
Hallo Habr! Wir veröffentlichen weiterhin Rezensionen zu wissenschaftlichen Artikeln von Mitgliedern der Open Data Science-Community über den Kanal #article_essense. Wenn Sie sie vor allen anderen erhalten möchten, treten Sie der Community bei !
Artikel für heute:
- Neuronale gewöhnliche Differentialgleichungen (University of Toronto, 2018)
- Halbüberwachtes Lernen mit tiefgreifenden generativen Modellen: Clustering und Klassifizierung mit ultra-spärlichen Labels (Universität Oxford, Alan Turing Institute, London, 2019)
- Aufdeckung und Abschwächung algorithmischer Verzerrungen durch erlernte latente Strukturen (Massachusetts Institute of Technology, Harvard University, 2019)
- Tiefes Lernen aus menschlichen Vorlieben (OpenAI, DeepMind, 2017)
- Erkundung zufällig verdrahteter neuronaler Netze zur Bilderkennung (Facebook AI Research, 2019)
- Photofeeler-D3: Ein neuronales Netzwerk mit Wählermodellierung für die Bewertung von Datierungsfotos (Photofeeler Inc., 2019)
- MixMatch: Ein ganzheitlicher Ansatz für halbüberwachtes Lernen (Google Reasearch, 2019)
- Teilen und erobern Sie den Einbettungsraum für metrisches Lernen (Universität Heidelberg, 2019)
Links zu früheren Sammlungen der Serie: 1. Neuronale gewöhnliche Differentialgleichungen
Autoren: Ricky TQ Chen, Julia Rubanova, Jesse Bettencourt, David Duvenaud (Universität von Toronto, 2018)
→ Originalartikel
Der Autor der Rezension: George Ignatov (in lockerem a2dy2n7okhtp)
NIPS Best Paper Award

Die Autoren des Artikels stellten fest, dass ResNet-ähnliche Netzwerke der Euler-Methode zur Lösung von Differentialgleichungen sehr ähnlich sind. Wenn ja, warum nicht sofort die Idee auf das Maximum bringen: Stellen Sie sich ein neuronales Netzwerk in Form einer Differentialgleichung vor und erhalten Sie
- Ein Netzwerk mit einer beliebigen Anzahl von Schichten, das jederzeit während des Trainings und der Inferenz geändert werden kann. Mehr Ebenen -> mehr Präzision und flüssigere Konvertierungen (und umgekehrt).
- Eine viel geringere Anzahl von Parametern senkt daher die Speicherkosten.
NODE durch Analogien:
- - So sieht die Definition der Ausgabe von Schicht n in einem resnetartigen Netzwerk aus: W - Parameter.
- - Dies würde wie ein NODE-ähnliches Netzwerk aussehen, vorausgesetzt, n ist eine diskrete Größe.
- , - Eulers Methode.
- - ta-da! ODE-basiertes neuronales Netzwerk.
Wir lösen es mit jedem Black-Box-ODEsolver und werfen die Gradienten mit der Methode der adjungierten Empfindlichkeit (Pontryagin et al., 1962). Aufgrund seiner vollständigen Differenzierbarkeit kann NODE mit herkömmlichen neuronalen Netzen kombiniert werden. Die Autoren haben den Code auf pytorch gepostet.
Der Artikel beschreibt 3 Anwendungen:
- Vergleich mit ResNet-ähnlicher Architektur (auf MNIST). NODE funktioniert fast nicht schlechter, während dreimal weniger Parameter verwendet werden.
- Überschreiben normalisierter Flüsse durch NODE - Continuous Normalized Flows (synthetischer Datensatz). Das neue Modell reduziert die Rechenkosten von O (n_hidden_units ^ 3) auf linear.
- Modellierung temporärer Ereignisse mit unregelmäßigen Beobachtungen (synthetischer Datensatz). Ein Datensatz von Spiraltrajektorien wurde generiert, aus dem zufällig ausgewählte Punkte bestreut wurden mit: Salz: Gaußsches Rauschen zur Plausibilität. Es testete das übliche RNN und NODE und das zweite erwies sich erneut als besser.
Im Kleingedruckten:
- Minibatch-Training verursacht eine Art Rechenaufwand, aber die Autoren argumentieren, dass dies in der Praxis fast unsichtbar ist.
- Es erscheinen zwei neue Hyperparameter: Netzwerktiefe und Fehlertoleranz beim Lösen von ODE.
- Damit die ODE-Lösung eindeutig bleibt, muss das Netzwerk endliche Gewichte haben und Lipshitz-Nichtlinearitäten wie tanh oder relu verwenden.
