
Die moderne Webinfrastruktur besteht aus vielen Komponenten für verschiedene Zwecke, die offensichtlich und nicht sehr miteinander verbunden sind. Dies wird besonders deutlich, wenn Anwendungen betrieben werden, die unterschiedliche Software-Stacks verwenden, die mit dem Aufkommen von Microservices buchstäblich bei jedem Schritt auftraten. Externe Faktoren (APIs, Dienste usw. von Drittanbietern) werden zum allgemeinen „Spaß“ hinzugefügt, was ein bereits schwieriges Bild kompliziert.
Selbst wenn diese Anwendungen durch gemeinsame architektonische Ideen und Lösungen vereint werden, müssen sie im Allgemeinen häufig durch die nächste unbekannte Wildnis waten, um ungewöhnliche Probleme zu beseitigen. Ob solche Probleme auftreten, ist nur eine Frage der Zeit. Dies sind die Beispiele aus unserer neuesten Praxis, der dieser Artikel gewidmet ist. Darsteller: Golang, Sentry, RabbitMQ, Nginx, PostgreSQL und andere.
Geschichte Nr. 1. Golang und HTTP / 2
Das Ausführen eines Benchmarks, der viele HTTP-Anforderungen an eine Webanwendung ausführt, hat zu unerwarteten Ergebnissen geführt. Eine einfache Go-Anwendung im Benchmark-Prozess wird an eine andere Go-Anwendung gesendet, die sich hinter ingress / openresty befindet. Wenn HTTP / 2 aktiviert ist, erhalten wir für einige Anforderungen Fehler mit Code 400. Um den Grund für dieses Verhalten zu verstehen, haben wir die Go-Anwendung am anderen Ende der Kette entfernt und einen einfachen Speicherort in Ingress erstellt, der immer 200 zurückgibt. Das Verhalten hat sich nicht geändert!
Dann wurde beschlossen, das Skript außerhalb der Kubernetes-Umgebung zu reproduzieren - auf einer anderen Hardware. Das Ergebnis war ein Makefile, mit dessen Hilfe zwei Container gestartet werden: in einem - Benchmarks, die an Nginx gehen, im anderen - in Apache. Beide hören HTTP / 2 mit einem selbstsignierten Zertifikat ab. Die endgültige Betriebszeit finden Sie in
diesem Repository .
Führen Sie die Benchmarks mit
concurrency=200 :
1.1. Nginx:
Completed 0 requests Completed 1000 requests Completed 2000 requests Completed 3000 requests Completed 4000 requests Completed 5000 requests Completed 6000 requests Completed 7000 requests Completed 8000 requests Completed 9000 requests ----- Bench results begin ----- Requests per second: 10336.09 Failed requests: 1623 ----- Bench results end -----
1.2. Apache:
… ----- Bench results begin ----- Requests per second: 11427.60 Failed requests: 0 ----- Bench results end -----
Wir gehen davon aus, dass es hier um eine weniger strenge Implementierung von HTTP / 2 in Apache geht.
Versuchen wir es mit
concurrency=1000 :
2.1. Nginx:
… ----- Bench results begin ----- Requests per second: 11274.92 Failed requests: 4205 ----- Bench results end -----
2.2. Apache:
… ----- Bench results begin ----- Requests per second: 11211.48 Failed requests: 5 ----- Bench results end -----
Gleichzeitig stellen wir fest, dass die Ergebnisse
nicht jedes Mal reproduziert werden : Einige der Starts verlaufen ohne Probleme.
Eine Suche nach Problemen im Github des Golang-Projekts führte zu
# 25009 und
# 32441 . Durch sie gingen wir zu
PR 903 : Deaktivieren von HTTP / 2 in Go standardmäßig!
Das Interpretieren von Benchmark-Ergebnissen, ohne tief in die Architektur der oben genannten Webserver einzutauchen, ist ziemlich schwierig. In einem bestimmten Fall war es ausreichend, HTTP / 2 für den angegebenen Dienst zu deaktivieren.
Geschichte Nr. 2. Alte Symfonie und Wachposten
In einem der Projekte funktioniert noch eine sehr alte Version des symfony PHP Framework (v2.3). Ein alter Raven-Client und eine selbstgeschriebene Klasse in PHP sind "im Kit" angehängt, was das Debuggen etwas erschwert.
