Fortsetzung der Übersetzung eines kleinen Buches:
"Message Brokers verstehen",
Autor: Jakub Korab, Herausgeber: O'Reilly Media, Inc., Erscheinungsdatum: Juni 2017, ISBN: 9781492049296.
Übersetzung abgeschlossenVorheriger Teil:
Grundlegendes zu Message Brokern. Erlernen der Mechanismen des Messaging über ActiveMQ und Kafka. Kapitel 1. EinführungKAPITEL 2
Activemq
ActiveMQ lässt sich am besten als klassisches Messagingsystem beschreiben. Es wurde 2004 geschrieben, um den Bedarf an einem Open-Source-Nachrichtenbroker zu decken. Zu dieser Zeit waren teure kommerzielle Produkte die einzige Wahl, wenn Sie Messaging in Ihren Anwendungen verwenden wollten.
ActiveMQ wurde als Implementierung der Java Message Service (JMS) -Spezifikation entwickelt. Diese Entscheidung wurde getroffen, um die Anforderungen für die Implementierung von JMS-kompatiblem Messaging im Apache Geronimo-Projekt, einem Open-Source-J2EE-Anwendungsserver, zu erfüllen.
Ein Messaging-System (oder eine nachrichtenorientierte Middleware, wie sie manchmal genannt wird), die die JMS-Spezifikation implementiert, besteht aus den folgenden Komponenten:
MaklerEine zentrale Middleware, die Nachrichten verteilt.
KundeDie Software, die Nachrichten über einen Broker sendet. Es besteht wiederum aus folgenden Artefakten:
- Code mit der JMS-API.
- Die JMS-API besteht aus einer Reihe von Schnittstellen für die Interaktion mit einem Broker gemäß den in der JMS-Spezifikation festgelegten Garantien.
- Die Clientbibliothek des Systems, die die Implementierung der API bereitstellt und mit dem Broker interagiert.
Der Client und der Broker kommunizieren über das Anwendungsschichtprotokoll, das auch als
Interaktionsprotokoll bezeichnet wird, miteinander (Abbildung 2-1) . Die JMS-Spezifikation überließ die Details dieses Protokolls bestimmten Implementierungen.
 Abbildung 2-1. JMS-Überprüfung
Abbildung 2-1. JMS-ÜberprüfungJMS verwendet den Begriff
Provider , um die Implementierung des Messaging-Systems durch den
Anbieter zu beschreiben, das der JMS-API zugrunde liegt, zu der der Broker sowie seine Client-Bibliotheken gehören.
Die Entscheidung für die Implementierung von JMS hatte weitreichende Konsequenzen für die Implementierungsentscheidungen der ActiveMQ-Autoren. Die Spezifikation selbst enthält klare Richtlinien zu den Verantwortlichkeiten des Kunden des Nachrichtensystems und des Maklers, mit dem er kommuniziert, wobei die Verpflichtung des Maklers zur Verteilung und Zustellung von Nachrichten bevorzugt wird. Die Hauptverantwortung des Kunden besteht darin, mit dem Adressaten (Warteschlange oder Thema) der von ihm gesendeten Nachrichten zu interagieren. Die Spezifikation selbst zielt darauf ab, die Interaktion der API mit dem Broker relativ einfach zu machen.
Dieser Bereich hatte, wie wir später sehen werden, einen erheblichen Einfluss auf die ActiveMQ-Leistung. Zusätzlich zu den Komplexitäten des Brokers hatte das Kompatibilitätspaket für die von Sun Microsystems bereitgestellte Spezifikation viele Nuancen, die sich auf die Leistung auswirkten. Diese Nuancen sollten alle berücksichtigt worden sein, damit ActiveMQ als JMS-kompatibel angesehen werden kann.
Kommunikation
Obwohl die API und das erwartete Verhalten in der JMS-Spezifikation gut definiert waren, wurde das tatsächliche Client-Broker-Kommunikationsprotokoll absichtlich von der Spezifikation ausgeschlossen, damit vorhandene Broker JMS-konform gemacht werden konnten. Somit konnte ActiveMQ sein eigenes Interaktionsprotokoll, OpenWire, definieren. OpenWire wird von der Implementierung der ActiveMQ JMS-Clientbibliothek sowie von ihren Gegenstücken in .Net und C ++: NMS und CMS verwendet, bei denen es sich um ActiveMQ-Teilprojekte handelt, die von der Apache Software Foundation gehostet werden.
Im Laufe der Zeit wurde ActiveMQ um die Unterstützung anderer Interaktionsprotokolle erweitert, wodurch die Fähigkeit zur Interaktion mit anderen Sprachen und Umgebungen verbessert wurde:
AMQP 1.0Das Advanced Message Queuing-Protokoll (ISO / IEC 19464: 2014) darf nicht mit seinem Vorgänger 0.X verwechselt werden, der in anderen Messaging-Systemen, insbesondere RabbitMQ, unter Verwendung von 0.9.1 implementiert ist. AMQP 1.0 ist ein universelles Binärprotokoll zum Austausch von Nachrichten zwischen zwei Knoten. Es hat kein Konzept für Kunden oder Makler und enthält Funktionen wie Flusskontrolle, Transaktionen und verschiedene QoS (nicht mehr als einmal, mindestens einmal und genau einmal).
STOMPSimple / Streaming Text Oriented Messaging Protocol, ein einfach zu implementierendes Protokoll mit Dutzenden von Client-Implementierungen in verschiedenen Sprachen.
XmppErweiterbares Messaging- und Anwesenheitsprotokoll. (Extensible Messaging and Presence Protocol). Früher als Jabber bezeichnet, wurde dieses XML-basierte Protokoll ursprünglich für Chat-Systeme entwickelt, aber über seine ursprünglichen Anwendungsfälle hinaus um Publish-Subscribe-Messaging erweitert.
MQTTDas einfache Publish-Subscribe-Protokoll (ISO / IEC 20922: 2016), das für Machine-to-Machine- (M2M) und Internet of Things- (IoT) Anwendungen verwendet wird.
ActiveMQ unterstützt auch das Auferlegen der oben genannten Protokolle auf WebSockets, wodurch ein Vollduplex-Datenaustausch zwischen Anwendungen in einem Webbrowser und Zielen im Broker ermöglicht wird.
Wenn wir jetzt über ActiveMQ sprechen, beziehen wir uns nicht mehr ausschließlich auf den Interaktionsstapel, der auf den JMS / NMS / CMS-Bibliotheken und dem OpenWire-Protokoll basiert. Die Kombination und Auswahl von Sprachen, Plattformen und externen Bibliotheken, die für diese Anwendung am besten geeignet sind, wird immer beliebter. Beispielsweise kann eine JavaScript-Anwendung in einem Browser mit der
Eclipse Paho MQTT-Bibliothek ausgeführt werden, um Nachrichten über Web-Sockets an ActiveMQ zu senden. Diese Nachrichten werden von einem C ++ - Serverprozess gelesen, der AMQP über die
Apache Qpid Proton- Bibliothek verwendet. Aus dieser Perspektive wird die Messaging-Landschaft immer vielfältiger.
Mit Blick auf die Zukunft wird insbesondere AMQP viel mehr Möglichkeiten haben als jetzt, da Komponenten, die weder Kunden noch Makler sind, ein vertrauterer Bestandteil der Messaging-Landschaft werden. Beispielsweise fungiert der
Apache Qpid Dispatch Router als Nachrichtenrouter, mit dem Clients eine direkte Verbindung herstellen, sodass verschiedene Ziele unterschiedliche Adressen verarbeiten können und die Möglichkeit des Sharding (Trennung) besteht.
Beachten Sie bei der Arbeit mit Bibliotheken und externen Komponenten von Drittanbietern, dass diese eine variable Qualität haben und möglicherweise nicht mit den in ActiveMQ bereitgestellten Funktionen kompatibel sind. Als sehr einfaches Beispiel: Es ist unmöglich, Nachrichten über MQTT an die Warteschlange zu senden (ohne das Routing im Broker einzurichten). Daher müssen Sie einige Zeit mit Optionen arbeiten, um den Stapel des Messagingsystems zu bestimmen, der für die Anforderungen Ihrer Anwendung am besten geeignet ist.
Der Kompromiss zwischen Leistung und Zuverlässigkeit
Bevor wir uns mit den Details der Funktionsweise von Punkt-zu-Punkt-Nachrichten in ActiveMQ befassen, müssen wir ein wenig darüber sprechen, was alle Systeme mit starker Datenverarbeitung zu bieten haben: einen Kompromiss zwischen Leistung und Zuverlässigkeit.
Jedes System, das Daten akzeptiert, sei es ein Nachrichtenbroker oder eine Datenbank, sollte angewiesen werden, wie diese Daten im Falle eines Fehlers verarbeitet werden. Fehler können viele Formen annehmen, aber der Einfachheit halber werden wir sie auf eine Situation eingrenzen, in der das System die Stromversorgung verliert und sofort herunterfährt. In dieser Situation müssen wir darüber spekulieren, was mit den Daten im System geschehen wird. Wenn sich die Daten (in diesem Fall Nachrichten) im Speicher oder im flüchtigen Teil von Eisen befanden, z. B. im Cache, gehen diese Daten verloren. Wenn die Daten jedoch an einen nichtflüchtigen Speicher gesendet wurden, z. B. an eine Festplatte, sind sie wieder verfügbar, wenn das System wieder funktioniert.
