Wie kann man Ideen, Architekturen und Algorithmen testen, ohne Code zu schreiben? Wie formuliere und verifiziere ich ihre Eigenschaften? Was sind Modellprüfer und Modellfinder? Was tun, wenn die Fähigkeiten der Tests nicht ausreichen?
Hallo. Mein Name ist Vasil Dyadov, jetzt arbeite ich als Programmierer in Yandex.Mail. Bevor ich bei Intel arbeitete, hatte ich zuvor RTL-Code (Register Transfer Level) auf Verilog / VHDL für ASIC / FPGA entwickelt. Ich habe mich lange mit dem Thema Software- und Hardware-Zuverlässigkeit, Mathematik, Tools und Methoden beschäftigt, die zur Entwicklung von Software und Logik mit garantierten, vordefinierten Eigenschaften verwendet werden.
Dies ist der zweite Artikel in einer Reihe (der erste Artikel hier ), der Entwickler und Manager auf den technischen Ansatz für die Softwareentwicklung aufmerksam machen soll. In letzter Zeit wurde er trotz revolutionärer Änderungen in seinem Ansatz und seinen Unterstützungsinstrumenten zu Unrecht ignoriert.
Der erste Artikel erschien einigen Lesern zu abstrakt. Viele möchten ein Beispiel für die Verwendung eines technischen Ansatzes und formaler Spezifikationen unter realitätsnahen Bedingungen sehen.
In diesem Artikel sehen wir uns ein Beispiel für die tatsächliche Anwendung von TLA + zur Lösung eines praktischen Problems an.
Ich bin immer offen für Fragen im Zusammenhang mit der Softwareentwicklung und freue mich, mit den Lesern zu chatten (die Koordinaten für die Kommunikation finden Sie in meinem Profil).
Was ist TLA +?
Zunächst möchte ich ein paar Worte zu TLA + und TLC sagen.
TLA + (Temporal Logic of Actions + Data) ist ein Formalismus, der auf einer Art zeitlicher Logik basiert. Entworfen von Leslie Lamport.
Im Rahmen dieses Formalismus kann man den Raum der Systemverhaltensvarianten und die Eigenschaften dieser Verhaltensweisen beschreiben.
Der Einfachheit halber können wir annehmen, dass das Verhalten des Systems durch eine Folge seiner Zustände dargestellt wird (wie unendliche Perlen, Kugeln auf einer Schnur), und die TLA + -Formel definiert eine Klasse von Ketten, die alle möglichen Varianten des Systemverhaltens beschreiben (eine große Anzahl von Perlen).
TLA + ist gut geeignet, um interagierende nicht deterministische Finite-State-Maschinen (zum Beispiel die Interaktion von Diensten in einem System) zu beschreiben, obwohl seine Ausdruckskraft ausreicht, um viele andere Dinge zu beschreiben (die in Logik erster Ordnung ausgedrückt werden können).
Und TLC ist ein Modellprüfer für explizite Zustände: ein Programm, das gemäß einer gegebenen TLA + -Systembeschreibung und Eigenschaftsformeln die Systemzustände durchläuft und bestimmt, ob das System die angegebenen Eigenschaften erfüllt.
In der Regel wird die Arbeit mit TLA + / TLC folgendermaßen aufgebaut: Wir beschreiben das System in TLA +, formalisieren interessante Eigenschaften in TLA + und führen TLC zur Überprüfung aus.
Da es nicht einfach ist, ein mehr oder weniger komplexes System in TLA + direkt zu beschreiben, wurde eine übergeordnete Sprache erfunden - PlusCal, das in TLA + übersetzt wird. PlusCal gibt es auf zwei Arten: mit Pascal- und C-ähnlicher Syntax. In dem Artikel, in dem ich Pascal-ähnliche Syntax verwendet habe, scheint es mir besser zu lesen. PlusCal in Bezug auf TLA + ist ungefähr dasselbe wie C in Bezug auf Assembler.
Hier werden wir nicht tief in die Theorie gehen. Literatur zum Eintauchen in TLA + / PlusCal / TLC finden Sie am Ende des Artikels.
Meine Hauptaufgabe ist es, die Anwendung von TLA + / TLC in einem einfachen und verständlichen Beispiel aus der Praxis zu zeigen.
In einigen Kommentaren zum vorherigen Artikel wurde mir vorgeworfen, dass ich nicht die theoretischen Grundlagen von Werkzeugen gemalt habe, aber der Zweck dieser Artikelserie war es, die praktische Anwendung von Werkzeugen für den technischen Ansatz in der Softwareentwicklung zu zeigen.
Ich denke, ein tiefes Eintauchen in die Theorie ist für niemanden von Interesse, aber wenn Sie interessiert sind, können Sie sich jederzeit an die PM wenden, um Links und Erklärungen zu erhalten. Soweit ich über ausreichende Kenntnisse verfüge (schließlich bin ich kein theoretischer Mathematiker, sondern ein Softwareentwickler), werde ich versuchen, zu antworten .
Erklärung des Problems
Zunächst werde ich ein wenig über die Aufgabe sprechen, für die TLA + verwendet wurde.
Die Aufgabe bezieht sich auf die Verarbeitung des Ereignisflusses. Nämlich zum Erstellen einer Warteschlange zum Speichern von Ereignissen und zum Senden von Benachrichtigungen über diese Ereignisse.
Das Data Warehouse ist physisch auf Basis des PostgreSQL-DBMS organisiert.
Die Hauptsache, die Sie wissen müssen:
- Es gibt Quellen für Ereignisse. Für unsere Zwecke können wir uns darauf beschränken, dass jedes Ereignis durch die Zeit gekennzeichnet ist, in der seine Verarbeitung geplant ist. Diese Quellen schreiben Ereignisse in die Datenbank. Normalerweise hängen der Zeitpunkt des Schreibens in die Datenbank und der Zeitpunkt der geplanten Verarbeitung in keiner Weise zusammen.
- Es gibt koordinierende Prozesse, die Ereignisse aus der Datenbank lesen und Benachrichtigungen über bevorstehende Ereignisse an die Komponenten des Systems senden, die auf diese Benachrichtigungen reagieren müssen.
