
Dies ist ein Mythos, der auf dem Gebiet der Serverhardware weit verbreitet ist. In der Praxis brauchen hyperkonvergente Lösungen (wenn alles in einem) viel für was. In der Vergangenheit wurden die ersten Architekturen von Amazon und Google für ihre Dienste entwickelt. Dann bestand die Idee darin, eine Computerfarm aus denselben Knoten zu erstellen, von denen jeder seine eigenen Laufwerke hat. All dies wurde von einer systembildenden Software (Hypervisor) kombiniert und bereits in virtuelle Maschinen unterteilt. Die Hauptaufgabe ist ein Minimum an Aufwand für die Wartung eines Knotens und ein Minimum an Skalierungsproblemen: Wir haben gerade weitere tausend oder zwei gleiche Server gekauft und in der Nähe eine Verbindung hergestellt. In der Praxis handelt es sich um Einzelfälle, und viel häufiger handelt es sich um eine geringere Anzahl von Knoten und eine etwas andere Architektur.
Das Plus bleibt jedoch das gleiche - die unglaubliche Leichtigkeit der Skalierung und Steuerung. Minus - verschiedene Aufgaben verbrauchen Ressourcen unterschiedlich, und irgendwo gibt es viele lokale Festplatten, irgendwo gibt es wenig RAM usw., dh bei verschiedenen Arten von Aufgaben sinkt die Ressourcennutzung.
Es stellte sich heraus, dass Sie für eine einfache Einrichtung 10-15% mehr bezahlen. Dies verursachte den Schlagzeilen-Mythos. Wir haben lange gesucht, wo die Technologie optimal angewendet wird, und sie gefunden. Tatsache ist, dass Tsiska keine eigenen Speichersysteme hatte, aber einen vollständigen Servermarkt wollte. Und sie haben Cisco Hyperflex zu einer lokalen Speicherlösung auf Knoten gemacht.
Und dies stellte sich plötzlich als sehr gute Lösung für Backup-Rechenzentren heraus (Disaster Recovery). Warum und wie - jetzt werde ich es erzählen. Und ich werde Clustertests zeigen.
Wohin?
Hyperkonvergenz ist:
- Übertragen Sie Datenträger auf Rechenknoten.
- Vollständige Integration des Speichersubsystems in das Virtualisierungssubsystem.
- Übertragung / Integration mit dem Netzwerksubsystem.
Mit einer solchen Kombination können Sie viele Funktionen von Speichersystemen auf Virtualisierungsebene und alle in einem Steuerungsfenster implementieren.
In unserem Unternehmen sind Projekte zum Entwerfen redundanter Rechenzentren sehr beliebt, und häufig wird häufig die hyperkonvergente Lösung ausgewählt, da viele Replikationsoptionen (bis zum Metro-Cluster) sofort verfügbar sind.
Bei Backup-Rechenzentren handelt es sich normalerweise um eine Remote-Einrichtung an einem Standort auf der anderen Seite der Stadt oder in einer anderen Stadt im Allgemeinen. Sie können kritische Systeme im Falle eines teilweisen oder vollständigen Ausfalls des Hauptrechenzentrums wiederherstellen. Dort werden Verkaufsdaten ständig repliziert, und diese Replikation kann auf Anwendungsebene oder auf Blockgeräteebene (SHD) erfolgen.
Jetzt werde ich über das Gerät und die Tests des Systems sprechen und dann über einige reale Szenarien mit Daten zu Einsparungen.
Tests
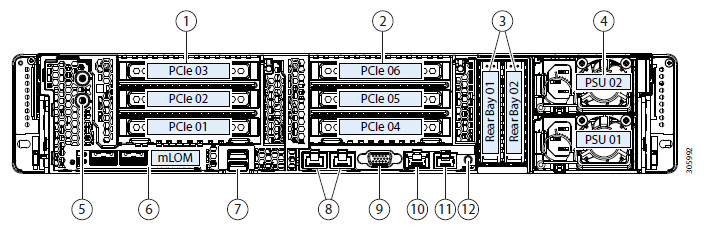
Unsere Kopie besteht aus vier Servern mit jeweils 10 SSD-Festplatten pro 960 GB. Es gibt eine dedizierte Festplatte zum Zwischenspeichern von Schreibvorgängen und zum Speichern der virtuellen Dienstmaschine. Die Lösung selbst ist die vierte Version. Der erste ist ehrlich gesagt roh (nach den Bewertungen zu urteilen), der zweite ist feucht, der dritte ist bereits ziemlich stabil, und dieser kann nach dem Ende des Beta-Tests für die breite Öffentlichkeit als Veröffentlichung bezeichnet werden. Während des Testens habe ich keine Probleme gesehen, alles funktioniert wie eine Uhr.
