
Einführung
Hallo, liebe Chabrowiten!
Die letzten zwei Jahre meiner Arbeit bei
Synesis waren eng mit dem Prozess der Erstellung und Entwicklung von
Synet verbunden - einer offenen Bibliothek zum Ausführen von vorab trainierten Faltungs-Neuronalen Netzen auf der CPU. Bei dieser Arbeit musste ich auf eine Reihe interessanter Punkte stoßen, die sich auf die Optimierung direkter Signalausbreitungsalgorithmen in neuronalen Netzen beziehen. Es scheint mir, dass eine Beschreibung dieser Punkte für die Leser von Habrahabr sehr interessant wäre. Was ich einer Reihe meiner Artikel widmen möchte. Die Dauer des Zyklus hängt von Ihrem Interesse an diesem Thema und natürlich von meiner Fähigkeit ab, Faulheit zu überwinden. Ich möchte den Zyklus mit einer Beschreibung des
Rahmenrads selbst beginnen. Die Fragen der zugrunde liegenden Algorithmen werden in den folgenden Artikeln offenbart:
- Faltungsschicht: Techniken zur Optimierung der Matrixmultiplikation
- Faltungsschicht: schnelle Faltung nach der Methode von Shmuel Vinograd
Antworten auf Fragen
Bevor ich mit einer detaillierten Beschreibung des Frameworks beginne, werde ich versuchen, eine Reihe von Fragen, die die Leser wahrscheinlich haben werden, sofort zu beantworten. Die Erfahrung zeigt, dass es besser ist, dies im Voraus zu tun, da viele sofort anfangen, wütende Kommentare zu schreiben, ohne bis zum Ende gelesen zu haben.
Die erste Frage, die sich normalerweise in solchen Fällen stellt:
Wer betreibt jetzt Netzwerke auf herkömmlichen Prozessoren, wann gibt es Grafikbeschleuniger und Tensor- (Matrix-) Beschleuniger?Ich werde das mit Ja beantworten - es ist wirklich nicht ratsam, neuronale Netze auf der CPU zu trainieren, aber das Ausführen vorgefertigter neuronaler Netze ist eine ziemliche Anforderung, insbesondere wenn das Netz klein genug ist. Die Gründe dafür mögen unterschiedlich sein, aber die Hauptgründe:
- CPUs sind häufiger. Nicht alle Computer verfügen über eine GPU, insbesondere Server.
- In kleinen neuronalen Netzen sind die Vorteile der Verwendung der GPU gering und fehlen manchmal vollständig.
- Die effektive Einbeziehung der GPU zur Beschleunigung neuronaler Netze erfordert typischerweise eine wesentlich komplexere Anwendungsstruktur.
Die nächste mögliche Frage:
Warum eine spezielle Lösung zum Starten verwenden, wenn es Tensorflow , Caffe oder MXNet gibt ?Sie können Folgendes beantworten:
- Eine Vielzahl von Frameworks ist nicht immer gut. Wenn also in einem Projekt mehrere Modelle in unterschiedlichen Frameworks trainiert sind, müssen Sie sie alle in eine vorgefertigte Lösung einbetten, was sehr unpraktisch ist.
- Klassische Frameworks wurden entwickelt, um GPU-Modelle zu trainieren - und sie sind auf jeden Fall gut darin! Um trainierte Modelle auf der CPU auszuführen, ist ihre Funktionalität jedoch redundant und nicht optimal.
- Die Bestätigung der Notwendigkeit einer speziellen Lösung ist die Beliebtheit von OpenVINO - einem Framework von Intel, das dieselbe Funktion erfüllt.
Hier stellt sich sofort eine logische Frage nach der Erfindung des Fahrrads:
Warum Ihr Handwerk einsetzen, wenn es eine vollständig professionelle Lösung von einem anerkannten Weltmarktführer gibt?Meine Antwort lautet:
- Zu Beginn der Arbeiten an Synet steckte OpenVINO noch in den Kinderschuhen. Und in Wahrheit, wenn OpenVINO zu diesem Zeitpunkt in seinem aktuellen Zustand wäre, würde ich mich mit hoher Wahrscheinlichkeit nicht an meinem eigenen Projekt beteiligen.
- Sie können Ihr eigenes Framework an Ihre Bedürfnisse anpassen. In meinem Fall war die Hauptanforderung die maximale Single-Thread-Leistung.
- Sie können neue Funktionen so schnell wie möglich unterstützen, wenn Sie sie plötzlich benötigen (z. B. eine neue Ebene hinzufügen und einen Leistungsfehler beseitigen).
- Einfache Integration in eine schlüsselfertige Lösung.
- Die Funktionsweise der Bibliothek auf anderen Plattformen als x86 / x86_64 - beispielsweise auf ARM.
