Wir präsentieren einen ausführlichen Spickzettel, in dem wir in einfachen Worten erklären, woraus künstliche Intelligenz besteht und wie alles funktioniert.
Was ist der Unterschied zwischen künstlicher Intelligenz, maschinellem Lernen und Datenwissenschaft?
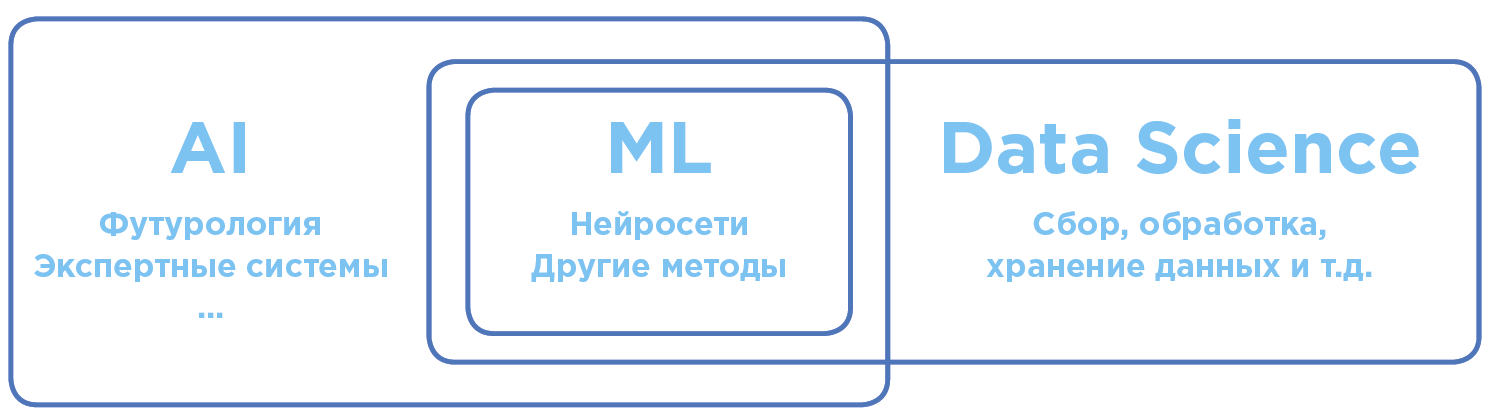 Differenzierung von Konzepten im Bereich der künstlichen Intelligenz und Datenanalyse.
Differenzierung von Konzepten im Bereich der künstlichen Intelligenz und Datenanalyse.Künstliche Intelligenz - KI (Künstliche Intelligenz)
Im globalen universellen Sinne ist KI der Begriff so weit wie möglich. Es umfasst sowohl wissenschaftliche Theorien als auch spezifische technologische Praktiken zur Erstellung von Programmen, die der menschlichen Intelligenz nahe kommen.
Maschinelles Lernen - ML (Maschinelles Lernen)
Abschnitt AI, aktiv in der Praxis angewendet. Wenn es heute um die Verwendung von KI in Unternehmen oder in der Fertigung geht, meinen wir meistens maschinelles Lernen.
ML-Algorithmen arbeiten in der Regel nach dem Prinzip eines mathematischen Lernmodells, das eine Analyse auf der Grundlage einer großen Datenmenge durchführt, während Schlussfolgerungen gezogen werden, ohne streng definierte Regeln zu befolgen.
Die häufigste Art von Aufgabe beim maschinellen Lernen ist das Lernen mit einem Lehrer. Um diese Art von Problemen zu lösen, wird eine Reihe von Daten trainiert, für die die Antwort im Voraus bekannt ist (siehe unten).
Data Science - DS (Datenwissenschaft)
Die Wissenschaft und Praxis der Analyse großer Datenmengen mit allen Arten von mathematischen Methoden, einschließlich maschinellem Lernen, sowie der Lösung verwandter Aufgaben im Zusammenhang mit der Erfassung, Speicherung und Verarbeitung von Datenfeldern.
