Modernes maschinelles Lernen ermöglicht es Ihnen, unglaubliche Dinge zu tun. Neuronale Netze arbeiten zum Wohle der Gesellschaft: Sie finden Kriminelle, erkennen Bedrohungen, helfen bei der Diagnose von Krankheiten und treffen schwierige Entscheidungen. Algorithmen können eine Person in ihrer Kreativität übertreffen: Sie malen Bilder, schreiben Lieder und machen aus gewöhnlichen Bildern Meisterwerke. Und diejenigen, die diese Algorithmen entwickeln, werden oft als karikierte Wissenschaftler dargestellt.
Nicht alles ist so beängstigend! Jeder, der mit Programmierung vertraut ist, kann aus Grundmodellen ein neuronales Netzwerk aufbauen. Und es ist nicht einmal notwendig, Python zu lernen, alles kann in nativem JavaScript gemacht werden. Es ist einfach, loszulegen und warum maschinelles Lernen für Front-End-
Anbieter erforderlich ist, sagte
Aleksey Okhrimenko (
obenjiro ) von FrontendConf, und wir haben es auf den Text übertragen, sodass Architekturnamen und nützliche Links zur Hand waren.
Spoiler. Alarm!
Diese Geschichte:
- Nicht für diejenigen, die bereits mit maschinellem Lernen arbeiten. Etwas Interessantes wird sein, aber es ist unwahrscheinlich, dass Sie unter dem Schnitt auf die Eröffnung warten.
- Nicht über Transferlernen. Wir werden nicht darüber sprechen, wie man ein neuronales Netzwerk in Python schreibt und dann mit JavaScript damit arbeitet. Keine Cheats - wir werden tiefe neuronale Netze speziell für JS schreiben.
- Nicht alle Details. Im Allgemeinen passen nicht alle Konzepte in einen Artikel, aber wir werden natürlich das Notwendige analysieren.
Über den Redner: Alexei Okhrimenko arbeitet bei Avito in der Abteilung Frontend Architecture und leitet in seiner Freizeit das Angular Moscow Meetup und veröffentlicht das „Five Minute Angular“. Im Laufe seiner langen Karriere hat er das Designmuster MALEVICH entwickelt, den PEG-Grammatik-Parser SimplePEG. Der CSSComb-Betreuer von Alexey teilt regelmäßig sein Wissen über neue Technologien auf Konferenzen und in seinem JS-
Telegrammkanal für maschinelles Lernen.
Maschinelles Lernen ist sehr beliebt.
Sprachassistenten, Siri, Google Assistant, Alice, sind beliebt und häufig in unserem Leben anzutreffen. Viele Produkte haben von der herkömmlichen algorithmischen Datenverarbeitung auf maschinelles Lernen umgestellt. Ein markantes Beispiel ist Google Translate.
Alle Innovationen und die coolsten Chips in Smartphones basieren auf maschinellem Lernen.

Beispielsweise verwendet Google NightSight maschinelles Lernen. Die coolen Fotos, die wir sehen, wurden nicht mit Objektiven, Sensoren oder Stabilisierung aufgenommen, sondern mit Hilfe des maschinellen Lernens. Die Maschine hat schließlich die Leute in DOTA2 geschlagen, was bedeutet, dass wir kaum eine Chance haben, künstliche Intelligenz zu besiegen. Deshalb müssen wir maschinelles Lernen so schnell wie möglich beherrschen.
Beginnen wir mit einem einfachen
Was ist unsere tägliche Programmierroutine, wie schreiben wir normalerweise Funktionen?

Wir nehmen die Daten und den Algorithmus, die wir selbst erfunden oder von populären fertigen übernommen haben, kombinieren, zaubern ein wenig und erhalten eine Funktion, die uns in einer bestimmten Situation die richtige Antwort gibt.
Wir sind an diese Reihenfolge gewöhnt, aber es würde eine solche Gelegenheit geben, ohne den Algorithmus zu kennen, aber einfach die Daten und die Antwort zu haben, um den Algorithmus von ihnen zu erhalten.

Sie können sagen: "Ich bin Programmierer, ich kann immer einen Algorithmus schreiben."
Ok, aber zum Beispiel, welcher Algorithmus wird hier benötigt?

Angenommen, die Katze hat scharfe Ohren und die Ohren des Hundes sind stumpf, klein wie ein Mops.

Versuchen wir an den Ohren zu verstehen, wer wer ist. Aber irgendwann stellen wir fest, dass Hunde scharfe Ohren haben können.

Unsere Hypothese ist nicht gut, wir brauchen andere Eigenschaften. Im Laufe der Zeit werden wir immer mehr Details erfahren und uns dadurch immer mehr demotivieren, und irgendwann werden wir dieses Geschäft ganz aufgeben wollen.
Ich stelle mir ein ideales Bild wie dieses vor: Im Voraus gibt es eine Antwort (wir wissen, um welche Art von Bild es sich handelt), es gibt Daten (wir wissen, dass eine Katze gezeichnet ist), wir möchten einen Algorithmus erhalten, der Daten füttert und Antworten am Ausgang erhält.
Es gibt eine Lösung - dies ist maschinelles Lernen, nämlich einer seiner Teile - tiefe neuronale Netze.
Tiefe neuronale Netze
Maschinelles Lernen ist ein riesiger Bereich. Es bietet eine gigantische Menge an Methoden, und jede ist auf ihre Weise gut.
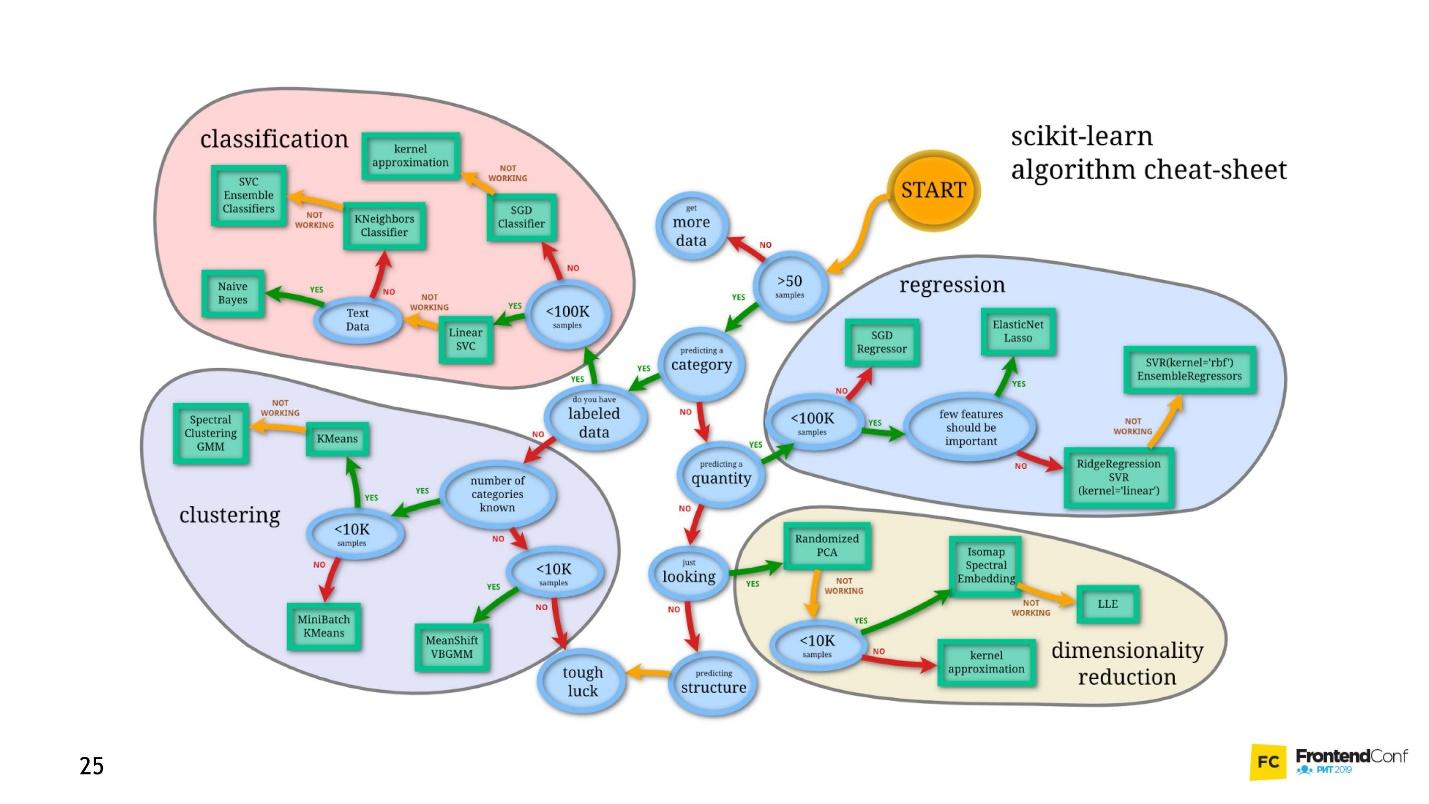
Eines davon ist Deep Neural Networks. Deep Learning hat einen unbestreitbaren Vorteil, aufgrund dessen es populär geworden ist.
Um diesen Vorteil zu verstehen, betrachten wir das klassische Klassifizierungsproblem am Beispiel von Katzen und Hunden.
Es gibt Daten: Bilder oder Fotos. Das erste, was zu tun ist, ist das Einbetten (Einbetten), dh das Transformieren der Daten, damit die Maschine bequem mit ihnen arbeiten kann. Es ist unpraktisch, mit Bildern zu arbeiten, das Auto braucht etwas Einfacheres.
Richten Sie zuerst die Bilder aus und entfernen Sie die Farbe. Unabhängig von der Farbe des Hundes oder der Katze ist es wichtig, die Art des Tieres zu bestimmen. Dann verwandeln wir die Bilder in Arrays, in denen beispielsweise 0 dunkel und 1 hell ist.