Änderungen in v4Einige Fehler wurden behoben.
Anfänglich konnte die Plattform nur mit dem VMware ESXi-Hypervisor arbeiten und unterstützte eine kleine Anzahl von Knoten. Außerdem wurde der Bereitstellungsprozess nicht immer erfolgreich beendet, ich musste einige Schritte neu starten, es gab Probleme beim Aktualisieren von alten Versionen, die Daten in der GUI wurden nicht immer korrekt angezeigt (obwohl ich immer noch nicht mit der Anzeige von Leistungsdiagrammen zufrieden bin), manchmal gab es Probleme an der Schnittstelle mit der Virtualisierung .
Nachdem alle Wunden der Kinder behoben wurden, kann HyperFlex sowohl ESXi als auch Hyper-V ausführen. Dies ist außerdem möglich:
- Erstellen eines gestreckten Clusters.
- Erstellen eines Clusters für Büros ohne Verwendung von Fabric Interconnect mit zwei bis vier Knoten (wir kaufen nur Server).
- Fähigkeit, mit externem Speicher zu arbeiten.
- Unterstützung für Container und Kubernetes.
- Erstellung von Barrierefreiheitszonen.
- Integration mit VMware SRM, wenn die integrierte Funktionalität nicht passt.
Die Architektur unterscheidet sich nicht wesentlich von den Entscheidungen der Hauptkonkurrenten, sie haben nicht begonnen, ein Fahrrad zu bauen. Alles funktioniert auf der VMware- oder Hyper-V-Virtualisierungsplattform. Hardware, die auf proprietären Cisco UCS-Servern gehostet wird. Es gibt diejenigen, die die Plattform wegen der relativen Komplexität der Ersteinrichtung hassen, viele Schaltflächen, ein nicht triviales System von Vorlagen und Abhängigkeiten, aber es gibt auch diejenigen, die Zen gelernt haben, von der Idee inspiriert waren und nicht mehr mit anderen Servern arbeiten möchten.
Wir werden die Lösung speziell für VMware in Betracht ziehen, da die Lösung ursprünglich für VMware entwickelt wurde und über mehr Funktionen verfügt. Hyper-V wurde hinzugefügt, um mit den Wettbewerbern Schritt zu halten und die Markterwartungen zu erfüllen.
Es gibt einen Cluster von Servern voller Festplatten. Es gibt Festplatten zur Datenspeicherung (SSD oder HDD - nach Ihrem Geschmack und Ihren Bedürfnissen), es gibt eine SSD-Festplatte zum Zwischenspeichern. Wenn Daten in den Datenspeicher geschrieben werden, werden Daten auf der Caching-Schicht (dedizierte SSD-Festplatte und Service-VM-RAM) gespeichert. Parallel dazu wird der Datenblock an die Knoten im Cluster gesendet (die Anzahl der Knoten hängt vom Clusterreplikationsfaktor ab). Nach der Bestätigung aller Knoten über die erfolgreiche Aufzeichnung wird die Bestätigung der Aufzeichnung an den Hypervisor und dann an die VM gesendet. Aufgezeichnete Daten im Hintergrund werden dedupliziert, komprimiert und auf Speicherplatten geschrieben. Gleichzeitig wird ein großer Block immer nacheinander auf Speicherplatten geschrieben, wodurch die Belastung der Speicherplatten verringert wird.
Deduplizierung und Komprimierung sind immer aktiviert und können nicht deaktiviert werden. Daten werden direkt von Speicherplatten oder aus dem RAM-Cache gelesen. Wenn eine Hybridkonfiguration verwendet wird, wird der Lesevorgang auch auf der SSD zwischengespeichert.
Die Daten sind nicht an den aktuellen Standort der virtuellen Maschine gebunden und werden gleichmäßig auf die Knoten verteilt. Mit diesem Ansatz können Sie alle Laufwerke und Netzwerkschnittstellen gleichermaßen laden. Das offensichtliche Minus lautet: Wir können die Leseverzögerung nicht minimieren, da keine Garantie für die lokale Datenverfügbarkeit besteht. Aber ich glaube, dass dies ein unbedeutendes Opfer im Vergleich zu den erhaltenen Pluspunkten ist. Darüber hinaus haben Netzwerkverzögerungen solche Werte erreicht, dass sie das Gesamtergebnis praktisch nicht beeinflussen.
