Hinweis perev. : Der führende Ingenieur von Zalando, Henning Jacobs, hat wiederholt Probleme mit Kubernetes-Benutzern beim Verständnis des Zwecks von Lebendigkeitssonden (und Bereitschaftssonden) und ihrer korrekten Anwendung festgestellt. Daher sammelte er seine Gedanken in diesem umfangreichen Artikel, der im Laufe der Zeit Teil der Dokumentation des K8 werden wird.
Gesundheitschecks, die in Kubernetes als
Lebendigkeitssonden bekannt sind ( dh wörtlich „Lebensfähigkeitstests“ - ca. übersetzt) , können sehr gefährlich sein. Ich empfehle, sie nach Möglichkeit zu vermeiden: Die einzigen Ausnahmen sind Fälle, in denen sie wirklich notwendig sind und Sie sich der Besonderheiten und Folgen ihrer Verwendung voll bewusst sind. Diese Veröffentlichung konzentriert sich auf Lebendigkeits- und Bereitschaftsprüfungen und erklärt auch, in welchen Fällen
es sich lohnt und welche nicht, sie zu verwenden.
Mein Kollege Sandor hat kürzlich auf Twitter die häufigsten Fehler mitgeteilt, auf die er stößt, einschließlich der Fehler bei der Verwendung von Bereitschafts- / Lebendigkeitssonden:
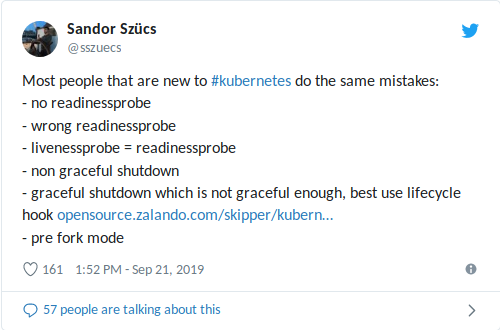
Eine falsch konfigurierte
livenessProbe kann Situationen mit hoher Last (Lawinenabschaltung + möglicherweise langer Start des Containers / der Anwendung) verschlimmern und zu anderen negativen Konsequenzen führen, z. B. zu einem Rückgang der Abhängigkeiten
(siehe auch meinen kürzlich erschienenen Artikel zur Begrenzung der Anzahl der Anforderungen im K3s + ACME-Bundle) . Schlimmer noch, wenn eine Lebendigkeitssonde mit einer Integritätsprüfung kombiniert wird, die als externe Datenbank fungiert: Der
einzige Datenbankfehler startet alle Ihre Container neu !
Die allgemeine Meldung
„Verwenden Sie keine Lebendigkeitssonden“ hilft in diesem Fall ein wenig. Daher werden wir uns überlegen, wozu Bereitschafts- und Lebendigkeitsprüfungen dienen.
Hinweis: Der größte Teil des folgenden Tests war ursprünglich in der internen Dokumentation für Zalando-Entwickler enthalten.Bereitschafts- und Lebendigkeitsprüfungen
Kubernetes bietet zwei wichtige Mechanismen, die als
Lebendigkeitssonden und Bereitschaftssonden bezeichnet werden . Sie führen regelmäßig eine Aktion aus, z. B. eine HTTP-Anforderung senden, eine TCP-Verbindung öffnen oder einen Befehl in einem Container ausführen, um zu bestätigen, dass die Anwendung ordnungsgemäß funktioniert.
Kubernetes verwendet
Bereitschaftssonden, um zu verstehen, wann ein Container für den Empfang von Datenverkehr bereit ist. Ein Pod gilt als betriebsbereit, wenn alle Behälter bereit sind. Eine Anwendung dieses Mechanismus besteht darin, zu steuern, welche Pods als Backends für Kubernetes-Dienste (und insbesondere Ingress) verwendet werden.
Liveness-Tests helfen Kubernetes zu verstehen, wann es Zeit ist, den Container neu zu starten. Mit einer solchen Überprüfung können Sie beispielsweise einen Deadlock abfangen, wenn die Anwendung an einer Stelle "hängen bleibt". Ein Neustart des Containers in diesem Zustand hilft, die Anwendung trotz Fehlern vom Boden zu entfernen, kann aber auch zu Kaskadenfehlern führen (siehe unten).
Wenn Sie versuchen, ein Update für eine Anwendung bereitzustellen, bei der die Überprüfung der Lebendigkeit / Bereitschaft fehlschlägt, wird die Einführung abgebrochen, da Kubernetes von allen Pods auf den Status "
Ready wartet.