Unter diesem Gesichtspunkt ist es sinnvoll, dass wir Nachrichten, die bei einem Brokerfehler nicht verloren gehen sollen, in den permanenten Speicher schreiben müssen. Die Kosten für diese spezielle Lösung sind leider ziemlich hoch.
Beachten Sie, dass der Unterschied zwischen dem Schreiben eines Megabytes an Daten auf die Festplatte 100-1000-mal langsamer ist als das Schreiben in den Speicher. Daher muss der Anwendungsentwickler entscheiden, ob die Zuverlässigkeit der Nachricht den Leistungsverlust wert ist. Entscheidungen wie diese sollten basierend auf einem Nutzungsszenario getroffen werden.
Der Kompromiss zwischen Leistung und Zuverlässigkeit basiert auf einer Reihe von Optionen. Je höher die Zuverlässigkeit, desto geringer die Leistung. Wenn Sie das System weniger zuverlässig machen, z. B. Nachrichten nur im Speicher speichern, steigt Ihre Produktivität erheblich. Standardmäßig ist JMS so konfiguriert, dass ActiveMQ aus Gründen der Zuverlässigkeit sofort einsatzbereit ist. Es gibt viele Mechanismen, mit denen Sie den Broker konfigurieren und mit ihm an einer Position in diesem Spektrum interagieren können, die für bestimmte Szenarien der Verwendung des Messagingsystems am besten geeignet ist.
Dieser Kompromiss wird auf der Ebene der einzelnen Makler angewendet. Nach Abschluss der Einrichtung eines einzelnen Brokers ist es jedoch möglich, das Nachrichtensystem über diesen Punkt hinaus zu skalieren, indem die Nachrichtenflüsse sorgfältig untersucht und der Datenverkehr zwischen mehreren Brokern aufgeteilt wird. Dies kann erreicht werden, indem bestimmten Empfängern ihre eigenen Broker zur Verfügung gestellt werden oder indem der gesamte Nachrichtenfluss entweder auf Anwendungsebene oder unter Verwendung einer Zwischenkomponente aufgeteilt wird. Später werden wir genauer untersuchen, wie die Topologien von Brokern berücksichtigt werden können.
Nachrichten speichern
ActiveMQ verfügt über eine Reihe steckbarer Strategien zur Aufbewahrung von Nachrichten. Sie werden in Form von Persistenzadaptern (Persistenzadaptern) geliefert, die als Nachrichtenspeicher-Engines betrachtet werden können. Dazu gehören festplattenbasierte Lösungen wie KahaDB und LevelDB sowie die Möglichkeit, die Datenbank über JDBC zu verwenden. Da erstere am häufigsten verwendet werden, werden wir unsere Diskussion auf sie konzentrieren.
Wenn ein Broker persistente Nachrichten empfängt, werden diese zuerst in einem Journal auf die Festplatte geschrieben. Ein Journal ist eine Datenstruktur auf der Festplatte, in der Sie nur Daten hinzufügen können und die aus mehreren Dateien besteht. Eingehende Nachrichten werden vom Broker in eine protokollunabhängige Darstellung des Objekts serialisiert und dann in binärer Form gemarshallt, die dann an das Ende des Protokolls geschrieben wird. Das Protokoll enthält ein Protokoll aller eingehenden Nachrichten sowie Informationen zu den Nachrichten, die vom Client als gelesen bestätigt wurden.
Persistenz-Festplattenadapter unterstützen Indexdateien, die verfolgen, wo sich die folgenden weitergeleiteten Nachrichten im Protokoll befinden. Wenn alle Nachrichten aus der Protokolldatei gelesen werden, werden sie vom ActiveMQ-Hintergrundworkflow entweder gelöscht oder archiviert. Wenn dieses Protokoll während des Ausfalls des Brokers beschädigt wird, erstellt ActiveMQ es basierend auf den Informationen in den Protokolldateien neu.
Nachrichten aus allen Warteschlangen werden in dieselben Protokolldateien geschrieben. Wenn also eine Nachricht nicht gelesen wird, kann die gesamte Datei (normalerweise 32 MB oder 100 MB, abhängig vom Persistenzadapter) nicht gelöscht werden. Dies kann im Laufe der Zeit zu Problemen mit geringem Speicherplatz führen.
Klassische Nachrichtenbroker sind nicht für die Langzeitspeicherung konzipiert - lesen Sie Ihre Nachrichten!
Protokolle sind ein äußerst effizienter Mechanismus zum Speichern und anschließenden Abrufen von Nachrichten, da der Datenträgerzugriff für beide Vorgänge sequentiell erfolgt. Auf herkömmlichen Festplatten wird dadurch die Anzahl der Festplattensuchen durch Zylinder minimiert, da die Köpfe auf der Festplatte einfach weiterhin Sektoren auf das rotierende Substrat der Festplatte lesen oder schreiben. In ähnlicher Weise ist bei SSDs der sequentielle Zugriff viel schneller als der wahlfreie Zugriff, da erstere die Speicherseiten des Laufwerks besser nutzen.
Festplattenleistungsfaktoren
Es gibt eine Reihe von Faktoren, die die Geschwindigkeit bestimmen, mit der eine Festplatte arbeiten kann. Um dies zu verstehen, betrachten Sie die Methode zum Schreiben auf eine Disc anhand eines vereinfachten mentalen Modells einer Pipe (
Abbildung 2-2 ).
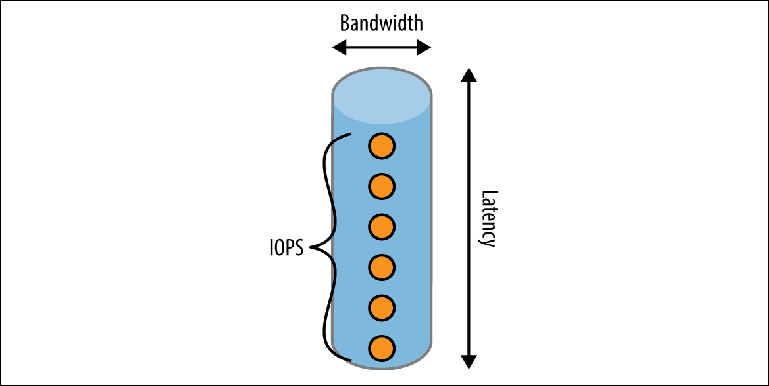 Abbildung 2-2. Disk Performance Tube-Modell
Abbildung 2-2. Disk Performance Tube-ModellEin Rohr hat drei Dimensionen:
LängeEntspricht der erwarteten
Latenz , um einen Vorgang abzuschließen. Für die meisten lokalen Laufwerke ist es ziemlich gut, aber es kann in Cloud-Umgebungen, in denen das lokale Laufwerk tatsächlich online ist, zu einem wichtigen einschränkenden Faktor werden. Zum Zeitpunkt des Schreibens (April 2017) garantiert Amazon beispielsweise, dass das Schreiben in den EBS-Speicher "in weniger als 2 ms" erfolgt. Wenn wir nacheinander aufnehmen, ergibt dies einen maximalen Durchsatz von 500 Datensätzen pro Sekunde.
BreiteBestimmt die
Tragfähigkeit oder Bandbreite einer einzelnen Operation. Dateisystem-Caches verwenden diese Eigenschaft, indem sie viele kleine Datensätze zu einem kleineren Satz größerer Schreibvorgänge kombinieren, die auf der Festplatte ausgeführt werden.
Bandbreite im Laufe der ZeitDie Idee wird in Form einer Reihe von Ereignissen dargestellt, die sich gleichzeitig in der Pipe befinden können, ausgedrückt durch eine Metrik namens
IOPS (die Anzahl der E / A-Operationen pro Sekunde) . IOPS wird häufig von Speicherherstellern und Cloud-Anbietern verwendet, um die Leistung zu messen. Die Festplatte hat in verschiedenen Kontexten unterschiedliche IOPS-Werte: ob die Arbeitslast hauptsächlich aus Lesen, Schreiben oder einer Kombination davon besteht und ob diese Vorgänge sequentiell, willkürlich oder gemischt sind. Die aus Sicht des Brokers am interessantesten IOPS-Messungen sind sequentielle Lese- und Schreibvorgänge, da sie dem Lesen und Schreiben von Protokollen eines Protokolls entsprechen.
Der maximale Durchsatz eines Nachrichtenbrokers wird durch das
Erreichen der ersten dieser Einschränkungen bestimmt. Die Brokerkonfiguration hängt weitgehend von der Art und Weise ab, wie Sie mit Datenträgern interagieren. Dies hängt nicht nur davon ab, wie beispielsweise der Broker konfiguriert ist, sondern auch davon, wie Produzenten mit dem Broker interagieren. Wie bei allem, was mit der Leistung zu tun hat, muss der Broker auf eine repräsentative Arbeitslast (d. H. So nah wie möglich an realen Nachrichten) und auf die tatsächliche Speicherkonfiguration getestet werden, die im PROM verwendet wird. Dies geschieht, um zu verstehen, wie sich das System in der Realität verhält.