Mit dieser Darstellung von Daten können neuronale Netze bereits funktionieren.
Lassen Sie uns zwei weitere Arrays erstellen und diese zu einer bestimmten „Ebene“ zusammenführen. Als nächstes werden wir jedes der Elemente der Schicht und des Datenarrays unter Verwendung einer einfachen Matrixmultiplikation miteinander multiplizieren und das Ergebnis in zwei Aktivierungsfunktionen umleiten (später werden wir analysieren, was diese Funktionen sind). Wenn die Aktivierungsfunktion eine ausreichende Anzahl von Werten empfängt, wird sie "aktiviert" und führt zu folgendem Ergebnis:
- Die erste Funktion gibt 1 zurück, wenn es sich um eine Katze handelt, und 0, wenn es sich nicht um eine Katze handelt.
- Die zweite Funktion gibt 1 zurück, wenn es sich um einen Hund handelt, und 0, wenn es sich nicht um einen Hund handelt.
Dieser Ansatz zum Codieren einer Antwort wird als
One-Hot-Codierung bezeichnet .

Einige Merkmale tiefer neuronaler Netze sind bereits erkennbar:
- Um mit neuronalen Netzen arbeiten zu können, müssen Sie Daten am Eingang codieren und am Ausgang decodieren.
- Durch die Codierung können wir von Daten abstrahieren.
- Durch Ändern der Eingabedaten können wir neuronale Netze für verschiedene Domänendomänen generieren. Auch solche, in denen wir keine Experten sind.
Es ist nicht notwendig zu wissen, was eine Katze ist, was ein Hund ist. Es reicht aus, die erforderlichen Nummern für eine zusätzliche Ebene auszuwählen.
Bisher bleibt nur unklar, warum diese Netzwerke als "tief" bezeichnet werden.
Alles ist sehr einfach: Wir können eine weitere Ebene erstellen (Arrays und ihre Aktivierungsfunktionen). Und übertragen Sie das Ergebnis einer Schicht auf eine andere.
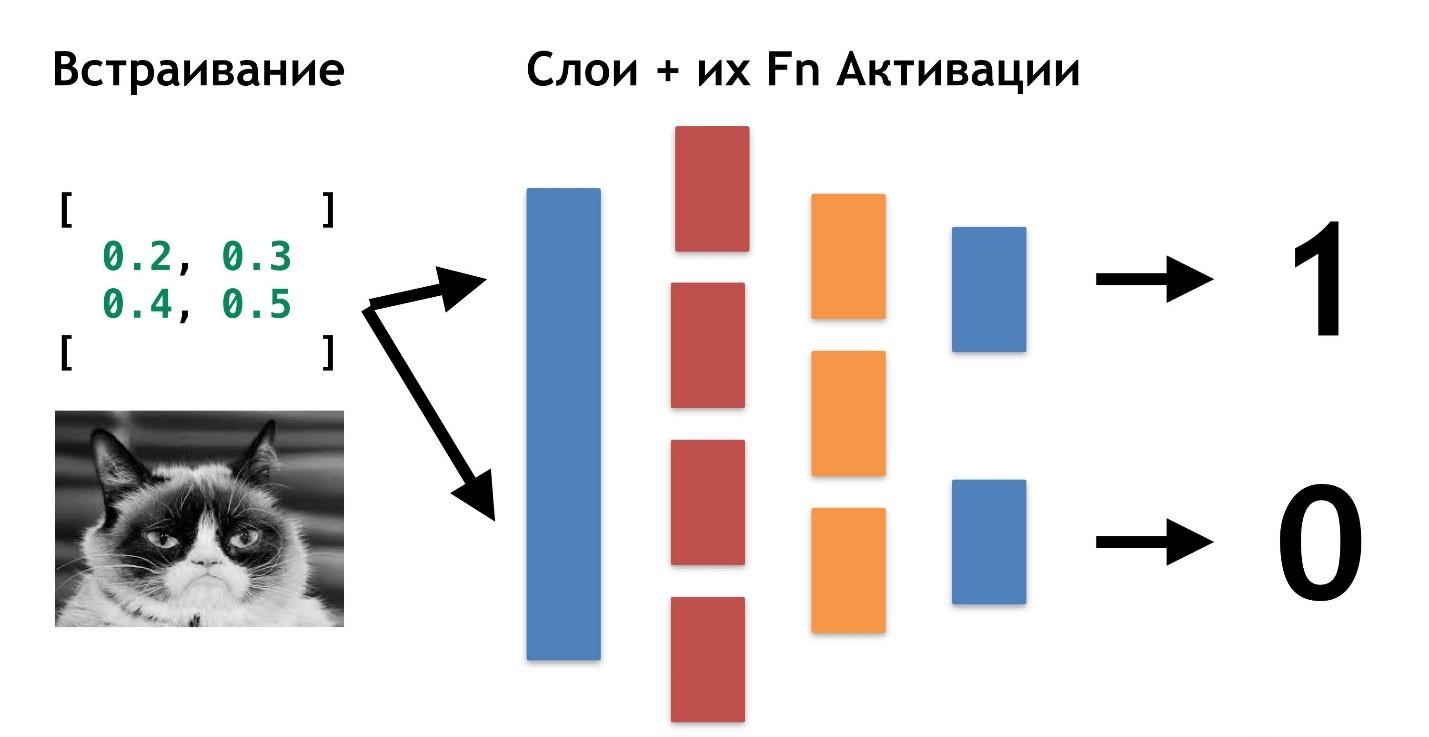
Sie können so viele dieser Ebenen und ihre Funktionen zur Aktivierung aufeinander legen. Durch die Kombination von Schichtarchitektur erhalten wir ein tiefes neuronales Netzwerk. Seine Tiefe ist eine Vielzahl von Schichten. Und gemeinsam als
"Modell" bezeichnet.Nun wollen wir sehen, wie die Werte für alle diese Ebenen ausgewählt werden. Es gibt eine coole
Visualisierung , mit der Sie verstehen können, wie der Lernprozess abläuft.
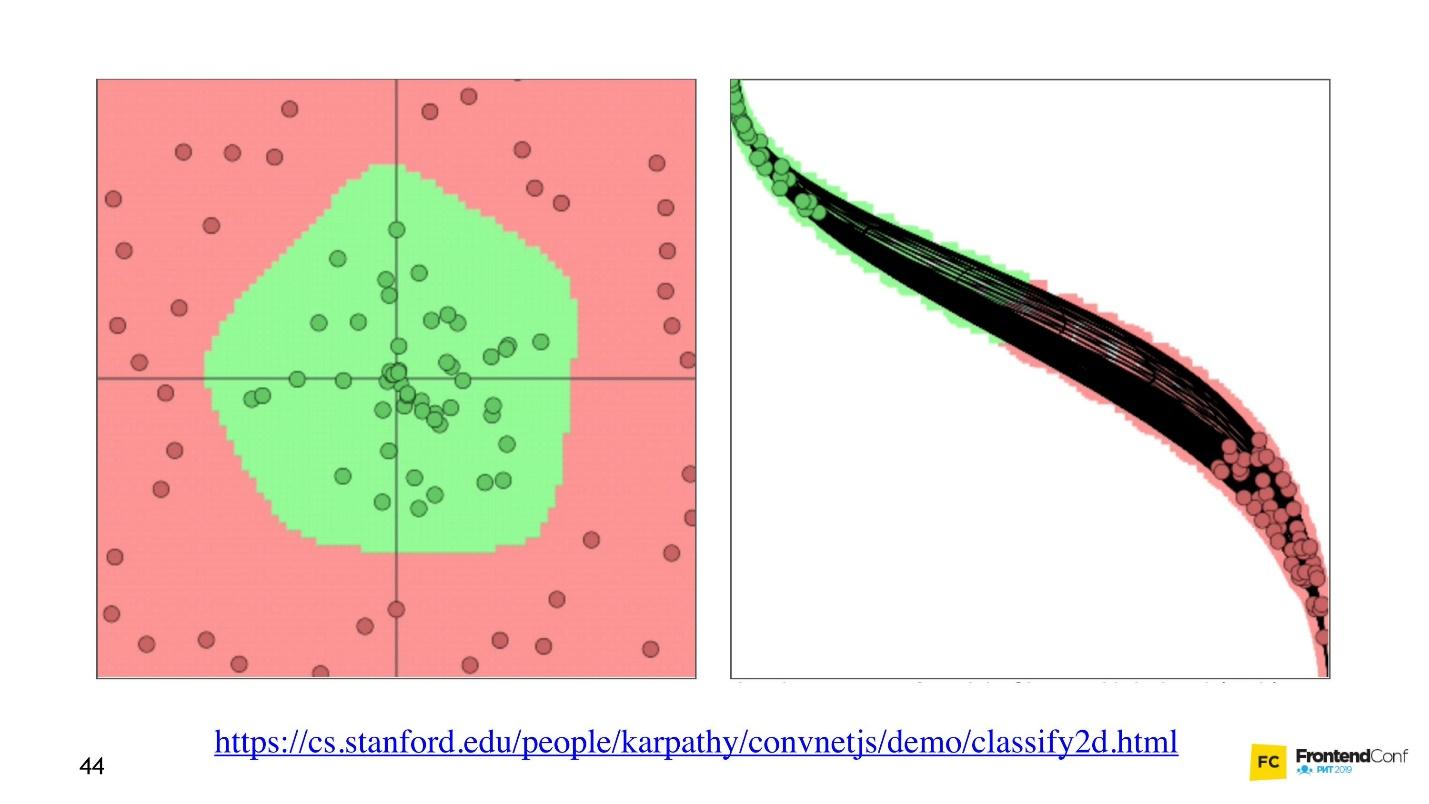
Links sind Daten und rechts ist eine der Ebenen. Es ist ersichtlich, dass das Ändern der Werte innerhalb der Ebenenarrays das Koordinatensystem zu ändern scheint. So Anpassung an die Daten und Lernen. Lernen ist also der Prozess der Auswahl der richtigen Werte für Layer-Arrays. Diese Werte werden als Gewichte oder Gewichte bezeichnet.
Maschinelles Lernen ist schwer
Ich möchte dich verärgern, maschinelles Lernen ist schwer. All dies ist eine große Vereinfachung. In Zukunft werden Sie eine große Menge linearer Algebra finden, die ziemlich komplex ist. Leider gibt es kein Entrinnen davon.
Natürlich gibt es Kurse, aber selbst das schnellste Training dauert mehrere Monate und ist nicht billig. Außerdem müssen Sie es noch selbst herausfinden. Das Feld des maschinellen Lernens ist so stark gewachsen, dass es fast unmöglich ist, alles im Auge zu behalten. Im Folgenden finden Sie beispielsweise eine Reihe von Modellen zum Lösen nur einer Aufgabe (Objekterkennung):

