
Fehlertoleranz und hohe Verfügbarkeit sind große Themen, daher werden RabbitMQ und Kafka separate Artikel widmen. In diesem Artikel geht es um RabbitMQ, und im nächsten geht es um Kafka im Vergleich zu RabbitMQ. Der Artikel ist lang, machen Sie es sich also bequem.
Berücksichtigen Sie die Strategien für Fehlertoleranz, Konsistenz und Hochverfügbarkeit (HA) sowie die Kompromisse, die jede Strategie eingehen muss. RabbitMQ kann auf einem Cluster von Knoten ausgeführt werden - und wird dann als verteiltes System klassifiziert. Wenn es um verteilte Systeme geht, sprechen wir oft über Konsistenz und Zugänglichkeit.
Diese Konzepte beschreiben, wie sich das System im Fehlerfall verhält. Netzwerkverbindungsfehler, Serverfehler, Festplattenfehler, vorübergehende Nichtverfügbarkeit des Servers aufgrund von Speicherbereinigung, Paketverlust oder Verlangsamung der Netzwerkverbindung. All dies kann zu Datenverlust oder Konflikten führen. Es stellt sich heraus, dass es fast unmöglich ist, ein System zu erstellen, das sowohl vollständig konsistent (ohne Datenverlust, ohne Datenunterschiede) als auch zugänglich (es akzeptiert Lese- und Schreibvorgänge) für alle Arten von Fehlern ist.
Wir werden sehen, dass Konsistenz und Zugänglichkeit an verschiedenen Enden des Spektrums liegen und Sie müssen entscheiden, wie Sie optimieren möchten. Die gute Nachricht ist, dass mit RabbitMQ eine solche Wahl möglich ist. Sie haben eine Art "Nerd" -Hebel, um das Gleichgewicht in Richtung größerer Kohärenz oder besserer Zugänglichkeit zu verschieben.
Wir werden besonders darauf achten, welche Konfigurationen aufgrund bestätigter Aufzeichnungen zu Datenverlust führen. Zwischen Verlagen, Maklern und Verbrauchern besteht eine Verantwortungskette. Nachdem die Nachricht an den Broker gesendet wurde, ist es seine Aufgabe, die Nachricht nicht zu verlieren. Wenn der Broker dem Herausgeber den Empfang der Nachricht bestätigt, erwarten wir nicht, dass diese verloren geht. Wir werden jedoch feststellen, dass dies je nach Konfiguration Ihres Brokers und Publishers tatsächlich passieren kann.
Die Grundelemente der Stabilität eines Knotens
Anhaltende Warteschlangen / Routing
In RabbitMQ gibt es zwei Arten von Warteschlangen: dauerhaft / nicht dauerhaft. Alle Warteschlangen werden in der Mnesia-Datenbank gespeichert. Permanente Warteschlangen werden beim Start des Knotens erneut deklariert und überleben somit einen Neustart, einen Systemabsturz oder einen Serverabsturz (solange die Daten gespeichert sind). Dies bedeutet, dass während Sie das Routing (Austausch) und die Warteschlange als ausfallsicher deklarieren, die Infrastruktur der Warteschlangen / des Routings online zurückkehrt.
Flüchtige Warteschlangen und Routing werden beim Neustart des Hosts gelöscht.
Permanente Nachrichten
Nur weil die Warteschlange lang ist, bedeutet dies nicht, dass alle Nachrichten einen Neustart des Knotens überleben. Es werden nur Nachrichten wiederhergestellt, die vom Herausgeber als dauerhaft festgelegt wurden. Persistente Nachrichten stellen eine zusätzliche Belastung für den Broker dar. Wenn der Verlust von Nachrichten jedoch nicht akzeptabel ist, gibt es keinen anderen Weg.
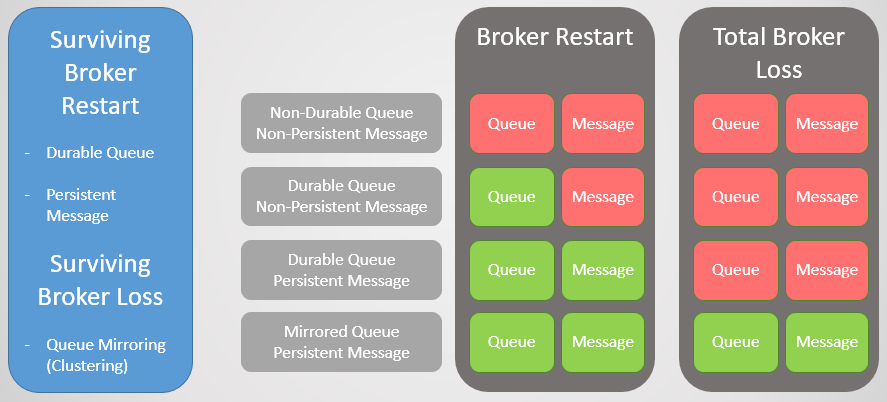 Abb. 1. Stabilitätsmatrix
Abb. 1. StabilitätsmatrixQueue Mirroring Clustering
Um den Verlust eines Maklers zu überleben, brauchen wir Redundanz. Wir können mehrere RabbitMQ-Knoten zu einem Cluster kombinieren und dann zusätzliche Redundanz hinzufügen, indem wir die Warteschlangen zwischen mehreren Knoten replizieren. Wenn also ein Knoten ausfällt, verlieren wir keine Daten und bleiben verfügbar.