Data Scientists sind insbesondere Datenexperten, die mithilfe von maschinellem Lernen analysieren.

Wie funktioniert maschinelles Lernen?
Betrachten Sie die Arbeit von ML am Beispiel der Aufgabe des Banking Scoring. Die Bank verfügt über Daten zu bestehenden Kunden. Er weiß, ob jemand überfällige Kreditzahlungen hat. Die Aufgabe besteht darin, festzustellen, ob ein neuer potenzieller Kunde pünktliche Zahlungen leistet. Für jeden Kunden hat die Bank eine Kombination bestimmter Merkmale / Merkmale: Geschlecht, Alter, monatliches Einkommen, Beruf, Wohnort, Bildung usw. Zu den Merkmalen gehören möglicherweise schlecht strukturierte Parameter wie Daten aus sozialen Netzwerken oder Kaufhistorie. Darüber hinaus können Daten mit Informationen aus externen Quellen angereichert werden: Wechselkurse, Daten von Kreditauskunfteien usw.
Eine Maschine sieht jeden Client als eine Kombination von Funktionen:
. Wo zum Beispiel
- Alter
- Einkommen und
- die Anzahl der Fotos teurer Einkäufe pro Monat (in der Praxis arbeitet Data Scientist im Rahmen einer ähnlichen Aufgabe mit mehr als hundert Funktionen). Jeder Client hat eine weitere Variable -
mit zwei möglichen Ergebnissen: 1 (es gibt verspätete Zahlungen) oder 0 (keine verspäteten Zahlungen).
Gesamtheit aller Daten
und
- Es gibt einen Datensatz. Mit diesen Daten erstellt Data Scientist ein Modell
, Auswählen und Ändern des Algorithmus für maschinelles Lernen.
In diesem Fall sieht das Analysemodell folgendermaßen aus:
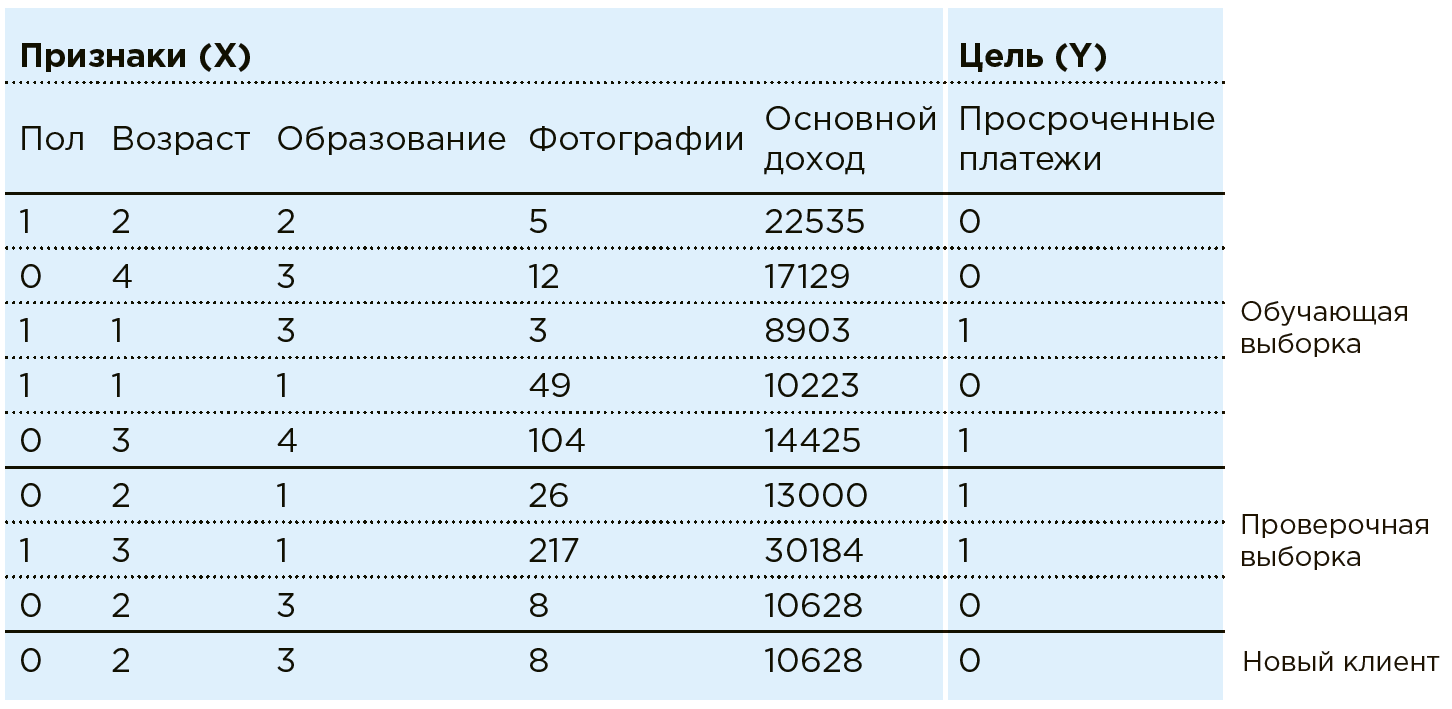
Algorithmen für maschinelles Lernen implizieren eine schrittweise Annäherung der Modellantworten
auf die wahren Antworten (die im Trainingsdatensatz im Voraus bekannt sind). Dies ist eine Ausbildung mit einem Lehrer in einer bestimmten Stichprobe.