Für die gesamte Logik des Festplattensubsystems ist eine spezielle Service-VM des Cisco HyperFlex Data Platform-Controllers verantwortlich, die auf jedem Speicherknoten erstellt wird. In unserer Service-VM-Konfiguration wurden acht vCPUs und 72 GB RAM zugewiesen, was nicht so klein ist. Ich möchte Sie daran erinnern, dass der Host selbst über 28 physische Kerne und 512 GB RAM verfügt.
Die Service-VM hat direkten Zugriff auf physische Festplatten, indem der SAS-Controller an die VM weitergeleitet wird. Die Kommunikation mit dem Hypervisor erfolgt über ein spezielles IOVisor-Modul, das E / A-Vorgänge abfängt, und über einen Agenten, mit dem Sie Befehle an die Hypervisor-API übertragen können. Der Agent ist für die Arbeit mit HyperFlex-Snapshots und -Klonen verantwortlich.
Im Hypervisor werden Festplattenressourcen als NFS- oder SMB-Ball bereitgestellt (je nach Typ des Hypervisors raten Sie, welcher). Und unter der Haube ist dies ein verteiltes Dateisystem, mit dem Sie Funktionen vollwertiger Speichersysteme für Erwachsene hinzufügen können: Zuweisung dünner Volumes, Komprimierung und Deduplizierung, Snapshots mithilfe der Redirect-on-Write-Technologie, synchrone / asynchrone Replikation.
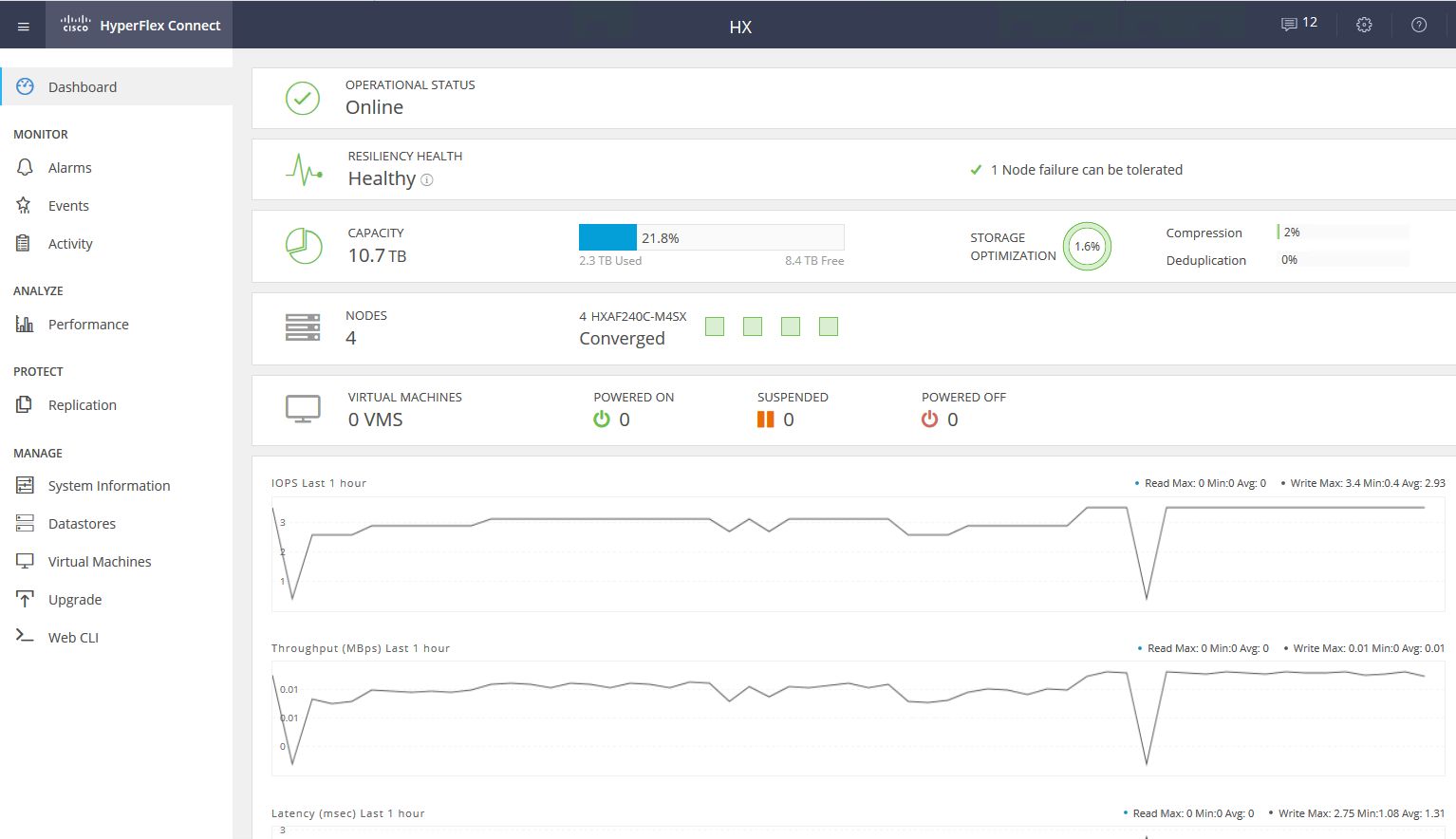
Service VM bietet Zugriff auf die WEB-Schnittstelle der HyperFlex-Subsystemverwaltung. Es gibt eine Integration mit vCenter, und die meisten täglichen Aufgaben können von dort aus ausgeführt werden. Datenspeicher können jedoch bequemer von einer separaten Webcam abgeschnitten werden, wenn Sie bereits auf eine schnelle HTML5-Oberfläche umgestellt haben oder einen vollständigen Flash-Client mit vollständiger Integration verwenden. In der Service-Webcam können Sie die Leistung und den detaillierten Status des Systems anzeigen.
Es gibt eine andere Art von Knoten in einem Cluster - Rechenknoten. Es können Rack- oder Blade-Server ohne integrierte Laufwerke sein. Auf diesen Servern können Sie VMs ausführen, deren Daten auf Servern mit Festplatten gespeichert sind. Unter dem Gesichtspunkt des Datenzugriffs gibt es keinen Unterschied zwischen den Knotentypen, da die Architektur das Abstrahieren vom physischen Standort der Daten umfasst. Das maximale Verhältnis von Rechenknoten und Speicherknoten beträgt 2: 1.