Persönlich war ich sehr demotiviert. Ich konnte mich den neuronalen Netzen nicht nähern und mit ihnen arbeiten. Aber ich habe einen Weg gefunden und möchte ihn mit Ihnen teilen. Es ist nicht revolutionär, es gibt nichts Vergleichbares, Sie kennen es bereits.
Blackbox - Ein einfacher Ansatz
Es ist nicht erforderlich, alle Aspekte des maschinellen Lernens zu verstehen, um zu lernen, wie Sie neuronale Netze auf Ihre Geschäftsaufgaben anwenden. Ich werde einige Beispiele zeigen, die Sie hoffentlich inspirieren.
Für viele ist ein Auto auch eine Black Box. Aber selbst wenn Sie nicht wissen, wie es funktioniert, müssen Sie die Regeln lernen. Beim maschinellen Lernen müssen Sie also noch einige Regeln kennen:
- Lernen Sie TensorFlow JS (Bibliothek für die Arbeit mit neuronalen Netzen).
- Lernen Sie, Modelle auszuwählen.
Wir konzentrieren uns auf diese Aufgaben und beginnen mit dem Code.
Lernen durch Erstellen von Code
Die TensorFlow-Bibliothek wurde für eine Vielzahl von Sprachen geschrieben: Python, C / C ++, JavaScript, Go, Java, Swift, C #, Haskell, Julia, R, Scala, Rust, OCaml, Crystal. Aber wir werden definitiv das Beste wählen - JavaScript.
TensorFlow kann durch Verbinden eines Skripts mit CDN mit unserer Seite verbunden werden:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
Oder benutze npm:
npm install @tensorflow/tfjs-node - für den npm install @tensorflow/tfjs-node (Website);npm install @tensorflow/tfjs-node-gpu (Linux CUDA) - für die GPU, jedoch nur, wenn der Linux-Computer und die Grafikkarte die CUDA-Technologie unterstützen. Stellen Sie sicher, dass die CUDA-Rechenkapazität mit Ihrer Bibliothek übereinstimmt, damit sich nicht herausstellt, dass teure Hardware nicht geeignet ist.npm install @tensorflow/tfjs ( npm install @tensorflow/tfjs / Browser) - für einen Browser ohne Verwendung von Node.js.
Um mit TensorFlow JS zu arbeiten, reicht es aus, eines der oben genannten Module zu importieren. Sie werden viele Codebeispiele sehen, in die alles importiert wird. Sie müssen dies nicht tun, wählen Sie nur einen aus und importieren Sie ihn.
Tensoren
Wenn die anfänglichen Daten fertig sind, müssen Sie zuerst
TensorFlow importieren . Wir werden Tensorflow / tfjs-node-gpu verwenden, um die Beschleunigung aufgrund der Leistung der Grafikkarte zu erhalten.
Es gibt ein zweidimensionales Datenarray - wir werden damit arbeiten.
Als nächstes muss
ein Tensor erstellt werden . In diesem Fall wird ein Tensor mit Rang 2 erzeugt, dh tatsächlich ein zweidimensionales Array. Wir übertragen die Daten und erhalten den 2x2-Tensor.
Beachten Sie, dass die
console.log aufgerufen wird und nicht
console.log , da
b (der von uns erstellte Tensor) kein gewöhnliches Objekt ist, nämlich der Tensor. Er hat seine eigenen Methoden und Eigenschaften.
Sie können auch einen Tensor aus einem planaren Array erstellen und seine Form im Auge behalten, sagen wir. Das heißt, ein Formular - ein zweidimensionales Array - zu deklarieren, einfach ein flaches Array zu übertragen und das Formular direkt anzugeben. Das Ergebnis wird das gleiche sein.
Aufgrund der Tatsache, dass die Daten und das Formular getrennt gespeichert werden können, ist es möglich, die Form des Tensors zu ändern. Wir können die
reshape aufrufen und die Form von 2x2 auf 4x1 ändern.
Der nächste wichtige Schritt besteht darin
, die Daten auszugeben und in die reale Welt zurückzugeben.
Der Code für alle drei Schritte.Die Datenmethode gibt Versprechen zurück. Nachdem es aufgelöst wurde, erhalten wir den unmittelbaren Wert des Rohwerts, aber asynchron. Wenn wir möchten, können wir es synchron abrufen, aber denken Sie daran, dass Sie hier an Leistung verlieren können. Verwenden Sie daher nach Möglichkeit asynchrone Methoden.
Die
dataSync Methode gibt Daten immer in einem Flat-Array-Format zurück. Und wenn wir die Daten in dem Format zurückgeben möchten, in dem sie im Tensor gespeichert sind, müssen wir
arraySync .
Betreiber
Alle Operatoren in TensorFlow sind
standardmäßig unveränderlich , dh bei jeder Operation wird immer ein neuer Tensor zurückgegeben. Nehmen Sie oben einfach unser Array und quadrieren Sie alle Elemente.
Warum solche Schwierigkeiten für einfache mathematische Operationen? Alle Operatoren, die wir brauchen - die Summe, der Median usw. - sind da. Dies ist erforderlich, da der Tensor und dieser Ansatz es Ihnen tatsächlich ermöglichen, ein Diagramm von Berechnungen zu erstellen und Berechnungen nicht sofort durchzuführen, sondern in WebGL (im Browser) oder CUDA (Node.js auf dem Computer). Das heißt, die tatsächliche Verwendung der Hardwarebeschleunigung ist für uns unsichtbar und führt bei Bedarf zu einem Fallback auf der CPU. Das Tolle ist, dass wir über nichts nachdenken müssen. Wir müssen nur die tfjs-API lernen.
Das Wichtigste ist jetzt das Modell.
Modell