JMS-API
Bevor wir uns mit den Details der Kommunikation von ActiveMQ mit Clients befassen, müssen wir zunächst die JMS-API kennenlernen. Die API definiert eine Reihe von Programmierschnittstellen, die vom Clientcode verwendet werden:
ConnectionFactoryDies ist die Schnittstelle der obersten Ebene, über die Verbindungen zum Broker hergestellt werden. In einer typischen Messaging-Anwendung gibt es nur eine Instanz dieser Schnittstelle. In ActiveMQ ist dies eine ActiveMQConnectionFactory. Auf der obersten Ebene gibt dieses Design den Standort des Nachrichtenbrokers sowie Details zur Interaktion mit ihm auf niedriger Ebene an. Wie der Name schon sagt, ist ConnectionFactory der Mechanismus, mit dem Verbindungsobjekte erstellt werden.
VerbindungDies ist ein langlebiges Objekt, das in etwa einer TCP-Verbindung ähnelt. Nach der Erstellung ist es normalerweise während des gesamten Lebenszyklus der Anwendung vorhanden, bis es geschlossen wird. Die Verbindung ist threadsicher und kann mit mehreren Threads gleichzeitig arbeiten. Mit Verbindungsobjekten können Sie Sitzungsobjekte erstellen.
SitzungDies ist ein Stream-Handle bei der Interaktion mit einem Broker. Sitzungsobjekte sind nicht threadsicher, was bedeutet, dass nicht mehrere Threads gleichzeitig auf sie zugreifen können. Sitzung ist der Haupttransaktionsdeskriptor, mit dem der Programmierer Rollback-Nachrichten festschreiben und zurücksetzen kann, wenn er sich im Transaktionsmodus befindet. Mit diesem Objekt erstellen Sie Message-, MessageConsumer- und MessageProducer-Objekte und erhalten Zeiger (Deskriptoren) auf Topic- und Queue-Objekte.
MessageProducerÜber diese Schnittstelle können Sie eine Nachricht an den Empfänger senden.
NachrichtenkonsumentÜber diese Schnittstelle kann der Entwickler Nachrichten empfangen. Es gibt zwei Mechanismen zum Abrufen von Nachrichten:
- Registrieren Sie MessageListener. Dies ist die von Ihnen implementierte Nachrichtenhandler-Schnittstelle, die alle vom Broker ausgegebenen Nachrichten nacheinander mit einem Stream verarbeitet.
- Abfragen von Nachrichten mit der Methode receive ().
NachrichtDies ist wahrscheinlich die wichtigste Struktur, da sie Ihre Daten überträgt. Nachrichten in JMS bestehen aus zwei Aspekten:
- Nachrichtenmetadaten. Die Nachricht enthält Header und Eigenschaften. Sowohl das als auch das können als Elemente einer Karte betrachtet werden. Header sind bekannte Elemente, die in der JMS-Spezifikation definiert sind und direkt über die API verfügbar sind, z. B. JMSDestination und JMSTimestamp. Eigenschaften sind beliebige Nachrichteninformationen, die die Verarbeitung oder Weiterleitung von Nachrichten vereinfachen, ohne die Nachrichtennutzdaten selbst lesen zu müssen. Sie können beispielsweise den Header auf AccountID oder OrderType setzen.
- Nachrichtentext. Abhängig von der Art des Inhalts, der im Hauptteil gesendet wird, können aus der Sitzung verschiedene Arten von Nachrichten erstellt werden. Die häufigsten sind TextMessage für Zeichenfolgen und BytesMessage für Binärdaten.
Wie Warteschlangen funktionieren: Eine Zwei-Hirn-Geschichte
Ein nützliches, wenn auch ungenaues ActiveMQ-Arbeitsmodell ist ein Modell aus zwei Gehirnhälften. Ein Teil ist für den Empfang von Nachrichten vom Hersteller verantwortlich, der andere Teil sendet diese Nachrichten an die Verbraucher. Beziehungen sind für Zwecke der Leistungsoptimierung tatsächlich komplexer, aber das Modell reicht für ein grundlegendes Verständnis aus.
Senden von Nachrichten an die Warteschlange
Schauen wir uns die Interaktion an, die beim Senden einer Nachricht auftritt.
Abbildung 2-3 zeigt ein vereinfachtes Modell des Prozesses, mit dem Nachrichten vom Broker empfangen werden. Es entspricht nicht vollständig dem jeweiligen Verhalten, ist aber durchaus geeignet, um ein grundlegendes Verständnis zu erlangen.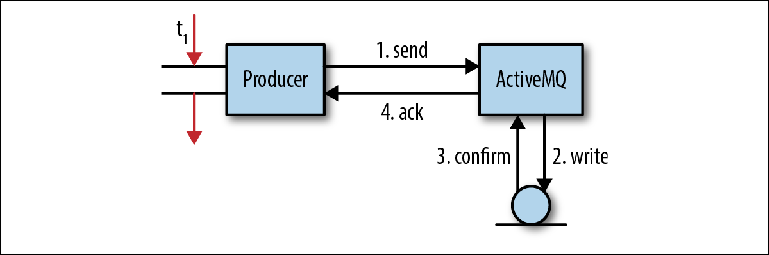 Abbildung 2-3. Senden von Nachrichten an JMSIn einer Clientanwendung erhält ein Thread einen Zeiger auf einen MessageProducer. Es erstellt eine Nachricht mit einer geschätzten Nachrichtennutzlast und ruft MessageProducer.send ("Bestellungen", Nachricht) auf, wobei die Warteschlange das endgültige Ziel der Nachricht ist. Da der Programmierer die Nachricht nicht verlieren möchte, wenn der Broker kaputt gegangen ist, wurde der Nachrichtenkopf JMSDeliveryMode auf PERSISTENT gesetzt (Standardverhalten).Zu diesem Zeitpunkt (1) ruft der sendende Stream die Clientbibliothek auf und führt die Nachricht im OpenWire-Format zusammen. Dann wird die Nachricht an den Broker gesendet.Im Broker entfernt der empfangende Stream die Nachricht aus der Leitung und stellt die Bereitstellung für das interne Objekt bereit. Anschließend wird das Nachrichtenobjekt an den Persistenzadapter übertragen, der die Nachricht im Format Google Protocol Buffers zusammenstellt und in den Speicher schreibt (2).Nach dem Aufzeichnen der Nachricht im Speicher sollte der Persistenzadapter eine Bestätigung erhalten, dass die Nachricht tatsächlich aufgezeichnet wurde (3). Dies ist normalerweise der langsamste Teil der gesamten Interaktion. dazu später mehr.Sobald der Broker sicherstellt, dass die Nachricht gespeichert wurde, sendet er eine Bestätigungsantwort (4) an den Kunden. Danach kann der Client-Thread, der ursprünglich die send () -Operation aufgerufen hat, seine Arbeit fortsetzen.Diese ausstehende Bestätigung persistenter Nachrichten ist die Grundlage für die Garantie der JMS-API. Wenn Sie möchten, dass die Nachricht gespeichert wird, ist es wahrscheinlich auch wichtig für Sie, ob die Nachricht überhaupt vom Broker empfangen wurde. Es gibt eine Reihe von Gründen, warum dies möglicherweise nicht möglich ist, z. B. wurde ein Speicher- oder Festplattenlimit erreicht. Anstelle eines Fehlers unterbricht der Broker entweder den Sendevorgang und zwingt den Produzenten, zu warten, bis genügend Systemressourcen zur Verarbeitung der Nachricht verfügbar sind (ein Prozess namens Producer Flow Control), oder er sendet eine negative Bestätigung an den Produzenten und löst eine Ausnahme aus. Das genaue Verhalten kann für jeden Broker angepasst werden.Bei dieser einfachen Operation findet eine erhebliche Anzahl von E / A-Interaktionen statt: zwei Netzwerkoperationen zwischen dem Hersteller und dem Broker, eine Speicheroperation und ein Bestätigungsschritt. Der Speichervorgang kann ein einfaches Schreiben auf die Festplatte oder ein anderer Netzwerkübergang zum Speicherserver sein.Dies wirft eine wichtige Frage zu Nachrichtenbrokern auf: Ihre Arbeit ist mit einem äußerst intensiven Strom von E / A-Vorgängen verbunden und sie reagieren sehr empfindlich auf die verwendete Infrastruktur, insbesondere auf Festplatten.Schauen wir uns den Bestätigungsschritt (3) in der obigen Interaktion genauer an. Wenn der Persistenzadapter dateibasiert ist, müssen Sie zum Speichern der Nachricht in das Dateisystem schreiben. Wenn ja, warum muss ich dann bestätigen, dass der Schreibvorgang abgeschlossen wurde? Bedeutet das Abschließen einer Aufnahme wirklich, dass eine Aufnahme stattgefunden hat?