Die Verwendung von Rechenknoten erhöht die Flexibilität bei der Skalierung von Clusterressourcen: Wir müssen keine Knoten mit Festplatten kaufen, wenn wir nur CPU / RAM benötigen. Darüber hinaus können wir einen Blade-Korb hinzufügen und Platz auf dem Rack-Server sparen.
Als Ergebnis haben wir eine hyperkonvergente Plattform mit den folgenden Funktionen:
- Bis zu 64 Knoten in einem Cluster (bis zu 32 Speicherknoten).
- Die Mindestanzahl von Knoten in einem Cluster beträgt drei (zwei für einen Edge-Cluster).
- Datenredundanzmechanismus: Spiegelung mit Replikationsfaktor 2 und 3.
- Metro-Cluster.
- Asynchrone VM-Replikation auf einen anderen HyperFlex-Cluster.
- Orchestrierung des Wechsels von VMs zu einem Remote-Rechenzentrum.
- Native Snapshots mit Redirect-on-Write-Technologie.
- Bis zu 1 PB nutzbarer Speicherplatz mit Replikationsfaktor 3 und ohne Deduplizierung. Replikationsfaktor 2 wird nicht berücksichtigt, da dies keine Option für ernsthafte Verkäufe ist.
Ein weiteres großes Plus ist die einfache Verwaltung und Bereitstellung. Alle Komplexitäten bei der Konfiguration von UCS-Servern werden von einer speziellen VM übernommen, die von Cisco-Ingenieuren erstellt wurde.
Testbed-Konfiguration:
- 2 x Cisco UCS Fabric Interconnect 6248UP als Verwaltungscluster und Netzwerkkomponenten (48 Ports im Ethernet 10G / FC 16G-Modus).
- Vier Cisco UCS HXAF240 M4-Server.
Serverfunktionen:
Weitere KonfigurationsoptionenNeben dem ausgewählten Bügeleisen stehen derzeit folgende Optionen zur Verfügung:
- HXAF240c M5.
- Eine oder zwei CPUs von Intel Silver 4110 bis Intel Platinum I8260Y. Die zweite Generation ist verfügbar.
- 24 Speichersteckplätze, Lamellen von 16 GB RDIMM 2600 bis 128 GB LRDIMM 2933.
- 6 bis 23 Datenträger für Daten, ein Caching-Datenträger, ein System und ein Startdatenträger.
Kapazitätslaufwerke- HX-SD960G61X-EV 960 GB 2,5-Zoll-Enterprise-Value-6G-SATA-SSD (1-fache Lebensdauer) SAS 960 GB.
