 Sie können die Datei mit dem Code und den Daten im Originalbeitrag auf meinem Blog herunterladen
Sie können die Datei mit dem Code und den Daten im Originalbeitrag auf meinem Blog herunterladenEs gibt ein sehr interessantes Projekt - "
Rosetta Code" . Ihr Ziel ist es, „die Lösung der gleichen Probleme in einer möglichst großen Anzahl verschiedener Programmiersprachen zu präsentieren, um ihre gemeinsamen Orte und Unterschiede aufzuzeigen und einer Person, die das Wissen hat, das Problem mit einer Methode zu lösen, zu helfen, eine andere zu lernen.
Diese Ressource bietet eine einzigartige Möglichkeit, Programmcodes in verschiedenen Sprachen zu vergleichen, was wir in diesem Artikel tun werden. Es ist eine vollständige Überarbeitung und Verfeinerung des Artikels von John MacLoon "
Code Length Measured in 14 Languages ".
Daten importieren und analysieren
Beginnen wir mit einer Änderung der
Importfunktion , in der Daten für die zukünftige Verwendung gespeichert werden, um sie später nicht vom Server anzufordern.
Clear[importOnce]; importOnce[args___]:=importOnce[args]=Import[args]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "importOnce.mx"}]
Erstellen Sie einen Parser zum Importieren von Daten.
Clear[createPageLinkDataset]; createPageLinkDataset[baseLink_]:=createPageLinkDataset[baseLink]=Cases[Cases[Import[baseLink, "XMLObject"], XMLElement["div", {"class"->"mw-content-ltr", "dir"->"ltr", "lang"->"en"}, data_]:>data, Infinity], XMLElement["li", {}, {XMLElement["a", {___, "href"->link_, ___}, {name_}]}]:><|"name"->name, "link"->"http://rosettacode.org"<>link|>, Infinity]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "createPageLinkDataset.mx"}]
Wir importieren die Liste aller vom Projekt unterstützten Programmiersprachen (es gibt bereits mehr als 750 davon):
$Languages=createPageLinkDataset["http://rosettacode.org/wiki/Category:Programming_Languages"]; Dataset@$Languages

Wir werden Funktionen zum Übersetzen des Namens in einen Link erstellen und umgekehrt. Dies wird uns später nützlich sein:
langLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Languages, #[["link"]]==link&]["name"]; langNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Languages, #[["name"]]==name&]["link"];
Wir werden die Liste der Aufgaben laden, die in jeder der Programmiersprachen gelöst sind. Das Parsen ist so konzipiert, dass nicht alle Links zu Seiten Aufgaben sind. Wir werden sie später reinigen.
$LangTasksAllPre=Map[<|"name"->#["name"], "link"->#["link"], "tasks"->createPageLinkDataset[#["link"]][[All, "link"]]|>&, $Languages]; Dataset@$LangTasksAllPre

Wir berechnen eine Liste aller potenziellen Aufgaben, die im Projekt gelöst werden können (es gibt etwas mehr als 2600 davon):
$TasksPre=DeleteDuplicates[Flatten[$LangTasksAllPre[[;;, "tasks"]]]]; Length[$TasksPre]

Erstellen wir eine Funktion, die alle Codefragmente auf der Aufgabenseite erfasst.
ClearAll[codeExtractor]; codeExtractor[link_String]:=Module[{code, positions, rawData}, code=importOnce[link, "XMLObject"]; positions=Map[{#[[1, 1;;-2]], Partition[#[[;;, -1]], 2, 1]}&, DeleteCases[ Gather[ Position[code, XMLElement["h2", _, title_]], And[Length[#1]==Length[#2], #1[[1;;-2]]==#2[[1;;-2]]]&], x_/; Length[x]==1]]; rawData=Framed/@Flatten[Map[ With[{pos=#[[1]]}, Map[Extract[code, pos][[#[[1]];;#[[2]]-1]]&, #[[2]]]]&, positions], 1]; Association@DeleteCases[Map[langLinkToName[("link"/.#)]->("code"/.#)&, Map[ KeyValueMap[If[#1==="link", #1->#2[[1]], #1->#2]&, Merge[SequenceSplit[Cases[#, Highlighted[x_, ___]:>x, Infinity], {"Output"}][[1]], Identity]]&, rawData/.{XMLElement["h2", _, title_]:>Cases[title, XMLElement["a", {___, "href"->linkInner_/; MemberQ[$Languages[[;;, "link"]], "http://rosettacode.org"<>linkInner], ___}, {___}]:>Highlighted[<|"link"->"http://rosettacode.org"<>linkInner|>], Infinity], XMLElement["div", {}, x_/; Not[FreeQ[x, "Output:"]]]:>Highlighted["Output"], XMLElement["pre", _, code_]:>Highlighted[<|"code"->Check[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]], Echo[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]]]]|>, Background->Red]} ]], _->"code"]];
Jetzt werden wir alle Seiten bearbeiten:
ClearAll[taskCodes]; taskCodes[link_]:=taskCodes[link]=Check[codeExtractor[link], Echo[link]]; If[FileExistsQ[#], Get[#], taskCodes/@$TasksPre; DumpSave[#, taskCodes]]&@FileNameJoin[{NotebookDirectory[], "taskCodes.mx"}];
Ein Beispiel dafür, was die Funktion erzeugt:
Dataset[taskCodes[$TasksPre[[20]]]]
Wählen Sie Aufgabenseiten aus (solche mit mindestens einem Code):
$taskLangs=DeleteCases[{#, taskCodes[#]}&/@$TasksPre, {_, <||>}];
$langTasks=Map[<|"name"->#[["name"]], "link"->#[["link"]], "tasks"->With[{lang=#[["name"]]}, Select[$taskLangs, MemberQ[Keys[#[[2]]], lang]&][[;;, 1]]]|>&, $Languages]; Dataset[$langTasks]

Eine Liste von Aufgaben und Funktionen, die den Aufgabennamen in einen Link übersetzen und umgekehrt:
$Tasks=<|"name"->StringReplace[URLDecode[StringReplace[#, "http://rosettacode.org/wiki/"->""]], {"_"->" ", "/"->" -> "}], "link"->#|>&/@$taskLangs[[;;, 1]]; taskLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Tasks, #[["link"]]==link&]["name"]; taskNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Tasks, #[["name"]]==name&]["link"];
Einfache Statistik
Für eine Reihe von Sprachen gibt es noch kein gelöstes Problem:
WordCloud[1/StringLength[#]->#&/@Select[$langTasks, Length[#["tasks"]]==0&][[All, "name"]], ImageSize->{1200, 800}, MaxItems->All, WordOrientation->{

Liste der Sprachen, die Probleme gelöst haben:
$LanguagesWithTasks=Select[$langTasks, Length[#["tasks"]]=!=0&][[All, "name"]]; Length[$LanguagesWithTasks]
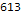
Verteilung der Anzahl der gelösten Probleme nach Sprache:
Histogram[Length/@$langTasks[[;;, "tasks"]], 50, PlotRange->All, BarOrigin->Bottom, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", lg[" "]}], ScalingFunctions->"Log10", PlotLabel->Style[" ", 20]]
Verteilung der Anzahl der Sprachen nach gelösten Aufgaben:
Histogram[Length/@$taskLangs[[;;, 2]], 50, PlotRange->All, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", " "}], PlotLabel->Style[" ", 20]]

Sprachen, in denen die am meisten gelösten Probleme sind:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.1, BarOrigin -> Left, AspectRatio -> 1, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last], {_, x_/; x<200}]

Aufgaben, die in den meisten Programmiersprachen gelöst wurden:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.2, BarOrigin -> Left, AspectRatio -> 1.6, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last], {_, x_/; x<100}]