Es ist wahrscheinlich, dass die Leser andere Fragen oder Einwände haben werden - aber ich kann sie immer noch nicht vorhersagen, und deshalb werde ich in den Kommentaren zum Artikel antworten. Beginnen wir in der Zwischenzeit mit einer direkten Beschreibung von Synet.
Synet-Kurzbeschreibung
Synet ist in
C ++ geschrieben und enthält nur
Header-Dateien . In
Simd , einem weiteren Open-Source-Projekt zur Beschleunigung der Bildverarbeitung auf einer CPU, werden plattformspezifische Optimierungen auf niedriger Ebene implementiert. Und dies ist die einzige externe Abhängigkeit von Synet (ein solches Schema wurde gewählt, um die Integration der Bibliothek in Projekte von Drittanbietern zu erleichtern). Zum Starten neuronaler Netze werden Modelle ihres eigenen internen Formats verwendet.
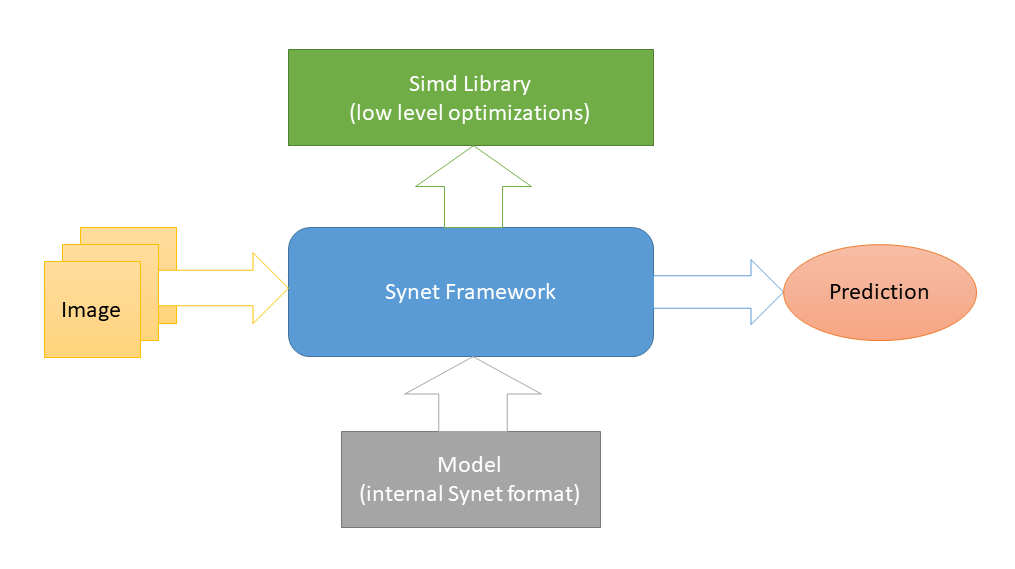
Die Konvertierung von vorab trainierten Modellen in das interne Format erfolgt nach einem zweistufigen Schema: 1) Konvertieren Sie zunächst das Modell in das Inference Engine-Format (gut)
OpenVINO verfügt dazu über alle notwendigen
Tools . 2) Konvertieren Sie dann aus dieser Zwischendarstellung direkt in das interne Synet-Format.

Das Synet-Modell enthält zwei Dateien: 1) * .XML - eine Datei mit einer Beschreibung der Struktur des Modells. 2) * .BIN - eine Datei mit trainierten Gewichten.

Synet Beispiel
Das folgende Beispiel zeigt die Verwendung von Synet zum Erkennen von Gesichtern. Das ursprüngliche Inference Engine-Modell wird
hier aufgenommen .