Abbildung 2-3. Senden von Nachrichten an JMSIn einer Clientanwendung erhält ein Thread einen Zeiger auf einen MessageProducer. Es erstellt eine Nachricht mit einer geschätzten Nachrichtennutzlast und ruft MessageProducer.send ("Bestellungen", Nachricht) auf, wobei die Warteschlange das endgültige Ziel der Nachricht ist. Da der Programmierer die Nachricht nicht verlieren möchte, wenn der Broker kaputt gegangen ist, wurde der Nachrichtenkopf JMSDeliveryMode auf PERSISTENT gesetzt (Standardverhalten).Zu diesem Zeitpunkt (1) ruft der sendende Stream die Clientbibliothek auf und führt die Nachricht im OpenWire-Format zusammen. Dann wird die Nachricht an den Broker gesendet.Im Broker entfernt der empfangende Stream die Nachricht aus der Leitung und stellt die Bereitstellung für das interne Objekt bereit. Anschließend wird das Nachrichtenobjekt an den Persistenzadapter übertragen, der die Nachricht im Format Google Protocol Buffers zusammenstellt und in den Speicher schreibt (2).Nach dem Aufzeichnen der Nachricht im Speicher sollte der Persistenzadapter eine Bestätigung erhalten, dass die Nachricht tatsächlich aufgezeichnet wurde (3). Dies ist normalerweise der langsamste Teil der gesamten Interaktion. dazu später mehr.Sobald der Broker sicherstellt, dass die Nachricht gespeichert wurde, sendet er eine Bestätigungsantwort (4) an den Kunden. Danach kann der Client-Thread, der ursprünglich die send () -Operation aufgerufen hat, seine Arbeit fortsetzen.Diese ausstehende Bestätigung persistenter Nachrichten ist die Grundlage für die Garantie der JMS-API. Wenn Sie möchten, dass die Nachricht gespeichert wird, ist es wahrscheinlich auch wichtig für Sie, ob die Nachricht überhaupt vom Broker empfangen wurde. Es gibt eine Reihe von Gründen, warum dies möglicherweise nicht möglich ist, z. B. wurde ein Speicher- oder Festplattenlimit erreicht. Anstelle eines Fehlers unterbricht der Broker entweder den Sendevorgang und zwingt den Produzenten, zu warten, bis genügend Systemressourcen zur Verarbeitung der Nachricht verfügbar sind (ein Prozess namens Producer Flow Control), oder er sendet eine negative Bestätigung an den Produzenten und löst eine Ausnahme aus. Das genaue Verhalten kann für jeden Broker angepasst werden.Bei dieser einfachen Operation findet eine erhebliche Anzahl von E / A-Interaktionen statt: zwei Netzwerkoperationen zwischen dem Hersteller und dem Broker, eine Speicheroperation und ein Bestätigungsschritt. Der Speichervorgang kann ein einfaches Schreiben auf die Festplatte oder ein anderer Netzwerkübergang zum Speicherserver sein.Dies wirft eine wichtige Frage zu Nachrichtenbrokern auf: Ihre Arbeit ist mit einem äußerst intensiven Strom von E / A-Vorgängen verbunden und sie reagieren sehr empfindlich auf die verwendete Infrastruktur, insbesondere auf Festplatten.Schauen wir uns den Bestätigungsschritt (3) in der obigen Interaktion genauer an. Wenn der Persistenzadapter dateibasiert ist, müssen Sie zum Speichern der Nachricht in das Dateisystem schreiben. Wenn ja, warum muss ich dann bestätigen, dass der Schreibvorgang abgeschlossen wurde? Bedeutet das Abschließen einer Aufnahme wirklich, dass eine Aufnahme stattgefunden hat?Nicht wirklich.
Je tiefer Sie etwas studieren, desto komplexer wird es normalerweise. In diesem speziellen Fall ist das Caching der Schuldige .Caches, Caches überall
Wenn ein Betriebssystemprozess, z. B. ein Broker, Daten auf die Festplatte schreibt, interagiert er mit dem Dateisystem. Ein Dateisystem ist ein Prozess, der die Details der Interaktion mit dem verwendeten Speichermedium abstrahiert und eine API für Dateivorgänge wie OPEN, CLOSE, READ und WRITE bereitstellt. Eine dieser Funktionen besteht darin , die Anzahl der Schreibvorgänge zu minimieren, indem die vom Betriebssystem geschriebenen Daten in Blöcke gepuffert werden, die in einem Ansatz auf der Festplatte gespeichert werden können. Schreibvorgänge für Dateisysteme, die so aussehen, als würden sie mit Festplatten interagieren, werden tatsächlich in diesen Puffercache geschrieben .Übrigens, deshalb beschwert sich Ihr Computer, wenn Sie ein USB-Laufwerk unsicher auswerfen - die von Ihnen kopierten Dateien wurden möglicherweise nicht geschrieben!Sobald die Daten den Puffercache überschreiten, gelangen sie zur nächsten Caching-Ebene, diesmal auf Hardwareebene - dem Festplattencontroller-Cache . Sie sind besonders wichtig für RAID-basierte Systeme und erfüllen dieselbe Funktion wie das Caching auf Betriebssystemebene: Minimieren Sie die Anzahl der Interaktionen, die für die Laufwerke selbst erforderlich sind. Diese Caches lassen sich in zwei Kategorien einteilen:DurchschreibenSchreibvorgänge werden sofort nach Erhalt auf die Festplatte übertragen.RückschreibenDie Aufzeichnung wird nur dann auf Discs durchgeführt, wenn der Puffer voll ist und einen bestimmten Schwellenwert erreicht.Die in diesen Caches gespeicherten Daten können bei einem Stromausfall leicht verloren gehen, da der von ihnen verwendete Speicher normalerweise flüchtig (flüchtig) ist . Teurere Karten verfügen über redundante Akkus (BBUs), die die Cache-Stromversorgung unterstützen, bis das gesamte System die Stromversorgung wiederherstellen kann. Anschließend werden die Daten auf die Festplatte geschrieben.Die letzte Cache-Ebene befindet sich auf den Festplatten selbst. Festplatten-Cachesbefindet sich auf Festplatten (sowohl auf Standardfestplatten als auch auf Solid-State-Laufwerken) und kann entweder durchgeschrieben oder zurückgeschrieben werden. Die meisten kommerziellen Laufwerke verwenden Write-Back-Caches und sind flüchtig, was wiederum bedeutet, dass bei einem Stromausfall Daten verloren gehen können.Wenn Sie zum Nachrichtenbroker zurückkehren, müssen Sie den Bestätigungsschritt ausführen, um sicherzustellen, dass die Daten tatsächlich die Festplatte erreicht haben. Leider hängt die Interaktion mit diesen Hardwarepuffern vom Dateisystem ab. Ein Prozess wie ActiveMQ kann also nur ein Signal an das Dateisystem senden, dass alle Systempuffer mit dem verwendeten Gerät synchronisiert werden sollen. Zu diesem Zweck ruft der Broker die Methode java.io.FileDescriptor.sync () auf, die wiederum die POSIX-Operation fsync () startet.Dieses Synchronisationsverhalten ist eine Anforderung des JMS, um sicherzustellen, dass alle als persistent gekennzeichneten Nachrichten tatsächlich auf der Festplatte gespeichert und daher ausgeführt werden, nachdem jede Nachricht oder jeder Satz verwandter Nachrichten in einer Transaktion empfangen wurde. Daher ist die Geschwindigkeit, mit der eine Festplatte sync () ausführen kann, für die Leistung des Brokers von entscheidender Bedeutung.Interne Konflikte