Nach der Übertragung eines der Dienste in Kubernetes an Sentry, mit dem Fehler bei der Anwendung dieses Projekts verfolgt wurden, kamen plötzlich keine Ereignisse mehr. Um dieses Verhalten zu reproduzieren, haben wir Beispiele von der Sentry-Website verwendet, zwei Optionen ausgewählt und den DSN aus den Sentry-Einstellungen kopiert. Optisch hat alles geklappt: Fehlermeldungen (angeblich) wurden nacheinander gesendet.
JavaScript-Überprüfungsoption:
<!DOCTYPE html> <html> <body> <script src="https://browser.sentry-cdn.com/5.6.3/bundle.min.js" integrity="sha384-/Cqa/8kaWn7emdqIBLk3AkFMAHBk0LObErtMhO+hr52CntkaurEnihPmqYj3uJho" crossorigin="anonymous"> </script> <h2>JavaScript in Body</h2> <p id="demo">A Paragraph.</p> <button type="button" onclick="myFunction()">Try it</button> <script> Sentry.init({ dsn: 'http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12' }); try { throw new Error('Caught'); } catch (err) { Sentry.captureException(err); } </script> </body> </html>
Ähnlich in Python:
from sentry_sdk import init, capture_message init("http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12") capture_message("Hello World")
Sie kamen jedoch nicht in Sentry. Beim Senden einer Nachricht wird die Illusion erzeugt, dass die Nachricht gesendet wurde, da Clients sofort einen Hash für das Problem generieren.
Infolgedessen wurde das Problem sehr einfach gelöst: Das Senden von Ereignissen ging an HTTP, und der Sentry-Dienst hörte nur HTTPS ab. Es wurde eine Umleitung von HTTP zu HTTPS bereitgestellt, aber der alte Client (der Code auf der Symfony-Seite) konnte den Weiterleitungen nicht folgen, die Sie heutzutage standardmäßig nicht erwarten.
Geschichte Nr. 3. RabbitMQ und Proxy von Drittanbietern
In einem Projekt wird die Evotor-Cloud zum Verbinden von Registrierkassen verwendet. Tatsächlich funktioniert es als Proxy: POST-Anforderungen von Evotor gehen direkt an RabbitMQ - über das über WebSocket-Verbindungen implementierte
STOMP-Plugin .
Einer der Entwickler stellte Testanfragen mit Postman und erhielt die erwarteten Antworten von
200 OK . Anfragen über die Cloud führten jedoch zu unerwarteten
405 Method Not Allowed .
200 OK source: kubernetes namespace: kube-nginx-ingress host: kube-node-2 pod_name: nginx-2bpt7 container_name: nginx stream: stdout app: nginx controller-revision-hash: 5bdbfd564 pod-template-generation: 25 time: 2019-09-10T09:42:50+00:00 request_id: 1271dba228f0943ab2df0196ff0d7f67 user: client address: 100.200.300.400 protocol: HTTP/1.1 scheme: http method: POST host: rmq-review.kube-dev.client.domain path: /api/queues/vhost/queue.gen.eeeeffff111:1.onlinecassa:55556666/get request_query: referrer: user_agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 content_kind: cacheable namespace: review ingress: stomp-ws service: rabbitmq service_port: stats vhost: rmq-review.kube-dev.client.domain location: / nginx_upstream_addr: 10.127.1.1:15672 nginx_upstream_bytes_received: 2538 nginx_upstream_response_time: 0.008 nginx_upstream_status: 200 bytes_received: 757 bytes_sent: 1254 request_time: 0 status: 200 upstream_response_time: 0 upstream_retries: 0
405 Methode nicht zulässig source: kubernetes namespace: kube-nginx-ingress host: kube-node-1 pod_name: nginx-4xx6h container_name: nginx stream: stdout app: nginx controller-revision-hash: 5bdbfd564 pod-template-generation: 25 time: 2019-09-10T09:46:26+00:00 request_id: b8dd789604864c95b4af499ed6805630 user: client address: 200.100.300.400 protocol: HTTP/1.1 scheme: http method: POST host: rmq-review.kube-dev.client.domain path: /api/queues/vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get request_query: referrer: user_agent: ru.evotor.proxy/37 content_kind: cache-headers-not-present namespace: review ingress: stomp-ws service: rabbitmq service_port: stats vhost: rmq-review.kube-dev.client.domain location: / nginx_upstream_addr: 10.127.1.1:15672 nginx_upstream_bytes_received: 134 nginx_upstream_response_time: 0.004 nginx_upstream_status: 405 bytes_received: 878 bytes_sent: 137 request_time: 0 status: 405 upstream_response_time: 0 upstream_retries: 0
