Nachdem ein Team von Geophysikern Erdbeben im Labor erfolgreich vorhergesagt hatte, wandte es den Algorithmus des maschinellen Lernens auf Erdbeben an der nordwestlichen Pazifikküste an
 Die Überreste eines 2000 Jahre alten Nadelwaldes am Nescovin Beach in Oregon - einer von Dutzenden von „Geisterwäldern“ an den Küsten von Oregon und Washington. Es wird angenommen, dass ein großes Erdbeben einst die Subduktionszone von Cascadia erschütterte und Stümpfe unter den Trümmern des Tsunamis begraben wurden
Die Überreste eines 2000 Jahre alten Nadelwaldes am Nescovin Beach in Oregon - einer von Dutzenden von „Geisterwäldern“ an den Küsten von Oregon und Washington. Es wird angenommen, dass ein großes Erdbeben einst die Subduktionszone von Cascadia erschütterte und Stümpfe unter den Trümmern des Tsunamis begraben wurden
Im Mai letzten Jahres, nach einem 13-monatigen Nickerchen, geriet das Land unter Puget Bay, Washington, in Bewegung. Das Erdbeben begann in einer Tiefe von mehr als 30 km unter den Olympischen Bergen und bewegte sich innerhalb weniger Wochen nach Nordwesten, um die kanadische Insel Vancouver zu erreichen. Dann drehte es kurz seinen Kurs, kroch die US-Grenze entlang zurück und verstummte dann. Ein monatliches Erdbeben setzte genügend Energie frei, so dass seine Stärke auf 6 geschätzt werden konnte. Am Ende des Erdbebens rückte das südliche Ende von Vancouver Island einen zusätzlichen Zentimeter in den Pazifik vor.
Da das Erdbeben räumlich und zeitlich so verschwommen war, spürte es höchstwahrscheinlich niemand. Solche gespenstischen Erdbeben, die tiefer unter der Erde auftreten als gewöhnliche schnelle Erdbeben, werden als „langsame Ausrutscher“ bezeichnet. Ungefähr einmal im Jahr treten sie im pazifischen Nordwesten auf, entlang einer Verwerfung, entlang der die
Juan de Fuca-Platte langsam unter den nördlichen Teil des westlichen Randes der
nordamerikanischen Platte kriecht. Seit 2003 wurden in einem breiten Netz seismologischer Stationen in der Region mehr als ein Dutzend langsame Ausrutscher registriert. In den letzten anderthalb Jahren standen diese Ereignisse im Mittelpunkt des Erdbebenvorhersageprojekts unter der Leitung des Geophysikers
Paul Johnson .
Johnsons Team ist eine von mehreren Gruppen von Wissenschaftlern, die maschinelles Lernen einsetzen, um die Geheimnisse der Erdbebenphysik aufzudecken und die Anzeichen eines aufkommenden Erdbebens zu isolieren. Vor zwei Jahren haben Johnson und Kollegen Erdbeben in einem Labormodell mithilfe eines Mustersuchalgorithmus
erfolgreich vorhergesagt , der denjenigen ähnelt, die bei den jüngsten Durchbrüchen bei der Bild- und Spracherkennung und anderen Anwendungen künstlicher Intelligenz verwendet wurden. Seitdem wurde diese Leistung
von Wissenschaftlern aus Europa
wiederholt .
Und jetzt berichten Johnson und sein Team in einem
Artikel, der diesen September auf der Preprint-Website arxiv.org veröffentlicht wurde, dass sie ihren Algorithmus auf langsame Erdbeben im pazifischen Nordwesten testen. Die Arbeit muss noch von unabhängigen Experten getestet werden, aber sie berichten bereits, dass die Ergebnisse vielversprechend waren. Johnson argumentiert, dass der Algorithmus den Beginn eines langsamen Erdbebens "in wenigen Tagen - und möglicherweise früher" vorhersagen kann.
"Dies ist eine sehr interessante Entwicklung", sagte
Maarten de Hoop , ein Seismologe an der Rice University, der an dieser Arbeit nicht beteiligt ist. "Zum ersten Mal ist der Moment gekommen, in dem wir Fortschritte bei der Vorhersage von Erdbeben erzielt haben".