- Grundvoraussetzung: Wir dürfen keine Ereignisse verlieren. Die Benachrichtigung über das Ereignis kann in extremen Fällen wiederholt werden, dh es muss mindestens einmal eine Garantie gegeben werden . In verteilten Systemen ist es äußerst schwierig, eine Garantie nur einmal (es kann sogar unmöglich sein, aber es muss bewiesen werden) ohne Konsensmechanismen zu implementieren, und sie haben (zumindest alles, was ich weiß) einen sehr starken Einfluss auf das System in Bezug auf Verzögerung und Durchsatz.
Nun ein paar Details:
- Es gibt viele Quellprozesse, sie können Millionen (im schlimmsten Fall) von Ereignissen erzeugen, die in ein enges Zeitintervall fallen.
- Ereignisse können sowohl für die Zukunft als auch für die Vergangenheit generiert werden (z. B. wenn der Quellprozess verlangsamt wurde und ein Ereignis für einen bereits verstrichenen Moment aufgezeichnet hat).
- Die Priorität der Ereignisverarbeitung liegt in der Zeit, d. H. Wir müssen zuerst die frühesten Ereignisse verarbeiten.
- Für jedes Ereignis generiert der Quellprozess eine Zufallszahl worker_id , aufgrund derer Ereignisse unter den Koordinatoren verteilt werden.
- Es gibt verschiedene Koordinierungsprozesse (skaliert je nach Bedarf basierend auf der Systemlast).
- Jeder Koordinatorprozess verarbeitet Ereignisse für seine eigene Menge worker_id , d. H. Aufgrund von worker_id vermeiden wir den Wettbewerb zwischen Koordinatoren und die Notwendigkeit von Sperren.
Wie aus der Beschreibung hervorgeht, können wir nur einen Koordinierungsprozess berücksichtigen und nicht die worker_id in unserer Aufgabe berücksichtigen.
Das heißt, der Einfachheit halber nehmen wir an, dass:
- Es gibt viele Quellprozesse.
- Der Koordinierungsprozess ist einer.
Ich werde die Entwicklung der Idee, dieses Problem schrittweise zu lösen, beschreiben, damit verständlicher wird, wie sich der Gedanke von einer einfachen Implementierung zu einer optimierten entwickelte.
Stirnentscheidung
Wir erstellen eine Platte für Ereignisse, in der wir Ereignisse nur in Form eines Zeitstempels speichern (wir sind an anderen Parametern in dieser Aufgabe nicht interessiert). Erstellen wir einen Index für das Zeitstempelfeld .
Es scheint eine ganz normale Lösung zu sein.
Nur gibt es ein Problem mit der Skalierbarkeit: Je mehr Ereignisse, desto langsamer die Datenbankoperationen.
Ereignisse können in der Vergangenheit auftreten, daher muss der Koordinator die gesamte Zeitachse ständig überprüfen.
Das Problem kann umfassend gelöst werden, indem die Datenbank nach Zeit usw. in Shards aufgeteilt wird. Dies ist jedoch ein ressourcenintensiver Weg.
Infolgedessen wird die Arbeit der Koordinatoren verlangsamt, da Sie Daten aus mehreren Datenbanken lesen und kombinieren müssen.
Es ist schwierig, das Zwischenspeichern von Ereignissen im Koordinator zu implementieren, um nicht zu den Basen zu gehen, um jedes Ereignis zu verarbeiten.
Mehr Datenbanken - mehr Fehlertoleranzprobleme.
Usw.
Wir werden nicht im Detail auf diese frontale Lösung eingehen, da sie trivial und uninteressant ist.
Erste Optimierung
Mal sehen, wie man die Frontallösung verbessert.
Um den Zugriff auf die Datenbank zu optimieren, können Sie den Index etwas komplizieren und Ereignissen, die beim Festschreiben einer Transaktion in der Datenbank generiert werden, eine monoton ansteigende Kennung hinzufügen. Das heißt, das Ereignis ist jetzt durch das Paar {Zeit, ID} gekennzeichnet , wobei Zeit die Zeit ist, zu der das Ereignis geplant ist, ID ein monoton ansteigender Zähler ist. Es gibt eine Garantie für die Eindeutigkeit der ID für jedes Ereignis, aber es gibt keine Garantie dafür, dass ID- Werte ohne Löcher auskommen (dh es kann eine solche Reihenfolge geben: 1 , 2 , 7 , 15 ).
Es scheint, dass wir jetzt den Bezeichner des zuletzt gelesenen Ereignisses im Koordinatorprozess speichern und beim Abrufen Ereignisse mit Bezeichnern auswählen können, die größer als das zuletzt verarbeitete Ereignis sind.
Aber hier taucht das Problem sofort auf: Quellprozesse können ein Ereignis mit einem Zeitstempel weit in der Zukunft aufzeichnen. Dann müssen wir im Koordinierungsprozess ständig die Ereignisse mit kleinen Kennungen berücksichtigen, deren Verarbeitungszeit noch nicht gekommen ist.
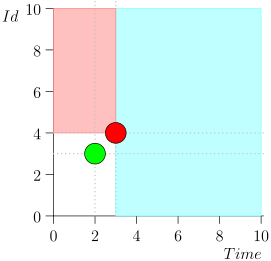
Sie können feststellen, dass Ereignisse relativ zur aktuellen Zeit in zwei Klassen unterteilt sind:
- Ereignisse mit einem Zeitstempel in der Vergangenheit, aber mit einer großen Kennung. Sie wurden kürzlich in die Datenbank geschrieben, nachdem wir dieses Zeitintervall verarbeitet hatten. Dies sind Ereignisse mit hoher Priorität, und sie müssen zuerst verarbeitet werden, damit die Benachrichtigung - die bereits zu spät ist - nicht einmal zu spät ist.
- Es wurden einmal Ereignisse mit Zeitstempeln aufgezeichnet, die nahe am aktuellen Moment liegen. Solche Ereignisse haben einen niedrigen Bezeichnerwert.
Dementsprechend ist der aktuelle Zustand des Koordinatorprozesses durch das Paar {state.time, state.id} gekennzeichnet.