Warteschlangenspiegelung:
- eine Hauptwarteschlange (Master), die alle Schreib- und Lesebefehle empfängt
- ein oder mehrere Spiegel, die alle Nachrichten und Metadaten aus der Hauptwarteschlange empfangen. Diese Spiegel existieren nicht zur Skalierung, sondern nur zur Redundanz.
 Abb. 2. Spiegeln der Warteschlange
Abb. 2. Spiegeln der WarteschlangeDie Spiegelung wird durch die entsprechende Richtlinie festgelegt. Darin können Sie die Replikationsrate und sogar die Knoten auswählen, auf denen die Warteschlange platziert werden soll. Beispiele:
ha-mode: all
ha-mode: exactly, ha-params: 2 (ein Master und ein Spiegel)
ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
Bestätigung an den Verlag
Um eine sequentielle Aufzeichnung zu erreichen, muss Publisher Confirms bestätigt werden. Ohne sie besteht die Möglichkeit, dass Nachrichten verloren gehen. Nach dem Schreiben der Nachricht auf die Festplatte wird eine Bestätigung an den Herausgeber gesendet. RabbitMQ schreibt Nachrichten nicht nach Erhalt, sondern in regelmäßigen Abständen im Bereich von mehreren hundert Millisekunden auf die Festplatte. Wenn die Warteschlange gespiegelt wird, wird die Bestätigung erst gesendet, nachdem alle Spiegel auch ihre Kopie der Nachricht auf die Festplatte geschrieben haben. Dies bedeutet, dass die Verwendung von Bestätigungen die Verzögerung erhöht. Wenn jedoch die Datensicherheit wichtig ist, sind sie erforderlich.
Failover-Warteschlange
Wenn der Broker heruntergefahren wird oder abstürzt, fallen alle führenden Warteschlangen (Master) auf diesem Knoten damit ab. Der Cluster wählt dann den ältesten Spiegel jedes Masters aus und befördert ihn als neuen Master.
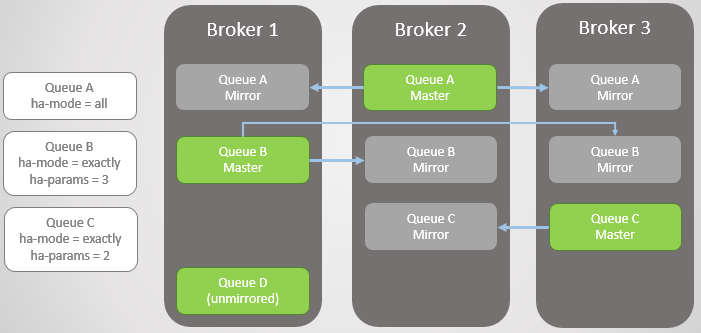 Abb. 3. Mehrere gespiegelte Warteschlangen und ihre Richtlinien
Abb. 3. Mehrere gespiegelte Warteschlangen und ihre RichtlinienBroker 3 Tropfen. Beachten Sie, dass der Spiegel von Warteschlange C in Broker 2 auf einen Master aktualisiert wird. Beachten Sie auch, dass für Warteschlange C in Broker 1 ein neuer Spiegel erstellt wurde. RabbitMQ versucht immer, die in Ihren Richtlinien angegebene Replikationsrate beizubehalten.
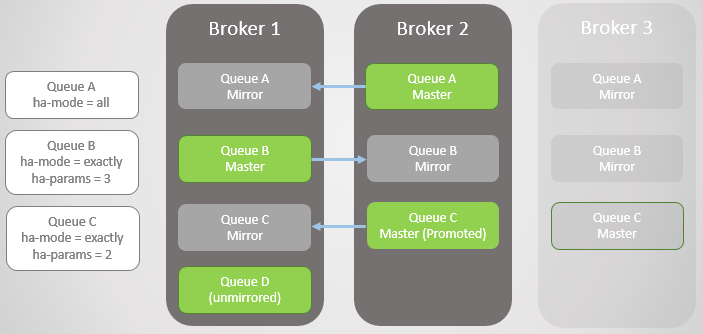 Abb. 4. Broker 3 fällt ab und Warteschlange C schlägt fehl
Abb. 4. Broker 3 fällt ab und Warteschlange C schlägt fehlDer nächste Broker 1 fällt! Wir haben nur noch einen Broker. Der Spiegel von Warteschlange B erhebt sich zum Master.
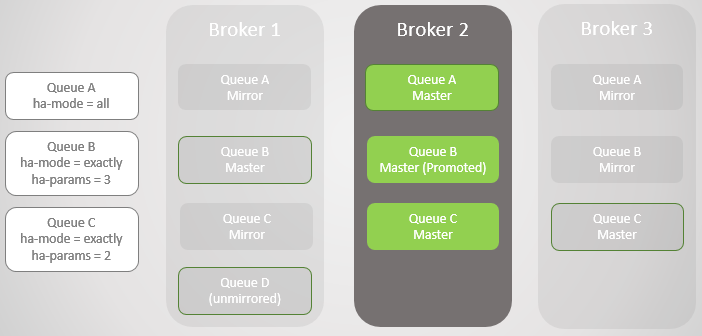 Abb. 5
Abb. 5Wir haben Broker 1 zurückgegeben. Unabhängig davon, wie erfolgreich die Daten den Verlust und die Wiederherstellung des Brokers überstanden haben, werden alle gespiegelten Warteschlangennachrichten beim Neustart verworfen. Dies ist wichtig zu beachten, da dies Konsequenzen haben wird. Wir werden diese Konsequenzen bald berücksichtigen. Somit ist Broker 1 jetzt wieder Mitglied des Clusters, und der Cluster versucht, die Richtlinien einzuhalten, und erstellt daher Spiegel für Broker 1.