Der einfachste Weg, ein Modell zu erstellen, ist Sequential, dh ein sequentielles Modell, wenn Daten von einer Ebene zur nächsten Ebene und von dieser zur nächsten Ebene übertragen werden. Die einfachsten Ebenen, die hier verwendet werden, werden verwendet.
Die Schicht selbst ist nur eine Abstraktion von Tensoren und Operatoren. Grob gesagt sind dies Hilfsfunktionen, die eine große Menge Mathematik vor Ihnen verbergen.
Versuchen wir zu verstehen, wie man mit dem Modell arbeitet, ohne auf die Implementierungsdetails einzugehen.
Zunächst geben wir die Form der Daten an, die in das neuronale Netzwerk fallen -
inputShape ist ein erforderlicher Parameter. Wir geben
units - die Anzahl der mehrdimensionalen Arrays und die Aktivierungsfunktion.
Die
relu Funktion
relu bemerkenswert, als sie zufällig gefunden wurde - sie wurde ausprobiert, sie funktionierte besser und sie suchten sehr lange nach einer mathematischen Erklärung, warum dies geschieht.
Für die letzte Ebene, wenn wir eine Kategorie erstellen, wird häufig die Softmax-Funktion verwendet - sie eignet sich sehr gut zum Anzeigen einer Antwort im One-Hot-Encoding-Format. Rufen Sie nach dem
model.summary() des Modells
model.summary() auf, um sicherzustellen, dass das Modell richtig zusammengesetzt ist. In besonders schwierigen Situationen können Sie sich der Erstellung eines Modells mithilfe der funktionalen Programmierung nähern.
Wenn Sie ein besonders komplexes Modell erstellen müssen, können Sie den funktionalen Ansatz verwenden: Jedes Mal, wenn jede Ebene eine neue Variable ist. Als Beispiel nehmen wir die nächste Ebene manuell und wenden die vorherige Ebene darauf an, damit wir komplexere Architekturen erstellen können. Ich werde Ihnen später zeigen, wo dies nützlich sein kann.
Das nächste sehr wichtige Detail ist, dass wir die Eingabe- und Ausgabeschichten in das Modell übergeben, dh die Schichten, die in das neuronale Netzwerk eintreten, und die Schichten, die Schichten für die Antwort sind.
Danach ist ein wichtiger Schritt das
Kompilieren des Modells . Versuchen wir zu verstehen, was Kompilierung in Bezug auf tfjs ist.
Denken Sie daran, wir haben versucht, die richtigen Werte in unserem neuronalen Netzwerk zu finden. Es ist nicht notwendig, sie abzuholen. Sie werden auf eine bestimmte Weise ausgewählt, wie die Optimierungsfunktion sagt.
Code zur Beschreibung von sequentiellen Ebenen und zur Kompilierung.Ich werde veranschaulichen, was ein Optimierer ist und was eine Verlustfunktion ist.
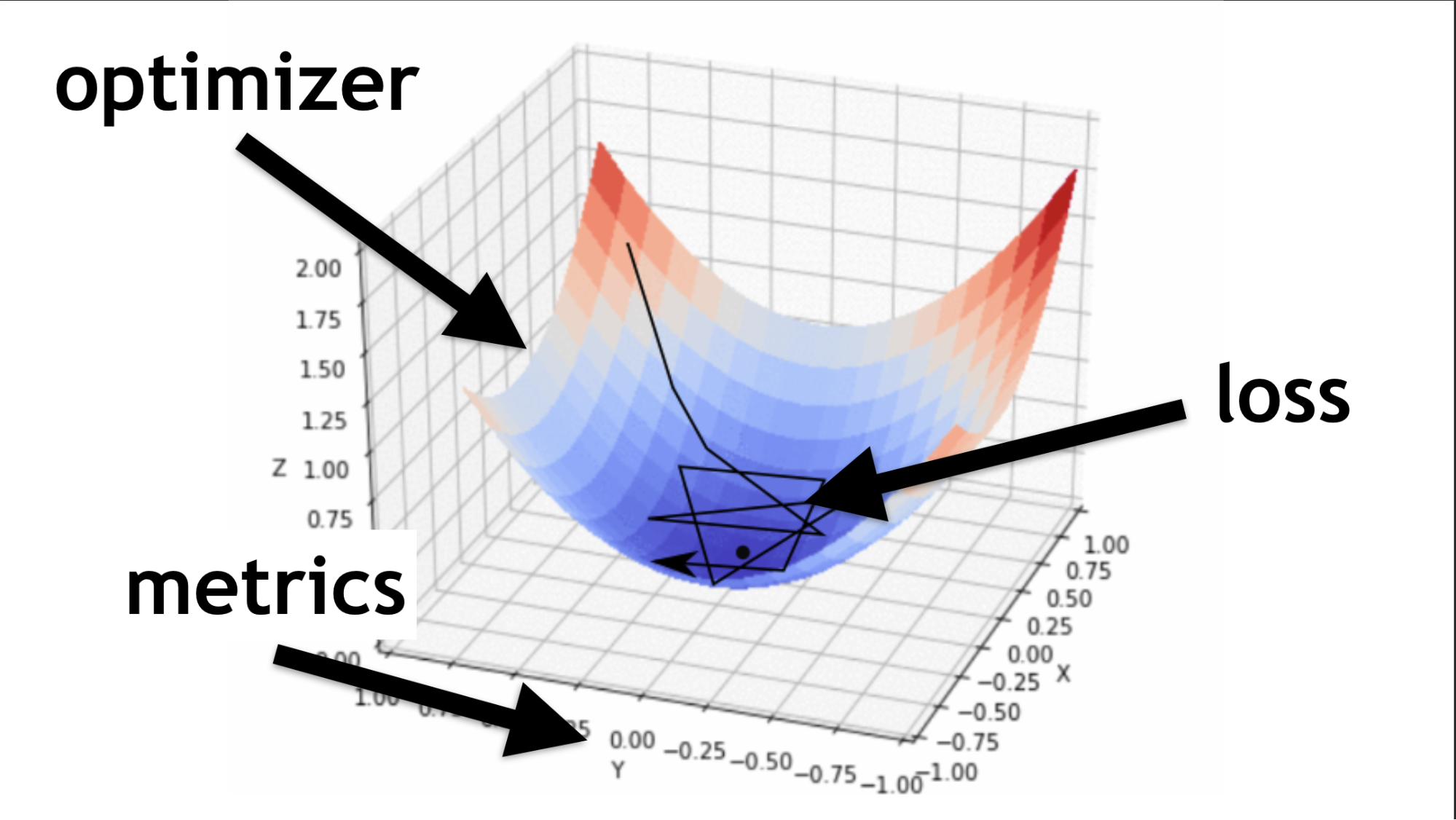
Der Optimierer ist die gesamte Karte. Es ermöglicht Ihnen, nicht nur zufällig herumzulaufen und nach Wert zu suchen, sondern dies nach einem bestimmten Algorithmus mit Bedacht zu tun.
Die Verlustfunktion ist die Art und Weise, wie wir nach dem optimalen Wert suchen (kleiner schwarzer Pfeil). Es hilft zu verstehen, welche Gradientenwerte zum Trainieren unseres neuronalen Netzwerks verwendet werden sollen.
Wenn Sie in Zukunft neuronale Netze beherrschen, werden Sie selbst eine Verlustfunktion schreiben. Ein großer Teil des Erfolgs eines neuronalen Netzwerks hängt davon ab, wie gut diese Funktion geschrieben ist. Aber das ist eine andere Geschichte. Fangen wir einfach an.
Beispiel für ein Netzwerklernen
Wir werden zufällige Daten und zufällige Antworten (Labels) generieren. Wir rufen das
fit Modul auf, übergeben die Daten, Antworten und einige wichtige Parameter:
epochs - 5 Mal, das heißt ungefähr 5 Mal, werden wir ein vollwertiges Training durchführen;batchSize , wie viele Gewichte gleichzeitig zum Heben geändert werden können - wie viele Elemente gleichzeitig verarbeitet werden müssen. Je besser die Grafikkarte ist, desto mehr Speicher kann über batchSize eingestellt werden.
Code aller letzten Schritte.Model.fit asynchrone Methode
Model.fit gibt ein Versprechen zurück. Auf diese Weise können Sie jedoch async / await verwenden und auf die Ausführung warten.
Als nächstes ist die
Verwendung . Wir haben unser Modell trainiert, dann nehmen wir die Daten, die wir verarbeiten möchten, und nennen die
predict . Wir sagen: "Vorhersagen, was wirklich da ist?", Und dank dessen erhalten wir das Ergebnis.
Standardstruktur
Jedes neuronale Netzwerk hat drei Hauptdateien:
- index.js - Datei, in der alle Parameter des neuronalen Netzwerks gespeichert sind;
- model.js - eine Datei, in der das Modell und seine Architektur direkt gespeichert werden;
- data.js - eine Datei, in der Daten gesammelt, verarbeitet und in unser System eingebettet werden.
Also sprach ich darüber, wie man TensorFlow.js lernt. Kleinunternehmen bleibt
es, ein Modell zu wählen .
Dies ist leider nicht ganz richtig. Tatsächlich müssen Sie jedes Mal, wenn Sie ein Modell auswählen, bestimmte Schritte wiederholen.
- Bereiten Sie Daten dafür vor, dh machen Sie die Einbettung und passen Sie sie an die Architektur an.