Es stellt sich heraus, dass sich Ereignisse mit hoher Priorität links und über diesem Punkt befinden (rosa Bereich) und normale Ereignisse rechts (hellblau):
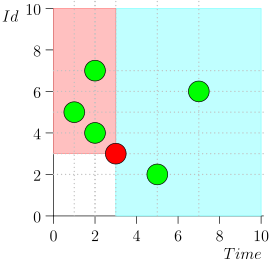
Flussdiagramm
Der Koordinator-Arbeitsalgorithmus lautet wie folgt:
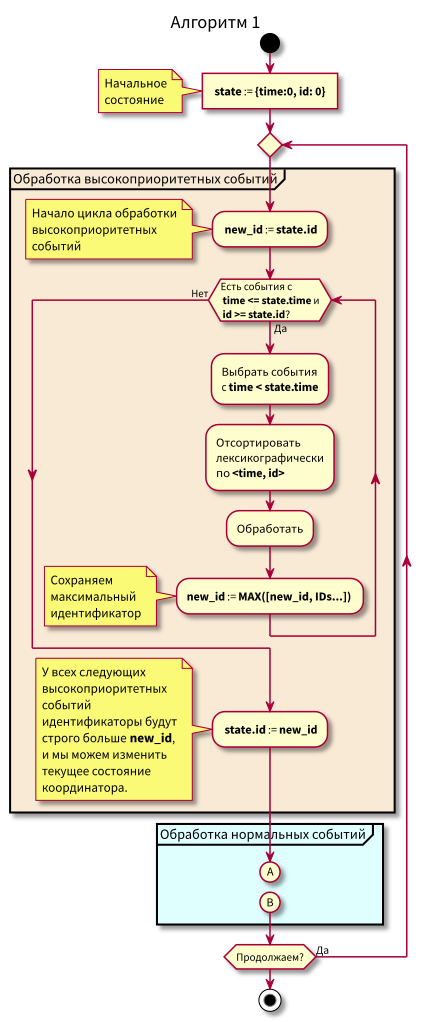
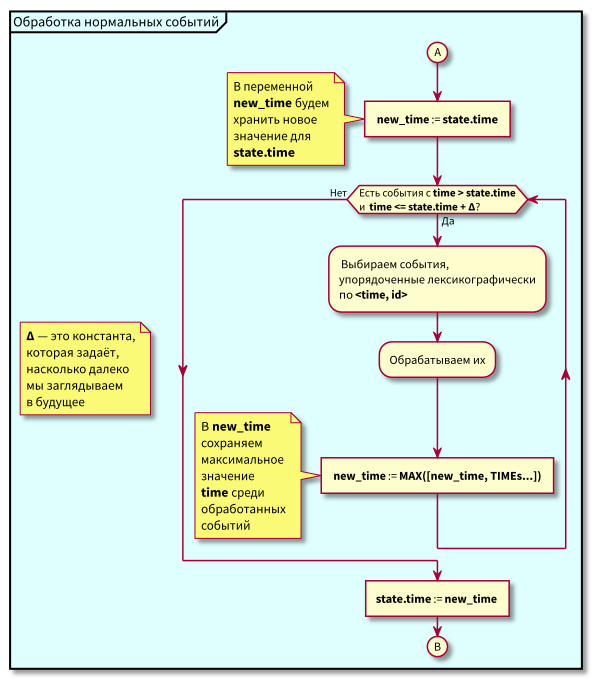
Beim Studium des Algorithmus können Fragen auftauchen:
- Was ist, wenn die Verarbeitung normaler Ereignisse beginnt und in diesem Moment neue Ereignisse in der Vergangenheit (im rosa Bereich) eintreffen, werden sie nicht verloren gehen? Antwort: Sie werden im nächsten Zyklus der Verarbeitung von Ereignissen mit hoher Priorität verarbeitet. Sie können nicht verloren gehen, da ihre ID garantiert höher als state.id ist.
- Was ist, wenn nach der Verarbeitung aller normalen Ereignisse - zum Zeitpunkt des Wechsels zur Verarbeitung von Ereignissen mit hoher Priorität - neue Ereignisse mit Zeitstempeln aus dem Intervall [state.time, state.time + Delta] eintreffen, verlieren wir sie? Antwort: Sie fallen in den rosa Bereich, da sie die Zeit <state.time and id > haben. State.id: Sie sind vor kurzem angekommen und die ID nimmt monoton zu.
Beispiel für eine Algorithmusoperation
Schauen wir uns einige Schritte des Algorithmus an:
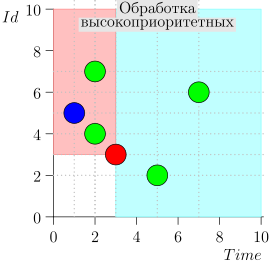
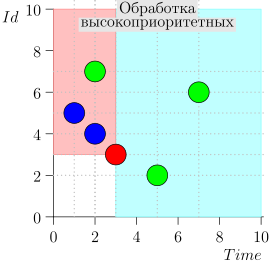
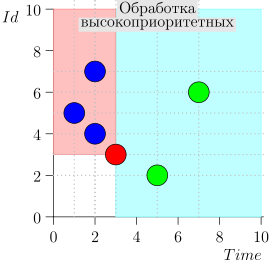
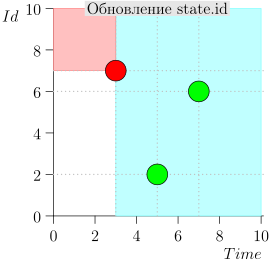
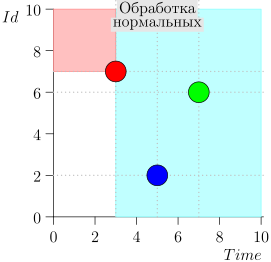
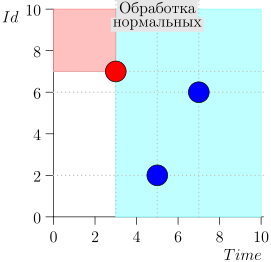
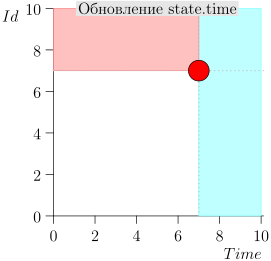
Modell
Wir werden sicherstellen, dass der Algorithmus keine Ereignisse verpasst und alle Benachrichtigungen gesendet werden: Wir werden ein einfaches Modell erstellen und es überprüfen.