Mostafa Mousavi, Geophysiker an der Stanford University, bezeichnete die neuen Ergebnisse als "interessant und motivierend". Er, de Hoop und andere Experten auf diesem Gebiet betonen, dass maschinelles Lernen noch einen langen Weg vor sich hat, bevor es katastrophale Erdbeben vorhersagt - und dass einige Hindernisse auf diesem Weg sehr schwierig und möglicherweise unüberwindbar sein können. Dennoch könnte sich maschinelles Lernen als die beste Chance für Wissenschaftler auf dem Gebiet herausstellen, auf dem sie seit Jahrzehnten stagnieren und kaum Hoffnungsschimmer gesehen haben.
Marmeladen und Ausrutscher
Der verstorbene Seismologe
Charles Richter , der die Bewertungsskala für die Erdbebenstärke benannte, stellte 1977 fest, dass die Erdbebenvorhersage „ein ausgezeichneter Boden für Liebhaber, Spinner und Betrüger sein könnte, die Werbung suchen“. Heute werden Ihnen viele Seismologen bestätigen, dass sie eine ganze Reihe von Vertretern aller drei Typen getroffen haben.
Es kam jedoch vor, dass angesehene Wissenschaftler Ideen herausgaben, die im Nachhinein weit von der Wahrheit entfernt und manchmal einfach nur verrückt erscheinen. Ein Geophysiker an der Universität von Athen, Panagiotis Varotsos, erklärte, er könne drohende Erdbeben durch Messung "seismischer elektrischer Signale" erkennen. Brian Brady, ein Physiker des US-Minenministeriums in den frühen 1980er Jahren, warnte mehrmals falsch vor den bevorstehenden Erdbeben in Peru und stützte seine Ergebnisse auf unbestätigte Ergebnisse, dass das Knacken von Steinen in Minen ein Zeichen für bevorstehende Erdbeben war.
Paul Johnson ist sich dieser kontroversen Geschichte bewusst. Er weiß, dass es an vielen Orten sogar unanständig ist, über "Erdbebenvorhersagen" zu sprechen. Er weiß, dass 2012 sechs italienische Wissenschaftler wegen unbeabsichtigter Tötung von 29 Menschen verurteilt wurden, die die Wahrscheinlichkeit eines Erdbebens in der italienischen Stadt L'Aquila einige Tage vor der
fast vollständigen Zerstörung der
Region durch ein Erdbeben der Stärke 6,3 heruntergespielt hatten (dann wurde das Berufungsgericht aufgehoben dieses Urteil). Er kennt prominente Seismologen, die
überzeugend festgestellt haben
, dass "Erdbeben nicht vorhergesagt werden können".
Johnson weiß jedoch auch, dass Erdbeben physikalische Prozesse sind, die sich nicht wesentlich vom Zusammenbruch eines sterbenden Sterns oder einer Änderung der Windrichtung unterscheiden. Und obwohl er betont, dass das Hauptziel seiner Forschung darin besteht, die Physik der Fehler besser zu verstehen, lehnt er die Aufgabe der Vorhersagen nicht ab.
 Paul Johnson, ein Seismologe vom Los Alamos National Laboratory mit einer Probe aus Acrylkunststoff in den Händen - eines der Materialien, mit denen das Team Erdbeben im Labor simuliert
Paul Johnson, ein Seismologe vom Los Alamos National Laboratory mit einer Probe aus Acrylkunststoff in den Händen - eines der Materialien, mit denen das Team Erdbeben im Labor simuliertVor mehr als einem Jahrzehnt begann Johnson mit der Untersuchung von „Laborerdbeben“, die mit Blöcken simuliert werden, die entlang dünner Schichten aus körnigem Material gleiten. Diese Blöcke gleiten wie tektonische Platten nicht reibungslos, sondern mit Schnappschüssen und Anschlägen. Manchmal frieren sie einige Sekunden lang ein, gehalten durch Reibung, und dann reicht die zunehmende Kraft aus, so dass sie plötzlich weiter zu rutschen beginnen. Dieser Schlupf - die Laborversion des Erdbebens - löst Stress, wonach der Zyklus zerlumpter Bewegungen von neuem beginnt.