- HX-SD38T61X-EV 3,8 TB 2,5 Zoll Enterprise Value 6G SATA SSD (1X Ausdauer) SAS 3,8 TB.
- Treiber zwischenspeichern
- HX-NVMEXPB-I375 375 GB 2,5-Zoll-Intel Optane-Laufwerk, extreme Leistung und Ausdauer.
- HX-NVMEHW-H1600 * 1,6 TB 2,5 Zoll Ent. Perf NVMe SSD (3X Ausdauer) NVMe 1,6 TB.
- HX-SD400G12TX-EP 400 GB 2,5 Zoll Ent. Perf 12G SAS SSD (10X Ausdauer) SAS 400 GB.
- HX-SD800GBENK9 ** 800GB 2,5 Zoll Ent. Perf 12G SAS SED SSD (10X Ausdauer) SAS 800 GB.
- HX-SD16T123X-EP 1,6 TB 2,5-Zoll-12G-SAS-SSD mit Unternehmensleistung (3-fache Lebensdauer).
System- / Protokolllaufwerke- HX-SD240GM1X-EV 240 GB 2,5 Zoll Enterprise Value 6G SATA-SSD (Upgrade erforderlich).
Boot-Treiber- HX-M2-240 GB 240 GB SATA M.2 SSD SATA 240 GB.
Verbindung zu einem Netzwerk über 40G-, 25G- oder 10G-Ethernet-Ports.
Da FI HX-FI-6332 (40G), HX-FI-6332-16UP (40G), HX-FI-6454 (40G / 100G) sein kann.
Testen Sie sich
Zum Testen des Festplattensubsystems habe ich HCIBench 2.2.1 verwendet. Dies ist ein kostenloses Dienstprogramm, mit dem Sie die Erstellung von Lasten aus mehreren virtuellen Maschinen automatisieren können. Die Last selbst wird durch reguläres fio erzeugt.
Unser Cluster besteht aus vier Knoten, Replikationsfaktor 3, allen Flash-Laufwerken.
Zum Testen habe ich vier Datenspeicher und acht virtuelle Maschinen erstellt. Bei Schreibtests wird davon ausgegangen, dass die Caching-Festplatte nicht voll ist.
Die Testergebnisse sind wie folgt:
Fettgedruckte Werte sind angegeben, wonach keine Produktivitätssteigerung mehr auftritt, manchmal ist sogar eine Verschlechterung sichtbar. Aufgrund der Tatsache, dass wir uns auf die Netzwerkleistung / Controller / Laufwerke stützen.- Sequentielles Lesen von 4432 MB / s.
- Sequentielles Schreiben von 804 MB / s.
- Wenn ein Controller ausfällt (Ausfall einer virtuellen Maschine oder eines Hosts), wird der Leistungsabfall verdoppelt.
- Wenn das Speicherlaufwerk ausfällt, beträgt der Drawdown 1/3. Die Rebild-Festplatte beansprucht 5% der Ressourcen jedes Controllers.
Auf einem kleinen Block stoßen wir auf die Leistung des Controllers (virtuelle Maschine), dessen CPU zu 100% ausgelastet ist, während wir den Block erhöhen, auf den die Portbandbreite läuft. 10 Gbit / s reichen nicht aus, um das Potenzial des AllFlash-Systems auszuschöpfen. Leider erlauben die Parameter des bereitgestellten Demostands keine Überprüfung der Arbeit mit 40 Gbit / s.
In meinem Eindruck von den Tests und dem Studium der Architektur erhalten wir aufgrund des Algorithmus, der Daten zwischen allen Hosts platziert, eine skalierbare vorhersagbare Leistung. Dies ist jedoch auch eine Einschränkung beim Lesen, da hier mehr von lokalen Datenträgern und mehr gequetscht werden könnte Um ein produktiveres Netzwerk zu speichern, stehen beispielsweise 40-Gbit / s-FIs zur Verfügung.
Außerdem kann eine Festplatte für das Caching und die Deduplizierung eine Einschränkung darstellen. In diesem Stand können wir sogar auf vier SSD-Festplatten schreiben. Es wäre großartig, die Anzahl der zwischengespeicherten Festplatten erhöhen zu können und den Unterschied zu erkennen.