Link zu einer detaillierteren Übersicht über habr.
2. Halbüberwachtes Lernen mit tiefgreifenden generativen Modellen: Clustering und Klassifizierung mit ultra-spärlichen Labels
Artikelautoren: Matthew Willetts, Stephen Roberts und Christopher Holmes
(Universität Oxford, Alan Turing Institute, London, 2019)
→ Originalartikel
Rezensionsautor: Alex Chiron (in sliron shiron8bit)
Die Autoren betrachten einen halb unbeaufsichtigten Fall für das Klassifizierungsproblem, wenn im Daten-Markup aufgrund von Selektionsverzerrungen einige der vorhandenen Klassen überhaupt nicht und nicht so viele gemäß bekannten Datenklassen gekennzeichnet wurden. Dies führt zu zusätzlichen Problemen, da die meisten Modelle normalerweise entweder im halbüberwachten / überwachten Modus (Klassifizierung) oder im unbeaufsichtigten Modus (Clustering) arbeiten. In diesem Fall müssen beide Optionen berücksichtigt werden. Darüber hinaus kann die Verwendung von halbüberwachten Algorithmen dazu führen, dass nicht zugewiesene Daten gemäß einer Metrik der Nähe zu falschen Klassen zugewiesen werden. Ein hypothetisches Beispiel für solche Daten ist eine Reihe von Tumorscans. Wir haben an den Daten teilgenommen und alle in diesem Teil vorhandenen Tumortypen markiert, aber es stellte sich heraus, dass in den verbleibenden Daten andere Tumortypen vorhanden waren und die Variabilität der bekannten Arten im Markup nicht vollständig widergespiegelt wurde.
Die Autoren ließen sich von tiefgreifenden generativen Modellen inspirieren (das einfachste Beispiel für ein solches Modell mit einer einzigen Schichttiefe versteckter Variablen ist ein Variations-Auto-Encoder, auch bekannt als VAE): In früheren Arbeiten konnten solche Modelle sowohl den halbüberwachten Fall (M2, ADGM) als auch das Clustering ( VaDE, GM-VAE).
Warum nicht zwei Probleme gleichzeitig lösen (halbüberwachtes Lernen in selten markierten Klassen und unbeaufsichtigtes Lernen in nicht platzierten Klassen), den Raum der gelernten latenten Variablen gemeinsam halten und Ideen aus den oben genannten Modellen kombinieren? Es ist diese Idee, die den im Artikel vorgeschlagenen GM-DGM / AGM-DGM-Modellen zugrunde liegt.
Betrachten Sie das M2-Modell in einem halbüberwachten Fall. Dies wird so genannt, weil der Schöpfer unter M1 ein sequentielles Training von VAE und einem Klassifikator (svm) für die resultierenden latenten Darstellungen von z implizierte, aber M2 wird bereits von VAE erhalten, indem der Variablen verborgener Variable die Variable y hinzugefügt wird, die für die manchmal beobachtete Klasse verantwortlich ist.
,
wo ,
Hier ist q ein Codierer, p ist ein Decodiererteil - direkt ausgebildeter Klassifikator.
Für den unbeaufsichtigten / halb unbeaufsichtigten Fall funktioniert M2 nicht - ein posteriorer Kollaps tritt auf, der Klassifizierungsteil q_phi (y | x) kollabiert auf die a priori-Verteilung p (y). Der Autor von GM-VAE in seinem Artikel zeigte auch die Inoperabilität von M2 in der Praxis und stellte fest, dass die erste Schicht des h1-Decoders bei der Implementierung von M2 häufig einer Mischung von Gaußschen sehr ähnlich ist.
Basierend auf dieser Beobachtung verwendet GM-VAE eine explizite Schicht versteckter Variablen zum Clustering von Gaußschen Gemischen zum Clustering, was auch von den Autoren des untersuchten Artikels wiederholt wird. Daher ist das GM-DGM-Modell, das einen erfolgreichen Betrieb im halb unbeaufsichtigten Modus ermöglicht, eine Modifikation VAE unter Verwendung einer Mischung von Gaußschen in einer verborgenen Schicht, abhängig von einer Variablen der Klasse y, mit der obigen Funktion von zwei Begriffen zum Zählen und Maximieren von ELBO.
Die Autoren des Artikels führten ein Experiment mit einer halb unbeaufsichtigten Version von Fashion-MNIST durch: Sie entfernten die Etiketten der ersten 5 Klassen, die restlichen 5 Klassen ließen 5% der Etiketten übrig, während sie eine Gesamtgenauigkeit von 77,2% gegenüber 53% für M2 erhielten. Die Möglichkeit, das Modell für das Clustering zu verwenden, wurde ebenfalls gezeigt (was nicht überraschend ist, da es fast GM-VAE ist).