Aufgaben, die eine Lösung für einen bestimmten Satz von Programmiersprachen haben
Eine Funktion, die Aufgaben anzeigt, die in einer oder mehreren Programmiersprachen gleichzeitig gelöst wurden:
commonTasks[lang_String]:=commonTasks[lang]=Sort[SelectFirst[$langTasks, #["name"]==lang&][["tasks"]]]; commonTasks["Mathematica"]:=commonTasks["Mathematica"]=Union[commonTasks["Wolfram Language"], Sort[SelectFirst[$langTasks, #["name"]=="Mathematica"&][["tasks"]]]]; commonTasks[lang_List]:=commonTasks[lang]=Sort[Intersection@@(commonTasks/@lang)];
Aufgaben, die den ersten 25 beliebtesten Sprachen gemeinsam sind (die Schriftgröße entspricht der relativen Anzahl der Sprachen, in denen das Problem gelöst ist):
WordCloud[With[{tasks=taskLinkToName/@commonTasks[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-25;;-1]][[;;, 1]]]}, Transpose@{tasks, tasks/.Rule@@@SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last]}], ImageSize->{1000, 1000}, MaxItems->All, WordOrientation->{

Funktion zum Messen der Codelänge
Als nächstes benötigen wir eine Metrik, um die Codelänge zu schätzen. Es wird allgemein angenommen, dass dies die Anzahl der Codezeilen ist:
SetAttributes[lineCount, Listable] lineCount[str_String]:=StringCount[StringReplace[StringReplace[str, {" "->"", "\t"->""}], "\n"..->"\n"], "\n"]+1;
Da dieser Parameter jedoch erheblich vom Markup des Codes beeinflusst wird (am Ende können Sie beispielsweise in Wolfram Langiuage (
Mathematica ) mehrere Befehle gleichzeitig in eine Zeile schreiben), verwenden wir die Anzahl der Zeichen, die keine Leerzeichen sind, als Metrik.
SetAttributes[characterCount, Listable] characterCount[str_String]:=StringLength[StringReplace[str, WhitespaceCharacter->""]];
Eine solche Metrik spielt
Mathematica mit ihren langen beschreibenden Befehlsnamen nicht in die Hände (was zweifellos ein großes Plus außerhalb dieses Blogs ist). Daher implementieren wir auch eine Metrik, die auf dem Zählen von Token („symbolischen“ Objekten) basiert, für die wir einzelne Wörter nehmen, die durch ein nicht getrenntes Zeichen getrennt sind der Brief.
SetAttributes[tokens, Listable] tokens[str_String]:=DeleteCases[StringSplit[str, Complement[Characters@FromCharacterCode[Range[1, 127]], CharacterRange["a", "z"], CharacterRange["A", "Z"], CharacterRange["0", "9"], {"."}]], ""]; tokenCount[str_String]:=Length[tokens[str]];
Codelängenmessung
Zu jeder Aufgabe erhalten wir einen Datensatz:
$taskData=Map[<|"name"->#[[1]], "lineCount"->Map[lineCount, #[[2]]], "characterCount"->Map[characterCount, #[[2]]], "tokens"->Map[Flatten[tokens[#]]&, #[[2]]]|>&, $taskLangs]; Dataset[$taskData]

Eine Funktion, die Statistiken für jede Sprache zu allen darauf gelösten Aufgaben sammelt:
Clear[langData]; langData[name_]:=langData[name]=<|"name"->name, "lineCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]], "characterCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]], "tokens"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]|>&@(With[{task=#}, SelectFirst[$taskData, #[["name"]]==task&]]&/@commonTasks[name]); Map[langData, $LanguagesWithTasks];
Eine Funktion, die Vergleichsmetriken für zwei (oder mehr) Programmiersprachen anhand aller gängigen Aufgaben vergleicht:
ClearAll[compareLanguagesData, compareLanguages]; compareLanguagesData[langs_List/; Length[langs]>=2]:=compareLanguagesData[langs]=Module[{tasks, data}, tasks=commonTasks[langs]; data=langData/@langs; <|"lineCount"->Transpose[Lookup[#[["lineCount"]], tasks][[;;, 1]]&/@data], "characterCount"->Transpose[Lookup[#[["characterCount"]], tasks][[;;, 1]]&/@data], "tokensCount"->Transpose[Lookup[Map[Length, #[["tokens"]]], tasks]&/@data]|> ]; compareLanguages[langs_List/; Length[langs]>=2, function_]:=Module[{data}, data=compareLanguagesData[langs]; Map[Map[function, #]&, data] ];
Analyse und Visualisierung
Jetzt können wir viele Analysen erhalten.
Zunächst vergleichen wir die absoluten Indikatoren. Die folgende Funktion erstellt ein Diagramm, in dem Punkte die entsprechenden Werte für zwei Sprachen anzeigen. Wenn der Punkt unterhalb der diagonalen Linie liegt (die Skalierung entlang der Achsen ist unterschiedlich, häufig wenn die Länge des Codes stark variiert), bedeutet dies, dass die Sprache von unten „gewonnen“ wird, andernfalls ist die Sprache „von oben“.
compareGraphic[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[Graphics[{Map[{If[#[[1]]<#[[2]], Orange, Darker@Green], Point[#]}&, #2], AbsoluteThickness[2], Gray, InfiniteLine[{{0, 0}, {1, 1}}]}, PlotRangePadding->0, GridLines->Automatic, AspectRatio->1, PlotRange->All, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"])]&, compareLanguages[{lang1, lang2}, Identity]], Background->White]
Sie können deutlich sehen, dass der Wolfram-Sprachcode immer fast kürzer als der C-Code ist:
compareGraphic[{"Mathematica", "C"}]

Oder Pytnon:
compareGraphic[{"Mathematica", "Python"}]