Tcpdump-Anfrage von Evotor 200.100.300.400.21519 > 100.200.400.300: Flags [P.], cksum 0x8e29 (correct), seq 1:879, ack 1, win 221, options [nop,nop,TS val 2313007107 ecr 79097074], length 878: HTTP, length: 878 POST /api/queues//vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1 device-model: ST-5 device-os: android Accept-Encoding: gzip content-type: application/json; charset=utf-8 connection: close accept: application/json x-original-forwarded-for: 10.11.12.13 originhost: rmq-review.kube-dev.client.domain x-original-uri: /api/v2/apps/e114-aaef-bbbb-beee-abadada44ae/requests x-scheme: https accept-encoding: gzip user-agent: ru.evotor.proxy/37 Authorization: Basic X-Evotor-Store-Uuid: 20180417-73DC-40C9-80B7-00E990B77D2D X-Evotor-Device-Uuid: 20190909-A47B-40EA-806A-F7BC33833270 X-Evotor-User-Id: 01-000000000147888 Content-Length: 58 Host: rmq-review.kube-dev.client.domain {"count":1,"encoding":"auto","ackmode":"ack_requeue_true"}[!http] 12:53:30.095385 IP (tos 0x0, ttl 64, id 5512, offset 0, flags [DF], proto TCP (6), length 52) 100.200.400.300:80 > 200.100.300.400.21519: Flags [.], cksum 0xfa81 (incorrect -> 0x3c87), seq 1, ack 879, win 60, options [nop,nop,TS val 79097122 ecr 2313007107], length 0 12:53:30.096876 IP (tos 0x0, ttl 64, id 5513, offset 0, flags [DF], proto TCP (6), length 189) 100.200.400.300:80 > 200.100.300.400.21519: Flags [P.], cksum 0xfb0a (incorrect -> 0x03b9), seq 1:138, ack 879, win 60, options [nop,nop,TS val 79097123 ecr 2313007107], length 137: HTTP, length: 137 HTTP/1.1 405 Method Not Allowed Date: Tue, 10 Sep 2019 10:53:30 GMT Content-Length: 0 Connection: close allow: HEAD, GET, OPTIONS
Tcpdump-Anfrage von curl 777.10.74.11.61211 > 100.200.400.300:80: Flags [P.], cksum 0x32a8 (correct), seq 1:397, ack 1, win 2052, options [nop,nop,TS val 734012594 ecr 4012360530], length 396: HTTP, length: 396 POST /api/queues/%2Fvhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1 Host: rmq-review.kube-dev.client.domain User-Agent: curl/7.54.0 Authorization: Basic = Content-Type: application/json Accept: application/json Content-Length: 58 {"count":1,"ackmode":"ack_requeue_true","encoding":"auto"}[!http] 12:40:11.001442 IP (tos 0x0, ttl 64, id 50844, offset 0, flags [DF], proto TCP (6), length 52) 100.200.400.300:80 > 777.10.74.11.61211: Flags [.], cksum 0x2d01 (incorrect -> 0xfa25), seq 1, ack 397, win 59, options [nop,nop,TS val 4012360590 ecr 734012594], length 0 12:40:11.017065 IP (tos 0x0, ttl 64, id 50845, offset 0, flags [DF], proto TCP (6), length 2621) 100.200.400.300:80 > 777.10.74.11.61211: Flags [P.], cksum 0x370a (incorrect -> 0x6872), seq 1:2570, ack 397, win 59, options [nop,nop,TS val 4012360605 ecr 734012594], length 2569: HTTP, length: 2569 HTTP/1.1 200 OK Date: Tue, 10 Sep 2019 10:40:11 GMT Content-Type: application/json Content-Length: 2348 Connection: keep-alive Vary: Accept-Encoding cache-control: no-cache vary: accept, accept-encoding, origin
Das geschulte Auge eines Ingenieurs sieht sofort den Unterschied:
- curl:
POST /api/queues/%2Fclient… - Evotor:
POST /api/queues//client…
Die Sache war, dass in einem Fall ein unverständlicher (für RabbitMQ)
//vhost und in dem anderen -
%2Fvhost , was das erwartete Verhalten ist, wenn:
# rabbitmqctl list_vhosts Listing vhosts ... /vhost
In der
Ausgabe des RabbitMQ-Projekts zu diesem Thema erklärt der Entwickler:
Wir werden% -encoding nicht ersetzen. Es ist eine Standardmethode für die URL-Pfadcodierung und das schon seit Ewigkeiten. Die Annahme, dass die% -Kodierung in HTTP-basierten Tools aufgrund des gängigsten Frameworks, das davon ausgeht, dass solche URL-Pfade "böswillig" sind, nicht mehr funktioniert, ist kurzsichtig und naiv. Der Standardname des virtuellen Hosts kann in einen beliebigen Wert geändert werden (z. B. einen, der keine Schrägstriche oder andere Zeichen verwendet, für die% -Codierung erforderlich ist). Zumindest mit der Pivotal BOSH-Version von RabbitMQ wird der virtuelle Standardhost zum Zeitpunkt der Bereitstellung ohnehin gelöscht .