In der Praxis lernt die Maschine meistens nur auf einem Teil des Arrays (80%), wobei der Rest (20%) verwendet wird, um die Richtigkeit des ausgewählten Algorithmus zu überprüfen. Beispielsweise kann ein System auf einem Array trainiert werden, von dem Daten eines Paares von Regionen ausgeschlossen sind, auf dem die Genauigkeit des Modells danach überprüft wird.
Nun, wenn ein neuer Kunde zur Bank kommt, wonach
Die Bank ist noch nicht bekannt. Das System teilt die Zuverlässigkeit des Zahlers anhand der ihm bekannten Daten mit
.
Das Unterrichten mit einem Lehrer ist jedoch nicht die einzige Klasse von Problemen, die ML lösen kann.
Ein weiterer Aufgabenbereich ist das Clustering, bei dem Objekte nach ihren Attributen getrennt werden können, um beispielsweise verschiedene Kategorien von Kunden zu identifizieren, damit diese individuelle Angebote machen können.
Mit Hilfe von ML-Algorithmen werden auch Aufgaben wie die Modellierung der Kommunikation zwischen einem Support-Spezialisten oder die Erstellung von Kunstwerken gelöst, die nicht von menschlichen Kreationen zu unterscheiden sind (z. B. malen Bilder aus neuronalen Netzen).
Eine neue und beliebte Klasse von Aufgaben ist das Verstärkungstraining, das in einer begrenzten Umgebung stattfindet, in der die Aktionen von Agenten bewertet werden (mit diesem Algorithmus wurde beispielsweise AlphaGo erstellt, das die Person in Go besiegt hat).

Neuronales Netz
Eine der Methoden des maschinellen Lernens. Ein Algorithmus, der von der Struktur des menschlichen Gehirns inspiriert ist und auf Neuronen und den Verbindungen zwischen ihnen basiert. Während des Lernprozesses werden die Verbindungen zwischen Neuronen so angepasst, dass Fehler des gesamten Netzwerks minimiert werden.
Ein Merkmal neuronaler Netze ist das Vorhandensein von Architekturen, die für nahezu jedes Datenformat geeignet sind: Faltungs-Neuronale Netze zum Analysieren von Bildern, wiederkehrende Neuronale Netze zum Analysieren von Texten und Sequenzen, Auto-Encoder zur Datenkomprimierung, generative neuronale Netze zum Erstellen neuer Objekte usw.