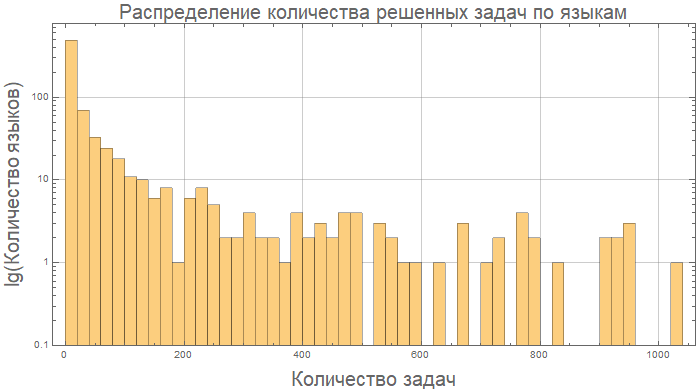
Und hier sind beispielsweise Kotlin und Java in Bezug auf die Codelänge im Wesentlichen "gleich":
compareGraphic[{"Kotlin", "Java"}]
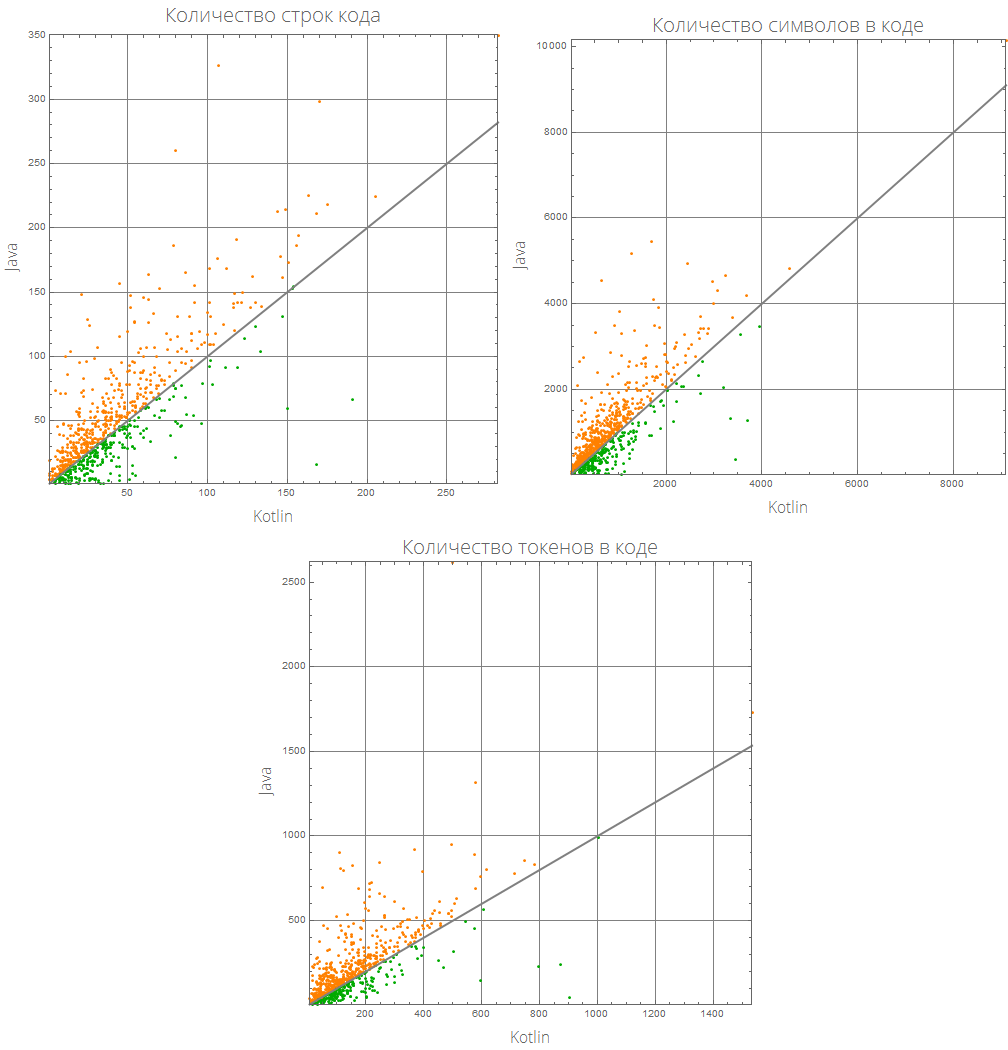
Diese grafische Darstellung kann informativer gestaltet werden:
comparePlot[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[ListLinePlot[Sort@#2, GridLines->Automatic, AspectRatio->1, PlotRange->{Automatic, {0, 2}}, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"]), ColorFunction->(If[#2>1, Orange, Darker@Green]&), ColorFunctionScaling->False, PlotStyle->AbsoluteThickness[3]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]], Background->White]
comparePlot[{"Mathematica", "R"}]
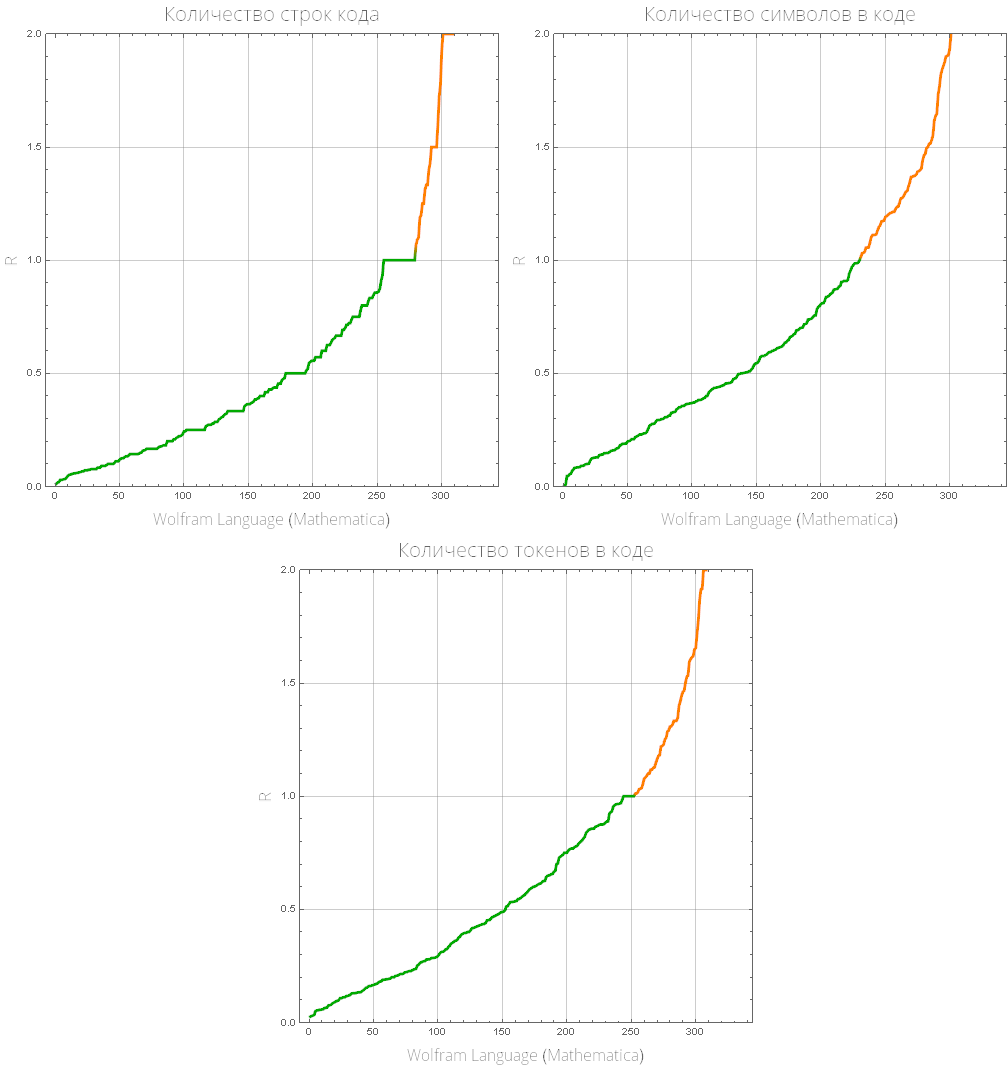
comparePlot[{"BASIC", "ALGOL 68"}]
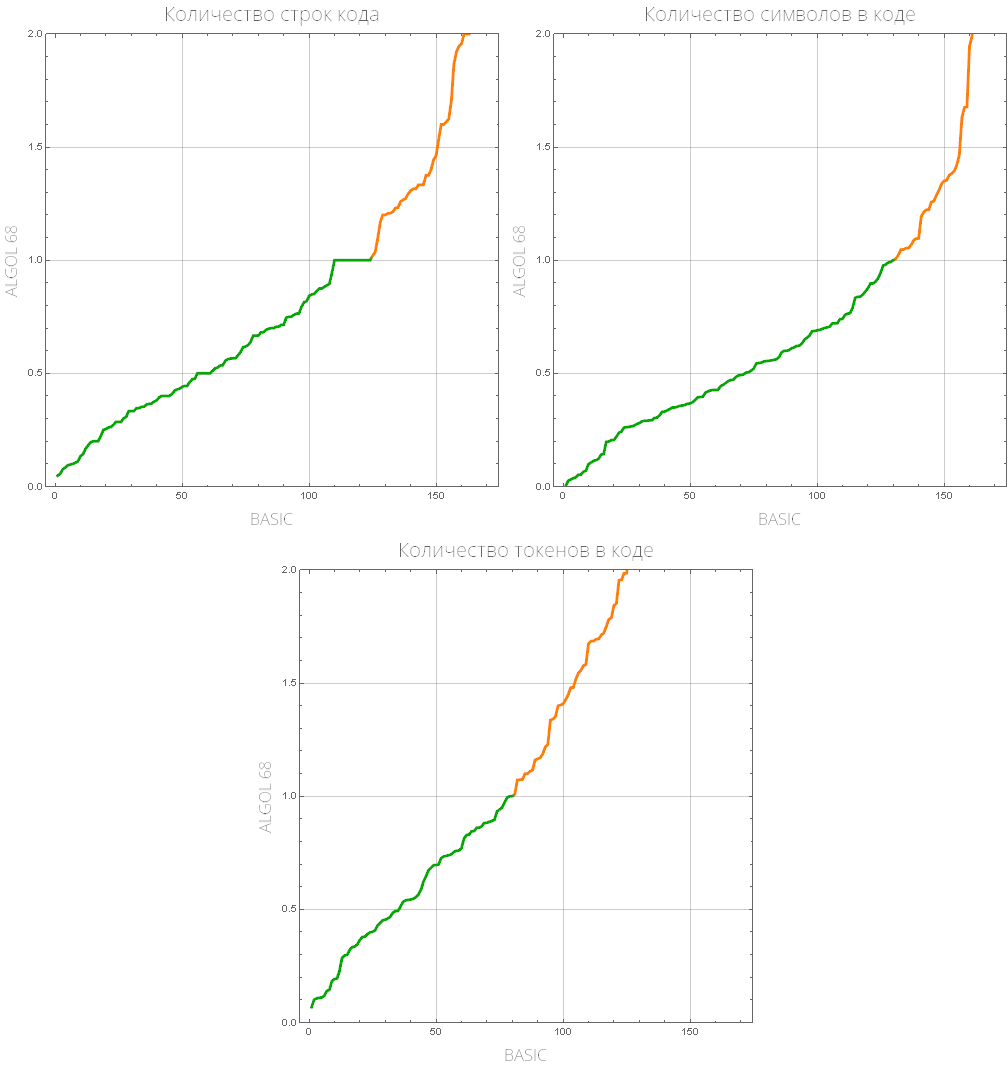
Wir definieren eine Funktion, die eine Liste der „gängigen“ Programmiersprachen anzeigt (diejenigen mit der größten Anzahl gelöster Aufgaben):
Clear[$popularLanguages]; $popularLanguages[n_/; n>2]:=$popularLanguages[n]=Reverse[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-n;;-1]]]
$popularLanguages[25]