- Konfigurieren Sie die Hyper-Einstellungen (ich werde Ihnen später sagen, was dies bedeutet).
- Trainiere / trainiere jedes neuronale Netzwerk (jedes Modell kann seine eigenen Nuancen haben).
- Wenden Sie ein neuronales Modell an, und Sie können es auch auf verschiedene Arten anwenden.
Wählen Sie ein Modell
Beginnen wir mit den grundlegenden Optionen, auf die Sie häufig stoßen werden.
Tiefer Sinn
Dies ist ein beliebtes Beispiel für ein tiefes neuronales Netzwerk. Alles ist ganz einfach gemacht: Es gibt einen öffentlich verfügbaren Datensatz - MNIST-Datensatz.
Dies sind beschriftete Bilder mit Zahlen, auf deren Grundlage es bequem ist, ein neuronales Netzwerk zu trainieren.
In Übereinstimmung mit der Architektur der One-Hot-Codierung codieren wir jede der letzten Schichten. Ziffern 10 - dementsprechend gibt es am Ende 10 letzte Schichten. Wir senden einfach Schwarzweißbilder an den Eingang, all dies ist sehr ähnlich zu dem, worüber wir am Anfang gesprochen haben.
const model = tf.sequential({ layers: [ tf.layers.dense({ inputShape: [784], units: 512, activation: 'relu' }), tf.layers.dense({ units: 256, activation: 'relu' }), tf.layers.dense({ units: 10, activation: 'softmax' }), ] });
Wir begradigen das Bild zu einem eindimensionalen Array, wir erhalten 784 Elemente. In einer Schicht 512 Arrays. Aktivierungsfunktion
'relu' .
Die nächste Schicht von Arrays ist etwas kleiner (256), die Aktivierungsschicht ist ebenfalls
'relu' . Wir haben die Anzahl der Arrays reduziert, um nach allgemeineren Merkmalen zu suchen. Das neuronale Netzwerk muss aufgefordert werden, zu lernen, und gezwungen sein, eine ernstere, allgemeine Entscheidung zu treffen, weil sie es selbst nicht tun wird.
Am Ende erstellen wir 10 Matrizen und verwenden die Softmax-Aktivierung für die One-Hot-Codierung. Diese Art der Aktivierung funktioniert gut mit dieser Art der Antwortcodierung.
In tiefen Netzwerken können Sie 80-90% der Bilder korrekt erkennen - ich möchte mehr. Eine Person erkennt mit einer Qualität von ca. 96%. Können neuronale Netze eine Person fangen und überholen?
CNN (Convolutional Neural Network)
Faltungsnetzwerke funktionieren wahnsinnig einfach. Am Ende haben sie die gleiche Architektur wie in den vorherigen Beispielen. Aber am Anfang passiert etwas anderes. Arrays reduzieren das Bild, anstatt nur einige Lösungen anzugeben. Sie nehmen an dem Bild teil und reduzieren es auf eine Ziffer. Dann werden sie alle zusammen gesammelt und wieder reduziert.
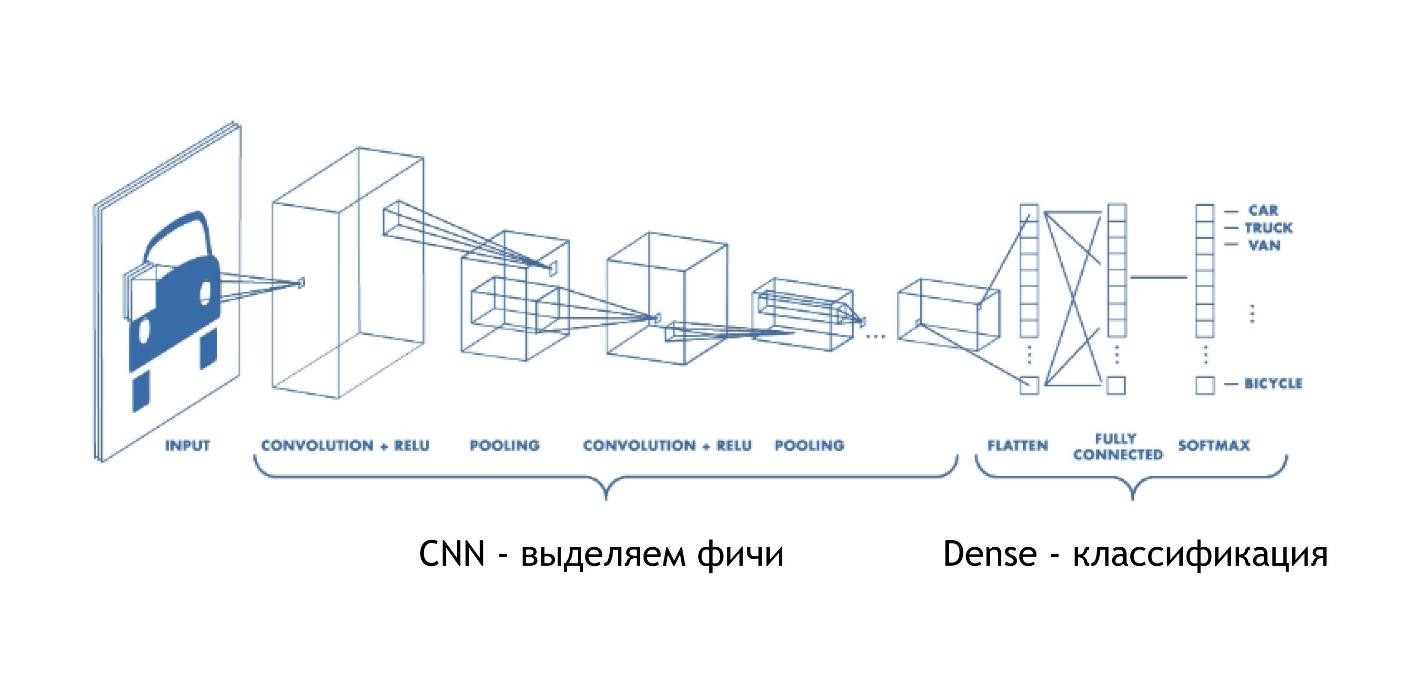
Dadurch wird die Größe des Bildes verringert, gleichzeitig werden Teile des Bildes immer besser erkannt. Faltungsnetzwerke eignen sich sehr gut für die Mustererkennung, sogar besser als Menschen.
Das Erkennen von Bildern wird einem Auto besser anvertraut als einer Person. Es gab eine spezielle Studie, und die Person verlor leider.
CNNs funktionieren sehr einfach:
const model = tf.sequential({ layers: [ tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.maxPooling2d({poolSize: [2, 2]}), tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', }) tf.layers.flatten(tf.layers.maxPooling2d({ poolSize: [2, 2] })), tf.layers.dense({units: 512, activation: 'relu'}), tf.layers.dense({units: 10, activation: 'softmax'}) ] });
Wir geben ein bestimmtes mehrdimensionales Array ein: ein Bild mit 28 x 28 Pixel plus eine Dimension für die Helligkeit. In diesem Fall ist das Bild schwarzweiß, die dritte Dimension ist also 1.
Als Nächstes legen wir die Anzahl der
filters und
kernelSize - wie viele Pixel werden schmaler. Aktivierungsfunktion überall
relu .
Es gibt eine weitere Ebene
maxPooling2d , die benötigt wird, um die Größe noch effizienter zu reduzieren. Faltungsnetzwerke verengen die Größe sehr allmählich, und oft besteht keine Notwendigkeit, sehr tiefe Faltungsnetzwerke herzustellen.
Ich werde erklären, warum es etwas später unmöglich ist, sehr tiefe Faltungsnetzwerke zu erstellen, aber denken Sie vorerst daran: Manchmal müssen sie etwas schneller aufgerollt werden. Hierfür gibt es eine separate maxPooling-Ebene.
Ganz am Ende befindet sich die gleiche dichte Schicht. Das heißt, wir haben mithilfe von Faltungs-Neuronalen Netzen verschiedene Zeichen aus den Daten herausgezogen. Danach verwenden wir den Standardansatz und kategorisieren unsere Ergebnisse, dank derer wir die Bilder erkennen.
U net
Dieses Architekturmodell ist Faltungsnetzwerken zugeordnet. Mit seiner Hilfe wurden viele Entdeckungen auf dem Gebiet der Krebsbekämpfung gemacht, beispielsweise bei der Erkennung von Krebszellen und Glaukom. Darüber hinaus kann dieses Modell bösartige Zellen nicht schlechter finden als ein Professor auf diesem Gebiet.
Ein einfaches Beispiel: Unter den verrauschten Daten müssen Sie Krebszellen (Kreise) finden.