Als Johnson und Kollegen das akustische Signal aufzeichneten, das während dieser intermittierenden Bewegung auftritt, bemerkten sie scharfe Spitzen, die vor jedem Schlupf auftreten. Diese Ereignisse vor der Bewegung wurden zum Laboräquivalent seismischer Wellen, die Schocks erzeugen, die Erdbeben vorausgehen. Gerade als Seismologen erfolglos versuchten, vorläufige Schocks in eine Vorhersage des Zeitpunkts des Ausbruchs des Haupterdbebens umzuwandeln, konnten Johnson und Kollegen nicht herausfinden, wie diese Vorereignisse in zuverlässige Vorhersagen von Laborerdbeben umgewandelt werden können. "Wir sind in einer Sackgasse", erinnert sich Johnson. "Ich habe keinen Weg gesehen, weiterzumachen."
Bei einem Treffen in Los Alamos vor einigen Jahren erklärte Johnson einer Gruppe von Theoretikern dieses Dilemma. Sie schlugen vor, die Daten mithilfe von Algorithmen für maschinelles Lernen erneut zu analysieren. Dieser Ansatz war zu diesem Zeitpunkt bereits für seine Fähigkeit bekannt, Muster in Audiodaten gut zu erkennen.
Wissenschaftler haben gemeinsam einen Plan entwickelt. Sie beschlossen, während der Experimente fünf Minuten Audio aufzunehmen - was etwa 20 Zyklen des Rutschens und Feststeckens beinhaltete - und sie in viele kleine Segmente zu schneiden. Für jedes Segment berechneten die Forscher mehr als 80 statistische Merkmale, einschließlich des Durchschnittssignals, Abweichungen vom Durchschnitt und Informationen darüber, ob der Ton vor der Verschiebung in diesem Segment enthalten ist. Als die Forscher die Daten rückwirkend analysierten, wussten sie, wie viel Zeit zwischen den einzelnen Segmenten mit Schall und dem anschließenden Druck im Labor verging.
Mit diesen Daten für das Training ausgestattet, verwendeten sie einen Algorithmus für maschinelles Lernen namens "
Random Forest ", um systematisch nach Kombinationen von Merkmalen zu suchen, die eindeutig mit der verbleibenden Zeit vor der Schicht zusammenhängen. Nach mehreren Minuten experimenteller Daten könnte der Algorithmus beginnen, die Scherzeit basierend auf akustischen Merkmalen vorherzusagen.
Johnson und Kollegen haben den Zufallswald-Algorithmus gewählt, um die verbleibende Zeit bis zu einer neuen Verschiebung vorherzusagen, insbesondere weil der Zufallswald (im Vergleich zu neuronalen Netzen und anderen gängigen Algorithmen für maschinelles Lernen) relativ einfach zu interpretieren ist. Der Algorithmus arbeitet im Wesentlichen als Entscheidungsbaum, in dem jeder Zweig einen Datensatz basierend auf einem statistischen Merkmal gemeinsam nutzt. Daher speichert der Baum die Aufzeichnungen darüber, welche Zeichen der Algorithmus für Vorhersagen verwendet hat - und die relative Bedeutung jedes der Zeichen, die dem Algorithmus geholfen haben, zu einer bestimmten Vorhersage zu gelangen.
 Polarisierte Linsen zeigen eine Spannungsakkumulation, bevor sich das tektonische Plattenmodell entlang der Verwerfungslinie seitwärts bewegt.
Polarisierte Linsen zeigen eine Spannungsakkumulation, bevor sich das tektonische Plattenmodell entlang der Verwerfungslinie seitwärts bewegt.Als Forscher aus Los Alamos die Details ihres Algorithmus untersuchten, waren sie überrascht. Der Algorithmus stützte sich größtenteils auf ein statistisches Merkmal, das nicht mit Ereignissen in Verbindung gebracht wurde, die unmittelbar vor dem Erdbeben im Labor auftraten. Es ist mehr
Streuung - ein Maß für die Abweichung des Signals vom Durchschnitt - darüber hinaus über den gesamten Brems- und Gleitzyklus verteilt und nicht in den Momenten unmittelbar vor der Verschiebung konzentriert. Die Dispersion begann mit kleinen Werten und sammelte sich dann allmählich während der Annäherung an die Verschiebung an, wahrscheinlich weil die Körner zwischen den Blöcken mit zunehmender akkumulierter Spannung immer mehr miteinander kollidierten. Da der Algorithmus diese Varianz kannte, konnte er die Startzeit der Verschiebung gut vorhersagen. Informationen über unmittelbar vorhergehende Ereignisse halfen, diese Vermutungen zu klären.