Beispiel
Hier ist ein Beispiel für eine Bereitschaftsprüfung, die den Pfad
/health über HTTP mit Standardeinstellungen überprüft (
Intervall : 10 Sekunden,
Zeitüberschreitung : 1 Sekunde,
Erfolgsschwelle : 1,
Fehlerschwelle : 3):
# deployment'/ podTemplate: spec: containers: - name: my-container # ... readinessProbe: httpGet: path: /health port: 8080
Empfehlungen
- Definieren Sie für Microservices mit einem HTTP-Endpunkt (REST usw.) immer einen Bereitschaftstest , der prüft, ob die Anwendung (Pod) bereit ist, Datenverkehr zu empfangen.
- Stellen Sie sicher, dass der Bereitschaftstest die Verfügbarkeit des tatsächlichen Webserver-Ports abdeckt :
- Stellen Sie bei Verwendung von Ports für administrative Anforderungen mit den Namen "admin" oder "management" (z. B. 9090) für "
readinessProbe sicher, dass der Endpunkt nur dann "OK" zurückgibt, wenn der Haupt-HTTP-Port (wie 8080) bereit ist, Datenverkehr zu akzeptieren *.
* Ich kenne mindestens einen Fall in Zalando, in dem dies nicht geschehen ist, readinessProbe hat den "Management" readinessProbe überprüft, aber der Server selbst wurde aufgrund von Problemen beim Laden des Caches nicht gestartet. - Das Aufhängen der Bereitschaftsprüfung an einem separaten Port kann dazu führen, dass die Überlastung des Hauptports nicht in der Integritätsprüfung berücksichtigt wird (dh der Thread-Pool auf dem Server ist voll, die Integritätsprüfung zeigt jedoch weiterhin, dass alles in Ordnung ist).
- Stellen Sie sicher, dass die Bereitschaftsprüfung die Initialisierung / Migration der Datenbank ermöglicht .
- Der einfachste Weg, dies zu erreichen, besteht darin, erst nach Abschluss der Initialisierung auf den HTTP-Server zuzugreifen (z. B. Datenbankmigration von Flyway usw.). Anstatt den Status der Integritätsprüfung zu ändern, starten Sie den Webserver einfach erst, wenn die Datenbankmigration * abgeschlossen ist.
* Sie können auch Datenbankmigrationen von Init-Containern außerhalb des Pods ausführen. Ich bin immer noch ein Fan von eigenständigen Anwendungen, dh solchen, bei denen der Anwendungscontainer ohne externe Koordination weiß, wie die Datenbank in den gewünschten Zustand gebracht werden kann.
- Verwenden Sie
httpGet für Bereitschaftsprüfungen über typische Endpunkte von Gesundheitsprüfungen (z. B. /health ). successThreshold: 1 ( interval: 10s , timeout: 1s , successThreshold: 1 , failureThreshold: 3 ):- Standardparameter bedeuten, dass der Pod in etwa 30 Sekunden nicht bereit ist (3 erfolglose Integritätsprüfungen).
- Verwenden Sie einen separaten Port für "admin" oder "management", wenn der Technologie-Stack (z. B. Java / Spring) dies ermöglicht, um die Verwaltung von Integrität und Metriken vom normalen Datenverkehr zu trennen:
- aber vergessen Sie nicht Absatz 2.
- Bei Bedarf kann die Bereitschaftssonde verwendet werden, um den Cache aufzuwärmen / zu laden und den Statuscode 503 zurückzugeben, bis der Container „aufgewärmt“ ist:
- Ich empfehle Ihnen auch, sich mit dem neuen
startupProbe Check vertraut zu startupProbe , der in Version 1.16 erschien (wir haben hier auf Russisch darüber geschrieben - ca. übersetzt) .
Warnungen
- Verlassen Sie sich bei der Durchführung von Bereitschafts- / Lebendigkeitstests nicht auf externe Abhängigkeiten (z. B. Datenspeicher) - dies kann zu Kaskadenfehlern führen:
- Nehmen wir als Beispiel einen zustandsbehafteten REST-Service mit 10 Pods in Abhängigkeit von einer Postgres-Datenbank: Wenn die Überprüfung von einer funktionierenden Verbindung zur Datenbank abhängt, können alle 10 Pods fallen, wenn es im Netzwerk / auf der Datenbankseite zu Verzögerungen kommt. normalerweise endet alles schlimmer als es könnte;
- Beachten Sie, dass Spring Data standardmäßig die Verbindung zur Datenbank * überprüft.