Wir visualisieren die Liste der ersten 350 Sprachen (so wurde der Bildschirmschoner für diesen Beitrag zu Beginn erstellt):
WordCloud[$popularLanguages[350], ColorNegate@Binarize@ImageCrop@Import@"D:\\YandexDisk\\WolframMathematicaRuFiles\\388-3885229_rosetta-stone-silhouette-stone-silhouette-png-transparent-png.png", ImageSize->1000, MaxItems->All, WordOrientation->{

Eine Funktion, die die Codelängenanalyse in verschiedenen Metriken für die n ersten gängigen Sprachen anzeigt:
ClearAll[langMetricsGrid]; langMetricsGrid[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]<OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; orderedMeans=Round[If[OptionValue["SortQ"], Map[Mean, tableData/.""->Nothing][[order]], Map[Mean, tableData/.""->Nothing]], 1/1000]//N; {min, max}=MinMax[Cases[Flatten[tableData], _?NumericQ]]; scale=Function[Evaluate[Rescale[#, {min, max}, {0, 1}]]]; fullTableData=Transpose[{{""}~Join~$pl[[order]]}~Join~{{""}~Join~orderedMeans}~Join~Transpose[{Map[Rotate[#, 90Degree]&, $pl]}~Join~ReplaceAll[tableData, x_?NumericQ:>Item[Round[x, 1/100]//N, Background->Which[x<1, LightGreen, x==1, LightBlue, x>1, LightRed]]][[order]]/.""->Item["", Background->Gray]]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], Grid[fullTableData, Background->White, ItemStyle->Directive[FontSize -> 12, FontFamily->"Open Sans Light"], Dividers->White]], FrameStyle->None, Background->White]];
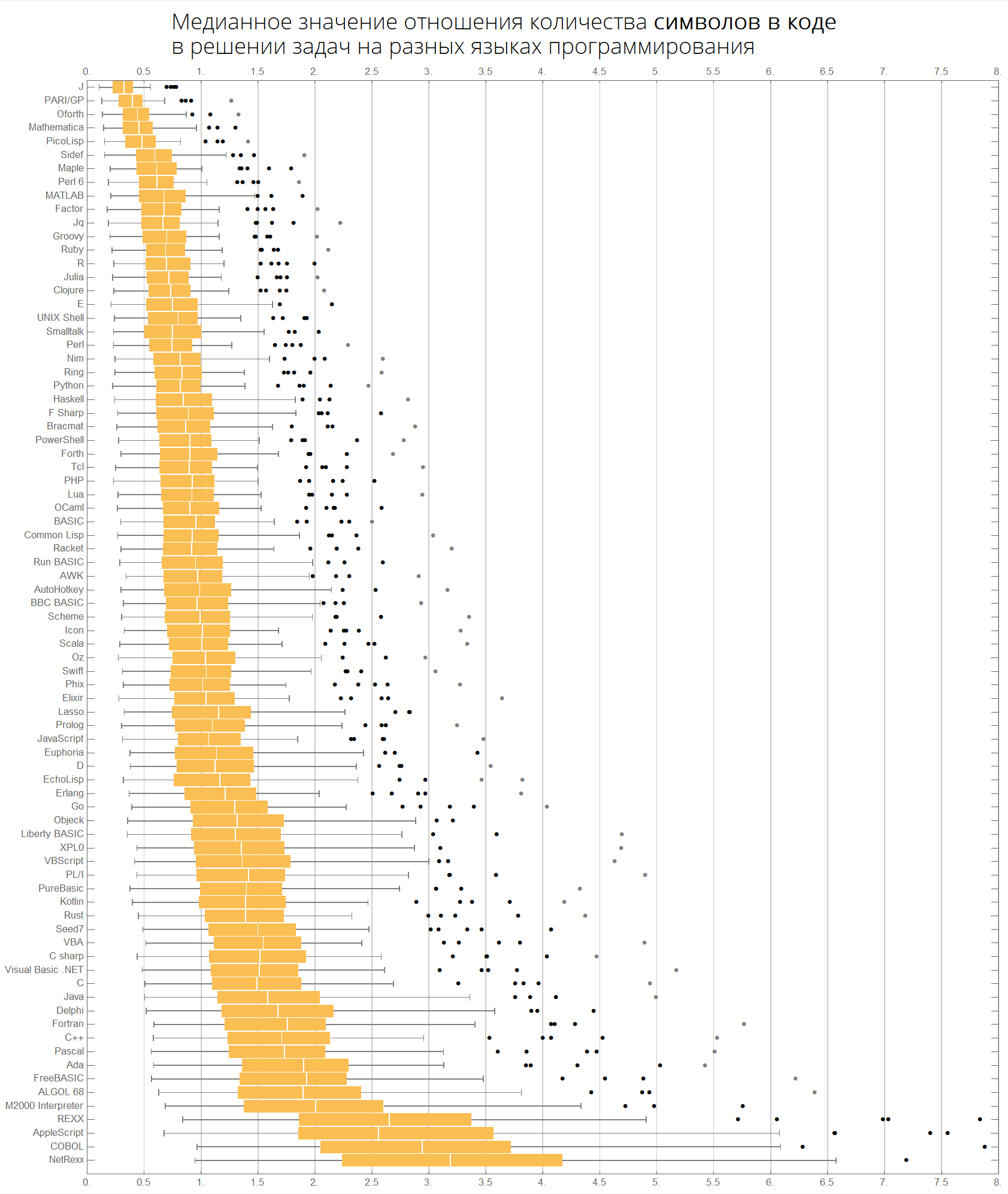
Der Medianwert des Verhältnisses der Anzahl der Codezeilen bei der Lösung von Problemen in verschiedenen Programmiersprachen:
langMetricsGrid[25, "lineCount", "SortQ"->False]

Wenn Sie die Tabelle nach der Spalte "Durchschnitt" sortieren, ist dies offensichtlicher - Wolfram Language (Mathematica) führt:
langMetricsGrid[25, "lineCount", "SortQ"->True]
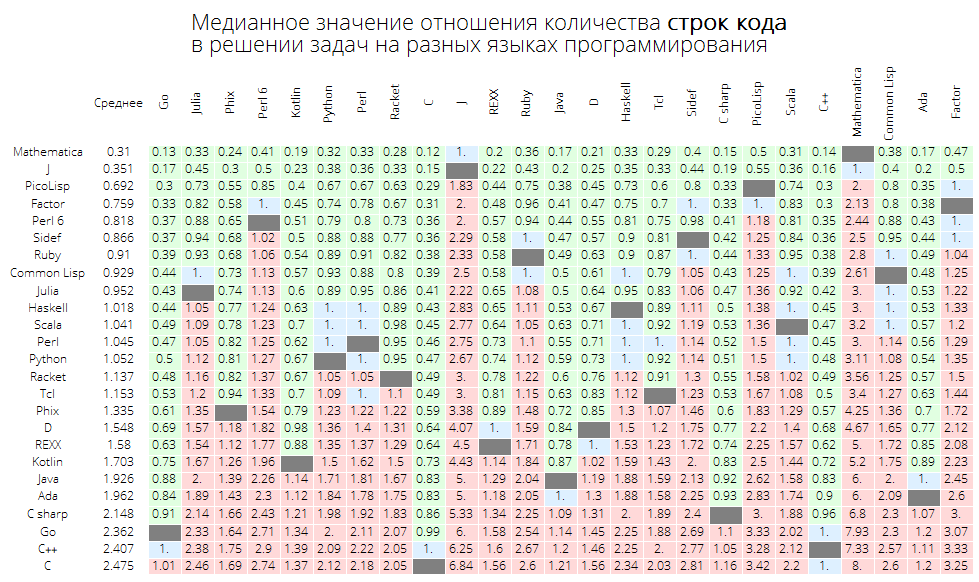
Der Medianwert des Verhältnisses der Anzahl der Zeichen im Code bei der Lösung von Problemen in verschiedenen Programmiersprachen:
langMetricsGrid[25, "characterCount", "SortQ"->True]