Die Verwendung eines Protokolls für alle Warteschlangen erhöht die Komplexität. Zu einem bestimmten Zeitpunkt können mehrere Hersteller gleichzeitig Nachrichten senden. Der Broker verfügt über mehrere Streams, die diese Nachrichten von eingehenden Sockets empfangen. Jeder Thread muss seine Nachricht im Protokoll speichern. Da können nicht mehrere Threads gleichzeitig in dieselbe Datei schreiben, weil Datensätze stehen in Konflikt miteinander, dann sollten die Datensätze mithilfe des gegenseitigen Ausschlussmechanismus in die Warteschlange gestellt werden. Wir nennen diesen Thread-Konflikt .Jede Nachricht muss vollständig aufgezeichnet und synchronisiert werden, bevor die nächste Nachricht verarbeitet wird. Diese Einschränkung betrifft alle Warteschlangen im Broker gleichzeitig. Die Geschwindigkeit, mit der eine Nachricht empfangen werden kann, ist somit die Zeit, die zum Schreiben auf die Festplatte benötigt wird, sowie die Wartezeit, bis andere Streams die Aufzeichnung beendet haben.ActiveMQ enthält einen Schreibpuffer, in den die empfangenden Streams ihre Nachrichten schreiben und auf den Abschluss der vorherigen Aufzeichnung warten. Dann wird der Puffer in einer Aktion geschrieben, wenn die Nachricht verfügbar wird. Nach Abschluss werden die Threads benachrichtigt. Somit maximiert der Broker die Nutzung der Speicherbandbreite.Um die Auswirkungen von Thread-Konflikten zu minimieren, können Warteschlangensätzen mithilfe des mKahaDB-Adapters eigene Protokolle zugewiesen werden. Dieser Ansatz reduziert die Schreiblatenz, da Threads zu einem bestimmten Zeitpunkt höchstwahrscheinlich in verschiedene Journale schreiben und nicht miteinander um den exklusiven Zugriff auf eine einzelne Protokolldatei konkurrieren müssen.Transaktionen
Der Vorteil der Verwendung eines einzelnen Journals für alle Warteschlangen besteht darin, dass aus Sicht der Autoren des Brokers die Implementierung von Transaktionen viel einfacher ist.Schauen wir uns ein Beispiel an, in dem mehrere Nachrichten von einem Produzenten an mehrere Warteschlangen gesendet werden. Die Verwendung einer Transaktion bedeutet, dass der gesamte Satz der zu sendenden Nachrichten als eine atomare Operation betrachtet werden sollte. In dieser Interaktion kann die ActiveMQ-Clientbibliothek einige Optimierungen vornehmen, die die Sendegeschwindigkeit erheblich erhöhen.In der in Abbildung 2-4 gezeigten OperationDer Produzent sendet drei Nachrichten, alle in unterschiedlichen Warteschlangen. Anstelle der üblichen Interaktion mit dem Broker sendet der Client bei Bestätigung jeder Nachricht alle drei Nachrichten asynchron, dh ohne auf eine Antwort zu warten. Diese Nachrichten werden im Speicher des Brokers gespeichert. Sobald der Vorgang abgeschlossen ist, informiert der Produzent seine Sitzungen über die Notwendigkeit eines Commits, was wiederum den Broker zwingt, einen großen Datensatz mit einem Synchronisationsvorgang auszuführen.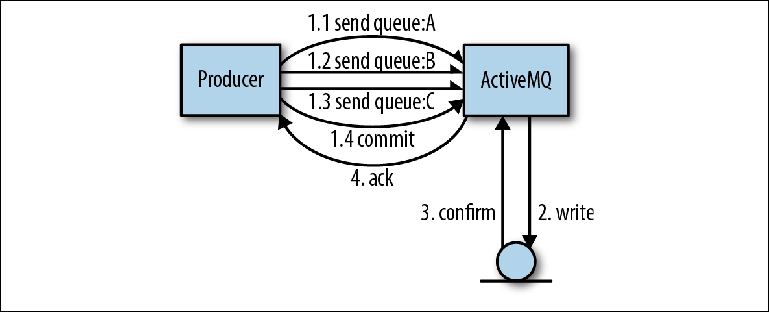 Abbildung 2-4. Senden von Nachrichten in TransaktionenBei dieser Art von Operation verwendet ActiveMQ zwei Optimierungen, um die Geschwindigkeit zu erhöhen:
Abbildung 2-4. Senden von Nachrichten in TransaktionenBei dieser Art von Operation verwendet ActiveMQ zwei Optimierungen, um die Geschwindigkeit zu erhöhen:- Das Entfernen der Wartezeit vor dem nächsten Versand durch den Hersteller wird möglich
- Kombinieren Sie viele kleine Festplattenvorgänge zu einem großen - so können Sie die gesamte Bandbreite des Festplattenbusses nutzen
Wenn wir dies mit der Situation vergleichen, in der jede Warteschlange in einem eigenen Protokoll gespeichert ist, müsste der Broker so etwas wie die Koordination von Transaktionen zwischen allen Datensätzen bereitstellen.Subtrahieren von Nachrichten aus der Warteschlange
Der Prozess des Lesens von Nachrichten beginnt, wenn der Verbraucher seine Bereitschaft zum Akzeptieren zum Ausdruck bringt, indem er entweder einen MessageListener zum Verarbeiten von Nachrichten beim Eintreffen einrichtet oder die MessageConsumer.receive () -Methode aufruft ( Abbildung 2-5 ).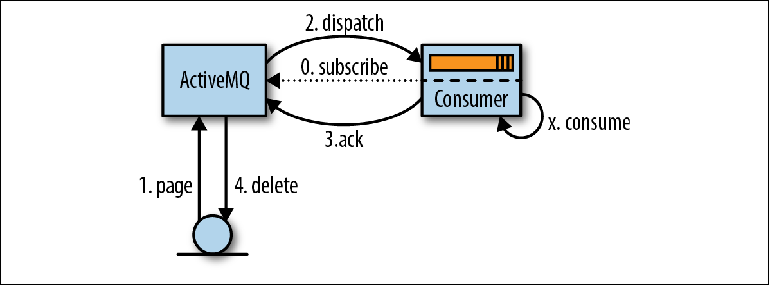 Abbildung 2-5. Lesen von Nachrichten über JMSWenn ActiveMQ einen Verbraucher erkennt, liest es (ActiveMQ) (Seiten) Nachrichten Seite für Seite vom Speicher zum Verteilungsspeicher (1). Anschließend werden diese Nachrichten an den Buchhalter (2) weitergeleitet (versandt), häufig in mehreren Teilen, um den Umfang der Netzwerkinteraktion zu verringern. Der Broker verfolgt, welche Nachrichten an welchen Verbraucher umgeleitet wurden.Vom Verbraucher empfangene Nachrichten werden von der Anwendung nicht sofort verarbeitet, sondern in einem Speicherbereich abgelegt, der als bekannt istVorabrufpuffer (Prefetch - Puffer) . Der Zweck dieses Puffers besteht darin, den Nachrichtenfluss zu optimieren, damit der Broker Nachrichten an den Supervisor senden kann, sobald diese zum Senden verfügbar sind, während der Verbraucher sie nacheinander ordnungsgemäß empfangen kann.Irgendwann nach dem Erreichen des Prefetch-Puffers werden Nachrichten von der Anwendungslogik (X) ausgelesen und eine Bestätigung des Korrekturlesens an den Broker gesendet (3). Zeitordnung zwischen Nachrichtenverarbeitung und Bestätigung ist so konfiguriert , indem JMS - Session - Parameter aufgerufen Quittierungsmodus , die wir später besprechen werden.Sobald der Broker die Bestätigung der Nachrichtenübermittlung akzeptiert, wird sie aus dem Speicher und aus dem Nachrichtenspeicher gelöscht (4). Der Begriff „Löschen“ ist etwas irreführend, da in Wirklichkeit ein Bestätigungsdatensatz in das Protokoll geschrieben wird und der Index im Index zunimmt. Das eigentliche Löschen der Protokolldatei mit der Nachricht wird vom Garbage Collector im Hintergrund-Thread basierend auf diesen Informationen durchgeführt.Das oben beschriebene Verhalten ist eine Vereinfachung, um das Verständnis zu erleichtern. Tatsächlich liest ActiveMQ nicht nur Seite für Seite Daten von der Festplatte, sondern verwendet stattdessen den Cursormechanismus zwischen den empfangenden und umleitenden Teilen des Brokers, um die Interaktion mit dem Repository des Brokers nach Möglichkeit zu minimieren. Die Paginierung ist, wie oben beschrieben, einer der in diesem Mechanismus verwendeten Modi. Cursor können als Cache auf Anwendungsebene angesehen werden, der mit dem Repository des Brokers synchronisiert werden muss. Das verwendete Kohärenzprotokoll ist ein wesentlicher Bestandteil dessen, was den ActiveMQ-Versandmechanismus wesentlich komplexer macht als den im nächsten Kapitel beschriebenen Kafka-Mechanismus.