In diesem Fall war der Verlust von Broker 1 sowie der Daten vollständig, sodass die nicht spiegelnde Warteschlange D vollständig verloren ging.
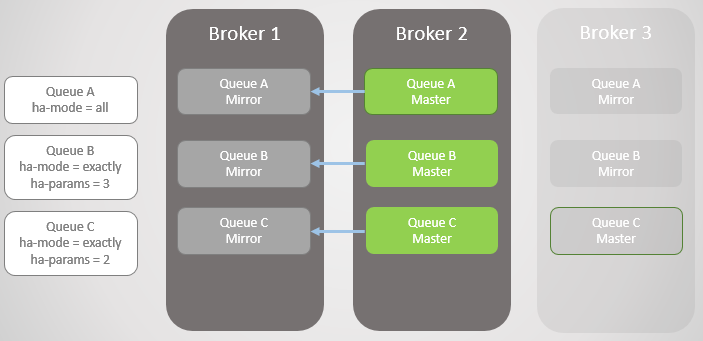 Abb. 6. Broker 1 ist wieder in Betrieb
Abb. 6. Broker 1 ist wieder in BetriebBroker 3 ist wieder online, sodass in den Zeilen A und B Spiegel erstellt werden, die ihren HA-Richtlinien entsprechen. Aber jetzt sind alle Hauptleitungen auf einem Knoten! Dies ist nicht ideal, eine gleichmäßige Verteilung zwischen den Knoten ist besser. Leider gibt es keine besonderen Möglichkeiten, um die Meister wieder ins Gleichgewicht zu bringen. Wir werden später auf dieses Problem zurückkommen, da wir zuerst die Warteschlangensynchronisation in Betracht ziehen müssen.
 Abb. 7. Broker 3 ist wieder in Betrieb. Alle Hauptwarteschlangen auf einem Knoten!
Abb. 7. Broker 3 ist wieder in Betrieb. Alle Hauptwarteschlangen auf einem Knoten!Daher sollten Sie jetzt eine Vorstellung davon haben, wie Spiegel Redundanz und Fehlertoleranz bieten. Dies stellt die Verfügbarkeit bei einem Ausfall eines einzelnen Knotens sicher und schützt vor Datenverlust. Aber wir sind noch nicht fertig, denn in Wirklichkeit ist alles viel komplizierter.
Synchronisieren
Beim Erstellen eines neuen Spiegels werden alle neuen Nachrichten immer auf diesen und alle anderen Spiegel repliziert. Die vorhandenen Daten in der Hauptwarteschlange können in einem neuen Spiegel repliziert werden, der zu einer vollständigen Kopie des Masters wird. Wir können auch vorhandene Nachrichten nicht replizieren und zulassen, dass die Hauptwarteschlange und der neue Spiegel rechtzeitig zusammenlaufen, wenn neue Nachrichten am Ende ankommen und vorhandene Nachrichten den Kopf der Hauptwarteschlange verlassen.
Diese Synchronisation wird automatisch oder manuell durchgeführt und über eine Warteschlangenrichtlinie gesteuert. Betrachten Sie ein Beispiel.
Wir haben zwei gespiegelte Linien. Warteschlange A wird automatisch und Warteschlange B manuell synchronisiert. Beide Zeilen haben jeweils zehn Nachrichten.
 Abb. 8. Zwei Warteschlangen mit unterschiedlichen Synchronisationsmodi
Abb. 8. Zwei Warteschlangen mit unterschiedlichen SynchronisationsmodiJetzt verlieren wir Broker 3.
 Abb. 9. Broker 3 fiel
Abb. 9. Broker 3 fielBroker 3 ist wieder in Betrieb. Der Cluster erstellt für jede Warteschlange auf dem neuen Knoten einen Spiegel und synchronisiert die neue Warteschlange A automatisch mit dem Master. Der Spiegel der neuen Kurve B bleibt jedoch leer. Somit haben wir eine vollständige Redundanz von Warteschlange A und nur einen Spiegel für die vorhandenen Nachrichten von Warteschlange B.