Für das Modell verwenden wir TLA +, genauer gesagt PlusCal, was sich in TLA + übersetzt.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* \* (by Daniel Jackson) \* small-scope hypothesis, \* , ́ \* \* \* : \* Events - - , \* [time, id], \* \* \* \* Event_Id - \* id \* MAX_TIME - , \* \* TIME_DELTA - Delta, \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, TIME_DELTA \in 1..3 define \* \* ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x \* fold_left/fold_right RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) (* ( ) *) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) (* : *) ToSet(S) == {S[i] : i \in DOMAIN(S)} (* map *) MapSet(Op(_), S) == {Op(x) : x \in S} (* *) \* id GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) \* time GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) (* SQL *) \* \* ORDER BY EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \* time, id \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) \* SELECT * FROM events \* WHERE time <= curr_time AND id >= max_id \* ORDER BY time, id SELECT_HIGH_PRIO(state) == LET \* \* time <= curr_time \* AND id >= maxt_id selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } IN selected \* SELECT * FROM events \* WHERE time > current_time AND time - Time <= delta_time \* ORDER BY time, id SELECT_NORMAL(state, delta_time) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } IN selected \* Safety predicate \* ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; \* - fair process inserter = "Sources" variable n, t; begin forever: while TRUE do \* get_time: \* \* , , \* with evt_time \in 0..MAX_TIME do t := evt_time; end with; \* ; \* : \* 1. . \* 2. , \* Event_Id - , \* commit: \* either - either Events := Events \cup {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process coordinator = "Coordinator" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do \* high_prio: events := SELECT_HIGH_PRIO(state); \* process_high_prio: \* , \* Events, \* state.id := MAX({state.id} \union GetIds(events)) || \* , \* Events := Events \ events || \* events , \* events := {}; \* - normal: events := SELECT_NORMAL(state, TIME_DELTA); process_normal: state.time := MAX({state.time} \union GetTimes(events)) || Events := Events \ events || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ================================
Wie Sie sehen können, ist die Beschreibung relativ klein, trotz des ziemlich umfangreichen Abschnitts von Definitionen (define), der in einem separaten Modul herausgenommen und dann wiederverwendet werden könnte.
In den Kommentaren habe ich versucht zu erklären, was im Modell passiert. Hoffe das
Ich habe es geschafft und es besteht keine Notwendigkeit, das Modell detaillierter zu bemalen.
Ich möchte nur einen Punkt in Bezug auf die Atomizität von Übergängen zwischen Zuständen und Modellierungsmerkmalen klarstellen.
Die Modellierung erfolgt durch atomare Prozessschritte. In einem Übergang wird ein atomarer Schritt eines Prozesses ausgeführt, in dem dieser Schritt ausgeführt werden kann. Die Wahl von Schritt und Prozess ist nicht deterministisch: Während der Modellierung werden alle möglichen Ketten atomarer Schritte aller Prozesse sortiert.
Es kann sich die Frage stellen: Was ist mit der Modellierung echter Parallelität, wenn wir gleichzeitig mehrere atomare Schritte in verschiedenen Prozessen ausführen?
Diese Frage wurde Leslie Lamport seit langem im Buch Specifying Systems und anderen Werken beantwortet.
Ich werde die Antwort nicht vollständig zitieren, kurz gesagt lautet das Wesentliche: Wenn es keine genaue Zeitskala gibt, in der jedes Ereignis an einen bestimmten Moment gebunden ist, gibt es keinen Unterschied bei der Modellierung paralleler Ereignisse als nicht deterministisch auftretende sequentielle Ereignisse, da wir immer davon ausgehen können, dass ein Ereignis früher als ein anderes aufgetreten ist Infinitesimalwert.
Was aber wirklich wichtig ist, ist die kompetente Zuordnung der atomaren Schritte. Wenn es zu viele von ihnen gibt, kommt es zu einer kombinatorischen Explosion des Zustandsraums. Wenn Sie weniger Schritte als nötig ausführen oder diese falsch auswählen, dh die Wahrscheinlichkeit, dass ein ungültiger Zustand / Übergang ungültig wird (d. H. Wir werden die Fehler im Modell übersehen).
Um Prozesse korrekt in atomare Schritte zu unterteilen, müssen Sie eine gute Vorstellung davon haben, wie das System in Bezug auf die Abhängigkeit von Prozessen von Daten und Synchronisationsmechanismen funktioniert.
Die Aufteilung von Prozessen in atomare Schritte verursacht in der Regel keine großen Probleme. Wenn dies der Fall ist, deutet dies eher auf ein Unverständnis des Problems hin und nicht auf Probleme beim Kompilieren des Modells und Schreiben der TLA + -Spezifikation. Dies ist ein weiteres sehr nützliches Merkmal formaler Spezifikationen: Sie erfordern eine gründliche Untersuchung und Analyse.
ein Problem. Wenn die Aufgabe sinnvoll und gut verstanden ist, gibt es in der Regel keine Probleme mit ihrer Formalisierung.
Modellprüfung
Für die Modellierung werde ich TLA-Toolbox verwenden. Sie können natürlich alles über die Befehlszeile ausführen, aber die IDE ist immer noch praktischer, insbesondere um sich mit dem Modellieren mit TLA + vertraut zu machen.
Die Erstellung des Projekts ist in Handbüchern, Artikeln und Büchern gut beschrieben, auf die ich am Ende des Artikels verwiesen habe, sodass ich mich nicht wiederholen werde. Das einzige, worauf ich Sie aufmerksam machen werde, sind die Simulationseinstellungen.