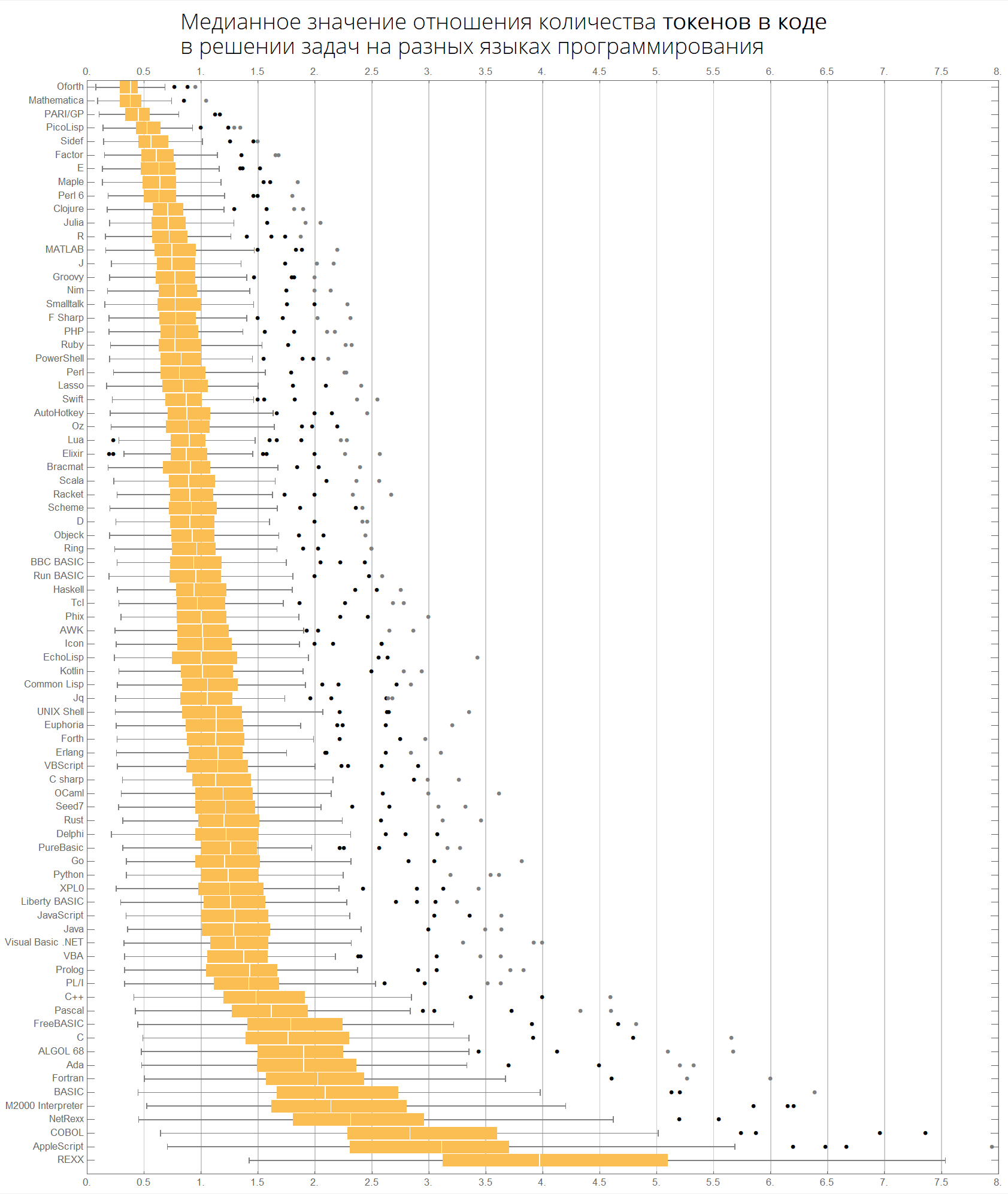
Der Medianwert des Verhältnisses der Anzahl der Token im Code bei der Lösung von Problemen in verschiedenen Programmiersprachen:
langMetricsGrid[25, "tokensCount", "SortQ"->True]

Dieselben Tabellen können beispielsweise für die ersten 50 beliebtesten Sprachen erstellt werden:
langMetricsGrid[50, "lineCount", "SortQ"->True] langMetricsGrid[50, "characterCount", "SortQ"->True] langMetricsGrid[50, "tokensCount", "SortQ"->True]