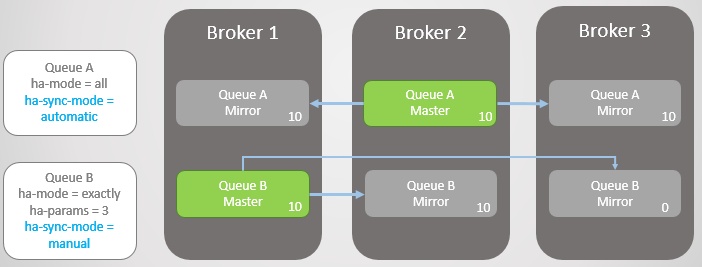 Abb. 10. Der neue Spiegel von Warteschlange A empfängt alle vorhandenen Nachrichten, der neue Spiegel von Warteschlange B jedoch nicht
Abb. 10. Der neue Spiegel von Warteschlange A empfängt alle vorhandenen Nachrichten, der neue Spiegel von Warteschlange B jedoch nichtBeide Leitungen erhalten zehn weitere Nachrichten. Dann fällt Broker 2 aus und Warteschlange A wird auf den ältesten Spiegel zurückgesetzt, der sich auf Broker 1 befindet. Im Falle eines Fehlers tritt kein Datenverlust auf. Es gibt zwanzig Nachrichten in Warteschlange B im Assistenten und nur zehn im Spiegel, da diese Warteschlange die ursprünglichen zehn Nachrichten nie repliziert hat.
 Abb. 11. Zeile A wird auf Broker 1 zurückgesetzt, ohne dass Nachrichten verloren gehen
Abb. 11. Zeile A wird auf Broker 1 zurückgesetzt, ohne dass Nachrichten verloren gehenBeide Leitungen erhalten zehn weitere Nachrichten. Broker 1 stürzt jetzt ab. Warteschlange A wechselt problemlos zum Spiegel, ohne dass Nachrichten verloren gehen. Warteschlange B hat jedoch Probleme. An diesem Punkt können wir entweder die Zugänglichkeit oder die Konsistenz optimieren.
Wenn wir die Zugänglichkeit optimieren möchten, sollte die Richtlinie "
Ha-Promotion-on-Failure" immer festgelegt werden . Dies ist der Standardwert, sodass Sie die Richtlinie einfach weglassen können. In diesem Fall erlauben wir tatsächlich Fehler in nicht synchronisierten Spiegeln. Dies führt zu einem Nachrichtenverlust, die Warteschlange bleibt jedoch lesbar und beschreibbar.
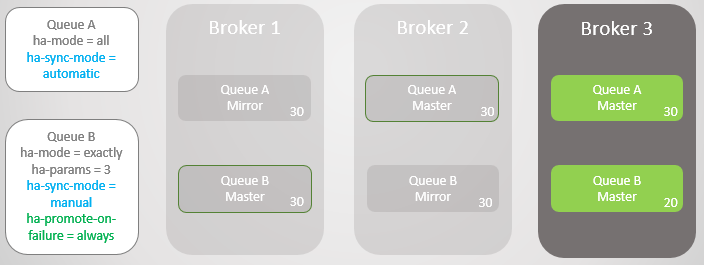 Abb. 12. Zeile A wird auf Broker 3 zurückgesetzt, ohne dass Nachrichten verloren gehen. Zeile B kehrt mit dem Verlust von zehn Nachrichten zu Broker 3 zurück
Abb. 12. Zeile A wird auf Broker 3 zurückgesetzt, ohne dass Nachrichten verloren gehen. Zeile B kehrt mit dem Verlust von zehn Nachrichten zu Broker 3 zurückWir können
ha-promote-on-failure auf "
when-synced . In diesem Fall wartet die Warteschlange, anstatt zum Spiegel zurückzukehren, bis Broker 1 mit seinen Daten in den Online-Modus zurückkehrt. Nach seiner Rückkehr wird die Hauptwarteschlange erneut auf Broker 1 ohne Datenverlust angezeigt. Die Zugänglichkeit wird für die Datensicherheit geopfert. Dies ist jedoch ein riskanter Modus, der sogar zu einem vollständigen Datenverlust führen kann, den wir in naher Zukunft in Betracht ziehen werden.
 Abb. 13. Zeile B bleibt nach dem Verlust von Broker 1 nicht verfügbar
Abb. 13. Zeile B bleibt nach dem Verlust von Broker 1 nicht verfügbarMöglicherweise stellen Sie eine Frage: „Vielleicht ist es besser, niemals die automatische Synchronisierung zu verwenden?“. Die Antwort ist, dass die Synchronisation eine Blockierungsoperation ist. Während der Synchronisation kann die Hauptwarteschlange keine Lese- oder Schreibvorgänge ausführen!
Betrachten Sie ein Beispiel. Jetzt haben wir sehr lange Schlangen. Wie können sie auf diese Größe wachsen? Aus mehreren Gründen:
- Warteschlangen werden nicht aktiv verwendet.
- Dies sind Hochgeschwindigkeitsstrecken, und im Moment sind die Verbraucher langsam
- Dies sind Hochgeschwindigkeitswarteschlangen, ein Fehler ist aufgetreten und die Verbraucher holen auf
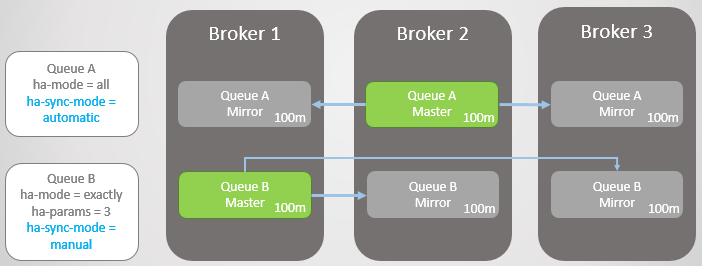 Abb. 14. Zwei große Warteschlangen mit unterschiedlichen Synchronisationsmodi
Abb. 14. Zwei große Warteschlangen mit unterschiedlichen SynchronisationsmodiJetzt stürzt Broker 3 ab.