Echte Verwendung
Zum Organisieren eines Backup-Rechenzentrums können zwei Ansätze verwendet werden (wir ziehen nicht in Betracht, Backups an einem Remote-Standort zu platzieren):
- Aktiv Passiv Alle Anwendungen werden im Hauptrechenzentrum gehostet. Die Replikation ist synchron oder asynchron. Im Falle eines Sturzes im Hauptrechenzentrum müssen wir das Backup aktivieren. Dies kann manuell / mit Skripten / Orchestrierungsanwendungen erfolgen. Hier erhalten wir ein RPO, das der Replikationshäufigkeit entspricht, und das RTO hängt von der Reaktion und den Fähigkeiten des Administrators und der Qualität der Entwicklung / des Debuggens des Switching-Plans ab.
- Aktiv Aktiv In diesem Fall ist nur eine synchrone Replikation vorhanden. Die Verfügbarkeit von Rechenzentren wird durch ein Quorum / Arbiter bestimmt, das ausschließlich auf der dritten Plattform platziert ist. RPO = 0, und RTO kann 0 erreichen (sofern die Anwendung dies zulässt) oder gleich der Zeit für ein Failover eines Knotens in einem Virtualisierungscluster. Auf der Virtualisierungsebene wird ein gestreckter (Metro) Cluster erstellt, für den Active-Active-Speicher erforderlich ist.
Normalerweise sehen wir bei Kunden eine bereits implementierte Architektur mit klassischem Speicher im Hauptrechenzentrum, daher entwerfen wir eine andere für die Replikation. Wie bereits erwähnt, bietet Cisco HyperFlex eine asynchrone Replikation und die Erstellung eines erweiterten Virtualisierungsclusters. Gleichzeitig benötigen wir kein dediziertes Midrange- oder höheres Speichersystem mit den teuren Funktionen der Replikation und des Active-Active-Datenzugriffs auf zwei Speichersystemen.
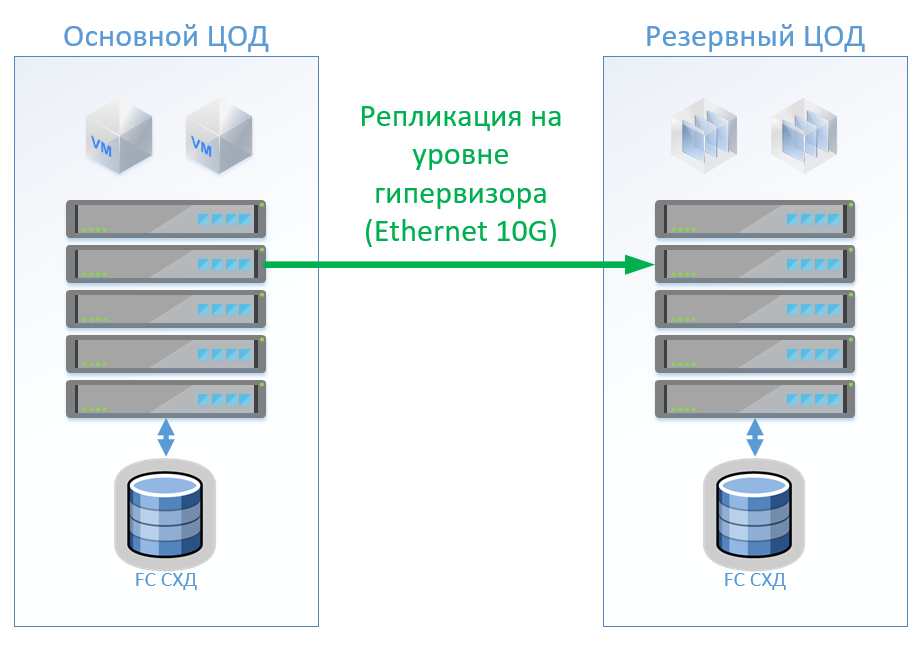
Szenario 1: Wir haben primäre und Backup-Rechenzentren, eine Virtualisierungsplattform auf VMware vSphere. Alle Produktivsysteme befinden sich hauptsächlich im Rechenzentrum. Die Replikation der virtuellen Maschine wird auf Hypervisor-Ebene durchgeführt. Dadurch können die VMs im Sicherungs-Rechenzentrum nicht eingeschaltet bleiben. Wir replizieren Datenbanken und spezielle Anwendungen mit integrierten Tools und lassen VMs eingeschaltet. Wenn das Hauptdatenzentrum ausfällt, starten wir das System im Sicherungsdatenzentrum. Wir glauben, dass wir ungefähr 100 virtuelle Maschinen haben. Solange das Hauptdatenzentrum in Betrieb ist, können Testumgebungen und andere Systeme im Sicherungsdatenzentrum gestartet werden, die deaktiviert werden können, wenn das Hauptdatenzentrum umgeschaltet wird. Es ist auch möglich, dass wir die bidirektionale Replikation verwenden. Aus Sicht der Ausrüstung wird sich nichts ändern.