Wir können uns die gleichen Informationen kompakter vorstellen - in Form von Kisten mit Schnurrbart (Box-and-Whiskers-Diagramm):
ClearAll[langMetricsBoxWhiskerChart]; langMetricsBoxWhiskerChart[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=Reverse@$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]>OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], BoxWhiskerChart[tableData[[order]], "Outliers", ChartLabels->$pl[[order]], BarOrigin->Left, ImageSize->1000, AspectRatio->1, GridLines->{Range[0, 20, 1/2], None}, FrameTicks->{Range[0, 20, 0.5], Automatic}, PlotRangePadding->0, PlotRange->{{0, 8}, Automatic}, Background->White] ], FrameStyle->None, Background->White]];
Die Sprachen sind nach Beliebtheit sortiert (das Diagramm zeigt das Verhältnis der Anzahl der Codezeilen zwischen den Sprachen):
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->False]
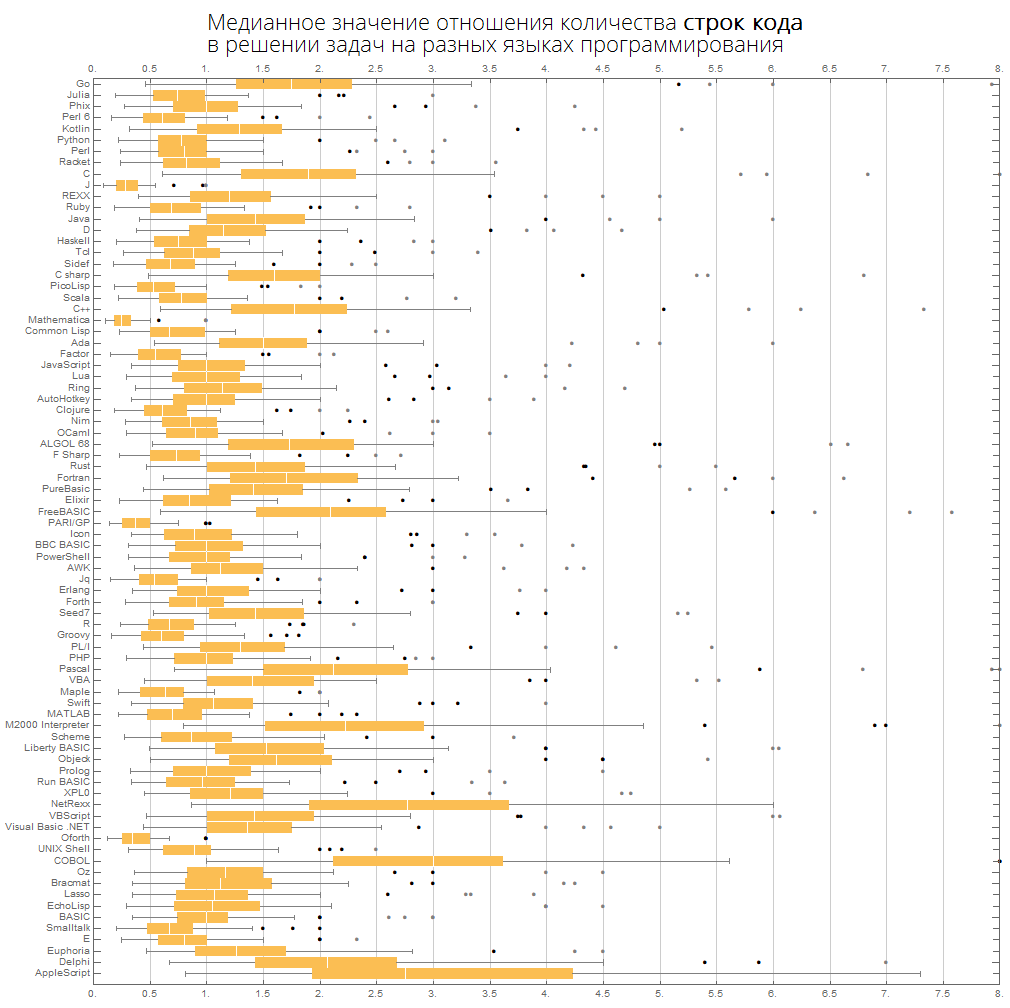
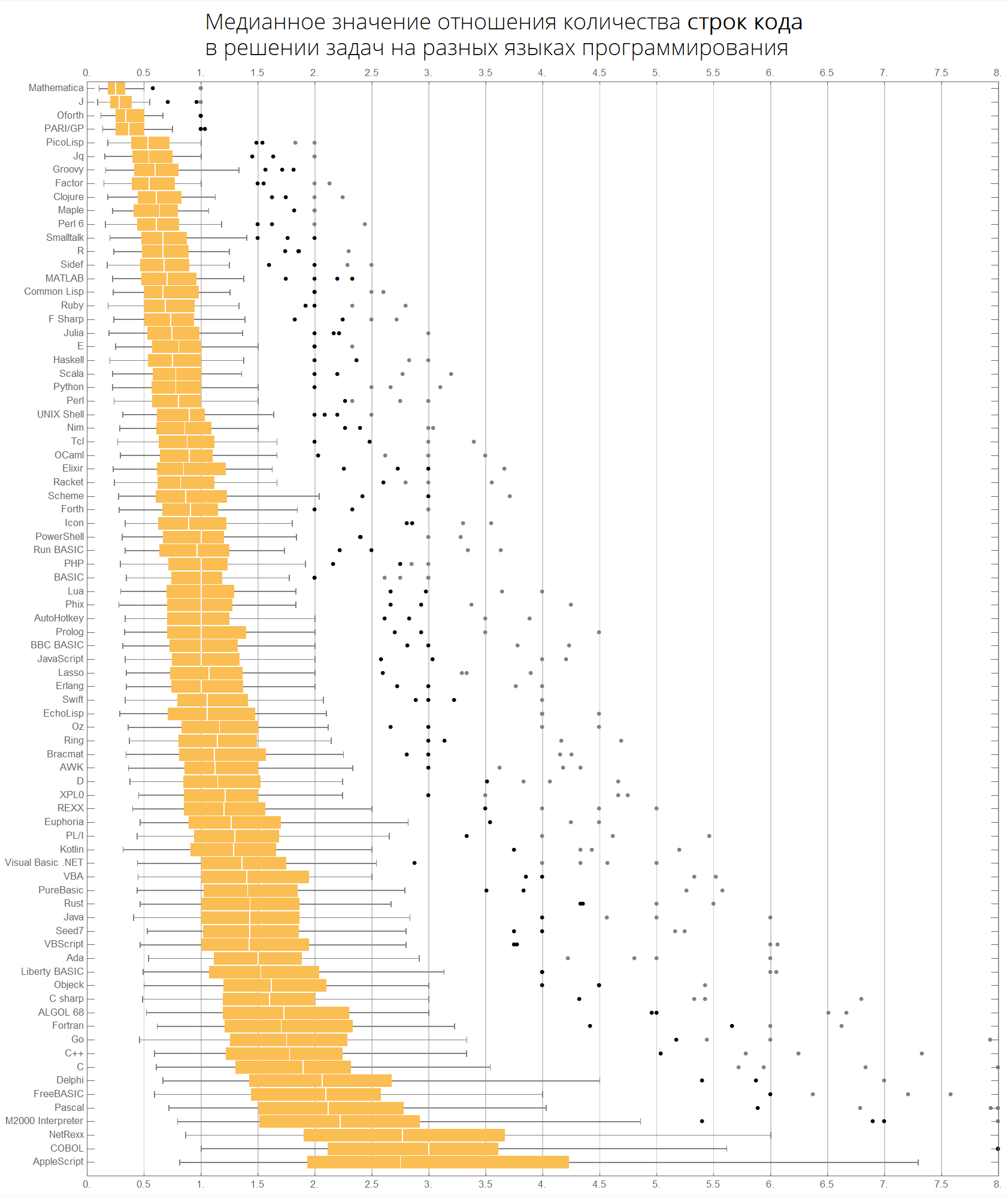
Nach Medianwert:
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->True]
Zum Schluss Diagramme zur Anzahl der Zeichen und Token:
langMetricsBoxWhiskerChart[80, "characterCount", "SortQ"->True] langMetricsBoxWhiskerChart[80, "tokensCount", "SortQ"->True]
Mal sehen, welche Token in verschiedenen Sprachen beliebt sind:
languagePopularTokens[lang_, nMin_:50]:=Framed[Labeled[Style[Row[{" ", Style[lang, Bold]}], FontFamily->"Open Sans Light", 24], WordCloud[Cases[SortBy[Tally[Flatten[Values[langData[lang][["tokens"]]]]], -Last[#]&], {x_/; (StringLength[x]>1&&StringMatchQ[x, RegularExpression["[a-zA-Z0-9.]+"]]&&Not[StringMatchQ[x, RegularExpression["[0-9.]+"]]]), y_/; y>nMin}], ImageSize->{1000, 500}, MaxItems->200, WordOrientation->{
clouds=Grid[{Image[#, ImageSize->All]&@Rasterize[languagePopularTokens[#, 10]]}&/@{"Mathematica", "C", "Python", "Go", "JavaScript"}]