3. Aufdecken und Abschwächen algorithmischer Verzerrungen durch erlernte latente Strukturen
Autoren: Alexander Amini, Ava Soleimany, Wilko Schwarting, Sangeeta N. Bhatia, Daniela Rus (Massachusetts Institute of Technology, Harvard University, 2019)
→ Originalartikel
Rezensionsautor: Alex Chiron (in sliron shiron8bit)
In letzter Zeit finden Sie in den Medien immer häufiger Nachrichten, die das Thema der Verzerrung von Daten berühren, insbesondere in Bezug auf Algorithmen, die sich auf Einzelpersonen beziehen - mit zunehmender Anwendbarkeit besteht das Risiko einer starken negativen Auswirkung auf diejenigen Kategorien und Personengruppen, die unzureichend (oder übermäßig) sind. im Datensatz dargestellt. Eines der neuesten Beispiele ist eine Studie, die eine geringere Genauigkeit bei der Erkennung von Fußgängern mit dunkler Hautfarbe zeigte (im Zusammenhang mit der Objekterkennung in Standard-BDD100K- und MSCOCO-Datensätzen, Link ). Grundlegende Ansätze zur Beseitigung von Verzerrungen:
- Klassenausgleich durch Resampling (erfordert ein vorheriges Verständnis der verborgenen Datenstruktur).
- Generierung unvoreingenommener Daten (z. B. Verwendung von GAN zur Generierung von Personen mit einer Vielzahl von Hauttönen ).
- Clustering und anschließendes Resampling.
- Sie können immer noch warten, bis das IBM Diversity in Faces-Dataset an Academictorrents gesendet wird.
Die Autoren des Artikels bieten eine Modifikation der VAE und der Stichprobe unter Berücksichtigung der Verteilung der latenten Variablen z an, wodurch der Einfluss der Verzerrung in den Daten in der Trainingsphase verringert werden kann.
Die Hauptideen hinter DB-VAE sind also:
- Stellen Sie sich ein Klassifizierungsproblem vor, bei dem wir einen Trainingsdatensatz {(x, y)} haben, x m-dimensionale Merkmale sind, y d-dimensionale Beschriftungen sind und unsere Aufgabe darin besteht, die Abbildung X-> Y zu approximieren.
- Nehmen wir VAE, aber zusätzlich zum Vektor der versteckten Variablen z der Dimension 2k (wir erinnern uns, 2 hier, weil es sich um Mittelwerte und Varianzen handelt) lernen wir auch den Encoder der Dimension d, der für die oben genannten Bezeichnungen verantwortlich ist. In diesem Fall akzeptiert der Decoder nur den Vektor z als Eingabe. Auf diese Weise erhalten wir den Anschein eines halbüberwachten Lernens, bei dem ein Teil des Modells gelernt wird, Eingaben zu rekonstruieren, und ein Teil darin besteht, ein bestimmtes Problem zu lösen (Klassifizierung).
- Wir steuern das Training des Modells aufgrund des kombinierten Verlusts, indem wir den Standard für den VAE-Verlust (Rekonstruktion + KL-Divergenz) und den Verlust für eine Hilfsaufgabe (z. B. Kreuzentropie für das binäre Klassifizierungsproblem) kombinieren.
- Besonderes Augenmerk wird auf die Tatsache gelegt, dass Sie das Training für Daten steuern müssen, die Sie nicht debiasen möchten (dh nicht vom Decoder zurücksetzen).
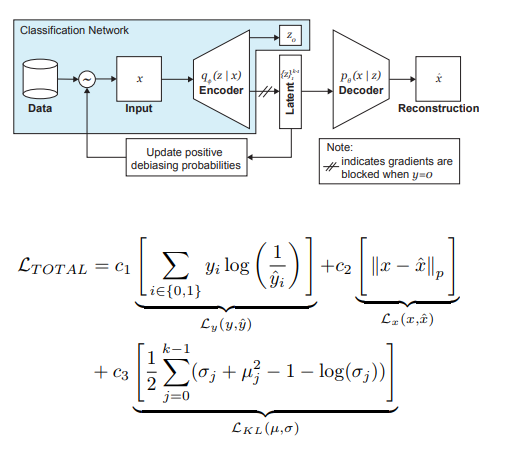
Die wichtigste Rolle bei der Beseitigung der Schmerzen von Schwarzen spielt die adaptive Probenahme in der Trainingsphase. Wir wollen seltene (aus der Sicht einiger versteckter, nicht explizit identifizierter Faktoren) Stichproben auswählen, also wenden wir uns den Histogrammen für jede Dimension des Raums der verborgenen Variablen z zu, deren Produkt die Verteilung Q (z | X) von Daten über den gesamten Raum Z approximieren kann. Bei der Bildung eines neuen Stapels berücksichtigen wir die 'Inverse' zur Q (z | X) -Verteilung W (z (x) | X), die die Wahrscheinlichkeit der Auswahl eines Beispiels im Stapel bestimmt (Alpha ist ein Hyperparameter, der den Grad des Debiasing bestimmt) und Q (z | aktualisiert) X) zu jeder Zeit. Wie Sie sehen, ist das Debiasing nicht vorausgewählt, sondern basiert auf den erlernten latenten Variablen.