TLC ist eine Modellprüfung mit expliziter Zustandsprüfung. Es ist klar, dass der Zustandsraum durch angemessene Grenzen begrenzt werden muss. Einerseits sollte es groß genug sein, um die für uns interessanten Eigenschaften überprüfen zu können, und andererseits klein genug, um die Simulation in angemessener Zeit mit akzeptablen Ressourcen abzuschließen.
Dies ist ein ziemlich heikler Punkt. Hier müssen Sie die Eigenschaften des Systems und des Modells verstehen. Aber es kommt schnell mit Erfahrung. Für den Anfang können Sie einfach die maximal möglichen Grenzwerte festlegen, die hinsichtlich der Simulationszeit und des Ressourcenverbrauchs noch akzeptabel sind.
Es gibt auch eine Möglichkeit, nicht den gesamten Zustandsraum, sondern selektive Ketten bis zu einer bestimmten Tiefe zu überprüfen. Es ist auch manchmal möglich und notwendig zu verwenden.
Wir kehren zu den Simulationseinstellungen zurück.
Zunächst definieren wir die Einschränkungen für den Zustandsraum des Systems. Einschränkungen werden im Abschnitt Erweiterte Optionen / Simulationseinstellungen für Statusbeschränkungen festgelegt.
Dort habe ich einen TLA + Ausdruck angegeben: Cardinality(Events) <= 5 /\ Event_Id <= 5 ,
Dabei ist Event_Id die Obergrenze für den Wert der Ereigniskennung. Cardinality(Events) ist die Größe des Satzes von Ereignisdatensätzen (begrenzt das Basismodell)
Daten von fünf Datensätzen in einer Platte).
In der Simulation betrachtet die DC nur die Zustände, in denen diese Formel wahr ist.
Sie können weiterhin gültige Statusübergänge zulassen ( Erweiterte Optionen / Aktionsbeschränkung ).
aber wir brauchen es nicht
Als nächstes geben wir die TLA + -Formel an, die unser System beschreibt: Modellübersicht / Zeitformel = Spec , wobei Spezifikation der Name der von PlusCal automatisch generierten TLA + -Formel ist (im obigen Modellcode heißt es nicht: Um Platz zu sparen, habe ich das Ergebnis der Übersetzung von PlusCal in TLA + nicht zitiert). .
Die nächste Einstellung, auf die Sie achten sollten, ist die Deadlock-Prüfung.
(Häkchen in Modellübersicht / Deadlock ). Wenn dieses Flag aktiviert ist, überprüft der TLC das Modell auf "hängende" Zustände, dh solche, bei denen keine ausgehenden Übergänge vorhanden sind. Wenn sich solche Zustände im Zustandsraum befinden, bedeutet dies einen eindeutigen Fehler im Modell. Oder in TLC, das wie jedes andere nicht triviale Programm nicht vor Fehlern gefeit ist :) In meiner (nicht so großen) Praxis bin ich noch nicht auf Deadlocks gestoßen.
Und schließlich, für die all diese Tests gestartet wurden, die Sicherheitsformel in Modellübersicht / Invarianten = ALL_EVENTS_PROCESSED(state) .
TLC überprüft die Gültigkeit der Formel in jedem Zustand. Wenn sie falsch wird,
zeigt eine Fehlermeldung an und zeigt die Reihenfolge der Zustände an, die zu dem Fehler geführt haben.
Nach dem Starten von TLC, nachdem etwa 8 Minuten gearbeitet wurde, wurde "Keine Fehler" gemeldet. Dies bedeutet, dass das Modell getestet wird und die angegebenen Eigenschaften erfüllt.
TLC zeigt auch viele interessante Statistiken an. Zum Beispiel wurden für dieses Modell 7 677 824 eindeutige Zustände erhalten, insgesamt untersuchte die DC 27 109 029 Zustände, der Durchmesser des Zustandsraums beträgt 47 (dies ist die maximale Länge der Zustandskette vor der Wiederholung).
maximale Zykluslänge aus sich nicht wiederholenden Zuständen im Zustands- und Übergangsgraphen).
Wenn wir 27 Millionen Staaten in 8 Minuten aufteilen, erhalten wir ungefähr 56.000 Staaten pro Sekunde, was möglicherweise nicht sehr schnell erscheint. Beachten Sie jedoch, dass ich die Simulation auf einem Laptop ausgeführt habe, der im Energiesparmodus arbeitete (ich habe die Kernfrequenz auf 800 MHz erzwungen, weil ich zu diesem Zeitpunkt in einem elektrischen Zug unterwegs war) und das Modell überhaupt nicht für die Simulationsgeschwindigkeit optimiert habe.
Es gibt viele Möglichkeiten, die Simulation zu beschleunigen: von der Portierung eines Teils des TLA + -Modellcodes auf Java und der schnellen Verbindung zu TLC (es ist nützlich, alle Arten von Hilfsfunktionen zu beschleunigen) bis zur Ausführung von TLC in den Clouds und Clustern (die Cloud-Unterstützung von Amazon und Azure ist direkt in TLC selbst integriert).
Zweite Optimierung
Im vorherigen Algorithmus ist bis auf einige Probleme alles in Ordnung:
[state.time, state.time + Delta] wir nicht alle Ereignisse aus der blauen Zone im Intervall [state.time, state.time + Delta] , können wir nicht zu Ereignissen mit hoher Priorität [state.time, state.time + Delta] . Das heißt, späte Ereignisse werden noch mehr spät sein. Und normalerweise ist die Verzögerung nicht vorhersehbar. Aus diesem Grund kann state.time weit hinter der aktuellen Zeit zurückbleiben, und dies ist die Ursache für das nächste Problem.- Ereignisse, die im Bereich normaler Ereignisse eintreffen, können verspätet sein ( id > state.id). Sie haben bereits hohe Priorität und sollten als Ereignisse aus der rosa Region betrachtet werden. Wir betrachten sie weiterhin als normal und behandeln sie als normal.
- Es ist schwierig, das Zwischenspeichern von Ereignissen und das Auffüllen von Caches (Lesen aus der Datenbank) zu organisieren.
Wenn die ersten beiden Punkte offensichtlich sind, wird der dritte wahrscheinlich die meisten Fragen aufwerfen. Lassen Sie uns näher darauf eingehen.