Abbildung 2-5. Lesen von Nachrichten über JMSWenn ActiveMQ einen Verbraucher erkennt, liest es (ActiveMQ) (Seiten) Nachrichten Seite für Seite vom Speicher zum Verteilungsspeicher (1). Anschließend werden diese Nachrichten an den Buchhalter (2) weitergeleitet (versandt), häufig in mehreren Teilen, um den Umfang der Netzwerkinteraktion zu verringern. Der Broker verfolgt, welche Nachrichten an welchen Verbraucher umgeleitet wurden.Vom Verbraucher empfangene Nachrichten werden von der Anwendung nicht sofort verarbeitet, sondern in einem Speicherbereich abgelegt, der als bekannt istVorabrufpuffer (Prefetch - Puffer) . Der Zweck dieses Puffers besteht darin, den Nachrichtenfluss zu optimieren, damit der Broker Nachrichten an den Supervisor senden kann, sobald diese zum Senden verfügbar sind, während der Verbraucher sie nacheinander ordnungsgemäß empfangen kann.Irgendwann nach dem Erreichen des Prefetch-Puffers werden Nachrichten von der Anwendungslogik (X) ausgelesen und eine Bestätigung des Korrekturlesens an den Broker gesendet (3). Zeitordnung zwischen Nachrichtenverarbeitung und Bestätigung ist so konfiguriert , indem JMS - Session - Parameter aufgerufen Quittierungsmodus , die wir später besprechen werden.Sobald der Broker die Bestätigung der Nachrichtenübermittlung akzeptiert, wird sie aus dem Speicher und aus dem Nachrichtenspeicher gelöscht (4). Der Begriff „Löschen“ ist etwas irreführend, da in Wirklichkeit ein Bestätigungsdatensatz in das Protokoll geschrieben wird und der Index im Index zunimmt. Das eigentliche Löschen der Protokolldatei mit der Nachricht wird vom Garbage Collector im Hintergrund-Thread basierend auf diesen Informationen durchgeführt.Das oben beschriebene Verhalten ist eine Vereinfachung, um das Verständnis zu erleichtern. Tatsächlich liest ActiveMQ nicht nur Seite für Seite Daten von der Festplatte, sondern verwendet stattdessen den Cursormechanismus zwischen den empfangenden und umleitenden Teilen des Brokers, um die Interaktion mit dem Repository des Brokers nach Möglichkeit zu minimieren. Die Paginierung ist, wie oben beschrieben, einer der in diesem Mechanismus verwendeten Modi. Cursor können als Cache auf Anwendungsebene angesehen werden, der mit dem Repository des Brokers synchronisiert werden muss. Das verwendete Kohärenzprotokoll ist ein wesentlicher Bestandteil dessen, was den ActiveMQ-Versandmechanismus wesentlich komplexer macht als den im nächsten Kapitel beschriebenen Kafka-Mechanismus.Bestätigungs- und Transaktionsmodi
Verschiedene Bestätigungsmodi, die die Reihenfolge zwischen Korrekturlesen und Bestätigung bestimmen, haben einen erheblichen Einfluss darauf, welche Logik im Client implementiert werden muss. Sie lauten wie folgt:AUTO_ACKNOWLEDGEDies ist der am häufigsten verwendete Modus, möglicherweise weil er das Wort AUTO enthält. Dieser Modus zwingt die Clientbibliothek, die Nachricht gleichzeitig mit dem Lesen der Nachricht durch den Aufruf von receive () zu bestätigen. Dies bedeutet, dass die Nachricht verloren geht, wenn die von der Nachricht initiierte Geschäftslogik eine Ausnahme auslöst, da sie bereits auf dem Broker gelöscht wurde. Wenn die Nachricht durch den Listener gelesen wird, wird die Nachricht erst bestätigt, nachdem der Listener die Arbeit erfolgreich abgeschlossen hat.CLIENT_ACKNOWLEDGEEine Bestätigung wird nur gesendet, wenn der Consumer-Code die Message.acknowledge () -Methode explizit aufruft.DUPS_OK_ACKNOWLEDGEHier werden Bestätigungen im Consumer gepuffert, bevor sie gleichzeitig gesendet werden, um den Netzwerkverkehr zu reduzieren. Wenn das Client-System jedoch heruntergefahren wird, gehen Bestätigungen verloren und Nachrichten werden erneut gesendet und ein zweites Mal verarbeitet. Daher sollte der Code die Wahrscheinlichkeit doppelter Nachrichten berücksichtigen.Bestätigungsmodi werden durch Transaktionslesewerkzeuge ergänzt. Beim Erstellen einer Sitzung kann diese als transaktional markiert werden. Dies bedeutet, dass der Programmierer Session.commit () oder Session.rollback () explizit aufrufen muss. Auf der Verbraucherseite erweitern Transaktionen den Bereich der Interaktionen, die Code als eine atomare Operation ausführen kann. Sie können beispielsweise mehrere Nachrichten als Ganzes lesen und verarbeiten oder eine Nachricht von einer Warteschlange subtrahieren und dann mit demselben Sitzungsobjekt an eine andere senden.Versand und mehrere Verbraucher
Bisher haben wir das Verhalten beim Lesen von Nachrichten mit einem einzelnen Verbraucher diskutiert. Schauen wir uns nun an, wie dieses Modell auf mehrere Verbraucher anwendbar ist.Wenn mehrere Konsumenten die Warteschlange abonnieren, sendet der Broker standardmäßig Round-Robin-Nachrichten an diejenigen Konsumenten, die einen Platz in den Prefetch-Puffern haben. Nachrichten werden in der Reihenfolge gesendet, in der sie in der Warteschlange angekommen sind - dies ist die einzige gewährte FIFO-Garantie (first in, first out; first in, first out).Wenn der Verbraucher plötzlich herunterfährt, werden alle an ihn gesendeten, aber noch nicht bestätigten Nachrichten erneut an einen anderen verfügbaren Kunden gesendet.Dies wirft eine wichtige Frage auf: Selbst wenn Verbrauchertransaktionen verwendet werden, kann nicht garantiert werden, dass die Nachricht nicht mehrmals verarbeitet wird.Berücksichtigen Sie die folgende Verarbeitungslogik im Consumer:- Die Nachricht wird von der Warteschlange abgezogen. Die Transaktion beginnt.
- Ein Webdienst wird mit dem Inhalt der Nachricht aufgerufen.
- Die Transaktion wird festgeschrieben. Eine Bestätigung wird an den Broker gesendet.
Wenn der Client zwischen den Schritten 2 und 3 abgeschlossen ist, hat das Korrekturlesen der Nachricht bereits ein anderes System durch Aufrufen des Webdienstes beeinflusst. Webdienstaufrufe sind HTTP-Anforderungen und daher keine Transaktionsanforderungen.
Dieses Verhalten gilt für alle Warteschlangensysteme. Selbst wenn es sich um Transaktionssysteme handelt, können sie nicht garantieren, dass bei der Verarbeitung von Nachrichten in ihnen keine Nebenwirkungen auftreten. Nachdem wir die Verarbeitung von Nachrichten im Detail untersucht haben, können wir zuversichtlich sagen, dass:
Es gibt keine einmalige Nachrichtenübermittlung .Warteschlangen bieten eine Garantie für die Zustellung
mindestens einmal, und vertrauliche Teile des Codes sollten immer die Möglichkeit in Betracht ziehen, wiederholte Nachrichten zu empfangen. Wir werden später diskutieren, wie ein Messaging-Client das idempotente Lesen verwenden kann, um bereits angezeigte Nachrichten zu verfolgen und Duplikate zu vermeiden.
Nachrichtensortierung
Für eine Reihe von Nachrichten, die in der Reihenfolge [A, B, C, D] ankommen, und für zwei Verbraucher C1 und C2 ist die normale Verteilung der Nachrichten wie folgt:
C1: [A, C]
C2: [B, D]Da der Broker den Betrieb von Leseprozessen nicht steuert und die Verarbeitungsreihenfolge parallel ist, ist sie nicht deterministisch. Wenn C1 langsamer als C2 ist, kann der anfängliche Satz von Nachrichten als [B, D, A, C] verarbeitet werden.
Dieses Verhalten kann Anfänger überraschen, die erwarten, dass Nachrichten in der richtigen Reihenfolge verarbeitet werden, und auf dieser Grundlage ihre eigene Messaging-Anwendung entwickeln. Die Anforderung, dass von demselben Absender gesendete Nachrichten in der Reihenfolge zueinander verarbeitet werden müssen, was auch als
kausale Reihenfolge bezeichnet wird , ist weit verbreitet.
Nehmen Sie als Beispiel den folgenden Anwendungsfall aus Online-Wetten:
- Das Benutzerkonto ist konfiguriert.
- Geld wird dem Konto gutgeschrieben.
- Es wird eine Wette abgeschlossen, die Geld vom Konto abhebt.
Hier ist es sinnvoll, dass die Nachrichten in der Reihenfolge verarbeitet werden, in der sie gesendet wurden, damit der allgemeine Status des Kontos berücksichtigt wird. Seltsame Dinge können passieren, wenn das System versucht, Geld von einem Konto ohne Guthaben zu entfernen. Es gibt natürlich Möglichkeiten, dies zu umgehen.
Das
exklusive Kundenmodell umfasst das Senden aller Nachrichten aus der Warteschlange an einen Kunden. Wenn Sie bei diesem Ansatz mehrere Instanzen von Anwendungen oder Threads mit der Warteschlange verbinden, werden diese mit einem speziellen Empfängerparameter signiert:
my.queue?consumer.exclusive=true . Wenn Sie einen Monopolverbraucher verbinden, erhält er alle Nachrichten. Wenn der zweite Verbraucher verbunden ist, erhält er keine Nachrichten, bis der erste die Verbindung trennt. Dieser zweite Verbraucher ist eigentlich eine heiße Reserve, während der erste Verbraucher Nachrichten genau in der Reihenfolge empfängt, in der sie im Journal aufgezeichnet wurden - in einer kausalen Reihenfolge.
Der Nachteil dieses Ansatzes besteht darin, dass die Nachrichtenverarbeitung zwar konsistent ist, jedoch einen Leistungsengpass darstellt, da alle Nachrichten von einem einzelnen Verbraucher verarbeitet werden müssen.
Um diesen Anwendungsfall intelligenter zu verstehen, müssen Sie das Problem überdenken. Müssen alle Nachrichten in der richtigen Reihenfolge verarbeitet werden? Bei der oben beschriebenen Verarbeitung von Geboten müssen nur Nachrichten, die sich auf ein Konto beziehen, nacheinander verarbeitet werden. ActiveMQ bietet einen Mechanismus zur Bewältigung dieser Situation, der als
JMS-Nachrichtengruppen bezeichnet wird .
Nachrichtengruppen sind eine Art Partitionierungsmechanismus, mit dem Produzenten Nachrichten in Gruppen verteilen können, die nacheinander nach einem Geschäftsschlüssel verarbeitet werden. Dieser Geschäftsschlüssel wird in einer Nachrichteneigenschaft namens
JMSXGroupID .
