Hallo Habr!
Im Rahmen der Erforschung des Themas C # 8 empfehlen wir, den folgenden Artikel zu den neuen Regeln für die Implementierung von Schnittstellen zu diskutieren.
 Wenn Sie
Wenn Sie sich die Struktur der Schnittstellen
in C # 8 genau ansehen , müssen Sie berücksichtigen, dass Sie bei der Implementierung von Schnittstellen standardmäßig Brennholz beschädigen können.
Annahmen im Zusammenhang mit der Standardimplementierung können zu beschädigtem Code, Laufzeitausnahmen und schlechter Leistung führen.Eine der aktiv beworbenen Funktionen von C # 8-Schnittstellen besteht darin, dass Sie einer Schnittstelle Mitglieder hinzufügen können, ohne vorhandene Implementierer zu beschädigen. Aber Unaufmerksamkeit ist in diesem Fall mit großen Problemen behaftet. Betrachten Sie den Code, in dem die falschen Annahmen getroffen werden - dies macht klarer, wie wichtig es ist, solche Probleme zu vermeiden.
Der gesamte Code für diesen Artikel ist auf GitHub veröffentlicht: jeremybytes / interfaces-in-csharp-8 , speziell im DangerousAssumptions- Projekt .
Hinweis: In diesem Artikel werden die Funktionen von C # 8 erläutert, die derzeit nur in .NET Core 3.0 implementiert sind. In den von mir verwendeten Beispielen Visual Studio 16.3.0 und .NET Core 3.0.100 .
Annahmen zu ImplementierungsdetailsDer Hauptgrund, warum ich dieses Problem artikuliere, ist folgender: Ich habe im Internet einen Artikel gefunden, in dem der Autor Code mit sehr schlechten Annahmen zur Implementierung anbietet (ich werde den Artikel nicht angeben, weil ich nicht möchte, dass der Autor mit Kommentaren aufgerollt wird; ich werde ihn persönlich kontaktieren). .
Der Artikel beschreibt, wie gut die Standardimplementierung ist, da wir damit die Schnittstellen ergänzen können, auch wenn der Code bereits Implementierer enthält. In diesem Code werden jedoch einige schlechte Annahmen getroffen (der Code befindet sich im Ordner
BadInterface of in meinem GitHub-Projekt).
Hier ist die ursprüngliche Oberfläche:
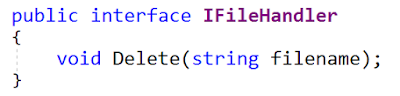
Der Rest des Artikels zeigt die Implementierung der MyFile-Schnittstelle (für mich in der Datei
MyFile.cs ):
Der Artikel zeigt dann, wie Sie die
Rename Methode mit der Standardimplementierung hinzufügen können, ohne dass die vorhandene
MyFile Klasse
MyFile .
Hier ist die aktualisierte Schnittstelle (aus der Datei
IFileHandler.cs ):

MyFile funktioniert immer noch, also ist alles in Ordnung. Also? Nicht wirklich.
Schlechte AnnahmenDas Hauptproblem bei der Umbenennungsmethode besteht darin, dass eine RIESIGE Annahme damit verbunden ist: Implementierungen verwenden eine physische Datei im Dateisystem.
Betrachten Sie die Implementierung, die ich für die Verwendung in einem Dateisystem im RAM erstellt habe. (Hinweis: Dies ist mein Code. Er stammt nicht aus einem Artikel, den ich kritisiere. Die vollständige Implementierung finden Sie in der Datei
MemoryStringFileHandler.cs .)