Bei der klassischen Architektur werden wir in jedem Rechenzentrum ein hybrides Speichersystem mit Zugriff über FibreChannel, Zerreißen, Deduplizieren und Komprimieren (jedoch nicht online), 8 Servern pro Standort, 2 FibreChannel-Switches und Ethernet 10G installieren. Für die Replikations- und Switching-Steuerung in einer klassischen Architektur können wir VMware-Tools (Replication + SRM) oder Tools von Drittanbietern verwenden, die etwas billiger und manchmal bequemer sind.
Die Abbildung zeigt ein Diagramm.
Wenn Sie Cisco HyperFlex verwenden, erhalten Sie die folgende Architektur:
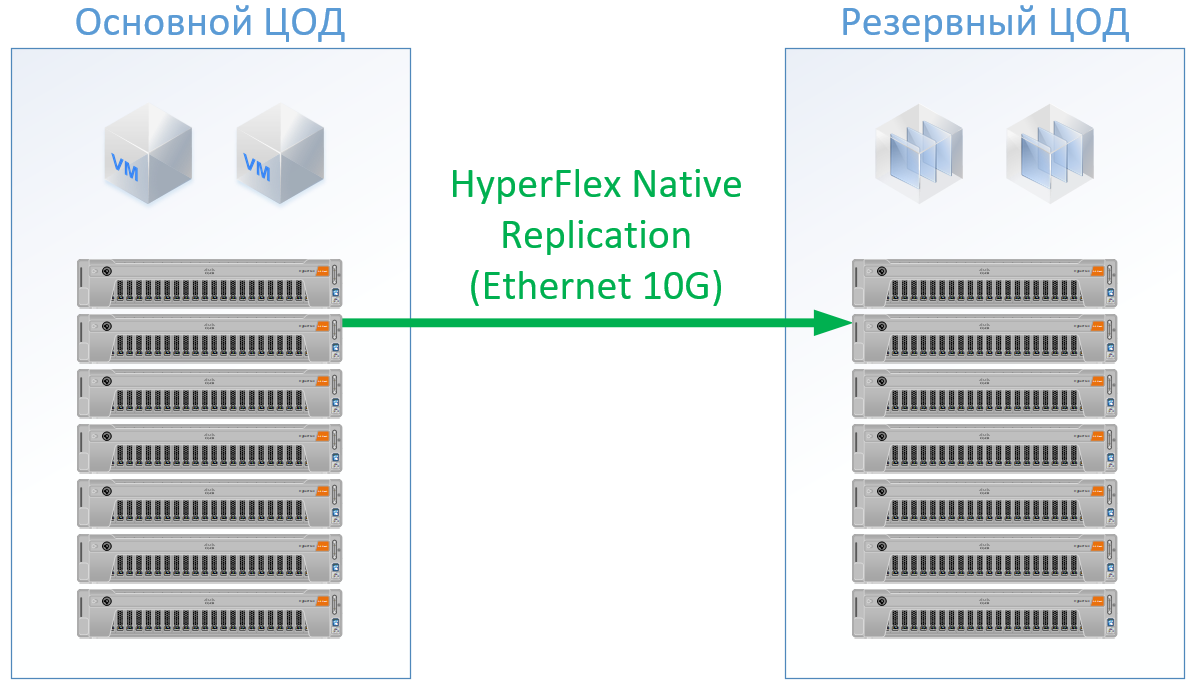
Für HyperFlex habe ich Server mit großen CPU / RAM-Ressourcen verwendet, z Ein Teil der Ressourcen wird an die VM des HyperFlex-Controllers gesendet. Ich habe sogar ein wenig in die HyperFlex-Konfiguration auf der CPU und im Speicher neu geladen, um nicht neben Cisco zu spielen und Ressourcen für den Rest der VMs zu garantieren. Wir können jedoch FibreChannel-Switches ablehnen, und wir benötigen nicht für jeden Server Ethernet-Ports. Der lokale Datenverkehr wird innerhalb von FI umgeschaltet.
Das Ergebnis ist die folgende Konfiguration für jedes Rechenzentrum:
Für Hyperflex habe ich keine Replikationssoftwarelizenzen zugesagt, da diese bei uns sofort verfügbar sind.