Als Experiment lösten die Autoren das Problem der binären Klassifizierung (Finden des Gesichts auf dem Foto). Für das Training haben wir einen Datensatz gesammelt, der aus 200.000 Personen mit CelebA und 200.000 Nicht-Personen mit Imagenet bestand. Die Größe der Bilder wurde auf 64 x 64 geändert. Wie bereits erwähnt, wurde während des Trainings die Rückausbreitung vom Decoder für Fotos ohne Gesichter blockiert (y = 0). Nach dem Training wurden sie im Pilot Parliaments Benchmark (PPB) validiert (1270 Fotos von Personen aus den Parlamenten von Südafrika, Ruanda, Senegal, Schweden, Finnland, Island): Für alle Alpha> 0 erhöhte sich die Erkennungsgenauigkeit in den Kategorien dunkle Männer, dunkle Frauen, helle Frauen im Vergleich zu Option ohne Debiasing.
4. Tiefes Lernen aus menschlichen Vorlieben
Autoren: Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg und Dario Amodei (OpenAI, DeepMind, 2017)
→ Originalartikel
Rezensionsautor: Dmitry Nikulin (in Dniku Slack)
In diesem Artikel geht es darum, wie die alte Idee im Kontext des Deep Reinforcement Learning (RL) umgesetzt werden kann. Idee: Lassen Sie uns eine Person bitten, das Verhalten eines Agenten zu bewerten, und auf dieser Grundlage lernen wir die Belohnungsfunktion. Das Problem ist, dass tiefes RL sehr unersättlich ist und menschliche Zeit teuer ist. Der Artikel enthält eine Reihe von Hacks, mit denen Sie die Arbeitszeit auf angemessene Werte reduzieren können.
Die Belohnungsfunktion ist eine Funktion für Paare (Beobachtung, Aktion). Sie wird durch Mittelung der Vorhersage eines Ensembles neuronaler Netze festgelegt. Die verwendeten RL-Algorithmen (im Artikel A2C für Atari und TRPO für Mujoco) glauben, dass dieser Durchschnitt eine echte Belohnung ist, und sind darauf trainiert. Daher konzentriert sich der Artikel auf das Thema der Ausbildung dieses Ensembles.
Das Ensemble ist auf menschliche Bewertungen geschult. Jedes Rating ist wie folgt aufgebaut. Einer Person werden zwei Videos eines Agenten gezeigt, die 1-2 Sekunden lang sind. Er kann ein solches Paar auf vier Arten bewerten: links ist besser / rechts ist besser / zu ähnlich / unvergleichlich. Wenn eine Person "unvergleichlich" sagte, wird eine solche Bewertung weggeworfen. Andernfalls wird an das Tripel (σ¹, σ², μ) erinnert, wobei σⁱ die Flugbahn des Agenten im entsprechenden Video ist (d. H. Die Liste der Paare (obs, act)) und μ das Paar (1, 0), (0, 1) ist ) oder (½, ½). Ferner wird angenommen, dass die Vorhersage der Belohnung für die Flugbahn gleich der Summe der Vorhersagen für jedes Paar ist (obs, act). Schließlich optimieren wir einfach softmax_cross_entropy_with_logits.
Es wird angenommen, dass eine Person mit einer Wahrscheinlichkeit von 10% eine zufällige Antwort auswählt, und dies wird bei der Erstellung einer Trainingsstichprobe berücksichtigt. Abschnitt 2.2.3 des Artikels enthält einige weitere Tricks und schreibt alle Formeln auf.
Paare von Clips zur Demonstration für eine Person werden wie folgt ausgewählt: Eine große Anzahl von Clips wird abgetastet, die Streuung des Ensembles wird darauf berücksichtigt, und zufällige Paare von Clips mit hoher Streuung werden Personen gezeigt. Die Autoren sagen, dass ich nach dem Wert der Informationen wählen möchte, aber dies ist eine zukünftige Arbeit.