U-Net ist so gut, dass es sie fast perfekt finden kann. Die Architektur ist sehr einfach:
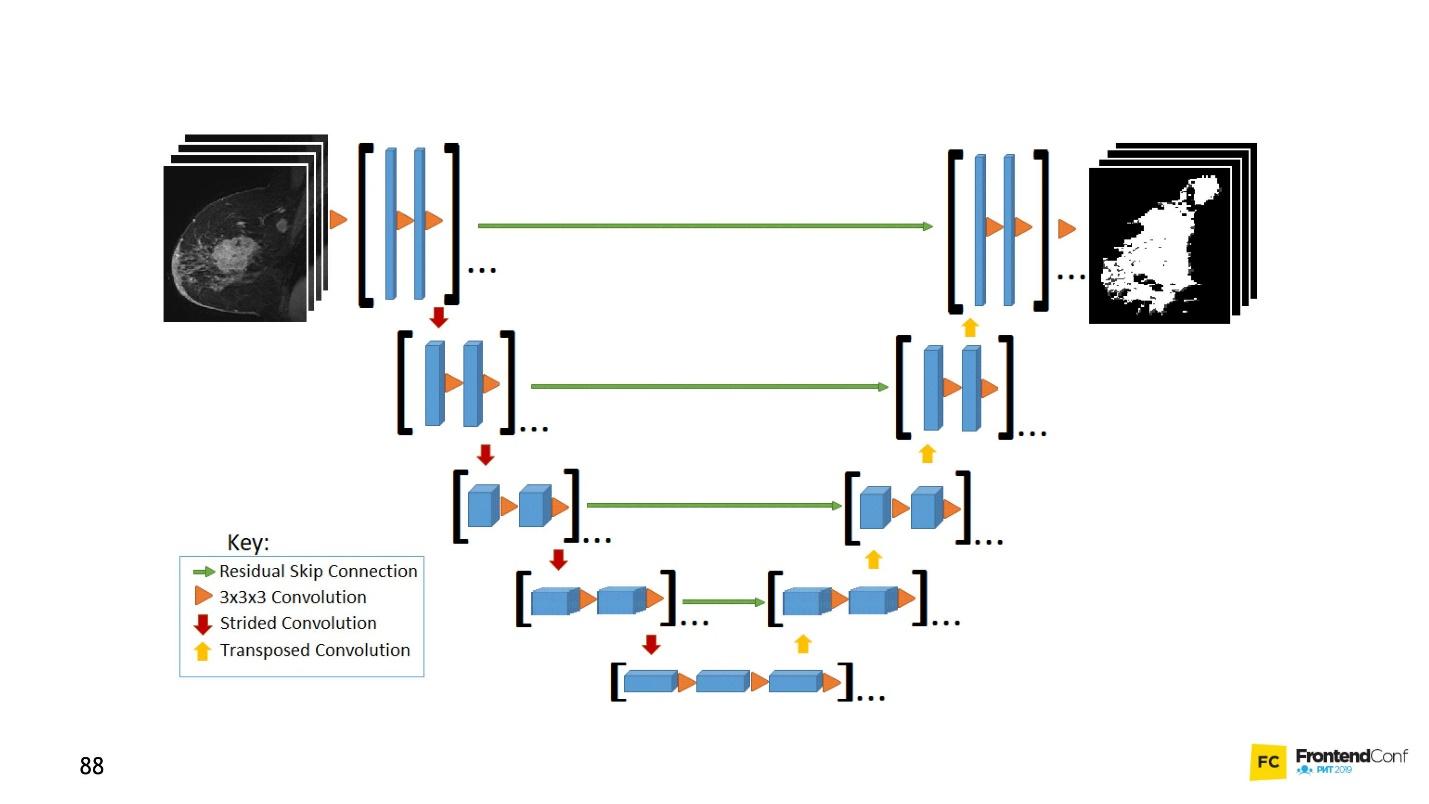
Es gibt dieselben Faltungsnetzwerke wie MaxPooling, wodurch die Größe verringert wird. Der einzige Unterschied: Das Modell verwendet auch
Scan- Netzwerke - das
Entfaltungsnetzwerk .
Zusätzlich zum Faltungsscan wird jede der Ebenen auf hoher Ebene miteinander kombiniert (Start und Ausgang), wodurch eine große Anzahl von Beziehungen auftritt. Solche U-Net funktionieren auch bei kleinen Datenmengen gut.
Dieser Code ist im Editor leichter zu erlernen. Im Allgemeinen wird hier eine große Anzahl von Faltungsnetzwerken erstellt. Um sie wieder bereitzustellen,
concatenate wir mehrere Ebenen und führen sie zusammen. Dies ist nur eine Visualisierung eines Bildes, nur in Codeform. Alles ist ganz einfach - das Kopieren und Reproduzieren eines solchen Modells ist einfach.
LSTM (Long Short-Term Memory)
Beachten Sie, dass alle betrachteten Beispiele eine Funktion haben - das Eingabedatenformat ist festgelegt. Bei der Eingabe in das Netzwerk müssen die Daten gleich groß sein und miteinander übereinstimmen. LSTM-Modelle konzentrieren sich darauf, wie sie damit umgehen sollen.
Zum Beispiel gibt es einen Dienst Yandex.Referats, der Abstracts generiert.
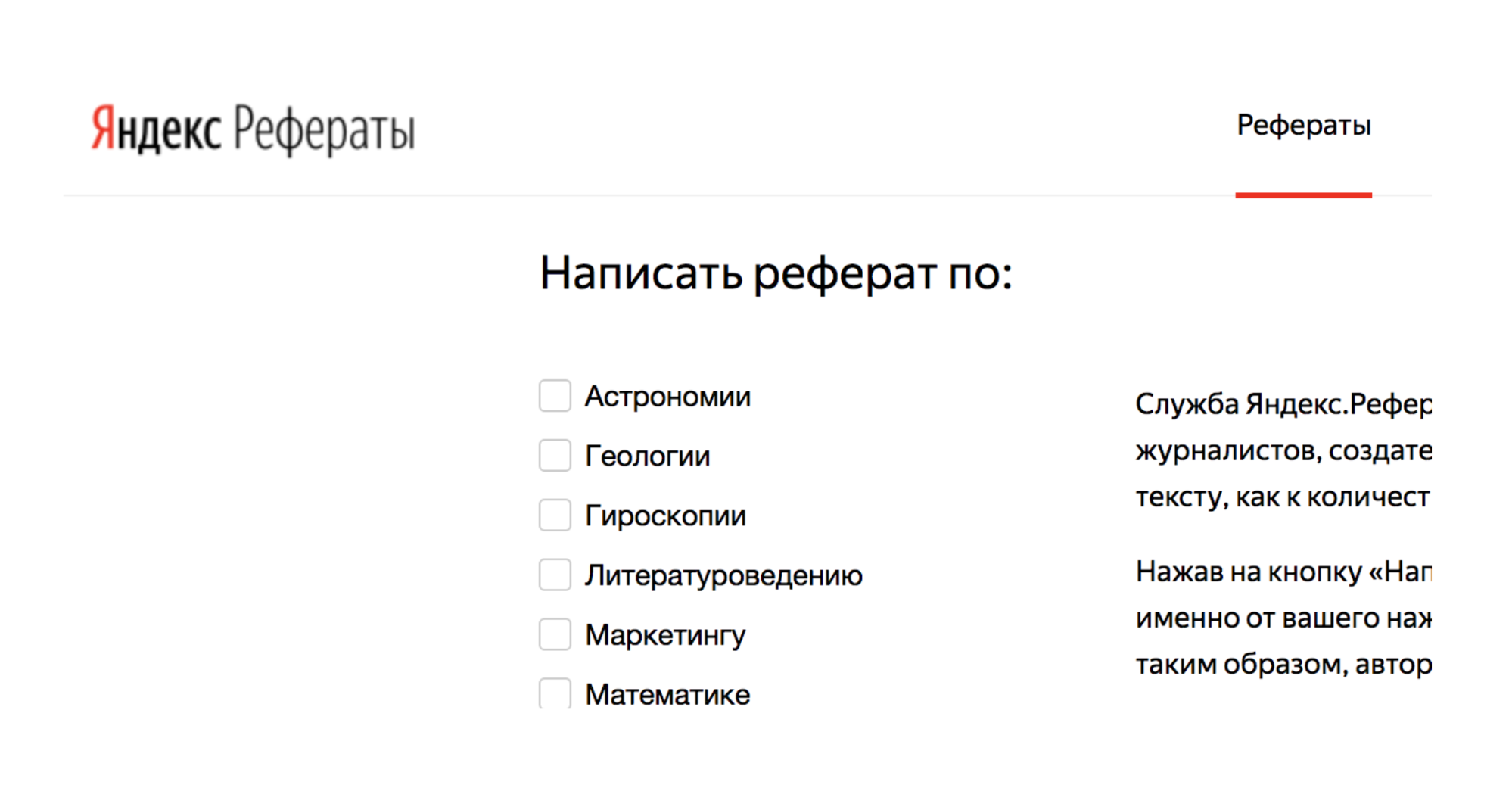
Er gibt einen vollständigen Abrakadabra aus, der aber gleichzeitig der Wahrheit ziemlich ähnlich ist:
Zusammenfassung in Mathematik zum Thema: "Newtons Binom als Axiom"
Gemäß dem Vorstehenden erzeugt das Oberflächenintegral ein krummliniges Integral. Die nach unten konvexe Funktion ist weiterhin gefragt.
Daraus folgt natürlich, dass die Normalität zur Oberfläche noch gefragt ist. Gemäß dem vorherigen spezifiziert das Poisson-Integral im Wesentlichen das trigonometrische Poisson-Integral.
Der Dienst basiert auf neuronalen Seq-to-Seq-Netzen. Ihre Architektur ist komplexer.