Gleichzeitig weisen fast alle neuronalen Netze eine erhebliche Einschränkung auf - für ihr Training wird eine große Datenmenge benötigt (Größenordnungen größer als die Anzahl der Verbindungen zwischen Neuronen in diesem Netz). Aufgrund der Tatsache, dass in letzter Zeit das zur Analyse bereitgestellte Datenvolumen erheblich zugenommen hat, wächst auch der Umfang. Mit Hilfe von neuronalen Netzen werden heute beispielsweise Bilderkennungsaufgaben gelöst, beispielsweise das Bestimmen des Alters und des Geschlechts einer Person anhand eines Videos oder das Tragen eines Helms am Arbeiter.
Interpretation des Ergebnisses
Der Abschnitt Data Science, in dem die Gründe für die Auswahl der einen oder anderen Lösung nach dem ML-Modell erläutert werden.
Es gibt zwei Hauptforschungsbereiche:
- Studieren des Modells als Black Box. Der Algorithmus analysiert die darin geladenen Beispiele und vergleicht die Merkmale dieser Beispiele und die Schlussfolgerungen des Algorithmus, um Schlussfolgerungen über die Priorität eines dieser Beispiele zu ziehen. Bei neuronalen Netzen wird üblicherweise eine Blackbox verwendet.
- Untersuchung der Eigenschaften des Modells selbst. Die Untersuchung der Merkmale, anhand derer das Modell den Grad ihrer Bedeutung bestimmt. Wird am häufigsten auf Algorithmen angewendet, die auf der Entscheidungsbaummethode basieren.
Zum Beispiel bei der Vorhersage von Produktionsfehlern Anzeichen von Objekten
- Dies sind die Daten zu den Einstellungen der Maschinen, der chemischen Zusammensetzung der Rohstoffe, den Indikatoren der Sensoren, dem Video vom Förderband usw.
- Dies sind die Antworten auf die Frage, ob es eine Ehe geben wird oder nicht.
Natürlich interessiert sich die Produktion nicht nur für die Vorhersage der Ehe selbst, sondern auch für die Interpretation des Ergebnisses, d. H. Die Gründe für die Ehe für ihre spätere Beseitigung. Dies kann eine lange Abwesenheit von Maschinenwartung, die Qualität der Rohstoffe oder einfach abnormale Messwerte einiger Sensoren sein, auf die der Techniker achten sollte.
Daher sollte im Rahmen des Projekts zur Vorhersage der Ehe in der Produktion nicht nur ein ML-Modell erstellt werden, sondern es sollte auch daran gearbeitet werden, es zu interpretieren, dh Faktoren zu identifizieren, die die Ehe beeinflussen.

Wann ist maschinelles Lernen effektiv?
Wenn es eine große Menge statistischer Daten gibt, es jedoch unmöglich oder sehr mühsam ist, Abhängigkeiten mit fachmännischen oder klassischen mathematischen Methoden zu finden. Wenn also mehr als tausend Parameter am Eingang vorhanden sind (darunter sowohl numerische als auch Textparameter sowie Video, Audio und Bilder), ist es ohne Maschine unmöglich, die Abhängigkeit des Ergebnisses von ihnen zu ermitteln.
Zusätzlich zu den Substanzen, die selbst in die Wechselwirkung eintreten, wird eine chemische Reaktion beispielsweise von vielen Parametern beeinflusst: Temperatur, Feuchtigkeit, Material des Behälters, in dem sie auftritt usw. Für einen Chemiker ist es schwierig, alle diese Zeichen zu berücksichtigen, um die Reaktionszeit genau zu berechnen. Höchstwahrscheinlich wird er mehrere Schlüsselparameter berücksichtigen und auf seinen Erfahrungen basieren. Gleichzeitig kann maschinelles Lernen auf der Grundlage der Daten früherer Reaktionen alle Anzeichen berücksichtigen und eine genauere Prognose abgeben.