Das Problem wurde ohne weitere Beteiligung unserer Ingenieure gelöst (auf der Evotor-Seite nach Kontaktaufnahme).
Geschichte Nr. 4. Gen in PostgreSQL
PostgreSQL hat einen sehr nützlichen Index, der oft vergessen wird. Diese Geschichte begann mit Beschwerden über die Bremsen in der Anwendung. In einem
kürzlich erschienenen Artikel haben wir bereits ein Beispiel für einen ungefähren Workflow bei der Analyse solcher Situationen angegeben. Und hier zeigte unser APM -
Atatus - folgendes Bild:

Um 10 Uhr morgens erhöht sich die Zeit, die die Anwendung für die Arbeit mit der Datenbank benötigt. Der Grund liegt erwartungsgemäß in den langsamen Reaktionen des DBMS. Für uns ist es eine verständliche Routine, Abfragen zu analysieren, Problembereiche zu identifizieren und Indizes zu „hängen“. Das
von uns verwendete
Okmeter hilft dabei
sehr : Es gibt sowohl Standard-Panels zur Überwachung des
Serverstatus als auch die Möglichkeit,
schnell eigene zu erstellen - mit der Ausgabe problematischer Metriken:

Diagramme zur CPU-Auslastung zeigen an, dass eine der Datenbanken zu 100% ausgelastet ist. Warum? Die neuen PostgreSQL-Panels werden Folgendes auffordern:

Die Ursache der Probleme ist sofort ersichtlich - der Hauptverbraucher der CPU:
SELECT u.* FROM users u WHERE u.id = ? & u.field_1 = ? AND u.field_2 LIKE '%somestring%' ORDER BY u.id DESC LIMIT ?
In Anbetracht des Arbeitsplans der Problemabfrage haben wir festgestellt, dass das Filtern nach indizierten Feldern der Tabelle eine zu große Auswahl ergibt: Die Datenbank empfängt mehr als
field_1 Zeilen nach
id und
field_1 und sucht dann nach einem Teilstring unter ihnen. Es stellt sich heraus, dass
LIKE auf einem Teilstring eine große Menge von Textdaten durchläuft, was zu einer ernsthaften Verlangsamung der Abfrageausführung und einer Erhöhung der CPU-Auslastung führt.
Hier können Sie zu Recht feststellen, dass ein Architekturproblem nicht ausgeschlossen ist (eine Korrektur der Anwendungslogik oder sogar eine Volltext-Engine ist erforderlich ...), aber es gibt keine Zeit für Nacharbeiten, aber es hätte vor 15 Minuten schnell funktionieren müssen. Gleichzeitig ist das Suchwort tatsächlich eine Kennung (und warum nicht in einem separaten Feld? ..), die Zeileneinheiten erzeugt. Wenn wir einen Index für dieses Textfeld erstellen könnten, wären alle anderen unnötig.Die letzte aktuelle Lösung besteht darin, einen GIN-Index für
field_2 . Das ist der Held des Tages - der gleiche "Geist". Kurz gesagt, GIN ist eine Art Index, der bei der Volltextsuche eine sehr gute Leistung erbringt und ihn qualitativ beschleunigt. Mehr darüber können Sie zum Beispiel in
diesem wunderbaren Material lesen.

Wie Sie sehen können, konnte mit dieser einfachen Operation die zusätzliche Last entfernt und damit Geld für den Kunden gespart werden.