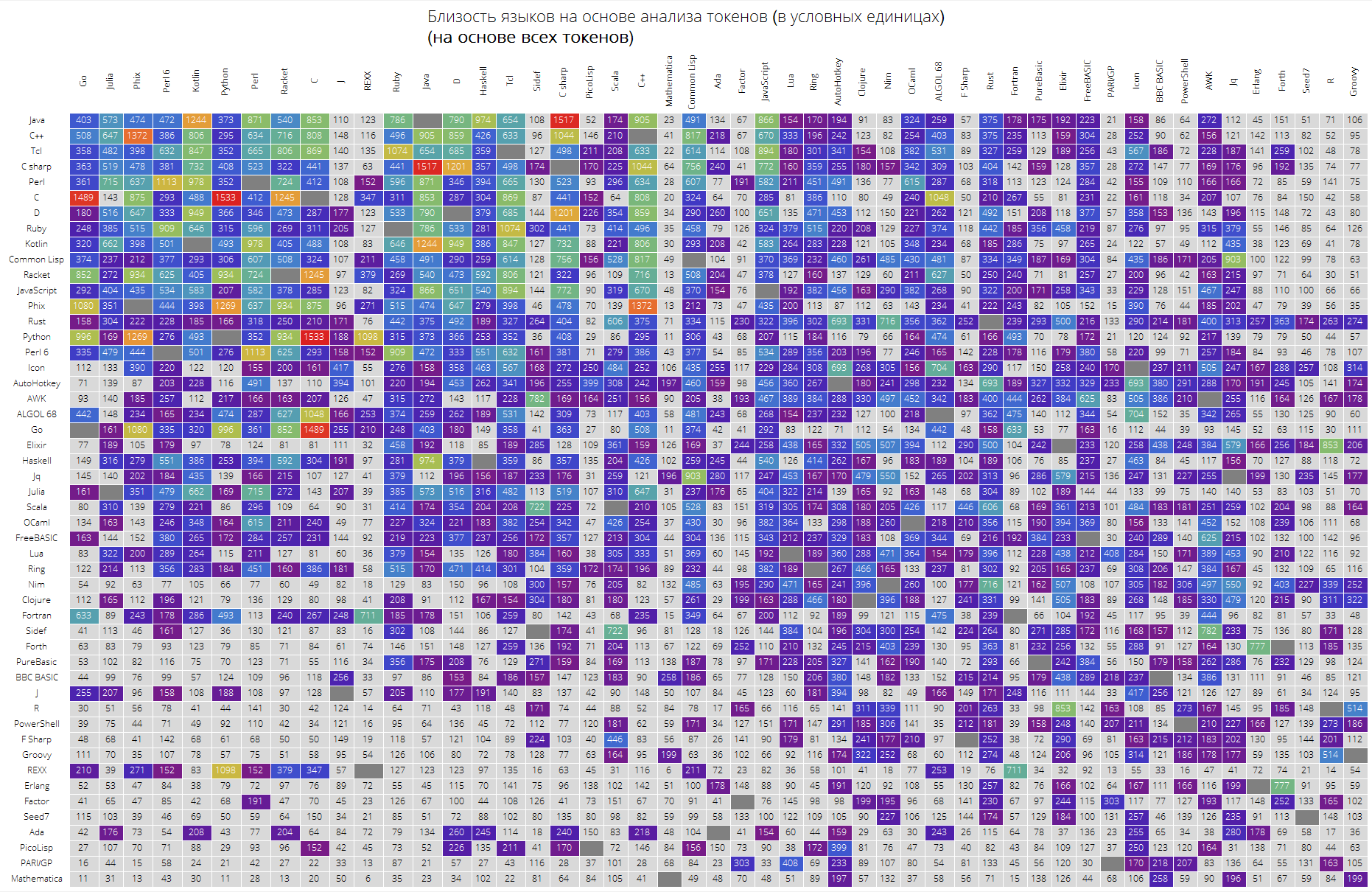
Und schließlich ein sehr interessanter Vergleich der Sprachen anhand der Nähe ihrer Token.
Die langSimilarity-Funktion funktioniert wie folgt: Zuerst werden "aussagekräftige Token" ausgewählt (diejenigen, die als alle Zeichenfolgen lateinischer Zeichen mit einer Länge von mindestens 2 Zeichen betrachtet werden, die einen Punkt enthalten können); Dann werden Token nach zwei Sprachen lang1 und lang2 durchsucht. Danach wird das Maß für ihre „Ähnlichkeit“ als Produkt des Jacquard-Maßes zweier Token-Sätze um den Betrag betrachtet, der für die Nähe der Token untereinander verantwortlich ist (die Summe der Elemente der Form
wo
Ist die Summe der Token-Auftritte in allen Lösungen für lang1- bzw. lang2-Sprachprobleme.
Clear[langSimilarity]; langSimilarity[{lang1_,lang2_},clearTokens_]:=langSimilarity@@(Sort[{lang1,lang2}]~Join~{clearTokens}); langSimilarity[lang1_,lang2_,clearTokens_:False]:=langSimilarity[lang1,lang2,clearTokens]=Module[{tokens,t1,t2,t1W,t2W,intersection}, tokens[lang_]:=Module[{values,tokensPre,allValues,replacements,n}, values=Values[langData[lang][["tokens"]]]; n=Length[values]; allValues=DeleteDuplicates[Flatten[values]]; tokensPre=If[clearTokens,Cases[allValues,x_/;(StringLength[x]>1&&StringMatchQ[x,RegularExpression["[a-zA-Z0-9._$]+"]]&&Not[StringMatchQ[x,RegularExpression["[0-9.,eE]+"]]])],allValues]; replacements=Dispatch@ Thread[Complement[allValues,tokensPre]->Nothing]; Cases[Tally@Flatten@(values/.replacements),{t_,x_/;x>=n/10}:>{t,x}]]; {t1,t2}=tokens/@{lang1,lang2}; {t1W,t2W}=Dispatch/@{Rule@@@t1,Rule@@@t2}; intersection=Intersection[t1[[;;,1]],t2[[;;,1]]]; Times@@{Total[(#[[1]]+#[[2]])/(1+Abs[#[[1]]-#[[2]]])&/@Transpose@N[{intersection/.t1W,intersection/.t2W}]],Length[intersection]/Length[Union[t1[[;;,1]],t2[[;;,1]]]]}]
ClearAll[langSimilarityGrid]; langSimilarityGrid[n_Integer, OptionsPattern[{"SortQ" -> True, "measureFunction" -> Mean, "clearTokens" -> True}]] := Module[{$nPL, $pl, tableData, notSortedTableData, order, fullTableData, min, max, orderedMeans, median, rescale}, $nPL = n; $pl = $popularLanguages[$nPL][[;; , 1]]; tableData = Quiet@Table[ If[i == j, "", langSimilarity[{$pl[[i]], $pl[[j]]}, OptionValue["clearTokens"]]], {i, 1, $nPL}, {j, 1, $nPL}]; {min, max} = MinMax[Flatten[tableData] /. "" -> Nothing]; median = 10^Median@Log10@Flatten[tableData /. "" -> Nothing]; rescale = Function[Evaluate[Rescale[#, {median, max}, {0, 1}]]]; order = If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1 /. "" -> Nothing] > OptionValue["measureFunction"][#2 /. "" -> Nothing] &], Range[1, $nPL]]; fullTableData = Transpose[{{""}~Join~$pl[[order]]}~Join~ Transpose[{Map[Rotate[#, 90 Degree] &, $pl]}~Join~ ReplaceAll[tableData[[order]], x_?NumericQ :> Item[Style[Round[x, 1], If[x < median, Black, White]], Background -> If[x < median, LightGray, ColorData["Rainbow"][rescale[x]]]]] /. "" -> Item["", Background -> Gray]]]; Framed[ Labeled[Style[ Row[{" ( )", "\n", "(", Style[If[OptionValue["clearTokens"], " ", " "], Bold], ")"}], 22, FontFamily -> "Open Sans Light", TextAlignment -> Center], Grid[fullTableData, Background -> White, ItemStyle -> Directive[FontSize -> 12, FontFamily -> "Open Sans Light"], Dividers -> White]], FrameStyle -> None, Background -> White]];
UPD: Nach einem wertvollen Kommentar entschied sich Assembly, zwei Tabellen zu erstellen: mit gelöschten Token und mit allen Token, ohne jegliche Bereinigung, um das Ergebnis so wenig wie möglich zu beeinflussen. Das Ergebnis ist etwas anders, wie Sie selbst sehen können, obwohl einige Abhängigkeiten klarer geworden sind.
Folgendes erhalten wir (unsortierte Tabelle):
langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> True] langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> False]
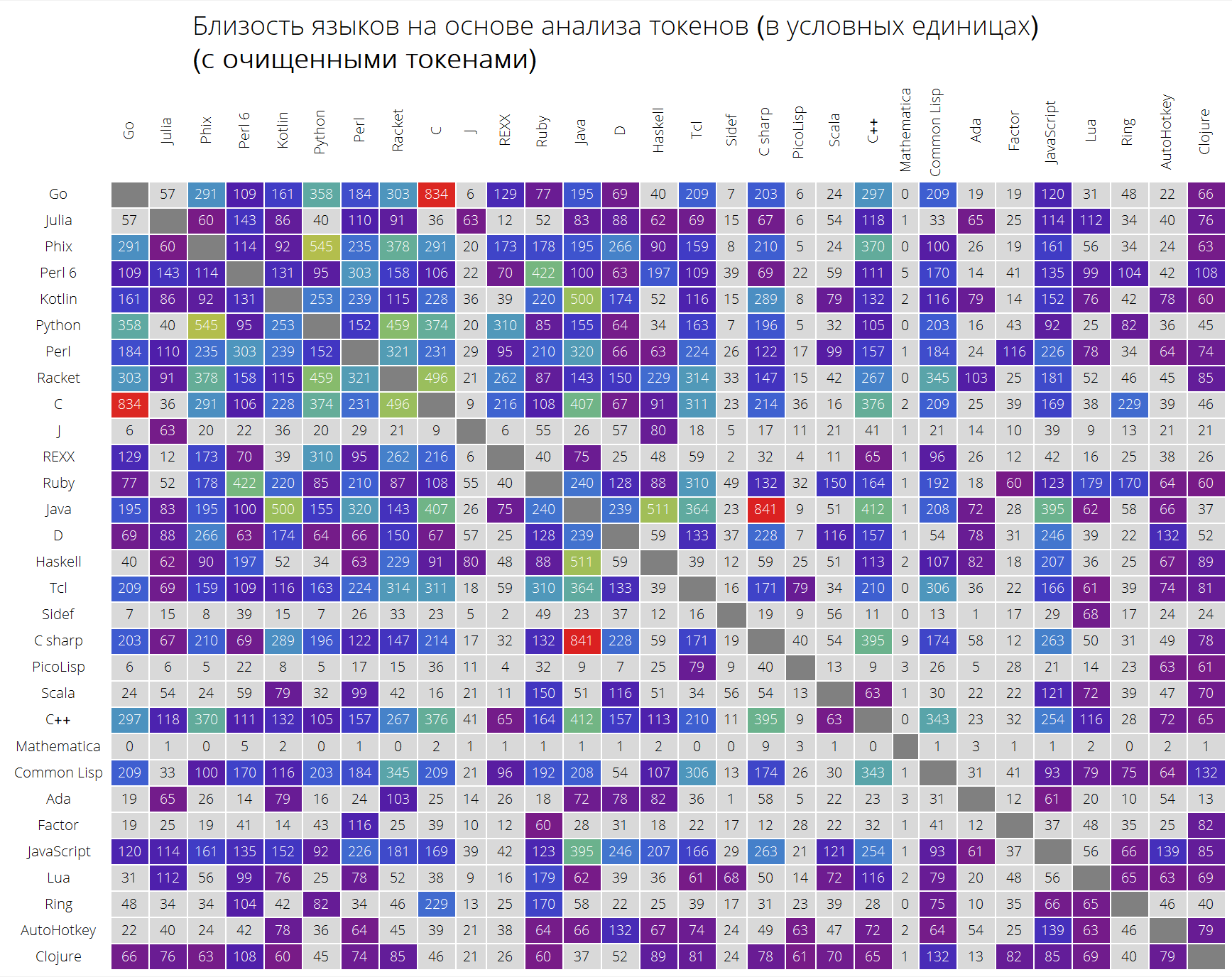