Diese Klasse implementiert ein formales Dateisystem, das ein Wörterbuch im RAM verwendet, das Textdateien enthält. Hier gibt es keine Auswirkungen auf das physische Dateisystem. Im Allgemeinen gibt es keine Verweise auf
System.IO .
Fehlerhafter ImplementiererNach dem Aktualisieren der Schnittstelle ist diese Klasse beschädigt.
Wenn der Clientcode die Umbenennungsmethode aufruft, wird ein Laufzeitfehler generiert (oder, schlimmer noch, die im Dateisystem gespeicherte Datei umbenannt).
Selbst wenn unsere Implementierung mit physischen Dateien funktioniert, kann sie auf Dateien zugreifen, die sich im Cloud-Speicher befinden, und auf solche Dateien kann nicht über System.IO.File zugegriffen werden.
Es gibt auch ein potenzielles Problem beim Testen von Einheiten. Wenn das simulierte oder gefälschte Objekt nicht aktualisiert wird und der getestete Code aktualisiert wird, versucht es, bei der Durchführung von Komponententests auf das Dateisystem zuzugreifen.
Da die falsche Annahme die Schnittstelle betrifft, sind die Implementierer dieser Schnittstelle beschädigt.
Unangemessene Ängste?Es ist wertlos, solche Befürchtungen für unbegründet zu halten. Wenn ich über Missbräuche im Code spreche, antworten sie mir: "Nun, es ist nur so, dass eine Person nicht weiß, wie man programmiert." Dem kann ich nicht widersprechen.
Normalerweise mache ich das: Ich warte und schaue, wie das funktionieren wird. Ich hatte zum Beispiel Angst, dass die Möglichkeit der "statischen Verwendung" missbraucht würde. Bisher musste dies nicht überzeugt werden.
Es muss bedacht werden, dass solche Ideen in der Luft liegen, daher liegt es in unserer Macht, anderen zu helfen, einen bequemeren Weg einzuschlagen, dessen Befolgung nicht so schmerzhaft sein wird.
LeistungsproblemeIch begann darüber nachzudenken, welche anderen Probleme uns erwarten könnten, wenn wir falsche Annahmen über Schnittstellenimplementierer treffen würden.
Im vorherigen Beispiel wird Code aufgerufen, der sich außerhalb der Schnittstelle selbst befindet (in diesem Fall außerhalb von System.IO). Sie werden wahrscheinlich zustimmen, dass solche Aktionen eine gefährliche Glocke sind. Aber wenn wir die Dinge verwenden, die bereits Teil der Benutzeroberfläche sind, sollte alles in Ordnung sein, oder?
Nicht immer.
Als ausdrückliches Beispiel habe ich die IReader-Schnittstelle erstellt.
Die Quellschnittstelle und ihre ImplementierungHier ist die ursprüngliche IReader-Oberfläche (aus der Datei
IReader.cs - obwohl diese Datei jetzt bereits aktualisiert wurde):

Dies ist eine generische Methodenschnittstelle, mit der Sie eine Sammlung schreibgeschützter Elemente abrufen können.
Eine der Implementierungen dieser Schnittstelle generiert eine Folge von Fibonacci-Zahlen (ja, ich habe ein ungesundes Interesse daran, Fibonacci-Folgen zu erzeugen). Hier ist die
FibonacciReader Oberfläche (aus der Datei
FibonacciReader.cs - sie wird auch auf meinem Github aktualisiert):
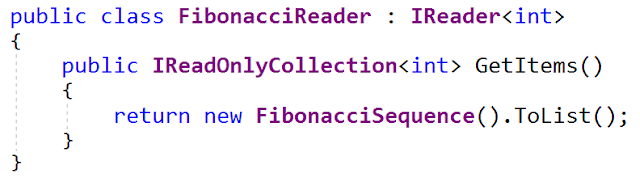
Die
FibonacciSequence Klasse ist eine Implementierung von
IEnumerable <int> (aus der Datei FibonacciSequence.cs). Es wird eine 32-Bit-Ganzzahl als Datentyp verwendet, sodass ein Überlauf recht schnell auftritt.

Wenn Sie an dieser Implementierung interessiert sind, werfen Sie einen Blick auf mein
TDDing in eine Fibonacci-Sequenz in C # -Artikel.
Das DangerousAssumptions-Projekt ist eine Konsolenanwendung, die die Ergebnisse von FibonacciReader (aus der Datei
Program.cs ) anzeigt:

Und hier ist die Schlussfolgerung:
 Aktualisierte Schnittstelle
Aktualisierte SchnittstelleJetzt haben wir also den Arbeitscode. Früher oder später müssen wir möglicherweise ein separates Element von IReader abrufen und nicht die gesamte Sammlung auf einmal. Da wir einen generischen Typ für die Schnittstelle verwenden und dennoch nicht die Eigenschaft "natürliche ID" im Objekt haben, erweitern wir das Element, das sich an einem bestimmten Index befindet.
Hier ist unsere Schnittstelle, zu der die
GetItemAt Methode
GetItemAt (aus der endgültigen Version der Datei
IReader.cs ):

GetItemAt hier eine Standardimplementierung voraus. Auf den ersten Blick - nicht so schlimm. Es wird ein vorhandenes Schnittstellenelement (
GetItems ) verwendet, daher werden hier keine "externen" Annahmen getroffen. Mit den Ergebnissen verwendet er die LINQ-Methode. Ich bin ein großer Fan von LINQ, und dieser Code ist meiner Meinung nach vernünftig aufgebaut.
LeistungsunterschiedeDa die Standardimplementierung
GetItems , muss die gesamte Sammlung zurückgegeben werden, bevor ein bestimmtes Element ausgewählt wird.
Im Fall von
FibonacciReader dies, dass alle Werte generiert werden. In einer aktualisierten Form enthält die Datei
Program.cs den folgenden Code:

Also rufen wir
GetItemAt . Hier ist die Schlussfolgerung:

Wenn wir einen Prüfpunkt in die Datei FibonacciSequence.cs einfügen, sehen wir, dass die gesamte Sequenz dafür generiert wird.
Nachdem wir das Programm gestartet haben, werden wir zweimal auf diesen Kontrollpunkt
GetItems : zuerst beim Aufrufen von
GetItems und dann beim Aufrufen von
GetItemAt .
Leistungsschädigende AnnahmeDas schwerwiegendste Problem bei dieser Methode besteht darin, dass die gesamte Sammlung von Elementen abgerufen werden muss. Wenn dieser
IReader es aus der Datenbank entnehmen will, müssen viele Elemente aus der Datenbank herausgezogen werden, und dann wird nur eines davon ausgewählt. Es wäre viel besser, wenn eine solche endgültige Auswahl in einer Datenbank vorgenommen würde.
In Zusammenarbeit mit unserem
FibonacciReader berechnen wir jedes neue Element. Daher muss die gesamte Liste vollständig berechnet werden, um nur ein Element zu erhalten, das wir benötigen. Die Fibonacci-Sequenzberechnung ist eine Operation, die den Prozessor nicht zu stark belastet. Was aber, wenn wir uns beispielsweise mit etwas Komplizierterem befassen, berechnen wir Primzahlen?
Sie könnten sagen: „Nun, wir haben eine
GetItems Methode, die alles zurückgibt. Wenn es zu lange funktioniert, sollte es wahrscheinlich nicht hier sein. Und das ist eine ehrliche Aussage.
Der aufrufende Code weiß jedoch nichts darüber. Wenn ich
GetItems , weiß ich, dass (wahrscheinlich) meine Informationen über das Netzwerk übertragen werden müssen und dieser Prozess
GetItems ist. Wenn ich nach einem einzelnen Artikel frage, warum sollte ich dann mit solchen Kosten rechnen?
Spezifische LeistungsoptimierungIm Fall von
FibonacciReader wir unsere eigene Implementierung hinzufügen, um die Leistung erheblich zu verbessern (in der endgültigen Version der Datei
FibonacciReader.cs ):

Die
GetItemAt Methode überschreibt die in der Schnittstelle bereitgestellte Standardimplementierung.
Hier verwende ich dieselbe LINQ
ElementAt Methode wie in der Standardimplementierung. Ich verwende diese Methode jedoch nicht mit der schreibgeschützten Auflistung, die GetItems zurückgibt, sondern mit FibonacciSequence, die
IEnumerable .
Da
FibonacciSequence IEnumerable , wird der Aufruf von
ElementAt beendet, sobald das Programm das von uns ausgewählte Element erreicht. Wir generieren also nicht die gesamte Sammlung, sondern nur die Elemente, die sich bis zur angegebenen Position im Index befinden.
Lassen Sie dazu den oben angegebenen Kontrollpunkt in der Anwendung und führen Sie die Anwendung erneut aus. Diesmal
GetItems wir nur einmal auf einen Haltepunkt (beim Aufrufen von
GetItems ). Beim Aufruf von
GetItemAt dies nicht passieren.
Ein leicht erfundenes BeispielDieses Beispiel ist etwas weit hergeholt, da Sie in der Regel keine Elemente aus dem Datensatz nach Index auswählen müssen. Sie können sich jedoch etwas Ähnliches vorstellen, das passieren könnte, wenn wir mit der natürlichen ID-Eigenschaft arbeiten würden.
Wenn wir Elemente nach ID und nicht nach Index abgerufen haben, sind möglicherweise dieselben Leistungsprobleme bei der Standardimplementierung aufgetreten. Die Standardimplementierung erfordert die Rückgabe aller Elemente, wonach nur eines aus ihnen ausgewählt wird. Wenn Sie der Datenbank oder einem anderen „Leser“ erlauben, ein bestimmtes Element anhand seiner ID abzurufen, wäre eine solche Operation viel effizienter.
Denken Sie über Ihre Annahmen nachAnnahmen sind unabdingbar. Wenn wir versuchen würden, mögliche Anwendungsfälle unserer Bibliotheken im Code zu berücksichtigen, würde keine Aufgabe jemals abgeschlossen werden. Sie müssen jedoch die Annahmen im Code sorgfältig prüfen.
Dies bedeutet nicht, dass die
GetElementAt unbedingt fehlerhaft ist. Ja, es gibt potenzielle Leistungsprobleme. Wenn die Datensätze jedoch klein oder die berechneten Elemente „billig“ sind, kann die Standardimplementierung ein vernünftiger Kompromiss sein.
Ich freue mich jedoch nicht über Änderungen an der Schnittstelle, nachdem sie bereits Implementierer hat. Ich verstehe jedoch, dass es auch solche Szenarien gibt, in denen alternative Optionen bevorzugt werden. Programmierung ist die Lösung von Problemen, und bei der Lösung von Problemen müssen die Vor- und Nachteile der einzelnen von uns verwendeten Tools und Ansätze abgewogen werden.
Die Standardimplementierung kann möglicherweise Schnittstellenimplementierern (und möglicherweise dem Code, der diese Implementierungen aufruft) schaden. Daher müssen Sie besonders vorsichtig mit Annahmen sein, die sich auf Standardimplementierungen beziehen.
Viel Glück bei Ihrer Arbeit!