Wie hängen Big Data und maschinelles Lernen zusammen?
Um maschinelle Lernmodelle zu erstellen, sind in verschiedenen Fällen numerische, Text-, Foto-, Video-, Audio- und andere Daten erforderlich. Um diese Informationen zu speichern und zu analysieren, gibt es einen ganzen Technologiebereich - Big Data. Für eine optimale Datenspeicherung und -analyse erstellen sie „Data Lake“ - einen speziellen verteilten Speicher für große Mengen schlecht strukturierter Informationen, die auf Big Data-Technologien basieren.
Digitales Doppel als elektronischer Reisepass
Ein digitales Double ist eine virtuelle Kopie eines realen materiellen Objekts, Prozesses oder einer realen Organisation, mit der Sie das Verhalten des untersuchten Objekts / Prozesses simulieren können. Beispielsweise können Sie vorab die Ergebnisse von Änderungen der chemischen Zusammensetzung im Werk nach Änderungen der Einstellungen der Produktionslinien, Änderungen des Umsatzes nach einer Werbekampagne mit bestimmten Merkmalen usw. anzeigen. In diesem Fall werden Prognosen durch ein digitales Double basierend auf den gesammelten Daten erstellt und Szenarien und zukünftige Situationen modelliert einschließlich Methoden des maschinellen Lernens.
Was wird für qualitativ hochwertiges maschinelles Lernen benötigt?
Data Scientiest! Sie erstellen den Prognosealgorithmus: Sie untersuchen die verfügbaren Daten, stellen Hypothesen auf und erstellen Modelle auf der Grundlage des Datensatzes. Sie sollten über drei Hauptkompetenzgruppen verfügen: IT-Kenntnisse, mathematische und statistische Kenntnisse sowie fundierte Erfahrung in einem bestimmten Bereich.
Maschinelles Lernen steht auf drei Säulen
DatenabrufVerwendbare Daten aus verwandten Systemen: Arbeitsplan, Verkaufsplan. Daten können auch durch externe Quellen angereichert werden: Wechselkurse, Wetter, Feiertagskalender usw. Es ist erforderlich, eine Methodik für die Arbeit mit jedem Datentyp zu entwickeln und eine Pipeline zu überlegen, um sie in ein Modellformat für maschinelles Lernen (eine Reihe von Zahlen) umzuwandeln.
CharakterisierungEs wird zusammen mit Experten aus dem erforderlichen Bereich durchgeführt. Dies hilft bei der Berechnung von Daten, die für Prognosezwecke gut geeignet sind: Statistiken und Änderungen der Anzahl der Verkäufe im letzten Monat für Marktprognosen.
Modell des maschinellen LernensDie Methode zur Lösung dieses Geschäftsproblems wird vom Datenwissenschaftler unabhängig auf der Grundlage seiner Erfahrung und der Fähigkeiten verschiedener Modelle ausgewählt. Für jede spezifische Aufgabe müssen Sie einen separaten Algorithmus auswählen. Die Geschwindigkeit und Genauigkeit des Ergebnisses der Quelldatenverarbeitung hängt direkt von der ausgewählten Methode ab.
