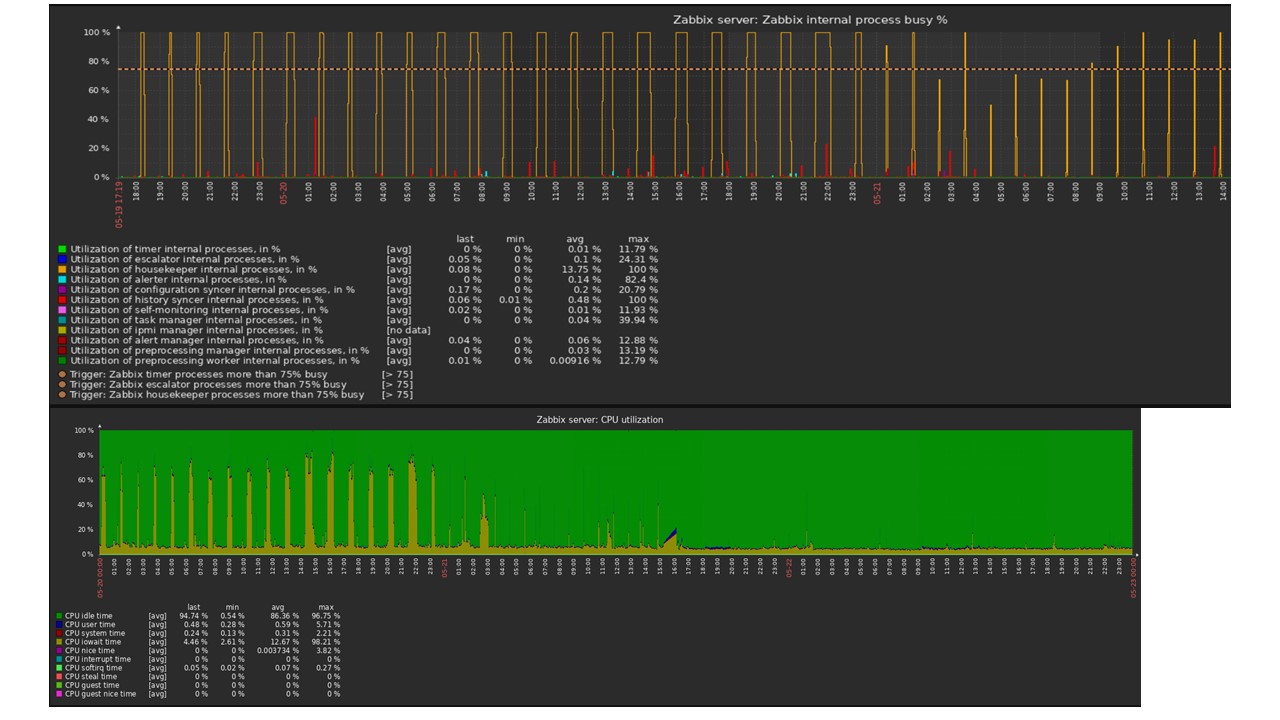
Schlussfolgerungen
TimescaleDB ist eine gute Lösung für kleine „Setups“ , die auf der Festplattenleistung basieren. Damit können Sie weiterhin gut arbeiten, bis die Datenbank schneller auf Bügeln migriert wird.
TimescaleDB ist einfach zu konfigurieren, bietet eine Leistungssteigerung, funktioniert gut mit Zabbix und
hat Vorteile gegenüber PostgreSQL .
Wenn Sie PostgreSQL verwenden und nicht vorhaben, es zu ändern, empfehle ich die
Verwendung von PostgreSQL mit der Erweiterung TimescaleDB in Verbindung mit Zabbix . Diese Lösung funktioniert effektiv bis zum mittleren "Setup".
Wir sagen "hohe Leistung" - wir meinen HighLoad ++ . Warten Sie darauf, sich kurz mit den Technologien und Praktiken vertraut zu machen, mit denen Dienste Millionen von Benutzern bedienen können. Wir haben bereits eine Liste mit Berichten für den 7. und 8. November zusammengestellt, aber Mitaps können weiterhin angeboten werden.
Abonnieren Sie unseren Newsletter und unser Telegramm , in denen wir die Chips der bevorstehenden Konferenz enthüllen und erfahren, wie Sie das Beste daraus machen können.