Angenommen, wir möchten zuerst eine feste Anzahl von Ereignissen in den Speicher lesen und dann verarbeiten.
Nach der Verarbeitung möchten wir Ereignisse in der Datenbank mit Blockabfragen als verarbeitet markieren. Wenn Sie nicht mit Blöcken, sondern mit einzelnen Ereignissen arbeiten, wird das Zwischenspeichern keinen großen Gewinn bringen.
Angenommen, wir haben einen Teil der Blöcke verarbeitet und möchten den Cache ergänzen. Wenn dann späte Ereignisse mit hoher Priorität während der Verarbeitung eintreffen, können wir sie frühzeitig verarbeiten.
Das heißt, es ist sehr wünschenswert, Ereignisse in kleinen Blöcken lesen zu können, um späte Ereignisse so schnell wie möglich zu verarbeiten, aber das Verarbeitungsattribut in der Datenbank mit großen Blöcken gleichzeitig zu aktualisieren - aus Effizienzgründen.
Was ist in diesem Fall zu tun?
Versuchen Sie, mit der Datenbank in kleinen Blöcken mit einem blauen und rosa Bereich zu arbeiten, und verschieben Sie den Statuspunkt in kleinen Schritten.
Somit wurde der Cache eingeführt und aus den Datenbankdaten in ihn eingelesen. Nach jedem Lesen wurde der Statuspunkt verschoben, um bereits gelesene Ereignisse nicht erneut zu lesen.
Jetzt ist der Algorithmus etwas komplizierter geworden, wir haben begonnen, in begrenzten Abschnitten zu lesen.
Flussdiagramm
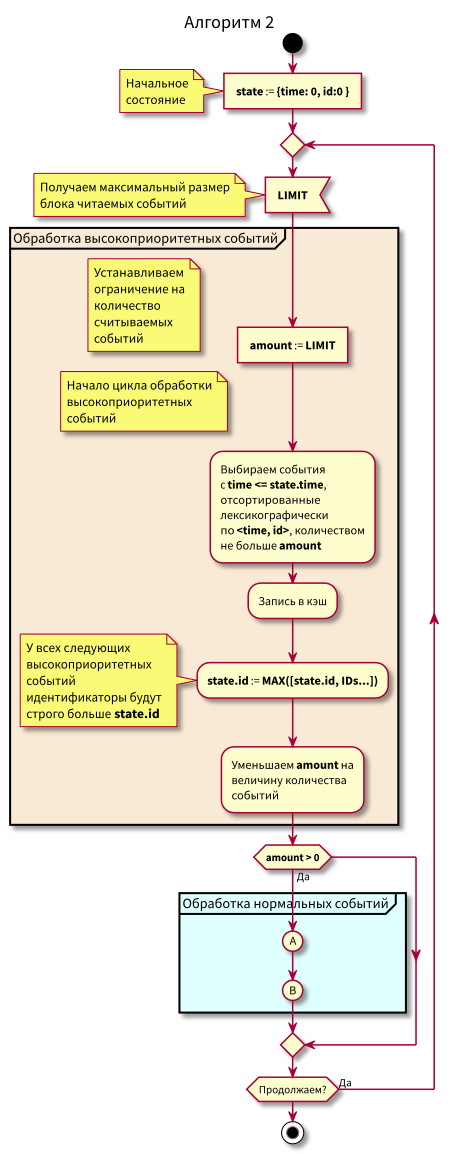
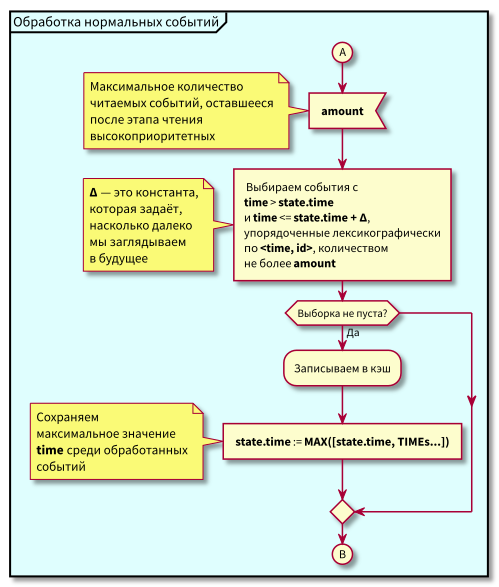
In diesem Algorithmus ist ersichtlich, dass aufgrund der Beschränkung auf Blöcke lesbarer Ereignisse die maximale Verzögerung beim Übergang von der Verarbeitung mit niedriger Priorität zur Verarbeitung mit hoher Priorität gleich der maximalen Verarbeitungszeit des Blocks ist.
Das heißt, jetzt können wir beide Ereignisse in kleinen Blöcken in den Cache einlesen und die maximale Verzögerung beim Übergang zur Verarbeitung von Ereignissen mit hoher Priorität durch Steuern der maximalen Blockgröße zum Lesen steuern.
Beispiel für eine Algorithmusoperation
Schauen wir uns den Algorithmus in Arbeit in Schritten an. Nehmen Sie der LIMIT = 2 .