Schichten sind in einem ziemlich komplexen System angeordnet. Aber seien Sie nicht beunruhigt - Sie müssen nicht alle diese Pfeile selbst ausführen. Wenn Sie möchten, können Sie, aber nicht notwendig. Es gibt einen Helfer, der dies für Sie erledigt.
Die Hauptsache zu verstehen ist, dass jedes dieser Stücke mit dem vorherigen kombiniert wird. Es werden Daten nicht nur aus den Anfangsdaten, sondern auch aus der vorherigen neuronalen Schicht entnommen. Grob gesagt ist es möglich, eine Art Speicher aufzubauen - eine Sequenz von Daten zu speichern, zu reproduzieren und aufgrund dieser Arbeit „Sequenz zu Sequenz“. Darüber hinaus können die Sequenzen sowohl am Eingang als auch am Ausgang unterschiedlich groß sein.
Im Code sieht alles schön aus:
tf.sequential({ layers: [ tf.layers.lstm({ units: 512, returnSequences: true, inputShape: [10000, 64] }), tf.layers.lstm({ units: 512, returnSequences: false }), tf.layers.dense({ units: 64, activation: 'softmax' }) ] }) ;
Es gibt einen speziellen Helfer, der besagt, dass wir 512 Objekte (Arrays) haben.
inputShape: [10000, 64] Nächstes die Sequenz und das Eingabeformular zurück (
inputShape: [10000, 64] ). Als nächstes führen wir eine weitere Ebene ein, geben aber die Sequenz nicht zurück (
returnSequences: false ), da wir am Ende sagen, dass wir jetzt die Aktivierungsfunktion für 64 verschiedene Zeichen (Klein- und Großbuchstaben) verwenden müssen. 64 Optionen werden mithilfe der One-Hot-Codierung aktiviert.
Am interessantesten
Jetzt fragen Sie sich wahrscheinlich: „Das ist natürlich alles gut, aber warum brauche ich es? "Krebs zu bekämpfen ist gut, aber warum brauche ich ihn an vorderster Front?"
Und Tänze mit einem Tamburin beginnen: um herauszufinden, wie man beispielsweise neuronale Netze auf das Layout anwendet.
Mit Hilfe neuronaler Netze können Probleme gelöst werden, die bisher nicht zu lösen waren. Einige, an die man nicht einmal denken konnte. Es hängt alles von Ihnen, Ihrer Vorstellungskraft und ein wenig Übung ab.
Jetzt werde ich live interessante Beispiele für die Verwendung der von uns untersuchten Modelle zeigen.
CNN Audio-Teams
Mithilfe von Faltungsnetzwerken können Sie nicht nur Bilder, sondern auch Audiobefehle erkennen. Bei einer Erkennungsqualität von 97%, dh auf der Ebene von Google Assistant und Yandex-Alice.
Natürlich ist es allein im Netzwerk nicht möglich, vollwertige Sprache und Sätze zu erkennen, aber Sie können einen einfachen Sprachassistenten erstellen.
Weitere Informationen zu Alice finden Sie im
Bericht von Nikita Dubko sowie zum Google-Assistenten, zum Umgang mit Sprache und zu Browserstandards.
Tatsache ist, dass jedes Wort, jeder Befehl in ein Spektrogramm umgewandelt werden kann.
Sie können beliebige Audioinformationen in ein solches Spektrogramm konvertieren. Anschließend können Sie das Audio im Bild codieren, CNN auf das Bild anwenden und einfache Sprachbefehle erkennen.
U-net. Screenshot-Test
U-Net eignet sich nicht nur für eine erfolgreiche Krebsdiagnose, sondern auch zum Testen von Screenshots. Einzelheiten finden Sie im
Bericht von Lyudmila Mzhachikh, und ich werde die Basis selbst informieren.
Zum Testen mit Screenshots werden zwei Screenshots benötigt:
- Grund (Referenz), mit dem wir vergleichen;
- Screenshot zum Testen.