Diese Entdeckung kann schwerwiegende Folgen haben. Seit Jahrzehnten versuchen die Menschen, Erdbeben anhand vorläufiger Schocks und anderer isolierter seismischer Ereignisse vorherzusagen. Das Ergebnis von Los Alamos deutet darauf hin, dass sie alle am falschen Ort gesucht haben - und dass der Schlüssel zu den Vorhersagen weniger explizite Informationen waren, die in relativ ruhigen Perioden zwischen großen seismischen Ereignissen gesammelt werden konnten.
Natürlich beschreiben die Gleitblöcke aus Kunststoff die chemische, thermische und morphologische Komplexität realer geologischer Fehler nicht genau. Um die Leistungsfähigkeit des maschinellen Lernens bei der Vorhersage realer Erdbeben zu demonstrieren, musste Johnson es auf reale Fehler testen. Gibt es einen besseren Ort als die pazifische Nordwestküste?
Verlasse das Labor
Die meisten Orte auf der Erde, an denen Erdbeben der Stärke 9 auftreten können, sind
Subduktionszonen, in denen eine tektonische Platte unter eine andere kriecht. Die Subduktionszone östlich von Japan ist verantwortlich für
das Erdbeben in Tohoku und den anschließenden Tsunami, der 2011 die Küste des Landes zerstörte. Einmal wird auch die Subduktionszone Cascadia, in der sich die Juan de Fuca-Platte unter den nördlichen Teil des westlichen Randes der nordamerikanischen Platte kriecht, die Bucht zerstören Puget, Vancouver Island und der umliegende pazifische Nordwesten.
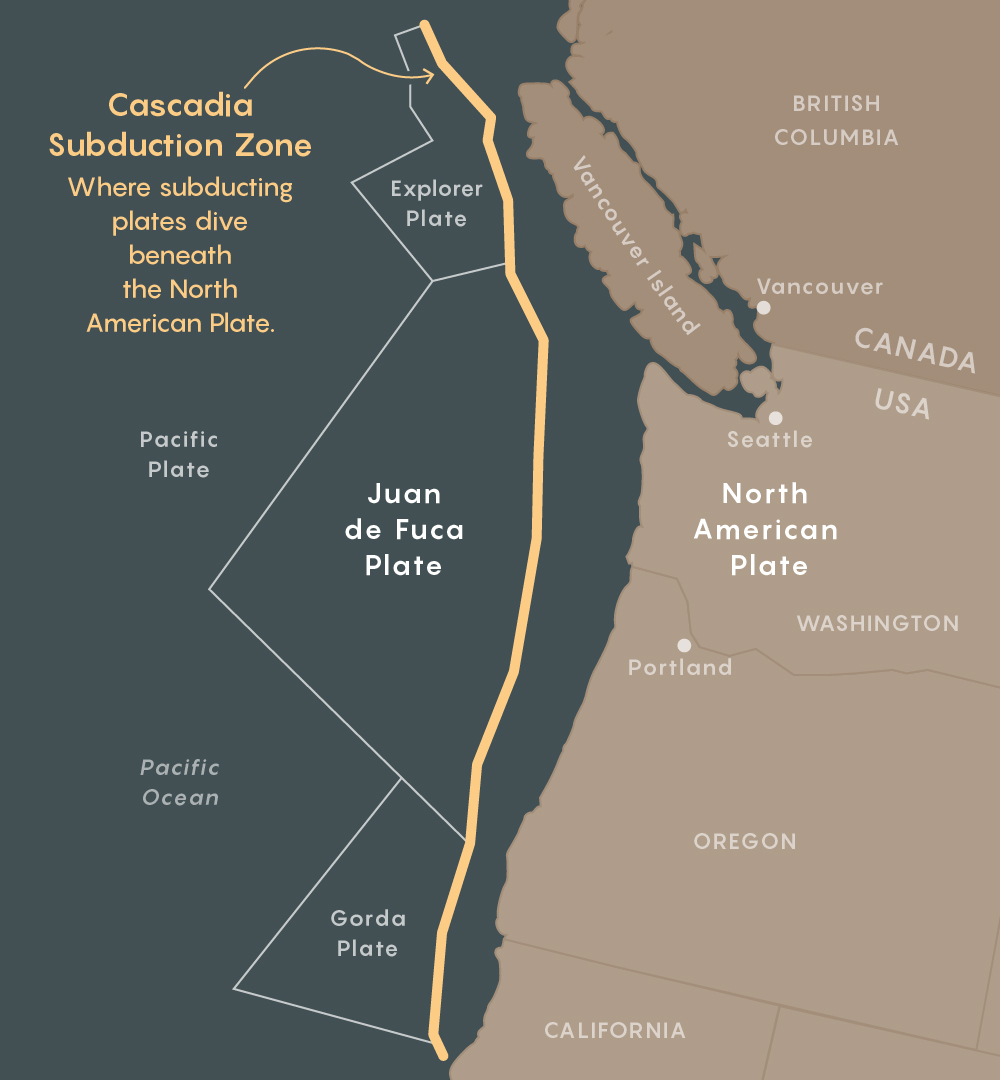
Die Cascadia-Subduktionszone erstreckt sich über 1000 km entlang der Pazifikküste von Cape Mendochino in Kalifornien bis Vancouver Island. Das letzte Mal, als es im Januar 1700 ein Erdbeben gab, verursachte es Zittern mit einer Stärke von 9 Punkten und einen Tsunami, der die Küste Japans erreichte. Geologische Untersuchungen zeigen, dass dieser Fehler während des
Holozäns etwa alle eine halbe Million Jahre, plus oder minus mehrere hundert Jahre, ähnliche Mega-Erdbeben verursachte. Statistisch gesehen kann Folgendes in jedem Jahrhundert passieren.