Die Autoren führen Tests mit Atari und Mujoco durch, wobei echte menschliche Bewertungen (beauftragte Auftragnehmer) und synthetische (Bewertungen werden gemäß der tatsächlichen Belohnungsfunktion generiert) und gleichzeitig mit den üblichen RL verglichen werden. Bei ungefähr gleicher Anzahl von Bewertungen funktionieren synthetische und reale Tests ähnlich. Darüber hinaus funktioniert reguläres RL (das die wahre Belohnungsfunktion sieht) überraschenderweise nicht unbedingt besser.
Zusätzlich zu dem Versuch, den Agenten zu schulen, um eine Menge Belohnung im üblichen Sinne zu erhalten, enthält der Artikel Beispiele für zwei weitere Aufgaben: Der Hopper in Mujoco macht einen Backflip, und die Maschine in Atari Enduro überholt keine anderen Autos, sondern fährt parallel zu ihnen. Es stellte sich heraus, beide Probleme zu lösen.
Fazit: Das Beispiel beschreibt einen Versuch, diesen Artikel zu reproduzieren. Der Versuch war erfolgreich, aber es dauerte 8 Monate Arbeit in der Freizeit und 220 Stunden reine Zeit, von denen die Hälfte für das Debuggen der einfachsten Version verwendet wurde.
5. Erkundung zufällig verdrahteter neuronaler Netze zur Bilderkennung
Autoren: Saining Xie, Alexander Kirillov, Ross Girshick und Kaiming He (Facebook AI Research, 2019)
→ Originalartikel
Rezensionsautor: Egor Panfilov (in slack tutk1ja)
Einführung:
Die Arbeit wirft das Problem der Generierung der Architektur neuronaler Netze auf. Derzeit sind viele Architekturtricks bekannt (LSTM, Inception, ResNet, DenseNet), die die Qualität vieler Aufgaben verbessern können, aber auch eine bestimmte starke Architektur vor dem Modell einführen. Anstelle der genannten Lösungen treibt Google die Suche nach neuronalen Architekturen (NAS) voran, bei der die Architektursuche für eine bestimmte Aufgabe aus vordefinierten Modulen über RL - NASNet, AmoebaNet durchgeführt wird.
Die Autoren argumentieren, dass beide Ansätze, bei denen das Design vom Menschen und von NAS bestimmt wird, vor der Architektur zu streng eingeführt werden. Um dies zu reduzieren, versuchen sie, den parametrischen generativen Ansatz des neuronalen Netzwerks zu verwenden, bei dem die Verdrahtung (Verbindung) von Elementen zufällig erfolgt. Es stellt sich heraus, dass Wissenschaftler wie A. Turing, M. Minsky und F. Rosenblatt seit den 1940er Jahren zufällige Verdrahtungsansätze untersucht haben. Als weiteres Argument erinnern die Autoren daran, dass in neurowissenschaftlichen Studien gezeigt wurde, dass die Struktur neuronaler Verbindungen in Organismen einer Art unterschiedlich ist (natürlich bis zu einem gewissen Detaillierungsgrad). Dies gilt sowohl für Würmer als auch für menschliche Babys. Im Allgemeinen klingt die Idee der prozeduralen Erzeugung neuronaler Netze interessant und vielversprechend, worum es in der Arbeit geht.