Sortierte Tabelle (in Bezug auf die durchschnittliche Ähnlichkeit mit anderen Sprachen - je höher die Zeile, desto mehr andere Programmiersprachen sieht diese Sprache aus):
langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> False]


Schließlich eine große Tabelle für die ersten 50 Sprachen in der Popularität.
Es wird erwartet, dass die "Schlüssel" -Sprachen wie Java, C, C ++, C # ganz oben stehen. Racket (ehemals PLTScheme) war dort, einer seiner Zwecke ist die Erstellung, Entwicklung und Implementierung von Programmiersprachen.
Interessanterweise stellte sich heraus, dass die Wolfram-Sprache im Wesentlichen eine andere Sprache war.
Die Verknüpfungen zwischen Sprachen sind ebenfalls sichtbar. Nehmen wir an, die Verknüpfungen zwischen Java und C #, Go und C, C und Java, Haskell und Java, Kotlin und Java, Python und Phix, Python und Racket und mehr sind sehr gut sichtbar.
langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> False]
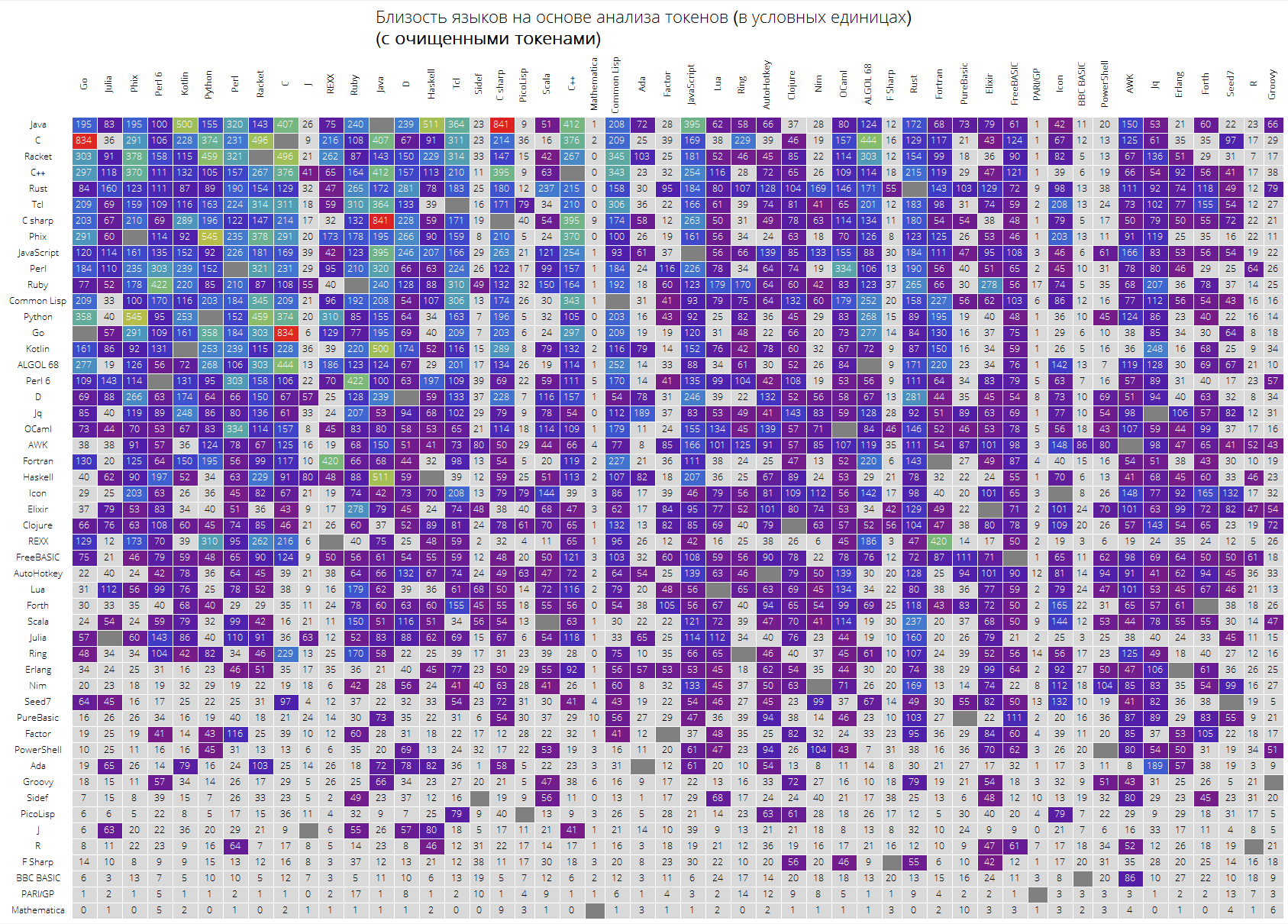
Ich hoffe, dass diese Studie für Sie interessant ist und Sie etwas Neues entdecken können. Für mich als Person, die ständig die Wolfram-Sprache verwendet, war es schön zu wissen, dass sie sich als die „kompakteste“ Sprache herausstellt. Einerseits macht ihre objektive „Unähnlichkeit“ zu anderen Sprachen die Eingabe offensichtlich etwas schwieriger.
Möchten Sie lernen, wie man in Wolfram-Sprache programmiert?
Sehen Sie sich wöchentliche Webinare an .
Anmeldung für neue Kurse . Bereit Online-Kurs .