Dies ist einer der Gründe, warum Seismologen den langsamen Erdbeben in dieser Region große Aufmerksamkeit schenken. Es wird angenommen, dass langsame Erdbeben im unteren Teil der Subduktionszone eine geringe Menge an Spannung in die darüber liegende spröde Kruste tragen, wo schnelle und zerstörerische Schocks auftreten. Mit jedem langsamen Erdbeben ist die Wahrscheinlichkeit eines Mega-Erdbebens in der Region Puget Bay - Vancouver Islands - etwas höher. In Japan wurde einige Monate vor dem Erdbeben in Tohoku ein langsames Erdbeben beobachtet.
Aber Johnson hat noch einen weiteren Grund, langsame Erdbeben im Auge zu behalten: Sie produzieren eine riesige Datenmenge. Zum Vergleich: In den letzten 12 Jahren gab es kein einziges großes schnelles Erdbeben in der Schuld von Puget Bay - Vancouver Island. Im gleichen Zeitraum löste dieser Fehler jedoch mehr als zehn langsame Erdbeben aus, von denen jedes sorgfältig im seismischen Katalog erfasst wurde.
Dieser seismische Katalog ist eine echte Kopie der akustischen Aufzeichnungen, die in Johnsons Laborexperimenten mit Erdbeben erhalten wurden. Johnson und seine Kollegen teilten die seismischen Daten auf die gleiche Weise wie bei ihren akustischen Laboraufzeichnungen in kleine Segmente auf und beschrieben sie jeweils mit einer Reihe statistischer Merkmale. Dann gaben sie diese Daten und Informationen darüber, wann die vorherigen langsamen Erdbeben aufgetreten waren, in ihren Algorithmus für maschinelles Lernen ein.
Nachdem der Algorithmus die Daten von 2007 bis 2013 trainiert hatte, konnte er langsame Erdbeben von 2013 bis 2018 anhand von Daten, die mehrere Monate vor jedem Ereignis aufgezeichnet wurden, erfolgreich vorhersagen. Der Schlüsselfaktor war die seismische Energie - ein Wert, der eng mit der Streuung des akustischen Signals in Laborexperimenten zusammenhängt. Wie die Dispersion wuchs auch die seismische Energie in Erwartung jedes langsamen Erdbebens.