Methode:
Versuchen wir, den Prozess der prozeduralen Generierung der neuronalen Netzwerkarchitektur durch einen Graph-Ansatz zu modularisieren. Die ersten Schritte sind wie folgt:
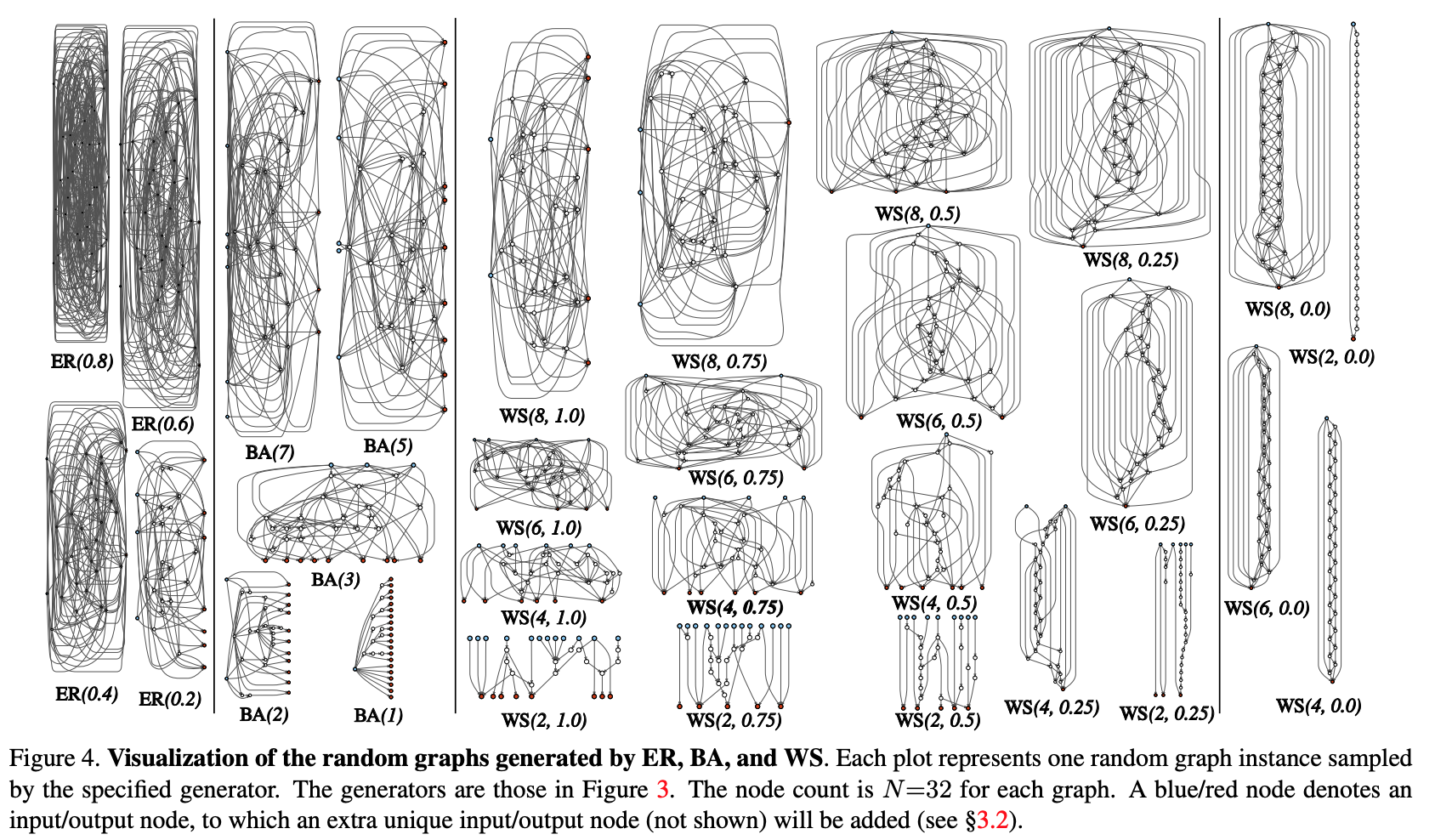
- Ein stochastischer Graph wird aus einer parametrisierten Familie erzeugt. Es werden klassische Methoden verwendet: Erdos-Renyi (ER), Barabasi-Albert (BA) und Watts-Strogatz (WS).
- Der Graph wird in ein neuronales Netzwerk konvertiert:
- Es wird angenommen, dass alle Kanten des Graphen gerichtete Träger von Datentensoren sind.
- Für jeden Scheitelpunkt des Graphen wird die Art der Operation bestimmt, die er ausführt: (I) Aggregation durch Summieren mit den trainierten Gewichten, (II) Transformation - ReLU + Faltung + BN, (III) Verteilung - Übertragung des Tensors entlang jeder Ausgangskante;
- Gemäß den Ergebnissen des vorherigen Unterabschnitts kann es mehrere Eingabe- und Ausgabescheitelpunkte geben, aber ich möchte 1 Einstiegspunkt im Diagramm und 1 Ausgabepunkt haben. Solche Knoten werden separat erstellt. Bei der Eingabe wird einfach eine Kopie des Tensors auf alle Eingabescheitelpunkte des Diagramms verteilt, bei der Ausgabe wird der ungewichtete Durchschnitt aller Ausgabescheitelpunkte berücksichtigt. Als Ergebnis der Schritte 1 und 2 wird tatsächlich kein vollständiges Netzwerk erstellt, sondern nur eines der Module (wie conv_1, ...) Faltungscodierer). Um das neuronale Netzwerk vollständig zu erhalten:
- Mehrere Module werden erstellt und in Reihe geschaltet. Um die Anzahl der Netzwerkparameter zu verringern, werden Transformationen an allen Eingangsscheitelpunkten der Module mit einem Schritt von 2x2 durchgeführt. Die Anzahl der Kanäle beim Übergang zum nächsten Modul erhöht sich um das Zweifache. So führen Sie Experimente zu einer bestimmten Aufgabe durch:
- Der Kopf für die Klassifizierung wird zur Ausgabe des Netzwerks hinzugefügt.