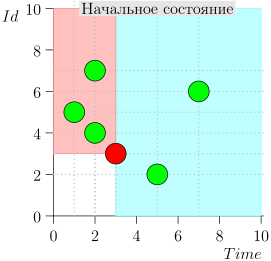
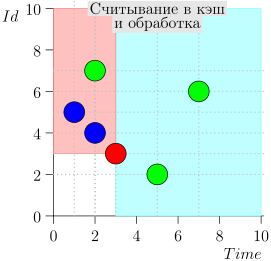
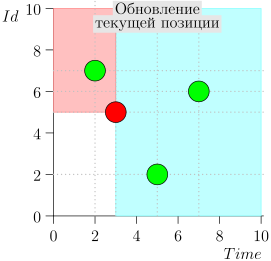
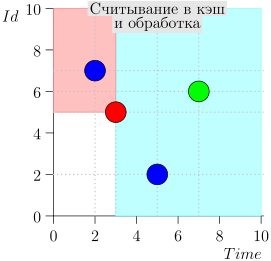
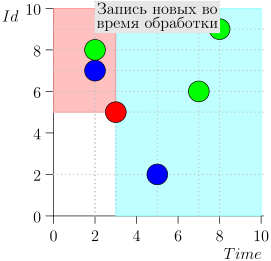
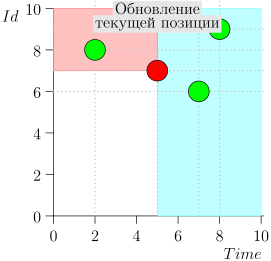
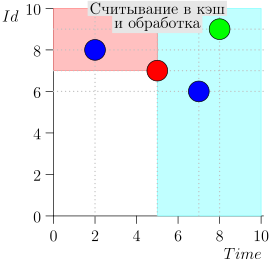
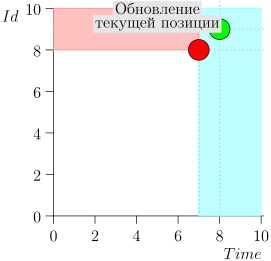
Es stellt sich heraus, dass das Problem gelöst ist? Aber nein. (Es ist klar, dass, wenn das Problem zu diesem Zeitpunkt vollständig gelöst war, dann
Dieser Artikel wäre nicht gewesen :))
Der Fehler?
In dieser Form hat der Algorithmus ziemlich lange funktioniert. Tests gingen alle gut. Auch in der Produktion gab es keine Probleme.
Aber der Entwickler des Algorithmus und seiner Implementierung (mein Kollege Peter Reznikov) ist sehr erfahren und er hatte intuitiv das Gefühl, dass hier etwas nicht stimmt. Daher wurde neben dem Hauptcode eine Überprüfung durchgeführt, bei der gelegentlich ein Timer überprüft wurde, um festzustellen, ob Ereignisse verpasst wurden, und
wenn überhaupt, habe ich sie verarbeitet.
In dieser Form hat das System erfolgreich funktioniert. Es stimmt, niemand hat Statistiken über die Anzahl der vom Prüfer ausgewählten Ereignisse geführt. Daher wissen wir leider nicht, wie viele Fehler mit einer vorzeitigen Ereignisverarbeitung verbunden waren.
Ich habe eine ähnliche Warteschlange zeitgebundener Objekte implementiert. Wir haben mit Peter Reznikov über die Implementierung und Optimierung von Algorithmen gesprochen und über diesen Algorithmus für die Arbeit mit Ereignissen gesprochen. Sie bezweifelten, dass der Algorithmus korrekt ist. Wir haben uns für ein kleines Modell entschieden, um Zweifel zu bestätigen oder zu zerstreuen. Infolgedessen haben wir einen Fehler gefunden.
Modell
Bevor ich den Trace mit einem Fehler zerlege, gebe ich den Quellcode des Modells an, auf dem der Fehler erkannt wurde.
Die Unterschiede zum Vorgängermodell sind sehr gering, die Größe der Leseblöcke ist nur begrenzt: Der Operator Limit wird hinzugefügt und dementsprechend werden die Operatoren zur Ereignisauswahl geändert.
Um Platz zu sparen, habe ich nur Kommentare zu den geänderten Teilen des Modells hinterlassen.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* LIMIT, \* \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, LIMIT \in 1..3, TIME_DELTA \in 1..2 define ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) Limit(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result \* SELECT * FROM events \* WHERE time <= curr_time AND id > max_id \* ORDER BY id \* LIMIT limit SELECT_HIGH_PRIO(state, limit) == LET selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } \* Id sorted == SortSeq(ToSeq(selected), EventsOrderById) \* limited == Limit(sorted, limit) IN ToSet(limited) \* SELECT * FROM events \* WHERE time > current_time \* AND time - Time <= delta_time \* ORDER BY time, id \* LIMIT limit SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events: /\ e.time <= state.time + delta_time /\ e.time > state.time } \* sorted == SortSeq(ToSeq(selected), EventsOrder) \* limited == Limit(sorted, limit) IN ToSet(limited) ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, LIMIT) new_limit == LIMIT - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, TIME_DELTA, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events))] || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Ein aufmerksamer Leser kann feststellen, dass neben der Einführung von Limit auch die Bezeichnungen in event_processor geändert wurden. Das Ziel ist etwas besser, echten Code zu simulieren, den zwei Auswahlen in einer Transaktion ausführen, dh die Auswahl von Ereignissen kann als atomar ausgeführt bezeichnet werden.
Nun, und wenn wir einen Fehler in einem Modell mit größeren atomaren Operationen finden, garantiert dies praktisch, dass der gleiche Fehler im gleichen Modell auftritt, aber mit kleineren atomaren Schritten (eine ziemlich starke Aussage, aber ich denke, es ist intuitiv; obwohl es sollte gut sein, wenn es nicht bewiesen ist, und dann an einer großen Auswahl von Modellen überprüft werden).
Modellprüfung
Wir starten die Simulation mit den gleichen Parametern wie in der ersten Ausführungsform.
Bei der Suche in der Breite wird im 19. Schritt der Simulation eine Verletzung der Eigenschaft ALL_EVENTS_PROCESSED angezeigt.
Für gegebene Anfangsdaten (dies ist ein sehr kleiner Zustandsraum) zeigt der Fehler im 19. Schritt an, dass der Fehler sehr selten und schwer zu erkennen ist, da zuvor alle Zustandsketten mit einer Länge von weniger als 19 untersucht wurden.
Daher ist dieser Fehler in Tests schwer zu erkennen. Nur wenn Sie wissen, wo Sie suchen müssen, und speziell Tests und temporäre Hütten auswählen.