Der natürliche Schlüssel bei der Bearbeitung von Geboten ist die Kontokennung.
Um zu veranschaulichen, wie das Senden funktioniert, betrachten Sie eine Reihe von Nachrichten, die in der folgenden Reihenfolge ankommen:
[(A, Group1), (B, Group1), (C, Group2), (D, Group3), (E, Group2)]
Wenn eine Nachricht vom Dispatching-Mechanismus in ActiveMQ verarbeitet wird und eine
JMSXGroupID nicht vorhandene
JMSXGroupID , wird dieser Schlüssel dem Verbraucher zyklisch zugewiesen. Von nun an werden alle Nachrichten mit diesem Schlüssel an diesen Buchhalter gesendet.
Hier werden die Gruppen wie folgt zwischen zwei Verbrauchern aufgeteilt: C1 und C2:
C1: [Group1, Group3] C2: [Group2]
Nachrichten werden wie folgt umgeleitet und verarbeitet:
C2: [B, D] C2: [(C, Group2), (E, Group2)]
Wenn der Verbraucher ausfällt, werden alle ihm zugewiesenen Gruppen auf den Rest der Verbraucher verteilt und alle nicht bestätigten Nachrichten werden erneut umgeleitet. Obwohl wir garantieren können, dass alle zugehörigen Nachrichten in der richtigen Reihenfolge verarbeitet werden, können wir daher nicht behaupten, dass sie von demselben Verbraucher verarbeitet werden.
Hochverfügbarkeit
ActiveMQ bietet Hochverfügbarkeit mit einem Master-Slave, der auf gemeinsam genutztem Speicher basiert. In diesem Schema werden zwei oder mehr Broker (obwohl normalerweise zwei) auf separaten Servern konfiguriert und ihre Nachrichten werden in einem Nachrichtenspeicher an einem externen Speicherort gespeichert. Ein Nachrichtenspeicher kann nicht von mehreren Instanzen eines Brokers gleichzeitig verwendet werden. Daher besteht seine (Speicher-) Sekundärfunktion darin, als Blockierungsmechanismus zu fungieren, um zu bestimmen, welcher Broker exklusiven Zugriff erhält (
Abbildung 2-6 ).
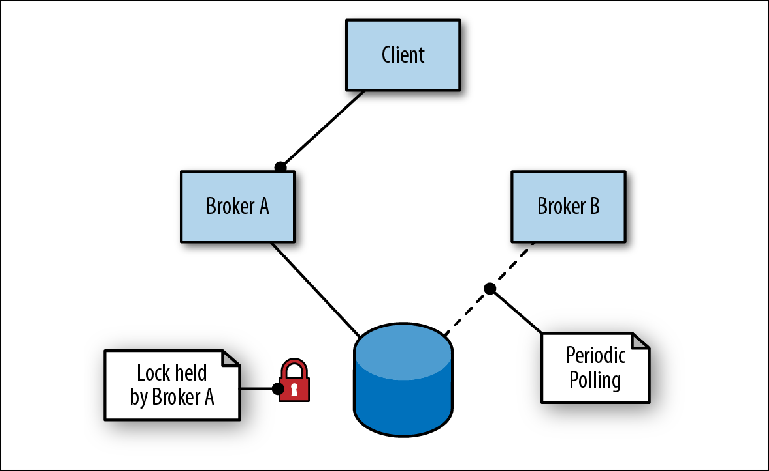 Abbildung 2-6. Broker A ist der Lead, Broker B ist als Slave in Bereitschaft
Abbildung 2-6. Broker A ist der Lead, Broker B ist als Slave in BereitschaftUm eine Verbindung zum Repository herzustellen, übernimmt der erste Broker (Broker A) die Rolle des Leiters und öffnet seine Ports für den Nachrichtenverkehr. Wenn der zweite Broker (Broker B) eine Verbindung zum Repository herstellt, versucht er, eine Sperre zu erhalten, und stoppt kurz, da er keinen Erfolg hat, bevor er erneut versucht, eine Sperre zu erhalten. Dies wird als getriebene Eindämmung bezeichnet.
Gleichzeitig wechselt der Client die Adressen der beiden Broker, um eine Verbindung zum eingehenden Port herzustellen, der als Transportconnector bezeichnet wird. Sobald der Hauptbroker verfügbar ist, stellt der Client eine Verbindung zu seinem Port her und kann Nachrichten senden und lesen.
Wenn Broker A als Leader aufgrund eines Prozessfehlers ausfällt (
Abbildung 2-7 ), treten die folgenden Ereignisse auf:
- Der Client trennt die Verbindung und versucht sofort, die Verbindung wiederherzustellen, wobei die Adressen zweier Broker abgewechselt werden.
- Die Sperre in der Nachricht wird aufgehoben. Der Zeitpunkt hierfür hängt von der Speicherimplementierung ab.
- Broker B, der sich im Slave-Modus befand und regelmäßig versuchte, eine Sperre zu erhalten, ist schließlich erfolgreich und übernimmt die Rolle des Masters, indem er seine Ports öffnet.
- Der Kunde stellt eine Verbindung zu Broker B her und setzt seine Arbeit fort.
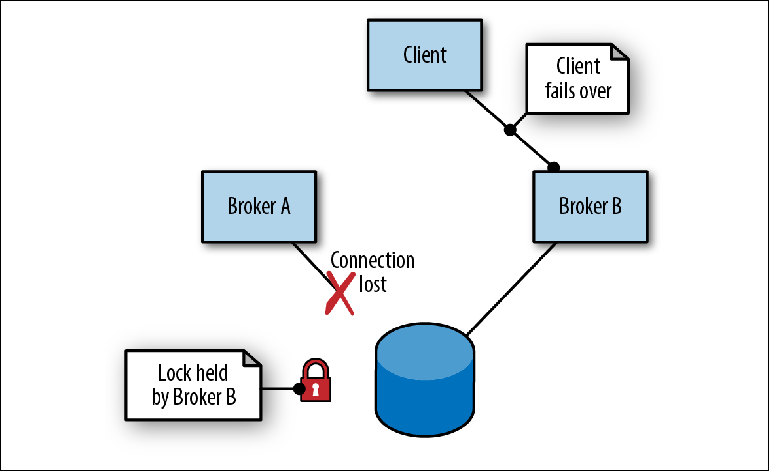 Abbildung 2-7. Broker A wird beendet, indem die Verbindung zum Repository unterbrochen wird. Broker B übernimmt die Führung
Abbildung 2-7. Broker A wird beendet, indem die Verbindung zum Repository unterbrochen wird. Broker B übernimmt die FührungEs ist nicht garantiert, dass die Wechsellogik zwischen mehreren Brokeradressen in die Clientbibliothek integriert ist, wie dies bei JMS / NMS / CMS-Implementierungen der Fall ist. Wenn die Bibliothek nur die Wiederverbindung mit einer einzelnen Adresse ermöglicht, müssen Sie möglicherweise einige Broker hinter einem Load Balancer platzieren, der ebenfalls hoch verfügbar sein sollte.
Der Hauptnachteil dieses Ansatzes besteht darin, dass zur Vereinfachung der Arbeit eines logischen Brokers mehrere physische Server erforderlich sind. In diesem Fall ist einer der beiden Server des Brokers inaktiv und wartet auf die Trennung seines Partners, bevor er seine Arbeit aufnehmen kann.
Dieser Ansatz hat auch die zusätzliche Komplexität, dass der verwendete Broker-Speicher, ob es sich um ein gemeinsam genutztes Netzwerkdateisystem oder eine Datenbank handelt, auch in hohem Maße zugänglich sein muss. Dies führt zu zusätzlichen Kosten für die Ausrüstung und Verwaltung der Brokereinstellungen. In diesem Szenario ist es verlockend, vorhandene Hochverfügbarkeits-Repositorys, die von anderen Teilen der Infrastruktur verwendet werden, z. B. einer Datenbank, wiederzuverwenden. Dies ist jedoch ein Fehler.
Es ist wichtig zu bedenken, dass die Festplatte der Hauptbegrenzer für die Gesamtleistung des Brokers ist. Wenn die Festplatte selbst gleichzeitig von einem anderen Prozess als dem Nachrichtenbroker verwendet wird, verlangsamt die Interaktion dieses Prozesses mit der Festplatte wahrscheinlich die Aufzeichnung vom Broker und damit die Geschwindigkeit, mit der Nachrichten das System durchlaufen können. Solche Verlangsamungen sind schwer zu diagnostizieren und können nur umgangen werden, indem die beiden Prozesse in unterschiedliche Speichervolumes aufgeteilt werden.
Um den stabilen Betrieb des Brokers sicherzustellen, ist ein dedizierter und exklusiver Speicher erforderlich.
Vertikale und horizontale Skalierung
Zu einem bestimmten Zeitpunkt im Projektverlauf kann es zu einer Leistungsbeschränkung des Nachrichtenbrokers kommen. Diese Einschränkungen beziehen sich normalerweise auf Ressourcen, insbesondere ActiveMQ-Interaktionen mit dem verwendeten Speicher. Diese Probleme treten normalerweise aufgrund von Nachrichtenvolumen- oder Bandbreitenkonflikten zwischen Empfängern auf, beispielsweise wenn in Spitzenzeiten eine Warteschlange den Broker überläuft.