Geschichte Nr. 5. Zwischenspeichern von s3 in Nginx
S3-kompatibler Cloud-Speicher steht seit langem fest auf der Liste der Technologien, die von vielen Projekten verwendet werden. Wenn Sie einen zuverlässigen Bildspeicher für Ihre Site oder für neuronale Netzwerkdaten benötigen, ist Amazon S3 eine gute Wahl. Die Zuverlässigkeit der Speicherung und die hohe Datenverfügbarkeit (und das Fehlen der Notwendigkeit, den Garten zu "umzäunen") sind faszinierend.
Manchmal ist es jedoch eine gute Lösung, einen Caching-Proxyserver vor dem Speicher zu installieren, um Geld zu sparen, da die Zahlung für S3 normalerweise für Anforderungen und für den Datenverkehr erfolgt. Diese Methode reduziert die Kosten, wenn es beispielsweise um Benutzeravatare geht, von denen es auf jeder Seite viele gibt.
Es scheint, dass es einfacher ist, als Nginx zu nehmen und Proxys mit Caching, Revalidierung, Hintergrundaktualisierung und anderem Blackjack einzurichten? Wie auch anderswo gibt es jedoch einige Nuancen ...
Die ungefähre Konfiguration eines solchen Proxys mit Caching sah folgendermaßen aus:
proxy_cache_key $uri; proxy_cache_methods GET HEAD; proxy_cache_lock on; proxy_cache_revalidate on; proxy_cache_background_update on; proxy_cache_use_stale updating error timeout invalid_header http_500 http_502 http_503 http_504; proxy_cache_valid 200 1h; location ~ ^/(?<bucket>avatars|images)/(?<filename>.+)$ { set $upstream $bucket.s3.amazonaws.com; proxy_pass http://$upstream/$filename; proxy_set_header Host $upstream; proxy_cache aws; proxy_cache_valid 200 1h; proxy_cache_valid 404 60s; }
Und im Allgemeinen hat es funktioniert: Bilder wurden angezeigt, alles war in Ordnung mit dem Cache ... es traten jedoch Probleme mit AWS S3-Clients auf. Insbesondere der Client von
aws-sdk-php funktioniert nicht mehr. Die Analyse der Nginx-Protokolle ergab, dass der Upstream 403-Code für HEAD-Anforderungen zurückgab und die Antwort einen bestimmten Fehler enthielt:
SignatureDoesNotMatch . Als wir sahen, dass Nginx eine GET-Anfrage an Upstream sendet, passte alles zusammen.
Tatsache ist, dass der S3-Client jede Anforderung signiert und der Server diese Signatur überprüft. Beim einfachen Proxy funktioniert alles einwandfrei: Die Anfrage erreicht den Server unverändert. Wenn jedoch das Caching aktiviert ist, beginnt nginx mit der Optimierung der Arbeit mit dem Backend und ersetzt HEAD-Anforderungen durch GET. Die Logik ist einfach: Es ist besser, das gesamte Objekt und dann alle HEAD-Anforderungen aus dem Cache abzurufen und zu speichern. In unserem Fall kann die Anforderung jedoch nicht geändert werden, da sie signiert ist.
Es gibt im Wesentlichen zwei Lösungen:
- Fahren Sie S3-Clients nicht über Proxys.
- Wenn dies erforderlich ist,
proxy_cache_convert_head Option proxy_cache_convert_head und fügen $request_method dem Caching-Schlüssel $request_method . In diesem Fall sendet nginx HEAD-Anforderungen "wie sie sind" und speichert die Antworten separat zwischen.
Geschichte Nr. 6. DDoS und Google User Content
Der Sonntagabend war erst plötzlich ein Problem! - Die Warteschlange für die Ungültigmachung des Caches auf Edgeservern ist nicht gewachsen, wodurch echte Benutzer Datenverkehr erhalten. Dies ist ein sehr seltsames Symptom: Schließlich ist der Cache im Speicher implementiert und nicht an Festplatten gebunden. Das Leeren des Caches in der verwendeten Architektur ist eine billige Operation, sodass dieser Fehler nur bei einer wirklich hohen Last auftreten kann. Dies wurde durch die Tatsache bestätigt, dass dieselben Server über das Auftreten von 500 Fehlern zu informieren begannen
(rote Linienspitzen in der folgenden Grafik) .