Leider gibt es beim Screenshot-Testen oft viele negative Stürze (falsch positive). Dies kann jedoch vermieden werden, indem fortschrittliche Krebsbekämpfungstechnologien auf das Front-End angewendet werden.
Denken Sie daran, wir haben das Bild in dem Bereich markiert, in dem Krebs vorliegt und nicht. Das gleiche kann hier gemacht werden.
Wenn wir ein Bild mit einem guten Layout sehen, markieren wir es nicht und wir markieren Bilder mit einem schlechten Layout. So können Sie das Layout mit einem einzigen Bild testen. , , , . U-Net .
, , . , U-Net, . , .
LSTM. Twitter — 2000
, , , .
, LSTM . 40 - , :
« — » .
, :

- , ?
— . - :


, «» , , (, ).
:
« » « » .
— .
« ».
:

EPOCS 250
, .
- , , , . , Overfitting — .
, — . , , . , , , .
, , .
, .

, , , . ( , ), . .
— . .
overfitting. , helper-: Dropout; BatchNormalization.
LSTM. Prettier
, — Prettier . , .
const a = 1 . :
[]c co on ns st , , :
[][] []c co on ns st , .
, , .
, , . , , 0 — , - , - . .
, . .
Anstelle von Schlussfolgerungen
, , . . , , Deep Neural Network.
. , . . . .
JS, , . , . , JavaScript, . TensorFlow.js.
, . telegram- JS.FrontendConf , 13 . 32 .
, , . Saint AppsConf, . , , , .