Ergebnisse:
Die Methode wurde auf das Klassifizierungsproblem in ImageNet getestet. Die Qualität des generierten neuronalen Netzwerks entsprach den SotA-Architekturen und verlor etwas an dem aktuellen DeepBrain AmoebaNet von Google: (mit einer vergleichbaren Anzahl von Parametern).
Wir haben überprüft, was passieren würde, wenn wir einen zufälligen Scheitelpunkt / eine zufällige Kante aus dem resultierenden Diagramm entfernen würden. Metrik - Qualitätsreduzierung in Abhängigkeit von der benachbarten Anzahl der Ausgabekanten bzw. Eingabescheitelpunkte. Im Allgemeinen sinkt die Qualität, ist aber nicht kritisch.
Die Autoren überprüften auch, ob Transferlernen mit dieser Architektur funktioniert. Bei der COCO-Erkennungsaufgabe wurde das Backbone Faster R-CNN mit FPN durch ein generiertes und vorab trainiertes Netzwerk ersetzt. Die Ergebnisse zeigten, dass die Qualität des Modells nicht schlechter ist als die von ResNeXt-50 / -101. Aber selbst die Tatsache, dass das Transferlernen beginnt, ist ziemlich unterhaltsam.
6. Photofeeler-D3: Ein neuronales Netzwerk mit Voter-Modellierung zur Datierung von Fotobewertungen
Autoren des Artikels: Agastya Kalra und Ben Peterson (Photofeeler Inc., 2019)
→ Originalartikel
Rezensionsautor: Alex Chiron (in sliron shiron8bit)
Die Autoren schlagen Photofeeler-D3 vor: eine Netzwerkarchitektur zur Bewertung von Fotos von Dating-Sites in drei Richtungen / Merkmalen - wie intelligent eine Person erscheint, vertrauenswürdig und attraktiv (vernachlässigen Sie den Halo-Effekt!). Die Aufgabe ergab sich aus einer Umfrage von The Guardian, nach der 90% der Menschen einen zukünftigen Termin ausschließlich auf der Grundlage der Auswertung von Fotos eines potenziellen Satelliten festlegen
Das Netzwerk besteht also aus folgenden Blöcken:
- ( ) — (GAP ), 10 ( ) — temporary output.
- ( , voter model) - (voter), , temporary output , , 10 v_ij (( 10 [0;1]). v_ij [0.05, 0.15, 0.25...0.95].
- , 200 , .
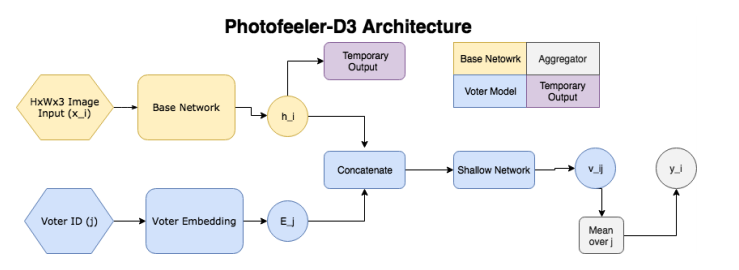
, , , , . Facial Beauty Prediction (FBP) SCUT-FBP Hot-Or-Not, , Photofeeler, . : +100k , 1.2 , (200 ) 200 (50 ). , 600px. 10000 8000 . , 0 3, [0,1] ( , ).
:
- (backbone , , etc) (20000 train, 3000 val, 2311 test), xception 600x600.
- , (temporary output) KL- ( , , 10 [0,1]).
- voter model one-hot .
- voter' , 2 .
- trait' 2 , .:
- ~80% , London Faces , prettyscale.com hotness.ai (81 53 52).
- FBP (SCUT-FBP Hot-Or-Not) , SOTA.