Die Vorhersagen für die Cascadia-Subduktionszone waren nicht so genau wie für Laborerdbeben. Die Korrelationskoeffizienten, die die Qualität der Übereinstimmung der Vorhersagen mit den Beobachtungen charakterisieren, waren in den neuen Ergebnissen signifikant geringer als im Labor. Trotzdem konnte der Algorithmus alle Erdbeben bis auf ein Jahr von 2013 bis 2018 vorhersagen und die Startdaten laut Johnson mit einer Genauigkeit von mehreren Tagen angeben (das langsame Erdbeben im August 2019 wurde nicht in die Studie aufgenommen).
Für de Hoop lautet die Hauptschlussfolgerung: "Technologien für maschinelles Lernen haben uns einen Einstiegspunkt gegeben, eine Datenanalysemethode zum Auffinden von Dingen, die wir zuvor noch nicht gesehen oder gesucht haben." Er warnt jedoch davor, dass noch viel zu tun sei. „Wir haben einen wichtigen Schritt getan - einen äußerst wichtigen. Dies ist jedoch ein winziger Schritt in die richtige Richtung. "
Ernüchternde Wahrheit
Der Zweck der Erdbebenvorhersage war nie die Vorhersage langsamer Erdbeben. Jeder muss plötzliche und katastrophale Erschütterungen vorhersagen, die Leben und Gesundheit bedrohen. Für das maschinelle Lernen schien dies ein Paradoxon zu sein: Die größten Erdbeben, die Seismologen am liebsten vorhersagen würden, treten am seltensten auf. Wie kann ein Algorithmus für maschinelles Lernen genügend Trainingsdaten erhalten, um diese sicher vorherzusagen?
Die Los Alamos-Gruppe ist der Ansicht, dass ihr Algorithmus im Prinzip nicht auf Daten trainiert werden muss, die aus Aufzeichnungen über katastrophale Erdbeben stammen, um diese erfolgreich vorherzusagen. Jüngste Studien legen nahe, dass seismische Muster, die kleinen Erdbeben vorausgehen, statistisch denen ähnlich sind, die großen Erdbeben vorausgehen, und dass Dutzende kleiner Erdbeben an jedem Tag in einem einzigen Fehler auftreten können. Nachdem der Computer aus Tausenden dieser kleinen Schocks gelernt hat, kann er möglicherweise große vorhersagen. Algorithmen für maschinelles Lernen können möglicherweise auch aus Computersimulationen schneller Erdbeben lernen, die eines Tages als Ersatz für reale Daten dienen können.
Trotzdem werden Wissenschaftler mit einer ernüchternden Wahrheit konfrontiert: Obwohl die physikalischen Prozesse, die zu einem Fehler am Rande eines Erdbebens führen, vorhersehbar werden können, enthält das Auftreten eines Erdbebens - das Wachstum kleiner seismischer Störungen, die zu einem vollständigen Fehlerbruch führen - nach Ansicht der meisten Wissenschaftler ein Element des Zufalls. Wenn ja, können sie Erdbeben unabhängig von der Qualität des maschinellen Lernens möglicherweise nie so vorhersagen, wie Wissenschaftler andere Naturkatastrophen vorhersagen konnten.
"Wir wissen noch nicht, wie genau die Daten sein werden, um Vorhersagen zu treffen", sagte Johnson. - Wird es wie eine Vorhersage von Hurrikanen sein? Nein, das glaube ich nicht. "
Vorhersagen von großen Erdbeben geben bestenfalls Zeitrahmen von Wochen, Monaten oder Jahren. Solche Vorhersagen können beispielsweise nicht verwendet werden, um die Massenevakuierung von Städten am Vorabend des Zitterns zu organisieren. Sie können jedoch die Vorbereitung auf dieses Ereignis verbessern, den Beamten helfen, sich auf die Stärkung unsicherer Gebäude zu konzentrieren, und auf andere Weise das Risiko eines katastrophalen Erdbebens verringern.
Johnson glaubt, dass ein solches Ziel es wert ist, erreicht zu werden. Als Realist erkennt er jedoch, dass es viel Zeit in Anspruch nehmen wird. "Ich sage nicht, dass wir lernen werden, Erdbeben in meinem Leben vorherzusagen", sagte er, "aber wir werden enorme Fortschritte in dieser Richtung machen."