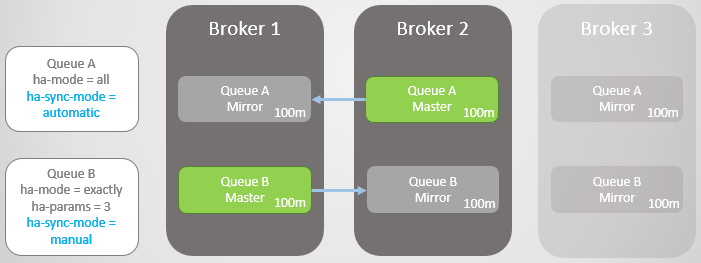 Abb. 15. Broker 3 fällt und hinterlässt einen Master und einen Spiegel in jeder Warteschlange
Abb. 15. Broker 3 fällt und hinterlässt einen Master und einen Spiegel in jeder WarteschlangeBroker 3 kehrt zurück und es werden neue Spiegel erstellt. Hauptwarteschlange A beginnt, vorhandene Nachrichten auf einen neuen Spiegel zu replizieren, und während dieser Zeit ist Warteschlange A nicht verfügbar. Die Datenreplikation dauert zwei Stunden, was zu zwei Stunden Ausfallzeit für diese Warteschlange führt!
Linie B bleibt jedoch während des gesamten Zeitraums verfügbar. Sie opferte einige Redundanz für die Zugänglichkeit.
 Abb. 16. Die Warteschlange bleibt während der Synchronisierung nicht verfügbar
Abb. 16. Die Warteschlange bleibt während der Synchronisierung nicht verfügbarNach zwei Stunden ist auch Warteschlange A verfügbar und akzeptiert möglicherweise wieder Lese- und Schreibvorgänge.
Updates
Dieses Blockierungsverhalten während der Synchronisation macht es schwierig, Cluster mit sehr großen Warteschlangen zu aktualisieren. Irgendwann muss der Knoten mit dem Assistenten neu gestartet werden. Dies bedeutet, dass Sie entweder zum Spiegel wechseln oder die Warteschlange während der Serveraktualisierung deaktivieren müssen. Wenn wir einen Übergang wählen, verlieren wir Nachrichten, wenn die Spiegel nicht synchronisiert sind. Wenn ein Broker deaktiviert ist, wird standardmäßig kein Übergang zu einem nicht synchronisierten Spiegel durchgeführt. Dies bedeutet, dass wir keine Nachrichten verlieren, sobald der Broker zurückkehrt. Der einzige Schaden war nur eine einfache Warteschlange. Das Deaktivieren von Brokern unterliegt der Richtlinie zum
ha-promote-on-shutdown . Sie können einen von zwei Werten festlegen:
always = Aktiviertes Umschalten auf nicht synchronisierte Spiegel
when-synced = wechselt nur zum synchronisierten Spiegel, andernfalls kann auf die Warteschlange nicht mehr gelesen und geschrieben werden. Die Warteschlange kehrt zurück, sobald der Broker zurückkehrt
Auf die eine oder andere Weise müssen Sie bei großen Warteschlangen zwischen Datenverlust und Unzugänglichkeit wählen.
Wenn Verfügbarkeit die Datensicherheit verbessert
Bevor eine Entscheidung getroffen wird, muss eine weitere Komplikation berücksichtigt werden. Während die automatische Synchronisierung aus Redundanzgründen besser ist, wie wirkt sie sich auf die Datensicherheit aus? Natürlich ist es dank der besseren Redundanz weniger wahrscheinlich, dass RabbitMQ vorhandene Nachrichten verliert, aber was ist mit neuen Nachrichten von Herausgebern?
Hier müssen Sie Folgendes berücksichtigen:
- Kann ein Publisher nur einen Fehler zurückgeben und ein höherer Dienst oder Benutzer wird es später erneut versuchen?
- Kann ein Herausgeber eine Nachricht lokal oder in einer Datenbank speichern, um sie später erneut zu versuchen?
Wenn der Herausgeber die Nachricht nur löschen kann, erhöht eine Verbesserung der Barrierefreiheit auch die Datensicherheit.
Daher müssen Sie nach einem Gleichgewicht suchen, und die Entscheidung hängt von der spezifischen Situation ab.
Probleme mit Ha-Promotion-on-Failure = bei Synchronisierung
Die Idee von
ha-fördern-bei-Fehler =
bei Synchronisierung ist, dass wir das Umschalten auf einen nicht synchronisierten Spiegel verhindern und somit Datenverlust vermeiden. Die Warteschlange bleibt zum Lesen oder Schreiben unzugänglich. Stattdessen versuchen wir, einen gefallenen Broker mit unbeschädigten Daten zurückzugeben, damit er ohne Datenverlust seine Arbeit als Master wieder aufnimmt.
Aber (und das ist groß, aber) wenn der Broker seine Daten verloren hat, haben wir ein großes Problem: Die Warteschlange ist verloren! Alle Daten sind weg! Selbst wenn Sie Spiegel haben, die im Grunde die Hauptwarteschlange einholen, werden diese Spiegel ebenfalls verworfen.
Um einen Knoten mit demselben Namen erneut hinzuzufügen, weisen Sie den Cluster an, den verlorenen Knoten (mit dem
Befehl rabbitmqctl compare_cluster_node ) zu vergessen und einen neuen Broker mit demselben Hostnamen zu starten. Solange sich der Cluster an den verlorenen Knoten erinnert, merkt er sich die alte Warteschlange und die nicht synchronisierten Spiegel. Wenn ein Cluster angewiesen wird, einen verlorenen Knoten zu vergessen, wird auch diese Warteschlange vergessen. Jetzt müssen Sie es erneut deklarieren. Wir haben alle Daten verloren, obwohl wir Spiegel mit einem Teildatensatz hatten. Es wäre besser, zu einem nicht synchronisierten Spiegel zu wechseln!
Daher ist die manuelle Synchronisation (und der Synchronisationsfehler) in Kombination mit
ha-promote-on-failure=when-synced meiner Meinung nach ziemlich riskant. Dokumente sagen, dass diese Option für die Datensicherheit existiert, aber es ist ein zweischneidiges Messer.
Meister neu ausbalancieren
Wie versprochen kehren wir zum Problem der Akkumulation aller Master auf einem oder mehreren Knoten zurück. Dies kann auch aufgrund fortlaufender fortlaufender Cluster-Updates geschehen. In einem Cluster mit drei Knoten werden alle Hauptwarteschlangen auf einem oder zwei Knoten angesammelt.
Das Ausbalancieren von Mastern kann aus zwei Gründen problematisch sein:
- Keine guten Ausgleichswerkzeuge
- Warteschlangensynchronisierung
Für das Rebalancing gibt es ein
Plugin eines Drittanbieters, das nicht offiziell unterstützt wird. In Bezug auf Plug-Ins von Drittanbietern heißt es im RabbitMQ-Handbuch: „Das Plug-In bietet einige zusätzliche Konfigurations- und Berichterstellungstools, wird jedoch vom RabbitMQ-Team nicht unterstützt und nicht getestet. Die Verwendung erfolgt auf eigenes Risiko. “
Es gibt noch einen weiteren Trick, um die Hauptwarteschlange durch HA-Richtlinien zu verschieben. Das Handbuch erwähnt hierfür ein
Skript . Es funktioniert wie folgt:
- Löscht alle Spiegel mithilfe einer temporären Richtlinie mit einer höheren Priorität als die vorhandene HA-Richtlinie.
- Ändert die temporäre HA-Richtlinie so, dass der Knotenmodus mit dem Knoten verwendet wird, auf den die Hauptwarteschlange verschoben werden muss.
- Synchronisiert die Warteschlange für die erzwungene Migration.
- Löscht nach Abschluss der Migration die temporäre Richtlinie. Die HA-Anfangsrichtlinie tritt in Kraft und die erforderliche Anzahl von Spiegeln wird erstellt.
Der Nachteil ist, dass dieser Ansatz möglicherweise nicht funktioniert, wenn Sie große Warteschlangen oder strenge Redundanzanforderungen haben.
Nun wollen wir sehen, wie RabbitMQ-Cluster mit Netzwerkpartitionen funktionieren.
Unterbrechung der Konnektivität
Die Knoten eines verteilten Systems sind durch Netzwerkverbindungen verbunden, und Netzwerkverbindungen können und werden getrennt. Die Häufigkeit von Ausfällen hängt von der lokalen Infrastruktur oder der Zuverlässigkeit der ausgewählten Cloud ab. In jedem Fall sollten verteilte Systeme in der Lage sein, damit umzugehen. Wieder haben wir die Wahl zwischen Zugänglichkeit und Konsistenz, und wieder ist die gute Nachricht, dass RabbitMQ beides bietet (nur nicht gleichzeitig).
Mit RabbitMQ haben wir zwei Hauptoptionen:
- Erlaube logische Trennung (Split-Brain). Dies bietet Zugriff, kann jedoch zu Datenverlust führen.
- Logische Trennung nicht zulassen. Dies kann zu einem kurzfristigen Verlust der Verfügbarkeit führen, je nachdem, wie Clients eine Verbindung zum Cluster herstellen. Dies kann auch zu einer vollständigen Unzugänglichkeit in einem Cluster von zwei Knoten führen.
Aber was ist logische Trennung? Dies ist der Fall, wenn ein Cluster aufgrund eines Verlusts der Netzwerkverbindungen in zwei Teile geteilt wird. Auf jeder Seite erheben sich die Spiegel zum Meister, so dass sich am Ende in jeder Runde mehrere Meister befinden.
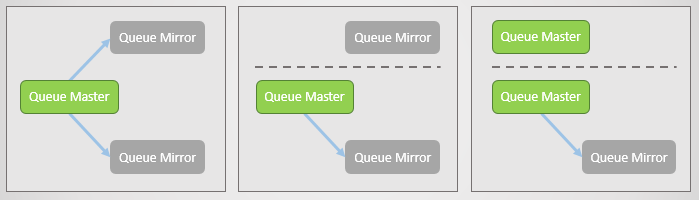 Abb. 17. Die Hauptleitung und zwei Spiegel, jeweils auf einem separaten Knoten. Dann tritt ein Netzwerkfehler auf und ein Spiegel trennt sich. Der abgetrennte Knoten sieht, dass die anderen beiden abgefallen sind, und schiebt seine Spiegel zum Master. Jetzt haben wir zwei Hauptzeilen, und beide erlauben das Schreiben und Lesen.
Abb. 17. Die Hauptleitung und zwei Spiegel, jeweils auf einem separaten Knoten. Dann tritt ein Netzwerkfehler auf und ein Spiegel trennt sich. Der abgetrennte Knoten sieht, dass die anderen beiden abgefallen sind, und schiebt seine Spiegel zum Master. Jetzt haben wir zwei Hauptzeilen, und beide erlauben das Schreiben und Lesen.Wenn Publisher Daten an beide Master senden, erhalten wir zwei unterschiedliche Kopien der Warteschlange.
Die verschiedenen RabbitMQ-Modi bieten entweder Zugänglichkeit oder Konsistenz.
Ignoriermodus (Standard)
Dieser Modus bietet Barrierefreiheit. Nach dem Verlust der Konnektivität erfolgt eine logische Trennung. Nach dem erneuten Herstellen der Verbindung muss der Administrator entscheiden, welche Partition er bevorzugen möchte. Die verlierende Seite wird neu gestartet und alle gesammelten Daten von dieser Seite gehen verloren.
 Abb. 18. Drei Verlage sind drei Maklern zugeordnet. Intern leitet der Cluster alle Anforderungen an die Hauptwarteschlange von Broker 2 weiter.
Abb. 18. Drei Verlage sind drei Maklern zugeordnet. Intern leitet der Cluster alle Anforderungen an die Hauptwarteschlange von Broker 2 weiter.Jetzt verlieren wir Broker 3. Er sieht, dass andere Broker abgefallen sind und bewegt seinen Spiegel zum Master. Dies ist die logische Trennung.
 Abb. 19. Logische Trennung (Split-Brain). Die Aufzeichnungen bestehen aus zwei Hauptzeilen, und zwei Kopien weichen voneinander ab.
Abb. 19. Logische Trennung (Split-Brain). Die Aufzeichnungen bestehen aus zwei Hauptzeilen, und zwei Kopien weichen voneinander ab.Die Konnektivität wird wiederhergestellt, die logische Trennung bleibt jedoch bestehen. Der Administrator muss die Verliererseite manuell auswählen. Im folgenden Fall startet der Administrator Broker 3 neu. Alle Nachrichten, die er nicht übertragen konnte, gehen verloren.
 Abb. 20. Der Administrator deaktiviert Broker 3.
Abb. 20. Der Administrator deaktiviert Broker 3. Abb. 21. Der Administrator startet Broker 3 und tritt dem Cluster bei, wobei alle dort verbleibenden Nachrichten verloren gehen.
Abb. 21. Der Administrator startet Broker 3 und tritt dem Cluster bei, wobei alle dort verbleibenden Nachrichten verloren gehen.Während des Verbindungsverlusts und nach seiner Wiederherstellung standen der Cluster und diese Warteschlange zum Lesen und Schreiben zur Verfügung.
Autoheal-Modus
Es funktioniert ähnlich wie der Ignoriermodus, außer dass der Cluster selbst automatisch die verlierende Seite auswählt, nachdem die Konnektivität aufgeteilt und wiederhergestellt wurde. Die verlierende Seite kehrt leer zum Cluster zurück, und die Warteschlange verliert alle Nachrichten, die nur an diese Seite gesendet wurden.
Minority-Modus anhalten
Wenn wir keine logische Trennung zulassen möchten, besteht unsere einzige Möglichkeit darin, das Lesen und Schreiben auf der kleineren Seite nach der Partition des Clusters zu verweigern. Wenn ein Broker sieht, dass er auf der geringeren Seite ist, hält er inne, schließt alle bestehenden Verbindungen und lehnt neue ab. Einmal pro Sekunde wird nach einer erneuten Verbindung gesucht. Sobald die Konnektivität wiederhergestellt ist, wird die Arbeit wieder aufgenommen und dem Cluster beigetreten.
 Abb. 22. Drei Verlage sind drei Maklern zugeordnet. Intern leitet der Cluster alle Anforderungen an die Hauptwarteschlange von Broker 2 weiter.
Abb. 22. Drei Verlage sind drei Maklern zugeordnet. Intern leitet der Cluster alle Anforderungen an die Hauptwarteschlange von Broker 2 weiter.Dann werden Broker 1 und 2 von Broker 3 getrennt. Anstatt ihren Spiegel auf einen Master zu aktualisieren, wird Broker 3 angehalten und ist nicht mehr zugänglich.
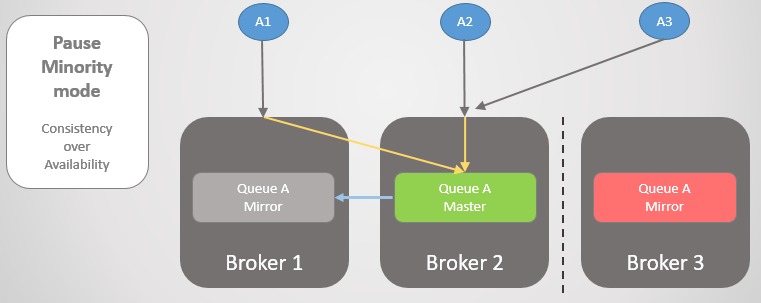 Abb. 23. Broker 3 hält an, trennt alle Clients und lehnt Verbindungsanforderungen ab.
Abb. 23. Broker 3 hält an, trennt alle Clients und lehnt Verbindungsanforderungen ab.Sobald die Konnektivität wiederhergestellt ist, kehrt sie zum Cluster zurück.
Schauen wir uns ein anderes Beispiel an, in dem sich die Hauptzeile auf Broker 3 befindet.
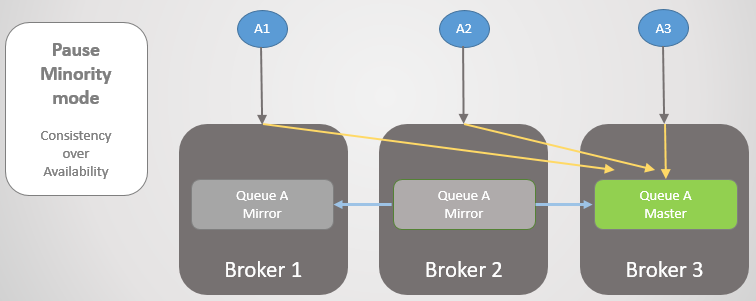 Abb. 24. Die Hauptlinie bei Broker 3.
Abb. 24. Die Hauptlinie bei Broker 3.Dann tritt der gleiche Konnektivitätsverlust auf. Broker 3 pausiert, weil es kleiner ist. Auf der anderen Seite sehen die Knoten, dass Broker 3 abgefallen ist, so dass der ältere Spiegel von Broker 1 und 2 zum Master aufsteigt.
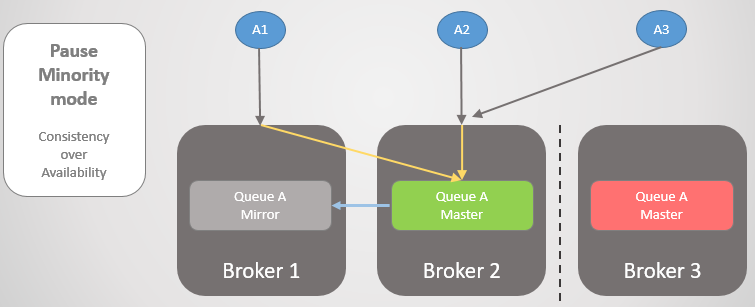 Abb. 25. Übergang zu Broker 2, wenn Broker 3 nicht verfügbar ist.
Abb. 25. Übergang zu Broker 2, wenn Broker 3 nicht verfügbar ist.Wenn die Konnektivität wiederhergestellt ist, tritt Broker 3 dem Cluster bei.
 Abb. 26. Der Cluster kehrte zum normalen Betrieb zurück.
Abb. 26. Der Cluster kehrte zum normalen Betrieb zurück.Es ist wichtig zu verstehen, dass wir Konsistenz erhalten, aber wir können auch Zugänglichkeit erhalten,
wenn wir Kunden erfolgreich auf den größten Teil des Abschnitts übertragen. In den meisten Situationen würde ich persönlich den Modus "Minderheit pausieren" wählen, aber das hängt wirklich vom jeweiligen Fall ab.
Um die Verfügbarkeit sicherzustellen, ist es wichtig sicherzustellen, dass Clients erfolgreich eine Verbindung zur Site herstellen. Betrachten Sie unsere Optionen.
Kundenkonnektivität
Wir haben verschiedene Möglichkeiten, wie Clients nach einem Verbindungsverlust an den Hauptteil des Clusters oder an Arbeitsknoten gesendet werden (nach einem Ausfall eines Knotens). Erinnern wir uns zunächst daran, dass eine bestimmte Warteschlange auf einem bestimmten Host gehostet wird, Routing und Richtlinien jedoch auf allen Hosts repliziert werden. Clients können eine Verbindung zu einem beliebigen Knoten herstellen, und das interne Routing leitet sie bei Bedarf weiter. Wenn ein Knoten angehalten wird, wird die Verbindung abgelehnt, sodass Clients eine Verbindung zu einem anderen Knoten herstellen müssen. Wenn ein Knoten abfällt, kann er überhaupt wenig tun.
Unsere Möglichkeiten:
- Der Zugriff auf den Cluster erfolgt über einen Load Balancer, der einfach die Knoten durchläuft und Clients wiederholt versucht, eine Verbindung herzustellen, bis sie erfolgreich abgeschlossen wurden. , , ( ). , .
- / , . , , .
- , . , , .
- / DNS. TTL.
Schlussfolgerungen
RabbitMQ . , :
. RabbitMQ , . , . RabbitMQ . RabbitMQ :
, :
ha-promote-on-failure=always
ha-sync-mode=manual
cluster_partition_handling=ignore ( autoheal )
- , , -
( ) :
- Publisher Confirms Manual Acknowledgements
ha-promote-on-failure=when-synced , ! =always .
ha-sync-mode=automatic ( ; , , )
- Pause Minority
; , (, ). Shovel.
- , , .
.
, RabbitMQ Docker Blockade, , .
:
№1 —
habr.com/ru/company/itsumma/blog/416629№2 —
habr.com/ru/company/itsumma/blog/418389№3 —
habr.com/ru/company/itsumma/blog/437446