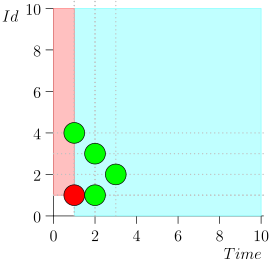
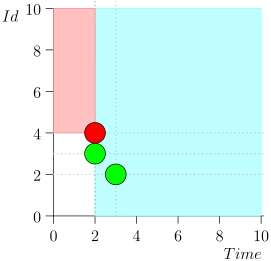
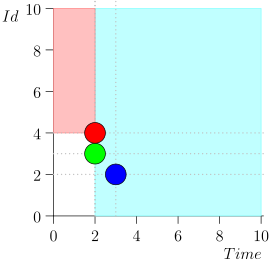
Ich werde nicht die gesamte Route mitbringen, um Platz und Zeit zu sparen. Hier ist ein Segment aus mehreren Staaten zusammen mit einem Fehler:

Analyse und Korrektur
Was ist passiert?
Wie Sie sehen, manifestierte sich der Fehler darin, dass wir das Ereignis {2, 3} verpasst haben, weil das Limit beim Ereignis {2, 1} endete, und danach den Status des Koordinators geändert haben. Dies kann nur geschehen, wenn zu einem bestimmten Zeitpunkt mehrere Ereignisse vorliegen.
Deshalb war der Fehler in Tests schwer zu fassen. Für seine Manifestation ist es notwendig, dass ziemlich seltene Dinge zusammenfallen:
- Mehrere Ereignisse treffen denselben Zeitpunkt.
- Die Begrenzung der Auswahl von Ereignissen endete vor dem Lesen all dieser Ereignisse.
Der Fehler kann relativ einfach korrigiert werden, wenn der Status des Koordinators etwas erweitert wird: Fügen Sie die Zeit und die Kennung des zuletzt gelesenen Ereignisses aus dem normalen Ereignisbereich mit der maximalen ID hinzu, wenn die Zeit dieses Ereignisses dem nächsten Status entspricht.
Wenn es kein solches Ereignis gibt, setzen wir den zusätzlichen Status (extra_state) auf einen ungültigen Status (UNDEF_EVT) und berücksichtigen ihn bei der Arbeit nicht.
Ereignisse aus der normalen Region, die im vorherigen Schritt des Koordinators nicht verarbeitet wurden, werden als hohe Priorität angesehen, und wir werden die Auswahl des Prädikats mit hoher Priorität und Sicherheit entsprechend korrigieren.
Es wäre möglich, einen weiteren Bereich zwischen hoher Priorität und Normal einzuführen und den Algorithmus zu ändern. Zuerst werden die mit hoher Priorität, dann die Zwischenprodukte verarbeitet und dann mit der anschließenden Zustandsänderung zu den normalen übergegangen.
Solche Änderungen würden jedoch zu einem größeren Refactoring-Volumen mit nicht offensichtlichen Vorteilen führen (der Algorithmus wird etwas klarer sein; andere Vorteile sind nicht sofort sichtbar).
Aus diesem Grund haben wir uns entschlossen, den aktuellen Status und die Auswahl der Ereignisse aus der Datenbank nur geringfügig anzupassen.
Angepasstes Modell
Hier ist das korrigierte Modell.
------------------- MODULE events ------------------- EXTENDS Naturals, FiniteSets, Sequences, TLC \* CONSTANTS MAX_TIME, LIMIT, TIME_DELTA (* --algorithm Events variables Events = {}, Limit \in LIMIT, Delta \in TIME_DELTA, Event_Id = 0 define \* \* , extra_state UNDEF_EVT == [time |-> MAX_TIME + 1, id |-> 0] ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) TakeN(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result (* SELECT * FROM events WHERE time <= curr_time AND id > max_id ORDER BY id Limit limit *) SELECT_HIGH_PRIO(state, limit, extra_state) == LET \* \* time <= curr_time \* AND id > maxt_id selected == {e \in Events : \/ /\ e.time <= state.time /\ e.id >= state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id} sorted == \* SortSeq(ToSeq(selected), EventsOrderById) limited == TakeN(sorted, limit) IN ToSet(limited) SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } sorted == SortSeq(ToSeq(selected), EventsOrder) limited == TakeN(sorted, limit) IN ToSet(limited) \* extra_state UpdateExtraState(events, state, extra_state) == LET exact == {evt \in events : evt.time = state.time} IN IF exact # {} THEN CHOOSE evt \in exact : \A e \in exact: e.id <= evt.id ELSE UNDEF_EVT \* extra_state ALL_EVENTS_PROCESSED(state, extra_state) == \A e \in Events: \/ e.time >= state.time \/ e.id > state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable events = {}, state = ZERO_EVT, extra_state = UNDEF_EVT; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, Limit, extra_state) new_limit == Limit - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, Delta, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events)) ]; extra_state := UpdateExtraState(events, state, extra_state) || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Wie Sie sehen können, sind die Änderungen sehr gering:
- Zusätzliche Daten zum Status "extra_state" hinzugefügt.
- Die Auswahl der Ereignisse mit hoher Priorität wurde geändert.
- UpdateExtraState extra_state.
- safety - .
, . , (, , , ).
, , TLA+/TLC . :) :)
Fazit
, , ( , , , ).
, , TLA+/TLC, . , .
TLA+/TLC , , ( , ) .
, , , TLA+/TLC .
Bibliographie
Bücher
, , , . .
Michael Jackson Problem Frames: Analysing & Structuring Software Development Problems
( !), . , . , .
Hillel Wayne Practical TLA+: Planning Driven Development
TLA+/PlusCal . , . . : .
MODEL CHECKING.
. , , . , .
Leslie Lamport Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers
TLA+. , . : , . , TLA+ , .
Formal Development of a Network-Centric RTOS
TLA+ ( RTOS ) TLC.
, . , TLA+ , , RTOS — Virtuoso. , .
, (, , , , ).
w Amazon Web Services Uses Formal Methods
TLA+ AWS. : http://lamport.azurewebsites.net/tla/amazon-excerpt.html
Das Internet
Blogs
Hillel Wayne ( "Practical TLA+")
. , . , - .
Ron Pressler
. . , TLA+. TLA+, computer science .
Leslie Lamport
TLA+ computer science . TLA+ .
. . , . . , . . .
, , .
TLA+,
, TLA+. , TLA+.
Hillel Wayne
Hillel Wayne . .
Ron Pressler
, Hillel Wayne, . , . Ron Pressler . ́ , , .
TLA toolbox + TLAPS : TLA+
. Alloy Analyzer .