#define SYNET_SIMD_LIBRARY_ENABLE #include "Synet/Network.h" #include "Synet/Converters/InferenceEngine.h" #include "Simd/SimdDrawing.hpp" typedef Synet::Network<float> Net; typedef Synet::View View; typedef Synet::Shape Shape; typedef Synet::Region<float> Region; typedef std::vector<Region> Regions; int main(int argc, char* argv[]) { Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin"); Net net; net.Load("synet.xml", "synet.bin"); net.Reshape(256, 256, 1); Shape shape = net.NchwShape(); View original; original.Load("faces_0.ppm"); View resized(shape[3], shape[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea); net.SetInput(resized, 0.0f, 255.0f); net.Forward(); Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f); uint32_t white = 0xFFFFFFFF; for (size_t i = 0; i < faces.size(); ++i) { const Region & face = faces[i]; ptrdiff_t l = ptrdiff_t(face.x - face.w / 2); ptrdiff_t t = ptrdiff_t(face.y - face.h / 2); ptrdiff_t r = ptrdiff_t(face.x + face.w / 2); ptrdiff_t b = ptrdiff_t(face.y + face.h / 2); Simd::DrawRectangle(original, l, t, r, b, white); } original.Save("annotated_faces_0.ppm"); return 0; }
Als Ergebnis des Beispiels sollte ein Bild mit kommentierten Gesichtern angezeigt werden:

Nehmen wir nun ein Beispiel für die Schritte:
- Zunächst wird das Modell vom Inference Engine-Format in Synet konvertiert:
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
In der Realität wird dieser Schritt einmal ausgeführt, und dann wird das bereits konvertierte Modell überall verwendet. - Konvertiertes Modell herunterladen:
Net net; net.Load("synet.xml", "synet.bin");
- Ein optionaler Schritt zum Ändern der Größe des Eingabebilds und des Stapels (natürlich muss das Modell das Ändern der Größe des Eingabebilds unterstützen):
net.Reshape(256, 256, 1);
- Laden Sie ein Bild und bringen Sie es in die Eingabegröße des Modells:
View original; original.Load("faces_0.ppm"); View resized(net.NchwShape()[3], net.NchwShape()[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea);
- Bild in Modell laden:
net.SetInput(resized, 0.0f, 255.0f);
- Starten der direkten Signalausbreitung im Netzwerk:
net.Forward();
- Abrufen einer Reihe von Regionen mit gefundenen Gesichtern:
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
Leistungsvergleich
Es wäre wahrscheinlich nicht ganz richtig, Synet mit klassischen Frameworks für maschinelles Lernen zu vergleichen. Beispielsweise
umgeht die Inference Engine
diese bei einer Reihe von Tests mehrmals .
Im Folgenden finden Sie ein Beispiel für den Vergleich der Single-Thread-Leistung der Inference Engine (ein Produkt mit ähnlicher Funktionalität) und von Synet anhand eines Beispiels aus einer
Reihe offener Modelle :
Wie aus der Tabelle hervorgeht, entspricht bei diesen Tests auf einem Computer mit Unterstützung für AVX2 (i7-6700) die Leistung von Synet im Allgemeinen der Leistung der Inference Engine (obwohl sie von Modell zu Modell sehr unterschiedlich ist). Auf einem Computer mit Unterstützung für den AVX-512 (i9-7900X) liegt die Leistung von Synet im Durchschnitt um 25% über der der Inference Engine.
Alle Messungen wurden von der Testanwendung in Synet durchgeführt. Auf Wunsch können die Leser die Tests selbst reproduzieren:
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet cd synet ./build.sh inference_engine ./test.sh
Vor- und Nachteile
Ich werde mit den Profis beginnen:
- Das Projekt ist klein und kann problemlos in Projekten von Drittanbietern implementiert werden.
- Zeigt eine hohe Single-Threaded-Leistung.
- Funktioniert auf mobilen Prozessoren (unterstützt ARM-NEON).
Gut und Nachteile, wo ohne sie:
- GPU und andere spezielle Beschleuniger werden nicht unterstützt.
- Schlechte Parallelisierung einer Aufgabe auf Mehrkern-CPUs.
- Keine Unterstützung für INT8 (Quantisierung von Gewichten).
Fazit
Synet wird derzeit im Rahmen des
Kipod- Projekts verwendet, einer Cloud-basierten Plattform für Videoanalysen. Vielleicht hat er andere Benutzer, aber das ist nicht sicher :). Während sich das Projekt entwickelt, möchte ich in Zukunft Folgendes hinzufügen:
- Unterstützung für neue Modelle, Ebenen, Algorithmen.
- Unterstützung für Ganzzahlberechnungen im INT8-Format (quantisierte Gewichte).
- GPU-Computing-Unterstützung.
- Vom ONNX-Format konvertieren.
Diese Liste ist bei weitem nicht vollständig und ich möchte sie unter Berücksichtigung der Meinung der Community ergänzen - daher warte ich auf Ihr Feedback! Damit das Tool nicht nur für unser Unternehmen, sondern auch für eine Vielzahl von Anwendern nützlich ist. Außerdem würde der Autor die Unterstützung der Community im Entwicklungsprozess nicht verweigern.
Bei der Beschreibung von Synet, die ich in diesem Artikel gemacht habe, habe ich mich bewusst nicht mit den Details seiner internen Implementierung befasst - es gibt viele leckere Algorithmen unter der Haube, aber ich möchte die Details ihrer Implementierung in den folgenden Artikeln der Serie offenlegen:
- Faltungsschicht: Techniken zur Optimierung der Matrixmultiplikation
- Faltungsschicht: schnelle Faltung nach der Methode von Shmuel Vinograd