Für die klassische Architektur habe ich einen Anbieter ausgewählt, der sich als qualitativ hochwertiger und kostengünstiger Hersteller etabliert hat. Für beide Optionen habe ich einen Standard für einen bestimmten Lösungs-Skid verwendet, bei der Ausgabe habe ich echte Preise erhalten.
Die Lösung auf Cisco HyperFlex war 13% billiger.
Szenario 2: Erstellen von zwei aktiven Rechenzentren. In diesem Szenario entwerfen wir einen erweiterten Cluster auf VMware.
Die klassische Architektur besteht aus Virtualisierungsservern, SAN (FC-Protokoll) und zwei Speichersystemen, die auf dem zwischen ihnen gespannten lesen und schreiben können. Auf jedem SHD legen wir eine nützliche Kapazität für das Schloss.
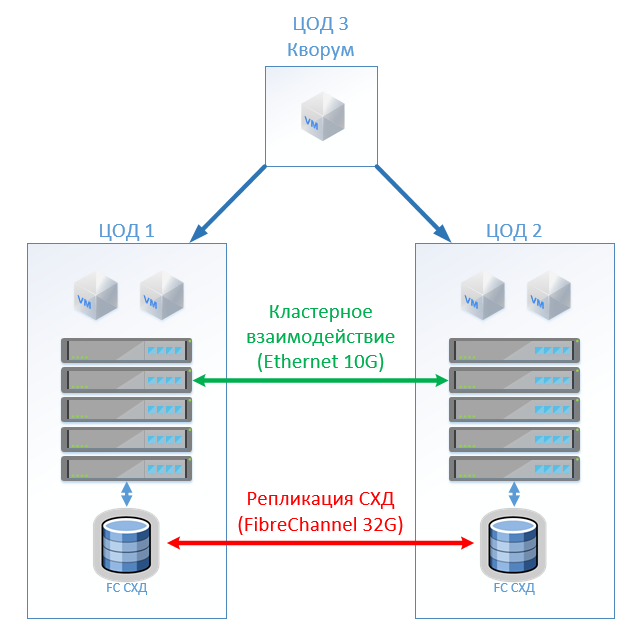
Bei HyperFlex erstellen wir einfach einen Stretch-Cluster mit der gleichen Anzahl von Knoten an beiden Standorten. In diesem Fall wird der Replikationsfaktor 2 + 2 verwendet.
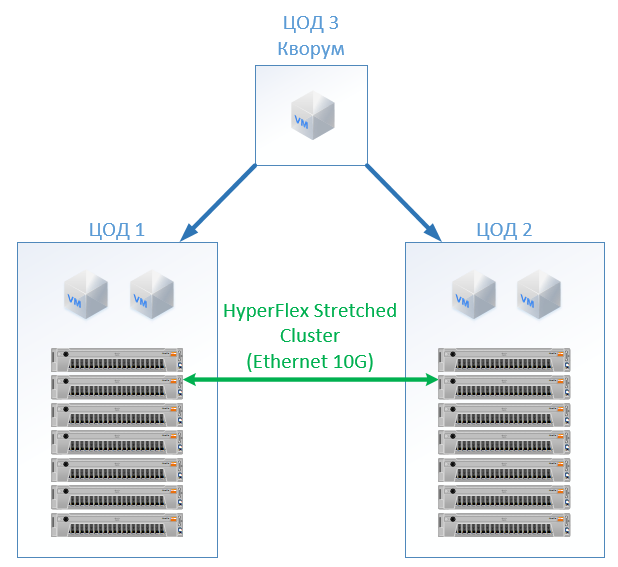
Die folgende Konfiguration hat sich herausgestellt:
Bei allen Berechnungen habe ich die Netzwerkinfrastruktur, die Kosten für Rechenzentren usw. nicht berücksichtigt: Sie sind für die klassische Architektur und für die HyperFlex-Lösung gleich.
Zu Anschaffungskosten erwies sich HyperFlex als 5% teurer. Es ist erwähnenswert, dass ich für die CPU / RAM-Ressourcen eine Tendenz für Cisco habe, weil es in der Konfiguration die Kanäle der Speichercontroller gleichmäßig füllte. Die Kosten sind etwas höher, aber nicht um eine Größenordnung, was eindeutig darauf hinweist, dass Hyperkonvergenz nicht unbedingt ein "Spielzeug für die Reichen" ist, sondern mit dem Standardansatz zum Aufbau eines Rechenzentrums konkurrieren kann. , Cisco UCS .
SAN , - , (, , — ), ( ), .
, — Cisco. Cisco UCS, , HyperFlex , . , . : « , ?» « - , . !» — , : « » .
Referenzen