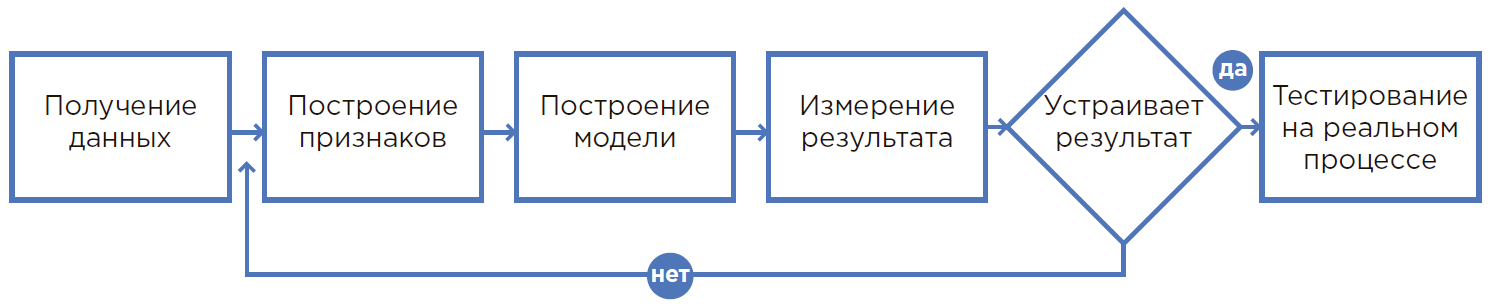 Der Prozess der Erstellung eines ML-Modells.
Der Prozess der Erstellung eines ML-Modells.Von der Hypothese zum Ergebnis
1. Alles beginnt mit einer Hypothese
Eine Hypothese entsteht, wenn der Problemprozess, die Erfahrung der Mitarbeiter oder ein neuer Blick auf die Produktion analysiert werden. In der Regel wirkt sich eine Hypothese auf einen Prozess aus, bei dem eine Person physisch nicht in der Lage ist, viele Faktoren zu berücksichtigen, und Rundungen, Annahmen oder einfach das verwendet, was sie immer getan hat.
In diesem Prozess können Sie durch den Einsatz von maschinellem Lernen wesentlich mehr Informationen verwenden, um Entscheidungen zu treffen. Daher können Sie deutlich bessere Ergebnisse erzielen. Darüber hinaus minimieren die Automatisierung von Prozessen mit ML und die Verringerung der Abhängigkeit von einer bestimmten Person den menschlichen Faktor (Krankheit, niedrige Konzentration usw.) erheblich.
2. Bewertung der Hypothese
Basierend auf der formulierten Hypothese werden die Daten ausgewählt, die für die Entwicklung eines maschinellen Lernmodells erforderlich sind. Es wird nach den relevanten Daten gesucht und bewertet, ob sie geeignet sind, das Modell in die aktuellen Prozesse einzubetten, wer seine Benutzer sein wird und aufgrund dessen der Effekt erzielt wird. Bei Bedarf werden organisatorische und sonstige Änderungen vorgenommen.
3. Berechnung des wirtschaftlichen Effekts und der Kapitalrendite (ROI)
Die Bewertung der wirtschaftlichen Auswirkungen der implementierten Lösung wird von Spezialisten in Zusammenarbeit mit den relevanten Abteilungen durchgeführt: Effizienz, Finanzen usw. In dieser Phase müssen Sie verstehen, wie genau die Metrik ist (Anzahl korrekt identifizierter Kunden / Steigerung der Produktion / Einsparung von Verbrauchsmaterialien usw.) und das gemessene Ziel klar artikulieren.
4. Die mathematische Formulierung des Problems
Nachdem Sie das Geschäftsergebnis verstanden haben, müssen Sie es auf die mathematische Ebene verschieben, um Messmetriken und Einschränkungen zu definieren, die nicht verletzt werden können. Datenstufen Daten
Ein Wissenschaftler tritt in Zusammenarbeit mit einem Geschäftskunden auf.
5. Datenerfassung und -analyse
Es ist notwendig, Daten an einem Ort zu sammeln, sie unter Berücksichtigung verschiedener Statistiken zu analysieren, die Struktur und die verborgenen Beziehungen dieser Daten zu verstehen, um Zeichen zu bilden.
6. Erstellen eines Prototyps
Es ist in der Tat ein Test der Hypothese. Dies ist eine Gelegenheit, ein Modell auf aktuellen Daten aufzubauen und zunächst die Ergebnisse seiner Arbeit zu überprüfen. In der Regel wird ein Prototyp aus vorhandenen Daten erstellt, ohne Integrationen zu entwickeln und in Echtzeit mit einem Stream zu arbeiten.
Prototyping ist eine schnelle und kostengünstige Möglichkeit, um zu überprüfen, ob ein Problem gelöst wird. Dies ist sehr nützlich, wenn nicht im Voraus verstanden werden kann, ob der gewünschte wirtschaftliche Effekt erzielt werden kann. Darüber hinaus können Sie durch die Erstellung eines Prototyps den Umfang und die Details des Projekts zur Implementierung der Lösung besser einschätzen und eine wirtschaftliche Begründung für eine solche Implementierung erstellen.
DevOps und DataOps
Während des Betriebs kann ein neuer Datentyp angezeigt werden (z. B. wird ein anderer Sensor an der Maschine angezeigt oder ein neuer Warentyp wird im Lager angezeigt). Anschließend muss das Modell geschult werden. DevOps und DataOps sind Methoden, mit denen die Zusammenarbeit und End-to-End-Prozesse zwischen Data Science-Teams, Datenaufbereitungsingenieuren, IT-Entwicklungs- und Betriebsservices eingerichtet und solche Ergänzungen schnell, fehlerfrei und ohne jedes Mal eindeutig in den aktuellen Prozess integriert werden können Probleme.
7. Eine Lösung erstellen
In diesem Moment, in dem die Ergebnisse der Prototypenarbeit das sichere Erreichen von Indikatoren belegen, wird eine vollständige Lösung erstellt, bei der das Modell des maschinellen Lernens nur ein Bestandteil der untersuchten Prozesse ist. Als nächstes Integration, Installation der erforderlichen Ausrüstung, Schulung des Personals, Änderung der Entscheidungsprozesse usw.
8. Pilot- und Industriebetrieb
Während des Testbetriebs arbeitet das System in der Art der Beratung, während der Spezialist die üblichen Aktionen wiederholt, wobei jedes Mal Feedback zu den erforderlichen Verbesserungen des Systems gegeben und die Genauigkeit der Prognosen erhöht wird.
Der letzte Teil ist der industrielle Betrieb, wenn die etablierten Prozesse auf vollautomatische Wartung umgestellt werden.
Sie können den Spickzettel über den
Link herunterladen.
Morgen im Forum für künstliche Intelligenzsysteme
RAIF 2019 von 09:30 bis 10:45 Uhr findet eine Podiumsdiskussion statt: "KI für Menschen: Wir verstehen in einfachen Worten."
In diesem Abschnitt erklären die Redner in einem Debattenformat komplexe Technologien mit einfachen Worten an Lebensbeispielen. Und diskutieren Sie auch über die folgenden Themen:
- Was ist der Unterschied zwischen künstlicher Intelligenz, maschinellem Lernen und Datenwissenschaft?
- Wie funktioniert maschinelles Lernen?
- Wie funktionieren neuronale Netze?
- Was wird für qualitativ hochwertiges maschinelles Lernen benötigt?
- Was ist Markup, Datenkennzeichnung?
- Was ist ein digitales Double und wie arbeitet man mit virtuellen Kopien realer materieller Objekte?
- Was ist das Wesentliche der Hypothese? Wie kommt man von der Art und Weise, wie es gestellt wird, zur Bewertung und Interpretation des Ergebnisses?
Die Diskussion wird besucht von:
Nikolay Marine, Technischer Direktor, IBM in Russland und der GUS
Alexey Natekin, Gründer von Open Data Science x Data Souls
Alexey Hakhunov, CTO, Dbrain
Evgeny Kolesnikov, Direktor, Zentrum für maschinelles Lernen, Jet Infosystems
Pavel Doronin, CEO von AI Today
Die Diskussion wird Ende Oktober auf
dem YouTube-Kanal von Jet Infosystems verfügbar sein .