Es gibt verschiedene Möglichkeiten, um mehr Leistung aus der Infrastruktur des Brokers zu ziehen:
- Verwenden Sie keine Persistenz, wenn dies nicht erforderlich ist. Einige Verwendungsszenarien ermöglichen den Verlust von Nachrichten während eines Absturzes, insbesondere wenn ein System regelmäßig oder bei Bedarf einen anderen vollständigen Snapshot-Status über die Warteschlange an das andere System sendet.
- Führen Sie den Broker auf schnelleren Laufwerken aus. Unter realen Bedingungen wurden signifikante Unterschiede in der Aufzeichnungsbandbreite zwischen Standard-Festplatte und speicherbasierten Alternativen festgestellt.
- Nutzen Sie die Festplattengrößen optimal. Wie in dem oben beschriebenen Interaktionsmodell für die Plattenpipeline gezeigt, kann ein höherer Durchsatz erzielt werden, indem Transaktionen zum Senden von Gruppen von Nachrichten verwendet werden, wodurch mehrere Schreibvorgänge zu einem größeren kombiniert werden.
- Verwenden Sie die Verkehrspartitionierung. Sie können einen höheren Durchsatz erzielen, indem Sie Ziele auf eine der folgenden Arten aufteilen:
- Mehrere Datenträger innerhalb eines Brokers, z. B. mithilfe des mKahaDB-Persistenzadapters für mehrere Verzeichnisse, von denen jedes auf einem separaten Datenträger bereitgestellt ist.
- Mehrere Broker, und die Partitionierung des Datenverkehrs wird manuell von der Client-Anwendung durchgeführt. ActiveMQ bietet zu diesem Zweck keine nativen Funktionen.
Eine der häufigsten Ursachen für Broker-Leistungsprobleme ist einfach der Versuch, mit einer Instanz zu viel zu tun. Dies tritt in der Regel in Situationen auf, in denen der Broker naiv auf mehrere Anwendungen aufgeteilt ist, ohne die vorhandene Belastung des Brokers zu berücksichtigen oder die Volumes zu verstehen. Im Laufe der Zeit wird ein Broker immer mehr geladen, bis er sich nicht mehr angemessen verhält.
Das Problem tritt häufig während der Systementwurfsphase auf, wenn der Systemarchitekt ein solches Schema wie in
Abbildung 2-8 vorschlagen kann.
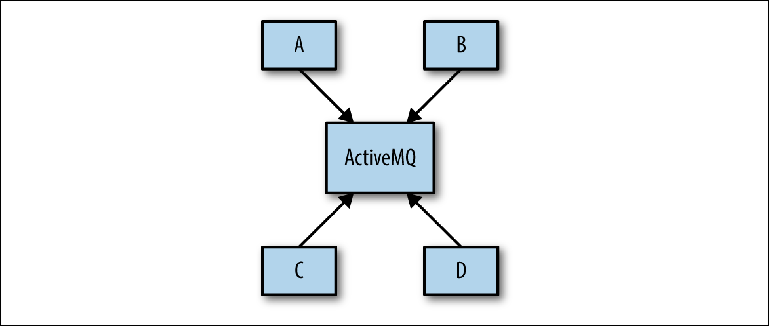 Abbildung 2-8. Konzeptionelle Ansicht der Messaging-Infrastruktur
Abbildung 2-8. Konzeptionelle Ansicht der Messaging-InfrastrukturZiel ist es, dass mehrere Anwendungen über ActiveMQ asynchron miteinander kommunizieren. Das Ziel wird nicht mehr angegeben und dann bestimmt das Schema die Basis der realen Brokerkonfiguration. Dieser Ansatz wird als Universal Data Pipeline bezeichnet.
Der grundlegende Schritt der Analyse zwischen dem oben genannten Konzeptentwurf und der physischen Umsetzung wird nicht berücksichtigt. Bevor Sie mit der Erstellung einer bestimmten Konfiguration fortfahren, müssen Sie eine Analyse durchführen, die dann zur Begründung des physischen Projekts verwendet wird. Der erste Schritt in diesem Prozess besteht darin, zu bestimmen, welche Systeme miteinander interagieren - ein ziemlich einfaches Diagramm mit Rechtecken und Pfeilen (
Abbildung 2-9 ).
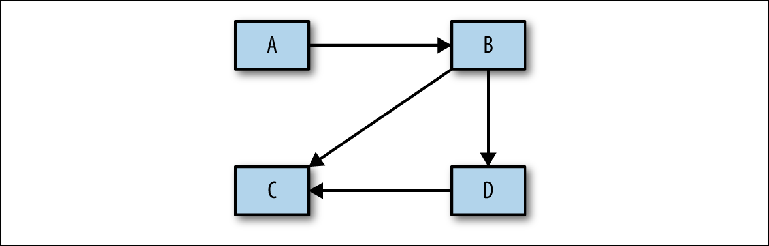 Abbildung 2-9. Skizzieren Sie Nachrichtenflüsse zwischen Systemen
Abbildung 2-9. Skizzieren Sie Nachrichtenflüsse zwischen SystemenNach der Genehmigung können Sie die Details aufrufen, um die folgenden Fragen zu beantworten:
- Wie viele Warteschlangen und Themen werden verwendet?
- Welche Nachrichtenmengen werden für jede von ihnen erwartet?
- Wie groß sind die Nachrichten in jedem Empfänger? Große Nachrichten können Probleme im Paging-Prozess verursachen, die dazu führen, dass Speichergrenzen überschritten werden und der Broker blockiert wird.
- Werden die Nachrichtenflüsse den ganzen Tag über gleichmäßig sein oder wird es aufgrund von Stapeljobs Spitzen geben? Große Stapel in einer weniger genutzten Warteschlange können zeitnahe Schreibvorgänge für Hochleistungsziele beeinträchtigen.
- Befinden sich die Systeme im selben Rechenzentrum oder in unterschiedlichen? An der Fernkommunikation sind Netzwerkbroker beteiligt.
Die Idee ist, separate Messaging-Szenarien zu definieren, die von einzelnen Brokern kombiniert oder aufgeteilt werden können (
Abbildung 2-10 ).
Nach einer solchen Aufschlüsselung können Nutzungsszenarien simuliert werden, indem sie mithilfe des ActiveMQ-Leistungsmoduls miteinander kombiniert werden, um Probleme zu identifizieren.
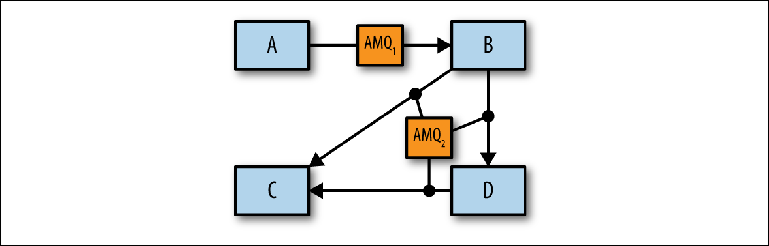 Abbildung 2-10. Identifizierung einzelner Makler
Abbildung 2-10. Identifizierung einzelner MaklerNachdem Sie die entsprechende Anzahl logischer Broker ermittelt haben, können Sie mithilfe hochzugänglicher Konfigurationen und Brokernetzwerke festlegen, wie diese auf physischer Ebene implementiert werden sollen.
Zusammenfassung
In diesem Kapitel haben wir den Mechanismus untersucht, mit dem ActiveMQ Nachrichten empfängt und verteilt. Wir haben Funktionen besprochen, die von dieser Architektur unterstützt werden, einschließlich des Sticky-Load-Balancing verwandter Nachrichten und Transaktionen. Gleichzeitig haben wir eine Reihe von Konzepten eingeführt, die allen Nachrichtensystemen gemeinsam sind, einschließlich Kommunikationsprotokollen und Magazinen. Wir haben auch detailliert untersucht, welche Schwierigkeiten beim Schreiben auf die Festplatte auftreten und wie Broker Techniken wie das Schreiben von Paketen verwenden können, um die Leistung zu verbessern. Schließlich haben wir untersucht, wie ActiveMQ hoch verfügbar gemacht werden kann und wie es über die Fähigkeiten eines einzelnen Brokers hinaus skaliert werden kann.
Im nächsten Kapitel werden wir uns mit Apache Kafka befassen und wie seine Architektur die Beziehung zwischen Clients und Brokern neu definiert, um eine unglaublich robuste Nachrichtenpipeline mit einer Bandbreite bereitzustellen, die um ein Vielfaches größer ist als die eines normalen Nachrichtenbrokers. Wir werden die Funktionalität diskutieren, die zur Erreichung dieses Ziels verwendet wird, und kurz die Architektur von Anwendungen betrachten, die diese Funktionalität bereitstellen.
Nächster Teil:
Grundlegendes zu Message Brokers. Erlernen der Mechanismen des Messaging über ActiveMQ und Kafka. Kapitel 3. KafkaÜbersetzung abgeschlossen: tele.gg/middle_java