Ein derart starker Anstieg führte zu CPU-Überläufen:
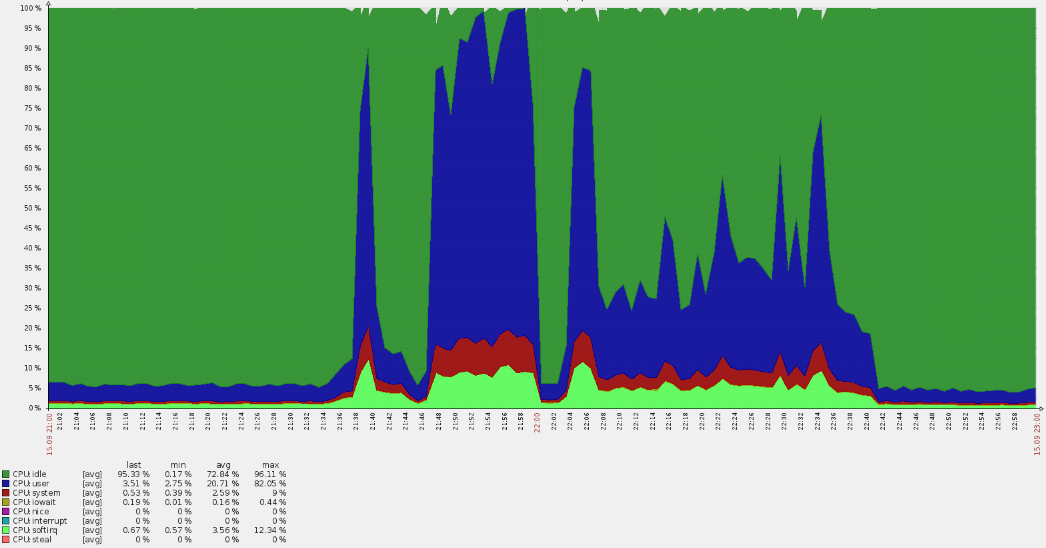
Eine schnelle Analyse ergab, dass die Anforderungen nicht an die Hauptdomänen gingen, aber aus den Protokollen ging hervor, dass sie sich im Standard-vhost befanden. Auf dem Weg stellte sich heraus, dass viele amerikanische Benutzer auf die russische Ressource kamen. Solche Umstände werfen immer sofort Fragen auf.
Nachdem wir Daten aus den Nginx-Protokollen gesammelt hatten, stellten wir fest, dass es sich um ein bestimmtes Botnetz handelt:
35.222.30.127 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?ITPDH=XHJI" HTTP/1.1 301 178 "http://example.ru/ORQHYGJES" "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?ITPDH=XHJI" "redirect=http://www.example.ru/?ITPDH=XHJI" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?REVQSD=VQPYFLAJZ" HTTP/1.1 301 178 "http://www.usatoday.com/search/results?q=MLAJSBZAK" "Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?REVQSD=VQPYFLAJZ" "redirect=http://www.example.ru/?REVQSD=VQPYFLAJZ" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?MPYGEXB=OMJ" HTTP/1.1 301 178 "http://engadget.search.aol.com/search?q=MIWTYEDX" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?MPYGEXB=OMJ" "redirect=http://www.example.ru/?MPYGEXB=OMJ" ancient=1 cipher=- "LM=-;EXP=-;CC=-"
Ein verständliches Muster wird in den Protokollen verfolgt:
- wahrer User-Agent;
- eine Anfrage an die Root-URL mit einem zufälligen GET-Argument, um zu vermeiden, dass sie in den Cache gelangt;
- Referer gibt an, dass die Anfrage von einer Suchmaschine kam.
Wir sammeln die Adressen und überprüfen ihre Zugehörigkeit - sie gehören alle zu
googleusercontent.com mit zwei Subnetzen (107.178.192.0/18 und 34.64.0.0/10). Diese Subnetze enthalten virtuelle GCE-Maschinen und verschiedene Dienste, z. B. die Seitenübersetzung.
Glücklicherweise dauerte der Angriff nicht so lange (ungefähr eine Stunde) und nahm allmählich ab. Es scheint, dass die Schutzalgorithmen in Google funktioniert haben, sodass das Problem "von selbst" gelöst wurde.
Dieser Angriff war nicht destruktiv, warf aber nützliche Fragen für die Zukunft auf:
- Warum haben Anti-DDOs nicht funktioniert? Es wird ein externer Dienst verwendet, an den wir eine entsprechende Anfrage gesendet haben. Es gab jedoch viele Adressen ...
- Wie können Sie sich in Zukunft davor schützen? In unserem Fall sind sogar Optionen zum Schließen des Zugriffs auf geografischer Basis möglich.
PS
Lesen Sie auch in unserem Blog: