
2017 haben wir den Wettbewerb für die Entwicklung des Transaktionskerns für das Investmentgeschäft der Alfa-Bank gewonnen und sofort mit der Arbeit begonnen. (Vladimir Drynkin, Leiter des Entwicklungsteams für den Investment Business Transaction Core der Alfa-Bank,
sprach auf der HighLoad ++ 2018 über den Investment Business Core.) Dieses System sollte Transaktionsdaten in verschiedenen Formaten aus verschiedenen Quellen zusammenfassen, die Daten vereinheitlichen, speichern und Zugriff darauf gewähren.
Im Laufe der Entwicklung hat das System seine Funktionen weiterentwickelt und erweitert. Irgendwann wurde uns klar, dass wir viel mehr als nur Anwendungssoftware für einen genau definierten Aufgabenbereich erstellt haben: Wir haben ein System zum Erstellen verteilter Anwendungen mit dauerhaftem Speicher erstellt. Unsere Erfahrung diente als Grundlage für das neue Produkt
Tarantool Data Grid (TDG).
Ich möchte über die TDG-Architektur und die Lösungen sprechen, die wir während der Entwicklung erarbeitet haben. Ich werde die Grundfunktionen vorstellen und zeigen, wie unser Produkt zur Grundlage für schlüsselfertige Lösungen werden kann.
In Bezug auf die Architektur haben wir das System in separate
Rollen unterteilt . Jeder von ihnen ist für eine bestimmte Reihe von Aufgaben verantwortlich. Eine laufende Instanz einer Anwendung implementiert einen oder mehrere Rollentypen. In einem Cluster können mehrere Rollen desselben Typs vorhanden sein:
Anschluss
Der Connector ist für die Kommunikation mit der Außenwelt verantwortlich. Es ist so konzipiert, dass es die Anforderung akzeptiert, analysiert und bei Erfolg die Daten zur Verarbeitung an den Eingabeprozessor sendet. Folgende Formate werden unterstützt: HTTP, SOAP, Kafka, FIX. Die Architektur ermöglicht es uns, Unterstützung für neue Formate hinzuzufügen (IBM MQ-Unterstützung wird in Kürze verfügbar sein). Wenn das Analysieren von Anforderungen fehlschlägt, gibt der Connector einen Fehler zurück. Andernfalls wird geantwortet, dass die Anforderung erfolgreich verarbeitet wurde, auch wenn bei der weiteren Verarbeitung ein Fehler aufgetreten ist. Dies geschieht absichtlich, um mit Systemen zu arbeiten, die nicht wissen, wie Anforderungen wiederholt werden sollen, oder umgekehrt, und zwar zu aggressiv. Um sicherzustellen, dass keine Daten verloren gehen, wird die Reparaturwarteschlange verwendet: Das Objekt tritt der Warteschlange bei und wird erst nach erfolgreicher Verarbeitung aus der Warteschlange entfernt. Der Administrator erhält Benachrichtigungen über die in der Reparaturwarteschlange verbleibenden Objekte und kann die Verarbeitung nach Behandlung eines Softwarefehlers oder eines Hardwarefehlers wiederholen.
Eingabeprozessor
Der Eingabeprozessor kategorisiert die empfangenen Daten nach Merkmalen und ruft die entsprechenden Handler auf. Handler sind Lua-Code, der in einer Sandbox ausgeführt wird, sodass sie den Systembetrieb nicht beeinflussen können. In diesem Stadium könnten die Daten nach Bedarf transformiert werden, und bei Bedarf können beliebig viele Aufgaben ausgeführt werden, um die erforderliche Logik zu implementieren. Wenn Sie beispielsweise einen neuen Benutzer in MDM hinzufügen (Master Data Management basierend auf Tarantool Data Grid), wird ein goldener Datensatz als separate Aufgabe erstellt, damit die Anforderungsverarbeitung nicht verlangsamt wird. Die Sandbox unterstützt Anforderungen zum Lesen, Ändern und Hinzufügen von Daten. Außerdem können Sie eine Funktion für alle Rollen des Speichertyps aufrufen und das Ergebnis aggregieren (Zuordnen / Reduzieren).
Handler können in Dateien beschrieben werden:
sum.lua local x, y = unpack(...) return x + y
Dann in der Konfiguration deklariert:
functions: sum: { __file: sum.lua }
Warum Lua? Lua ist eine einfache Sprache. Basierend auf unserer Erfahrung beginnen Menschen, Code zu schreiben, der ihr Problem nur ein paar Stunden nach dem ersten Sehen der Sprache löst. Und das sind nicht nur professionelle Entwickler, sondern zum Beispiel Analysten. Darüber hinaus ist Lua dank des JIT-Compilers sppedy.
Lagerung
Der Speicher speichert persistente Daten. Vor dem Speichern werden die Daten auf Übereinstimmung mit dem Datenschema überprüft. Zur Beschreibung des Schemas verwenden wir das erweiterte
Apache Avro- Format. Beispiel:
{ "name": "User", "type": "record", "logicalType": "Aggregate", "fields": [ { "name": "id", "type": "string" }, { "name": "first_name", "type": "string" }, { "name": "last_name", "type": "string" } ], "indexes": ["id"] }
Basierend auf dieser Beschreibung werden DDL (Data Definition Language) für Tarantool DBMS und
GraphQL- Schema für den Datenzugriff automatisch generiert.
Die asynchrone Datenreplikation wird unterstützt (wir planen auch die synchrone Replikation).
Ausgabeprozessor
Manchmal ist es notwendig, externe Verbraucher über die neuen Daten zu informieren. Deshalb haben wir die Rolle des Ausgabeprozessors. Nach dem Speichern der Daten können diese in den entsprechenden Handler übertragen werden (z. B. um sie gemäß den Anforderungen des Verbrauchers zu transformieren) und dann zum Senden an den Connector übertragen werden. Die Reparaturwarteschlange wird auch hier verwendet: Wenn niemand das Objekt akzeptiert, kann der Administrator es später erneut versuchen.
Skalieren
Die Rollen Connector, Input Processor und Output Processor sind zustandslos. Dadurch können wir das System horizontal skalieren, indem wir lediglich neue Anwendungsinstanzen mit der erforderlichen aktivierten Rolle hinzufügen. Für die horizontale Speicherskalierung wird ein Cluster mithilfe des Virtual Buckets-
Ansatzes organisiert . Nach dem Hinzufügen eines neuen Servers werden einige Buckets von den alten Servern auf einen neuen Server im Hintergrund verschoben. Dieser Prozess ist für die Benutzer transparent und wirkt sich nicht auf den Betrieb des gesamten Systems aus.
Dateneigenschaften
Objekte können sehr groß sein und andere Objekte enthalten. Wir stellen sicher, dass Daten atomar hinzugefügt und aktualisiert werden und das Objekt mit allen Abhängigkeiten von einem einzigen virtuellen Bucket gespeichert wird. Dies geschieht, um das sogenannte "Verschmieren" des Objekts über mehrere physische Server hinweg zu vermeiden.
Die Versionierung wird ebenfalls unterstützt: Jedes Update des Objekts erstellt eine neue Version, und wir können jederzeit eine Zeitscheibe erstellen, um zu sehen, wie alles zu der Zeit aussah. Für Daten, die keinen langen Verlauf benötigen, können wir die Anzahl der Versionen begrenzen oder sogar nur die letzte speichern, dh die Versionierung für einen bestimmten Datentyp deaktivieren. Wir können auch die historischen Grenzen festlegen: Löschen Sie beispielsweise alle Objekte eines bestimmten Typs, die älter als ein Jahr sind. Die Archivierung wird ebenfalls unterstützt: Wir können Objekte ab einem bestimmten Alter hochladen, um den Cluster-Speicherplatz freizugeben.
Aufgaben
Zu den interessanten Funktionen gehört die Möglichkeit, Aufgaben pünktlich, auf Benutzerwunsch oder automatisch über die Sandbox auszuführen:
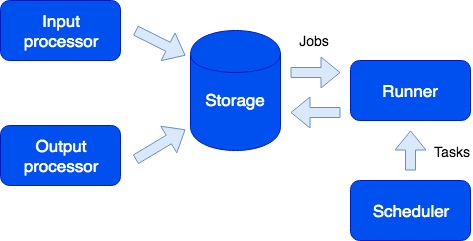
Hier sehen wir eine andere Rolle namens Runner. Diese Rolle hat keinen Staat; Bei Bedarf können dem Cluster weitere Anwendungsinstanzen mit dieser Rolle hinzugefügt werden. Der Runner ist für die Ausführung der Aufgaben verantwortlich. Wie bereits erwähnt, können neue Aufgaben aus der Sandbox erstellt werden. Sie treten der Warteschlange im Speicher bei und werden dann auf dem Läufer ausgeführt. Diese Art von Aufgaben wird als Job bezeichnet. Wir haben auch einen Aufgabentyp namens Task, dh eine benutzerdefinierte Aufgabe, die pünktlich (unter Verwendung der Cron-Syntax) oder bei Bedarf ausgeführt wird. Um solche Aufgaben auszuführen und zu verfolgen, verfügen wir über einen praktischen Task-Manager. Die Scheduler-Rolle muss aktiviert sein, um diese Funktion verwenden zu können. Diese Rolle hat einen Status, daher wird sie nicht skaliert, was ohnehin nicht erforderlich ist. Wie bei jeder anderen Rolle kann es jedoch eine Replik geben, die funktioniert, wenn der Master plötzlich ausfällt.
Logger
Eine andere Rolle heißt Logger. Es sammelt Protokolle aller Clustermitglieder und bietet eine Schnittstelle zum Hochladen und Anzeigen über die Weboberfläche.
Dienstleistungen
Es ist erwähnenswert, dass das System das Erstellen von Diensten vereinfacht. In der Konfigurationsdatei können Sie angeben, welche Anforderungen an den vom Benutzer geschriebenen Handler gesendet werden sollen, der in der Sandbox ausgeführt wird. Ein solcher Handler kann beispielsweise eine Art analytische Anforderung ausführen und das Ergebnis zurückgeben.
Der Dienst wird in der Konfigurationsdatei beschrieben:
services: sum: doc: "adds two numbers" function: sum return_type: int args: x: int y: int
Die GraphQL-API wird automatisch generiert und der Dienst steht für Aufrufe zur Verfügung:
query { sum(x: 1, y: 2) }
Dies ruft den Summenhandler auf, der das Ergebnis zurückgibt:
3
Profilerstellung und Metriken anfordern
Wir haben die Unterstützung für das OpenTracing-Protokoll implementiert, um ein besseres Verständnis der Systemmechanismen und der Erstellung von Anforderungsprofilen zu ermöglichen. Bei Bedarf kann das System Informationen darüber, wie die Anforderung ausgeführt wurde, an Tools senden, die dieses Protokoll unterstützen (z. B. Zipkin):
Selbstverständlich bietet das System interne Metriken, die mit Prometheus erfasst und mit Grafana visualisiert werden können.
Bereitstellung
Tarantool Data Grid kann mithilfe des integrierten Dienstprogramms oder Ansible aus RPM-Paketen oder Archiven bereitgestellt werden. Kubernetes wird ebenfalls unterstützt (
Tarantool Kubernetes Operator ).
Eine Anwendung, die Geschäftslogik (Konfiguration, Handler) implementiert, wird über die Benutzeroberfläche oder als Skript unter Verwendung der bereitgestellten API in den bereitgestellten Tarantool Data Grid-Cluster im Archiv geladen.
Beispielanwendungen
Welche Anwendungen können Sie mit Tarantool Data Grid erstellen? Tatsächlich hängen die meisten Geschäftsaufgaben in irgendeiner Weise mit der Verarbeitung, Speicherung und dem Zugriff auf Datenströme zusammen. Wenn Sie also große Datenströme haben, die sicheren Speicher und Zugriff erfordern, kann unser Produkt Ihnen viel Zeit bei der Entwicklung sparen und Ihnen helfen, sich auf Ihre Geschäftslogik zu konzentrieren.
Sie möchten beispielsweise Informationen über den Immobilienmarkt sammeln, um über die besten Angebote der Zukunft auf dem Laufenden zu bleiben. In diesem Fall werden die folgenden Aufgaben herausgearbeitet:
- Roboter, die Informationen aus offenen Quellen sammeln, sind Ihre Datenquellen. Sie können dieses Problem mit vorgefertigten Lösungen oder durch Schreiben von Code in einer beliebigen Sprache lösen.
- Als Nächstes akzeptiert und speichert Tarantool Data Grid die Daten. Wenn das Datenformat aus verschiedenen Quellen unterschiedlich ist, können Sie in Lua Code schreiben, der alles in ein einziges Format konvertiert. In der Vorverarbeitungsphase können Sie beispielsweise auch wiederkehrende Angebote filtern oder Datenbankinformationen über auf dem Markt tätige Agenten weiter aktualisieren.
- Jetzt haben Sie bereits eine skalierbare Lösung im Cluster, die mit Daten gefüllt und zum Erstellen von Datenproben verwendet werden kann. Anschließend können Sie neue Funktionen implementieren, z. B. einen Dienst schreiben, der eine Datenanforderung erstellt und das vorteilhafteste Angebot pro Tag zurückgibt. Es würde nur mehrere Zeilen in der Konfigurationsdatei und etwas Lua-Code erfordern.
Was kommt als nächstes?
Für uns ist es eine Priorität, den Entwicklungskomfort mit
Tarantool Data Grid zu erhöhen. (Dies ist beispielsweise eine IDE mit Unterstützung für die Profilerstellung und das Debuggen von Handlern, die in der Sandbox funktionieren.)
Wir achten auch sehr auf Sicherheitsfragen. Derzeit wird unser Produkt von der FSTEC Russlands (Föderaler Dienst für Technologie und Exportkontrolle) zertifiziert, um das hohe Sicherheitsniveau anzuerkennen und die Zertifizierungsanforderungen für Softwareprodukte zu erfüllen, die in Informationssystemen für personenbezogene Daten und Informationssystemen des Bundes verwendet werden.