* Dies ist das Standardverhalten von Spring Data Redis (zumindest war es so, als ich es das letzte Mal überprüft habe), was zu einem „katastrophalen“ Fehler führte: Als Redis für kurze Zeit nicht verfügbar war, fielen alle Pods. - "Extern" in diesem Sinne kann auch andere Pods derselben Anwendung bedeuten, dh im Idealfall sollte die Überprüfung nicht vom Status anderer Pods desselben Clusters abhängen, um kaskadierende Abstürze zu vermeiden:
- Die Ergebnisse können für Anwendungen mit verteiltem Status variieren (z. B. In-Memory-Caching in Pods).
- Verwenden Sie keine Lebendigkeitssonde für Pods (Ausnahmen sind Fälle, in denen sie wirklich notwendig sind und Sie sich der Besonderheiten und Konsequenzen ihrer Verwendung voll bewusst sind):
- Liveness Probe kann helfen, "hängengebliebene" Container wiederherzustellen. Da Sie jedoch die volle Kontrolle über Ihre Anwendung haben, sollten Dinge wie "hängengebliebene" Prozesse und Deadlocks im Idealfall nicht auftreten: Die beste Alternative besteht darin, die Anwendung absichtlich zu löschen und an sie zurückzugeben vorheriger stationärer Zustand;
- Ein fehlgeschlagener Liveness-Test startet den Container neu, wodurch sich die Folgen von Ladefehlern möglicherweise verschlimmern: Ein Neustart des Containers führt zu Ausfallzeiten (zumindest für die Startzeit der Anwendung, z. B. für mehr als 30 Sekunden), die neue Fehler verursachen und die Belastung erhöhen andere Behälter und Erhöhung der Wahrscheinlichkeit ihres Ausfalls usw.;
- Lebendigkeitsprüfungen in Kombination mit einer externen Abhängigkeit sind die schlechtesten Kombinationen, die zu Kaskadenfehlern führen können: Eine leichte Verzögerung auf der Datenbankseite startet alle Ihre Container neu!
- Die Parameter für Lebendigkeits- und Bereitschaftsprüfungen sollten unterschiedlich sein :
- Sie können die Lebendigkeitssonde mit derselben Integritätsprüfung verwenden, aber mit einem höheren Schwellenwert (
failureThreshold ) können Sie beispielsweise den Status nach 3 Versuchen als nicht bereit zuweisen und davon ausgehen, dass die Lebendigkeitssonde nach 10 Versuchen fehlgeschlagen ist.
- Verwenden Sie keine Exec-Checks , da diese mit bekannten Problemen verbunden sind, die zum Auftreten von Zombie-Prozessen führen:
Zusammenfassung
- Verwenden Sie Bereitschaftssonden, um festzustellen, wann ein Pod für den Empfang von Datenverkehr bereit ist.
- Verwenden Sie Lebendigkeitssonden nur dann, wenn sie wirklich benötigt werden.
- Die falsche Verwendung von Bereitschafts- / Lebendigkeitssonden kann zu einer verringerten Verfügbarkeit und zu Kaskadenfehlern führen.

Zusätzliche Materialien zum Thema
Update Nr. 1 vom 29.09.2019
Informationen zu Init-Containern für die Datenbankmigration : Fußnote hinzugefügt.
EJ erinnerte mich an PDB: Eines der Probleme bei der Überprüfung der Lebendigkeit ist die mangelnde Koordination zwischen den Pods. Kubernetes verfügt über
Pod Disruption Budgets (PDBs) , um die Anzahl gleichzeitiger Fehler zu begrenzen, die bei einer Anwendung auftreten können. Bei Überprüfungen werden PDBs jedoch nicht berücksichtigt. Im Idealfall können wir K8s bestellen: "Starten Sie einen Pod neu, wenn seine Überprüfung fehlschlägt, aber starten Sie nicht alle neu, um ihn nicht zu verschlimmern."
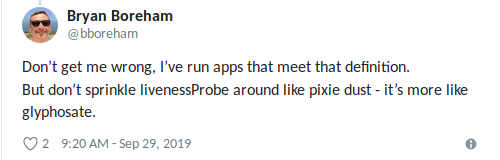
Bryan formulierte perfekt : „Verwenden Sie Lebendigkeit, wenn Sie sicher sind, dass das
Beste, was Sie tun können, darin besteht, die Anwendung zu„ töten “(lassen Sie sich auch hier nicht mitreißen).
Update Nr. 2 vom 29.09.2019
Zum Lesen der Dokumentation vor der Verwendung : Ich habe eine
Funktionsanforderung erstellt , um die Dokumentation zu Lebendigkeitssonden zu ergänzen.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: