Letztes Mal haben wir einen einfachen PEG-Parser-Generator bekommen. Jetzt werde ich zeigen, was der generierte Parser beim Parsen des Programms tatsächlich tut. Ich tauchte in die Retro-Welt der ASCII-Kunst ein, insbesondere in eine Bibliothek namens "curses", die in der Standard-Python-Distribution für Linux und Mac verfügbar ist, sowie in ein Add-On für Windows.
Inhalt der Python PEG Parser-Serie 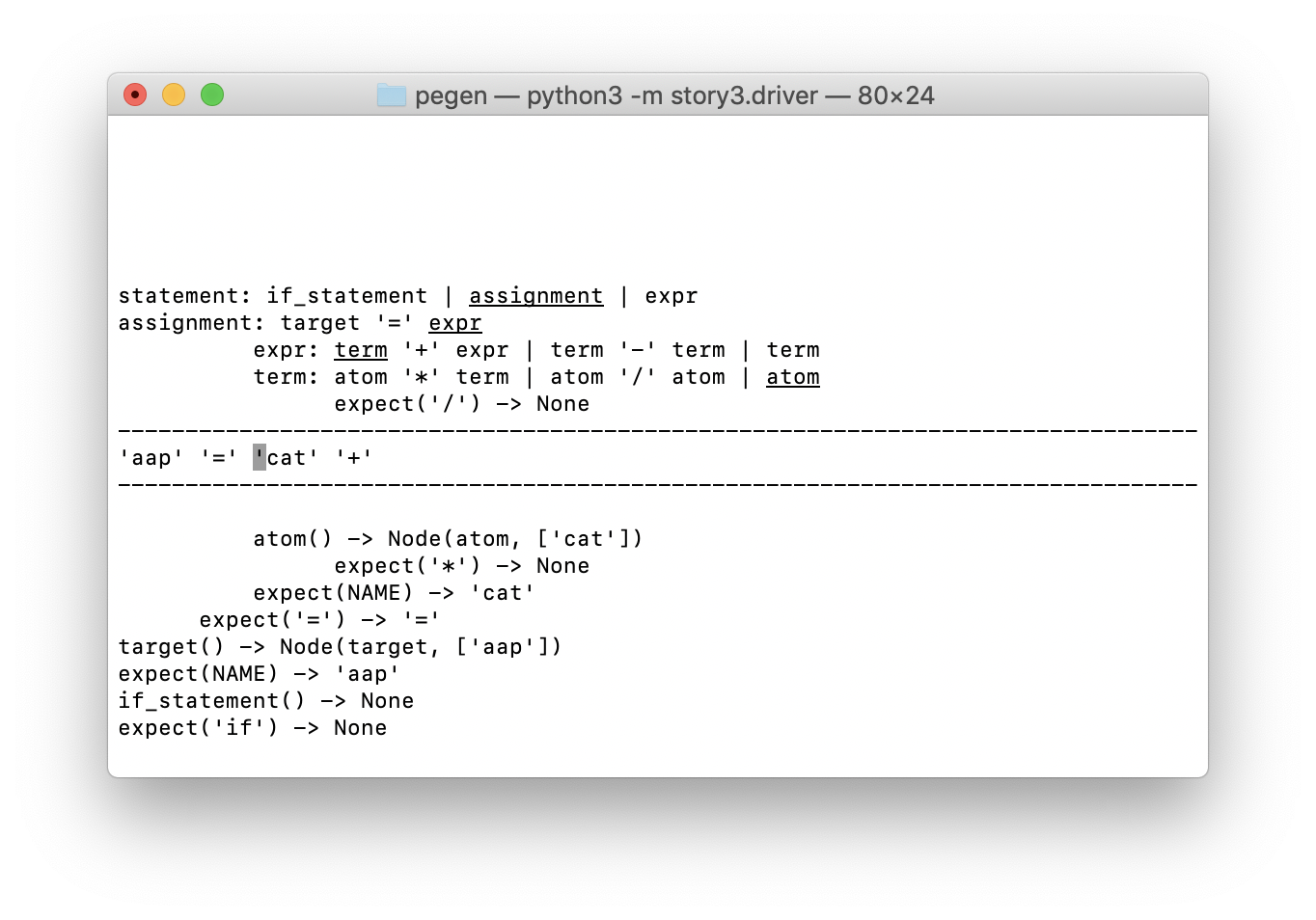
<Am Ende des Artikels wird unter dem Spoiler ein GIF angezeigt. Es schien mir verständlicher als ein statisches Bild
Schauen wir uns die Visualisierung an. Der Bildschirm ist, wie in ASCII üblich, in drei Teile mit einem Bindestrich unterteilt:
- Der obere Teil zeigt den Parser-Aufrufstapel, der, wie Sie sich erinnern, ein rekursiver Abstiegsanalysator mit unbegrenzter Rückgabe ist. Im Folgenden werde ich näher erläutern.
- Der einzeilige Abschnitt in der Mitte zeigt den Inhalt des Token-Puffers, wobei ein Cursor auf das Token zeigt, das als nächstes analysiert wird.
- Im Folgenden wird der vom Packrat-Parser-Algorithmus verwendete Cache visualisiert. Das Aufzeichnen seiner Elemente ähnelt in gewisser Weise einigen Elementen des Parser-Stacks (mit Ergebnissen).
Das Wichtigste, was Sie wissen müssen, um diese Visualisierung zu verstehen, ist, dass die Einrückung der Zeilen oben und unten dem Token-Puffer entspricht.
- Die ersten beiden Zeilen (beginnend mit
statement und assignment ) zeigen die Aufrufe der entsprechenden Parser-Methoden, die gerade die Analyse durchführen. Sie wurden aufgerufen, wenn sich der Tokenizer-Zeiger vor dem ersten Token befand ( 'aap' ). - Die nächsten beiden Zeilen (beginnend mit
expr und term ) sind am Anfang des 'cat' expr 'cat' Tokens ausgerichtet, wo die entsprechenden Parser-Methoden aufgerufen wurden. - Die fünfte und letzte Zeile des Stack-Renderings zeigt den zu
expect('/') Aufruf expect('/') , der None zurückgibt. Er meldete sich freiwillig bei der '+' Token-Position.
Das Einrücken von Elementen im Cache entspricht auch einer Position im Token-Puffer. Im unteren Bereich befinden sich beispielsweise negative Einträge im Cache, die beim Suchen nach den Regeln 'if' und if_statement am Anfang des if_statement abgerufen wurden. Wir finden auch erfolgreiche Cache-Einträge für das Token '=' und für NAME (insbesondere 'cat' ), die weiteren Eingabepositionen entsprechen.
Sowohl im Analyzer-Stack-Block als auch im Cache-Block werden die zurückgegebenen Aufrufe als function(args) -> result angezeigt. Manchmal werden mehrere zurückgegebene Methoden auf dem Parser-Stapel angezeigt. Ich habe dies getan, um Textjitter durch häufige Inhaltsänderungen zu reduzieren.
(Apropos Jitter: Die oberen Zeilen des Analysatorstapels werden nach oben verschoben, wenn ein Aufruf zum Stapel hinzugefügt wird, und fallen ab, wenn er vom Stapel entfernt wird. Das heißt, jeder neue Aufruf wird ganz unten im Stapelvisualisierungsblock eingefügt und verschiebt die vorhandenen Zeilen nach oben. Es scheint mir Das Betrachten dieses Teils des Bildschirms ist zumindest für mich kein Problem. Wahrscheinlich ist ein bedeutender Teil unseres Gehirns der Verfolgung sich bewegender Objekte gewidmet. :-)
Der Cache wird als LRU gerendert, wobei häufig verwendete Elemente oben angezeigt werden. seltenere gehen den Bildschirm runter. (Der Prototyp des Packrat-Parsers, den ich in früheren Artikeln gezeigt habe, verwendet keine LRU, aber es ist wahrscheinlich eine gute Idee, den Speicherverbrauch zu optimieren.)
Schauen wir uns beim Rendern des Parsing-Stacks einige Details an. Die oberen vier Einträge entsprechen den Parser-Methoden, die noch verarbeitet werden. Jede Zeile ist eine Zeile aus der Grammatik. Das hervorgehobene Element hat die nächste Herausforderung generiert.
Das heißt, Nach dem Screenshot zu urteilen, sind wir bei der zweiten Alternative für die statement , nämlich der assignment . In dieser Regel sind wir am dritten Punkt, nämlich expr . In der expr befinden wir uns nur im ersten Absatz der ersten Alternative ( term '+' expr ); und in der Regel für den term wir in der letzten Alternative ( atom ).
Unten sehen wir das Ergebnis, das zum Scheitern der zweiten Alternative ( atom '/' term ) geführt hat: expect('/') -> None Einrückung mit dem Token '+' . Im nächsten Schritt werden wir sehen, wie es in den Cache gelangt.
Aber sicherlich möchten Sie die gesamte Animation lieber selbst sehen!
Ich habe eine vollständige Analyse des kanonischen Beispielprogramms aufgezeichnet Sie können auch mit vorgefertigtem Code spielen , aber denken Sie daran, dass dies kein Sport ist.
Wenn Sie ein aufgezeichnetes GIF anzeigen, kann es etwas seltsam erscheinen, dass manchmal das nächste Token nicht angezeigt wird (z. B. wächst der Stapel zu Beginn um mehrere Datensätze, bevor das 'aap' Token erkannt wird). Genau das sieht der Analysator: Der Token-Puffer wird träge gefüllt. Tokens werden erst gescannt, wenn der Parser sie durch Aufrufen der Funktion expect() anfordert. Sobald der Token in den Puffer gelangt, bleibt er dort, auch wenn der Analysator die Token-Sequenz zurückspult. Die umgekehrte Verfolgung wird im Token-Puffer mit einem Cursor angezeigt, der nach links springt. Es gibt viele solche Situationen in der Akte. Sie können das Befüllen des Caches auch beobachten, wenn der Analysator keine zusätzlichen rekursiven Aufrufe ausführt. (Ich muss hervorheben, wann dies passiert, aber ich hatte nicht genug Zeit.)
Nächste Woche werde ich einen Parser entwickeln und vielleicht meine Perspektive auf die linken Regeln der rekursiven Grammatik hinzufügen. (Sie sind großartig!)
Danksagung: Für die Aufzeichnung habe ich ttygif von Ilya Choli und ttyrec von Matthew Jording verwendet.
Lizenz für diesen Artikel und zitierten Code: CC BY-NC-SA 4.0