- , , 10
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
: D. Berthelot, N. Carlini, IJ Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→
: ( JanRocketMan)
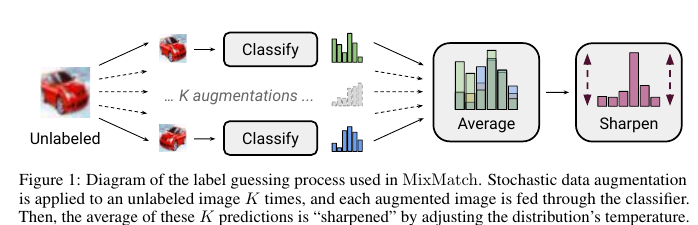
MeanTeacher Mixup- SOT- Semi-Supervised Learning (SSL) . , SSL consistency regularization. , ( ) "" , . Mean Teacher ( — c EMA ), — Mixup ( ). , . :
- unsupervised , .
"" p. - "" , one-hot. : . T , , , ( ), .
- , . , SVHN, STL CIFAR10.
CIFAR10 90% accuracy 250 . — VAT, 60%. SVHN - 96% 250- , VAT Mean Teacher 90.
STL10 90% 1 , - CCGAN, 80. , :
- , ( );
- GridSearch- ;
c. SSL SVHN .
8. Divide and Conquer the Embedding Space for Metric Learning
: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→
: ( Alexander Denisenko)
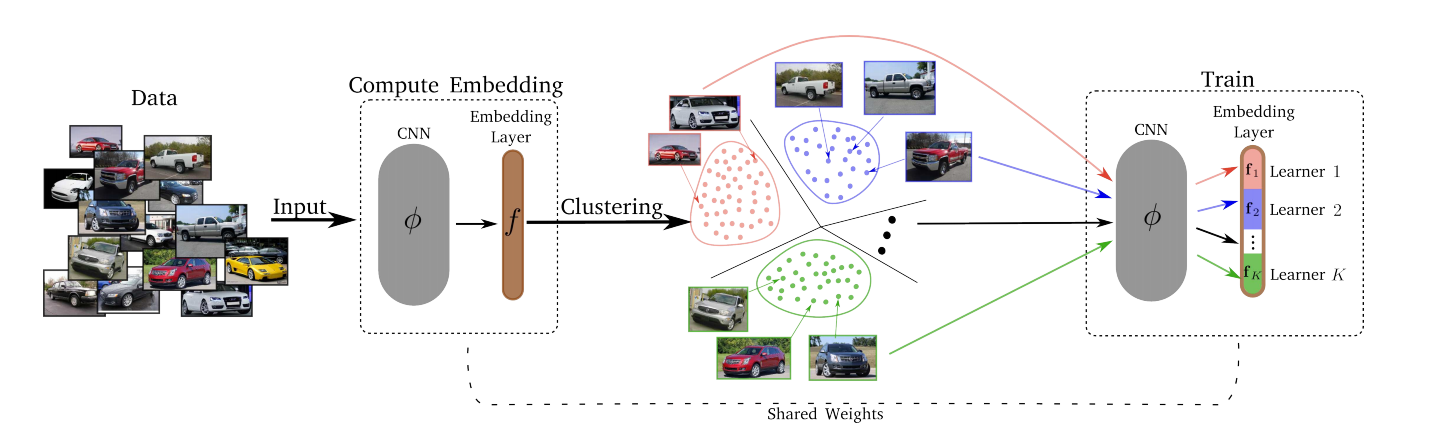
— , . , , – , , , ..
, :
- Divide.
- k-means. . . Embedding layer K . – . d/K (d – ). - Erobern.
Nach der Divide-Phase wird jeder der K-Cluster einem der K-Lerner zugeordnet. Lerners trainieren der Reihe nach, dh zu jedem bestimmten Zeitpunkt haben wir einen Cluster ausgewählt, auf dem das Training stattfindet, aus dem ein Mini-Batch entnommen wird, und der entsprechende Lerner minimiert seinen Verlust durch Aktualisierung seiner Parameter. Der Raum der Einbettungen wird im Laufe der Zeit aktualisiert, so dass jede T-Epoche, Clustering (Teilen), neu durchgeführt wird. - Merjim - wir verketten alle Lerner (Scheiben der Einbettungsschicht). Dann trainieren wir die Einbettungsschicht auf dem gesamten Datensatz, um die Lerners-Freunde zu finden.
Experimentelle Ergebnisse: Jeder gewann mit mehreren Datensätzen.
Verlust kann alles sein - Triplett-Verlust, Margin-Verlust, Proxy-NCA usw.
Die optimale Anzahl von K Lerners betrug 8 (die Dimension des gesamten Einbettungsraums betrug 128, so dass jeder Lerner seine Teilaufgabe im 16-dimensionalen Raum löste).
Eine Änderung von T von 1 auf 10 hatte keinen signifikanten Einfluss auf etwas, daher wurde T = 2 verwendet.